深入了解 Elasticsearch 8.1 中的 Script 使用
一、什么是 Elasticsearch Script?
Elasticsearch 中的 Script 是一种灵活的方式,允许用户在查询、聚合和更新文档时执行自定义的脚本。这些脚本可以用来动态计算字段值、修改查询行为、执行复杂的条件逻辑等等。
二、支持的脚本语言有哪些
支持多种脚本语言,包括 Painless、Expression、Mustache、Java等,其中默认的是Painless。

三、Painless 脚本的使用
Painless 是一种专为 Elasticsearch 设计的脚本语言,具有安全、快速、简单的特点,使其在 Elasticsearch 中非常方便入门。
-
安全性: Painless 被设计为一种安全的脚本语言。它采取了一系列的安全措施,如禁止无限循环、禁止访问 Java 类库中的危险类等,以减轻潜在的安全风险。
-
高性能: Painless 是为高性能而设计的,特别是在 Elasticsearch 中。它经过了优化,可以在大规模数据集上快速执行。
-
易学易用: Painless 实现了任何具有基本编码经验的人都自然熟悉的语法。Painless 使用 Java 语法的子集,并进行了一些额外的改进,以增强可读性并删除样板文件。
-
无需编译: Painless 脚本不需要预先编译。它可以在运行时解释,所以我们可以动态调整脚本而无需重新编译整个应用程序。
-
支持参数化: Painless 允许在脚本中使用参数,这可以使脚本更通用,适用于多种情况。参数化脚本可以接受外部传递的值,从而在不修改脚本的情况下改变其行为。
-
支持多种数据类型: Painless 支持多种数据类型,包括数字、字符串、日期、布尔值等。
-
集成性: Painless 被紧密集成到 Java 中,可以用于查询、聚合、脚本字段、脚本排序等各种用例。
3.1、编写我们的第一个脚本
使用的
Elasticsearch版本为8.1,历史文章除非特别说明,最近更文的ES版本都为Elasticsearch的8.1版本
脚本的组成有三个参数,只要是在 Elasticsearch API 支持脚本的地方,都可以使用如下三个参数来使用脚本。
"script": {"lang": "...","source" | "id": "...","params": { ... }}
-
lang:执行脚本语言类型,默认painless -
source,id:脚本的源码本身,或者提前存储的脚本ID -
params:作为变量传递给脚本的参数
下面我们将通过实际的例子来进行说明
3.2、在检索中使用脚本
-
首先我们先往索引中插入一篇文档
PUT zfc-doc-000007/_doc/1 {"sum": 5,"message":"test painless" } -
使用脚本实现
sum的值乘2,此处使用变量multiplier,在脚本的参数中指定参数值为2,其中doc['sum'].value * params['multiplier']的意思就是获取文档中sum的值并乘以脚本中multiplier的值GET zfc-doc-000007/_search {"script_fields": {"my_doubled_field": {"script": { "source": "doc['sum'].value * params['multiplier']", "params": {"multiplier": 2}}}} } -
在获取脚本的参数中的变量值除了使用
params['参数名']这种方式之外,还可以使用params.get('multiplier')方法获取GET zfc-doc-000007/_search {"script_fields": {"my_doubled_field": {"script": {"lang": "painless","source": "doc['sum'].value * params.get('multiplier');","params": {"multiplier": 2}}}} }
上面我们是在检索请求中使用的脚本字段来使用的脚本,下面我们先内置一个脚本,通过使用脚本ID来使用内置的脚本
3.3、使用内置的脚本
-
创建一个脚本
calculate-score,它可以使用Math.log(_score * 2) + params['my_modifier']修改分数值POST _scripts/calculate-score {"script": {"lang": "painless","source": "Math.log(_score * 2) + params['my_modifier']"} } -
创建完成的脚本我们可以使用
_scriptAPI查看脚本的内容GET _scripts/calculate-score -
在检索中只需要如下指定
脚本的ID即可进行检索时使用GET zfc-doc-000007/_search {"query": {"script_score": {"query": {"match": {"message": "painless"}},"script": {"id": "calculate-score", "params": {"my_modifier": 2}}}} } -
如果想删除脚本只需要调用
DELETE即可DELETE _scripts/calculate-score
下面我们再来演示一下如何使用脚本更新文档中的内容
3.4、使用脚本操作文档
-
先添加一个文档来进行测试
PUT zfc-doc-000007/_doc/1 {"counter" : 1,"tags" : ["red"] } -
使用脚本对文档中的
counter的值与脚本中的count值进行相加POST zfc-doc-000007/_update/1 {"script" : {"source": "ctx._source.counter += params.count","lang": "painless","params" : {"count" : 4}} } -
我们还可以对文档中的数组类型的
tags字段进行增加子对象,比如增加一个bluePOST zfc-doc-000007/_update/1 {"script": {"source": "ctx._source.tags.add(params['tag'])","lang": "painless","params": {"tag": "blue"}} } -
使用脚本对文档中的
tags的值进行删除,条件就是当tag的值与脚本中的值相等时删除。如下为当tags的值为blue时,删除bluePOST zfc-doc-000007/_update/1 {"script": {"source": "if (ctx._source.tags.contains(params['tag'])) { ctx._source.tags.remove(ctx._source.tags.indexOf(params['tag'])) }","lang": "painless","params": {"tag": "blue"}} } -
