分布式算法 - Snowflake算法
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。为什么如此重要?因为它提供了一种ID生成及生成的思路,当然这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
雪花算法-Snowflake
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
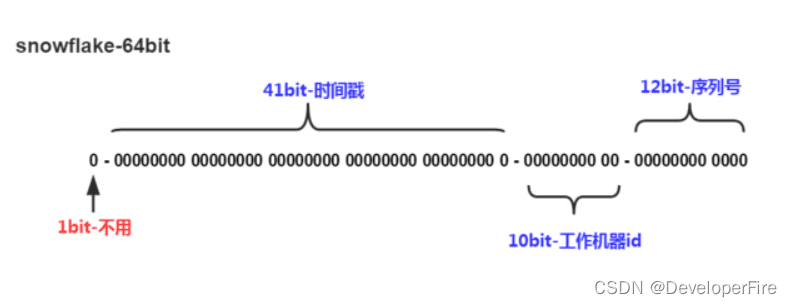
第1位占用1bit,其值始终是0,可看做是符号位不使用。
第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是(1L<<41)/(1000L360024*365)=69 年的时间。
中间的10-bit位可表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器。如果我们对IDC(互联网数据中心)有需求,还可以将 10-bit 分 5-bit 给 IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上可产生4096个有序的不重复的ID。但是我们 IDC 和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。
Snowflake 的Twitter官方原版是用Scala写的,对Scala语言有研究的同学可以去阅读下,以下是 Java 版本的写法。
package com.jajian.demo.distribute;/*** Twitter_Snowflake<br>* SnowFlake的结构如下(每部分用-分开):<br>* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>* 加起来刚好64位,为一个Long型。<br>* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。*/
public class SnowflakeDistributeId {// ==============================Fields===========================================/*** 开始时间截 (2015-01-01)*/private final long twepoch = 1420041600000L;/*** 机器id所占的位数*/private final long workerIdBits = 5L;/*** 数据标识id所占的位数*/private final long datacenterIdBits = 5L;/*** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)*/private final long maxWorkerId = -1L ^ (-1L << workerIdBits);/*** 支持的最大数据标识id,结果是31*/private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);/*** 序列在id中占的位数*/private final long sequenceBits = 12L;/*** 机器ID向左移12位*/private final long workerIdShift = sequenceBits;/*** 数据标识id向左移17位(12+5)*/private final long datacenterIdShift = sequenceBits + workerIdBits;/*** 时间截向左移22位(5+5+12)*/private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;/*** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)*/private final long sequenceMask = -1L ^ (-1L << sequenceBits);/*** 工作机器ID(0~31)*/private long workerId;/*** 数据中心ID(0~31)*/private long datacenterId;/*** 毫秒内序列(0~4095)*/private long sequence = 0L;/*** 上次生成ID的时间截*/private long lastTimestamp = -1L;//==============================Constructors=====================================/*** 构造函数** @param workerId 工作ID (0~31)* @param datacenterId 数据中心ID (0~31)*/public SnowflakeDistributeId(long workerId, long datacenterId) {if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}this.workerId = workerId;this.datacenterId = datacenterId;}// ==============================Methods==========================================/*** 获得下一个ID (该方法是线程安全的)** @return SnowflakeId*/public synchronized long nextId() {long timestamp = timeGen();//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp < lastTimestamp) {throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}//如果是同一时间生成的,则进行毫秒内序列if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;//毫秒内序列溢出if (sequence == 0) {//阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}//时间戳改变,毫秒内序列重置else {sequence = 0L;}//上次生成ID的时间截lastTimestamp = timestamp;//移位并通过或运算拼到一起组成64位的IDreturn ((timestamp - twepoch) << timestampLeftShift) //| (datacenterId << datacenterIdShift) //| (workerId << workerIdShift) //| sequence;}/*** 阻塞到下一个毫秒,直到获得新的时间戳** @param lastTimestamp 上次生成ID的时间截* @return 当前时间戳*/protected long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}/*** 返回以毫秒为单位的当前时间** @return 当前时间(毫秒)*/protected long timeGen() {return System.currentTimeMillis();}
}测试的代码如下
public static void main(String[] args) {SnowflakeDistributeId idWorker = new SnowflakeDistributeId(0, 0);for (int i = 0; i < 1000; i++) {long id = idWorker.nextId();
// System.out.println(Long.toBinaryString(id));System.out.println(id);}
}雪花算法提供了一个很好的设计思想,雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的,而且可以根据自身业务特性分配bit位,非常灵活。
但是雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。官方对于此并没有给出解决方案,而是简单的抛错处理,这样会造成在时间被追回之前的这段时间服务不可用。
很多其他类雪花算法也是在此思想上的设计然后改进规避它的缺陷,后面介绍的百度 UidGenerator 和 美团分布式ID生成系统 Leaf 中snowflake模式都是在 snowflake 的基础上演进出来的。
其它相关算法
在如下文章中已经包含了所有主流的全局唯一ID实现方案:
分布式系统 - 全局唯一ID实现方案
这里给出相关的链接:
为什么需要全局唯一ID
UUID
数据库生成
使用redis实现
雪花算法-Snowflake
百度-UidGenerator
DefaultUidGenerator 实现
CachedUidGenerator 实现
美团Leaf
Leaf-segment 数据库方案
Leaf-snowflake方案
Mist 薄雾算法
整理好的Java面试资料,推荐阅读下载:
最全的java面试题库
Java核心知识点整理
相关文章:
分布式算法 - Snowflake算法
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。…...
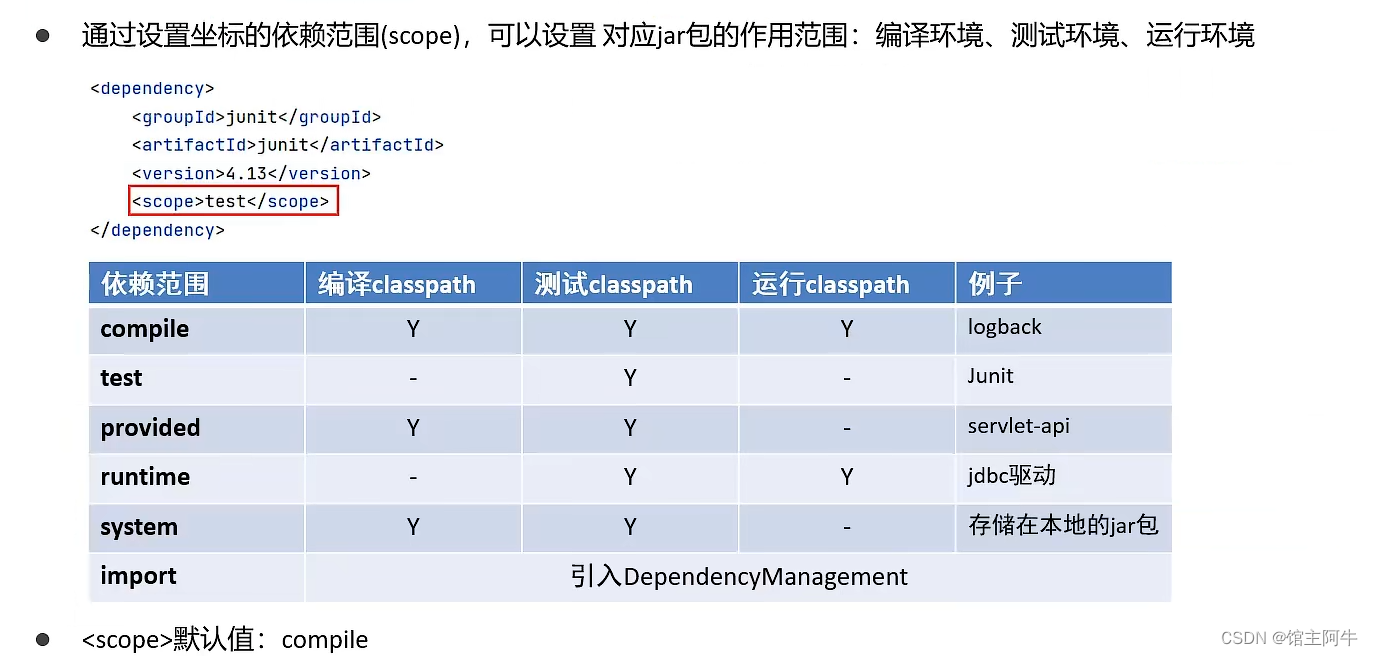
【java web篇】Maven的基本使用以及IDEA 配置Maven
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...

