深入理解Docker之:存储卷相关概念详解和分析
深入理解Docker之:存储卷相关概念详解和分析
1. 为什么要使用存储卷
- Docker镜像由多个只读层叠加而成,启动容器时,Docker会加载只读镜像层,并在镜像栈顶部添加一个读写层
- 如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件的只读版本仍然存在,只是已经被读写层中该文件的副本所隐藏,这个叫做 “写时复制cow”机制
- 关闭并重启容器,其数据不受影响;但是删除Docker容器,则其更改将会全部丢失
- 存在的问题就是:存储于联合文件系统中,不易于宿主机访问;容器间数据共享不便;删除容器其数据会丢失
- 解决方案就是使用volume,中文叫卷或者存储卷,“卷”是容器上的一个或多个“目录”,此类目录可绕过联合文件系统,与宿主机上的某个目录“关联”或者叫“绑定”
docker是容器运行的底层引擎,在组织和运行其容器时,一般只运行一个程序及其子程序。 而程序启动时所借助的镜像,很可能是不止一层的联合挂载组成的。像这种文件系统aufs和overlayfs2,一定要在最上面挂载一个读写层,对此读写层来说,所有在容器中所执行的操作,事实上都是保存在这一层之上的,而对下层内容的操作,比如要删除文件,我们就需要使用cow机制。
如果一个文件在底层layer0是存在的,而后在Layer1上标记删除,他不会真的删除,而是标记为删除。在layer2上就看不见了,在Layer0上的文件,在Layer2上标记为删除,用户也同样看不见。也就是说,如果一个数据在到达最上层之前,我们把它标记为删除,对于最上层的用户一定是不可见的,如果是没标记为删除的,或者是标记为删除的,而用户在最上层又建了一个一模一样的同名文件的,用户才可见。我们去访问一个文件,修改删除之类的操作之后,再访问效率非常的低。尤其是那些对IO要求比较高的应用,比如:redis这样的系统,在存储数据的时候,势必在于实现底层数据存储的时候,对于底层存储系统的性能要求较高。又比如,我们运行了一个存储系统,比如mariadb,或者mysql,本来mysql对于性能的要求就比较高,而mysql是运行在容器中自己创建的文件系统,也就是通过联合挂载之后,运行在最上层的可写文件系统之上的时候,不仅在容器停止的时候,数据会被删除,而且在存储的时候,效率也非常的低。 这就导致这类对IO要求比较高的应用,在使用容器本身的读写层时,性能影响比较大。
要想绕过这种使用的限制,我们需要使用存储卷的形式来实现。 在宿主机上,找一个文件系统,这个文件系统上可能存在一个目录,我们就把这个目录直接与容器内部的文件系统之上的某一目录,建立绑定关系,就好像挂载一样。比如:我们把主机上的/data/web与容器内的/containers/data/web目录建立映射关系,向/data/web中写目录的时候,会写在宿主机的/containers/data/web目录,就好像mount –bind的效果。这样就使得我们容器内的进程实现数据保存时,能够绕过容器内部文件系统的限制,从而与宿主机的目录建立关联关系,我们可以在容器内和系统上共享数据内容,让他们的数据是同步的,本来mount这样的名称空间本来应该是隔离的,但是我们却可以让两个本来是隔离的文件系统在某个子路径上建立一定程度的绑定关系,从而使得在两个容器之间的文件系统的子目录上不再是隔离的,而是能够实现一定意义上共享的效果。所以像这样的关联关系使得像容器之间跨文件系统共享数据这类需求变得容易了。而主机上的这个目录,就是跟容器内建立绑定关系的目录,对于容器来讲,就称作volume,就是存储卷。
2. 什么叫存储卷呢
- 存储卷提供了多种功能来持久存储和共享数据
- Volume于容器初始化之时就会创建,由base image提供的卷中的数据会于此期间完成复制
- 数据卷可以在容器间实现共享和复用
- 对于数据卷中数据的更改是直接体现在宿主机上的绑定的目录的
- 在更新镜像的时候,数据卷是不变的
- 即使容器被删除了,数据卷还是存在的
如果容器内进程的所有有效数据都是保存在存储卷,从而脱离的容器自身的文件系统以后,带来的好处就是,当容器关闭甚至删除时,我们都不用担心数据会丢失了。
不删除与之绑定的在宿主机上的存储目录就可以了。因此,数据就实现了持久,脱离了容器生命周期的持久,这样即便容器被删除,只要我们的容器在重建的时候,让他关联到同一个存储卷上,虽然创建的容器已经不是此前的容器了,但是数据还是那个数据。