上面只是对已有字段的增加删除修改,下面还可以使用脚本进行新字段的增加,比如增加一个字段
new_field,值是value_of_new_fieldPOST zfc-doc-000007/_update/1 {"script" : "ctx._source.new_field = 'value_of_new_field'" } -
上面是字段的增加,下面就是字段的移除
POST zfc-doc-000007/_update/1 {"script" : "ctx._source.remove('new_field')" } -
除了对字段的删除,数组对象内部值的删除,还可以对文档进行删除。如下,当
tags里面包含blue时,删除当前文档POST zfc-doc-000007/_update/1 {"script": {"source": "if (ctx._source.tags.contains(params['tag'])) { ctx.op = 'delete' } else { ctx.op = 'none' }","lang": "painless","params": {"tag": "blue"}} }
3.5、使用脚本解析日志信息
所谓的解析字符串,只是一组固定格式的字符串,提前使用变量的形式编译,在插入文档时,通过脚本进行解析保存,方便后面的检索等请求
假如我们有如下数据
"message" : "247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"
那么我们可以使用如下变量的形式解析该字符串
%{clientip} %{ident} %{auth} [%{@timestamp}] \"%{verb} %{request} HTTP/%{httpversion}\" %{status} %{size}
下面我们使用例子来说明脚本解析字符串之后是何种形式的存在
-
创建一个索引保存解析的数据
PUT zfc-doc-000008 {"mappings": {"properties": {"message": {"type": "wildcard"}}} } -
内置一个脚本,实现解析字符串信息,并提取需要的信息,如下为提取当前日志中的
http响应信息response,对于如下脚本的测试API使用详情可以参考官网https://www.elastic.co/guide/en/elasticsearch/painless/8.1/painless-execute-api.html
POST /_scripts/painless/_execute {"script": {"source": """String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response;if (response != null) emit(Integer.parseInt(response)); """},"context": "long_field", "context_setup": {"index": "zfc-doc-000008","document": { "message": """247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] "GET /images/hm_nbg.jpg HTTP/1.0" 304 0"""}} }
如果我们还想操作当前解析的数据我们可以使用运行时字段,因为运行时字段不需要进行索引会更加的灵活,可以很方便的修改脚本及运行方式。
-
那么我们现在删除一下刚刚创建的索引,重新添加一下,创建语句如下
DELETE zfc-doc-000008 PUT /zfc-doc-000008 {"mappings": {"properties": {"@timestamp": {"format": "strict_date_optional_time||epoch_second","type": "date"},"message": {"type": "wildcard"}}} } -
添加一个运行时字段来保存解析的结果
PUT zfc-doc-000008/_mappings {"runtime": {"http.response": {"type": "long","script": """String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response;if (response != null) emit(Integer.parseInt(response));"""}} } -
添加几条测试数据用于测试
POST /zfc-doc-000008/_bulk?refresh=true {"index":{}} {"timestamp":"2020-04-30T14:30:17-05:00","message":"40.135.0.0 - - [30/Apr/2020:14:30:17 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:30:53-05:00","message":"232.0.0.0 - - [30/Apr/2020:14:30:53 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:31:12-05:00","message":"26.1.0.0 - - [30/Apr/2020:14:31:12 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:31:19-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:19 -0500] \"GET /french/splash_inet.html HTTP/1.0\" 200 3781"} {"index":{}} {"timestamp":"2020-04-30T14:31:22-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"} {"index":{}} {"timestamp":"2020-04-30T14:31:27-05:00","message":"252.0.0.0 - - [30/Apr/2020:14:31:27 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"} {"index":{}} {"timestamp":"2020-04-30T14:31:28-05:00","message":"not a valid apache log"} -
下面我们进行运行时字段检索响应为
