Kafka集群
Kafka集群
- 1、Kafka 概述
- 1.1消息队列背景
- 1.2类型
- 1.3Kafka 定义
- 1.4Kafka 简介
- 2、消息队列好处
- 3、消息队列的模式
- 4、Kafka 的特性
- 5、Kafka 系统架构
- 4、部署 kafka 集群
- 4.1下载安装包
- 4.2 安装 Kafka
- 4.2.1 修改配置文件
- 4.2.2 修改环境变量
- 4.2.3 配置 zookeeper启动脚本
- 4.2.4 设置开机自启
- 4.2.5分别启动 Kafka
- 4.3 Kafka 命令行操作
- 4.3.1创建topic
- 4.3.2查看当前服务器中的所有 topic
- 4.3.3 查看某个 topic 的详情
- 4.3.4发布消息
- 4.3.5消费消息
- 4.3.6 修改分区数
- 4.3.7 删除 topic
Kafka集群使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
1、Kafka 概述
1.1消息队列背景
- 主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
- 我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
1.2类型
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
1.3Kafka 定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域。
1.4Kafka 简介
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
2、消息队列好处
- 解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 - 可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 - 缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 - 灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 - 异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3、消息队列的模式
- 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
- 发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic
的消息会被所有订阅者消费。发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
4、Kafka 的特性
- 高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。 - 可扩展性
