关于息肉检测和识别项目的总结
前言
整体的思路:首先息肉数据集分为三类:
1.正常细胞
2. 增生性息肉
3. 肿瘤
要想完成这个任务,首先重中之重是分割任务,分割结果的好坏, 当分割结果达到一定的准确度后,开始对分割后的结果进行下游分类任务处理。最后在进行两个网络的分类结果的综合处理,从而达到想要的目的和结果。
分割网络的实现
分割网络我们常见的是UNet、Unet++、以及各种Unet的魔改版,这是因为Unet强大的泛化性,以及它能在分割的大部分领域表现出良好的性能所决定的,本次项目的实现并未选择Unet进行实现,而是选择了ESFPNet进行任务分割。这里是关于这个网络的代码,有兴趣的同学可以搜索查看 。
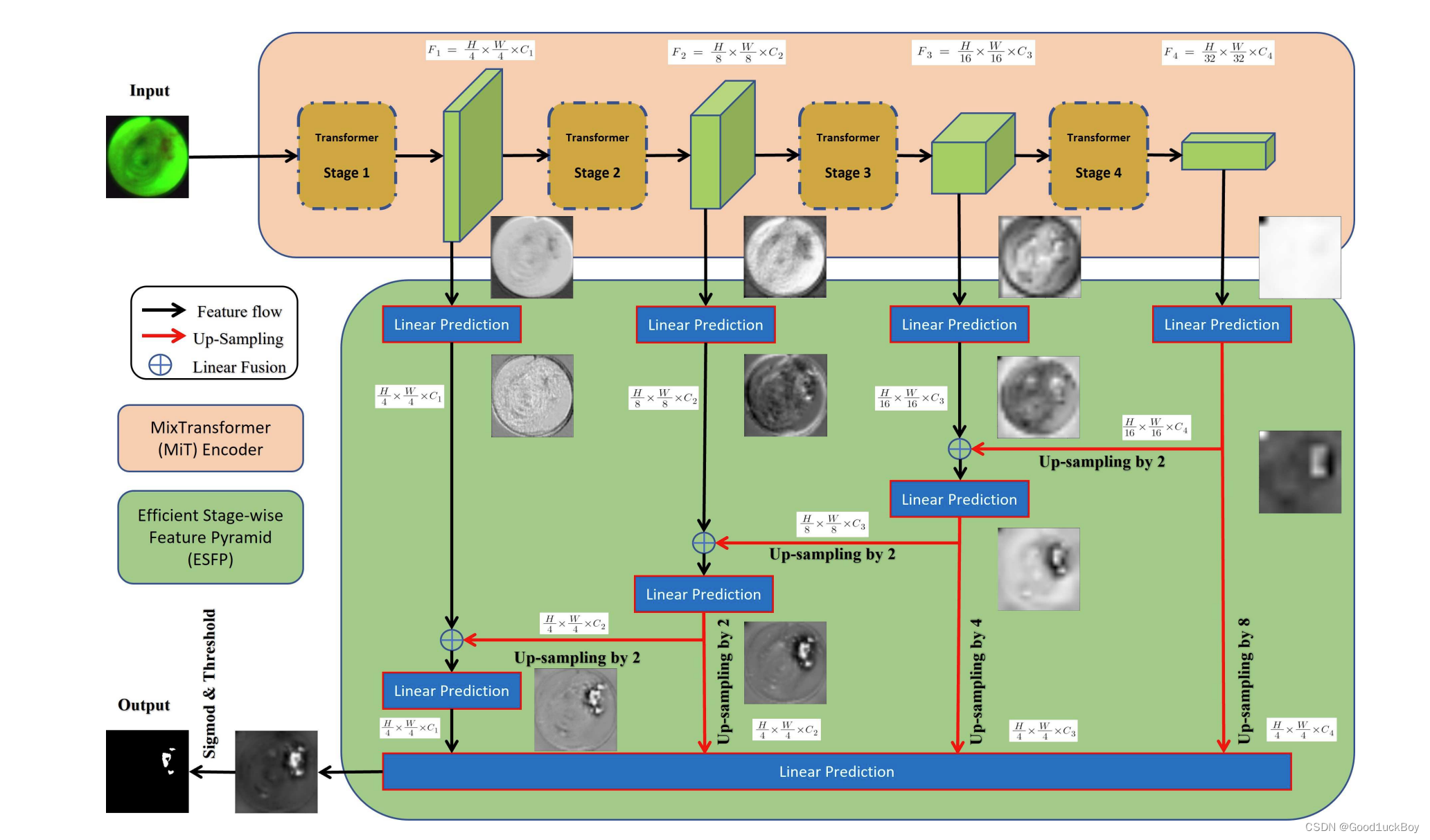
关于ESFP网络结构的介绍
from Encoder import mit
from Decoder import mlp
from mmcv.cnn import ConvModuleclass ESFPNetStructure(nn.Module):def __init__(self, embedding_dim = 160):super(ESFPNetStructure, self).__init__()# Backboneif model_type == 'B0':self.backbone = mit.mit_b0()if model_type == 'B1':self.backbone = mit.mit_b1()if model_type == 'B2':self.backbone = mit.mit_b2()if model_type == 'B3':self.backbone = mit.mit_b3()if model_type == 'B4':self.backbone = mit.mit_b4()if model_type == 'B5':self.backbone = mit.mit_b5()self._init_weights() # load pretrain# LP Headerself.LP_1 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])self.LP_2 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])self.LP_3 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])self.LP_4 = mlp.LP(input_dim = self.backbone.embed_dims[3], embed_dim = self.backbone.embed_dims[3])# Linear Fuseself.linear_fuse34 = ConvModule(in_channels=(self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), out_channels=self.backbone.embed_dims[2], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))self.linear_fuse23 = ConvModule(in_channels=(self.backbone.embed_dims[1] + self.backbone.embed_dims[2]), out_channels=self.backbone.embed_dims[1], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))self.linear_fuse12 = ConvModule(in_channels=(self.backbone.embed_dims[0] + self.backbone.embed_dims[1]), out_channels=self.backbone.embed_dims[0], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))# Fused LP Headerself.LP_12 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])self.LP_23 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])self.LP_34 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])# Final Linear Predictionself.linear_pred = nn.Conv2d((self.backbone.embed_dims[0] + self.backbone.embed_dims[1] + self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), 1, kernel_size=1)def _init_weights(self):if model_type == 'B0':pretrained_dict = torch.load('./Pretrained/mit_b0.pth')if model_type == 'B1':pretrained_dict = torch.load('./Pretrained/mit_b1.pth')if model_type == 'B2':pretrained_dict = torch.load('./Pretrained/mit_b2.pth')if model_type == 'B3':pretrained_dict = torch.load('./Pretrained/mit_b3.pth')if model_type == 'B4':pretrained_dict = torch.load('./Pretrained/mit_b4.pth')if model_type == 'B5':pretrained_dict = torch.load('./Pretrained/mit_b5.pth')model_dict = self.backbone.state_dict()pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}model_dict.update(pretrained_dict)self.backbone.load_state_dict(model_dict)print("successfully loaded!!!!")def forward(self, x):
# 这段代码是一个模型的前向传递过程。该模型首先通过backbone网络,
# 对输入的x进行特征提取,得到4个不同分辨率的特征图。
# 然后将这些特征图送入LP Header网络进行处理,融合不同层次的特征。
# 接着通过上采样(interpolation)将处理后的特征图进行恢复到原始输入图像尺寸大小,
# 并最终送入线性预测器(linear_pred)获得输出结果。################## Go through backbone ###################B = x.shape[0]#stage 1out_1, H, W = self.backbone.patch_embed1(x)for i, blk in enumerate(self.backbone.block1):out_1 = blk(out_1, H, W)out_1 = self.backbone.norm1(out_1)#将输入特征图out_1从形状(Batch_Size, N, W, H)变形为(Batch_Size, H, W, N)#其中-1表示自动计算N的值。接着使用permute函数将特征维度N和高宽维度H、W交换位置#变成(Batch_Size, N, H, W)的形状out_1 = out_1.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[0], 88, 88)# stage 2out_2, H, W = self.backbone.patch_embed2(out_1)for i, blk in enumerate(self.backbone.block2):out_2 = blk(out_2, H, W)out_2 = self.backbone.norm2(out_2)out_2 = out_2.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[1], 44, 44)# stage 3out_3, H, W = self.backbone.patch_embed3(out_2)for i, blk in enumerate(self.backbone.block3):out_3 = blk(out_3, H, W)out_3 = self.backbone.norm3(out_3)out_3 = out_3.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[2], 22, 22)# stage 4out_4, H, W = self.backbone.patch_embed4(out_3)for i, blk in enumerate(self.backbone.block4):out_4 = blk(out_4, H, W)out_4 = self.backbone.norm4(out_4)out_4 = out_4.