爬虫批量下载科研论文(SciHub)
系列文章目录
利用 eutils 实现自动下载序列文件
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 一、获取文献信息
- 二、下载文献PDF文件
- 参考
前言
大家好✨,这里是bio🦖。这次为大家带来自动收集文献信息、批量下载科研论文的脚本(只能批量下载公布在sci-hub上的科研论文)。平常阅读文献时只需要一篇一篇下载即可,并不需要用到批量下载的操作。但有时需要对某领域进行总结或者归纳,就可以考虑使用批量下载咯~
导师下令找文献,学生偷偷抹眼泪。
文献三千挤满屏,只下一篇可不行。
作息紊乱失双休,日夜不分忘寝食。
满腔热血搞科研,一盆冷水当头洛。
(打油诗人作)
一、获取文献信息
每个人的研究领域不一样,获取文献信息的方式不一样。这里以Pubmed1为例,PubMed是主要用于检索MEDLINE数据库中,生命科学和生物医学引用文献及索引的免费搜索引擎。之前爬取冠状病毒核酸数据使用过eutils,本篇博客也使用eutils去获取文献信息,关于eutils的介绍可以看利用 eutils 实现自动下载序列文件 。这里就不做介绍~
首先构造搜索url,其中term是你检索的关键词,year对应文献发表日期,API_KEY能够让你在一秒内的访问次数从3次提升到10次。这里将term替换为Machine learning,year替换为2022。然后使用requests库获取该url的对应的信息,在使用BeautifulSoup库将其转化为html格式。
https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi?db=pubmed&api_key={API_KEY}&term={term}+{year}[pdat]
代码如下:
import pandas as pd
import requests
from bs4 import BeautifulSoup
import math
import re
import timeAPI_KEY = "Your AIP KEY"
term = "Machine Learning"
year = "2022"
url_start = f'https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi?db=pubmed&api_key={API_KEY}&term={term}+{year}[pdat]'
info_page = BeautifulSoup(requests.get(url_start, timeout=(5, 5)).text, 'html.parser')
爬取的结果如下,可以看到结果主要包括许多PMID。然后包括的信息总数<count>31236</count>、最大返回数<retmax>20</retmax>以及结果开始的序号<retstart>0</retstart>。下一步就是根据id获取文章对应的信息。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE eSearchResult PUBLIC "-//NLM//DTD esearch 20060628//EN" "https://eutils.ncbi.nlm.nih.gov/eutils/dtd/20060628/esearch.dtd"><esearchresult><count>31236</count><retmax>20</retmax><retstart>0</retstart><idlist>
<id>37878682</id>
<id>37873546</id>
<id>37873494</id>
... # omitting many results
<id>37786662</id>
<id>37780106</id>
<id>37776368</id>
</idlist><translationset><translation> <from>Machine Learning</from> <to>"machine learning"[MeSH Terms] OR ("machine"[All Fields] AND "learning"[All Fields]) OR "machine learning"[All Fields]</to> </translation></translationset><querytranslation>("machine learning"[MeSH Terms] OR ("machine"[All Fields] AND "learning"[All Fields]) OR "machine learning"[All Fields]) AND 2022/01/01:2022/12/31[Date - Publication]</querytranslation></esearchresult>
可以看到结果也是31236条记录,爬取的信息忠实于实际的信息,可以放心食用~

