大文件分片上传-续传-秒传(详解)
前言
前面记录过使用库实现的大文件的分片上传
基于WebUploader实现大文件分片上传
基于vue-simple-uploader 实现大文件分片上传
前面记录过基于库实现的大文件的分片上传,那如果不使用库,
文件分片是怎么实现的,该怎么做到呢?
一起看看吧
思路
1、文件分片、
2、每个文件标识、
3、并发上传、
4、合并组装
5、上传前查询是否存在
实现
读取文件
通过监听 input 的 change 事件,当选取了本地文件后,可以在回调函数中拿到对应的文件:
const handleUpload = (e: Event) => {const files = (e.target as HTMLInputElement).filesif (!files) {return}// 读取选择的文件console.log(files[0]);
}
文件分片
核心是用Blob 对象的 slice 方法,用法如下:
let blob = instanceOfBlob.slice([start [, end [, contentType]]]};
start 和 end 代表 Blob 里的下标,表示被拷贝进新的 Blob 的字节的起始位置和结束位置。
contentType 会给新的 Blob 赋予一个新的文档类型,在这里我们用不到。
使用slice方法来实现下对文件的分片,获取分片的文件列表
const createFileChunks = (file: File) => {const fileChunkList = []let cur = 0while (cur < file.size) {fileChunkList.push({file: file.slice(cur, cur + CHUNK_SIZE),})cur += CHUNK_SIZE // CHUNK_SIZE为分片的大小}return fileChunkList
}
hash 计算
怎么区分每一个文件呢?
1、根据文件名去区分,不可以,因为文件名我们可以是随便修改的;
2、我们见过用 webpack 打包出来的文件的文件名,会有一串不一样的字符串,这个字符串就是根据文件的内容生成的 hash 值,文件内容变化,hash 值就会跟着发生变化。
3、而且妙传实现也是基于此:
服务器在处理上传文件的请求的时候,要先判断下对应文件的 hash 值有没有记录,如果 A 和 B 先后上传一份内容相同的文件,
所以这两份文件的 hash 值是一样的。当 A 上传的时候会根据文件内容生成一个对应的 hash 值,然后在服务器上就会有一个对应的文件,B 再上传的时候,服务器就会发现这个文件的 hash 值之前已经有记录了,说明之前
已经上传过相同内容的文件了,所以就不用处理 B 的这个上传请求了,给用户的感觉就像是实现了秒传
spark-md5
我们得先安装spark-md5。我们就可以用文件的所有切片来算该文件的hash 值,
但是如果一个文件特别大,每个切片的所有内容都参与计算的话会很耗时间,所有我们可以采取以下策略:
1、第一个和最后一个切片的内容全部参与计算;
2、中间剩余的切片我们分别在前面、后面和中间取 2 个字节参与计算;
3、既能保证所有的切片参与了计算,也能保证不耗费很长的时间
安装使用
npm install spark-md5
npm install @types/spark-md5 -Dimport SparkMD5 from 'spark-md5'
/*** 计算文件的hash值,计算的时候并不是根据所用的切片的内容去计算的,那样会很耗时间,我们采取下面的策略去计算:* 1. 第一个和最后一个切片的内容全部参与计算* 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算* 这样做会节省计算hash的时间*/
const calculateHash = async (fileChunks: Array<{file: Blob}>) => {return new Promise(resolve => {const spark = new sparkMD5.ArrayBuffer()const chunks: Blob[] = []fileChunks.forEach((chunk, index) => {if (index === 0 || index === fileChunks.length - 1) {// 1. 第一个和最后一个切片的内容全部参与计算chunks.push(chunk.file)} else {// 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算// 前面的2字节chunks.push(chunk.file.slice(0, 2))// 中间的2字节chunks.push(chunk.file.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2))// 后面的2字节chunks.push(chunk.file.slice(CHUNK_SIZE - 2, CHUNK_SIZE))}})const reader = new FileReader()reader.readAsArrayBuffer(new Blob(chunks))reader.onload = (e: Event) => {spark.append(e?.target?.result as ArrayBuffer)resolve(spark.end())}})
}
文件上传前端实现
const uploadChunks = async (fileChunks: Array<{ file: Blob }>) => {const data = fileChunks.map(({ file }, index) => ({fileHash: fileHash.value,index,chunkHash: `${fileHash.value}-${index}`,chunk: file,size: file.size,}))const formDatas = data.map(({ chunk, chunkHash }) => {const formData = new FormData()// 切片文件formData.append('chunk', chunk)// 切片文件hashformData.append('chunkHash', chunkHash)// 大文件的文件名formData.append('fileName', fileName.value)// 大文件hashformData.append('fileHash', fileHash.value)return formData})let index = 0const max = 6 // 并发请求数量const taskPool: any = [] // 请求队列while (index < formDatas.length) {const task = fetch('http://127.0.0.1:3000/upload', {method: 'POST',body: formDatas[index],})task.then(() => {taskPool.splice(taskPool.findIndex((item: any) => item === task))})taskPool.push(task)if (taskPool.length === max) {// 当请求队列中的请求数达到最大并行请求数的时候,得等之前的请求完成再循环下一个await Promise.race(taskPool)}index++percentage.value = ((index / formDatas.length) * 100).toFixed(0)}await Promise.all(taskPool)