kafka 集群支持热扩展 - 持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失 - 容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败) - 高并发
支持数千个客户端同时读写
5、Kafka 系统架构
(1)Broker
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(2)Topic
可以理解为一个队列,生产者和消费者面向的都是一个 topic。
类似于数据库的表名或者 ES 的 index
物理上不同 topic 的消息分开存储
(3)Partition
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。
##Partation 数据路由规则:
1.指定了 patition,则直接使用;
2.未指定 patition 但指定key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
3.patition 和key 都未指定,使用轮询选出一个 patition。
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。
每个 partition 中的数据使用多个 segment 文件存储。
如果 topic 有多个partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition数目设为 1。
- broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个broker 存储该 topic 的一个 partition。
- 如果某 topic 有 N 个 partition,集群有 (N+M) 个
broker,那么其中有 N 个 broker 存储 topic 的一个 partition,剩下的 M 个 broker不存储该 topic 的 partition 数据。- 如果某 topic 有 N 个 partition,集群中 broker 数目少于N 个,那么一个 broker 存储该 topic 的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
分区的原因
- 方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
- 可以提高并发,因为可以以Partition为单位读写了。
(4)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
(5)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
(6)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
(7)生产者
生产者即数据的发布者,该角色将消息 push 发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
(8)Consumer
消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据。
(9)Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响。
(10)offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终还是会被删除的,默认生命周期为 1 周(7*24小时)。
(11)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
也就是说,zookeeper的作用就是,生产者push数据到kafka集群,就必须要找到kafka集群的节点在哪里,这些都是通过zookeeper去寻找的。消费者消费哪一条数据,也需要zookeeper的支持,从zookeeper获得offset,offset记录上一次消费的数据消费到哪里,这样就可以接着下一条数据进行消费。
4、部署 kafka 集群
4.1下载安装包
官方下载地址:Apache Kafka
cd /opt
rz -E //将安装包导入
4.2 安装 Kafka
[root opt]#
[root opt]# tar xf kafka_2.13-2.8.2.tgz
[root opt]#
[root opt]# ls
kafka_2.13-2.8.2 kafka_2.13-2.8.2.tgz rh
[root opt]#
[root opt]# mv kafka_2.13-2.8.2 /usr/local/kafka
[root opt]#
4.2.1 修改配置文件
[root opt]# cd /usr/local/kafka/config/
[root config]#
[root config]# cp server.properties{,.bak}
[root config]#
[root config]# vim server.properties
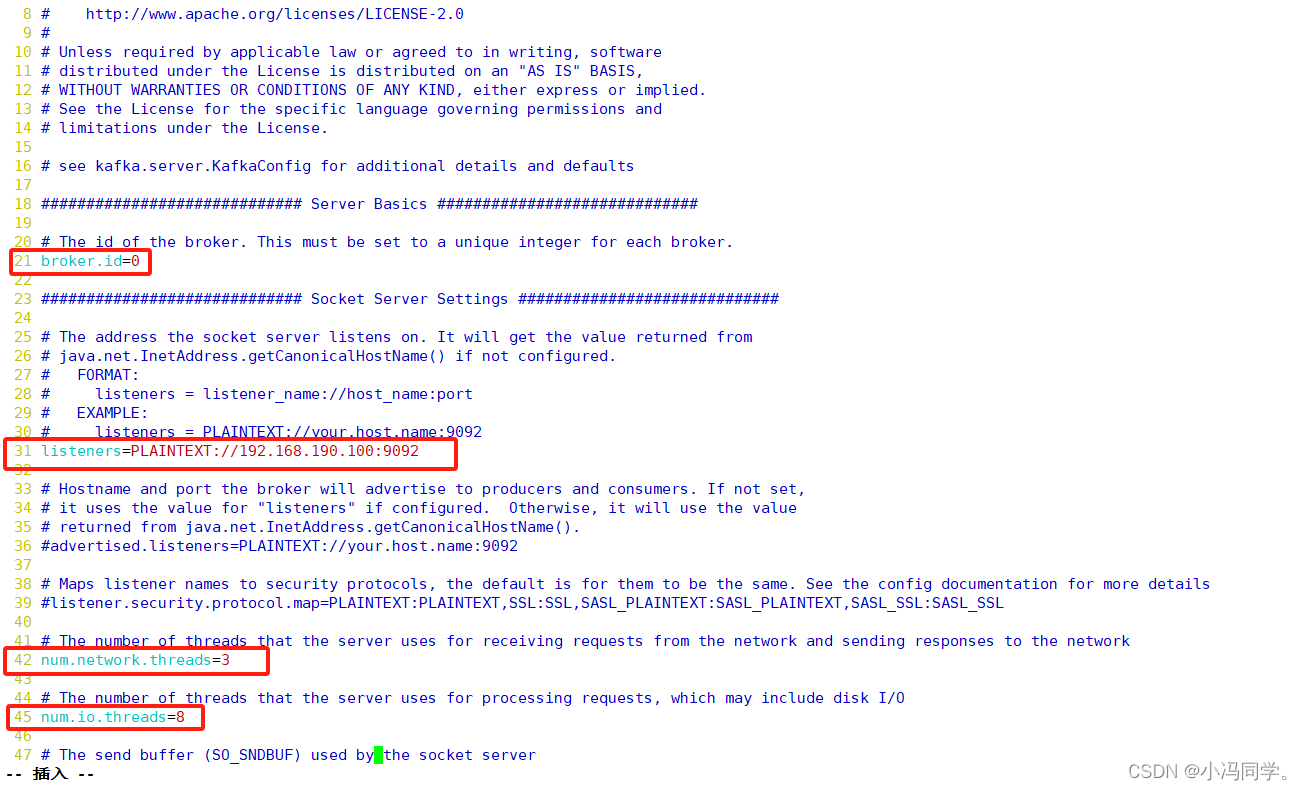
broker.id=0 //21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.30.107:9092 //31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
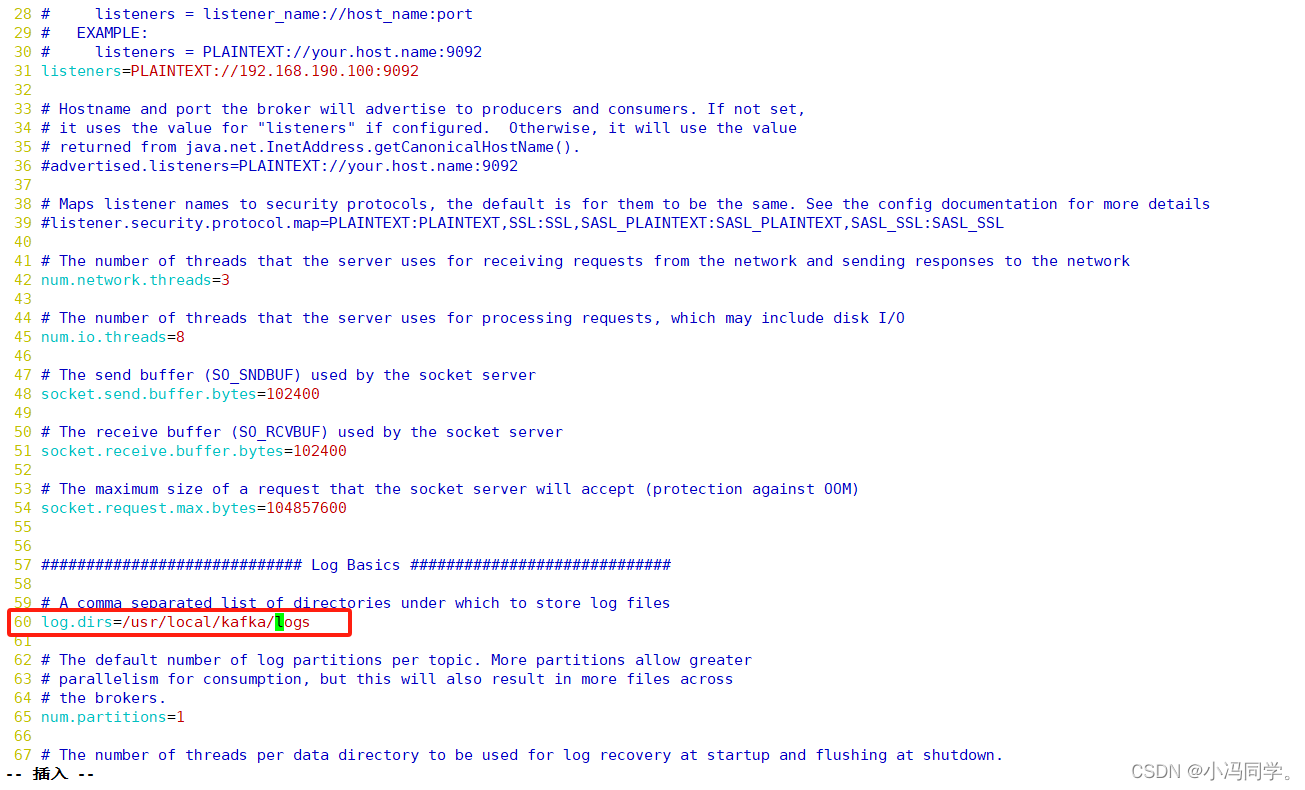
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.30.107:2181,192.168.30.108:2181,192.168.30.109:2181 //123行,配置连接Zookeeper集群地址

