基于hugging face的autogptq量化实践
1.量化并保存到本地的
#导入库:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"quantization_config = GPTQConfig(bits=4,group_size=128,dataset="c4",desc_act=False,
)tokenizer = AutoTokenizer.from_pretrained(model_id)
quant_model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config, device_map='auto')
出现问题:
1.关于hugging face无法下载模型、数据的问题
OSError: We couldn’t connect to ‘https://huggingface.co’ to load this file, couldn’t find it in the cached files and it looks like facebook/opt-125m is not the path to a directory containing a file named config.json.
以及ConnectionError: Couldn’t reach ‘allenai/c4’ on the Hub (ConnectTimeout)
采用方法:在官网下载到本地。
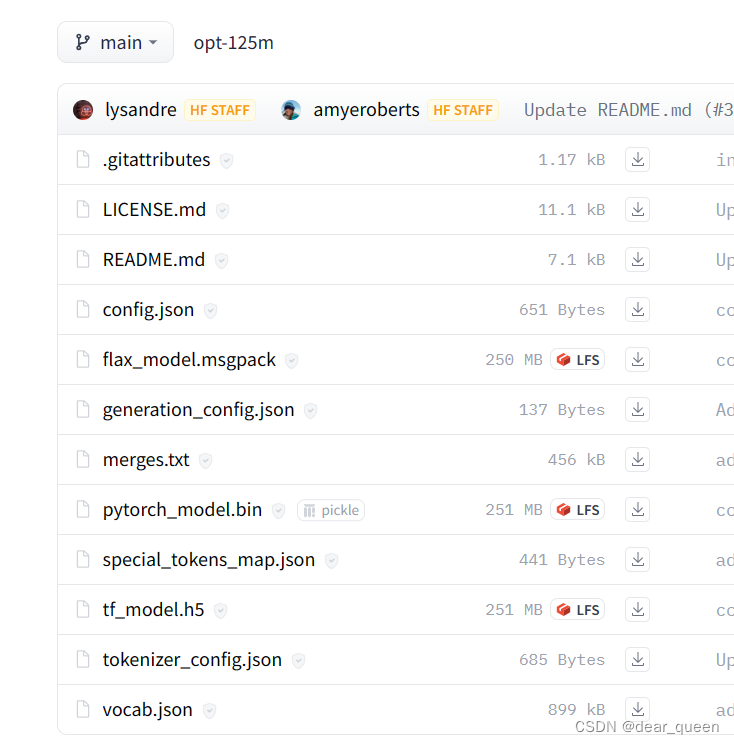
模型:https://huggingface.co/facebook/opt-125m/tree/main
数据集:https://huggingface.co/datasets
完整代码:
####实现基于hugging face的模型量化及保存
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfigmodel_id = "/pytorch/opt-125m"
#可选择公开数据集量化
tokenizer = AutoTokenizer.from_pretrained(model_id)
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
#或者采用自定义数据集量化
dataset = ["auto-gptq 是一个基于 GPTQ 算法的易于使用的模型量化库,具有用户友好的 api。"]
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)#注意,quantization_config用于选择数据集,输出量化后的模型
quant_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto",quantization_config=quantization)
#输出量化后权重,验证是否量化了
# print(quant_model.model.decoder.layers[0].self_attn.q_proj.__dict__)
#测试量化后的模型
text = "My name is"
inputs = tokenizer(text, return_tensors="pt").to(0)out = quant_model.generate(**inputs)
print(tokenizer.decode(out[0], skip_special_tokens=True))examples = [tokenizer("auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm.")
]
#保存量化模型:quant_model.save_pretrained("/pytorch/AutoGPTQ-main/demo/opt-125m-gptq")
tokenizer.save_pretrained("/pytorch/AutoGPTQ-main/demo/opt-125m-gptq")
从hugging face已经量化好的模型加载到本地
###加载hugging face Hub中已量化好的模型到本地,并测试其效果
from transformers import AutoTokenizer, AutoModelForCausalLM# model_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
model_id = "/pytorch/llama"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(model)
print(model.config.quantization_config.to_dict())
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt").to(0)
out = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(out[0], skip_special_tokens=True))
参考:
colab文档关于autogptq量化模型实践
hugging face官网
github快速实践
github高阶实践
transformer bitsandbytes通过int4量化LLM
其他
相关文章:
基于hugging face的autogptq量化实践
1.量化并保存到本地的 #导入库: from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig model_id "facebook/opt-125m"quantization_config GPTQConfig(bits4,group_size128,dataset"c4",desc_actFalse, )tokenizer A…...