}
文件上传后端实现
后端 express 框架,用到的工具包:multiparty、fs-extra、cors、body-parser、nodemon后端我们处理文件时需要用到 multiparty 这个工具,所以也是得先安装,然后再引入它。
我们在处理每个上传的分片的时候,应该先将它们临时存放到服务器的一个地方,方便我们合并的时候再去读
取。为了区分不同文件的分片,我们就用文件对应的那个 hash 为文件夹的名称,将这个文件的所有分片放到这
个文件夹中。
// 所有上传的文件存放到该目录下
const UPLOAD_DIR = path.resolve(__dirname, 'uploads')// 处理上传的分片
app.post('/upload', async (req, res) => {const form = new multiparty.Form()form.parse(req, async function (err, fields, files) {if (err) {res.status(401).json({ok: false,msg: '上传失败',})}const chunkHash = fields['chunkHash'][0]const fileName = fields['fileName'][0]const fileHash = fields['fileHash'][0]// 存储切片的临时文件夹const chunkDir = path.resolve(UPLOAD_DIR, fileHash)// 切片目录不存在,则创建切片目录if (!fse.existsSync(chunkDir)) {await fse.mkdirs(chunkDir)}const oldPath = files.chunk[0].path// 把文件切片移动到我们的切片文件夹中await fse.move(oldPath, path.resolve(chunkDir, chunkHash))res.status(200).json({ok: true,msg: 'received file chunk',})})
})
写完前后端代码后就可以来试下看看文件能不能实现切片的上传,如果没有错误的话,我们的 uploads 文件
夹下应该就会多一个文件夹,这个文件夹里面就是存储的所有文件的分片了。
文件合并前端实现
核心:切片合并
前端只需要向服务器发送一个合并的请求,并且为了区分要合并的文件,需要将文件的 hash 值给传过去
/*** 发请求通知服务器,合并切片*/
const mergeRequest = () => {// 发送合并请求fetch('http://127.0.0.1:3000/merge', {method: 'POST',headers: {'Content-Type': 'application/json',},body: JSON.stringify({size: CHUNK_SIZE,fileHash: fileHash.value,fileName: fileName.value,}),}).then((response) => response.json()).then(() => {alert('上传成功')})
}
文件合并后端实现
之前已经将所有的切片上传到服务器并存储到对应的目录里面去了,
合并的时候需要从对应的文件夹中获取所有的切片,然后利用文件的读写操作,实现文件的合并了。
合并完成之后,我们将生成的文件以 hash 值命名存放到对应的位置就可以了
// 提取文件后缀名
const extractExt = (filename) => {return filename.slice(filename.lastIndexOf('.'), filename.length)
}/*** 读的内容写到writeStream中*/
const pipeStream = (path, writeStream) => {return new Promise((resolve, reject) => {// 创建可读流const readStream = fse.createReadStream(path)readStream.on('end', async () => {fse.unlinkSync(path)resolve()})readStream.pipe(writeStream)})
}/*** 合并文件夹中的切片,生成一个完整的文件*/
async function mergeFileChunk(filePath, fileHash, size) {const chunkDir = path.resolve(UPLOAD_DIR, fileHash)const chunkPaths = await fse.readdir(chunkDir)// 根据切片下标进行排序// 否则直接读取目录的获得的顺序可能会错乱chunkPaths.sort((a, b) => {return a.split('-')[1] - b.split('-')[1]})const list = chunkPaths.map((chunkPath, index) => {return pipeStream(path.resolve(chunkDir, chunkPath),fse.createWriteStream(filePath, {start: index * size,end: (index + 1) * size,}),)})await Promise.all(list)// 文件合并后删除保存切片的目录fse.rmdirSync(chunkDir)
}// 合并文件