【蓝桥集训】第七天并查集
作者:指针不指南吗 专栏:Acwing 蓝桥集训每日一题 🐾或许会很慢,但是不可以停下来🐾 文章目录1.亲戚2.合并集合3.连通块中点的数量有关并查集的知识学习可以移步至—— 【算法】——并查集1.亲戚 或许你并不知道&#…...

【Playwright】扑面而来的Playwright测试框架
在当今快节奏的开发环境中,测试是软件开发的重要组成部分。 Microsoft Playwright 是一种流行的测试自动化框架,允许开发人员为 Web 应用程序编写端到端测试。 Playwright 建立在 Puppeteer 之上,这是另一个流行的测试自动化框架。在这篇博文…...
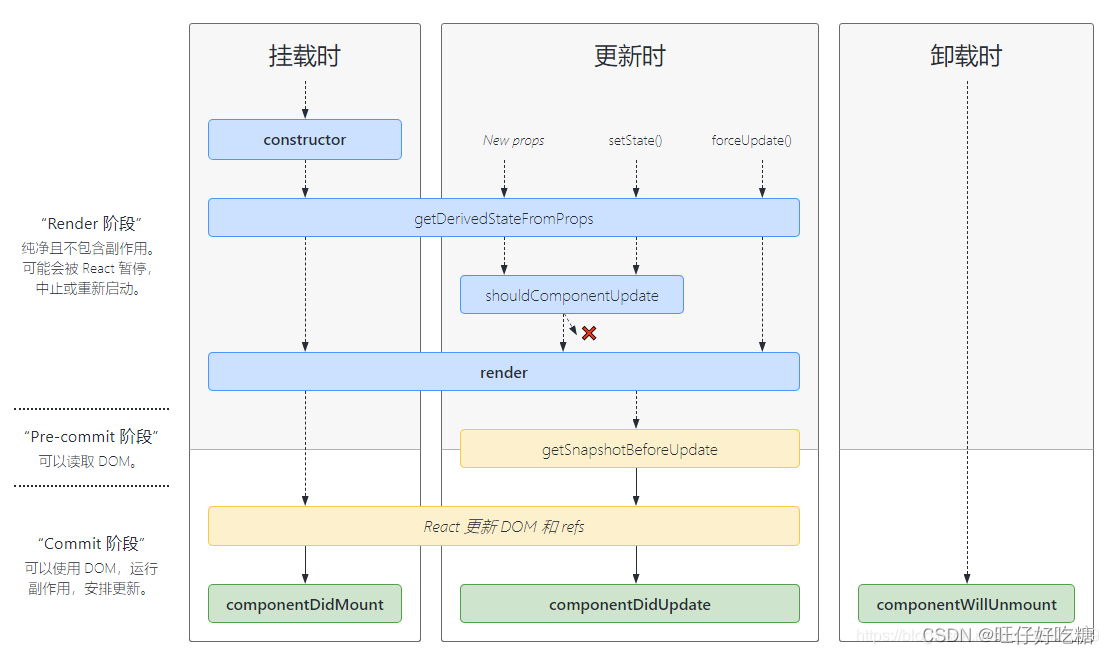
React(三) ——新、旧生命周期
🧁个人主页:个人主页 ✌支持我 :点赞👍收藏🌼关注🧡 文章目录⛳React生命周期🌋初始化阶段👣运行中阶段🏓销毁阶段🏫新生命周期的替代🚚react中性…...