容器会被当成一个有生命周期的动态对象来使用,容器关闭就是容器被删除的时候,但是底层的镜像不删除,我们可以基于镜像再启动一个容器。我们启动容器的时候,如果我们忘记了上次关联的文件目录怎么办?如果可以的话,我们希望有一个文件能够保存下来我们上次的容器是怎样启动和保存相关配置的,这个一般都是容器编排工具的作用。这样还有一个好处就是,容器启动在哪台主机上就不太重要了。如果我们有多个docker host,他们所关联的卷也不是宿主机本地的文件系统,我们会使用nfs,共享出来一个目录,这每一个docker主机挂载了nfs目录,对于宿主机来讲,就好像是挂载了本地目录一样,先确保宿主机能够驱动,并且连接到后端的存储服务上去。这每一个宿主机都必须是nfs客户端,并且能够正常挂载nfs文件系统。在宿主机之上,我们启动某一个容器的时候,使用自己本地的目录,关联到了容器上的某个目录,而这个目录恰恰就是nfs之上的某个目录,随后容器启动,保存数据会保存在宿主机之上。然后,这个容器就可以被删除了,下次容器启动在哪并不重要,我们可以在全集群内调度这个容器并启动,只要nfs上的数据目录还在, 且宿主机也能够关联到nfs之上,我们就还能访问到。
因此,我们以后再去分配存储计算和内存资源的时候,就不需要局限在单机之上了,而是在集群内部所有的机器上进行。 这种机制很多容器编排工具都能实现,但是这后面非常依赖一个共享的存储系统。
- 存储卷的初衷是独立于容器的生命周期实现数据持久化,因此删除容器之时既不会删除卷,也不会对哪怕未被引用的卷做垃圾回收操作;当然,如果我们删除容器的时候使用特殊的选项,也能够一并删除存储卷。
- 卷为docker提供了独立于容器的数据管理机制
- 可以把“镜像”想象成静态文件,例如“程序”,把卷类比为动态内容,例如“数据”;于是,镜像可以重用,而卷可以共享;
- 卷实现了“程序(镜像)”和“数据(卷)”分离,以及“程序(镜像)”和“制作镜像的主机”分离,用户制作镜像时,无须在考虑镜像运行的容器所在的主机的环境
Docker有了存储卷之后,在内部读取数据时,如果写在/上,那么还是会写在联合挂载文件系统上,只有写在挂载卷上来,比如/data,就会被关联到宿主机的某一个目录上来。又比如,我们在运行程序的时候会产生一些临时的文件,这些文件通常都会被写在/tmp下面,而tmp下面的数据都会被写在联合挂载的文件系统上。由于这些数据不需要保存,他们会随着容器的删除而删除。
如果说我们期望应用能够在多台机器上运行的话,就需要他在其他宿主机上启动的时候,能够找到此前存储数据的地方,否则,这种启动和运行,就不再是此前的容器所实现的效果了。这个对我们的生产是不适用的,因此,持久存储是必备的条件。 对于这种有状态的应用来讲,不用存储卷,数据只能放在容器本地,即使我们能接受他的存储效率,但是他会导致容器无法被迁移,相当于与当前宿主机绑定。一旦生命周期停止,我们只能让他处于停止状态而不能删除,需要下次启动的时候再启动这个容器,才能保证数据还在。 一旦删除了就不存在了,因为他的可写层是随着容器的生命周期存在而存在的 。 所以这么一来,大家应该牢牢建立起来一个概念,对于有状态的应用,只要他有存数据的需求,那么持久卷就是必须的。
不过对于docker的存储卷用起来并没有这么麻烦,他并没有我们想象的这么强大的功能,至少说,如果不借助额外的体系来组织这个维度的。因为docker的存储卷默认的情况下是使用其所在的宿主机之上的本地文件系统目录的。 也就是说,宿主机自己有一块磁盘,磁盘并没有共享给其他的docker主机,而这个容器所使用的目录,是关联到宿主机上磁盘的一个目录而已,也就意味着这个容器在当前一个宿主机上,启动,创建,再删除,只要他关联到宿主机的目录,那么他的数据就还存在,如果我们把他调度到其他机器上就不能的,这也是docker本身没有解决的问题。 所以说,docker的存储卷本身只能是宿主机的本地存储,而不是我们刚才说的共享存储。 大家发现,其实如果我们手动创建nfs服务器并且挂载到宿主机上,然后让容器在挂载的时候挂载nfs服务器所提供的存储的的方式也可以实现数据的跨主机迁移。但是这样的缺陷也很明显,就是这样也很依赖于运维人员的手动操作。
3. 存储卷的类型
Docker有两种类型的卷,每种类型都在容器中存在一个挂载点,但其在宿主机上的位置有所不同
