python爬虫入门(四)爬取猫眼电影排行(使用requests库和正则表达式)
本例中,利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。
1.目标
提取出猫眼电影 TOP100 的电影名称、时间、评分、图片等信息,提取的站点 URL 为 http://maoyan.com/board/4,提取的结果会以文件形式保存下来。
2.抓取分析
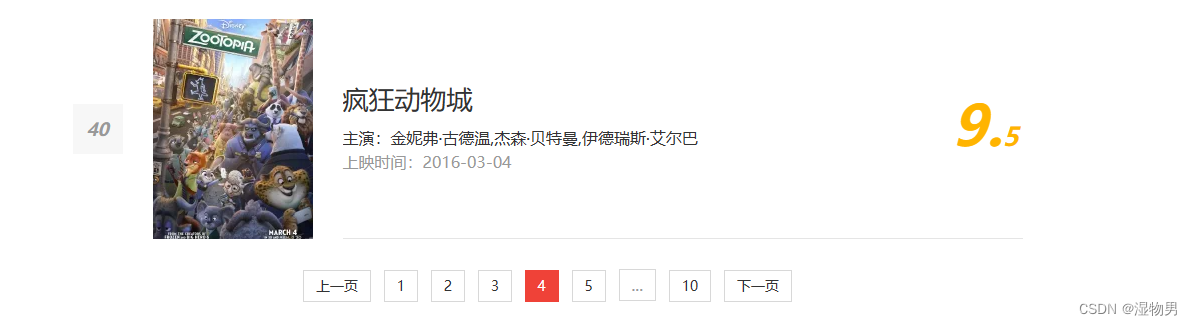
抓取页面如下:

页面中显示的有效信息有影片名称、主演、上映时间、上映地区、评分、图片等信息。
将网页滚动到最下方,可以发现有分页的列表。直接点击第 2 页,观察页面的 URL 和内容发生了怎样的变化。
第一页url:https://www.maoyan.com/board/4?offset=0
第二页url:https://www.maoyan.com/board/4?offset=10
可以发现offset从0变成了10,而每一页都显示了十部电影,由此可以总结出规律,offset 代表偏移量值。如果想获取 TOP100 电影,只需要分开请求 10 次,而 10 次的 offset 参数分别设置为 0、10、20…90 即可,这样获取不同的页面之后,再用正则表达式提取出相关信息,就可以得到 TOP100 的所有电影信息了。
3.抓取首页
首先抓取第一页的内容。实现 get_one_page 方法,并给它传入 url 参数。然后将抓取的页面结果返回。初步代码实现如下:
import requests
import redef get_one_page(url):headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}response=requests.get(url,headers=headers)if response.status_code==200:return response.textreturn Nonedef main():html=get_one_page('https://www.maoyan.com/board/4?offset=0')print(html)main()
4.正则提取
回到网页看一下页面的真实源码。在开发者模式下的 Network 监听组件中查看源代码。、
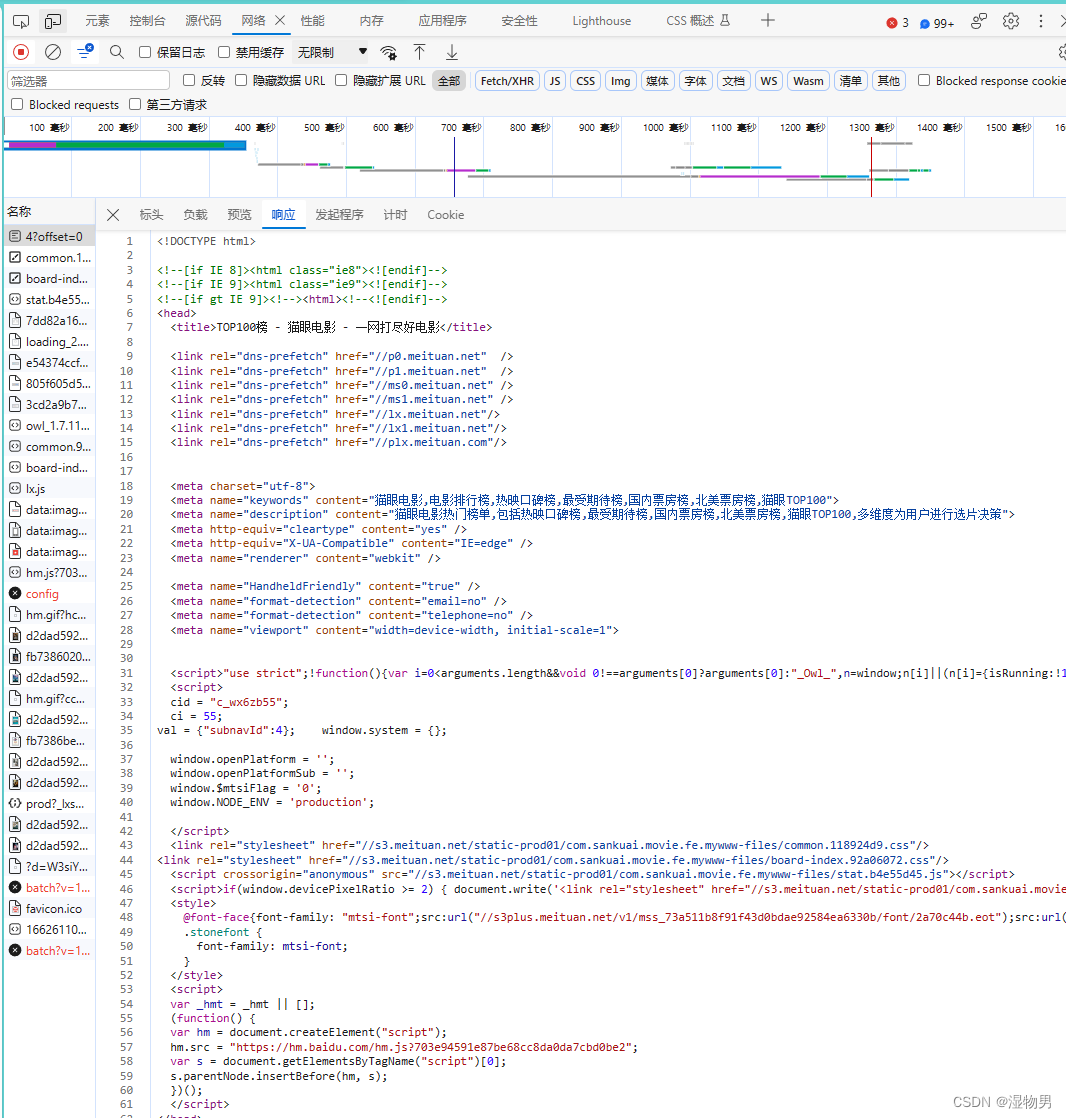
注意,这里不要在 Elements 选项卡中直接查看源码,因为那里的源码可能经过 JavaScript 操作而与原始请求不同,而是需要从 Network 选项卡部分查看原始请求得到的源码。
其中一个条目的源代码如下:
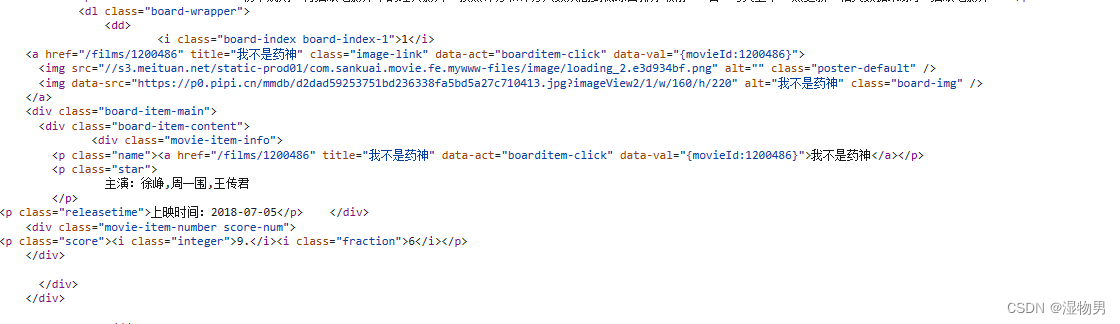
可以看到,一部电影信息对应的源代码是一个 dd 节点,我们用正则表达式来提取这里面的一些电影信息。首先,需要提取它的排名信息。而它的排名信息是在 class 为 board-index 的 i 节点内,这里利用非贪婪匹配来提取 i 节点内的信息,正则表达式写为:
result_ranking=re.findall('<dd>.*?board-index.*?>(.*?)</i>',html,re.S)
随后需要提取电影的图片。
result_img=re.findall('<img\sdata-src="(.*?)"',html,re.S)
再往后,需要提取电影的名称.
result_name=re.findall('class="name".*?data-val.*?>(.*?)</a>',html,re.S)
再提取主演、发布时间、评分等内容时,都是同样的原理。最后,正则表达式写为:
result_star=re.findall('class="star".*?>(.*?)</p>',html,re.S)
result_star = [star.strip() for star in result_star]
result_time=re.findall('class="releasetime".*?>(.*?)</p>',html,re.S)
result_score=re.findall('class="score".*?integer.*?>(.*?)</i>.*?fraction">(.*?)</i>',html,re.S)
由于这里的主演前后带有空格和换行符,使用strip去除。
到这里我们就可以将一部电影的6个数据提取出来,但这样还不够,数据比较杂乱,我们再将匹配结果处理一下,生成字典,如下:
index=0
result={'ranking':result_ranking[index],'img':result_img[index],'name':result_name[index],'star':result_star[index],'time':result_time[index],'score':result_score[index]}
5.写入文件
