关于生成式人工智能模型应用的调研
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:A survey of Generative AI Applications
链接:https://arxiv.org/abs/2306.02781
摘要
生成式人工智能(Generative AI)近年来经历了显著的增长,导致在各种领域出现了广泛的应用。在本文中,我们提供了对350多个生成式人工智能应用的综合调查,提供了结构化的分类法和对各种单模和多模生成式人工智能的简明描述。这项调查分为各个部分,涵盖了各种单模生成式人工智能应用,如文本、图像、视频、游戏和脑信息等。我们的调查旨在为研究人员和从业者提供宝贵的资源,以帮助他们在迅速扩展的生成式人工智能领域中导航,促进对当前最先进技术的更好理解,推动领域的进一步创新。
1 介绍
突破性的生成式人工智能(Generative AI)模型的出现,例如ChatGPT [229]和DALL-E [247],催生了数字内容的合成和处理的新时代。具体而言,这些强大的机器学习算法展示了合成逼真图像、音频、文本和其他数据形态的前所未有能力[153]。特别是,这些最先进的语言和图像生成模型,利用深度学习和变换器结构的优势,已经实现了在各种领域生成大量内容的可能性。生成式人工智能指的是可以生成新内容的人工智能,而不仅仅是像专家系统那样分析或处理现有数据[219]。装备了庞大数据集和复杂设计的生成式人工智能模型具有创造新的多样内容的非凡能力。它们可以处理和学习来自多种来源的信息,如维基百科[262]、Github[94]等。通过利用这些丰富的数据,这些模型可以生成广泛的多媒体格式,包括视频、音频和文本。
近年来,计算能力的不断增长已经利用了深度神经网络[188]、变换器以及其他创新模型,如生成对抗网络[113]和变分自动编码器[219]。所有这些模型都能有效地捕捉数据的复杂性,使它们擅长对特定或一般领域的语言或图像的高维概率分布进行建模。通过将生成模型与其他技术相结合,将语言或图像的潜在高维语义空间映射到文本、音频或视频的多媒体表示,可以将任何输入格式,如文本,转化为各种输出格式,如视频。这种多功能性允许在多媒体格式之间无缝转换,使生成模型在众多应用中变得不可或缺。生成式人工智能的一个最显著特点是它具有无限应用潜力。这些模型可以被训练成从各种输入格式生成真正不同的多媒体格式,如视频、音频或文本。例如,生成式人工智能可以从文本描述中创建逼真的图像,从音频生成视频内容,甚至根据特定风格或情感生成音乐作品。此外,生成式人工智能有望通过自动化内容创建和提供个性化体验,彻底改变广告、娱乐和教育等行业。借助从多种数据源学习和生成各种多媒体输出的能力,这些模型可以帮助企业和个人节省时间和资源,同时开拓新的创意可能性。总之,生成式人工智能模型,凭借其对丰富数据和复杂设计的访问,为内容的创建和转化提供了无与伦比的潜力。它们学习来自不同来源的数据,生成各种多媒体格式,并将一个格式的输入转化为另一个格式的输出,为当今技术驱动的世界提供了不可或缺的工具。
最近的工作中,已经有关于大型语言模型(LLMs)和生成式人工智能的调查,涵盖了不同应用技术[328,85,323,326,324,68,325]。与以往的调查不同,这次综合审查旨在通过强调不仅最突出的生成模型和它们的基础技术,还突出了这项技术的所有不同用途,提供独特的视角。此外,我们在这个不断发展的行业中提供了最新的竞争前景以及支持这一增长的模型。
这一资源包括15个类别,包括文本、图像、视频、3D、代码和软件、语音、AI理解、商业、游戏、音乐、生物技术、大脑、其他以及多模态。在每个部分中,详细介绍了当前技术的系统分类,包括可用的模型和工具。通过对这些多样的人工智能应用进行系统性探索,这项调查成为研究人员、学者和专业人士的重要参考,使他们能够更好地理解生成式人工智能不断发展的格局及其深远影响。
举个例子,一个3D游戏设计师可能对他的项目有各种生成式人工智能需求。他可以在3D和游戏两个类别下找到他的3D AI需求的解决方案,从而获得更具体的结果和不同的答案。他还可以在商业和文本两个类别下找到他更多的商业需求的解决方案。通过这项调查,我们相信用户将能够很好地了解生成式人工智能的发展趋势以及他们可能找到所需技术的领域。
在本文中,我们提出了一个广泛的字典的构想,以便于最受欢迎的生成式人工智能应用,这些应用正在显著改变诸如视频游戏[199]、设计[183]和商业运营[2]等行业。用户在确定每个不同应用领域内开发的程序时所经历的挑战,证实了对综合参考工具的需求。
2 模型的基本分类
本文探讨了生成式人工智能(Generative AI)的兴起应用,重点关注其在各个领域的变革潜力,包括艺术、商业、生物技术和设计等。我们通过将生成式人工智能分成13个部分,根据其产生的输出、使用的背景以及业务用途来进行分类。读者可以注意到许多模型可以被归类到文本类别中,因为它们的输出是文本。或者许多文案生成模型也可以被归类到文本类别。下面所示的分类是为了让潜在的生成式人工智能技术用户可以根据用例快速找到他们将要使用的技术。在本文的第一部分,我们介绍了我们对当前生成式人工智能技术进行分类的类别。在这里,我们提供了不同类别的摘要:
-
文本类别:文本类别中的生成式人工智能技术旨在创建和操作自然语言文本。这些技术包括可以生成类似人类文本的语言模型,例如OpenAI的GPT模型。尽管其中最著名的模型是聊天机器人,如OpenAI的ChatGPT或Google的BARD,但此类别还包括其他类型的模型,包括文本写作助手、科学语言模型或聊天机器人。此类别的主要标准是模型生成文本作为输出。
-
图像类别:图像类别中的生成式人工智能技术专注于创建和操作视觉图像。此类别的主要标准是最终输出是图像。这可以包括可以根据文本描述创建图像的图像生成模型以及图像编辑模型。为简化起见,该类别分为艺术图像创建、逼真图像创建和图像编辑。一些同时执行两种或更多任务的模型被随机放入其中一个类别。此类别中的其他模型包括文本到布局和文本到分子表示,它们无法包括在上述的其他类别中。
-
视频类别:视频类别中的生成式人工智能技术旨在创建和操作视频内容。此类别的主要标准是最终输出是视频。这主要包括可以根据文本描述生成新视频内容的视频创建模型。其他模型包括后期制作、文本到场景生成、文本到动作捕捉、图像到视频以及视频配音。
-
3D类别:3D类别中的生成式人工智能技术专注于创建和操作三维对象和环境。主要标准是使用生成的输出是完整的3D模型。此外,还有专为元宇宙目的而设计的4D模型和3D模型。输入包括文本、单一图像、图像和2D模型。
-
代码和软件类别:代码和软件类别中的生成式人工智能技术旨在自动编写代码和创建软件。主要标准是最终输出是代码。这包括各种类别:文本到代码、文本到网站、文本到软件和文本到应用程序。其他不太常见的模型包括设计到代码、文本到软件、文本到RPA和代码转换器。文本到软件类别旨在适应Adept,一家希望用户仅通过文本输入与计算机进行交流的公司,这也是为什么它被包括在这里的原因。
-
语音类别:语音类别中的生成式人工智能技术专注于创建和操作口语语言。所有这些技术都能将输入转换为口语输出。这分为文本到语音、语音到语音和语音编辑。
-
AI理解类别:AI理解类别中的生成式人工智能技术是那些可以将输入转化为文本输出的模型。这个特殊类别是因为需要一个总结可以将多种输入转化为语音的模型的类别。输入包括:语音、图像、音频和视频、图像、视频、隐喻、半结构化数据、结构化数据、电影和生成区域。
-
商业类别:商业类别中的生成式人工智能技术专注于将人工智能应用于改进业务流程和决策。许多在前述类别中提到的模型,如文本类别中的ChatGPT或图像类别中的Midjourney,也可以被企业使用。尽管如此,该类别的目的是为了让一般企业中的人找到适用于他们业务操作的模型。这些分为市场营销、新业务模型和业务运营。
-
游戏类别:游戏类别中的生成式人工智能技术旨在使游戏开发更加容易。他们使用文本、3D和图像模型来实现其目标。这分为视频游戏创建和角色。
-
音乐类别:音乐类别中的生成式人工智能技术专注于创建和操作音乐内容。这包括音乐生成、音乐编辑和舞蹈到音乐模型。
-
生物技术类别:生物技术类别中的生成式人工智能技术旨在将生成式人工智能应用于生物研究和医疗应用。这可以包括可以预测蛋白质或DNA序列结构的模型,以及可以识别新药候选的药物发现工具。尽管其中一些模型也可以包含在商业类别中,但由于该领域中生成式人工智能应用的丰富性,因此制定了这个类别。
-
大脑类别:大脑类别中的生成式人工智能技术专注于将生成式人工智能应用于帮助人们进行交流。这包括大脑到文本模型和大脑到图像模型。
-
其他类别:其他类别专门为适应Alphatensor(一种用于发现算法的开创性人工智能技术)以及AutoGPT(一种尝试实现自主GPT的模型)而设立。
-
多模态类别:多模态类别适用于那些可以输入多种类型的输入或输出多种形式数据的模型。其他提到的模型,如文本到幻灯片,也具有这个特点,但这些其他模型不能适应前述的任何其他类别之一。
3 生成式人工智能应用
在本节中,我们将介绍生成式人工智能应用的广泛概述,根据不同主题将其划分为各个小节。
3.1 文本