-
Bind mount volume:一个在宿主机文件系统上指向用户指定位置的卷。也就是说,两个卷都需要手工指定,然后才能建立绑定关系。
-
Docker-managed volume:docker进程创建的,在宿主机上的一个由docker管理的分区。也就是说,我们只管指定容器内部的卷路径,而在宿主机上的目录是由docker创建的,我们不需要人工干预。这样极大的减少了卷在使用时候的耦合关系,缺点是没法手动指定目录,这种卷用于临时使用很方便,但是如果容器删除,而需要再次挂载这个卷的时候,就必须找到指定位置的目录,也就是含有容器ID的目录,重新挂载上去才能继续使用上次的卷。
4. 在容器中使用Volumes
为docker run命令使用-v选项即可使用Volume
4.1 Docker-managed Volume
docker run -it --name bbox1 -v /data busybox
# 查看bbox1容器的卷、卷标识符及挂载的主机目录
docker inspect bbox1
使用docker inspect来观察一下容器,会看到
"Volumes": {"/data": {}},
而挂载的位置在
"Mounts": [{"Type": "volume","Name": "9e62f0c4931f7ea297e12d6baeb0ab74609fb4f85efdff8d5805e5332d8166c6","Source": "/home/webedit/docker_data_root/volumes/9e62f0c4931f7ea297e12d6baeb0ab74609fb4f85efdff8d5805e5332d8166c6/_data","Destination": "/data","Driver": "local","Mode": "","RW": true,"Propagation": ""}],
也就是说,如果我们在/home/webedit/docker_data_root/volumes/9e62f0c4931f7ea297e12d6baeb0ab74609fb4f85efdff8d5805e5332d8166c6/_data路径下创建一个文件,则在容器的/data目录下也能看到。
4.2 Bind-mount Volume
这次我们使用本机的/tmp作为存储卷送给docker的/data/tmp目录去挂载
docker run -it --name bbox1 -d -v /tmp:/data/tmp busybox
我们在通过docker inspect去查看mounts
"Mounts": [{"Type": "bind","Source": "/tmp","Destination": "/data/tmp","Mode": "","RW": true,"Propagation": "rprivate"}],
另外,如果指定的宿主机目录并不存在,docker也会自动创建目录。
4.3 Shared Volume
既然,我们可以把一个目录分给容器做为存储卷使用,我们同样也可以把这个目录同时分给另外一个目录使用,同时也实现了在容器间共享数据了。也就是让他们同时挂载宿主机上的同一个卷。
docker run --name b1 --it -d --rm -v /data/tmp:/tmp busybox
docker run --name b2 --it -d --rm -v /data/tmp:/tmp busybox
通常来说,我们使用共享卷的时候,需要在创建的时候指定这个卷,也就是要记住宿主机的目录的名字。 而Docker还支持共享已经启动的容器的存储卷,也就是说,我们只要指定容器名字,就可以读取这个容器内的定义好了的宿主机和容器内目录,且在创建新容器的时候直接应用到新容器中。也就是说,我们先创建一个容器,只要这个容器存在就可以,不一定要启动,只不过在创建这个容器的时候,我们指定他应该使用什么样的存储路径,但是我们不启动他,让他作为其他容器启动时候的架构容器,或者叫模板容器,我们创建新容器的时候复制架构容器的配置来启动新容器。好处就在于,我们可以直接获取架构容器中的设定,当然,如果只是为了存储卷这一个用途,这样有点大材小用。我们前面还学过joined containers,他还可以共享网络的名称空间。
相关文章:

深入理解Docker之:存储卷相关概念详解和分析
深入理解Docker之:存储卷相关概念详解和分析 1. 为什么要使用存储卷 Docker镜像由多个只读层叠加而成,启动容器时,Docker会加载只读镜像层,并在镜像栈顶部添加一个读写层如果运行中的容器修改了现有的一个已经存在的文件&#x…...

Node.js的基本概念node -v 和npm -v 这两个命令的作用
Node.js 是一个开源且跨平台的 JavaScript 运行时环境,它可以让你在服务器端运行 JavaScript 代码。Node.js 使用了 Chrome 的 V8 JavaScript 引擎来执行代码,非常高效。 在 Node.js 出现之前,JavaScript 通常只在浏览器中运行,用…...

mysql bin_log日志恢复数据
1、开启bin_log日志 开启方式1 my.ini 下配置开启或者vi /etc/my.cnf log_binmysql-bin server_id1 2、参考文章 https://blog.csdn.net/DreamEhome/article/details/130010601 (重点) 【mysql】binlog日志_mysql binlog日志-CSDN博客 MySQL 开启binlog日志和windows服务…...

C++系列之list的模拟实现
💗 💗 博客:小怡同学 💗 💗 个人简介:编程小萌新 💗 💗 如果博客对大家有用的话,请点赞关注再收藏 🌞 list的节点类 template struct list_Node { public: list_Node* _prev; list_…...
?)
什么情况下你会使用AI工具(chatgpt、bard)?
在当今数字化和智能化的时代,AI工具已成为许多领域的常见工具。在本文中,我将探讨什么情况下会使用AI工具。前言 – 人工智能教程 ChatGPT是一款由OpenAI开发的大型语言模型,可以生成文本、翻译语言、编写不同类型的创意内容,并以…...
【go】两数求和
文章目录 题目代码解法2 代码仓库 题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案…...

软考高项-成本管理
工具和技术 三点估算 通过考虑估算中的不确定性与风险,使用3种估算值来界定活动成本的近似区间,可以提高活动成本估算的准确性; 储备分析 为应对成本的不确定性,成本估算中可以包括应急储备。应急储备的管理方法: 将…...

24年FRM备考知识点以及一级公式表
FRM一级公示表以及备考知识点 链接:https://pan.baidu.com/s/17RpFF9OyfRk7FGtEQrxf3A?pwd1234 提取码:1234 FRM二级公示表以及备考知识点 链接:https://pan.baidu.com/s/175D05wV1p94dIfBZThutCQ?pwd1234 提取码:1234...
Spring Cloud学习:二【详细】
目录 Nacos的配置 Nacos的单机启动 服务注册 Nacos服务分级存储模型 优先访问同集群的服务 根据权重负载均衡 环境隔离Namespace Nacos调用流程 Nacos与Eureka注册对比 Nacos与Eureka的共同点 Nacos与Eureka的区别 Nacos配置管理 统一配置 配置自动刷新 多环境配…...

Unity的live2dgalgame多语言可配置剧情框架
这段代码用于读取表格 using System; using System.Collections; using System.Collections.Generic; using UnityEngine; using OfficeOpenXml; using System.IO; using UnityEngine.Networking; using UnityEngine.UI; using Random UnityEngine.Random;public class Plots…...

再畅通工程(最小生成树)
题目描述:还是畅通工程 某省调查乡村交通状况,得到的统计表中列出了任意两村庄间的距离。省政府“畅通工程”的目标是使全省任何两个村庄间都可以实现公路交通(但不一定有直接的公路相连,只要能间接通过公路可达即可)&…...
前后端分离不可忽视的陷阱,深入剖析挑战,分享解决方案,助你顺利实施分离开发。
不管你设计的系统架构是怎么样,最后都是你的组织内的沟通结构胜出。这个观点一直在组织内不断地被证明,但也不断地被忽略。 前后端分离的利与弊 近几年,随着微服务架构风格的引入、前后端生态的快速发展、多端产品化的出现,前后…...