随后,我们将提取的结果写入文件,这里直接写入到一个文本文件中。这里通过 JSON 库的 dumps 方法实现字典的序列化,并指定 ensure_ascii 参数为 False,这样可以保证输出结果是中文形式而不是 Unicode 编码。代码如下:
import json
def write_to_file(content): with open('result.txt', 'a', encoding='utf-8') as f: print(type(json.dumps(content))) f.write(json.dumps(content, ensure_ascii=False)+'\n')
6.整合代码分页爬取
因为我们需要抓取的是 TOP100 的电影,所以还需要遍历一下,给这个链接传入 offset 参数,实现其他 90 部电影的爬取,此时添加如下调用即可:
import time
for i in range(10):url='https://www.maoyan.com/board/4?offset='+str(i*10)time.sleep(0.5)html=get_one_page(url)result_ranking=re.findall('<dd>.*?board-index.*?>(.*?)</i>',html,re.S)result_img=re.findall('<img\sdata-src="(.*?)"',html,re.S)result_name=re.findall('class="name".*?data-val.*?>(.*?)</a>',html,re.S)result_star=re.findall('class="star".*?>(.*?)</p>',html,re.S)result_star = [star.strip() for star in result_star]result_time=re.findall('class="releasetime".*?>(.*?)</p>',html,re.S)result_score=re.findall('class="score".*?integer.*?>(.*?)</i>.*?fraction">(.*?)</i>',html,re.S)for index in range(10):result={'ranking':result_ranking[index],'img':result_img[index],'title':result_name[index],'star':result_star[index],'reaease_time':result_time[index],'score':result_score[index]}write_to_file(result)
注意每次请求页面后加入暂停时间,否则会被反爬机制阻止,需要更换新的user-agent和cookie。
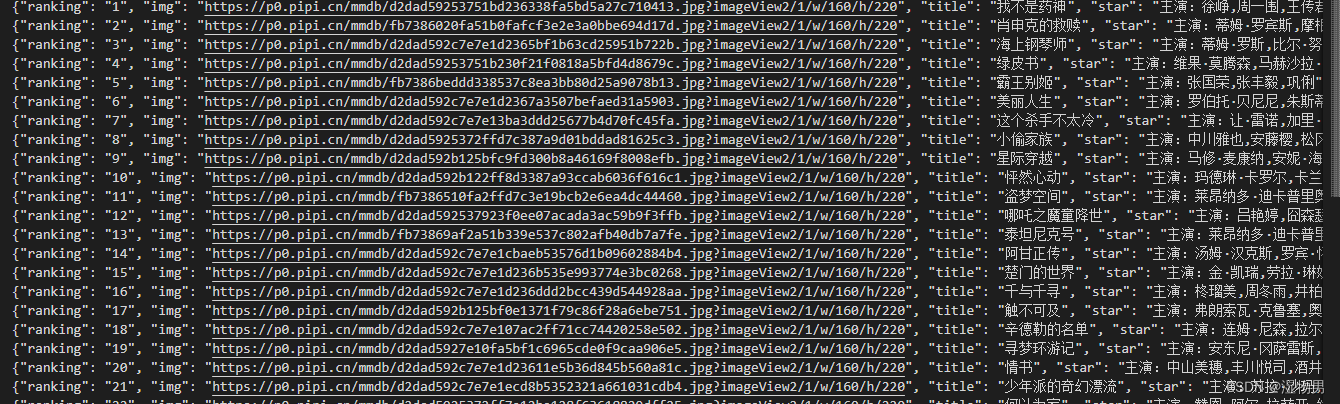
爬取结果如下:
番外:使用正则表达式对象改写
在上面的正则提取中我们为每一条要提取的信息都编写了一个正则表达式进行提取,可以利用compile方法编写正则表达式对象一次将六条信息全部提取出来,下面进行简化,我们将要提取的信息用一条正则表达式描述,使用group逐个提取出来。
可以看到,一部电影信息对应的源代码是一个 dd 节点,我们用正则表达式来提取这里面的一些电影信息。首先,需要提取它的排名信息。而它的排名信息是在 class 为 board-index 的 i 节点内,这里利用非贪婪匹配来提取 i 节点内的信息,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>
随后需要提取电影的图片。可以看到,后面有 a 节点,其内部有两个 img 节点。经过检查后发现,第二个 img 节点的 data-src 属性是图片的链接。这里提取第二个 img 节点的 data-src 属性,在原有正则表达式基础可以改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"
再往后,需要提取电影的名称,它在后面的 p 节点内,class 为 name。所以,可以用 name 做一个标志位,然后进一步提取到其内 a 节点的正文内容,此时正则表达式改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
