机器学习-模型评估与选择
文章目录
- 评估方法
- 留出法
- 交叉验证
- 自助法
- 性能的衡量
- 回归问题
- 分类问题
- 查准率、查全率与F1
- ROC与AUC
在机器学习中,我们通常面临两个主要问题:欠拟合和过拟合。欠拟合指模型无法在训练数据上获得足够低的误差,通常是因为模型太简单,无法捕捉数据中的复杂关系。过拟合则是指模型在训练数据上表现得很好,但在新数据上表现不佳,通常是因为模型太复杂,学习到了训练数据中的噪声和细节,而不是真正的模式。
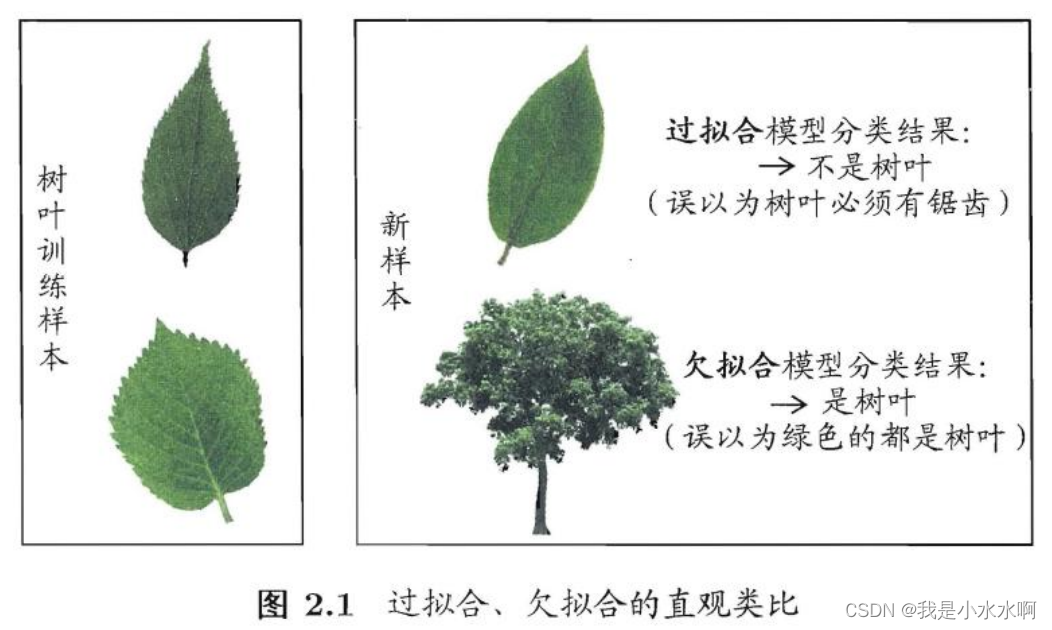
评估方法
留出法
留出法(Holdout Method)是机器学习中常用的一种评估模型性能的方法。它是将原始数据集划分为两个互斥的子集:一个用来训练模型,另一个用来测试模型性能。
留出法(Holdout Method)是机器学习中常用的一种评估模型性能的方法。它是将原始数据集划分为两个互斥的子集:一个用来训练模型,另一个用来测试模型性能。具体步骤如下:
-
数据集划分: 将原始数据集随机分为两部分,一部分用于训练模型,另一部分用于测试模型。通常,大部分数据(例如70%~80%)用于训练,剩余的部分用于测试。
-
训练模型: 在训练集上训练机器学习模型。
-
测试模型: 使用测试集评估模型的性能。可以使用各种性能指标(如准确率、精确度、召回率、F1分数等)来衡量模型在测试集上的表现。
留出法的优点包括简单易用,计算效率高。但也存在一些缺点,主要是对数据的划分可能会影响最终的评估结果。为了克服这个问题,可以多次随机划分数据集并取平均值,或者使用交叉验证等方法来更准确地评估模型性能。
在Python中,你可以使用train_test_split函数从sklearn.model_selection模块来实现留出法。以下是一个简单的留出法的Python实现示例:
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris # 示例使用鸢尾花数据集# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分数据集,将数据集的30%作为测试集,70%作为训练集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 输出训练集和测试集的大小
print("训练集大小:", len(X_train))
print("测试集大小:", len(X_test))
在上面的代码中,train_test_split函数用于将数据集划分为训练集和测试集。X是特征数据,y是标签数据。test_size参数指定了测试集的比例,这里是30%,random_state参数用于设置随机种子,保证每次运行代码时划分结果相同。X_train和y_train是训练集的特征和标签,X_test和y_test是测试集的特征和标签。
可以根据需要调整test_size的值来改变测试集的比例。
交叉验证
交叉验证(Cross-Validation)是一种用于评估模型性能的统计学技术,它在训练集上训练模型,在验证集上评估模型性能。这个过程重复多次,以便能够得到可靠的平均性能指标。交叉验证的主要目的是更准确地衡量模型的泛化能力,即模型对新数据的预测能力。
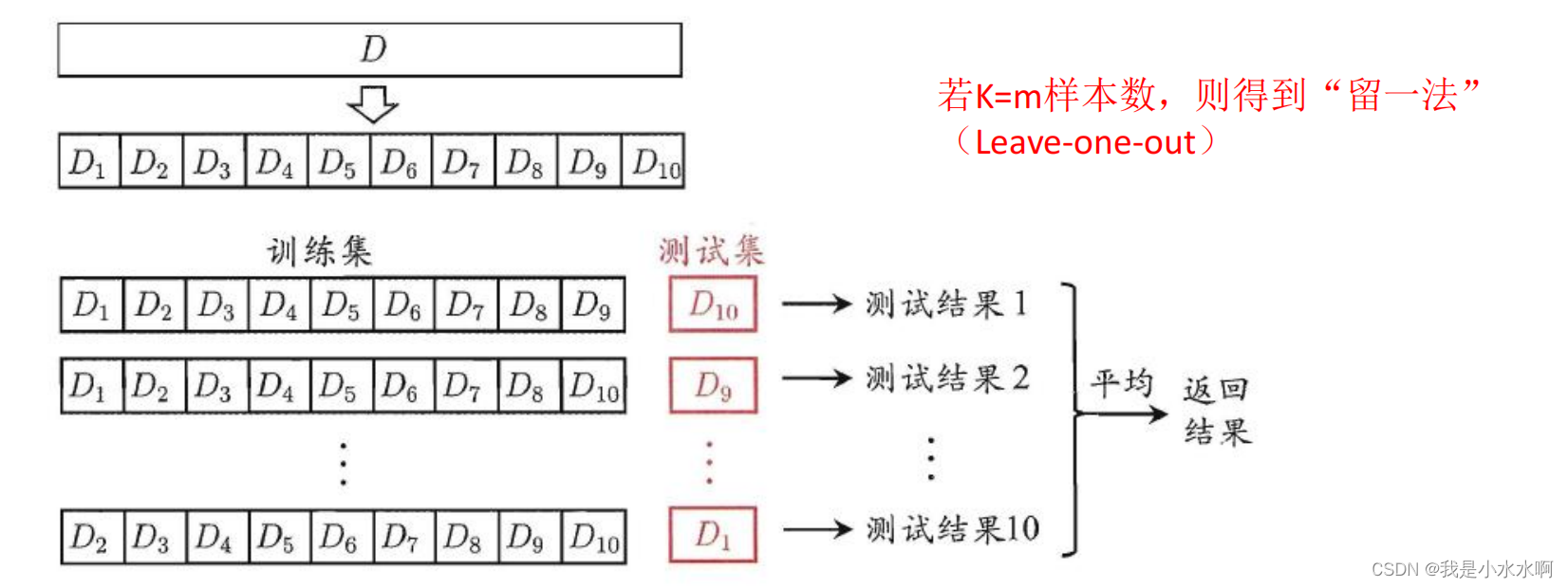
常见的交叉验证方法包括:
- k折交叉验证(k-Fold Cross-Validation): 将原始数据集随机分成k个子集,其中k-1个子集用于训练模型,剩下的一个子集用于测试模型。这个过程重复k次,每个子集都会被用作一次验证集,其余的k-1个子集被用作训练集。最终,计算k次验证的平均性能指标作为模型的性能度量。
实现:
在Python中,你可以使用cross_val_score函数从sklearn.model_selection模块来实现交叉验证。以下是一个简单的k折交叉验证的Python实现示例:
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression # 示例使用逻辑回归模型# 加载数据集
data = load_iris()
X = data.data
y = data.target# 创建模型(逻辑回归模型)
model = LogisticRegression()# 进行5折交叉验证,返回每折的评分(准确率)
scores = cross_val_score(model, X, y, cv=5)# 输出每折的评分和平均评分
print("每折评分:", scores)
print("平均评分:", scores.mean())
在上面的代码中,cross_val_score函数用于进行k折交叉验证。model是你选择的机器学习模型(这里使用了逻辑回归模型),X是特征数据,y是标签数据,cv参数指定了将数据划分为几折。在这个例子中,使用了5折交叉验证。