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[3], 11, 11)# go through LP Headerlp_1 = self.LP_1(out_1)lp_2 = self.LP_2(out_2) lp_3 = self.LP_3(out_3) lp_4 = self.LP_4(out_4)# linear fuse and go pass LP Header 上采样并拼接lp_34 = self.LP_34(self.linear_fuse34(torch.cat([lp_3, F.interpolate(lp_4,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))lp_23 = self.LP_23(self.linear_fuse23(torch.cat([lp_2, F.interpolate(lp_34,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))lp_12 = self.LP_12(self.linear_fuse12(torch.cat([lp_1, F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))# get the final outputlp4_resized = F.interpolate(lp_4,scale_factor=8,mode='bilinear', align_corners=False)lp3_resized = F.interpolate(lp_34,scale_factor=4,mode='bilinear', align_corners=False)lp2_resized = F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)lp1_resized = lp_12out = self.linear_pred(torch.cat([lp1_resized, lp2_resized, lp3_resized, lp4_resized], dim=1))out_resized = F.interpolate(out,scale_factor=4,mode='bilinear', align_corners=True)return out_resized
上述图片和代码是关于ESFP核心网络的编写,下面就来详细介绍一下这个网络。
backbone(部分引用于原论文)
- 使用model_type来加载预训练模型,这里有5个参数可选。通过指定的预训练权重来初始化backbone网络。
- Mix Transformer编码器(MiT)是一个模块,它利用了ViT网络的思想,并在四个阶段中使用四个重叠的路径合并模块和自注意力预测。
- transformer使用的自注意力层缺乏局部归纳偏差(图像像素是局部相关的,其相关图是平移不变的概念),会导致数据饥饿问题。
- 为了缓解受小数据集限制的应用面临的数据饥饿挑战,可以利用广泛使用的迁移学习的概念。MiT的编码器利用了这个想法,在大型ImageNet数据库上进行了预训练对于我们的ESPFNet架构,将这些预训练的MiT编码器集成为骨干,并用初始化的解码器再次训练它们。
- 这是一种直接的方法,可以在小型特定任务数据集表现良好性能,同时也能够超过最先进的CNN模型的性能。
Efficient stage-wise feature pyramid(ESFP)
- 高层(全局)特征比低层(局部)特征对整体分割性能的贡献更大。ESFP首先对每个阶段的输出进行线性预测(有效的是连接通道的数量),然后将这些预处理的特征从全局到局部线性融合。这些中间聚合特征被连接起来,并相互协作产生最终的分割。
- 在训练之前,将输入调整为352 × 352像素,并将其归一化以进行分割。我们还使用随机翻转、旋转和亮度变化作为输入的数据增强操作。损失函数结合了加权交联(IoU)损失和加权二元交叉熵(BCE)损失:
实现细节
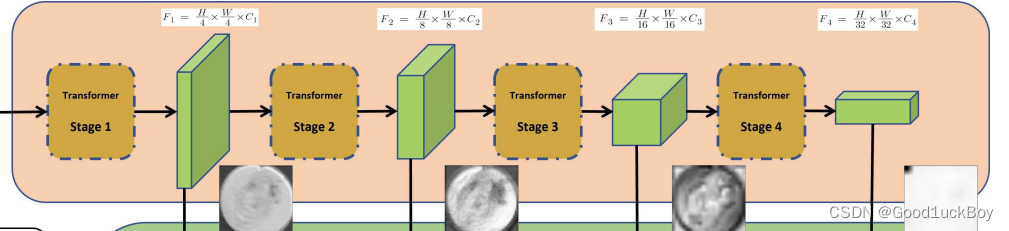
这一部分是关于MIt 编码器对图像进行编码的操作。
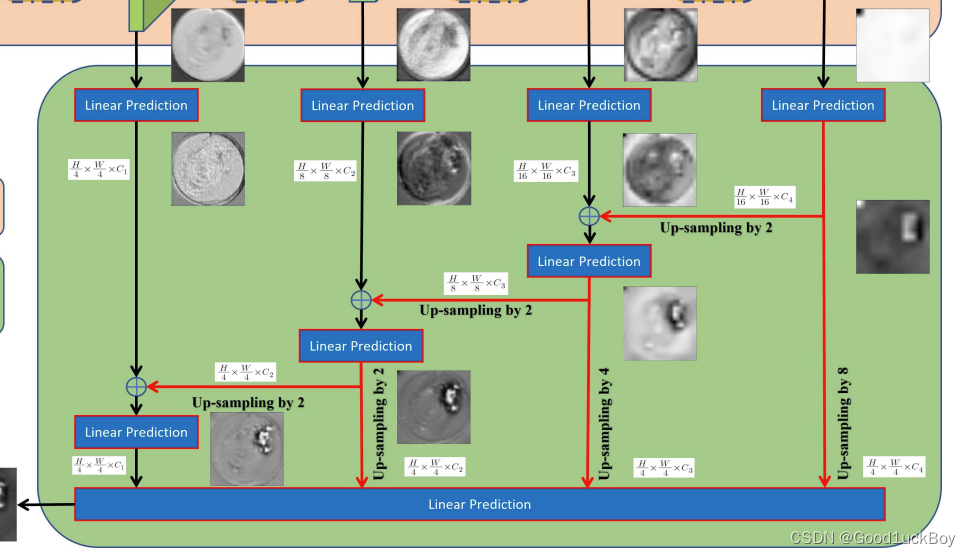
这一部分则是ESFP对网络进行解码的过程。
LP Header