4.2.2 修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka //在末尾加上以下两行配置
export PATH=$PATH:$KAFKA_HOME/bin
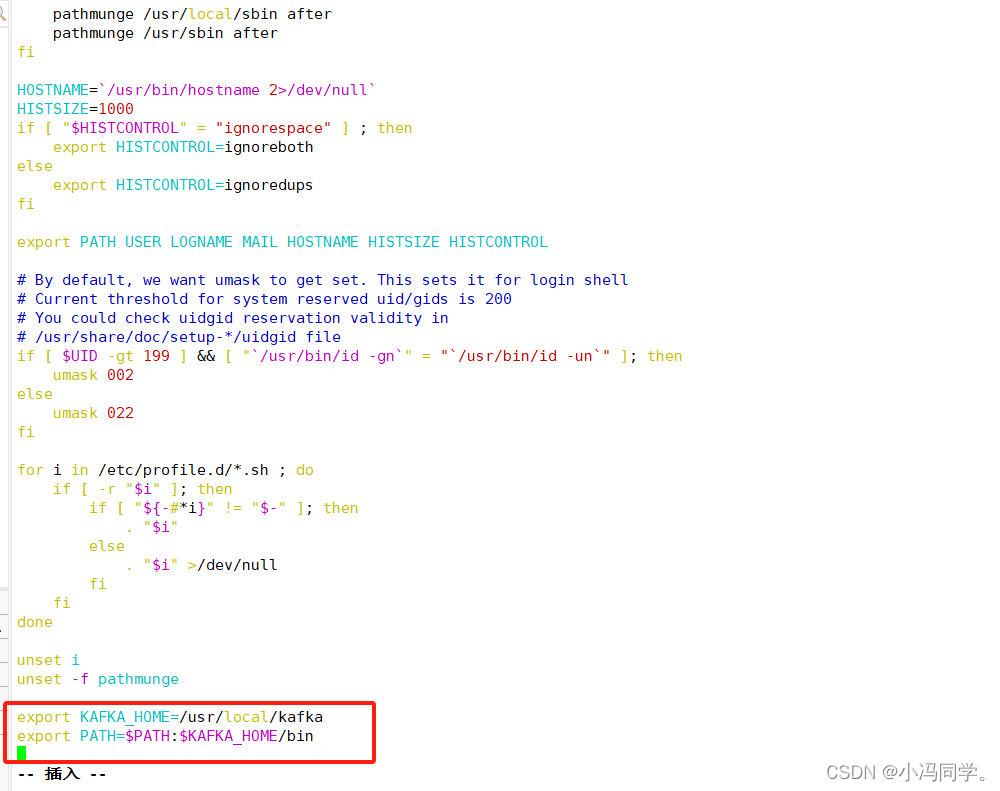
source /etc/profile
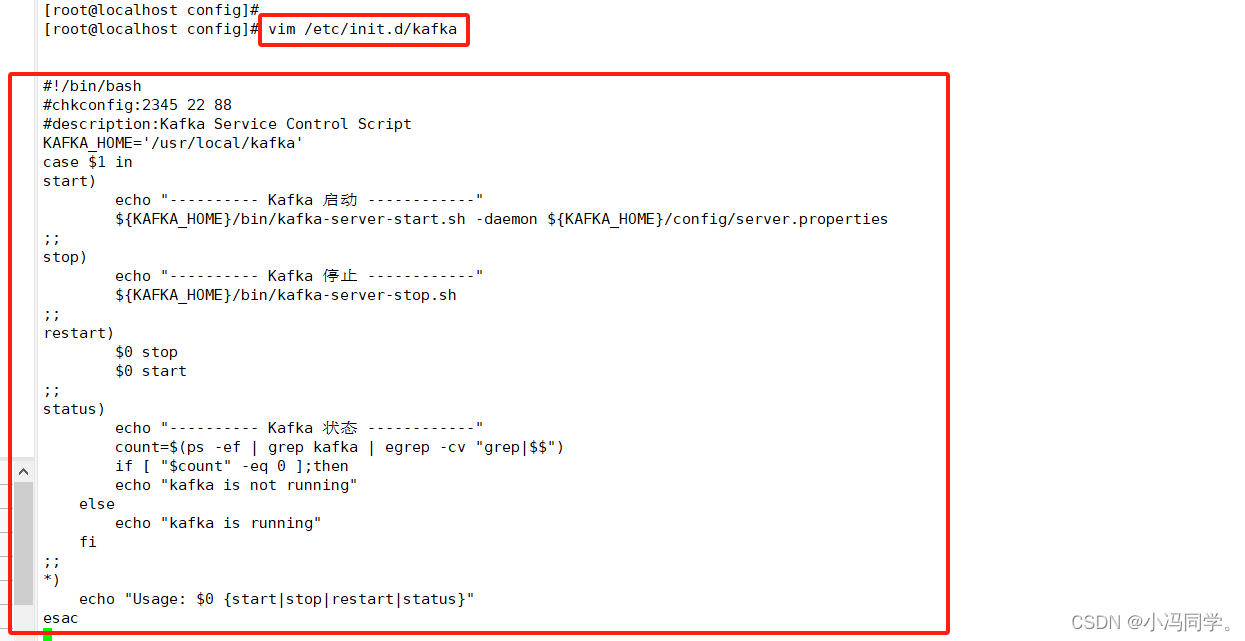
4.2.3 配置 zookeeper启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac
4.2.4 设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka

4.2.5分别启动 Kafka
service kafka start

4.3 Kafka 命令行操作
4.3.1创建topic
- -zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
- -replication-factor:定义分区副本数,1 代表单副本,建议为 2
- -partitions:定义分区数
- -topic:定义 topic 名称
kafka-topics.sh --create --zookeeper 192.168.190.100:2181,192.168.190.200:2181,192.168.190.101:2181 --replication-factor 2 --partitions 3 --topic test
4.3.2查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.190.100:2181,192.168.190.200:2181,192.168.190.101:2181
4.3.3 查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.190.100:2181,192.168.190.200:2181,192.168.190.101:2181
4.3.4发布消息
kafka-console-producer.sh --broker-list 192.168.190.100:2181,192.168.190.200:2181,192.168.190.101:2181 --topic test
4.3.5消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.190.100:2181,192.168.190.200:2181,192.168.190.101:2181 --topic test --from-beginning
//--from-beginning:会把主题中以往所有的数据都读取出来
4.3.6 修改分区数
kafka-console-consumer.sh --bootstrap-server 192.168.190.100:2181,192.168.190.200:2181,192.168.190.101:2181 --topic test --from-beginning
4.3.7 删除 topic
kafka-topics.sh --delete --zookeeper 192.168.190.100:2181,192.168.190.200:2181,192.168.190.101:2181 --topic test
相关文章:
Kafka集群
Kafka集群 1、Kafka 概述1.1消息队列背景1.2类型1.3Kafka 定义1.4Kafka 简介 2、消息队列好处3、消息队列的模式4、Kafka 的特性5、Kafka 系统架构4、部署 kafka 集群4.1下载安装包4.2 安装 Kafka4.2.1 修改配置文件4.2.2 修改环境变量4.2.3 配置 zookeeper启动脚本4.2.4 设置…...
国腾GM8775C完全替代CS5518 MIPIDSI转2 PORT LVDS
集睿致远CS5518描述: CS5518是一款MIPI DSI输入、LVDS输出转换芯片。MIPI DSI 支持多达4个局域网,每条通道以最 大 1Gbps 的速度运行。LVDS支持18位或24位像素,25Mhz至154Mhz,采用VESA或JEIDA格 式。它只能使用单个1.8v电源&am…...

搜索与图论:匈牙利算法
将所有点分成两个集合,使得所有边只出现在集合之间,就是二分图 二分图:一定不含有奇数个点数的环;可能包含长度为偶数的环, 不一定是连通图 二分图的最大匹配: #include<iostream> #include<cs…...

明星艺人类的百度百科怎么创建 ?
明星艺人们的知名度对于其事业的成功至关重要,而作为国内最大的中文百科全书网站,百度百科成为了人们获取信息的重要来源。一线明星当然百科不用自己操心,平台和网友就给维护了,但是刚刚走红的明星艺人应提早布局百科词条…...