获取文章的信息也是相同的步骤,首先构造url,然后爬取对应的信息,直接上代码:
API_KEY = "Your AIP KEY"
id_str = '37878682'
url_paper = f'https://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?db=pubmed&api_key={API_KEY}&id={id_str}&rettype=medline&retmode=text'
paper_info = BeautifulSoup(requests.get(url_paper, timeout=(5, 5)).text, 'html.parser')
结果如下,包括PMID、DOI、摘要、作者、单位、发表年份等等信息,你可以从这一步获得的信息中获取你需要的信息如DOI。接下来的就是要爬取文献对应的PDF文件。这是最关键的一步。
PMID- 37878682
OWN - NLM
STAT- Publisher
LR - 20231025
IS - 2047-217X (Electronic)
IS - 2047-217X (Linking)
VI - 12
DP - 2022 Dec 28
TI - Computational prediction of human deep intronic variation.
LID - giad085 [pii]
LID - 10.1093/gigascience/giad085 [doi]
AB - BACKGROUND: The adoption of whole-genome sequencing in genetic screens has facilitated the detection of genetic variation in the intronic regions of genes, far from annotated splice sites. However, selecting an appropriate computational tool to discriminate functionally relevant genetic variants from those with no effect is challenging, particularly for deep intronic regions where independent benchmarks are scarce. RESULTS: In this study, we have provided an overview of the computational methods available and the extent to which they can be used to analyze deep intronic variation. We leveraged diverse datasets to extensively evaluate tool performance across different intronic regions, distinguishing between variants that are expected to disrupt splicing through different molecular mechanisms. Notably, we compared the performance of SpliceAI, a widely used sequence-based deep learning model, with that of more recent methods that extend its original implementation. We observed considerable differences in tool performance depending on the region considered, with variants generating cryptic splice sites being better predicted than those that potentially affect splicing regulatory elements. Finally, we devised a novel quantitative assessment of tool interpretability and found that tools providing mechanistic explanations of their predictions are often correct with respect to the ground - information, but the use of these tools results in decreased predictive power when compared to black box methods. CONCLUSIONS: Our findings translate into practical recommendations for tool usage and provide a reference framework for applying prediction tools in deep intronic regions, enabling more informed decision-making by practitioners.
CI - (c) The Author(s) 2023. Published by Oxford University Press GigaScience.
FAU - Barbosa, Pedro
AU - Barbosa P
AUID- ORCID: 0000-0002-3892-7640
在进行尝试下载文献之前,构建两个函数便于批量爬取信息。get_literature_id和get_detailed_info分别获取文献的PMID以及详细信息。
def get_literature_id(term, year):API_KEY = "Your AIP KEY"# pdat means published date, 2020[pdat] means publised literatures from 2020/01/01 to 2020/12/31url_start = f'https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi?db=pubmed&api_key={API_KEY}&term={term}+{year}[pdat]'time.sleep(0.5)info = BeautifulSoup(requests.get(url_start, timeout=(5, 5)).text, 'html.parser')time.sleep(0.5)# translate str to intyear_published_count = int(info.find('count').text)id_list = [_.get_text() for _ in info.find_all('id')]for page in range(1, math.ceil(year_published_count/20)):url_page = f'https://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi?db=pubmed&api_key={API_KEY}&term=pbmc+AND+single+cell+{year}[pdat]&retmax=20&retstart={page*20}'time.sleep(0.5)info_page = BeautifulSoup(requests.get(url_page, timeout=(5, 5)).text, 'html.parser')id_list += [_.get_text() for _ in info_page.find_all('id')]return id_list, year_published_countdef get_detailed_info(id_list):API_KEY = "Your AIP KEY"# PMID DOI PMCID Title Abstract Author_1st Affiliation_1st Journel Pulication_timeextracted_info = []for batch in range(0, math.ceil(len(id_list)/20)):id_str = ",".join(id_list[batch*20: (batch+1)*20])detailed_url = f'https://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?db=pubmed&api_key={API_KEY}&id={id_str}&rettype=medline&retmode=text'time.sleep(0.5)detailed_info = BeautifulSoup(requests.get(detailed_url, timeout=(5, 5)).text, 'html.parser')literature_as_line_list = detailed_info.text.split('\nPMID')[1:]for literature in literature_as_line_list:# PMIDpmid = literature.split('- ')[1].split('\n')[0]# DOIif '[doi]' in literature:doi = literature.split('[doi]')[0].split(' - ')[-1].strip()else:doi = ""# PMCIDif "PMC" in literature:pmcid = literature.split('PMC -')[1].split('\n')[0].strip()else:pmcid = ""# Titletitle = re.split(r'\n[A-Z]{2,3}\s', literature.split('TI - ')[1])[0].replace("\n ", "")if '\n' in title:title = title.replace("\n ", "")# Abstractabstract = literature.split('AB - ')[1].split(' - ')[0].replace("\n ", "").split('\n')[0]# Author_1stauthor = literature.split('FAU - ')[1].split('\n')[0]# Affiliation_1sttmp_affiliation = literature.split('FAU - ')[1]if "AD - " in tmp_affiliation:affiliation = tmp_affiliation.split('AD - ')[1].replace("\n ", "").strip('\n')else:affiliation = ""# Journeljournel = literature.split('TA - ')[1].split('\n')[0]# Publication timepublication_time = literature.split('SO - ')[1].split(';')[0].split('. ')[1]if ':' in publication_time:publication_time = publication_time.split(':')[0]extracted_info.append([pmid, doi, pmcid, title, abstract, author, affiliation, journel, publication_time])return extracted_info
爬取的部分结果如下图所示。有些文章没有DOI号,不信的话可以尝试在PubMed中搜索该文章对应的PMID33604555看看~。