IT男的一次中年破局尝试--出书
一、转战外企 接上回《人到中年——IT男择业感悟》后,自己从大央企去了某知名外企。外企虽然最近几年的日子已经没有10年前的辉煌与滋润,但相对来说,还能勉强找到工作与生活的平衡点。 划重点,35岁上下的人换工作理由…...

Python 内置函数eval()
Python 内置函数eval() eval(expression, globalsNone, localsNone) 函数用来执行一个字符串表达式,并返回表达式的值。 expression: 字符串表达式。global: 可选,globals必须是一个字典。locals: 可选,locals可以是任何映射对象。 示例 &…...

【ArcGIS Pro二次开发】系列学习笔记,持续更新,记得收藏
一、前言 这个系列是本人的一个学习笔记。 作为一个ArcGIS Pro二次开发的初学者,最困扰的就是无从入手。网上关于ArcGIS Pro二次开发的中文资料极少,官方文档对于我这样的英文苦手又太不友好。 在搜索无果后,决定自已动手,从头…...

EasyRecovery16MAC苹果版本Photo最新版数据恢复软件
无论是在工作学习中,还是在生活中,Word、Excle等办公软件都是大家很常用的。我们在使用电脑的过程中,有时会因自己的误删或电脑故障,从而导致我们所写的文档丢失了。出现这样的大家不要着急,今天小编就给大家推荐一款可…...

Go的string与strings.Builder
Go的string与strings.Builder 文章目录Go的string与strings.Builder一、strings.Builder 的优势二、string类型的值三、与string相比,Builder的优势体现在拼接方面3.1 Builder的拼接,与Builder的自动扩容3.2 手动扩容3.3 Builder 的重用四、strings.Buil…...

8.Spring Security 权限控制
1.简介入门JavaEE和SpringMVC :Spring Security就是通过11个Fliter进行组合管理小Demouser实体类user.type字段,0普通用户,1超级管理员,2版主补全get set tostringimplement UserDetails,重写以下方法// true: 账号未过…...

curl / python+selenium爬取网页信息
Python爬取网页信息 需求: 持续爬取某嵌入式设备配置网页上的状态信息 shell脚本 简单快速, 不用装插件只能爬取静态内容 用curl命令返回整个网页的内容用grep命令抓取其中某些字段结合正则表达式可多样查找但对于动态内容, 比如对某嵌入式设备配置网页上的一条不断更新的信…...

晶体塑性有限元 Abaqus 三维泰森多边形(voronoi模型)插件 V7.0
1 上一版本完整功能介绍: Voronoi晶体插件-6.0版本[新功能介绍] 晶体塑性有限元 Abaqus 三维泰森多边形(voronoi模型)插件 V6.0 2 新增功能模块 7.0版本新增功能模块包括:柱状晶体模块和分层晶体模块。 2.1 二维柱状晶体模块 …...