app.post('/merge', async (req, res) => {const { fileHash, fileName, size } = req.bodyconst filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)// 如果大文件已经存在,则直接返回if (fse.existsSync(filePath)) {res.status(200).json({ok: true,msg: '合并成功',})return}const chunkDir = path.resolve(UPLOAD_DIR, fileHash)// 切片目录不存在,则无法合并切片,报异常if (!fse.existsSync(chunkDir)) {res.status(200).json({ok: false,msg: '合并失败,请重新上传',})return}await mergeFileChunk(filePath, fileHash, size)res.status(200).json({ok: true,msg: '合并成功',})
})
文件秒传&断点续传
服务器上给上传的文件命名的时候就是用对应的 hash 值命名的,
所以在上传之前判断有对应的这个文件,就不用再重复上传了,
直接告诉用户上传成功,给用户的感觉就像是实现了秒传。
文件秒传-前端
前端在上传之前,需要将对应文件的 hash 值告诉服务器,看看服务器上有没有对应的这个文件,
如果有,就直接返回,不执行上传分片的操作了
/*** 验证该文件是否需要上传,文件通过hash生成唯一,改名后也是不需要再上传的,也就相当于秒传*/
const verifyUpload = async () => {return fetch('http://127.0.0.1:3000/verify', {method: 'POST',headers: {'Content-Type': 'application/json',},body: JSON.stringify({fileName: fileName.value,fileHash: fileHash.value,}),}).then((response) => response.json()).then((data) => {return data // data中包含对应的表示服务器上有没有该文件的查询结果})
}// 点击上传事件
const handleUpload = async (e: Event) => {// ...// uploadedList已上传的切片的切片文件名称const res = await verifyUpload()const { shouldUpload } = res.dataif (!shouldUpload) {// 服务器上已经有该文件,不需要上传alert('秒传:上传成功')return}// 服务器上不存在该文件,继续上传uploadChunks(fileChunks)
}
文件秒传-后端
// 根据文件hash验证文件有没有上传过
app.post('/verify', async (req, res) => {const { fileHash, fileName } = req.bodyconst filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)if (fse.existsSync(filePath)) {// 文件存在服务器中,不需要再上传了res.status(200).json({ok: true,data: {shouldUpload: false,},})} else {// 文件不在服务器中,就需要上传res.status(200).json({ok: true,data: {shouldUpload: true,},})}
})
文件断点续传-前端
如果我们之前已经上传了一部分分片了,我们只需要再上传之前拿到这部分分片,
然后再过滤掉是不是就可以避免去重复上传这些分片了,也就是只需要上传那些上传失败的分片,
所以,再上传之前还得加一个判断。
我们还是在那个 verify 的接口中去获取已经上传成功的分片,然后在上传分片前进行一个过滤
const uploadChunks = async (fileChunks: Array<{ file: Blob }>, uploadedList: Array<string>) => {const formDatas = fileChunks.filter((chunk, index) => {// 过滤服务器上已经有的切片return !uploadedList.includes(`${fileHash.value}-${index}`)}).map(({ file }, index) => {const formData = new FormData()// 切片文件formData.append('file', file)// 切片文件hashformData.append('chunkHash', `${fileHash.value}-${index}`)// 大文件的文件名formData.append('fileName', fileName.value)// 大文件hashformData.append('fileHash', fileHash.value)return formData})// ...
}
文件断点续传-后端
只需在 /verify 这个接口中加上已经上传成功的所有切片的名称就可以,
因为所有的切片都存放在以文件的 hash 值命名的那个文件夹,
所以需要读取这个文件夹中所有的切片的名称就可以。
/*** 返回已经上传切片名* @param {*} fileHash* @returns*/
const createUploadedList = async (fileHash) => {return fse.existsSync(path.resolve(UPLOAD_DIR, fileHash))? await fse.readdir(path.resolve(UPLOAD_DIR, fileHash)) // 读取该文件夹下所有的文件的名称: []
}// 根据文件hash验证文件有没有上传过
app.post('/verify', async (req, res) => {const { fileHash, fileName } = req.bodyconst filePath = path.resolve(UPLOAD_DIR, `${fileHash}${extractExt(fileName)}`)if (fse.existsSync(filePath)) {// 文件存在服务器中,不需要再上传了res.status(200).json({ok: true,data: {shouldUpload: false,},})} else {// 文件不在服务器中,就需要上传,并且返回服务器上已经存在的切片res.status(200).json({ok: true,data: {shouldUpload: true,uploadedList: await createUploadedList(fileHash),},})}
})
相关文章:
)
大文件分片上传-续传-秒传(详解)
前言 前面记录过使用库实现的大文件的分片上传 基于WebUploader实现大文件分片上传 基于vue-simple-uploader 实现大文件分片上传 前面记录过基于库实现的大文件的分片上传,那如果不使用库, 文件分片是怎么实现的,该怎么做到呢?…...