再提取主演、发布时间、评分等内容时,都是同样的原理。最后,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>
接下来,通过调用 findall 方法提取出所有的内容。
pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',re.S)items = re.findall(pattern, html)
输出结果如下:
[('1', 'http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c', ' 霸王别姬 ', '\n 主演:张国荣,张丰毅,巩俐 \n ', ' 上映时间:1993-01-01(中国香港)', '9.', '6'), ('2', 'http://p0.meituan.net/movie/__40191813__4767047.jpg@160w_220h_1e_1c', ' 肖申克的救赎 ', '\n 主演:蒂姆・罗宾斯,摩根・弗里曼,鲍勃・冈顿 \n ', ' 上映时间:1994-10-14(美国)', '9.', '5'), ('3', 'http://p0.meituan.net/movie/fc9d78dd2ce84d20e53b6d1ae2eea4fb1515304.jpg@160w_220h_1e_1c', ' 这个杀手不太冷 ', '\n 主演:让・雷诺,加里・奥德曼,娜塔莉・波特曼 \n ', ' 上映时间:1994-09-14(法国)', '9.', '5'), ('4', 'http://p0.meituan.net/movie/23/6009725.jpg@160w_220h_1e_1c', ' 罗马假日 ', '\n 主演:格利高利・派克,奥黛丽・赫本,埃迪・艾伯特 \n ', ' 上映时间:1953-09-02(美国)', '9.', '1'), ('5', 'http://p0.meituan.net/movie/53/1541925.jpg@160w_220h_1e_1c', ' 阿甘正传 ', '\n 主演:汤姆・汉克斯,罗宾・怀特,加里・西尼斯 \n ', ' 上映时间:1994-07-06(美国)', '9.', '4'), ('6', 'http://p0.meituan.net/movie/11/324629.jpg@160w_220h_1e_1c', ' 泰坦尼克号 ', '\n 主演:莱昂纳多・迪卡普里奥,凯特・温丝莱特,比利・赞恩 \n ', ' 上映时间:1998-04-03', '9.', '5'), ('7', 'http://p0.meituan.net/movie/99/678407.jpg@160w_220h_1e_1c', ' 龙猫 ', '\n 主演:日高法子,坂本千夏,糸井重里 \n ', ' 上映时间:1988-04-16(日本)', '9.', '2'), ('8', 'http://p0.meituan.net/movie/92/8212889.jpg@160w_220h_1e_1c', ' 教父 ', '\n 主演:马龙・白兰度,阿尔・帕西诺,詹姆斯・凯恩 \n ', ' 上映时间:1972-03-24(美国)', '9.', '3'), ('9', 'http://p0.meituan.net/movie/62/109878.jpg@160w_220h_1e_1c', ' 唐伯虎点秋香 ', '\n 主演:周星驰,巩俐,郑佩佩 \n ', ' 上映时间:1993-07-01(中国香港)', '9.', '2'), ('10', 'http://p0.meituan.net/movie/9bf7d7b81001a9cf8adbac5a7cf7d766132425.jpg@160w_220h_1e_1c', ' 千与千寻 ', '\n 主演:柊瑠美,入野自由,夏木真理 \n ', ' 上映时间:2001-07-20(日本)', '9.', '3')]
相关文章:
python爬虫入门(四)爬取猫眼电影排行(使用requests库和正则表达式)
本例中,利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。 1.目标 提取出猫眼电影 TOP100 的电影名称、时间、评分、图片等信息,提取的站点 URL 为 http://maoyan.com/board/4,提取的结果会以文件形式保存下来。 2.抓取分析…...