cross_val_score函数返回每个交叉验证折的评分,这里使用准确率(accuracy)作为评分指标。你可以根据需要选择其他性能指标,比如均方误差(mean squared error)等。最后,代码输出了每个交叉验证折的评分和平均评分。
这种方法可以帮助你更准确地评估模型的性能,因为它会在不同的数据子集上多次测试模型,得到更稳定的性能评估结果。
-
留一法交叉验证(Leave-One-Out Cross-Validation): 当k等于数据集的样本数量时,即每个样本都作为一个验证集,其余的样本作为训练集。这种方法的评估结果非常准确,但计算成本较高,通常在数据集较小的情况下使用。
-
分层k折交叉验证(Stratified k-Fold Cross-Validation): 在k折交叉验证的基础上,保持每个折中类别的分布与整个数据集中的类别分布相似,确保每个子集中都包含了各个类别的样本。分层是指将每个类别内的样本均匀地分布到不同的折中。这样可以确保每个折中包含了各个类别的样本,从而避免某个类别在某个折中缺失的情况。
分层k折交叉验证和普通的k折交叉验证(k-Fold Cross-Validation)之间的主要区别在于数据的划分方式和目的。下面是它们的区别:1. 数据的划分方式:
k折交叉验证(k-Fold Cross-Validation): 在k折交叉验证中,原始数据集被随机分成k个互斥子集,其中k-1个子集被用作训练数据,剩下的一个子集用作测试数据。这个过程重复k次,每个子集都会被用作一次测试集,其余的k-1个子集被用作训练集。分层k折交叉验证(Stratified k-Fold Cross-Validation): 分层k折交叉验证是在普通k折交叉验证的基础上加入了分层抽样。在分层k折交叉验证中,原始数据集中的样本根据类别被分成k个子集。每个子集中的类别分布要尽量保持与整个数据集中的类别分布相似。然后,k折交叉验证的过程在这些分层的子集上进行。2. 主要目的:
k折交叉验证: 主要目的是为了更好地利用有限的数据,将数据分成多个子集,多次训练和测试模型,以更准确地评估模型的性能。它的重点是减小因为单次数据集划分而引入的随机性带来的评估误差。分层k折交叉验证: 主要目的是解决在某些问题中可能存在的类别不均衡(class imbalance)问题。通过分层抽样,确保每个折中都包含了各个类别的代表性样本,从而更准确地评估模型在各个类别上的性能。它的重点是确保评估的公平性和准确性,特别适用于类别分布不均匀的问题。总结:
如果数据集中的类别分布相对均匀,普通的k折交叉验证是一个简单而有效的方法。如果数据集中的类别分布不均匀,或者你希望更准确地评估模型在各个类别上的性能,那么分层k折交叉验证是更好的选择。- 时间序列交叉验证(Time Series Cross-Validation): 适用于时间序列数据,按照时间顺序划分训练集和测试集。在每个时间段内,使用历史数据进行训练,然后在未来的时间段内测试模型性能。
在Python中,你可以使用TimeSeriesSplit类来实现时间序列交叉验证。这个类在sklearn.model_selection模块中提供。以下是一个时间序列交叉验证的Python实现示例:
from sklearn.model_selection import TimeSeriesSplit
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression # 示例使用逻辑回归模型# 加载数据集
data = load_iris()
X = data.data
y = data.target# 创建模型(逻辑回归模型)
model = LogisticRegression()# 定义时间序列交叉验证,n_splits表示将数据集划分为几个折
tscv = TimeSeriesSplit(n_splits=5)# 用时间序列交叉验证来评估模型性能
scores = []
for train_index, test_index in tscv.split(X):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]# 训练模型model.fit(X_train, y_train)# 测试模型并获取评分score = model.score(X_test, y_test)scores.append(score)# 输出每个交叉验证折的评分和平均评分
print("每折评分:", scores)
print("平均评分:", sum(scores) / len(scores))