CE-LVD证书跟CE-EMC证书有什么区别?
CE-LVD证书跟CE-EMC证书有什么区别? CE-LVD证书跟CE-EMC证书有什么区别? 近日,TEMU平台电器需提交CE-LVD证书,不再接受EMC证书---玩具产品需提交满足玩具法规的CE证书,法规总是多变的,卖家也是很苦恼&…...

使用Mapster实现双向映射,解放搬砖体力活
经常会有对象属性互相赋值的操作,但是频繁的写实在是搬运工一样,比较难受比如下面两个类 public class AgencyBdm {public new int Id { set; get; }public string AgencyId { set; get; }public string AgencyName { set; get; }public string Region {…...
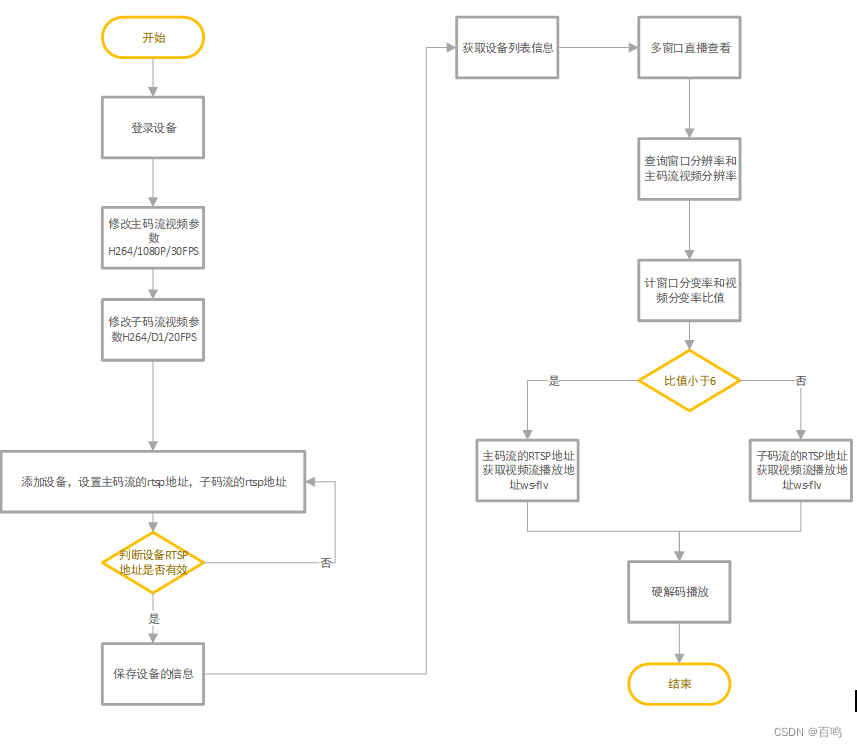
一种基于屏幕分辨率的RTSP主子码流切换的多路视频监控的播放方案
技术背景: 用户场景下,存在多个监控场所的100路监控摄像头,例如:大华、海康、宇视、杭州宇泛的枪机、球机、半球、NVR、DVR等不同类型的监控设备,通过视频监控平台进行设备的管理,通过RTSP拉流的方案管理监…...
SpringBoot日志+SpringMVC+UUID重命名文件+Idea热部署
目录 【SpringBoot日志】 什么是日志,日志的作用 关于日志的基本信息,又有哪些呢? 关于日志的级别 Springboot内置SLF4J【门面模式】 和 logback【日志框架】 在配置文件中可以设置日志级别【以.yml为例】 SpringBoot 持久化的保存日…...