Mybatis-Plus CRUD
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! Mybatis-Plus CRUD 通用 Service CRUD 封装 IService 接口,进一步封装 CRUD 采用 get 查询、remove 删除 、list 查询集合、page 分页的前缀命名方式区分 …...
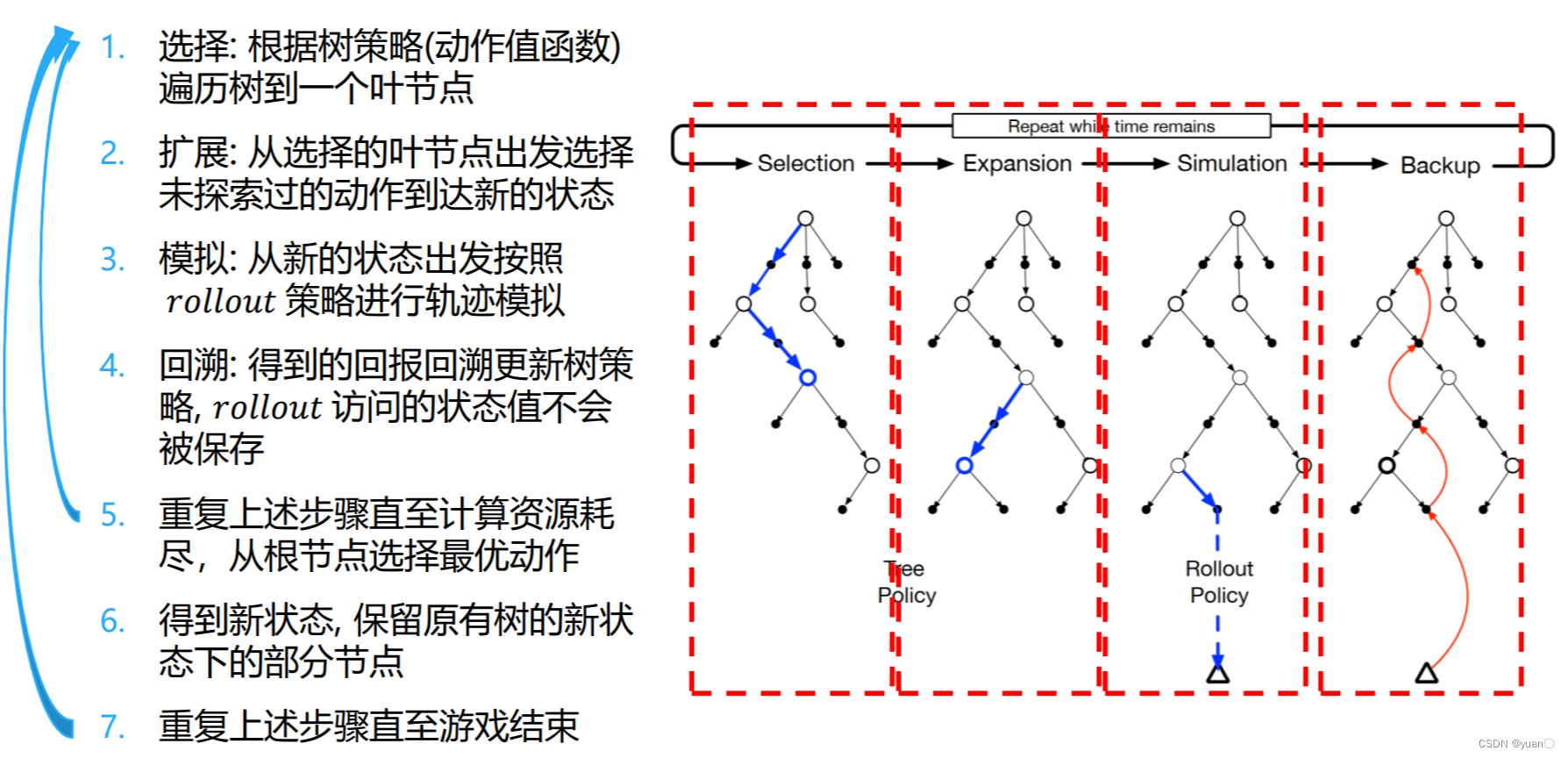
【强化学习】08——规划与学习(采样方法|决策时规划)
文章目录 优先级采样Example1 Prioritized Sweepingon Mazes局限性及改进 期望更新和采样更新不同分支因子下的表现 轨迹采样总结实时动态规划Example2 racetrack 决策时规划启发式搜索Rollout算法蒙特卡洛树搜索 参考 先做个简单的笔记整理,以后有时间再补上细节 …...
(链表) 25. K 个一组翻转链表 ——【Leetcode每日一题】