文本模型,尤其是以对话式聊天机器人为中心的模型,自ChatGPT的推出以来,已经彻底改革了人工智能。在自然语言处理和大型语言模型的帮助下,这些模型具有许多非常有用的功能,如摘要生成、写作辅助、代码生成、语言翻译和情感分析。由于ChatGPT的功能,它们一直是生成式人工智能的主要关注点,数百万用户已经开始受益于它们[163]。
对话式人工智能
对话式人工智能一直是人工智能领域最热门的话题之一。这些服务充当聊天机器人,能够执行各种各样的任务,将文本提示转化为文本输出。它们由大型语言模型或LLMs提供支持。大型语言模型(LLMs)是指包含数百亿(或更多)参数的变换器语言模型,这些模型是在大规模文本数据上训练的,如GPT-3、PaLM、Galactica和LLaMA[328]。它们的一些能力包括文本生成、常识推理、空间推理[177]、数学推理或编程辅助[298][142]。就业务运营而言,有许多应用,如需求预测、库存优化和风险管理[69]。在撰写这些文章时,许多这些功能正在进行研究,就像LLMs的功能一样正在不断被发现。
最著名的例子是ChatGPT,它是在2021年之前的数据基础上训练的,现在具有用于最新数据的测试版功能,包括插件[83]。其他不包含更新信息的聊天机器人包括Claude或Stanford Alpaca[63,278]。具有更新信息的模型包括Bing AI、Google的BARD(由LaMDA提供支持)、ChatGPT的测试版、DuckAssist、Metaphor或Perplexity AI[83,128,207,236,237]。
文本到科学
在科学领域,也可以看到其他应用,其中Galactica[293]和Minerva[191]已经合并。Galactica是一个大型语言模型,可以存储、组合和处理科学语言。Minerva是一个大型语言模型,专注于定量推理任务,如数学、科学和大学水平的工程问题。尽管这些模型完全不能替代人类在这些任务上的推理能力,但它们展示出了有希望的结果。
文本到作者模拟
这些模型最近展示出了重新创建某些写作风格的能力。最近的例子显示,LLMs能够模仿丹尼尔·C·丹尼特[263]或H.P.洛夫克拉夫特[145]等作家的写作风格。丹尼特的论文显示,对丹尼特作品的专家成功率达到了51%,能够区分哲学家的作品和大型语言模型的作品。洛夫克拉夫特的论文显示,没有先前接触过洛夫克拉夫特的人类读者无法区分作者编写的文本和ChatGPT编写的文本。这些都是非常出色的成就,展示了语言模型通过精细调整在模仿写作方面的强大能力。
生成式人工智能还可以用于实时写作辅助。之前提到的聊天机器人,如ChatGPT,可以用于此目的,但也已经创建了专门的应用,如GrammarlyGO[154]和PEER[262]。GrammarlyGO是由Grammarly创建的写作助手,能够撰写草稿、大纲、回复和修订。PEER与Grammarly的软件类似,但为学术文章进行了精细调整,提供了对其操作的解释。
文本到医疗建议
通过精细调整,大型语言模型还被证明对初步医疗建议有用。需要指出的是,目前这些模型仍然不完全适合用于这种用途,不应该用于替代人类。一些这些模型包括Chatdoctor[92]、GlassAI[148]、Med-PaLM 2[270]和YourDoctor AI[317]。它们已经展示了检索医学知识、对其进行推理和回答医学问题的能力,与医生相比,它们的表现相当出色。Med-PaLM 2在MedQA数据集上获得了高达86.5的分数。这些模型再次展示出了通过精细调整创造准确响应的非凡能力。这一领域中发现的最大初创公司是Hippocratic AI[159],它开发了在医学数据集上胜过GPT-4的LLMs。
文本到行程
其他功能包括旅行行程的创建,应用示例包括Roam Around[258]、TripNotes[47]或ChatGPT的Kayak插件[3]。前两者展示了创建访问时间表的能力,而Kayak插件能够通过自然语言查找酒店、航班等。
文档到文本
最后,生成式人工智能还可以使用自然语言来从文档中检索信息。两个应用包括ChatDOC[92]和MapDeduce[203]。它们能够通过自然语言查询快速提取、定位和总结PDF文档中的信息。
3.2 图像
自2022年DALL-E 2发布以来,图像生成式人工智能已经不断发展。这项技术在艺术创作和专业用途方面都非常有用,可用于根据文本提示创建图像,也可用于图像编辑。就艺术创作而言,它推动了创造力的边界,引领了革命。在图像创建方面,先进应用如Midjourney提供了非常逼真的图像,使光栅画似乎更近了一步。
图像编辑
生成式人工智能在图像编辑方面已被证明非常有用。一些有用的应用包括Alpaca AI [59],I2SB [198]和Facet AI [134]。这些应用的一些功能包括修补、去除、提高分辨率、超分辨率、去模糊和深度图生成。使用生成式人工智能进行图像编辑的一个示例是Photoroom AI [238],它能够通过该软件擦除背景并移除图像中的对象。甚至可以通过生成式人工智能实现面部恢复,正如腾讯的Face Restoration工具所展示的[309,294]。它们通过GANs(生成式对抗网络)实现这一目标,GANs是生成式人工智能和深度学习的支柱之一。为了创造性,Stable Diffusion Reimagine允许用户生成单个图像的多种变体[175]。
艺术图像
就艺术图像而言,已经创建了许多平台,用于通过文本提示创建艺术图像。一些示例包括使用DALL-E 2 [248]的OpenART [230],Midjourney [211],Stable Diffusion [124]以及根据文本提示创建图像的Mage.Space,它使用Stable Diffusion进行艺术生成,以及使用Stable Diffusion、DALL-E 2、CLIP-Guided Diffusion、VQGAN+CLIP和神经风格转移进行艺术图像生成的NightCafe。其他平台包括Wonder [312],这是一个用于艺术图像创作的移动应用程序,以及Neural.Love[170,224],这是一个由人工智能提供支持的平台,用于音频、视频和图像编辑和增强,其中包括艺术生成器,可以选择多种样式,如幻想或科幻。与其他平台不同,DALL-E [248]和Midjourney [211]使用自己的模型进行图像生成。
这些模型还被证明对其他艺术图像任务非常有用。通过Tattoos AI [290]可以帮助创作纹身。此外,通过Supermeme AI [283]可以制作网络迷因。此外,通过Profile Picture AI,可以生成艺术化的头像,使用自己的样本图像。
逼真图像
在逼真图像的创建方面,已经涌现出大量能够实现逼真图像生成的模型。它们包括Bing AI Image Creator [73],Craiyon [111],DALL-E 2 [248],GLIGEN [195] [194],Imagen [160],Midjourney [211],Muse [89] [88],Parti [318],Runway ML Text-to-Image [259]和Stable Diffusion ML [124]。通过文本输入,它们试图生成逼真的图像。除了简单的文本到图像生成,它们还有许多其他生成式人工智能的用途。通过图像样本,生成式人工智能可以创建逼真的图像。Booth AI [75]可以通过样本主题图像快速创建生活方式照片。其他应用程序,如Aragon AI [6],Avatar AI [10]和PrimeProfile [243],可以通过样本图像创建头像。生成式人工智能还可以通过文本将设计过程优化。PLaY [97]展示了如何使用潜在扩散将文本转化为布局。此外,Autodraw [67]是一种将简单的绘画转化为形状的绘图模型,可以快速优化设计过程。
3.3 视频
视频生成式人工智能帮助制片人进行叙事。尽管由于视频生成的复杂性,这仍然是一个发展中的领域,但列出的用例,如数字人类视频、人体动作捕捉和视频配音,是具有革命性意义的用途,可以迅速引领技术变革。
3.4 文本到视频
一般视频制作 文本到视频模型仍处于早期阶段,但已经有很多应用尝试在视频生成方面取得成功。最大的模型包括Imagen Video,[160],Meta Make A Video[30],Phenaki[306]和Runway Gen-2[259]。Imagen Video使用级联扩散模型创建视频输出。Meta Make a Video是由Meta Research创建的视频生成模型,可以进行文本到视频、图像到视频和视频编辑。尽管它们远远不能创建逼真的输出,但它们显示出了令人鼓舞的迹象,对制作简单视频非常有用。Phenaki通过文本提示创建多分钟长的视频。此外,Runway Gen-2可以通过文本、视频和图像输入生成视频。可以通过CogVideo[104]生成GIF形式的较短视频,该模型是通过继承预训练的文本到图像模型CogView2进行训练的。
这些视频模型在创建具有数字人物的视频方面有许多应用。应用程序如Colossyan AI[105]、Elai AI[131]、Heygen AI[158]、Hour One AI[162]、Rephrase AI[253]和Synthesia[285]可以通过不同的头像创建专业视频。其中一些应用程序,如Synthesia,将这一技术与120种不同语言的语音合成结合在一起。此外,还可以使用生成式人工智能将文章转化为视频输出。SuperCreator[282]是一款移动应用程序,通过生成式人工智能,可以为TikTok、Reels和Shorts生成短视频,输入文章即可。此外,Synths Video[287]可以将文章转化为YouTube视频。