在这个例子中,TimeSeriesSplit类的n_splits参数指定了将数据集分成几个折。split方法返回每一折的索引,然后你可以根据这些索引将数据集划分为训练集和测试集。在每一折中,模型被训练并在测试集上进行评估,得到一个分数。最后,代码输出了每个交叉验证折的评分和平均评分。
时间序列交叉验证适用于时间序列数据,它按照时间顺序划分训练集和测试集,确保模型在未来数据上的泛化性能。
自助法
自助法(Bootstrap)是一种用于估计统计量的重抽样方法。在机器学习中,自助法通常用于估计模型的性能和评估模型的泛化误差。它的基本思想是从原始数据集中有放回地抽取样本,构成一个新的训练集,然后使用这个训练集训练模型,最后在原始数据集上测试模型的性能。这个过程可以多次重复,以得到性能的分布,从而更准确地估计模型的性能。
自助法的步骤如下:
1. 有放回地抽样: 从原始数据集中有放回地抽取样本。由于是有放回地抽样,某些样本可能被抽取多次,而另一些样本可能被忽略。2. 构建训练集: 将抽取的样本构成一个新的训练集。由于是有放回地抽样,这个训练集的大小和原始数据集相同,但它包含了一些重复的样本和缺失的样本。3. 训练模型: 在新的训练集上训练机器学习模型。4. 测试模型: 在原始数据集上测试模型的性能,通常使用准确率、均方误差等指标来评估模型的性能。5. 重复步骤1-4: 重复以上步骤多次,得到多个模型性能的估计。
计算性能指标的分布: 将多次重抽样得到的性能指标进行汇总,例如计算均值、方差等,以得到性能的分布。
自助法的优点在于,它可以使用原始数据集的每个样本,不需要额外的验证集,且能够更准确地估计模型的性能。但由于有放回地抽样,自助法引入了样本之间的相关性,可能导致估计结果的方差较大。在数据量较小的情况下,自助法是一个有用的技术。
实现:
在机器学习中,结合自助法(Bootstrapping)和训练集/测试集的划分,通常用于估计模型的性能。以下是一个Python实现示例,演示如何使用自助法进行重抽样、划分训练集和测试集,并在训练集上训练模型、在测试集上评估模型性能:
from sklearn.utils import resample
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier # 示例使用随机森林分类器
from sklearn.metrics import accuracy_score
import numpy as np# 原始数据集(示例数据)
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])# 自助法抽样次数
num_samples = 1000# 划分训练集和测试集的比例
test_size = 0.2# 存储模型性能的分数
scores = []for _ in range(num_samples):# 使用自助法进行有放回的样本抽样bootstrap_sample = resample(data, replace=True)# 划分抽样后的数据为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(bootstrap_sample, bootstrap_sample, test_size=test_size)# 初始化模型(这里使用了随机森林分类器)model = RandomForestClassifier()# 在训练集上训练模型model.fit(X_train.reshape(-1, 1), y_train)# 在测试集上测试模型并计算性能得分predictions = model.predict(X_test.reshape(-1, 1))accuracy = accuracy_score(y_test, predictions)scores.append(accuracy)# 输出每个抽样的性能得分
for i, score in enumerate(scores):print(f"Sample {i + 1}: Accuracy Score: {score}")# 计算模型性能的平均值
average_score = np.mean(scores)
print(f"Average Accuracy Score: {average_score}")
在这个示例中,我们使用了自助法对原始数据进行有放回抽样,并将每个抽样后的数据划分为训练集和测试集。然后,我们使用随机森林分类器作为模型,在训练集上进行训练,然后在测试集上进行预测并计算准确率。最后,将每个抽样的准确率输出,并计算准确率的平均值。请注意,这是一个简单的示例,实际应用中需要根据问题和数据集选择合适的模型和性能指标。
性能的衡量
回归问题
回归问题:常用的性能度量是“均方误差”
均方误差(Mean Squared Error,MSE)是一种常用的用于衡量预测值与真实值之间差异的指标,它计算了预测值与真实值之间差异的平方的平均值。MSE的计算公式如下:

在计算MSE时,对每个样本的预测值与真实值之差进行平方,然后将所有样本的平方差值求和并除以样本数量 n,得到的就是均方误差。MSE越小,表示模型的预测结果与真实值之间的差异越小,模型的性能越好。
分类问题
分类问题:错误率与精度
错误率(Error Rate):
错误率表示分类错误的样本数与总样本数的比例。它衡量了分类错误的程度,计算公式如下:

精度(Accuracy):
精度表示分类正确的样本数与总样本数的比例。它衡量了分类模型的整体准确性,计算公式如下:

查准率、查全率与F1
查准率(Precision)、查全率(Recall)和F1分数(F1 Score)是在不同场景下用于评估分类模型性能的指标,它们关注于模型对正类别(Positive)的预测表现。它们的应用场景主要包括:
-
查准率(Precision):
- 定义: 查准率是指在所有被分类为正类别的样本中,有多少比例的样本实际上是正类别的。它强调的是模型预测为正类别的样本中真正是正类别的比例。
- 应用场景: 当我们关心的是确保被模型预测为正类别的样本确实是正类别时,例如在医学诊断中,确保模型预测为患有某种疾病的患者确实患有该疾病。
-
查全率(Recall):
- 定义: 查全率是指在所有实际正类别的样本中,有多少比例的样本被模型成功地预测为了正类别。它强调的是模型能够捕捉到实际正类别样本的能力。
- 应用场景: 当我们关心的是确保所有真实正类别的样本都被模型找出来时,例如在安全检查中,确保所有危险品都被检测出来。
-
F1分数(F1 Score):
- 定义: F1分数是查准率和查全率的调和平均数,它综合了查准率和查全率的信息,可以帮助我们在精度和召回率之间找到一个平衡点。
- 应用场景: 当我们需要综合考虑查准率和查全率时,避免查准率和查全率出现明显的不平衡时,例如在信息检索中,需要同时考虑搜索结果的准确性和完整性。
在实际应用中,根据问题的特性和需求,我们可以选择合适的指标进行模型性能评估,或者根据查准率和查全率的权衡选择一个F1分数较高的模型。
ROC与AUC
ROC(Receiver Operating Characteristic)曲线和AUC(Area Under the ROC Curve)是用于评估二分类模型性能的重要工具。
-
ROC曲线:
- 定义: ROC曲线是一个描述分类模型在不同阈值下真正类率(True Positive Rate,即查全率)与假正类率(False Positive Rate,即1 - 查准率)之间关系的图形。在ROC曲线上,横轴表示假正类率(FPR),纵轴表示真正类率(TPR)。
- 作用: ROC曲线能够帮助我们可视化模型在不同阈值下的性能,尤其在类别不平衡的情况下更为有用。通过观察ROC曲线,我们可以判断模型是否能在不同阈值下保持较好的性能。
-
AUC(Area Under the ROC Curve):
- 定义: AUC是ROC曲线下的面积,表示模型在所有可能阈值下的性能综合。AUC的取值范围在0.5到1之间,其中0.5表示模型性能等同于随机预测,1表示模型完美预测。
- 作用: AUC是一个单一数值,用于度量分类模型在不同阈值下的总体性能。AUC越接近1,表示模型的性能越好。它是一种常用的指标,特别在处理类别不平衡的问题时,AUC通常比准确率更能反映模型的性能。
作用总结:
- ROC曲线主要用于可视化不同阈值下模型性能的变化趋势,特别适用于类别不平衡的情况,帮助我们选择合适的阈值。
- AUC则是一个单一指标,用于综合评估模型在所有可能阈值下的性能,是一种常用的分类模型性能评估指标。
相关文章:
机器学习-模型评估与选择
文章目录 评估方法留出法交叉验证自助法 性能的衡量回归问题分类问题查准率、查全率与F1ROC与AUC 在机器学习中,我们通常面临两个主要问题:欠拟合和过拟合。欠拟合指模型无法在训练数据上获得足够低的误差,通常是因为模型太简单,无…...