304的数据GET zfc-doc-000008/_search {"query": {"match": {"http.response": "304"}},"fields" : ["http.response"] } -
刚才是属于提前内置好运行时字段,我们也可以直接在检索时指定运行时字段来使用,但下面所示的仅在运行时有效。如下所示
GET zfc-doc-000008/_search {"runtime_mappings": {"http.response": {"type": "long","script": """String response=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{response} %{size}').extract(doc["message"].value)?.response;if (response != null) emit(Integer.parseInt(response));"""}},"query": {"match": {"http.response": "304"}},"fields" : ["http.response"] }
我们也可以根据特定的值进行拆分,获取所需要的信息
3.6、使用脚本解析 GC 信息
-
例如如下
Elasticsearch的GC信息[2021-04-27T16:16:34.699+0000][82460][gc,heap,exit] class space used 266K, capacity 384K, committed 384K, reserved 1048576K -
下面我们根据
GC信息编写一个解析模式[%{@timestamp}][%{code}][%{desc}] %{ident} used %{usize}, capacity %{csize}, committed %{comsize}, reserved %{rsize} -
然后在检索时就可以使用如下语句来提交信息到运行时字段,首先添加测试数据,注意索引名称已经更换,解析模式不匹配会报错
POST /zfc-doc-000010/_bulk?refresh {"index":{}} {"gc": "[2021-04-27T16:16:34.699+0000][82460][gc,heap,exit] class space used 266K, capacity 384K, committed 384K, reserved 1048576K"} {"index":{}} {"gc": "[2021-03-24T20:27:24.184+0000][90239][gc,heap,exit] class space used 15255K, capacity 16726K, committed 16844K, reserved 1048576K"} {"index":{}} {"gc": "[2021-03-24T20:27:24.184+0000][90239][gc,heap,exit] Metaspace used 115409K, capacity 119541K, committed 120248K, reserved 1153024K"} {"index":{}} {"gc": "[2021-04-19T15:03:21.735+0000][84408][gc,heap,exit] class space used 14503K, capacity 15894K, committed 15948K, reserved 1048576K"} {"index":{}} {"gc": "[2021-04-19T15:03:21.735+0000][84408][gc,heap,exit] Metaspace used 107719K, capacity 111775K, committed 112724K, reserved 1146880K"} {"index":{}} {"gc": "[2021-04-27T16:16:34.699+0000][82460][gc,heap,exit] class space used 266K, capacity 367K, committed 384K, reserved 1048576K"} -
使用检索语句展示解析数据到运行时字段中
GET zfc-doc-000010/_search {"runtime_mappings": {"gc_size": {"type": "keyword","script": """Map gc=dissect('[%{@timestamp}][%{code}][%{desc}] %{ident} used %{usize}, capacity %{csize}, committed %{comsize}, reserved %{rsize}').extract(doc["gc.keyword"].value);if (gc != null) emit("used" + ' ' + gc.usize + ', ' + "capacity" + ' ' + gc.csize + ', ' + "committed" + ' ' + gc.comsize);"""}},"size": 1,"aggs": {"sizes": {"terms": {"field": "gc_size","size": 10}}},"fields" : ["gc_size"] }
通过上面的查询测试可以知道,Elasticsearch 中的 script 默认的时 painless 语言,功能已经非常强大可以满足我们的日常需求,如果还想更高级的脚本,可以使用 Java 语言来编写自己的脚本。关于 Expressions 的表达式的使用就参与官网吧,本文的所有例子均来自官网,并自测完成。如有错误欢迎指出,共同进步。
后面有机会会出现一片使用Java编译脚本的使用,等后面时间吧,最近这段时间听尴尬的,也托更很久了,以后慢慢的都要补上。
2023 最后俩月了,加油。
原文链接
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-scripting.html
本文由 mdnice 多平台发布
相关文章:
深入了解 Elasticsearch 8.1 中的 Script 使用
一、什么是 Elasticsearch Script? Elasticsearch 中的 Script 是一种灵活的方式,允许用户在查询、聚合和更新文档时执行自定义的脚本。这些脚本可以用来动态计算字段值、修改查询行为、执行复杂的条件逻辑等等。 二、支持的脚本语言有哪些 支持多种脚本…...
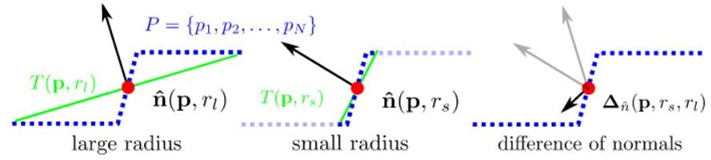
激光雷达点云基础-点云滤波算法与NDT匹配算法
激光雷达点云处理在五年前就做了较多的工作,最近有一些新的接触发现激光雷达代码原理五年前未见重大更新,或许C与激光雷达结合本身就是比较高的技术门槛。深度学习调包侠在硬核激光雷达技术面前可以说是完全的自愧不如啊。 1、点云滤波 在获取点云数据…...