❓ 25. K 个一组翻转链表 难度:困难 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保…...
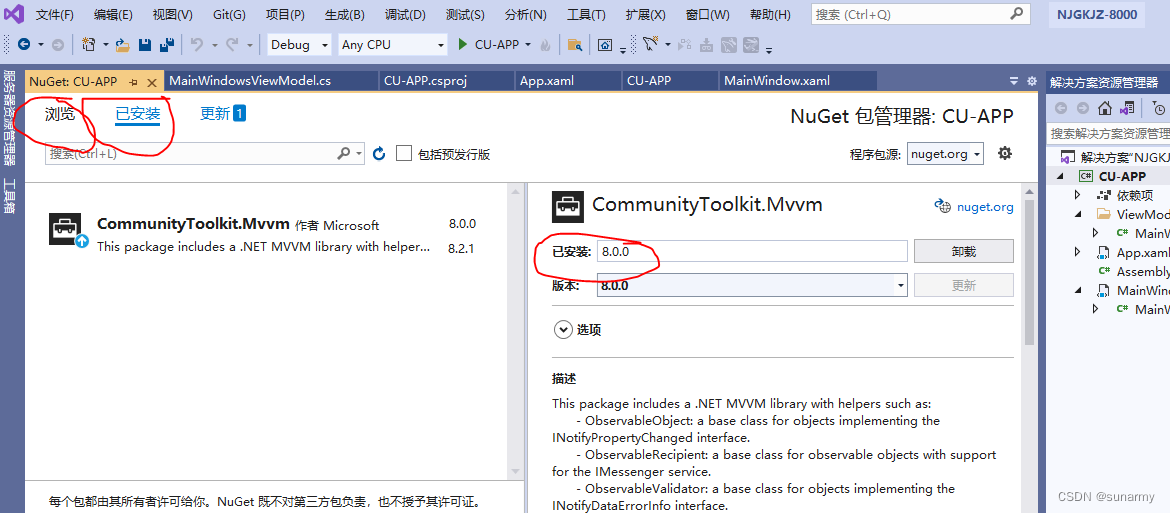
VisualStudio[WPF/.NET]基于CommunityToolkit.Mvvm架构开发
一、创建 "WPF应用程序" 新项目 项目模板选择如下: 暂时随机填一个目标框架,待会改: 二、修改“目标框架” 双击“解决方案资源管理器”中<项目>CU-APP, 打开<项目工程文件>CU-APP.csproj, 修改目标框架TargetFramew…...
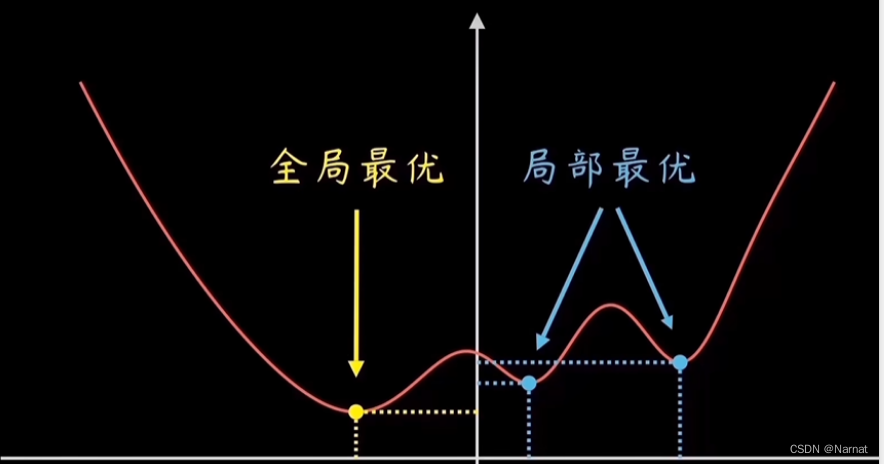
深度学习_5_模型拟合_梯度下降原理
需求: 想要找到一条直线,能更好的拟合这一些点 如何确定上述直线就是最优解呢? 由计算机算出所有点与我们拟合直线的误差,常见的是均方误差 例如:P1与直线之间的误差为e1 将P1坐标带入直线并求误差得: 推广到所有点&a…...