类EMD的“信号分解方法”及MATLAB实现(第八篇)——离散小波变换DWT(小波分解)
在之前的系列文章里,我们介绍了EEMD、CEEMD、CEEMDAN、VMD、ICEEMDAN、LMD、EWT,我们继续补完该系列。 今天要讲到的是小波分解,通常也就是指离散小波变换(Discrete Wavelet Transform, DWT)。在网上有一些介绍该方法…...
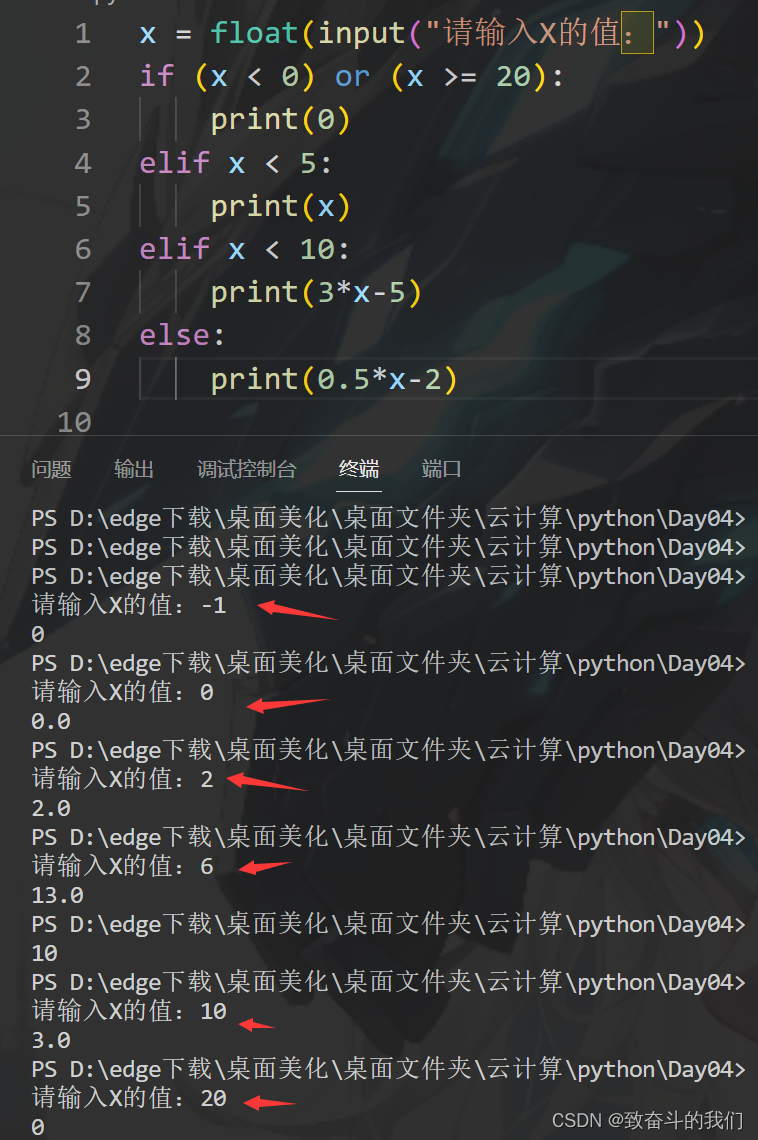
python随手小练10(南农作业题)
题目1: 编写程序,输出1~1000之间所有能被4整除,但是不能被5整除的数 具体操作: for i in range(1,1000): #循环遍历1~999,因为range是左闭右开if (i % 4 0) and (i % 5 ! 0) :print(i) 结果展示: 题目2&…...

How to install mongodb-7.0 as systemd service with podman
How to install mongodb-7.0 as systemd service with podman 1、安装1.1、创建卷1.2、配置文件1.3、创建容器1.4、服务管理1.5、容器管理 2、客户端管理 1、安装 1.1、创建卷 配置卷 podman volume create --label typemongo-7.0 --label envdev mongo-7.0-conf数据卷 pod…...

一文彻底理解python浅拷贝和深拷贝
目录 一、必备知识二、基本概念三、列表,元组,集合,字符串,字典浅拷贝3.1 列表3.2 元组3.3 集合3.4 字符串3.5 字典3.6 特别注意浅拷贝总结 四、列表,元组,集合,字符串,字典深拷贝 一…...

什么是软件的生命周期?全方位解释软件的生命周期
软件的生命周期 软件生命周期是指从软件产品的设想开始到软件不再使用而结束的时间。 如果把软件看成是有生命的事 物,那么软件的生命周期可以分成6个阶段,即需求分析、计划、设计、编码、测试、运行维护 需求分析阶段: 分析需求的可行性&…...

网络安全—小白自学
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...

List 3.5 详解原码、反码、补码
前言 欢迎来到我的博客,我是雨空集(全网同名),无论你是无意中发现我,还是有意搜索而来,我都感到荣幸。这里是一个分享知识、交流想法的平台,我希望我的博客能给你带来帮助和启发。如果你喜欢我…...

数据清洗与规范化详解
数据处理流程,也称数据处理管道,是将原始数据转化为有意义的信息和知识的一系列操作步骤。它包括数据采集、清洗、转换、分析和可视化等环节,旨在提供有用的见解和决策支持。在数据可视化中数据处理是可视化展示前非常重要的一步,…...

Ansible playbook的block
环境 控制节点:Ubuntu 22.04Ansible 2.10.8管理节点:CentOS 8 block 顾名思义,通过block可以把task按逻辑划分到不同的“块”里面,实现“块操作”。此外,block还提供了错误处理功能。 task分组 下面的例子&#x…...

Jupyter Notebook还有魔术命令?太好使了
在Jupyter Notebooks中,Magic commands(以下简称魔术命令)是一组便捷的功能,旨在解决数据分析中的一些常见问题,可以使用%lsmagic 命令查看所有可用的魔术命令 插播,更多文字总结指南实用工具科技前沿动态…...