向日葵远程控制中的键盘异常问题
本文记录的是ubuntu 20.04 上, 向日葵的最高版本目前只有V 11.0.1.44968(2022.02) 我的被控制和 控制端都是上述环境; 起因,由于我昨天在控制端按下了 win/ 或者是其他的组合键 (具体哪个键盘确实没有注…...
【iOS免越狱】利用IOS自动化web-driver-agent_appium-实现自动点击+滑动屏幕
1.目标 在做饭、锻炼等无法腾出双手的场景中,想刷刷抖音 刷抖音的时候有太多的广告 如何解决痛点 抖音自动播放下一个视频 iOS系统高版本无法 越狱 安装插件 2.操作环境 MAC一台,安装 Xcode iPhone一台,16 系统以上最佳 3.流程 下载最…...
聊聊“JVM 调优JVM 性能优化”是怎么个事?
所谓“调优”就是一个诊断和处理手段,最终的目标是让系统的处理能力,也就是“性能”达到最优化。 计算机系统中,性能相关的资源主要分为这几类: CPU:CPU 是系统最关键的计算资源,在单位时间内有限…...

再获Gartner认可!持安科技获评ZTNA领域代表供应商
近日,全球权威市场研究与咨询机构Gartner发布了《Hype Cycle for Security in China, 2023(2023中国安全技术成熟度曲线)》报告,对2023年的20个中国安全技术领域的现状与发展趋势进行了详细的分析与解读。 其中,持安科…...

微服务-Feign
文章目录 Feign介绍Feign的基本使用自定义Feign的配置Feign性能优化Feign最佳实践 Feign介绍 RestTemplate远程调用存在的问题:代码可读性差,java代码中夹杂url;参数复杂很难维护 String url "http://userservice/user/" order.g…...

jsp获取数据 jsp直接获取后端数据 获取input选中的值 单选 没 checked属性
let str0${showList}; let str1${showList}; 然后可以通过JSON.parse() 转 获取input选中的值 //goodsType 按类别 goods按货品var oneType $("input[ namecriteria1 ] ").val();//count按数量 totalprice按费用var twoType $("input[ namecriteria2 ] &q…...

React 中 keys 的作用是什么?
目录 前言:React 中的 Keys 的重要性 为什么 Keys 重要? 详解:key 属性的基本概念 用法:key 属性的示例 解析:key 属性的优势和局限性 优势: 局限性: key 属性的最佳实践 稳定的唯一标…...

代码随想录 | Day46
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 今日学习目标一、算法题1.完全背包问题2.零钱兑换 II3.组合总和 Ⅳ 学习及参考书籍 今日学习目标 完全背包问题 零钱兑换 II(518) 组合总和…...

word行内插入mathtype 公式后行距变大解决办法
现象 word行内插入mathtype 公式后行距变大 解决方法 选中要进行操作的那些行,依次单击菜单命令“格式→段落”,打开“段落”对话框;单击“缩进和间距”选项卡,将间距的“段前”和“段后”都调整为“0行”;将“如果…...

直播预告 | YashanDB 2023年度发布会正式定档11月2日,邀您共同见证国产数据库发展实践!
11月2日,YashanDB 2023年度发布会将于云端直播开启,发布会以 「惟实励新」 为主题,邀请企业用户、合作伙伴、广大开发者共同见证全新产品与解决方案。届时发布会将在墨天轮社区同步进行,欢迎大家报名! 惟实求真。Yasha…...

一文读懂WebClient和RestTemplate的差异
自 Spring 5 以来,WebClient已成为Spring WebFlux的一部分,并且是发出 HTTP 请求的首选方式。它是经典RestTemplate的首选替代方案,后者自 Spring 5.0 以来一直处于维护模式。 本文将讨论 Spring WebClient和RestTemplate类之间的主要区别。…...