MySQL2:MySQL中一条查询SQL是如何执行的?
MySQL2:MySQL中一条查询SQL是如何执行的? MySQL中一条查询SQL是如何执行的?1.连接怎么查看MySQL当前有多少个连接?思考:为什么连接数是查看线程?客户端的连接和服务端的线程有什么关系?MySQL参数…...
C++入门01—从hello word!开始
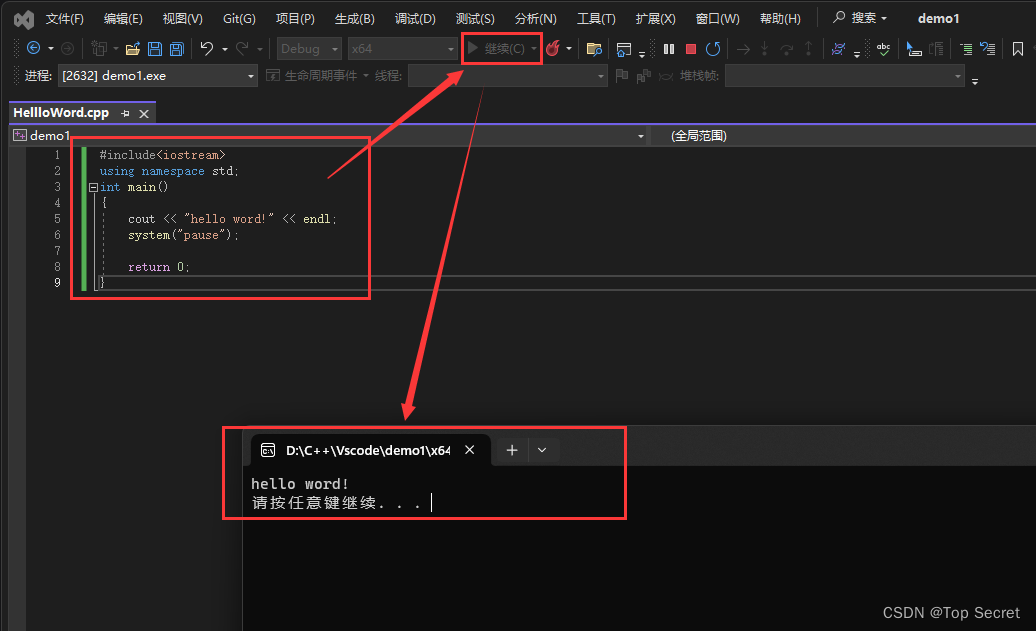
1.第一个C程序 1.1 创建项目 第一次使用Visual Studio时: 1.2 创建文件 1.3 编写代码 编写第一个代码: #include<iostream> using namespace std; int main() {cout << "hello word!" << endl;system("pause"…...
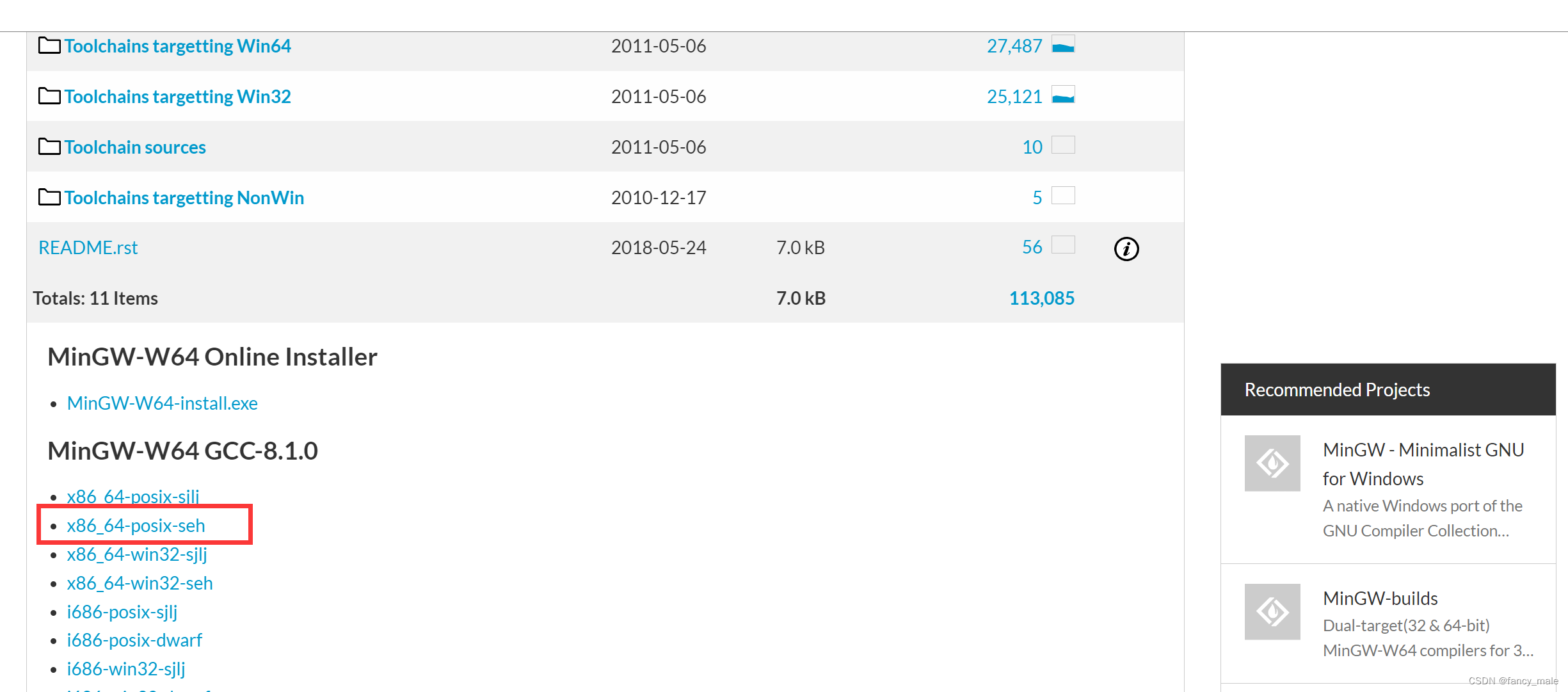
Mingw下载---运行vscodeC++文件
下载 下载网址: https://sourceforge.net/projects/mingw-w64/files/mingw-w64/mingw-w64-release/ 翻到最下面,选择win64的安装: 下载完,解压到没有空格和中文字符的路径。不然在vscode中运行不了C代码。...