二、下载文献PDF文件
关于下载文献的PDF文件,这里是从SciHub中爬取的,不是从期刊官方,部分文章可以没有被SciHub收录或者收录的预印版,因此,不能 保证上文中获取的信息就能从SciHub中全部下载成功。如果不能访问SciHub,自然就不能爬取对应的内容了,可以考虑买个VPN,科学上网~。
爬取SciHub上的文章需要构建一个访问头的信息,不然回返回403禁止访问。然后将获取的内容保存为PDF格式即可。其中从SciHub中爬取文献PDF文件参考了 用Python批量下载文献2
data = pd.read_csv('/mnt/c/Users/search_result.csv')
doi_data = data[~data['DOI'].isna()]
doi_list = doi_data["DOI"].tolist()
pmid_list = doi_data["PMID"].tolist()
for doi, pmid in zip(doi_list, pmid_list):download_url = f'https://sci.bban.top/pdf/{doi}.pdf?#view=FitH'headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36"}literature = requests.get(download_url, headers=headers)if literature.status_code != 200:print(f"this paper may have not downloading permission, it's doi: {doi}")else:with open(f'/mnt/c/Users/ouyangkang/Desktop/scraper_literature/{pmid}.pdf', 'wb') as f:f.write(literature.content)
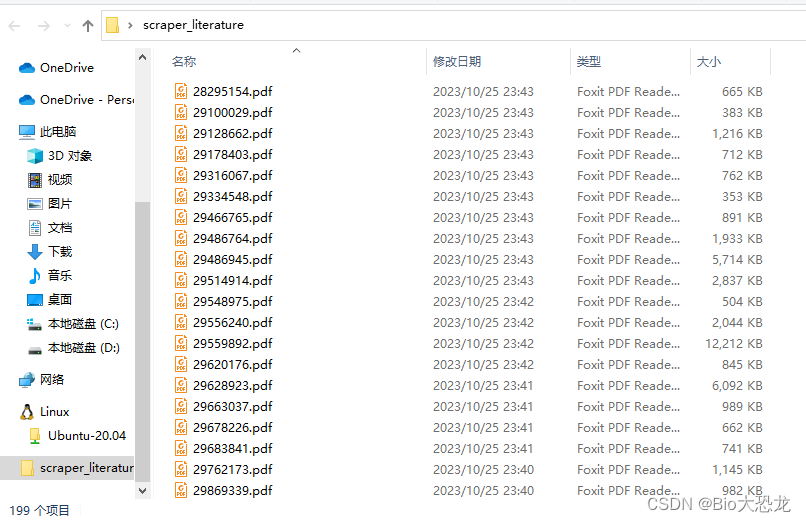
爬取结果如下图所示,成功下载了199篇~(这里的关键词不是机器学习,提供的doi数量是522,下载成功率为38%)。
参考
.Pubmed official websity ↩︎
用Python批量下载文献 ↩︎
相关文章:
爬虫批量下载科研论文(SciHub)
系列文章目录 利用 eutils 实现自动下载序列文件 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、获取文献信息二、下载文献PDF文件参考 前言 大家好✨,这里是bio🦖。…...

explain查询sql执行计划返回的字段的详细说明
当使用EXPLAIN命令查看SQL语句的执行计划时,会返回一张表格,其中包含了该SQL语句的执行计划。下面是每个字段的详细分析: id:执行计划的唯一标识符。如果查询中有子查询,每个子查询都会有一个唯一的ID。在执行计划中&a…...

讯飞输入法13.0发布,推出行业首款生成式AI输入法
🦉 AI新闻 🚀 讯飞输入法13.0发布,推出行业首款生成式AI输入法 摘要:科大讯飞在2023年全球开发者节上发布了全新讯飞输入法13.0版本,其中最大的亮点是推出了行业首款生成式AI输入法。这次升级将生成式AI能力融入输入…...

35. 搜索插入位置、Leetcode的Python实现
博客主页:🏆看看是李XX还是李歘歘 🏆 🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺 💗点关注不迷路,总有一些📖知识点📖是你想要的💗 ⛽️今…...