DailyRecord-231029
iOS&前端: 数组 iOS/Xcode异常:对象数组NSMutableArray添加元素-addObject,但count方法仍然返回0? - 周文 - 博客园(需要初始化) [__NSArrayI addObject:]: unrecognized selector sent to instance (检查addObj…...

雨云虚拟主机使用教程WordPress博客网站搭建教程
雨云虚拟主机(RVH)使用教程与宝塔面板搭建WordPress博客网站的教程,本文会讲解用宝塔面板一键部署以及手动安装两种方式来搭建WordPress博客,选其中一种方式即可。 WordPress WordPress是使用PHP语言开发的博客平台,用户可以在支持PHP和MyS…...

【SPSS】基于RFM+Kmeans聚类的客户分群分析(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
回溯法(1)--装载问题和0-1背包
一、回溯法 回溯法采用DFS+剪枝的方式,通过剪枝删掉不满足条件的树,提高本身作为穷举搜索的效率。 回溯法一般有子集树和排列树两种方式,下面的装载问题和01背包问题属于子集树的范畴。 解空间类型: 子集树࿱…...
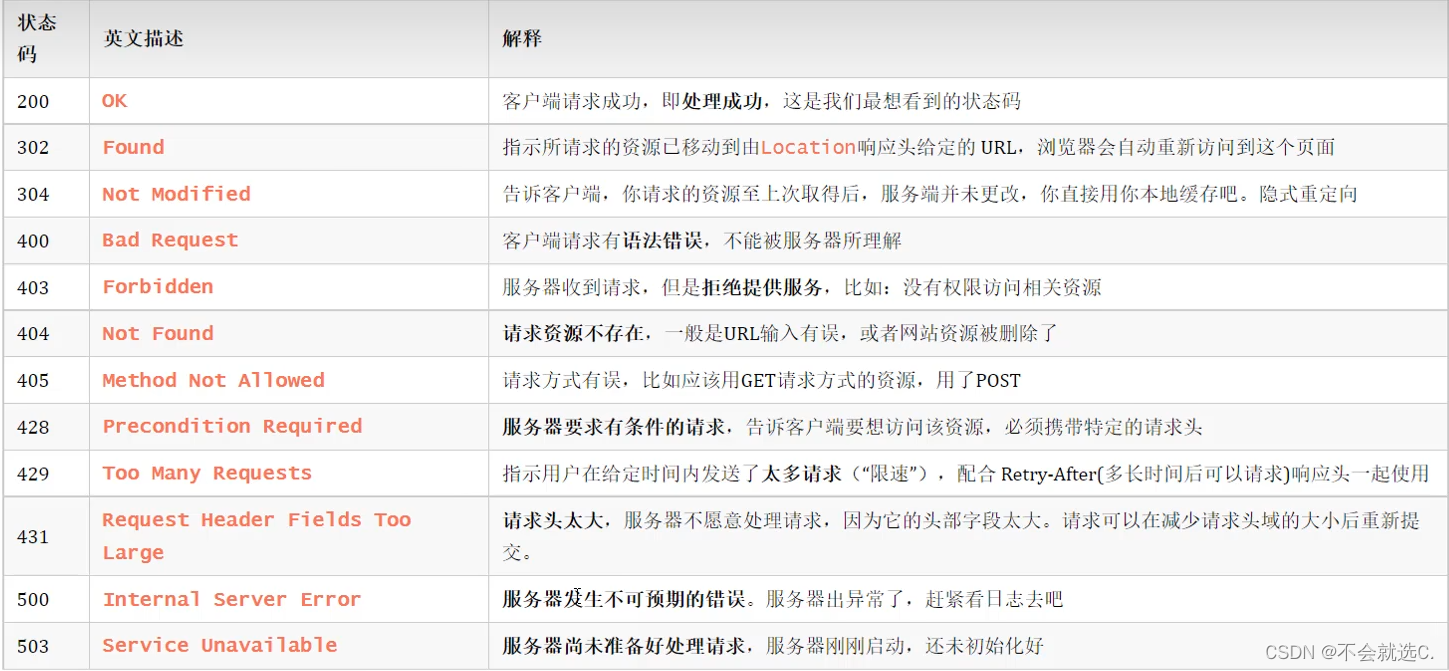
[javaweb]——HTTP请求与响应协议,常见响应状态码(如:404)
🌈键盘敲烂,年薪30万🌈 目录 HTTP概述 📕概念:Hyper Text Transfer Protocol,超文本传输协议,规定了浏览器和服务器之间数据传输的规则。 📕特点: 📕插播…...