回收废品抢派单小程序开源版开发
回收废品派单抢派单小程序开源版开发 在这个废品回收抢单派单小程序开源版开发中,我们将构建一个专业且富有趣味性的平台,以深度的模式来重塑废品回收体验。 我们将提供一个会员注册功能,用户可以通过小程序授权注册和手机号注册两种方式快…...

粤嵌实训医疗项目--day04(Vue + SpringBoot)
往期回顾 粤嵌实训医疗项目--day03(Vue SpringBoot)-CSDN博客粤嵌实训医疗项目day02(Vue SpringBoot)-CSDN博客粤嵌实训医疗项目--day01(VueSpringBoot)-CSDN博客 目录 一、用户详细信息查询 (查询信息与…...
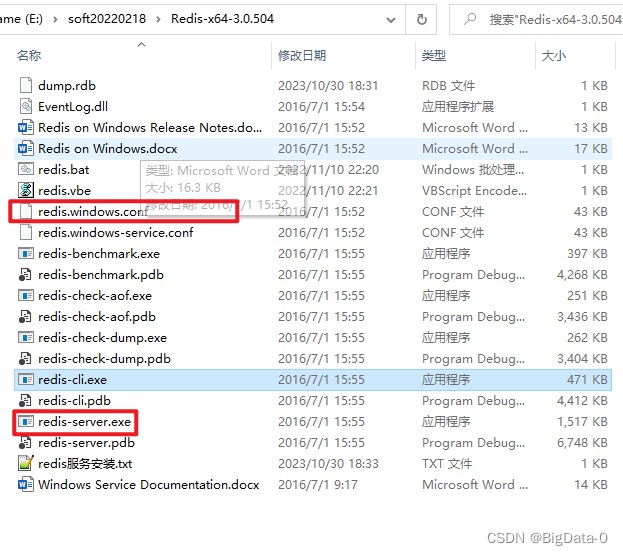
redis加入window服务及删除
1、命令redis-server.exe --service-install redis.windows.conf,在服务中可配置自动启动 删除redis服务,先停止redis服务运行,管理员cmd模式,sc delete "redis" ,...
leetcode-哈希表
1. 理论 从哈希表的概念、哈希碰撞、哈希表的三种实现方式进行学习 哈希表:用来快速判断一个元素是否出现集合里。也就是查值就能快速判断,O(1)复杂度; 哈希碰撞:拉链法,线性探测法等。只是一种…...