(四)库存超卖案例实战——优化redis分布式锁
前言 在上一节内容中,我们已经实现了使用redis分布式锁解决商品“超卖”的问题,本节内容是对redis分布式锁的优化。在上一节的redis分布式锁中,我们的锁有俩个可以优化的问题。第一,锁需要实现可重入,同一个线程不用重…...
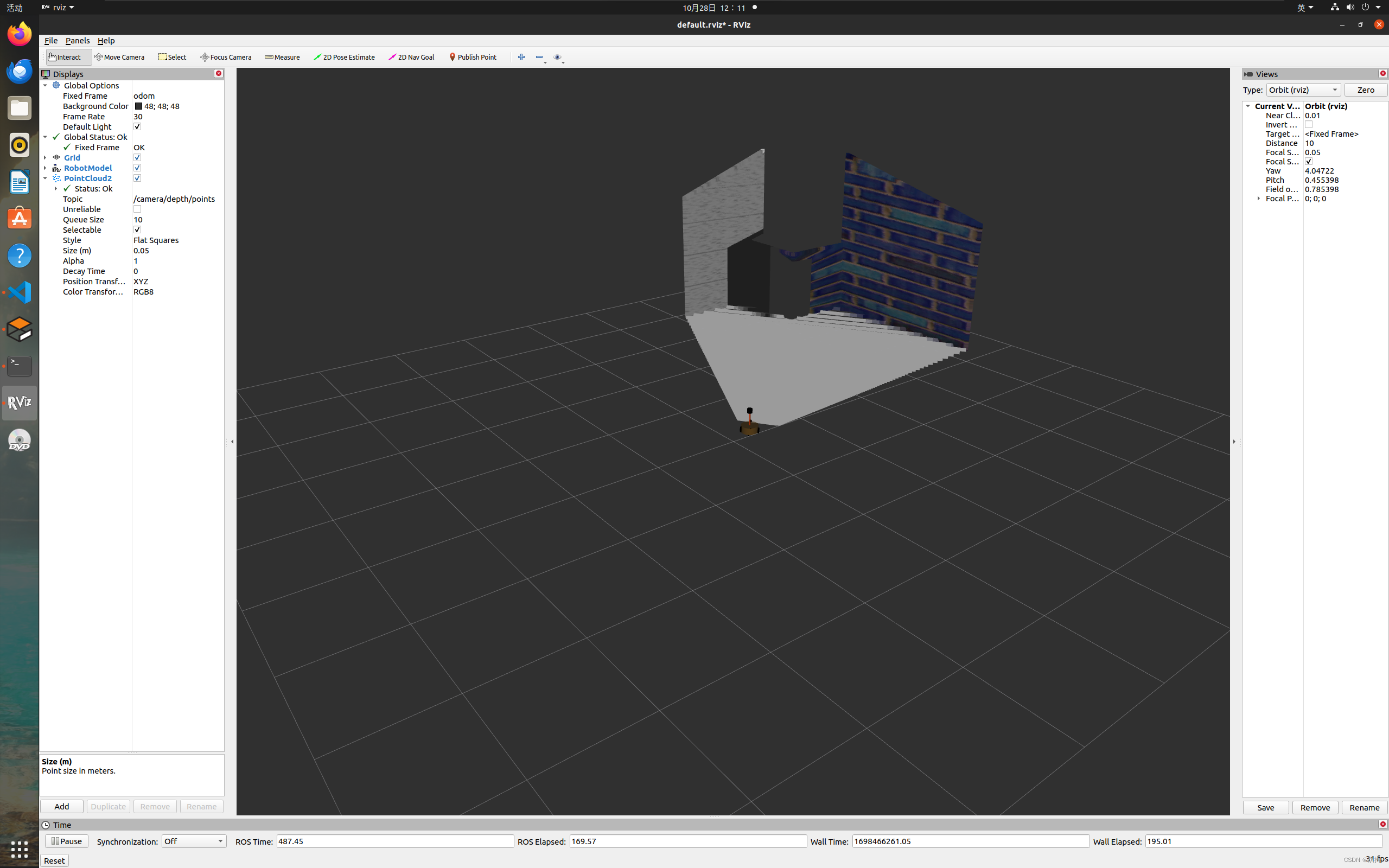
【ROS入门】雷达、摄像头及kinect信息仿真以及显示
文章结构 雷达信息仿真以及显示Gazebo仿真雷达配置雷达传感器信息xacro文件集成启动仿真环境 Rviz显示雷达数据 