使用 DDPO 在 TRL 中微调 Stable Diffusion 模型
引言 扩散模型 (如 DALL-E 2、Stable Diffusion) 是一类文生图模型,在生成图像 (尤其是有照片级真实感的图像) 方面取得了广泛成功。然而,这些模型生成的图像可能并不总是符合人类偏好或人类意图。因此出现了对齐问题,即如何确保模型的输出与…...

cocosCreator 之 crypto-es数据加密
版本: 3.8.0 语言: TypeScript 环境: Mac 简介 项目开发中,针对于一些明文数据,比如本地存储和Http数据请求等,进行加密保护,是有必要的。 关于加密手段主要有: 对称加密 使用相…...

Leetcode---368周赛
题目列表 2908. 元素和最小的山形三元组 I 2909. 元素和最小的山形三元组 II 2910. 合法分组的最少组数 2911. 得到 K 个半回文串的最少修改次数 一、元素和最小的山形三元组I 没什么好说的,不会其他方法就直接暴力,时间复杂度O(n^3),代…...
矢量图形编辑软件Illustrator 2023 mac中文版软件特点(ai2023) v27.9
illustrator 2023 mac是一款矢量图形编辑软件,用于创建和编辑排版、图标、标志、插图和其他类型的矢量图形。 illustrator 2023 mac软件特点 矢量图形:illustrator创建的图形是矢量图形,可以无限放大而不失真,这与像素图形编辑软…...

一、Docker Compose——什么是 Docker Compose
Docker Compose 是一个用来定义和运行多容器 Docker 应用程序的工具,他的方便之处就是可以使用 YAML 文件来配置将要运行的 Docker 容器,然后使用一条命令即可创建并启动配置好的 Docker 容器了;相比手动输入命令的繁琐,Docker Co…...

Java提升技术,进阶为高级开发和架构师的路线
原文网址:Java提升技术,进阶为高级开发和架构师的路线-CSDN博客 简介 Java怎样提升技术?怎样进阶为高级开发和架构师?本文介绍靠谱的成长路线。 首先点明,只写业务代码是无法成长技术的。提升技术的两个方法是&…...

记一次 .Net+SqlSugar 查询超时的问题排查过程
环境和版本:.Net 6 SqlSuger 5.1.4.* ,数据库是mysql 5.7 ,数据量在2000多条左右 业务是一个非常简单的查询,代码如下: var list _dbClient.Queryable<tb_name>().ToList(); tb_name 下配置了一对多的关系…...
PHP危险函数
PHP危险函数 文章目录 PHP危险函数PHP 代码执行函数eval 语句assert()语句preg_replace()函数正则表达式里修饰符 回调函数call_user_func()函数array_map()函数 OS命令执行函数system()函数exec()函数shell_exec()函数passthru() 函数popen 函数反引号 实列 通过构造函数可以执…...

【ARM Cortex-M 系列 4 番外篇 -- 常用 benchmark 介绍】
文章目录 1.1 CPU 性能测试 MIPS 计算1.1.1 Cortex-M7 CPI 1.2 benchmark 小节1.3.1 Geekbenck 介绍 1.3 编译参数配置 1.1 CPU 性能测试 MIPS 计算 每秒百万指令数 (MIPS):在数据压缩测试中,MIPS 每秒测量一次 CPU 执行的低级指令的数量。越高越好&…...
web安全-原发抗抵赖
原发抗抵赖 原发抗抵赖也称不可否认性,主要表现以下两种形式: 数据发送者无法否认其发送数据的事实。例如,A向B发信,事后,A不能否认该信是其发送的。数据接收者事后无法否认其收到过这些数据。例如,A向B发…...

强化学习------PPO算法
目录 简介一、PPO原理1、由On-policy 转化为Off-policy2、Importance Sampling(重要性采样)3、off-policy下的梯度公式推导 二、PPO算法两种形式1、PPO-Penalty2、PPO-Clip 三、PPO算法实战四、参考 简介 PPO 算法之所以被提出,根本原因在于…...
express框架)
node(三)express框架
文章目录 1.express介绍2.express初体验3.express路由3.1什么是路由?3.2路由的使用 1.express介绍 是一个基于Node平台的极简、灵活的WEB应用开发框架,官网地址:https://www.expressjs.com.cn/ 简单来说,express是一个封装好的工…...

linux find命令搜索日志内容
linux find命令搜索日志内容 查询服务器log日志 find /opt/logs/ -name "filename.log" | xargs grep -a "这里是要查询的字符"加上-a 是为了不报查出 binary 的错 服务器会返回 包含所查字符的整行日志信息...