数据安全与PostgreSQL:最佳保护策略
在当今数字化时代,数据安全成为了企业不可或缺的一环。特别是对于使用数据库管理系统(DBMS)的组织来说,确保数据的完整性、保密性和可用性至关重要。在众多DBMS中,PostgreSQL作为一个强大而灵活的开源数据库系统&#…...

火山引擎实时、低延时拥塞控制算法的优化实践
摘要 火山引擎智能拥塞控制算法 VICC(Volcano Intelligent Congestion Control)是一种自适应的拥塞控制算法,旨在解决全球不同网络环境下,不同音视频应用对带宽利用率和延时的差异化要求。它结合了传统拥塞控制算法(如…...

adb设备调试常用命令
自从工作越来越忙后,越来越懒得写文章了,趁着1024程序员节,仪式性地写篇文章,分享一下最近调试设备经常用到的adb指令~ 1.查看应用内存占用 1.1 dumpsys meminfo package dumpsys是查看系统服务信息的一个常用指令,可…...

ubuntu下Docker的简单使用并利用主机显示
首先分享一个docker镜像的网站:https://hub.docker.com/search?q 这个网站里面有很多配置好的镜像,可以直接拉取。 下面介绍一下docker的安装和使用。 1、docker得到安装: sudo apt-get install docker 2、docker拉取一个镜像到本地,这里我…...

第12章 PyTorch图像分割代码框架-1
从本章开始,本书将会进行深度学习图像分割的实战阶段。PyTorch作为目前最为流行的一款深度学习计算框架,在计算机视觉和图像分割任务中已经广泛使用。本章将介绍基于PyTorch的深度学习图像分割代码框架,在总体框架的基础上,基于PA…...