摄像头信息仿真以及显示Gazebo仿真摄像头新建xacro文件,配置摄像头传感器信息xacro文件集成启动仿真环境 Rviz显示摄像头数据 kinect信息仿真以及显示Ga…...
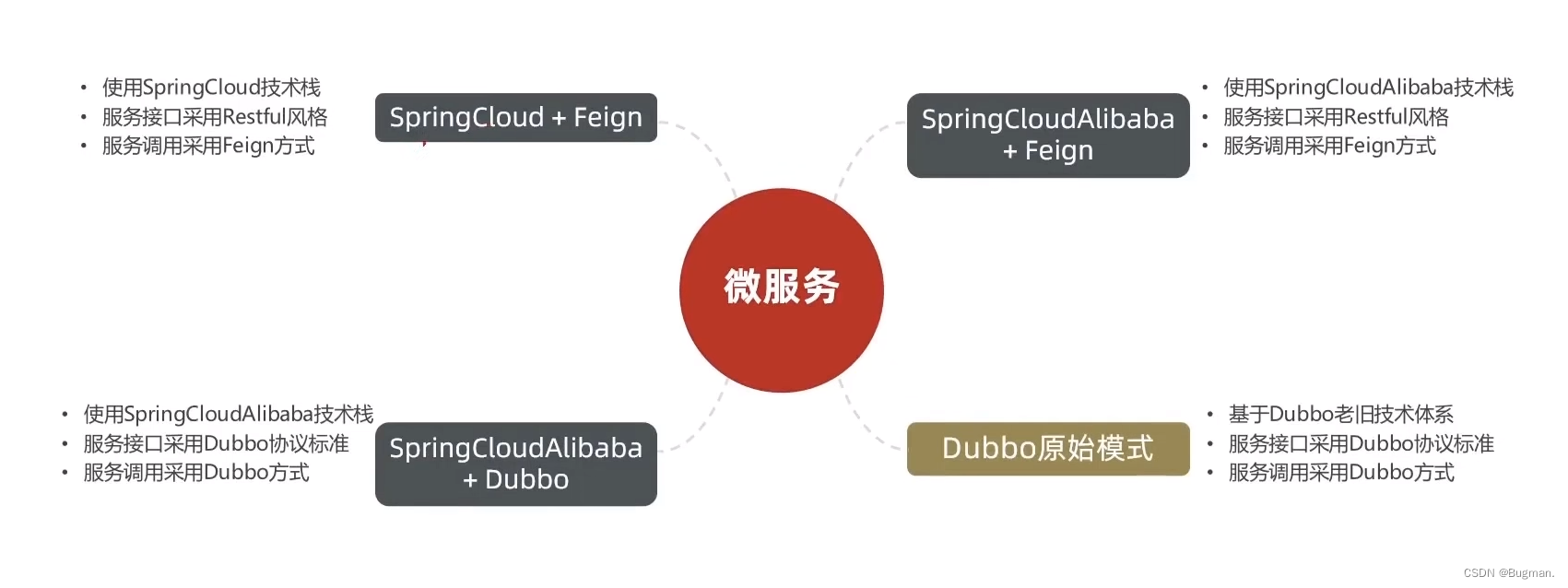
实用篇-认识微服务
一、服务架构演变 1. 单体架构 单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署 单体架构的优点: 架构简单部署成本低 单体架构的缺点: 耦合度高 2. 分布式架构 分布式架构: 根据业务功能对系…...