如何使用SpringBoot处理全局异常
如何使用SpringBoot处理全局异常 使用ControllerAdvice 和 ExceptionHandler处理全局异常 参考: ControllerAdvice ResponseBody Slf4j public class ExceptionHandler {ResponseStatus(HttpStatus.OK)org.springframework.web.bind.annotation.ExceptionHandler…...
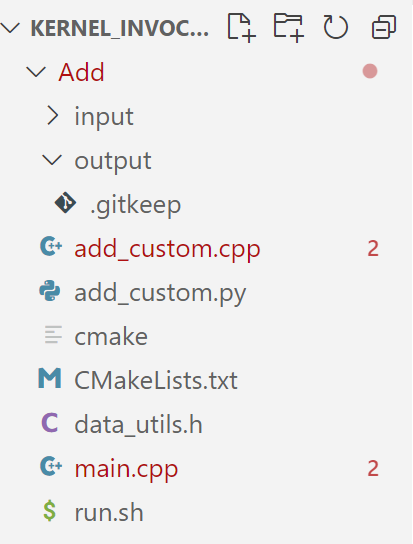
【2023CANN训练营第二季】——通过一份入门级算子开发代码了解Ascend C算子开发流程
本次博客讲解的代码是Gitee代码仓的Ascend C加法算子开发代码,代码地址为: quick-start 打开Add文件,可以看到文件结构如下: 其中add_custom.cpp是算子开发的核心文件,包括了核函数的实现,展示了如何在Asc…...
建模仿真软件 Comsol Multiphysics mac中文版软件介绍
COMSOL Multiphysics mac是一款全球通用的基于高级数值方法和模拟物理场问题的通用软件,拥有、网格划分、研究和优化、求解器、可视化和后处理、仿真 App等相关功能,轻松实现各个环节的流畅进行,它能够解释耦合或多物理现象。 附加产品扩展了…...

深入理解强化学习——强化学习的历史:近代强化学习的发展
分类目录:《深入理解强化学习》总目录 在《深入理解强化学习——强化学习的历史》前面的文章中我们讨论了最优控制和试错学习学习的思想,接下来,我们将讨论一些在20世纪60年代和70年代,在试错学习计算和理论研究被相对忽视的时候&…...

SAP KO88结算时,如何用BADI_FINS_ACDOC_POSTING_EVENTS把成本中心塞进自定义字段?
SAP KO88结算实战:通过BADI_FINS_ACDOC_POSTING_EVENTS实现成本中心到自定义字段的精准映射 在SAP工单结算(KO88)的复杂业务场景中,财务凭证的标准化字段往往无法满足企业多维度的分析需求。特别是当需要将特定成本中心信息映射到…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

AI模型部署实战:基于FastAPI与Tauri构建OpenClaw模型GUI应用
1. 项目概述与核心价值最近在AI应用开发圈里,一个名为“GrahamMiranda-AI/openclaw-model-gui”的项目引起了我的注意。乍一看这个标题,它融合了“openclaw-model”和“gui”两个关键部分,这让我立刻联想到一个典型的场景:一个已经…...

从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程
从GitHub克隆到点亮LED:手把手教你用Ubuntu编译调试别人的STM32工程 在开源硬件社区,GitHub上每天都有大量优秀的STM32项目被分享——从智能家居控制器到四轴飞行器飞控系统。但当开发者满怀期待地git clone后,却常常在第一步"编译通过&…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

Arduino与手机蓝牙通信:nRF8001 BLE模块硬件连接与软件配置全解析
1. 项目概述与核心价值如果你手头有一个Arduino项目,想让它和你的手机“说说话”,比如把传感器数据无线传到手机App上显示,或者用手机App远程控制几个LED灯,那么nRF8001这个蓝牙低功耗(BLE)模块绝对是你绕不…...

CC2530与ESP8266物联网网关:ZigBee转Wi-Fi通信协议转换实战
1. 项目概述:当ZigBee遇上Wi-Fi最近在折腾一个智能家居的传感器节点,核心是TI的CC2530 ZigBee芯片。这玩意儿功耗低、组网方便,是很多低功耗传感网络的绝佳选择。但问题来了,ZigBee网络的数据最终怎么方便地送到我们手机上去看呢&…...

FPGA与GPU在OSOS-ELM算法中的性能对比与优化
1. 项目概述在边缘计算和实时信号处理领域,极端学习机(ELM)因其独特的训练机制和高效的计算性能而备受关注。OSOS-ELM作为ELM的一种变体,通过在线顺序学习机制进一步提升了算法的实用性。这项研究聚焦于FPGA和GPU两种硬件平台在执行OSOS-ELM算法时的性能…...

2026运营经理学习数据分析对职场能力提升的影响
一、数据分析在运营管理中的核心价值数据分析能力帮助运营经理优化决策流程,通过数据驱动的方法提升业务效率。掌握用户行为分析、市场趋势预测等技能,能够更精准地制定运营策略。数据可视化工具(如Tableau、Power BI)的应用&…...