大模型时代,AI如何成为数实融合的驱动力?
10月25日,百度APP、百家号联合中兴通讯举办的“时代的增量“主题沙龙第二期在北京顺利召开。本期沙龙围绕“数实融合新视角”邀请学界、业界、媒体从业者等领域专家出席,以产学研相结合的视角深入探讨数实融合的最新技术趋势,并围绕数实融合在…...

MS COCO数据集的评价标准以及不同指标的选择推荐(AP、mAP、MS COCO、AR、@、0.5、0.75、1、目标检测、评价指标)
目标检测模型性能衡量指标、MS COCO 数据集的评价标准以及不同指标的选择推荐 0. 引言 0.1 COCO 数据集评价指标 目标检测模型通过 pycocotools 在验证集上会得到 COCO 的评价列表,具体参数的含义是什么呢? 0.2 目标检测领域常用的公开数据集 PASCAL …...

css实现鼠标多样化
cursor pointer: 手型default: 箭头text: 文本输入光标move: …...
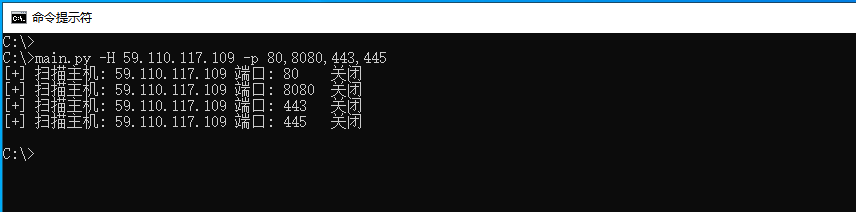
21.2 Python 使用Scapy实现端口探测
Scapy 是一款使用纯Python编写的跨平台网络数据包操控工具,它能够处理和嗅探各种网络数据包。能够很容易的创建,发送,捕获,分析和操作网络数据包,包括TCP,UDP,ICMP等协议,此外它还提…...
Qt设计一个自定义的登录框窗口
今天写了一个Qt登录、注册的小demo,后续完善会连接MySQL使用,过几天写完我会放在github上。 主要页面: 动态演示: 写完这个界面后,我终于知道了Qt为什么几乎没什么好看的窗口设计了,随便写一个简单大方的登…...
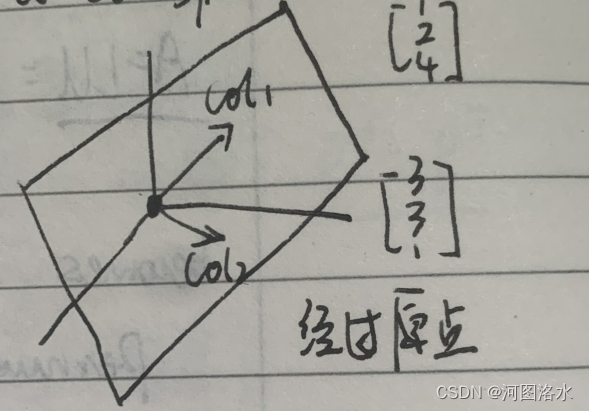
05 MIT线性代数-转置,置换,向量空间Transposes, permutations, spaces
1. Permutations P: execute row exchanges becomes PA LU for any invertible A Permutations P identity matrix with reordered rows mn (n-1) ... (3) (2) (1) counts recordings, counts all nxn permuations 对于nxn矩阵存在着n!个置换矩阵 , 2. Transpose: 2.…...
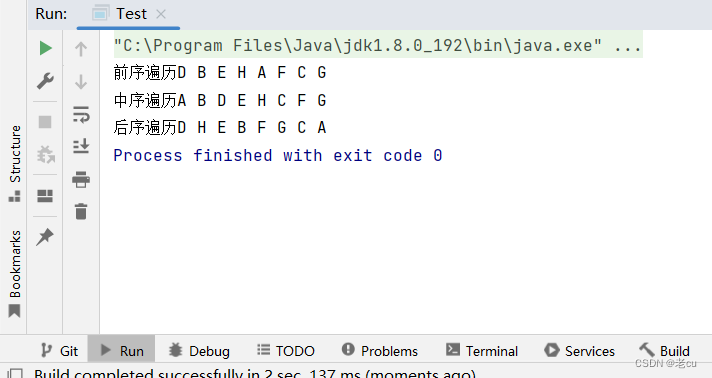
[数据结构】二叉树
1.概念 一棵二叉树是结点的一个有限集合,该集合: 1. 或者为空 2. 或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成 从上图我们可以发现: 1.二叉树不存在大于2 的度 2.二叉树的子树有左右之分,次序不能颠倒。是有…...
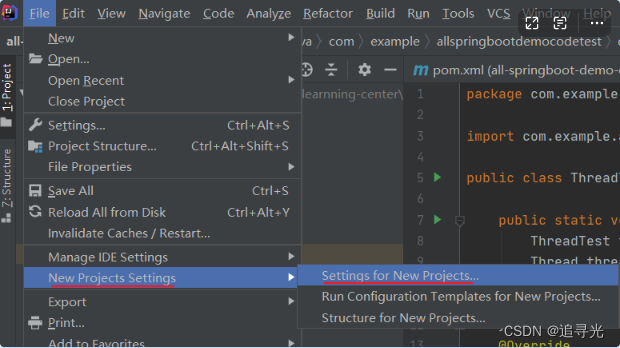
idea 中配置 maven
前文叙述: 配置 maven 一共要设置两个地方:1、为当前项目设置2、为新项目设置maven 的下载和安装可参考我之前写过的文章,具体的配置文章中也都有讲解。1、为当前项目进行 maven 配置 配置 VM Options: -DarchetypeCataloginternal2、为新项…...
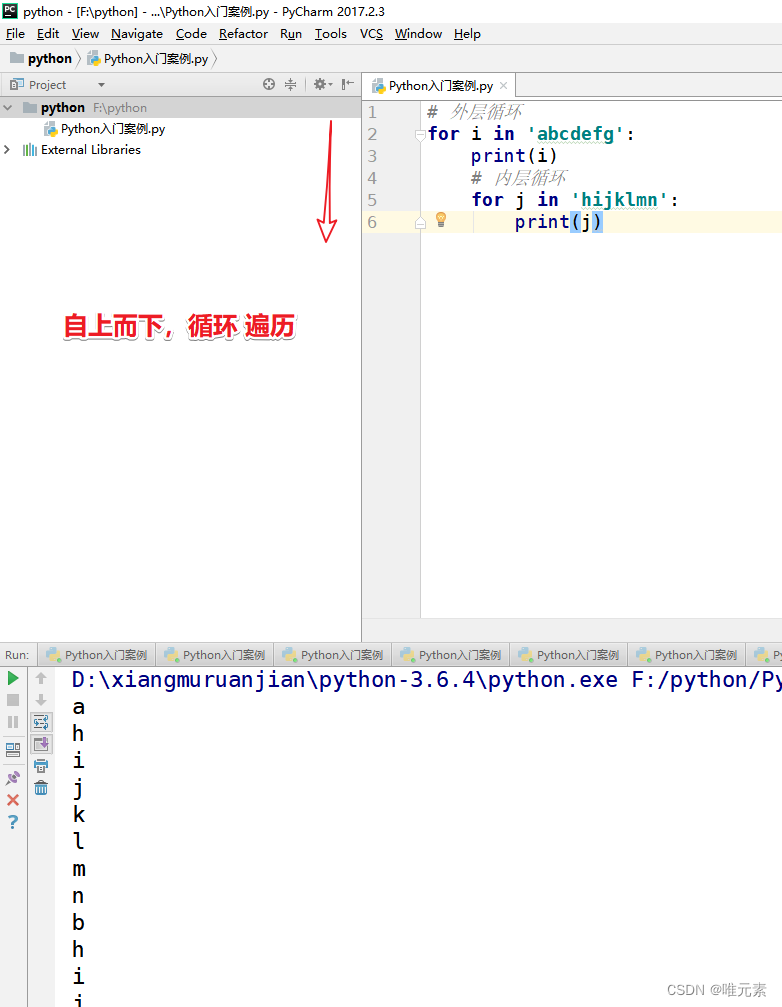
Python---for循环嵌套
for循环嵌套,就是一个for循环里面嵌套另外一个for循环的写法。 当循环结构相互嵌套时,位于外层的循环结构常简称为外层循环或外循环,位于内层的循环结构常简称为内层循环或内循环。 基本语法: # 外层循环 for i in 序列1:# 内层…...