CentOS 编译安装TinyXml2
安装 TinyXml2 Git 源码下载地址:https://github.com/leethomason/tinyxml2 步骤1:首先,你需要下载tinyxml2的源代码。你可以从Github或者源代码官方网站下载。并上传至/usr/local/source_code/ 步骤2:下载完成后,需要将源代码解…...

竞赛选题 深度学习人体跌倒检测 -yolo 机器视觉 opencv python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习的人体跌倒检测算法研究与实现 ** 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🥇学长这里给一个题目综合评分(每项满…...

使用gson将复杂的树型结构转Json遇到的问题,写入文件为空
某个项目需要用到一个较为复杂的数据结构。定义成一个树型链表。 public class TreeNode { private String name; public String getName() { return name; } public void setName(String name) { this.name name; } public String getPartType() { retur…...

AI专著撰写秘籍!AI专著生成工具助力,3天完成20万字专著写作!
撰写学术专著时,研究者必须在“内容的深度”和“覆盖的广度”之间找到一个合适的平衡点,这往往是很多学者面临的挑战。从深度来看,AI专著写作要确保核心观点具备充足的学术基础,不仅要清楚地回答“是什么”,还要深入探…...
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题 计算机视觉领域正经历一场由Transformer架构引领的革命。从最初的图像分类任务到如今的复杂场景理解,Transformer以其强大的全局建模能力不断刷新着各项基准。而在天气…...

巧用邮件合并批量生成带条形码的证件标签
1. 为什么需要批量生成带条形码的证件标签? 在日常办公中,我们经常会遇到需要批量制作证件标签的情况。比如学校图书馆要给新生办理借书证,公司要给新员工制作工牌,或者社区要给居民发放会员卡。传统的手工制作方式不仅效率低下&…...

轻量化AI助手框架部署指南:基于Nectar-GPT构建社交场景智能机器人
1. 项目概述:一个面向社交场景的轻量化AI助手最近在GitHub上看到一个挺有意思的项目,叫socialtribexyz/Nectar-GPT。光看名字,你可能会觉得这又是一个基于GPT API的简单封装,或者是一个聊天机器人。但当我深入去研究它的代码结构、…...

如何用ComfyUI-WanVideoWrapper开启你的AI动态内容创作之旅
如何用ComfyUI-WanVideoWrapper开启你的AI动态内容创作之旅 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 在AI视频生成的世界里,你是否曾想象过将文字描述转化为生动的动态画面&am…...
)
LangGraph Agent 开发指南(9~工具 Tools)
一、什么是工具? 1.1 通俗解释 想象你有一个智能助手: 没有工具:你: 帮我查一下北京明天的天气助手: 抱歉,我没有联网功能,无法查询实时天气有工具:你: 帮我查一下北京明天的天气助手: 好的,…...

Cursor AI插件开发指南:构建企业级智能编码助手
1. 项目概述:一个为开发者而生的智能编码伴侣如果你是一名开发者,每天在IDE里敲代码的时间超过8小时,那你一定对“上下文切换”和“信息查找”这两件事深恶痛绝。想象一下,你正在写一个复杂的API接口,突然需要回忆上周…...

从LED驱动到继电器控制:深入解析NPN与PNP三极管在电路设计中的选型避坑指南
从LED驱动到继电器控制:深入解析NPN与PNP三极管在电路设计中的选型避坑指南 在电子电路设计中,三极管作为基础却关键的元件,其选型直接影响着电路的可靠性和性能。特别是当我们需要驱动LED、继电器或电机等负载时,NPN与PNP三极管的…...

Win10下VSCode与OpenCV环境搭建:从零到一的避坑指南
1. 环境准备:安装必要工具链 在Windows 10上搭建OpenCV开发环境,首先需要准备好三个核心工具:MinGW、CMake和VSCode。这三个工具就像盖房子需要的钢筋、水泥和施工图纸,缺一不可。 MinGW是Windows下的GNU工具集,相当…...

Zenko CloudServer高可用部署:集群配置与负载均衡方案
Zenko CloudServer高可用部署:集群配置与负载均衡方案 【免费下载链接】cloudserver Zenko CloudServer, an open-source Node.js implementation of the Amazon S3 protocol on the front-end and backend storage capabilities to multiple clouds, including Azu…...