在Go项目中二次封装Kafka客户端功能
1.摘要
在上一章节中,我利用Docker快速搭建了一个Kafka服务,并测试成功Kafka生产者和消费者功能,本章内容尝试在Go项目中对Kafka服务进行封装调用, 实现从Kafka自动接收消息并消费。
在本文中使用了Kafka的一个高性能开源库Sarama, Sarama是一个遵循MIT许可协议的Apache Kafka Go客户端库, 该开源库地址为:GitHub - IBM/sarama: Sarama is a Go library for Apache Kafka.。
2.功能结构组织
为了能在项目中快速使用, 我在项目目录中专门新建了一个名为kafka的文件夹,在该文件夹下新建了四个文件,分别为:
kafka (目录)|----- consumer.go (消费者方法实现)|----- producer.go (生产者方法实现)|----- kafka.go (定义接口)|----- kafka_test.go (单元功能测试)为方便项目使用,在此基础上做了二次封装。
3.消费者实现
第一步首先定义了一个结构体, 里面包含了Kafka的主机、topic、接收通道和消费者对象信息:
type KafkaConsumer struct {Hosts string // Kafka主机IP:端口,例如:192.168.201.206:9092Ctopic string // topic名称Kchan chan string // 接收信息通道Consumer sarama.Consumer // 消费者对象
}接下来是消费者初始化函数:
func (k *KafkaConsumer) kafkaInit() {// 定义配置选项 config := sarama.NewConfig()config.Consumer.Return.Errors = trueconfig.Version = sarama.V0_10_2_0// 初始化一个消费对象consumer, err := sarama.NewConsumer(k.Hosts, config)if err != nil {err = errors.New("NewConsumer错误,原因:" + err.Error())fmt.Println(err.Error())return}// 获取所有Topictopics, err := consumer.Topics()if err != nil {fmt.Println(err.Error())return}// 判断是否有自定义的Topicvar topicsName = ""for _, e := range topics {if e == k.Ctopic {topicsName = ebreak}}// 没有自定义的Topic则报错if topicsName == "" {err = errors.New("找不到topics内容")fmt.Println(err.Error())return}// 将消费对象保存到结构体以备后面使用k.Consumer = consumer
}在上面的初始化函数中, 首先初始化一个消费对象, 然后获取所有的Topic名称,并判断了在这些Topic名称中是否有我自定义的名称,获取成功后则将消费对象保存到我们绑定的结构体中。
接下来是消费监控函数实现,代码如下:
func (k *KafkaConsumer) kafkaProcess() {var wg sync.WaitGroup// 遍历指定Topic分区持续监控消息Partitions, _ := k.Consumer.Partitions(k.Ctopic)for _, subPartitions := range Partitions {pc, err := k.Consumer.ConsumePartition(k.Ctopic, subPartitions, sarama.OffsetNewest)if err != nil {continue}wg.Add(1)go func() {defer wg.Done()// 这里进入另一个函数可以过滤消息内容k.processPartition(pc)}()}wg.Wait()
}函数processPartition()的实现代码如下:
func (k *KafkaConsumer) processPartition(pc sarama.PartitionConsumer) {defer pc.AsyncClose()for msg := range pc.Messages() {// 这里可以过滤不需要的Topic的信息if strings.Contains(string(msg.Value), "group_state2") {continue}// 这里将获取到的Topic信息发送到通道k.Kchan <- string(msg.Value)}
}4.生产者实现
为了跟消费者代码配套,这里也同步实现了生产者代码,主要功能是完成工作后,给指定Topic的生产方返回一个指定消息。
定义生产者的结构体如下:
type KafkaProducer struct {hosts string // Kafka主机sendmsg string // 消费方返回给生产方的消息ptopic string // TopicAsyncProducer sarama.AsyncProducer // Kafka生产者接口对象
}对应的生产者初始化函数实现如下:
func (k *KafkaProducer) kafkaInit() {// 定义配置参数config := sarama.NewConfig()config.Producer.RequiredAcks = sarama.WaitForAllconfig.Producer.Retry.Max = 5config.Producer.Return.Successes = trueconfig.Version = sarama.V0_10_2_0// 初始化一个生产者对象producer, err := sarama.NewAsyncProducer(k.hosts, config)if err != nil {err = errors.New("NewAsyncProducer错误,原因:" + err.Error())fmt.Println(err.Error())return}// 保存对象到结构体k.AsyncProducer = producer
}给生产者回复信息的函数实现如下:
func (k *KafkaProducer) kafkaProcess() {msg := &sarama.ProducerMessage{Topic: k.ptopic,}// 信息编码msg.Value = sarama.ByteEncoder(k.sendmsg)// 将信息发送给通道k.AsyncProducer.Input() <- msg
}5.接口定义实现
首先对于生产者和消费者,都有对应的初始化和执行操作,因此定义接口函数如下:
// Kafka方法接口
type IKafkaMethod interface {kafkaInit() // 初始化方法kafkaProcess() // 执行方法
}为了方便管理接口的赋值操作, 这里定义了一个接口管理方法, 并用Set()函数进行接口类型赋值, Run()函数负责运行对应的成员函数:
// 接口管理结构体
type KafkaManager struct {kafkaMethod IKafkaMethod // 接口对象
}// 定义实现Set方法
func (km *KafkaManager) Set(m IKafkaMethod) {km.kafkaMethod = m // 将指定的方法赋给接口
}// 定义实现Run方法
func (km *KafkaManager) Run() {km.kafkaMethod.kafkaInit()go km.kafkaMethod.kafkaProcess()
}最后一部分是供外部调用的函数,首先定义一个结构体,该结构体中保存了Kafka的基础信息和三个对象指针:
type KafkaMessager struct {KafkaManager *KafkaManager // 接口管理对象指针KafkaProducer *KafkaProducer // 生产者对象指针KafkaConsumer *KafkaConsumer // 消费者对象指针Hosts string // Kafka主机topic string // topic
}// 供外部调用初始化的函数,传入Kafka主机IP和Topic,返回操作对象指针,并初始化结构体成员变量
func NewKafkaMessager(hosts, topic string) *KafkaMessager {km := &KafkaMessager{KafkaManager: new(KafkaManager),KafkaProducer: new(KafkaProducer),KafkaConsumer: new(KafkaConsumer),Hosts: hosts,topic: topic,}return km
}6.功能调用和验证
在Kafka_test.go文件中,定义一个用于单元测试的函数,格式如下:
func TestKafka(t *testing.T) {....
}使用单元测试函数的好处是可以单独调试, 专注核心功能本身。
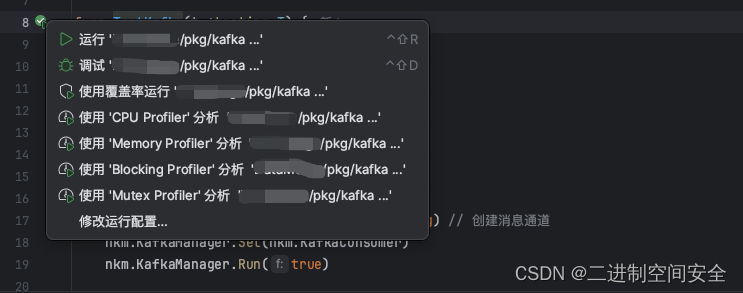
我使用的编辑器是Goland, 在TestKafka函数前面有个三角形小图标,点击可以选择各种调试选项,如图:
下面是我模拟用户调用的客户端代码片段:
// 这里选择我自己搭建的Kafka所在服务器,Topic为test123
// 注意:这里的hosts格式是IP:端口的格式,例如:192.168.201.206:9092
hosts := "192.168.201.206:9092"
topic := "test123"// 调用初始化函数,并将上面的内容作为参数传进去
nkm := NewKafkaMessager(hosts, topic)// 初始化消费者,当生产者发出消息,消费者自动消费
nkm.KafkaConsumer.Hosts = hosts // 消费者host赋值
nkm.KafkaConsumer.Ctopic = topic // 消费者topic赋值
nkm.KafkaConsumer.Kchan = make(chan string) // 初始化消息通道
nkm.KafkaManager.Set(nkm.KafkaConsumer) // 接口赋值,设置成操作消费者方法
nkm.KafkaManager.Run() // 执行消费者初始化方法// 监听通道,接收生产客户端发过来的消息
recv := <- nkm.KafkaConsumer.Kchan
fmt.Println(recv) // 打印接收到的消息现在我们可以选择直接运行程序了,然后在Kafka的生产者控制台中输入字符:Hello,Goland发送:

可以看到,我们的程序成功接收到Kafka生产者发送过来的信息。
--- END --
相关文章:
在Go项目中二次封装Kafka客户端功能
1.摘要 在上一章节中,我利用Docker快速搭建了一个Kafka服务,并测试成功Kafka生产者和消费者功能,本章内容尝试在Go项目中对Kafka服务进行封装调用, 实现从Kafka自动接收消息并消费。 在本文中使用了Kafka的一个高性能开源库Sarama, Sarama是一个遵循MIT许可协议的Apache Kafk…...

CVE-2021-44228 Apache log4j 远程命令执行漏洞
一、漏洞原理 log4j(log for java)是由Java编写的可靠、灵活的日志框架,是Apache旗下的一个开源项目,使用Log4j,我们更加方便的记录了日志信息,它不但能控制日志输出的目的地,也能控制日志输出的内容格式;…...

前端跨域相关
注:前端配置跨域后服务器端(Nginx)也需要配置,否则接口无法访问 vue跨域 配置文件 /vue.config.js devServer: { port: 7100, proxy: { /api: { target: http://域名, changeOrigin: true, logLevel: debug, pathRewrite: { ^/…...
HTML笔记-狂神
1. 初识HTML 什么是HTML? Hyper Text Markup Language : 超文本标记语言 超文本包括:文字、图片、音频、视频、动画等 目前使用的是HTML5,使用 W3C标准 W3C标准包括: 结构化标准语言(HTML、XML) 表现标…...

python自动化测试工具selenium
概述 selenium是网页应用中最流行的自动化测试工具,可以用来做自动化测试或者浏览器爬虫等。官网地址为:Selenium。相对于另外一款web自动化测试工具QTP来说有如下优点: 免费开源轻量级,不同语言只需要一个体积很小的依赖包支持…...
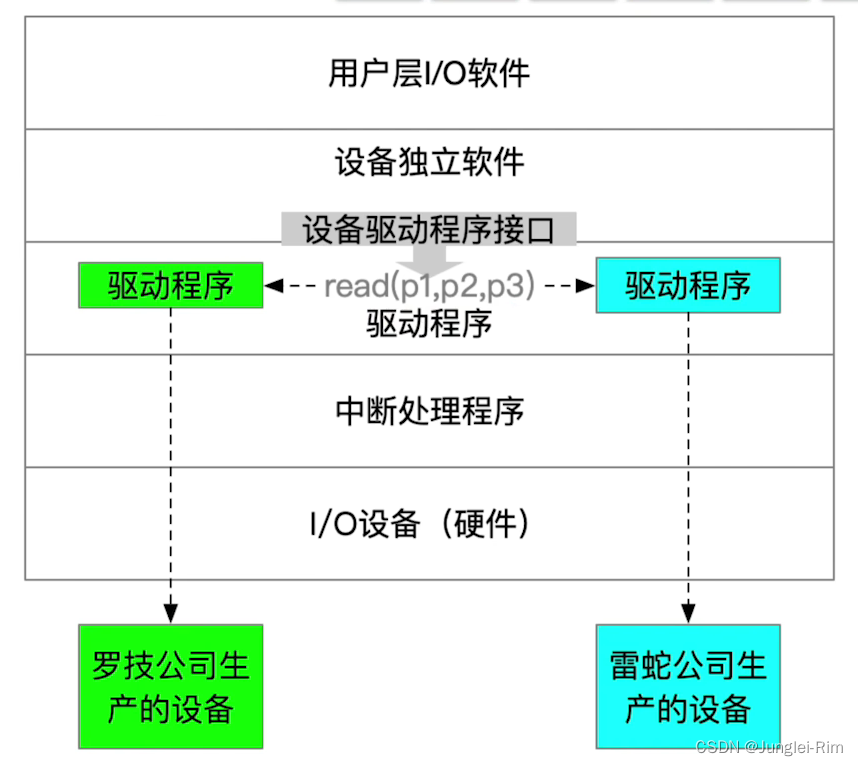
输入/输出应用程序接口和设备驱动程序接口
文章目录 1.输入/输出应用程序接口1.字符设备接口2.块设备接口3.网络设备接口1.网络设备套接字通信 4.阻塞/非阻塞I/O 2.设备驱动程序接口1.统一标准的设备驱动程序接口 1.输入/输出应用程序接口 1.字符设备接口 get/put系统调用:向字符设备读/写一个字符 2.块设备接口 read/wr…...