NOIP2023模拟6联测27 旅行
题目大意 有一个有 n n n个点 n n n条边的无向连通图,一开始每条边都有一个颜色 c c c。 有 m m m次操作,每次操作将一条两个端点为 x , y x,y x,y的边的颜色修改为 c c c。求每次修改之后,图中有多少个颜色相同的连通块。 一个颜色相同的…...
【表面缺陷检测】钢轨表面缺陷检测数据集介绍(2类,含xml标签文件)
一、介绍 钢轨表面缺陷检测是指通过使用各种技术手段和设备,对钢轨表面进行检查和测量,以确定是否存在裂纹、掉块、剥离、锈蚀等缺陷的过程。这些缺陷可能会对铁路运输的安全和稳定性产生影响,因此及时进行检测和修复非常重要。钢轨表面缺陷…...
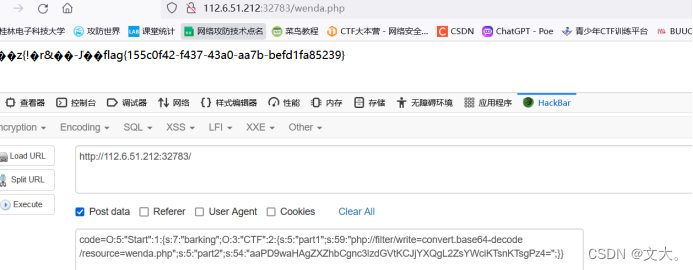
SHCTF 2023 新生赛 Web 题解
Web [WEEK1]babyRCE 源码过滤了cat 空格 我们使用${IFS}替换空格 和转义获得flag [WEEK1]飞机大战 源码js发现unicode编码 \u005a\u006d\u0078\u0068\u005a\u0033\u0074\u006a\u0059\u006a\u0045\u007a\u004d\u007a\u0067\u0030\u005a\u0069\u0030\u0031\u0059\u006d\u0045…...
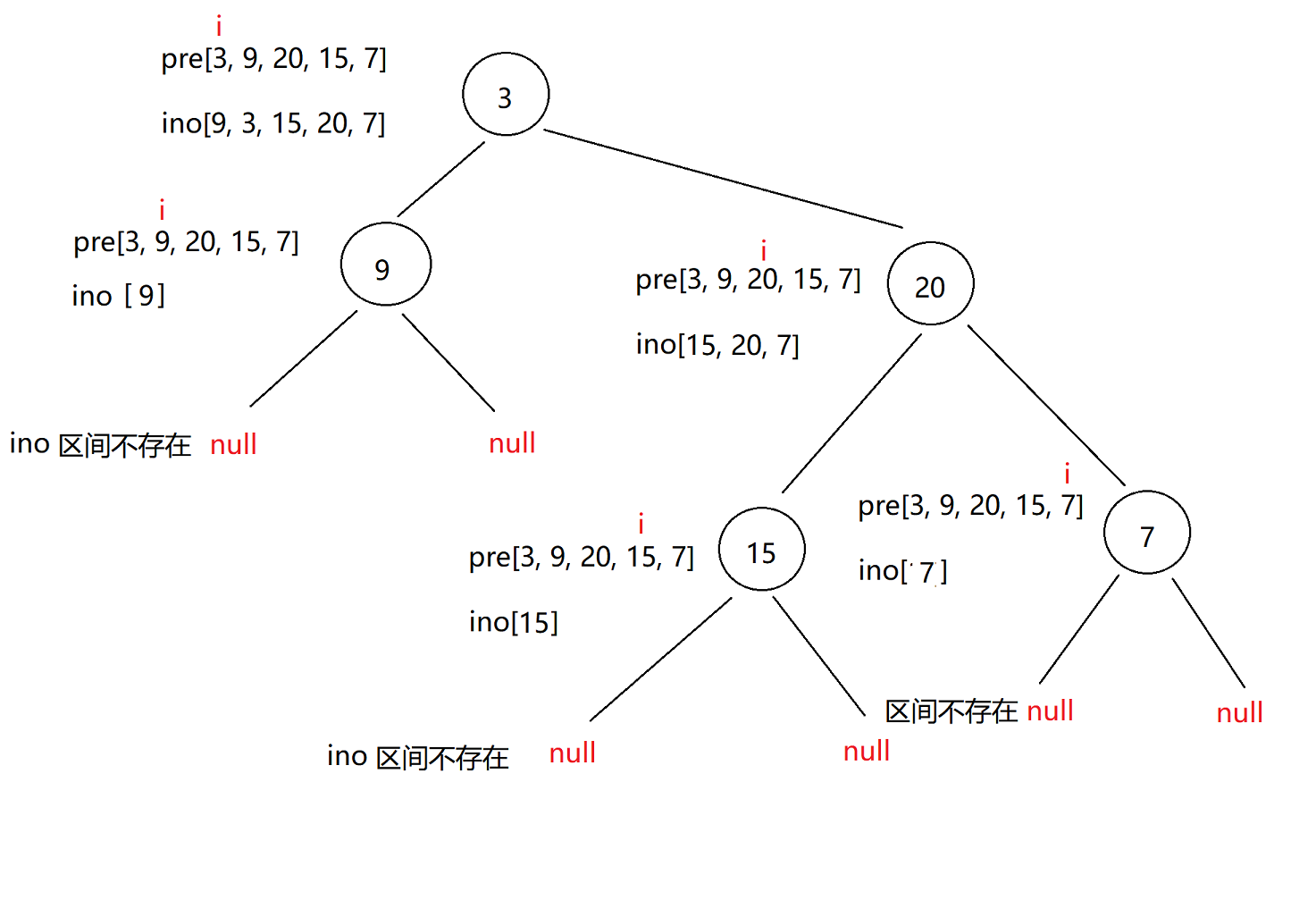
二叉树题目合集(C++)
二叉树题目合集 1.二叉树创建字符串(简单)2.二叉树的分层遍历(中等)3.二叉树的最近公共祖先(中等)4.二叉树搜索树转换成排序双向链表(中等)5.根据树的前序遍历与中序遍历构造二叉树&…...
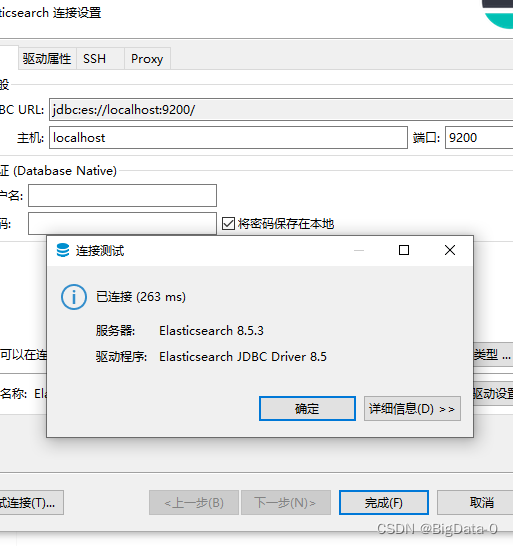
dbeaver配置es连接org.elasticsearch.xpack.sql.jdbc.EsDriver
查看目标es服务版本,下载对应驱动...