# LP Headerself.LP_1 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])self.LP_2 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])self.LP_3 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])self.LP_4 = mlp.LP(input_dim = self.backbone.embed_dims[3], embed_dim = self.backbone.embed_dims[3])
- self.backbone.embed_dims[0] [1] [2] [3]、 获取到相应分辨率的特征图通道数,在这里输入和输出通道是相同的维度数。
- LP Header用于对不同分辨率的特征图进行进一步的处理和提取,以获得更加有用的信息,为后续的特征融合和预测操作做准备。
Linear Fuse(线性融合)
# Linear Fuseself.linear_fuse34 = ConvModule(in_channels=(self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), out_channels=self.backbone.embed_dims[2], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))self.linear_fuse23 = ConvModule(in_channels=(self.backbone.embed_dims[1] + self.backbone.embed_dims[2]), out_channels=self.backbone.embed_dims[1], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))self.linear_fuse12 = ConvModule(in_channels=(self.backbone.embed_dims[0] + self.backbone.embed_dims[1]), out_channels=self.backbone.embed_dims[0], kernel_size=1,norm_cfg=dict(type='BN', requires_grad=True))- 通过上述的网络结构图可以看出,我们需要3个线性融合层。
- 通过ConvModule来定义Linear Fuse层,其中in_channels表示Linear Fuse的输入通道数,由两个特征图的通道数相加得到。out_channels表示Linear Fuse的输出通道数,与对应层次的特征图通道数相同。
- 通过这些Linear Fuse层的操作,可以将不同分辨率的特征图进行融合,从而提高特征的表达能力和多尺度信息的利用效果
Fused LP Header(融合的LP Header)
# Fused LP Headerself.LP_12 = mlp.LP(input_dim = self.backbone.embed_dims[0], embed_dim = self.backbone.embed_dims[0])self.LP_23 = mlp.LP(input_dim = self.backbone.embed_dims[1], embed_dim = self.backbone.embed_dims[1])self.LP_34 = mlp.LP(input_dim = self.backbone.embed_dims[2], embed_dim = self.backbone.embed_dims[2])
- 将融合后的特征图的通道数变换为与backbone的对应层次的特征图通道数相同的维度。
- 用于对线性融合后的特征图进行进一步的特征提取和转换,以获得更加有用的信息,并为最终的预测操作做准备
Final Linear Prediction(最终线性预测)
# Final Linear Predictionself.linear_pred = nn.Conv2d((self.backbone.embed_dims[0] + self.backbone.embed_dims[1] + self.backbone.embed_dims[2] + self.backbone.embed_dims[3]), 1, kernel_size=1)- n.Conv2d用于定义一个二维卷积层,其中的输入通道数为融合后的特征图的通道数总和。
- 输入通道是各个分辨率维度的总和,输出通道为1,表示进行目标检测的预测结果。
- 这个最终的线性预测层将融合后的特征图映射到一维的通道上,以输出目标检测的预测结果。这样,通过特征融合与转换后的特征图,可以进行最终的目标检测操作并得到预测结果。
前向传播