Java面向对象(进阶)-- 拼电商客户管理系统(康师傅)
文章目录 一、目标二、需求说明(1)主菜单(2)添加客户(3)修改客户(4)删除客户(5)客户列表 三、软件设计结构四、类的设计(1)Customer类…...

如何在浏览器中直接查看SQLite数据库文件?WebAssembly技术带来的零安装解决方案
如何在浏览器中直接查看SQLite数据库文件?WebAssembly技术带来的零安装解决方案 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer 你是否曾经需要快速查看一个SQLite数据库文件ÿ…...

python的pyd本质:就是Windows平台下的DLL动态链接库
一、 拆解:Python 库的真实生态与 .pyd / .so 的底层逻辑1. Python 真的有百万个第三方 PIP 库吗?不准确。 截至2026年,PyPI(Python Package Index)官方注册的开源项目总量大约在 50万到60万个 之间。虽然达不到“百万…...

不是碳基,也不是硅基!你好,我是金蝶灵基,企业AI原生操作系统!
AI是危还是机?自年初小龙虾“爆炸”以来,很多企业服务巨头都或主动或被动地陷入了深深地思考:连一直仰望并追捧的偶像——Salesforce都开始快速变革,我们能无动于衷吗?这半年以来,中国软件网注意到…...
)
为什么你的Agent总在真实场景中“失语”?揭秘LLM调用链中被忽略的2个关键中间态(Meta Llama-3.1内部调试日志首度公开)
更多请点击: https://kaifayun.com 第一章:AI Agent智能体未来趋势 AI Agent正从单任务执行者演进为具备目标分解、工具调用、环境感知与持续反思能力的自主协作体。其发展不再局限于模型规模扩张,而转向系统级架构创新——包括记忆机制标准…...

520遇见AI:猛犸AI智能体训练增长营第15期深圳圆满落幕
一束玫瑰,一场关于未来的对话。 2026年5月20日,猛犸AI智能体训练增长营第15期在深圳南山正式开课。课程伊始,GEO理论奠基人罗小军为每一位到场的100余名学员送上了一束玫瑰花——这一天恰逢520,这束花,是猛犸AI送给每一…...

测试工程师必学的接口自动化测试框架:从0到1搭建实战
在互联网产品迭代速度不断加快的今天,接口测试已经成为软件测试流程中不可或缺的核心环节。相较于UI自动化测试,接口测试具有稳定性高、响应快、落地成本低的优势,已经成为企业保障版本质量、缩短测试周期的核心手段。对于测试工程师而言&…...

源代码论文分享|基于 Spring Boot 的校园商铺管理系统!
很多同学选毕业设计时都会纠结:题目太简单,怕老师觉得没含金量;题目太复杂,又怕自己做不完。 其实像校园商铺管理系统这种项目,就挺适合拿来做毕设或课程设计。它有真实场景,功能也能展开,技术…...

毕业论文难写?2026年AI论文平台排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作软件排行榜来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!Ἴ…...

【Elasticsearch从入门到精通】第10篇:Elasticsearch REST API最佳实践——Content-Type、模糊性与访问控制
上一篇【第09篇】Elasticsearch API规范详解——多索引、日期数学与通用选项 下一篇【第11篇】Elasticsearch索引API详解——索引创建、删除与别名管理(明日更新,敬请期待) 摘要 掌握Elasticsearch REST API的使用规范不仅能避免常见错误&am…...

Playwright Python3.7+安装失败根因与一次成功配置指南
1. 为什么Playwright在Python3.7环境下总“装不上”?——这不是你的pip问题,是环境认知偏差 你刚在新配的Mac M2上敲下 pip install playwright ,终端卡在 Building wheel for playwright... 十分钟不动;或者Windows上反复提示…...