有监督学习线性回归
1、目标分析(回归问题还是分类问题?) 2、获取、处理数据 3、创建线性回归模型 4、训练模型 5、模型测试 x_data [[6000, 58], [9000, 77], [11000, 89], [15000, 54]] # 样本特征数据 y_data [30000, 55010, 73542, 63201] # 样本目标数…...
如何在vscode中添加less插件
Less (Leaner Style Sheets 的缩写) 是一门向后兼容的 CSS 扩展语言。它对CSS 语言增加了少许方便的扩展,通过less可以编写更少的代码实现更强大的样式。但less不是css,浏览器不能直接识别,即浏览器无法执行less代码&a…...
mediapipe 训练自有图像数据分类
参考: https://developers.google.com/mediapipe/solutions/customization/image_classifier https://colab.research.google.com/github/googlesamples/mediapipe/blob/main/examples/customization/image_classifier.ipynb#scrollToplvO-YmcQn5g 安装:…...
函数)
【pytorch】torch.gather()函数
dim0时 index[ [x1,x2,x2],[y1,y2,y2],[z1,z2,z3] ]如果dim0 填入方式为: index[ [(x1,0),(x2,1),(x3,2)][(y1,0),(y2,1),(y3,2)][(z1,0),(z2,1),(z3,2)] ]input [[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12] ] # shape(3,4) input torch.…...

Mac 安装psycopg2,报错Error: pg_config executable not found.
在mac 上安装psycopg2的方法:执行:pip3 install psycopg2-binary。 如果执行pip3 install psycopg2,无法安装psycopg2 报错信息如下: Collecting psycopg2Using cached psycopg2-2.9.9.tar.gz (384 kB)Preparing metadata (set…...

域名系统 DNS
DNS 概述 域名系统 DNS(Domain Name System)是因特网使用的命名系统,用来把便于人们使用的机器名字转换成为 IP 地址。域名系统其实就是名字系统。为什么不叫“名字”而叫“域名”呢?这是因为在这种因特网的命名系统中使用了许多的“域(domain)”&#x…...