生成式人工智能可以实现更深度的视频个性化,对于企业非常有用。一个很好的例子是Tavus AI[291],这是一个视频生成平台,可以自动为每个观众成员个性化视频。此外,D-ID[123]使用生成式人工智能技术创建实时视频,以实现身临其境的人类化体验。
它们还可以用于艺术视频生成。例如,Kaiber[179]是一个通过文本和图像提示创建艺术视频的应用程序。甚至可以用于电影制作,Opus AI[233]是一个面向从场景、角色、对话到视觉效果等一切的文本到视频生成器。
生成式人工智能还可以用于图像到视频生成,对虚拟现实非常有用。通过生成式人工智能创建的两个模型是GeoGPT[252]和SE3DS[182]。GeoGPT提供了一种新颖的方法,可以在给定单个场景图像和大规模相机运动轨迹的情况下合成一致的长期视频。SE3D是一种用于从新的视点生成高分辨率图像和视频的方法,包括远远超出输入图像的视点,同时通过使用图像到图像GAN(生成式对抗网络)保持三维一致性。
其他值得注意的视频生成方法包括Riverside AI[257],这是一个具有编辑功能的AI动力视频制作网站,Scenescape[141],这是一种文本驱动的永续视图生成方法,以及Human Motion Diffusion Model[296]。
3.5 3D
这些技术可以通过简单的文本提示、图像或视频实现更容易的3D设计。它们具有各种应用,如游戏制作、元宇宙或城市规划,其中3D设计是至关重要的。
3.6 文本到3D
通过生成式人工智能,可以通过多种类型的输入(文本、图像、图像和2D模型)生成3D模型。关于文本输入,一些重要的模型包括Adobe Firefly[5]、Dreamfusion[242]、GET3D[144]、Magic3D[196]、Synthesis AI[286]和Text2Room[267]。它们通过文本输入创建了带有纹理的3D形状。对于带有动画的3D输入,Mirage[214]是一个生成动画3D元素的3D工具。我们甚至可以通过生成式人工智能生成4D模型,就像MAV3D[269]所展示的动态场景生成器一样。
在图像输入方面,我们可以使用单个图像和多个图像创建3D模型。对于单图像输入,常见的模型有GeNVS[87]、Kaedim[178]、Make-It-3D[289]和RealFusion[205]。对于多图像输入,我们有NVIDIA Lion[322]、EVA3D[161]、Neural-Lift-360[315]和Scenedreamer[96]。特别是对于人物,我们有PersoNeRF[311],它接受样本人像图像并生成3D模型。我们还可以通过2D图像生成3D模型。我们还可以通过Deepmotion[118]和Plask AI[241]将视频输入转化为3D模型。最后,我们还可以通过几何点创建3D模型,NVIDIA LION[322]。
这项技术可以应用于元宇宙。已经将生成式人工智能和元宇宙结合起来的两家公司分别是Metaphysic AI[208]和Versy AI[51]。
3.7 代码和软件
自从这项技术诞生以来,开发人员已经受益匪浅,无论是Github Copilot还是ChatGPT。通过自然语言,这些模型可以帮助用户编程和构建网站。它们还可以帮助程序员处理更重复的任务,如文档编写。最具野心的应用程序Adept甚至表示NLP可以使人们仅仅使用语言与计算机进行交流。代码的民主化可以帮助许多非技术背景的专业人员轻松地操作这些程序,这可能是一项重大的技术进步。
3.8 Text-to-Code
多语言代码生成有许多可以通过文本输入进行多语言代码生成的软件。尽管ChatGPT广泛用于编码,但也正在为此目的创建更多的生成式人工智能应用程序。尽管它们大多是编码助手,但它们也能够通过文本提示生成代码。其中一些是Alphacode [193]、Amazon Codewhisperer [61]、BlackBox AI [13]、CodeComplete [101]、CodeGeeX [329]、Codeium [102]、Mutable AI [221]、GitHub Copilot [146]、GitHub Copilot X [147]、GhostWriter Replit [255]和Tabnine [53]。它们用于完成、解释、转换和生成代码。它们基于上下文和语法生成新的代码行。正如我们可以观察到的,这是应用程序数量最多的领域之一。它们可以根据您的写作风格进行个性化设置。Codex [95]是GitHub Copilot背后的模型,它是最著名的编码助手。对于编码文档,Mintlify [212]和Stenography [279]都已成为使用生成式人工智能进行代码文档编写的重要方式。
在特定编程语言方面,电子表格代码生成已经广泛通过生成式人工智能进行了探索。一些应用程序如AI Office Bot [54]、Data Sheets GPT [265]、Excel Formulabot [140]、Google Workspace AI-Sheets [150]和Sheets AI [42]。它们可以通过文本提示快速生成公式,而AI Office Bot甚至可以解释这些公式。此外,还有用于SQL代码生成的应用程序,如AI2SQL [56]和Seek AI [41]。代码翻译也通过生成式人工智能变得可能,其中Vercel AI Code Translator [299]是最有用的工具之一。甚至通过Microsoft Security Copilot [210]等自然语言可以帮助加强网络安全。这是一种AI动力的安全分析工具,可以快速响应威胁,处理信号并评估风险。
关于网站创建,有Durable [129]和Mutiny [222]。这两个应用程序都可以通过文本提示生成带有图像和文本的网站。特别是对于用户界面生成,我们有三个应用程序,Diagram AI [121]、Galileo AI [21]和Uizard AI[304],它们使用生成式人工智能生成良好的用户界面,并优化客户的体验。The.com [297]甚至可以自动化网页生成,因此公司可以为每位客户创建个性化页面。
关于应用程序创建,有许多应用程序非常适用于应用程序生成。关于应用程序,Flutterflow [138]、Imagica AI [168]和Google Generative App Builder [151]可以为非技术背景的用户生成企业级AI应用程序。至于Web应用程序,Debuild AI [116]、Literally Anything IO [174]和Second AI [264]是用户可以通过文本提示轻松创建Web应用程序的生成式人工智能技术的示例。此外,LLM应用程序创建现在可以通过文本和数据输入轻松提供给非技术专业人员,正如Berri AI[71]和Scale Spellbook [39]所展示的那样。最后,通过自然语言,现在可以设计具有私人数据的应用程序,如Zbrain [321]所示。
在编码领域,出现了其他技术。一个示例是通过Locofy [29]实现的设计到代码技术,它可以将设计转化为移动应用和Web的代码。此外,还有通过Drafter AI [19]的文本自动化工具,这是一个自动化最复杂分析任务的平台,以及使用自然语言构建任何机器人流程自动化的Lasso AI [27]。甚至Adept[4]也已经出现,该项目使自然语言能够与计算机中的一切进行互动。
3.9 Speech
语音技术试图模仿人类语音。文本转语音技术已经使演讲的制作变得更加容易。其他语音到语音技术使通过生成式人工智能进行声音克隆变得非常容易。这项技术在播客、YouTube视频或帮助哑巴进行交流等领域具有无限的未来可能性。
3.10 Text-to-Speech
在语音创作方面,生成式人工智能已经使通过文本提示轻松创建语音录音成为可能。已经创建了大量平台,包括Coqui [109]、Descript Overdub [119]、ElevenLabs [132]、Listnr [197]、Lovo AI [26]、Resemble AI [256]、Replica Studios [280]、Voicemod [307]和Wellsaid [52]。最重要的模型是AudioLM [76],这是Google的高质量音频生成框架,具有长期一致性。
至于语音到语音模型,ACE-VC [166]和VALL-E [308]是最重要的模型。特别是VALL-E可以获取某人声音的三秒录音,并复制该声音,将书面文字转化为语音,具有根据文本上下文的真实语调和情感。其他能够生成语音输出的技术包括Supertone AI [284],它可以提供语音编辑功能,以及Dubverse [127],可以将视频录音转化为语音,非常适用于视频配音。
3.11 AI Understanding
AI在将文本、视频、语音等不同类型的信息转化为自然语言方面取得了较高水平。这非常有用,因为AI能够与人进行沟通,能够将复杂的沟通形式转化为更简单的文本。如果我们可以将任何输入转化为文本,那么我们就可以轻松理解它,并且甚至可以将该输出用作其他技术的输入,从而使AI模型更加完善。