分享一下办公自动化常用的思想
目录 网页获取数据需求①大体思路:PythonseleniumXpath 网页获取数据需求②大体思路:requests爬虫 批量生成需求①文件的移动、重命名②word、Excel批量生成 匹配需求 网页获取数据需求① 大体思路:PythonseleniumXpath 我们在利用Python做…...

mac vscode 使用 clangd
C 的智能提示 IntelliSense 非常不准,我们可以使用 clangd clangd 缺点就是配置繁琐,优点就是跳转和提示代码精准 开启 clangd 之后会提示你关闭 IntelliSense 1、安装插件 clangd 搜索第一个下载多的就是 2、配置 clangd 可执行程序路径 clangd 插…...
DSI及DPHY的学习
DSI的物理层PHY只能是DPHY 本节讲述的DSI是V1.02.00---2010.6.28 从DSI V1.02开始DSI支持图像数据包RGB和YCbCr的传输,在此版本之前只支持RGB传输。 本节内容与CSICDPHY相同时 请参考: CSI2与CDPHY学习-CSDN博客 同时本节会做一些与CSICDPHY的比较 …...

环形链表(C++解法)
题目 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置&#…...

星闪技术 NearLink 一种专门用于短距离数据传输的新型无线通信技术
本心、输入输出、结果 文章目录 星闪技术 NearLink 一种专门用于短距离数据传输的新型无线通信技术前言星闪技术 NearLink 的诞生背景星闪技术 NearLink 简介星闪技术 NearLink 技术是一种蓝牙技术吗星闪技术 NearLink 优势星闪技术 NearLink 应用前景弘扬爱国精神星闪技术 Nea…...

【Python机器学习】零基础掌握RandomForestRegressor集成学习
如何预测房价是不是一直困扰着大家?特别是在房地产市场波动不定的情况下,这样的预测可以说是切实需要。 要解决这个问题,一个可行的方法是利用历史房价数据和房屋的各种属性(如面积、楼层、地理位置等)进行分析。通过这些数据,可以用一个模型来预测未来房价。 假设有以…...