Python---Socket 网络通信
Socket :进程之间通信的工具,进程之间想要进行网络通信需要Socket,两个进程之间通过socket进行相互通讯,就必须有服务端和客服端。 Socket服务端编程 # 1.创建socket对象 import socketsocket_server socket.socket()# 2. 绑定socket_server到指定IP和…...
使用 jdbc 技术升级水果库存系统(优化版本)
抽取执行更新方法抽取查询方法 —— ResultSetMetaData ResultSetMetaData rsmd rs.getMetaData();//元数据,结果集的结构数据 抽取查询方法 —— 解析结果集封装成实体对象提取 获取连接 和 释放资源 的方法将数据库配置信息转移到配置文件 <dependencies><depend…...
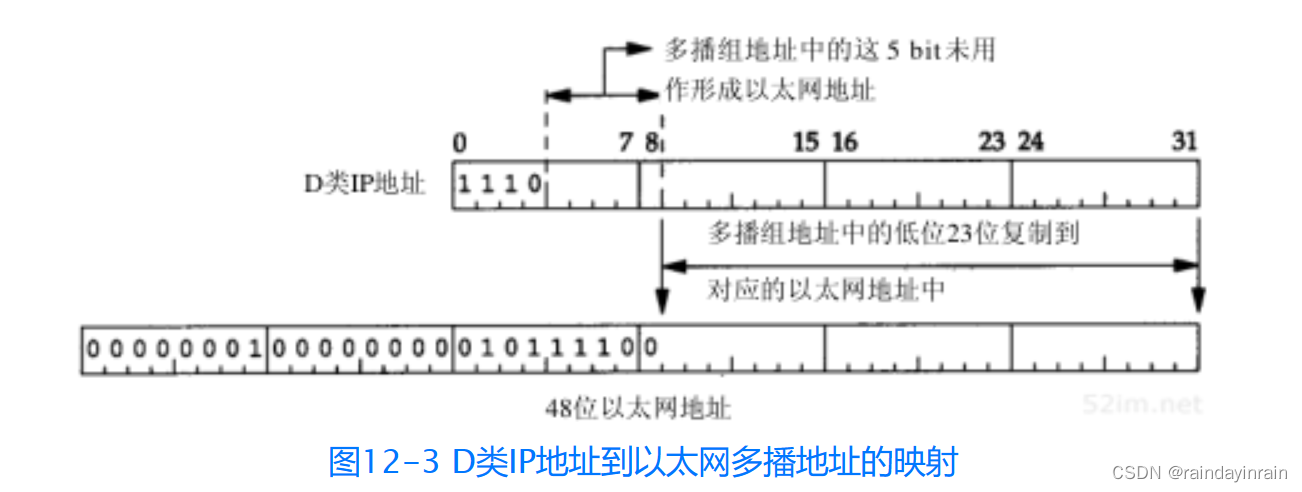
网络协议--广播和多播
12.1 引言 在第1章中我们提到有三种IP地址:单播地址、广播地址和多播地址。本章将更详细地介绍广播和多播。 广播和多播仅应用于UDP,它们对需将报文同时传往多个接收者的应用来说十分重要。TCP是一个面向连接的协议,它意味着分别运行于两主…...
正则表达式)
python爬虫入门(三)正则表达式
开源中国提供的正则表达式测试工具 http://tool.oschina.net/regex/,输入待匹配的文本,然后选择常用的正则表达式,就可以得出相应的匹配结果了 常用的匹配规则如下 模 式描 述\w匹配字母、数字及下划线\W匹配不是字母、数字及下划线的…...