B = x.shape[0]#stage 1out_1, H, W = self.backbone.patch_embed1(x)for i, blk in enumerate(self.backbone.block1):out_1 = blk(out_1, H, W)out_1 = self.backbone.norm1(out_1)#将输入特征图out_1从形状(Batch_Size, N, W, H)变形为(Batch_Size, H, W, N)#其中-1表示自动计算N的值。接着使用permute函数将特征维度N和高宽维度H、W交换位置#变成(Batch_Size, N, H, W)的形状out_1 = out_1.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[0], 88, 88)# stage 2out_2, H, W = self.backbone.patch_embed2(out_1)for i, blk in enumerate(self.backbone.block2):out_2 = blk(out_2, H, W)out_2 = self.backbone.norm2(out_2)out_2 = out_2.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[1], 44, 44)# stage 3out_3, H, W = self.backbone.patch_embed3(out_2)for i, blk in enumerate(self.backbone.block3):out_3 = blk(out_3, H, W)out_3 = self.backbone.norm3(out_3)out_3 = out_3.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[2], 22, 22)# stage 4out_4, H, W = self.backbone.patch_embed4(out_3)for i, blk in enumerate(self.backbone.block4):out_4 = blk(out_4, H, W)out_4 = self.backbone.norm4(out_4)out_4 = out_4.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous() #(Batch_Size, self.backbone.embed_dims[3], 11, 11)# go through LP Headerlp_1 = self.LP_1(out_1)lp_2 = self.LP_2(out_2) lp_3 = self.LP_3(out_3) lp_4 = self.LP_4(out_4)# linear fuse and go pass LP Header 上采样并拼接lp_34 = self.LP_34(self.linear_fuse34(torch.cat([lp_3, F.interpolate(lp_4,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))lp_23 = self.LP_23(self.linear_fuse23(torch.cat([lp_2, F.interpolate(lp_34,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))lp_12 = self.LP_12(self.linear_fuse12(torch.cat([lp_1, F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))# get the final outputlp4_resized = F.interpolate(lp_4,scale_factor=8,mode='bilinear', align_corners=False)lp3_resized = F.interpolate(lp_34,scale_factor=4,mode='bilinear', align_corners=False)lp2_resized = F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)lp1_resized = lp_12out = self.linear_pred(torch.cat([lp1_resized, lp2_resized, lp3_resized, lp4_resized], dim=1))out_resized = F.interpolate(out,scale_factor=4,mode='bilinear', align_corners=True)前向传播的过程,就是将结果中的完整过程串联起来,进行完整的预测。输入x的形状为(Batch_Size, C, H, W),其中B表示批量大小,C表示通道数,H和W分别表示输入特征图的高度和宽度