FreeRTOS深入教程(任务创建的深入和任务调度机制分析)
文章目录 前言一、深入理解任务的创建二、任务的调度机制1.FreeRTOS中任务调度的策略2.FreeRTOS任务调度策略实现的核心3.FreeRTOS内部链表源码解析4.如何通过就绪链表管理任务的执行顺序 三、一个任务能够运行多久1.高优先级任务可抢占低优先级任务一直运行2.相同优先级的任务…...
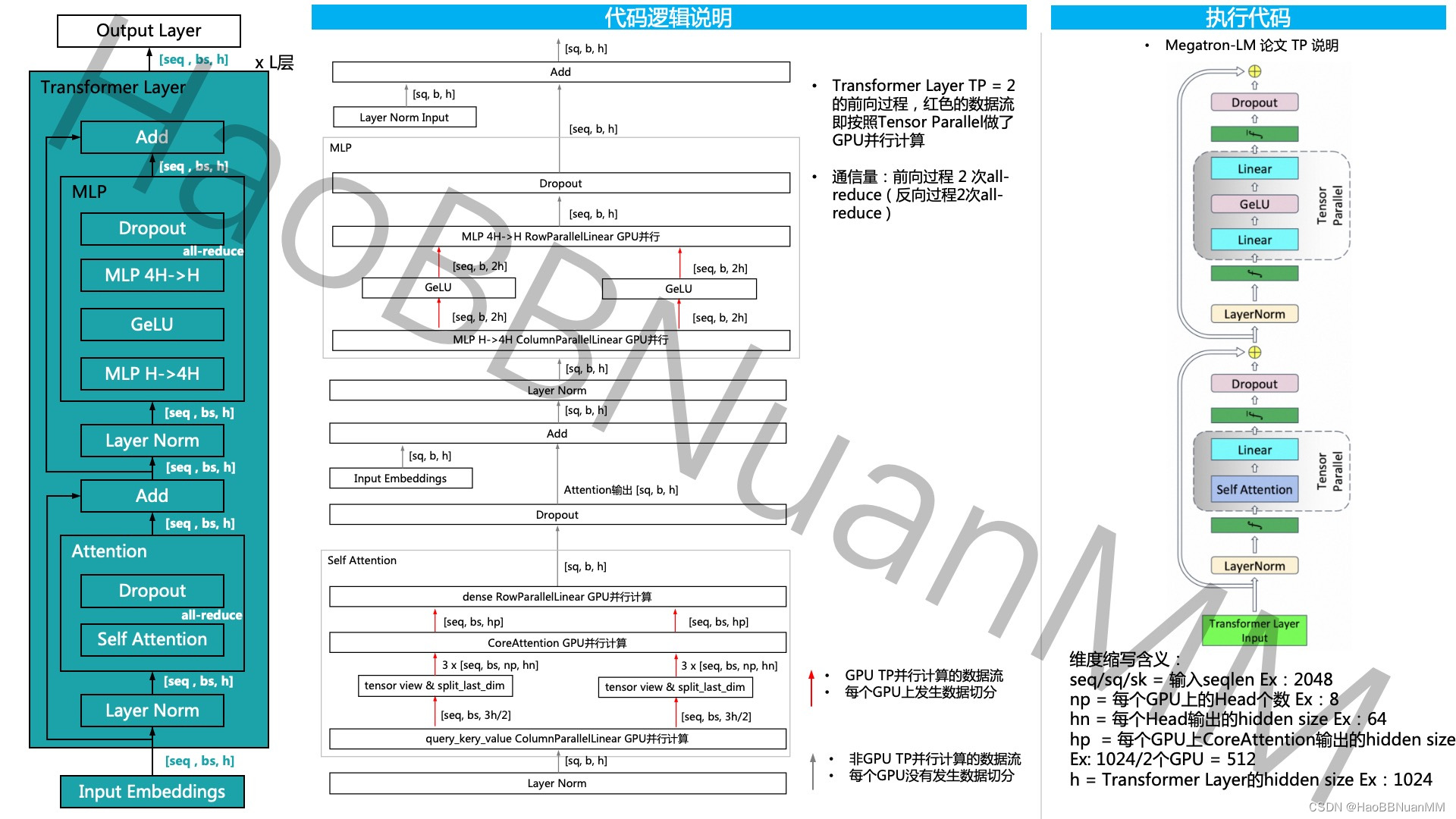
Megatron-LM GPT 源码分析(一) Tensor Parallel分析
引言 本文基于开源代码 GitHub - NVIDIA/Megatron-LM: Ongoing research training transformer models at scale ,通过GPT的模型运行示例,从三个维度 - 模型结构、代码运行、代码逻辑说明 对其源码做深入的分析。 Tensor Parallel源码分析...

分类预测 | MATLAB实现SSA-CNN-GRU麻雀算法优化卷积门控循环单元数据分类预测
分类预测 | MATLAB实现SSA-CNN-GRU麻雀算法优化卷积门控循环单元数据分类预测 目录 分类预测 | MATLAB实现SSA-CNN-GRU麻雀算法优化卷积门控循环单元数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现SSA-CNN-GRU麻雀算法优化卷积门控循环单元数据…...