189. 轮转数组 --力扣 --JAVA
题目 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 解题思路 通过位移后位置对数组长度的取余来判断元素变换后的位置 代码展示 class Solution {public void rotate(int[] nums, int k) {int size nums.length;int[]…...
C# 使用waveIn实现声音采集
文章目录 前言一、需要的对象及方法二、整体流程三、关键实现1、使用Thread开启线程2、TaskCompletionSource实现异步3、将指针封装为Stream 四、完整代码1.接口2.具体实现 五、使用示例方式一方式二 总结 前言 之前实现了《C 使用waveIn实现声音采集》,后来C#项目…...
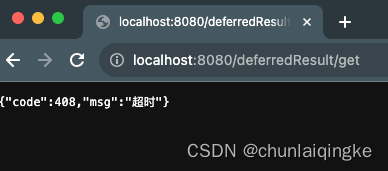
长连接的原理
Apollo的长连接实现是 Spring的DeferredResult来实现的,先看怎么用 import ...RestController RequestMapping("deferredResult") public class DeferredResultController {private Map<String, Consumer<DeferredResultResponse>> taskMap new HashMa…...

软考系列(系统架构师)- 2015年系统架构师软考案例分析考点
试题一 软件架构(质量属性效用树、架构风险、依够点、权衡点) 【问题1】(12分) 在架构评估过程中,质量属性效用树(utility tree)是对系统质量属性进行识别和优先级排序的重要工具。请给出合适的…...

小程序开发——小程序的视图与渲染
1.视图与渲染过程 基本概念: 视图层由WXML页面文件和样式文件WXSS共同组成。事件是视图层和逻辑层沟通的纽带,用户操作触发事件后可通过同名的事件处理函数执行相应的逻辑,处理完成后,更新的数据又将再次渲染到页面上。 WXML页面…...

python IntEnum
# 聊聊Python里的IntEnum:给常量一个体面的身份 在Python里处理常量或者状态码的时候,很多人习惯直接用数字或者字符串。比如写个status 1表示成功,status 0表示失败。刚开始这么写挺方便的,但项目稍微大一点,问题就…...

让魔兽争霸3重获新生:从卡顿到丝滑的180帧魔法之旅
让魔兽争霸3重获新生:从卡顿到丝滑的180帧魔法之旅 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3的卡顿问题头疼吗&…...

Blender 5.0三维建模软件免费下载
分享文件:Blender 下载链接:https://pan.xunlei.com/s/VOnoa-uAZeIscnA0CetsTTVXA1?pwdq9az# 下载连接...

在VMware Workstation上实战部署华为eSight网络管理平台
1. 环境准备:从零搭建虚拟化实验平台 第一次接触华为eSight时,我完全被它的企业级功能震撼了——但随之而来的问题是:如何在个人电脑上搭建测试环境?经过多次实践,我发现VMware Workstation是最理想的实验平台。这里分…...

C++ 智能指针在 STL 容器中的应用
C智能指针在STL容器中的应用 在现代C开发中,智能指针和STL容器是两大核心工具。智能指针通过自动管理内存,显著降低了资源泄漏的风险;而STL容器则提供了高效的数据存储和操作方式。将两者结合使用,既能确保内存安全,又…...

Godot资源解包利器:零基础掌握游戏资产提取技术
Godot资源解包利器:零基础掌握游戏资产提取技术 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker godot-unpacker是一款专为Godot引擎设计的资源解包(Resource Extraction&…...

Buildroot与Qt5的X11VNC集成:解决EGLFS与XCB插件冲突的实践指南
1. 为什么需要X11VNC与Qt5集成? 在嵌入式开发中,远程调试图形界面是个常见需求。想象一下,你的设备可能放在工厂车间或者户外,每次修改代码后都要跑到设备前查看效果,这效率实在太低。X11VNC就像给你的设备装了个"…...
进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持)
项目介绍 MATLAB实现基于豹群算法(LVO)进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持
MATLAB实现基于豹群算法(LVO)进行无人机三维路径规划的详细项目实例 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 无人机(UAV&#…...

SwitchButton自定义样式完全教程:从基础到高级的完整指南
SwitchButton自定义样式完全教程:从基础到高级的完整指南 【免费下载链接】SwitchButton SwitchButton.An beautifullightweightcustom-style-easy switch widget for Android,minSdkVersion > 11 项目地址: https://gitcode.com/gh_mirrors/swi/SwitchButton …...

新手如何践行qoderwork?快马平台带你从零生成首个网页项目
作为一个刚接触编程的新手,想要快速上手做出一个能实际运行的网页项目,往往会遇到各种困难。最近我在学习网页开发时,发现了一个特别适合新手入门的方法——通过InsCode(快马)平台来实践qoderwork理念,今天就分享一下我的经验。 …...