fabric.js介绍
fabric.js是可以简化canvas编写的js库,提供canvas缺少的对象模型,包含动画、数据序列化和反序列化的等高级功能的js库,开源项目,在GitHub有很多人贡献。 官网:Fabric.js Javascript Canvas Library (fabricjs.com) 文档…...

YOLOv5源码中的参数超详细解析(3)— 训练部分(train.py)| 模型训练调参
前言:Hello大家好,我是小哥谈。YOLOv5项目代码中,train.py是用于模型训练的代码,是YOLOv5中最为核心的代码之一,而代码中的训练参数则是核心中的核心,只有学会了各种训练参数的真正含义,才能使用YOLOv5进行最基本的训练。🌈 前期回顾: YOLOv5源码中的参数超详细解析…...

Linux高性能编程学习-TCP/IP协议族
一、TCP/IP协议族结构与主要协议 分层:数据链路层、网络层、传输层、应用层 1. 数据链路层 功能:实现网卡驱动程序,处理数据在不同物理介质的传输 协议: ARP:将目标机器的IP地址转成MAC地址RARP:将MAC地…...

用爬虫代码爬取高音质音频示例
目录 一、准备工作 1、安装Python和相关库 2、确定目标网站和数据结构 二、编写爬虫代码 1、导入库 2、设置代理IP 3、发送HTTP请求并解析HTML页面 4、查找音频文件链接 5、提取音频文件名和下载链接 6、下载音频文件 三、完整代码示例 四、注意事项 1、遵守法律法…...
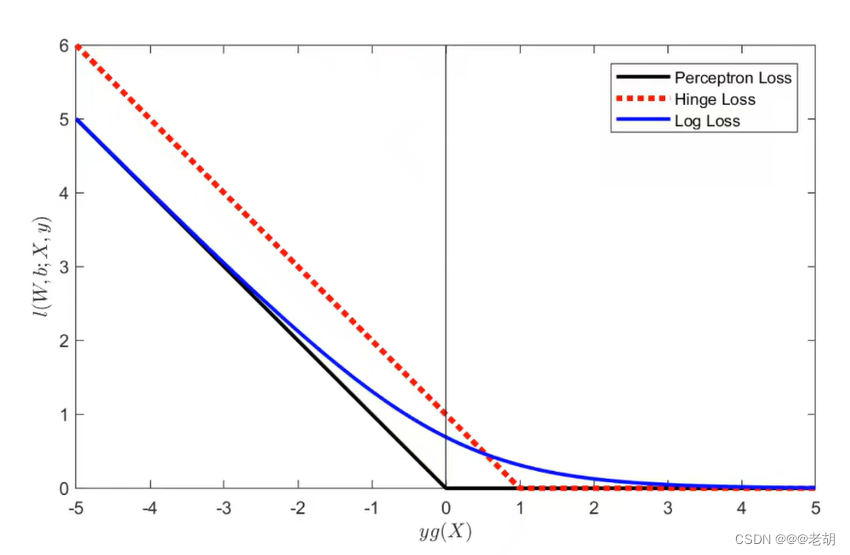
深度学习与计算机视觉(一)
文章目录 计算机视觉与图像处理的区别人工神经元感知机 - 分类任务Sigmoid神经元/对数几率回归对数损失/交叉熵损失函数梯度下降法- 极小化对数损失函数线性神经元/线性回归均方差损失函数-线性回归常用损失函数使用梯度下降法训练线性回归模型线性分类器多分类器的决策面 soft…...