3.12 Speech-to-Text
其中一个主要领域是语音转文本技术,因为字幕和转录非常有用。应用程序包括Cogram AI [103]、Deepgram AI [117]、Dialpad AI [122]、Fathom Video [135]、Fireflies AI [137]、GoogleUSM [327]、Papercup [234]、Reduct Video [305]、Whisper [246]和Zoom IQ [331]。这些技术不仅可以进行语音到文本的任务,还有一些可以实现更多的功能。Deepgram AI可以识别说话者、语言和关键词。Dialpad AI包括实时建议、通话摘要以及自动化客户接触点。Papercup甚至可以进行翻译,并生成具有人类声音的语音。最后,Zoom已经将AI集成到其系统中,包括聊天摘要和电子邮件草稿。通过结合多种生成式人工智能技术,我们可以看到工作流程如何得以优化。
还有其他技术,甚至可以将图像转化为文本。这些技术可以在计算机视觉等领域使用,帮助AI更好地理解人类生成的内容。对于这些技术,一些应用程序的示例包括Flamingo[57]、Segment Anything [181]和VisualGPT [93]。Flamingo甚至可以在视频输入上执行此任务。对于视频输入,我们找到了TwelveLabs [184]和MINOTAUR [152]。TwelveLabs可以从视频输入中提取关键特征,如动作、对象、屏幕上的文本、语音和人员,并将所有这些转化为矢量表示。这些矢量使快速搜索成为可能。Minotaur处理基于查询的长视频理解。在这个领域,还有一个叫做MOVIECLIP [77]的模型非常有用,因为它可以准确识别电影中的视觉场景。通过这项技术,我们可以看到计算机开始有效地理解非结构化的数据集。
甚至有一些平台可以将多种形式的输入转化为文本。Primer AI [36]是一种工具,可以实时理解和处理大量的文本、图像、音频和视频。它有助于理解和处理这些信息,以保护安全和民主。至于Speak AI [40],它可以帮助营销和研究团队将非结构化的音频、视频和文本转化为竞争性见解,使用转录和自然语言处理。通过这两种技术,我们可以看到生成式人工智能如何帮助我们快速分析庞大的非结构化数据集。我们甚至可以通过Primer进行理解和操作,通过Speak AI快速获得见解。
生成式人工智能还被发现可用于将数据表转化为文本。用于此目的的生成式人工智能应用程序的一些示例包括Defog AI [18]、MURMUR [260]和TabT5 [62]。MURMUR特别能够理解非结构化数据。如果我们能够完善这项技术,这可能会对优化业务决策产生重大影响,因为它可以帮助快速理解表格数据。
这项技术还被应用于生成区域到文本建模。GriT [314]是一种变压器,旨在通过区域和文本对实现对象理解,其中区域用于定位对象,文本用于描述对象。这对于对象检测任务可能非常有用。
3.13 Business
生成式人工智能在许多列出的技术领域,如文本、图像和视频,都具有明显的商业应用,可以帮助企业降低成本,减少重复性任务,甚至自动化其他更有创造力和成本的流程,如设计、营销文件或幻灯片制作。它甚至可以使新类型的基于人工智能的企业出现,例如自动化法律的Harvey或自动化会计的Truewind。尽管这些技术尚处于初期阶段,但我们可以设想生成式人工智能将如何改变企业运营的方式,如下所列。
3.14 Marketing
对于营销而言,生成式人工智能产生了巨大的影响,因为它能够更容易地生成创意的区域和图像。在文案撰写方面,已经开发了大量的应用程序,包括Anyword [64]、Copy AI [14]、Google Workspace- Gmail and Docs [150]、Hyperwrite [167]、Jasper [25]、Letterdrop [189]、Regie AI [37]、Simplified AI [268]、Type AI [49]和Writesonic [313]。这些应用程序的功能包括撰写电子邮件、网站内容、草稿、回复、营销内容和产品描述。我们可以轻松看出,优化这些过程对于许多企业将非常有用。事实上,Regie AI甚至会根据您公司的语气调整LM的语气,更符合业务需求。在这里,我们再次看到企业如何结合多种生成式人工智能技术,以优化他们的流程,比如Jasper,可以创建社交媒体帖子、电子邮件、博客和报告。
更具体地说,对于社交媒体内容创建,有一些应用程序,如Clips AI [100]、Pictory AI [239]、Predis AI [34]、Tweethunter [303]和Tweetmonk [48]。Clips AI和Pictory AI将长篇内容重新制作为社交媒体帖子。Predis AI生成品牌语言的视频和图像帖子。Tweethunter和Tweetmonk都会生成品牌内容的推文。我们可以看到生成式人工智能如何适应您的品牌,并快速自动化这些过程。企业也可以使用生成式人工智能生成播客,比如Bytepods [320]。
广告也可以通过生成式人工智能创建,我们可以看到许多应用程序,如Ad Creative AI [112]、Clickable [99]、Omneky [228]、Pencil [235]和Waymark [310]。其中最后一个Waymark非常有用,因为它基于网络数据扫描生成视频。此外,LensAI [28]也非常有用,因为它通过识别对象、标志、动作和背景来优化广告。广告中的叙事也可以由生成式人工智能提供支持,比如AI 21 Labs [55]和Subtxt [43]都可以帮助。
生成式人工智能还可以用于自动化与客户的沟通。一系列应用程序可以为您的业务提供个性化的聊天机器人,例如One Reach AI [33]、OpenSight AI [232]、Brainfish [78]和Yuma AI [319]。电子邮件也可以通过生成式人工智能工具实现自动化,如InboxPro [169]、Lavender [187]、Smartwriter [273]和Twain [302]。一些这些技术甚至包括社交媒体数据和电子邮件分析,可以优化操作。甚至还创建了具有语音助手的平台,例如Poly AI [35]。
销售也可以通过已经创建的大量应用程序由生成式人工智能支持。通过应用程序,联系中心可以得到优化,比如Cresta [15]、Forethought AI [139]、Grain AI [22]和Replicant [254],它们可以改进客户体验。Replicant可以通过电话、短信和聊天解决客户服务问题。而Cresta和Grain等则为联系中心提供实时帮助。Cresta将实时见解转化为实时操作,而Grain AI则自动化了为客户对话记录、记录和获取见解。至于Forethought,它旨在自动化客户体验。对于销售准备,有一个名为Tennr的应用程序 [295],可以在每次销售电话之前生成完美的会议准备。甚至还有一款名为Copy Monkey AI [108]的应用程序,旨在优化亚马逊列表和产品的自然排名。
我们可以看到公司正在投入资源到人工智能中,Salesforce创建的EinsteinGPT [261]就是一个例子,它可以跨Salesforce云生成个性化内容。它将在每一次销售、服务、营销、商务和IT互动中生成内容,从而改善客户体验。通过生成式人工智能,可以驱动视觉内容的生成。可以通过仅使用文本提示来快速创建设计,正如Microsoft Designer [209]所展示的,它可以创建邀请函、电子明信片、图形等等。甚至可以通过生成式人工智能来创建标志,正如Brandmark [79]和Looka AI [201]所展示的。Brandmark还会创建其他与业务相关的内容,如名片。如果您需要商业名称的创意,可以使用Namelix [223]、Brandinition [81]和Brandsnap [80]来生成商业名称。
生成式人工智能还可以帮助公司自动化重复性任务。这可以通过一些应用程序实现,如Bardeen AI [12]、Magical AI [202]和Notion AI [32]。这些专门为重复性任务设计的应用程序对于希望通过机器学习自动化相对简单的流程的公司特别有用。
生成式人工智能还可以帮助公司更具战略性和高级的部门。应用程序如Rationale AI [176]可以帮助创建多种业务分析。应用程序可以通过对话总结和员工支持自动化帮助企业大规模进行员工管理,如Albus ChatGPT [272]、Slack中的ChatGPT [272]和Moveworks [217]。产品创建也可以通过生成式人工智能进行优化,例如Cohere AI [16],它提供LM以检索、生成和分类文本,以创建最佳产品。通过生成式人工智能,可以快速获得反馈,从而更好地理解公司的想法,例如Venturus AI [50]和Mixo AI [213],这两者分析业务创意。