【产品运营】产品需求应该如何管理
产品项目在进行时经常会有一些需求需要实现,需求是产品更新迭代的动力,需求也是从用户诉求转化而来;在做需求管理时,我们需要判断一个需求的优先级等方面,对产品进行优化; 目录: 一、 为什么要…...
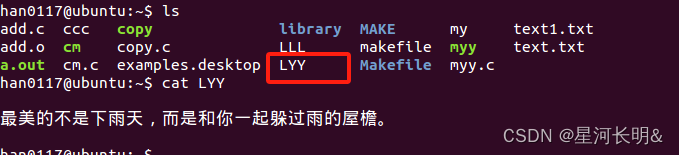
Linux 系统调用IO口,利用光标偏移实现文件复制
用系统调用IO函数实现从一个文件读取最后2KB数据并复制到另一个文件中,源文件以只读方式打开,目标文件以只写的方式打开,若目标文件不存在,可以创建并设置初始值为0664,写出相应代码,要对出错情况有一定的处…...

【原创】指针变量作为函数参数要点注意
指针变量作为函数参数要点注意(已写至笔记) 1传参指针不加*(main中函数) 2收参指针要加*(被main调用的函数) 3传参指针名可与收参指针名不同,不影响 4【问】如何看主函数中指针所指内容是否改变…...
SpringMVC Day 04 : 数据绑定
前言 SpringMVC是一个非常流行的Java Web框架,它提供了很多方便的功能和工具来帮助我们构建高效、灵活的Web应用程序。其中,数据绑定就是SpringMVC中非常重要的一部分,它可以帮助我们方便地将请求参数绑定到Java对象上,从而简化了…...

2.3.1 协程设计原理与汇编实现
1.为什么要有协程? 同步的编程方式,异步的性能。同步编程时,我们需要等待io就绪。但是在协程这里,我们使用一种机制,当io需要等待时,就切到下一个io,之后当之前的io就绪时,再切换回来…...

Ludusavi:你的游戏进度守护神,三分钟搞定跨平台存档备份
Ludusavi:你的游戏进度守护神,三分钟搞定跨平台存档备份 【免费下载链接】ludusavi Backup tool for PC game saves 项目地址: https://gitcode.com/gh_mirrors/lu/ludusavi 你是否曾在电脑崩溃后,发现数百小时的游戏进度瞬间归零&…...

无人机控制中的模糊控制:一维与二维模糊控制及其实现要点
无人机 控制方面 模糊控制 有一维模糊和二维模糊两种,文字说明资料已遗失,数学模型可以根据仿真图推导,直接运维simulink会报错,是因为没有导入模糊规则,在运行simulink之前需要在命令窗口输入workreadfis work.fis ,这…...

从按键消抖到I2C通信:深入浅出聊聊MCU上拉/下拉电阻与开漏输出的那些坑
从按键消抖到I2C通信:深入浅出聊聊MCU上拉/下拉电阻与开漏输出的那些坑 在嵌入式系统开发中,GPIO配置看似简单,却暗藏玄机。记得第一次调试I2C总线时,通信速率始终上不去,最后发现竟是上拉电阻选型不当;另一…...

从零到一:STM32手动移植FreeRTOS的工程化实践与源码解析
1. 为什么需要手动移植FreeRTOS? 第一次接触FreeRTOS时,很多人会选择用STM32CubeMX自动生成工程。这确实方便,就像用预制菜做饭,但真正想掌握RTOS内核,手动移植才是"从买菜到炒菜"的完整过程。我遇到过不少项…...

AI虚拟员工平台完整搭建教程:从源码获取到正式上线,全流程记录
温馨提示:文末有资源获取方式最近AI赛道又火了一个新方向,很多人都在讨论,但真正能用起来的没几个。技术门槛摆在那,普通用户想上手确实不容易。今天这篇教程,我把从源码部署到正式上线的完整过程整理出来,…...
)
告别WoMic:用VB-Audio Virtual Cable和TCP Socket自建无线麦克风(含参数配置避坑指南)
无线音频传输方案重构:VB-Audio与TCP Socket的工程实践 在音频处理领域,虚拟麦克风技术一直是个既实用又有趣的话题。许多开发者最初接触这一领域是通过WoMic这样的解决方案,但随着项目复杂度提升,人们往往需要更灵活、更可控的自…...

OpenClaw轻量化部署:在树莓派上运行Qwen3.5-9B微型服务
OpenClaw轻量化部署:在树莓派上运行Qwen3.5-9B微型服务 1. 为什么选择树莓派部署OpenClaw 去年夏天,我在整理个人文档时被重复的文件分类工作折磨得苦不堪言。当时我就在想:如果能有个AI助手帮我自动处理这些琐事该多好。但市面上的云端方案…...
)
Mac上PPT讲稿一键变文稿:用AppleScript自动化导出备注到TXT(附完整代码)
Mac上PPT讲稿一键变文稿:用AppleScript自动化导出备注到TXT(附完整代码) 每次做完PPT,看着密密麻麻的备注栏,你是不是也头疼怎么把这些零散的讲稿整理成连贯的文档?作为一位经常需要准备培训材料的讲师&…...

抖音视频智能管理:如何通过批量下载与自动化分类实现90%效率提升
抖音视频智能管理:如何通过批量下载与自动化分类实现90%效率提升 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 在短视频内容爆炸的时代,高效的视频采集、批量下载与系统化内容管理已…...

终极指南:OpCore Simplify如何让你零基础打造完美黑苹果系统
终极指南:OpCore Simplify如何让你零基础打造完美黑苹果系统 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的OpenCore EFI配置…...