2023CSPJ 旅游巴士 —— dijkstra
This way 题意: 给你一个有向图,1号点为起点,n为终点。你可以在k的倍数的时间点在起点开始,每条边的边长为1,同时,每条边有一个限定时间ai,表示你必须在大于等于ai的时间点才能走这条边。 …...
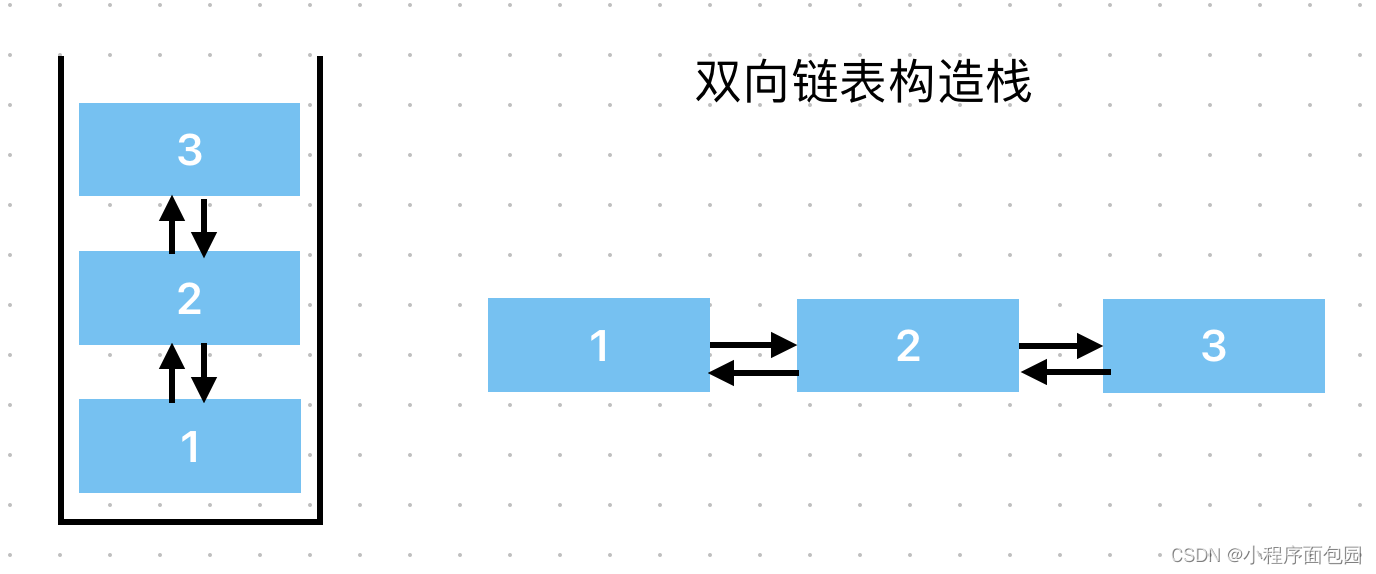
数据结构之栈的讲解(源代码+图解+习题)
我们在学习过顺序表和链表之后,了解了使用数组存储数据,使用结构体来存储数据和有关的指针,这些都是底层的东西,链表是靠指针的链接,顺序表是靠数组的下标才能得以实现增删查改。众多数据结构其实底层都离不开数组&…...
内网渗透-内网信息收集
内网信息收集 前言 当我们进行外网信息收集,漏洞探测以及漏洞利用后,获得了主机的权限后,我们需要扩大渗透的战果时,这是我们就要进行内网的渗透了,内网渗透最重要的还是前期的信息收集的操作了,就是我们的…...

LeetCode解法汇总2520. 统计能整除数字的位数
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 给你一个整…...

Lua语言编写爬虫程序
以下是一个使用luasocket-http库和Lua语言编写的爬虫程序。此程序使用了https://www.duoip.cn/get_proxy的代码。 -- 引入所需的库 local http require("socket.http") local ltn12 require("ltn12") local json require("json") -- 获取…...

安防监控项目---概要
文章目录 前言一、项目需求二、环境介绍三、关键点四、主框架分析总结 前言 各位小伙伴,在蛰伏了将近有半年的时间又要和大家分享新的知识了,这次和大家分享的是一个项目,因此呢我准备分项目阶段去和大家分享,希望大家都能够在每…...

数仓经典面试题
1.什么是数据仓库?请谈谈你对数据仓库的理解。 数据仓库是一个用于存储和管理数据的系统,它可以将分散的、异构的数据源中的数据进行抽取、转换、清洗和整合,然后按照一定的模型和架构进行组织和存储,以便更好地支持决策分析和业…...

【ARM Coresight 系列文章 15.2 – components power domain 详细介绍】
文章目录 1.1. Coresight 电源域模型1.1.1 CDBGPWRUPREQ 和 CDBGPWRUPACK1.1.2 CSYSPWRUPREQ 和 CSYSPWRUPACK1.1.3 Power Domain ID In RomTable1.1.4 Power domain entries1.1.5 Algorithm to discover power domain IDs1.1.6 Debug power requests1.1.7 System power reques…...