分析师的工作流程也可以通过生成式人工智能变得更加轻松。这可以通过帮助幻灯片生成和市场研究来实现。在幻灯片生成方面,有几款应用程序可以通过自然语言创建演示文稿。其中一些应用程序包括Autoslide AI [9]、Canva Docs to Decks [84]、ChatBA [91]、Decktopus AI [17]、Gamma AI [143]、Google Workspace AI- Slides [150]、Tome AI [45]和Slide AI [38]。其中一些应用程序可以通过简短的文本提示工作,如Tome AI,而其他应用程序可以通过输入长文本,如Canva Docs,将文档转化为幻灯片演示。此外,Decktopus甚至创建幻灯片注释,这可能非常有用。
3.15 Gaming
游戏行业将因为能够从图像、文本和3D模型中使用生成式人工智能技术而受益匪浅。3D模型可以帮助创建,文本模型可以用于叙事和角色。我们可以将游戏视为如何在某个特定行业的价值链的所有部分中使用生成式人工智能的明显案例研究。
生成式人工智能可以用于视频游戏制作。这可以通过应用程序如CSM [114]、Iliad AI [24]和Latitude [186]来实现。专门用于游戏素材的Pixelvibe [240]通过生成式人工智能帮助创建素材。此外,针对游戏纹理,Armorlab是一款专为基于人工智能的纹理创作而设计的软件。现在甚至有一个名为MarioGPT [281]的模型,专为基于LM的开放式文本到游戏关卡生成而设计。
特别是对于游戏角色,我们找到了Character AI [90]、ConvAI [107]、InWorld AI [173]和RCT AI Chaos Box [249]。ConvAI和InWorld AI通过自然语言制作角色。只需输入角色设置,您就可以获得完整的角色。至于RCT AI Chaos Box,该引擎使用深度强化学习,通过分析实时玩家输入动态生成NPC回应和新的故事情节。
这些应用程序和模型将游戏制作过程中的多个方面与生成式人工智能相结合,从而为游戏开发者提供更多工具和资源,以改善游戏的质量和创意。生成式人工智能的应用可以在游戏行业中产生广泛的影响,从游戏资产的创作到角色和故事情节的开发。
3.16 Music
生成式人工智能也可以极大地帮助音乐创作。这可以通过基本的文本提示或其他音乐来实现。这有助于艺术家进行歌曲创作,甚至可以通过简单的文本提示来制作基本的音乐。
在通过自然语言生成音乐方面,已经开发了许多应用程序。它们包括Aiva [7]、ERNIE-music [330]、Harmonai [156]、Infinite Album [58]、Jukebox [120]、Mubert [218]、Musico [220]、Noise2Music [164]、Sonify [275]、soundful [276]和Splash AI Beatbot [70]。它们具有通过简单的自然语言生成音乐的能力。Musico甚至能够对手势、动作、代码和其他声音作出反应。甚至舞蹈也开始可以通过名为EDGE [301]的模型转化为音乐。最后,音乐编辑也可以通过生成式人工智能进行,例如Moises AI [215]和SingSong [125]。
3.17 生物技术
生成式人工智能技术有助于生物技术领域的分子建模过程。这有助于药物发现和蛋白质建模,推动了该领域的进展。随着这些技术的发展,生物技术可能会更轻松地实现其进展。纳斯达克上市公司Absci Corporation [1]已经在其药物创造过程中使用生成式人工智能。
3.18 药物发现
关于药物发现,NVIDIA Bionemo [225]是一种云服务,用于药物发现研究提供了大规模的生成式和预测性生物分子人工智能模型。有众多公司使用生成式人工智能进行药物创造,包括Absci、Atomic AI [8]、BigHat AI [72]、Exscientia [133]、Menten AI [206]和ProteinQure [271]。它们结合了机器学习和生物知识以创建药物。
在蛋白质建模方面,发现的模型包括BARTSmiles [98],一种用于分子表示的生成式语言模型,以及Alphafold [251],这是一个计算机程序,用于预测整个人类基因组的蛋白质结构。此外,有两家公司以生成式人工智能为中心进行蛋白质设计的业务运营,它们分别是Cradle [110]和Profluent [244]。
3.19 大脑
大脑模型可以帮助哑巴人通过生成式人工智能进行交流。尽管这些技术还很年轻,但在这一领域已经可以看到一些有希望的结果。在将脑信号转化为文本的模型方面,我们找到了Meta AI的Speech From Brain [31]和非侵入性脑记录 [130]。它们都尝试从非侵入性脑记录中解码语音。使用稳定扩散用于大脑图像 [288] 是一种基于扩散模型(DM)的新方法,称为稳定扩散,用于从人类脑活动重建图像。
4 其他
这个分类适用于其他模型。首先,Alphatensor [136] 是一种基于强化学习的算法发现的人工智能系统。Alphatensor 的任务是提高矩阵乘法的效率,这在许多基本计算中都会出现。自动化算法发现过程是复杂的,因为可能的算法空间是庞大的。因此,这个模型使用 AlphaTensor,它经过训练,玩一个单人游戏,目标是在有限的因子空间中找到张量分解。AlphaTensor 发现了许多矩阵尺寸的复杂度优于现有技术的算法。
此外,AutoGPT [155] 已经成为生成式人工智能社区中非常著名的模型。这个程序由 GPT-4 驱动,可以自主地连接 LLM“思想”,以实现您设定的任何目标。
4.1 多模态
模型可以充分利用列出的技术,将它们结合到一个应用中。这些列出的应用程序接受多种输入,这可以极大地促进人工智能的进步。此外,像 GATO 这样的多任务代理项目可能是生成式人工智能的未来。虽然一些模型专门像文本到幻灯片这样的模型充分利用了许多生成式人工智能技术,但选择这些模型是因为它们不适合其他分类。
尽管尚未向公众发布,但第四版 GPT,GPT-4,可以接受图像和文本输入,并生成文本输出,正如 GPT-4 的技术报告所示[229]。在可以接受多种数据输入的聊天机器人领域,百度创建的 ERNIE 机器人 [316] 将包括解答数学问题、编写营销文案、回答关于中国文学的问题以及生成多媒体回应的功能。此外,它能够用多种方言回答问题。
关于多模态语言模型,Kosmos-1 [165] 是一种多模态语言模型,具有多种能力。它具有语言理解和生成、知觉语言任务,包括多模态对话、图像字幕、视觉问题回答以及视觉任务,如带有描述的图像识别。至于 Prismer [200],它是一个多模态专家的视觉语言模型。一些任务包括图像字幕、问题回答、对象检测和分割。这个模型在不需要大量训练数据的情况下,与当前最先进的视觉模型相竞争。至于 PALM-E [126],它是一个具有多模态语言的综合模型。一方面,PaLM-E 主要是为机器人开发的模型,可以解决多种类型的机器人和多种方式(图像、机器人状态和神经场景表示)的任务。同时,PaLM-E 也是一个具有广泛能力的视觉和语言模型。它可以执行视觉任务,如描述图像、检测对象或分类场景,并且在语言任务方面也很擅长,比如引用诗歌、解决数学方程或生成代码。
至于通用代理的尝试,GATO [250] 是一个超越文本输出的单一代理。它采用多模态、多任务、多体现的通用策略。同一网络可以同时玩游戏、聊天和按按钮。至于通用智能 [171],这是一个负责开发通用能力代理的公司。他们的目标是部署对齐的人类水平 AI 系统,能够推广到广泛的经济有用任务,并协助科学研究。
至于生成式 AI 的多模态云服务,NVIDIA Picasso [226] 是一种云服务,用于构建和部署生成式 AI 驱动的图像、视频和 3D 应用。它集成了文本到图像、文本到视频和文本到 3D 模型。
甚至有一个名为 HuggingGPT [266] 的框架,利用 LLM(例如 ChatGPT)将各种 AI 模型连接到机器学习社区(例如 Hugging Face)以解决 AI 任务。它使 LLM 充当控制器,管理现有的 AI 模型以解决复杂的 AI 任务,语言可以是通用界面来增强这一点。它在语言、视觉、语音和其他具有挑战性的任务中取得了令人印象深刻的结果,为先进的人工智能开辟了新的途径。
关于 Adobe Firefly [5],它是 Adobe 系列模型,可以使用文本创建图像、矢量、视频和 3D 模型。现在它已经应用在 Photoshop 中,允许用户使用简单的文本提示添加、扩展和删除图像中的内容。
5 总结和未来工作
总的来说,生成式人工智能已经展示出在彻底改变各种行业和重塑我们与数字内容互动方面的巨大潜力。随着这些模型的不断发展,它们为企业和个人提供了在内容创作、问题解决和决策制定方面前所未有的能力。它们生成逼真的图像、音频、文本和其他数据模态的能力为创新和增长带来了新的机会,同时也使体验更加个性化和高效。然而,随着我们拥抱这一强大的技术,有必要解决与其使用相关的伦理问题和潜在的陷阱。例如,像 ChatDoctor 这样的应用可能带来伦理问题,它可以提供医学诊断。通过促进生成式人工智能的负责任开发和采用,我们可以利用其改革潜力,塑造出更具创意、高效和繁荣的未来,使企业和个人受益。
至于未来的工作,本调查将继续更新。从 ChatGPT-3 的发布开始,这些应用程序中的大部分已经发布。随着更多技术的发布,这份调查将继续扩大。
References
(……)
相关文章:

关于生成式人工智能模型应用的调研
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题:A survey of Generative AI Applications 链接:https://arxiv.org/abs/2306.02781 摘要 生成式人工智能(Generative AI)近年来经历了显著的增长&…...

【问题】在安装torchvision的时候,会自动安装torch?
1 背景👇🏻👇🏻👇🏻 在使用如下命令安装torchvision的时候,发现之前已安装的torch被卸载了。 pip install torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple 2 分析🐰&a…...

MySQL数据库备份实战
一、为什么进行数据库备份? 保证业务连续性:数据库中存储着企业的核心业务数据,如果数据丢失或损坏,将会对企业的业务运营产生重大影响。通过定期备份数据库,可以在系统故障或数据丢失时快速恢复数据,保证业务的连续性。 保护数据资产:数据库中存储着企业的重要数据资产…...

每日一题 2558. 从数量最多的堆取走礼物(简单,heapq)
怎么这么多天都是简单题,不多说了 class Solution:def pickGifts(self, gifts: List[int], k: int) -> int:gifts [-gift for gift in gifts]heapify(gifts)for i in range(k):heappush(gifts, -int(sqrt(-heappop(gifts))))return -sum(gifts)...

JavaScript中的Promise
JavaScript中的Promise是一种异步编程的解决方案,它可以避免回调地狱,使代码更加简洁和易于维护。本文将详细介绍Promise的API及其使用案例,并附有代码注释。 Promise的API Promise构造函数 Promise构造函数用于创建一个Promise实例&#…...
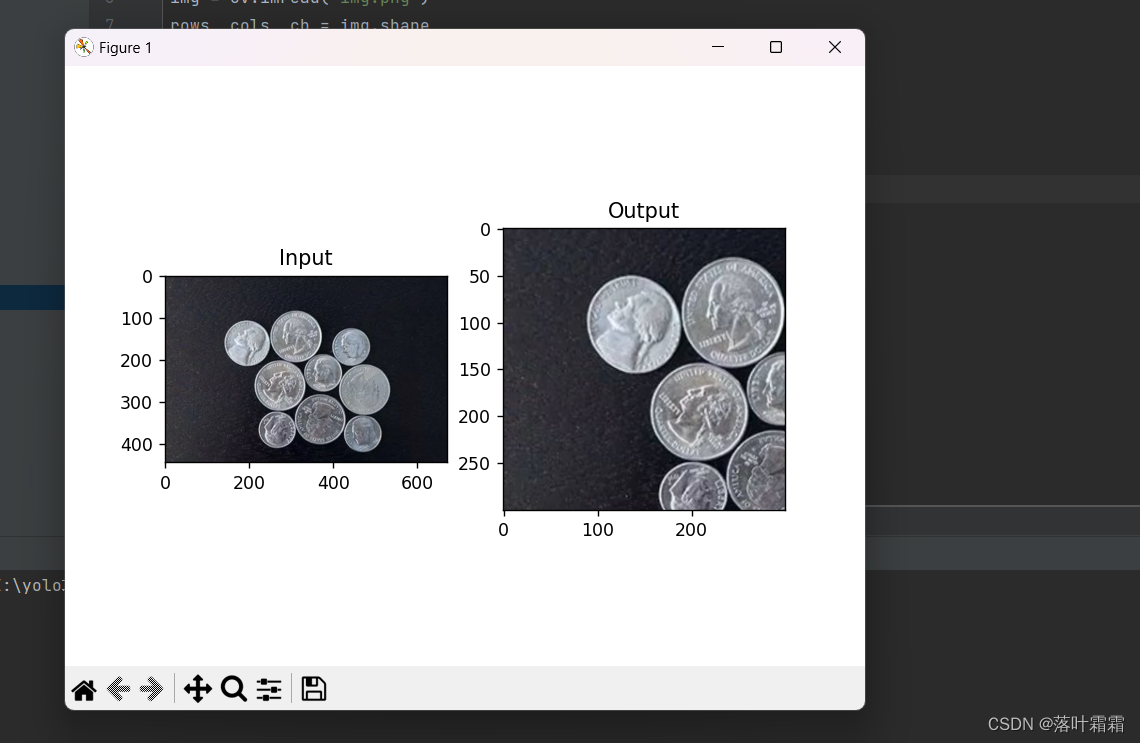
【OpenCV实现图像的几何变换】
文章目录 概要:OpenCV实现图像的几何变换、图像阈值和平滑图像变换小结 概要:OpenCV实现图像的几何变换、图像阈值和平滑图像 使用OpenCV库进行图像处理的三个重要主题:几何变换、图像阈值处理以及图像平滑。在几何变换部分,详细…...