阶段1
out_1, H, W = self.backbone.patch_embed1(x)for i, blk in enumerate(self.backbone.block1):out_1 = blk(out_1, H, W)out_1 = self.backbone.norm1(out_1)out_1 = out_1.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
- 通过self.backbone.patch_embed1对输入特征图进行分块嵌入操作,得到输出特征图out_1和新的高度H和宽度W
- 进行self.backbone.block1中的一系列残差块操作,对输出特征图out_1进行特征提取。
- 对out_1进行归一化处理,得到归一化后的特征图out_1。
- 将输入特征图out_1从形状(Batch_Size,H,W)变形为(Batch_Size,N, H, W),通过reshape进行N维度的计算,-1表示自动计算N的值。接着使用permute函数将特征维度N和高宽维度H、W交换位置,变成(Batch_Size, N, H, W)的形状
阶段2、3、4
与上述阶段一的操作大致相同,也就是图中最上面一层,backbone网络的操作。
LP Header
# go through LP Headerlp_1 = self.LP_1(out_1)lp_2 = self.LP_2(out_2) lp_3 = self.LP_3(out_3) lp_4 = self.LP_4(out_4)
将out_1、out_2、out_3、out_4分别输入到对应的LP模块中(LP_1、LP_2、LP_3、LP_4),得到相应的低层级特征表示lp_1、lp_2、lp_3、lp_4。
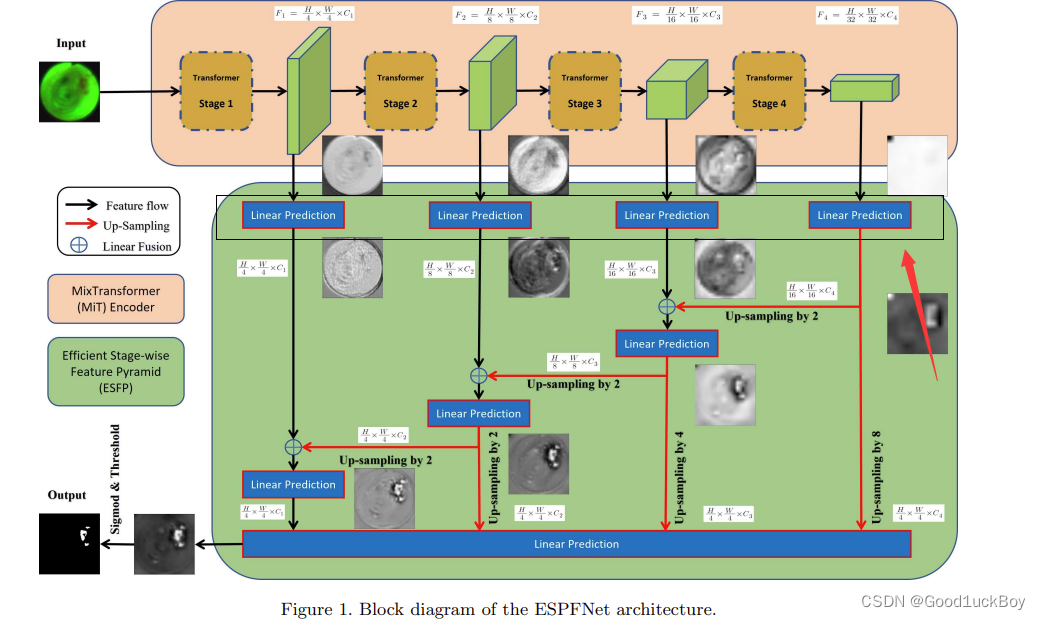
也就是黑色框中所做的事情。
线性融合与上采样:
# linear fuse and go pass LP Header 上采样并拼接lp_34 = self.LP_34(self.linear_fuse34(torch.cat([lp_3, F.interpolate(lp_4,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))lp_23 = self.LP_23(self.linear_fuse23(torch.cat([lp_2, F.interpolate(lp_34,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))lp_12 = self.LP_12(self.linear_fuse12(torch.cat([lp_1, F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)], dim=1)))
- 使用torch.cat函数将lp_3与经过上采样后的lp_4拼接起来,然后通过self.linear_fuse34和LP_34模块进行线性融合,得到lp_34。
- 类似地,通过拼接和线性融合操作得到lp_23和lp_12。
最终上采样
# get the final outputlp4_resized = F.interpolate(lp_4,scale_factor=8,mode='bilinear', align_corners=False)lp3_resized = F.interpolate(lp_34,scale_factor=4,mode='bilinear', align_corners=False)lp2_resized = F.interpolate(lp_23,scale_factor=2,mode='bilinear', align_corners=False)lp1_resized = lp_12
- 对lp_4进行上采样操作,得到lp4_resized,上采样因子为8;
- 对lp_34进行上采样操作,得到lp3_resized,上采样因子为4;
- 对lp_23进行上采样操作,得到lp2_resized,上采样因子为2;
- lp_12不进行上采样。
最终输出