Flutter Android IOS 获取通讯录联系人列表
1.在pubspec.yaml 文件中添加 contacts_service 和 permission_handler 插件的依赖: dependencies:contacts_service: ^0.6.3 #获取联系人permission_handler: ^11.0.1 #权限请求2.在你的 Dart 代码中,导入 contacts_service 插件: impo…...
Spring Boot集成SpringFox 3.0与Pageable参数处理
Springfox 3.0有多个模块,提供了spring boot starter,与Spring Boot集成时仅需引入springfox-boot-starter,如下: <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter<…...

2、基于pytorch lightning的fabric实现pytorch的多GPU训练和混合精度功能
文章目录 承接 上一篇,使用原始的pytorch来实现多GPU训练和混合精度,现在对比以上代码,我们使用Fabric来实现相同的功能。关于Fabric,我会在后续的博客中继续讲解,是讲解,也是在学习。通过fabric,可以减少代码量&#…...

UltraStar Deluxe:零成本构建专业家庭K歌系统的完整指南
UltraStar Deluxe:零成本构建专业家庭K歌系统的完整指南 【免费下载链接】USDX The free and open source karaoke singing game UltraStar Deluxe, inspired by Sony SingStar™ 项目地址: https://gitcode.com/gh_mirrors/us/USDX UltraStar Deluxe是一款开…...

【磁盘】gdisk 实战:分区创建与删除的完整流程解析
1. 认识gdisk:你的磁盘分区利器 第一次接触磁盘分区工具时,我完全被各种专业术语搞晕了。直到遇到gdisk,才发现原来分区可以这么简单。gdisk是Linux环境下专门用于GPT分区表的交互式工具,相比传统的fdisk,它支持更大容…...

如何用Python处理杭州交通数据集?从roadnet.json到flow.json的完整解析指南
杭州交通数据实战:用Python解析roadnet.json与flow.json的进阶技巧 第一次接触杭州交通数据集时,我被roadnet.json里密密麻麻的交叉点坐标和flow.json中流动的车辆轨迹震撼到了——这哪是数据文件,分明是一座数字孪生城市的血管与血液。作为算…...

终极Emscripten编译缓存策略:加速WebAssembly项目构建的完整指南
终极Emscripten编译缓存策略:加速WebAssembly项目构建的完整指南 【免费下载链接】emscripten Emscripten: An LLVM-to-WebAssembly Compiler 项目地址: https://gitcode.com/gh_mirrors/em/emscripten Emscripten作为一款强大的LLVM-to-WebAssembly编译器&a…...

HarfBuzz完全指南:如何理解字体渲染引擎的核心技术与字体子集化实践 [特殊字符]
HarfBuzz完全指南:如何理解字体渲染引擎的核心技术与字体子集化实践 🚀 【免费下载链接】harfbuzz HarfBuzz text shaping engine 项目地址: https://gitcode.com/gh_mirrors/ha/harfbuzz HarfBuzz是一个开源的文本整形引擎,专门处理复…...

Playwright浏览器上下文全解析:如何用Python实现多账号同时登录测试?
Playwright浏览器上下文全解析:如何用Python实现多账号同时登录测试? 在当今复杂的Web应用生态中,自动化测试工程师经常面临一个核心挑战:如何高效模拟真实用户的多账号并行操作场景?无论是电商平台的促销活动测试、社…...

5大核心功能解锁N_m3u8DL-RE:跨平台流媒体下载终极指南
5大核心功能解锁N_m3u8DL-RE:跨平台流媒体下载终极指南 【免费下载链接】N_m3u8DL-RE 跨平台、现代且功能强大的流媒体下载器,支持MPD/M3U8/ISM格式。支持英语、简体中文和繁体中文。 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

窗口置顶技术突破:AlwaysOnTop重构多任务处理逻辑
窗口置顶技术突破:AlwaysOnTop重构多任务处理逻辑 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 在数字化工作环境中,窗口管理效率直接影响任务处理速度…...

突破本地开发壁垒:tunnelto无缝连接全球网络的技术革新
突破本地开发壁垒:tunnelto无缝连接全球网络的技术革新 【免费下载链接】tunnelto Expose your local web server to the internet with a public URL. 项目地址: https://gitcode.com/GitHub_Trending/tu/tunnelto 痛点诊断:当本地服务成为协作孤…...

【3D设计】资源获取方法论:7个精准化策略助你高效获取专业级素材
【3D设计】资源获取方法论:7个精准化策略助你高效获取专业级素材 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在3D内容创作领域,优质资源…...