婚礼的魅力
昨日有幸被邀请去当伴郎,虽然是替补,即别人鸽了,过去救急,但总归是去起作用。 婚礼的魅力,感受到了,满满的仪式感,紧凑的流程,还有不断的拍照,做视频,留下美好…...
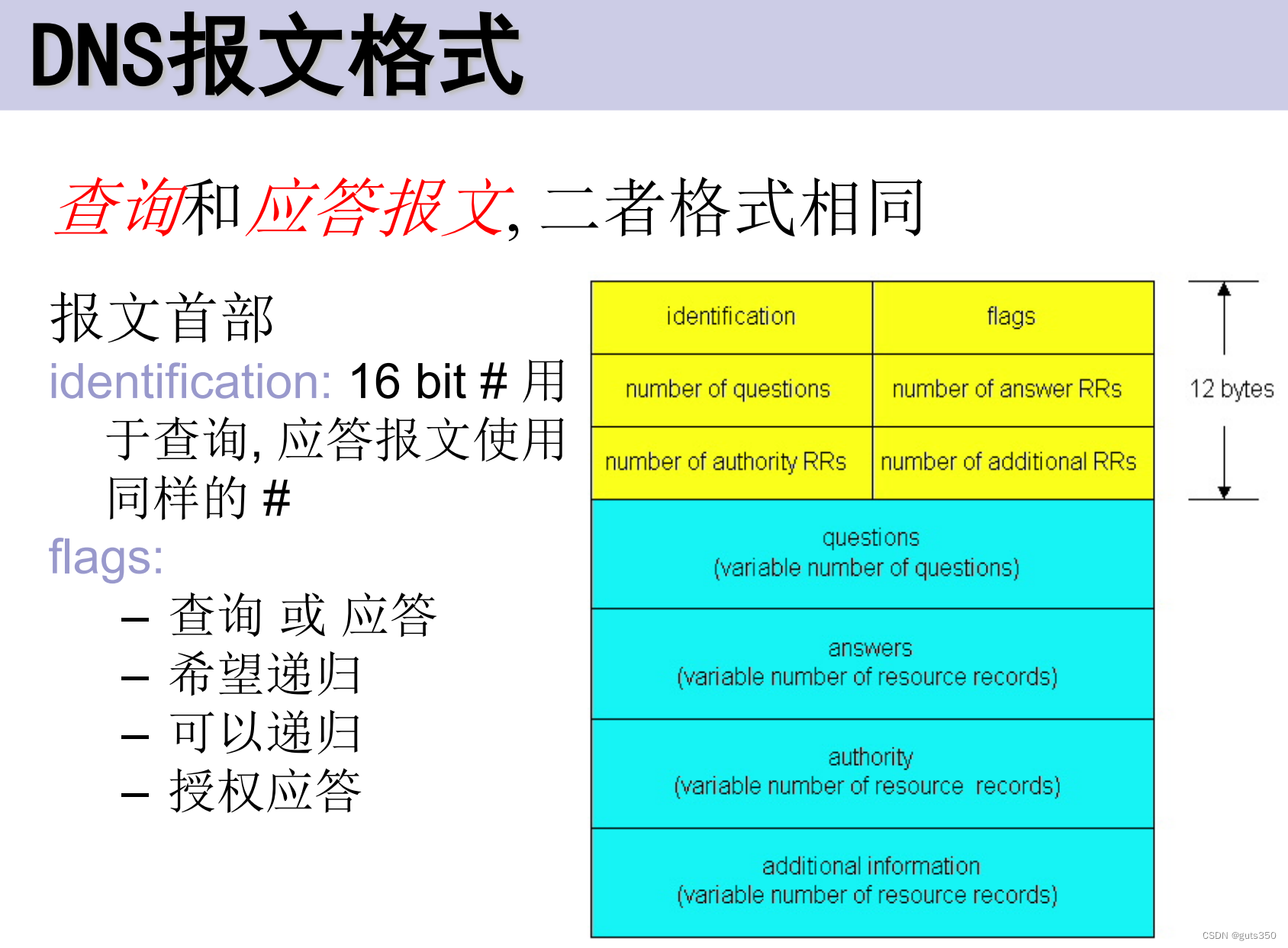
【计算机网络笔记】DNS报文格式
DNS 提供域名到主机IP地址的映射 域名服务的三大要素: 域(Domain)和域名(Domain name): 域指由地 理位置或业务类型而联系在一起的一组计算机构 成。 主机:由域名来标识。域名是由字符和(或&a…...
10月28日
...

【性能测试】初识 Jmeter 中的 BeanShell
初识 Jmeter 中的 BeanShell 1.简介1.1 应用场景1.2 BeanShell 类型 2.常用内置变量2.1 log 日志模块2.2 vars 模块2.3 props 模块2.4 prev 模块 3.常见应用场景3.1 Java 文件处理3.2 导入外部 jar 包 BeanShell 是一个小型嵌入式 Java 源代码解释器,完全兼容 Java …...