CPython解释器性能分析与优化
原文来自微信公众号“编程语言Lab”:CPython 解释器性能分析与优化 搜索关注 “编程语言Lab”公众号(HW-PLLab)获取更多技术内容! 欢迎加入 编程语言社区 SIG-元编程 参与交流讨论(加入方式:添加文末小助手…...
Linux 进程:理解进程和pcb
目录一、进程的概念二、CPU分时机制三、并发与并行1.并发2.并行四、pcb的概念一、进程的概念 什么是进程? 进程就是进行中的程序,即运行中的应用程序。比如:电脑上打开的LOL、QQ…… 这些都是一个个的进程。 什么是应用程序? 应用…...
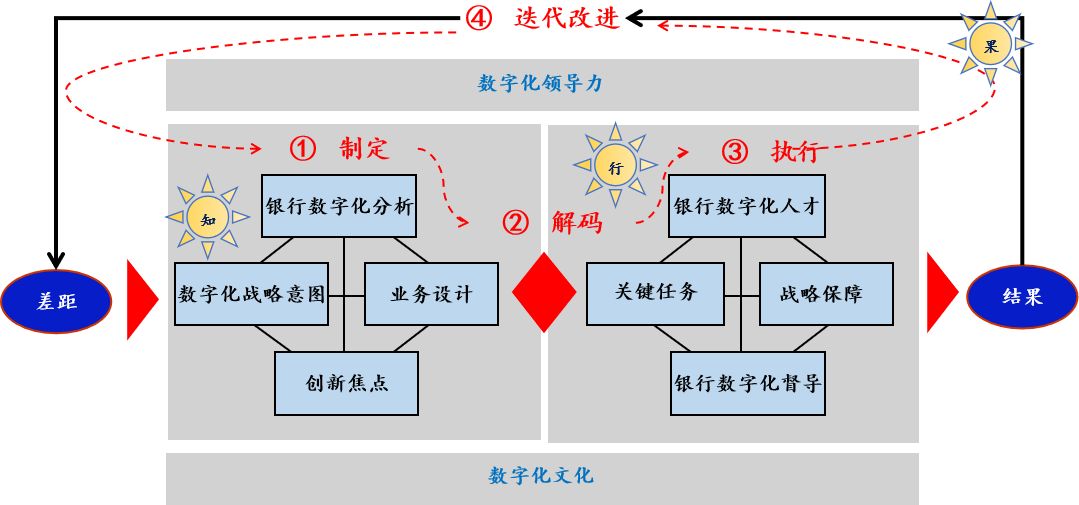
银行数字化转型导师坚鹏:招商银行数字化转型战略研究
招商银行数字化转型战略研究课程背景: 很多银行存在以下问题:不清楚如何制定银行数字化转型战略?不知道其它银行的数字化转型战略是如何演变的? 课程特色:用实战案例解读招商银行数字化转型战略。用独特视角解…...
java 一文讲透面向对象 (20万字博文)
目录 一、前言 二、面向对象程序设计介绍 1.oop三大特性 : 2.面向对象和面向过程的区别 : 3.面向对象思想特点 : 4.面向对象的程序开发 : 三、Java——类与对象 1.java中如何描述一个事物? 2.什么是类? 3.类的五大成员: 4.封装的前提——抽象 : 5.什么是对…...
使用file-selector-button美化原生文件上传
前言 你平时见到的上传文件是下面这样的? 还是下面这种美化过的button样式 还是下面这种复杂的上传组件。 <input type="file" >:只要指定的是type类型的input,打开浏览器就是上面第一种原生的浏览器默认的很丑的样式。 下面的两种是我从ElementUI截的图,…...

0402换元积分法-不定积分
文章目录1 第一类换元法1.1 定理11.2 例题1.2 常见凑微分形式1.2.1常见基本的导数公式的逆运算1.2.2被积函数含有三角函数2 第二类换元法2.1 定理22.2 常见第二换元代换方法2.2.1 三角代换-弦代换2.2.2 三角代换-切代换2.2.3 三角代换-割代换2.2.4 三角代换汇总2.2.5 倒代换2.2…...
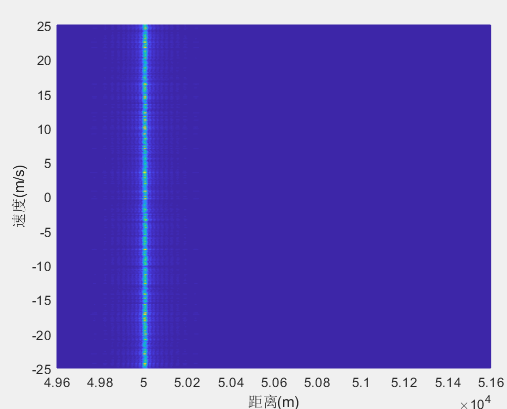
信号类型(雷达)——脉冲雷达(三)
系列文章目录 《信号类型(雷达通信)》 《信号类型(雷达)——雷达波形认识(一)》 《信号类型(雷达)——连续波雷达(二)》 文章目录 前言 一、相参雷达 1…...