【vector题解】杨辉三角 | 删除有序数组中的重复项 | 只出现一次的数字Ⅱ
杨辉三角 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1…...
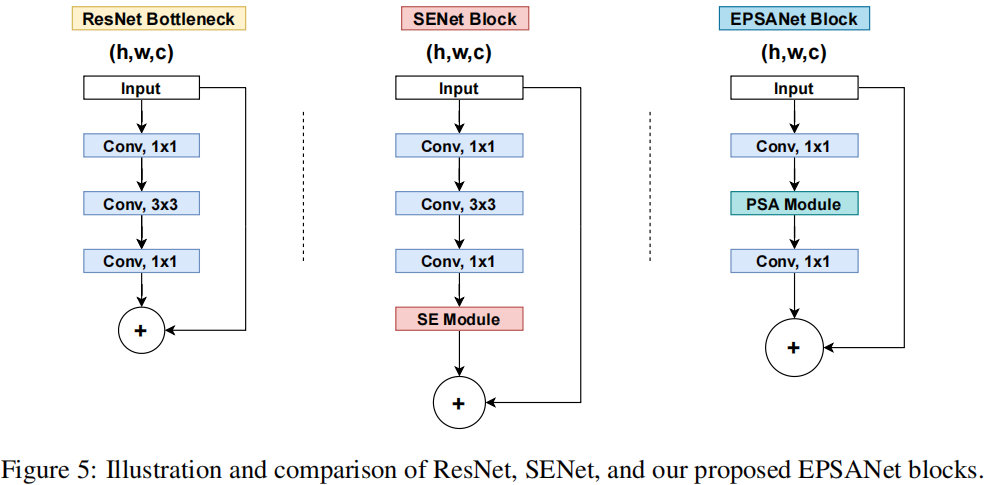
金字塔切分注意力模块PSA学习笔记 (附代码)
已有研究表明:将注意力模块嵌入到现有CNN中可以带来显著的性能提升。比如,SENet、BAM、CBAM、ECANet、GCNet、FcaNet等注意力机制均带来了可观的性能提升。但是,目前仍然存在两个具有挑战性的问题需要解决。一是如何有效地获取和利用不同尺度…...
Jenkins自动化测试
学习 Jenkins 自动化测试的系列文章 Robot Framework 概念Robot Framework 安装Pycharm Robot Framework 环境搭建Robot Framework 介绍Jenkins 自动化测试 1. Robot Framework 概念 Robot Framework是一个基于Python的,可扩展的关键字驱动的自动化测试框架。 它…...

python 字典dict和列表list的读取速度问题, range合并
嗨喽,大家好呀~这里是爱看美女的茜茜呐 python 字典和列表的读取速度问题 最近在进行基因组数据处理的时候,需要读取较大数据(2.7G)存入字典中, 然后对被处理数据进行字典key值的匹配,在被处理文件中每次…...
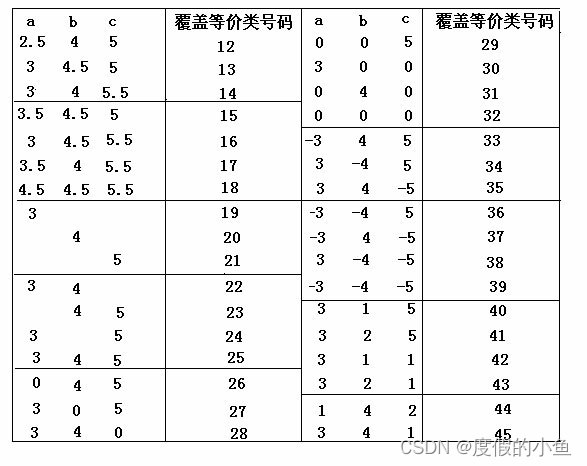
测试用例的设计方法(全):等价类划分方法
一.方法简介 1.定义 是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的,常用的黑盒测试用例设计方法。 2.划分等价类: 等价类是指某个输入域的…...