Rust实现基于Tokio的限制内存占用的channel
Rust实现基于Tokio的限制内存占用的channel 简介 本文介绍如何基于tokio的channel实现一个限制内存占用的channel。 Tokio提供了多种协程间同步的接口,用于在不同的协程中同步数据。 常用的channel有两种:bounded和unbounded,其中ubbounded的channel可…...
【C++】C++入门(上)--命名空间 输入输出 缺省参数 函数重载
目录 一 命名空间 1 命名空间的定义 2 命名空间的使用 二 C输入和输出 1 输出 2 输入 三 缺省参数 1 缺省参数概念 2 缺省参数分类 (1) 全缺省参数 (2)半缺省参数 四 函数重载 1 函数重载概念 2 分类 1 参数类型不同 2 参数个数不同 3 参数类型顺序不同 3 C为什…...
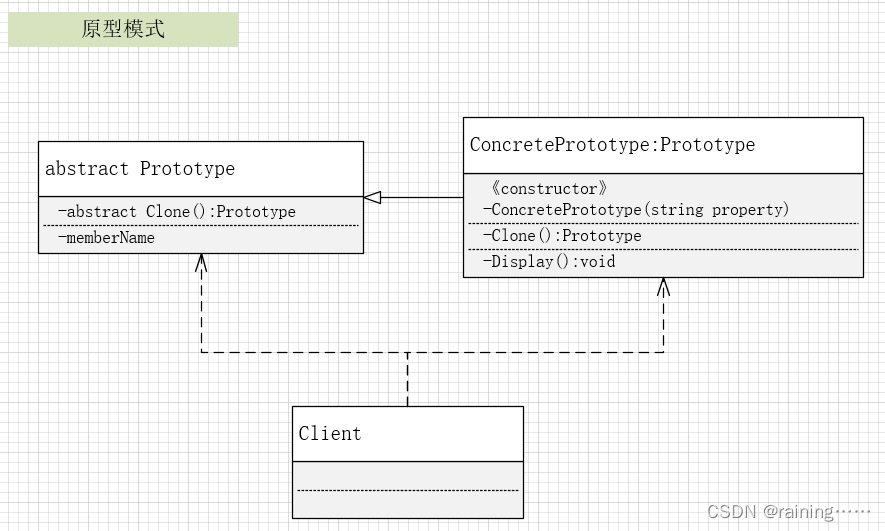
设计模式:原型模式(C#、JAVA、JavaScript、C++、Python、Go、PHP)
上一篇《访问者模式》 下一篇《享元模式》 简介: 原型模式,它是一种创建型设计模式,它允许通过复制原型对象来创建新的对象,而无需知道创建的细节。其工作原…...
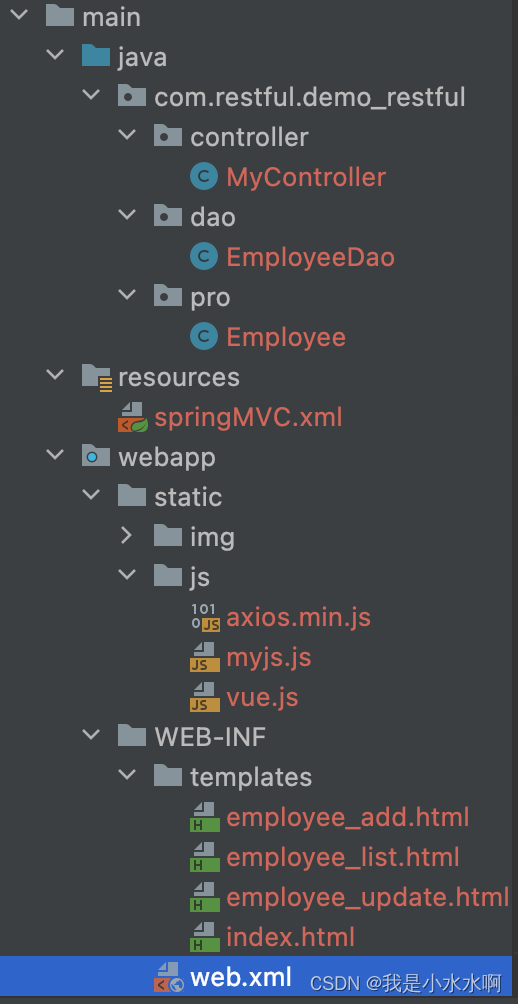
SpringMVC 资源状态转移RESTful
文章目录 1、RESTful简介a>资源b>资源的表述c>状态转移 2、RESTful的实现HiddenHttpMethodFilterRESTful案例 1、RESTful简介 REST:Representational State Transfer,表现层资源状态转移。 a>资源 资源是一种看待服务器的方式,…...

verilog vscode linux
安装 vscode 插件 插件:Verilog-HDL/SystemVerilog/Bluespec SystemVerilog 功能:.xdc .ucf .v 等代码高亮、代码格式化、语法检查(Linting)、光标放到变量上提示变量的信息等 关于其他语言的依赖工具等信息查看插件说明 代码对齐…...

Postman日常操作
一.Postman介绍 1.1第一个简单的demo 路特斯(英国汽车品牌)_百度百科 (baidu.com) 1.2 cookie 用postman测试需要登录权限的接口时,会被拦截,解决办法就是每次请求接口前,先执行登录,然后记住cookie或者to…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...