2023MathorCup(妈妈杯) 数学建模挑战赛 解题思路
云顶数模最新解题思路免费分享~~ 2023妈妈杯数学建模A题B题思路,供大家参考~~ A题 B题...
leetCode 76. 最小覆盖子串 + 滑动窗口 + 哈希Hash
我的往期文章:此题的其他解法,感兴趣的话可以移步看一下: leetCode 76. 最小覆盖子串 滑动窗口 图解(详细)-CSDN博客https://blog.csdn.net/weixin_41987016/article/details/134042115?spm1001.2014.3001.5501 力…...
集实战及其原理分析)
52.MongoDB复制(副本)集实战及其原理分析
MongoDB复制集架构 高可用 在生产环境中,不建议使用单机版的MongoDB服务器。 Mongodb复制集(Replication Set)由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Dr…...

【Unity实战】手戳一个自定义角色换装系统——2d3d通用
文章目录 每篇一句前言素材开始切换头型添加更改颜色随机控制头型和颜色新增眼睛同样的方法配置人物的其他部位设置相同颜色部位全部部位随机绘制UI并添加点击事件通过代码控制点击事件添加颜色修改的事件其他部位效果UI切换添加随机按钮保存角色变更数据跳转场景显示角色数据 …...
ruoyi-nbcio版本从RuoYi-Flowable-Plus迁移过程记录
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 从KonBAI / RuoYi-Flowable-Plus 项目移植过来,开始用yarn install之后yarn run dev 还是有问…...

竞赛 深度学习卷积神经网络垃圾分类系统 - 深度学习 神经网络 图像识别 垃圾分类 算法 小程序
文章目录 0 简介1 背景意义2 数据集3 数据探索4 数据增广(数据集补充)5 垃圾图像分类5.1 迁移学习5.1.1 什么是迁移学习?5.1.2 为什么要迁移学习? 5.2 模型选择5.3 训练环境5.3.1 硬件配置5.3.2 软件配置 5.4 训练过程5.5 模型分类效果(PC端) 6 构建垃圾…...
Linux音频-基本概念
文章目录 机器声音的采集原理机器声音的播放原理音频相关基本概念计算机采集音频的模型Linux系统音频框架Linux音频框架的三类角色 Linux音频框架参考文章:Linux音频框架 机器声音的采集原理 声音是一种连续的信号,故其是一种模拟量。 录音设备可以捕获…...