多渠道订单数据处理自动化,落地步骤与ERP打通方案 | 2026企业级智能体实战手册
在2026年的数字化转型深水区,企业面临的不再是“是否要自动化”的问题, 而是如何在高并发、多维度的全渠道业务压力下, 实现订单流、资金流与信息流的绝对同步。 传统的OMS(订单管理系统)与ERP(企业资源计划…...

Tinke完整技术指南:NDS游戏资源提取与逆向工程深度解析
Tinke完整技术指南:NDS游戏资源提取与逆向工程深度解析 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke Tinke是一款专业的任天堂DS(NDS)游戏资源提取与逆向工程…...

工程师实战指南:从原理到选型,全面解析电池核心技术参数与应用
1. 项目概述:为什么我们需要重新认识电池?干了三十多年电气工程,从数字电路、模拟信号到电源设计、通信协议和微控制器,我几乎把电子行业的各个角落都摸了一遍。现在我在一家叫MaxVision的公司,专门搞那种性能极端、皮…...

从怀疑到信服:VR如何从娱乐玩具进化为现实增强工具
1. 从怀疑到信服:一个技术怀疑论者的VR认知重塑之旅我不是那种会第一时间冲进苹果店排队买最新款手机的人,甚至可以说,我对新科技抱有一种近乎“卢德主义”的警惕。每当有新的技术浪潮涌来,我的第一反应不是兴奋,而是审…...

STM32高效驱动WS2812:SPI+DMA时序精解与实战避坑
1. WS2812驱动原理与SPIDMA方案优势 第一次接触WS2812灯带时,我被它的单线控制方式惊艳到了——只需要一根信号线就能控制数百个RGB灯珠。但真正动手实现时才发现,这个看似简单的协议背后藏着不少玄机。WS2812采用归零码(RZ)编码方…...

如何零成本测试ZPL标签?Virtual ZPL Printer终极解决方案揭秘
如何零成本测试ZPL标签?Virtual ZPL Printer终极解决方案揭秘 【免费下载链接】Virtual-ZPL-Printer An ethernet based virtual Zebra Label Printer that can be used to test applications that produce bar code labels. 项目地址: https://gitcode.com/gh_mi…...

UKF vs EKF实战对比:在ROS和激光雷达数据下,谁对转弯车辆的跟踪更准?
UKF与EKF在ROS激光雷达车辆跟踪中的实战对比:谁更胜一筹? 在自动驾驶和机器人领域,状态估计算法的选择直接影响着系统的感知能力和决策质量。当车辆执行转弯动作时,传统的线性运动模型往往难以准确预测其轨迹,这时就需…...

从内核恐慌到系统恢复:一次NMI watchdog触发的soft lockup深度诊断
1. 当服务器突然卡死:从NMI watchdog错误说起 那天下午3点,机房警报突然响起。我冲到服务器前,屏幕上赫然显示着刺眼的红色错误:"NMI watchdog: BUG: soft lockup - CPU#2 stuck for 23s!"。这台承载着核心业务的服务器…...
)
别再死记公式了!用Python+NumPy手撸一个卡尔曼滤波器(附代码详解)
用PythonNumPy从零实现卡尔曼滤波器:原理剖析与调参实战 卡尔曼滤波器这个听起来高大上的算法,其实离我们并不遥远。想象一下你在玩一个无人机航拍游戏,屏幕上的无人机位置总是飘忽不定——GPS信号有延迟,惯性传感器有漂移&#…...

紫光同创Logos系列FPGA的PCB设计避坑指南:从BGA扇出到配置管脚,新手必看
紫光同创Logos系列FPGA的PCB设计避坑指南:从BGA扇出到配置管脚实战解析 第一次接触紫光同创Logos系列FPGA的硬件设计时,面对密密麻麻的BGA封装和复杂的配置电路,多数工程师都会感到无从下手。我在设计第一块PGL22G开发板时,就曾因…...