Vue $nextTick 模板解析后在执行的函数
this.$nextTick(()>{ 模板解析后在执行的函数 })...

VBA技术资料MF76:将自定义颜色添加到调色板
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。我的教程一共九套,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到…...

zilong-20231030
1)k个反转 2)n!转12进制 求末尾多少0 一共有几位 (考虑了溢出问题) 3)大量数据获取前10个 4)reemap地城结构 5)红黑树规则特性 6)热更 7)压测 8)业务 跨服实现 9)有哪些线程以及怎么分配...

PMOS 在电源管理中的高效应用
1. PMOS在高侧开关中的天然优势 我第一次用PMOS做高侧开关是在一个车载设备项目里。当时需要控制12V电源的通断,尝试了几种方案后,发现PMOS简直是这个场景的"天选之子"。相比NMOS,PMOS最大的优势就是控制逻辑简单直接——栅极拉低导…...

Llama-3.2V-11B-cot与Dify集成:零代码构建企业AI智能体
Llama-3.2V-11B-cot与Dify集成:零代码构建企业AI智能体 最近和几个做企业服务的朋友聊天,大家普遍有个感觉:现在AI模型能力越来越强,但真要把它们用起来,门槛还是有点高。特别是对于业务部门的人来说,看着…...

从游戏机到影音中心:用wiliwili解锁Switch的隐藏娱乐潜能
从游戏机到影音中心:用wiliwili解锁Switch的隐藏娱乐潜能 【免费下载链接】wiliwili 专为手柄控制设计的第三方跨平台B站客户端,目前可以运行在PC全平台、PSVita、PS4 和 Nintendo Switch上 项目地址: https://gitcode.com/GitHub_Trending/wi/wiliwil…...

手把手教你用AI超分镜像:低清图片3倍放大,细节修复超简单
手把手教你用AI超分镜像:低清图片3倍放大,细节修复超简单 1. 为什么你需要这个AI超分工具? 你是不是也遇到过这些头疼的情况? 翻出十几年前的老照片,想打印出来,却发现画面模糊得像蒙了一层雾。从网上下…...

Magma智能剪辑系统:视频自动生成实战
Magma智能剪辑系统:视频自动生成实战 1. 引言 想象一下这样的场景:你有一个精彩的视频创意,写好了详细的脚本,但面对一堆零散的素材片段却无从下手。传统的视频剪辑需要逐帧挑选、拼接、添加转场,一个几分钟的视频可…...

Z-Image-Turbo-辉夜巫女惊艳效果:神社鸟居背景+巫女舞动姿态动态构图
Z-Image-Turbo-辉夜巫女惊艳效果:神社鸟居背景巫女舞动姿态动态构图 想看看AI如何将“辉夜巫女”的古典神秘与神社鸟居的庄严宁静完美融合,并赋予其灵动的舞姿吗?今天,我们就来深度体验一个名为“Z-Image-Turbo-辉夜巫女”的专属…...

YOLO12入门必看:从上传图片到JSON结果输出完整操作流程
YOLO12入门必看:从上传图片到JSON结果输出完整操作流程 1. 引言:为什么你需要了解YOLO12? 如果你正在寻找一个既快又准的目标检测工具,那么YOLO12的出现,可能就是你一直在等的那个答案。 想象一下这样的场景&#x…...

终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来
终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...
)
别再死记硬背GAT公式了!用Python+PyTorch手把手图解注意力机制(附代码)
图解GAT:用PythonPyTorch拆解图注意力机制的实现奥秘 当你第一次听说图注意力网络(GAT)时,是否被那些复杂的数学公式和抽象概念吓退?本文将以全新的可视化方式,带你从零实现一个完整的GAT层,用代…...

ROS2 Humble下,如何用MoveIt! Action接口让机械臂“听话”?一个抓取demo的完整复盘
ROS2 Humble下机械臂精准控制实战:从MoveIt! Action接口到完整抓取任务 在工业自动化和服务机器人领域,机械臂的精准运动控制一直是核心挑战。ROS2 Humble版本中的MoveIt!框架为这一挑战提供了优雅的解决方案,而理解其Action接口的运作机制则…...