Pop 核心架构解析:深入理解 Bubble Tea 框架与邮件发送原理
Pop 核心架构解析:深入理解 Bubble Tea 框架与邮件发送原理 【免费下载链接】pop Send emails from your terminal 📬 项目地址: https://gitcode.com/gh_mirrors/pop2/pop 想要在终端中优雅地发送邮件吗?Pop 是一个基于 Go 语言开发的…...

PX4飞控自定义Mavlink消息:实现UART传感器数据在QGC地面站的可视化
1. 为什么需要自定义Mavlink消息 在无人机开发中,我们经常需要将各种传感器数据实时传输到地面站进行监控和分析。PX4飞控虽然内置了丰富的标准Mavlink消息,但当我们接入一些特殊传感器时,标准消息往往无法满足需求。比如你想通过UART串口接入…...

ai域名后缀注册对SEO有影响吗
ai域名后缀注册对SEO有影响吗 在当今互联网时代,域名选择对于一个网站的成功至关重要。尤其是对于那些在科技、人工智能(AI)等前沿领域的企业和个人来说,ai域名后缀注册的问题更是备受关注。本文将从多个角度探讨ai域名后缀注册对…...

Project Quay镜像签名与验证:保障软件供应链安全的完整指南
Project Quay镜像签名与验证:保障软件供应链安全的完整指南 【免费下载链接】quay Build, Store, and Distribute your Applications and Containers 项目地址: https://gitcode.com/gh_mirrors/quay/quay 在当今云原生时代,容器镜像已成为软件交…...

Alpamayo-R1-10B参数调优教程:Temperature从0.4→1.2对轨迹激进程度的影响可视化对比
Alpamayo-R1-10B参数调优教程:Temperature从0.4→1.2对轨迹激进程度的影响可视化对比 1. 引言 如果你正在使用Alpamayo-R1-10B这个自动驾驶模型,可能会发现一个有趣的现象:同样的路口场景,同样的驾驶指令,模型给出的…...

幻境·流金惊艳生成:从织梦令到流金光影汇聚的全过程效果对比
幻境流金惊艳生成:从织梦令到流金光影汇聚的全过程效果对比 1. 开篇:当技术遇见艺术的美妙邂逅 想象一下,你脑海中浮现出一个绝美的画面:赛博朋克都市中霓虹流淌的街道,或是水墨意境中的玄金山水。传统方式需要数小时…...

从Claude Code代码泄漏到AI Agent逻辑设计VS龙虾OpenClaw
近期 Anthropic的Claude Code 的源码泄露事件,为业界提供了一份价值连城的“活体解剖指南”。本文将深入对比高内聚的 Claude Code 架构与高解耦的 OpenClaw 通用框架,从系统执行逻辑、上下文管理、OS 沙盒交互以及记忆提纯等维度,探讨次世代 AI Agent 在模型推理与工程落地…...

数据集成与 ETL 实践:从设计到优化
数据集成与 ETL 实践:从设计到优化 前言 作为一个在数据深渊里捞了十几年 Bug 的女码农,我深知数据集成和 ETL(Extract, Transform, Load)在企业数据管理中的重要性。随着数据量的爆炸式增长和数据来源的多样化,数据集…...

OpenClaw 入门:新一代 AI 智能助手平台全景解析
OpenClaw 入门:新一代 AI 智能助手平台全景解析 本文是「OpenClaw 研究」专题的第一篇,带你全面了解这个新兴的 AI 智能助手平台。 一、什么是 OpenClaw? OpenClaw 是一个开源的 AI 智能助手平台,旨在帮助开发者和企业快速构建、…...
)
从Logistic曲线到疫情预测:用Python和SciPy复现SI传染病模型(附代码)
从Logistic曲线到疫情预测:用Python和SciPy复现SI传染病模型(附代码) 最近在整理疫情数据时,我发现一个有趣的现象:很多地区的感染人数增长曲线都呈现出典型的S型特征。这让我想起了经典的SI传染病模型,它用…...