Spring Boot 依赖注入实现原理
Spring Boot 是 Spring 框架的扩展,它简化了 Spring 应用程序的创建和部署。在 Spring Boot 中,依赖注入是实现对象间解耦的重要技术,它使得应用程序的各个组件之间可以通过依赖注入来相互协作,提高了代码的可维护性和可重用性。 …...
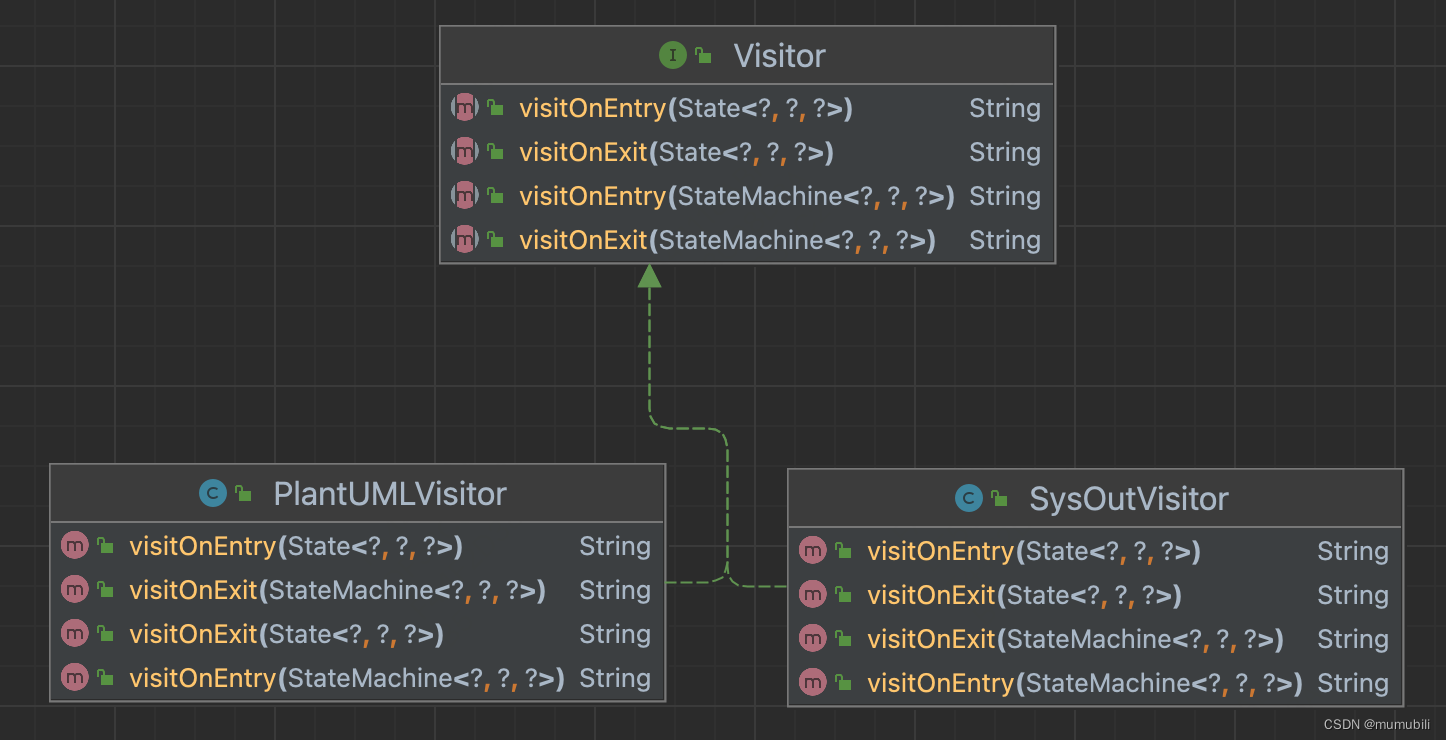
cola架构:cola源码中访问者模式应用浅析
目录 1.访问者模式简介 2.cola访问者模式应用 2.1 cola被访问者类图 2.2 cola访问者类图 我们知道,如果一个对象结构包含很多类型的对象,希望对这些对象实施一些依赖其具体类型的操作,但又避免让这些操作“污染”这些对象的类,…...

Openssl数据安全传输平台015:OCCI的使用方法+在项目中的设计与实现
文章目录 1 OCCI使用1.1 初始化 - Environment 类1.2 连接数据库 - Connection 类1.3 执行SQL 2 OCCI在项目中的使用2.1 OCCI单独封装为一个类文件OCCIOP2.2 在ServerOP中作为私有成员2.3 ServerOP::ServerOP(string json)中实例化进行使用2.4 秘钥协商过程中进行读写操作 1 OC…...

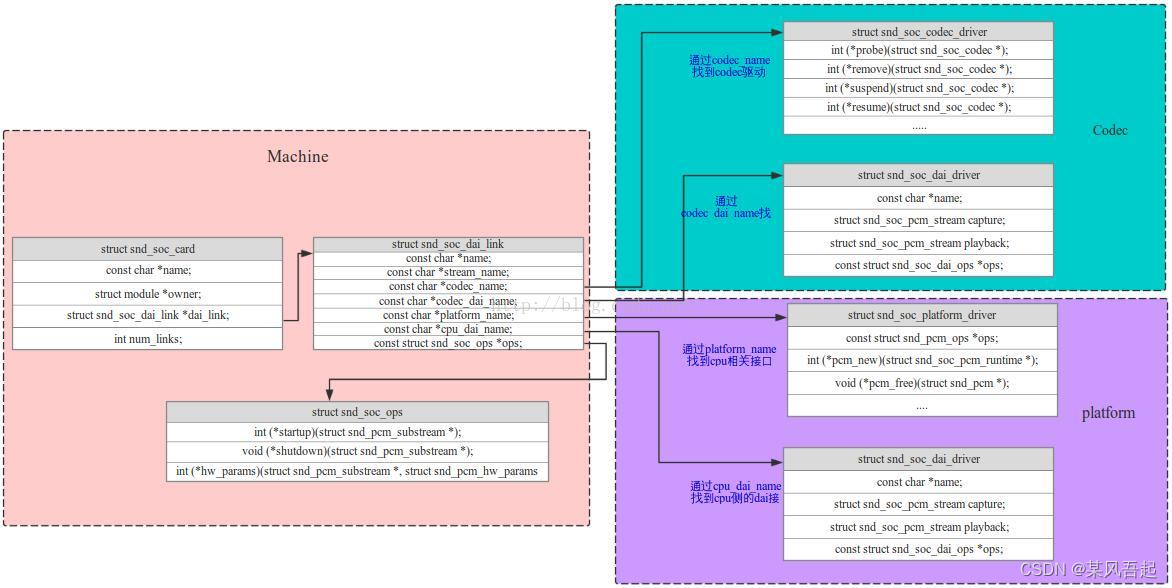
ardupilot开发 --- CAN BUS、DroneCAN 、UAVCAN 篇
1. CAN BUS、DroneCAN 、UAVCAN 区别 UAVCAN是一种轻量级协议,旨在通过CAN BUS 在航空航天和机器人应用中实现可靠通信。 UAVCAN网络是分散的对等网络,其中每个对等体(节点)具有唯一的数字标识符 - 节点ID,并且仅需要…...

京东平台数据分析:2023年9月京东空气净化器行业品牌销售排行榜
鲸参谋监测的京东平台9月份空气净化器市场销售数据已出炉! 9月份,空气净化器的销售同比上年增长。根据鲸参谋平台的数据显示,今年9月,京东平台空气净化器的销量将近15万,同比增长约1%;销售额将近2亿元&…...

vue使日历组件点击时间渲染到时间输入框
首先,你需要在 Vue 中创建一个日历组件,该组件应该能够显示一个月的日历并允许用户选择日期。然后,当用户点击一个日期时,你需要将所选日期的值传递给父组件。最后,你可以在父组件中创建一个时间输入框,当用…...
TensorFlow学习:使用官方模型和自己的训练数据进行图片分类
前言 教程来源:清华大佬重讲机器视觉!TensorFlowOpencv:深度学习机器视觉图像处理实战教程,物体检测/缺陷检测/图像识别 注: 这个教程与官网教程有些区别,教程里的api比较旧,核心思想是没有变…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

抖音批量下载助手:一键构建你的专属视频素材库
抖音批量下载助手:一键构建你的专属视频素材库 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为手动保存抖音视频而烦恼吗?想要批量获取心仪创作者的精彩内容却无从下手&#x…...

如何快速掌握ncmdumpGUI:Windows平台网易云音乐NCM文件转换完整教程
如何快速掌握ncmdumpGUI:Windows平台网易云音乐NCM文件转换完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

3步掌握OpenSpeedy:免费开源游戏加速工具使用指南
3步掌握OpenSpeedy:免费开源游戏加速工具使用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾为游戏卡顿而烦恼?是否希望在单机游戏中加快…...