out = self.linear_pred(torch.cat([lp1_resized, lp2_resized, lp3_resized, lp4_resized], dim=1))out_resized = F.interpolate(out,scale_factor=4,mode='bilinear', align_corners=True)- 使用torch.cat函数将lp1_resized、lp2_resized、lp3_resized和lp4_resized进行拼接,得到形状为(B, N, H, W)的特征图。
- 将拼接后的特征图通过self.linear_pred和线性预测模块进行特征转换,得到最终的输出特征图out。
- 对out进行上采样操作,得到out_resized,上采样因子为4。
- 最后对结果进行 Sigmod和Threshold便可以得到分割后的Output。、
分类网络介绍
分割任务完成了,那分类任务则是在分割任务的基础上,再做下游的分类任务。分类网络结构如下
self.conv_layers = nn.Sequential(nn.Conv2d(4, 128, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.fc_layers = nn.Sequential(nn.Flatten(),nn.Linear(16**2*512, 512), # 调整大小以适应您的需求nn.ReLU(),nn.Dropout(0.3),nn.Linear(512, 256), # 调整大小以适应您的需求nn.ReLU(),nn.Dropout(0.3),nn.Linear(256, 3),nn.LogSoftmax(dim=1))
首先对其进行4次卷积和3次最大池化进行下采样和特征提取。随后定义一个全连接层让通道数最终降到我们所需要的分类数,最后再做一次Softmax。
前向传播过程
前向传播过程则是将我们之前做好的分割结果,和原图进行通道维度cat连接后,再进行一最大池化操作,然后进行分类操作。我们对不同种类的数据做了one-hot类别编码。
以上就是大致总统思路,后续代码会上传到github
相关文章:
关于息肉检测和识别项目的总结
前言 整体的思路:首先息肉数据集分为三类: 1.正常细胞 2. 增生性息肉 3. 肿瘤要想完成这个任务,首先重中之重是分割任务,分割结果的好坏, 当分割结果达到一定的准确度后,开始对分割后的结果进行下游分类…...

Jetson Xavier NX FFmpeg支持硬件编解码
最近在用Jetson Xavier NX板子做视频处理,但是CPU进行视频编解码,效率比较地下。 于是便考虑用硬解码来对视频进行处理。 通过jtop查看,发现板子是支持 NVENC硬件编解码的。 1、下载源码 因为需要对ffmpeg进行打补丁修改,因此需要编译两份源码 1.1、编译jetson-ffmpeg …...

518抽奖软件,为什么说比别的抽奖软件更美观精美?
518抽奖软件简介 518抽奖软件,518我要发,超好用的年会抽奖软件,简约设计风格。 包含文字号码抽奖、照片抽奖两种模式,支持姓名抽奖、号码抽奖、数字抽奖、照片抽奖。(www.518cj.net) 精致美观功能 字体平滑无锯齿图片放大后清晰…...

React的组件学习
React的组件学习 参考资料:https://zh-hans.react.dev/learn/your-first-component 一、定义组件 export default function Profile() {return (<imgsrc"https://i.imgur.com/MK3eW3Am.jpg"alt"Katherine Johnson"/>) }以下是构建组件…...
uni-app配置微信开发者工具
一、配置微信开发者工具路径 工具->设置->运行配置->小程序运行配置->微信开发者工具路径 二、微信开发者工具开启服务端口...
肺癌不再是老年病:33岁作家的离世引发关注,有这些情况的请注意
近期,90后网络小说家七月新番和26岁男艺人蒋某某因肺癌去世,引发关注。他们都没有吸烟习惯,那么他们为什么会得肺癌呢?浙大二院呼吸内科副主任医师兰芬说,现在年轻人熬夜、加班导致身体过劳,在劳累情况下身…...

【兔子王赠书第4期】用ChatGPT轻松玩转机器学习与深度学习
文章目录 前言机器学习深度学习ChatGPT推荐图书粉丝福利尾声 前言 兔子王免费赠书第4期来啦,突破传统学习束缚,借助ChatGPT的神奇力量,解锁AI无限可能! 机器学习 机器学习是人工智能领域的一个重要分支,它的目的是让…...
(转载))
Ubuntu18.04 ROS Melodic的cv_bridge指向问题(四种方式,包括opencv4)(转载)
转载自: 【精选】Ubuntu18.04 ROS Melodic的cv_bridge指向问题(四种方式,包括opencv4)_XiangrongZ的博客-CSDN博客...
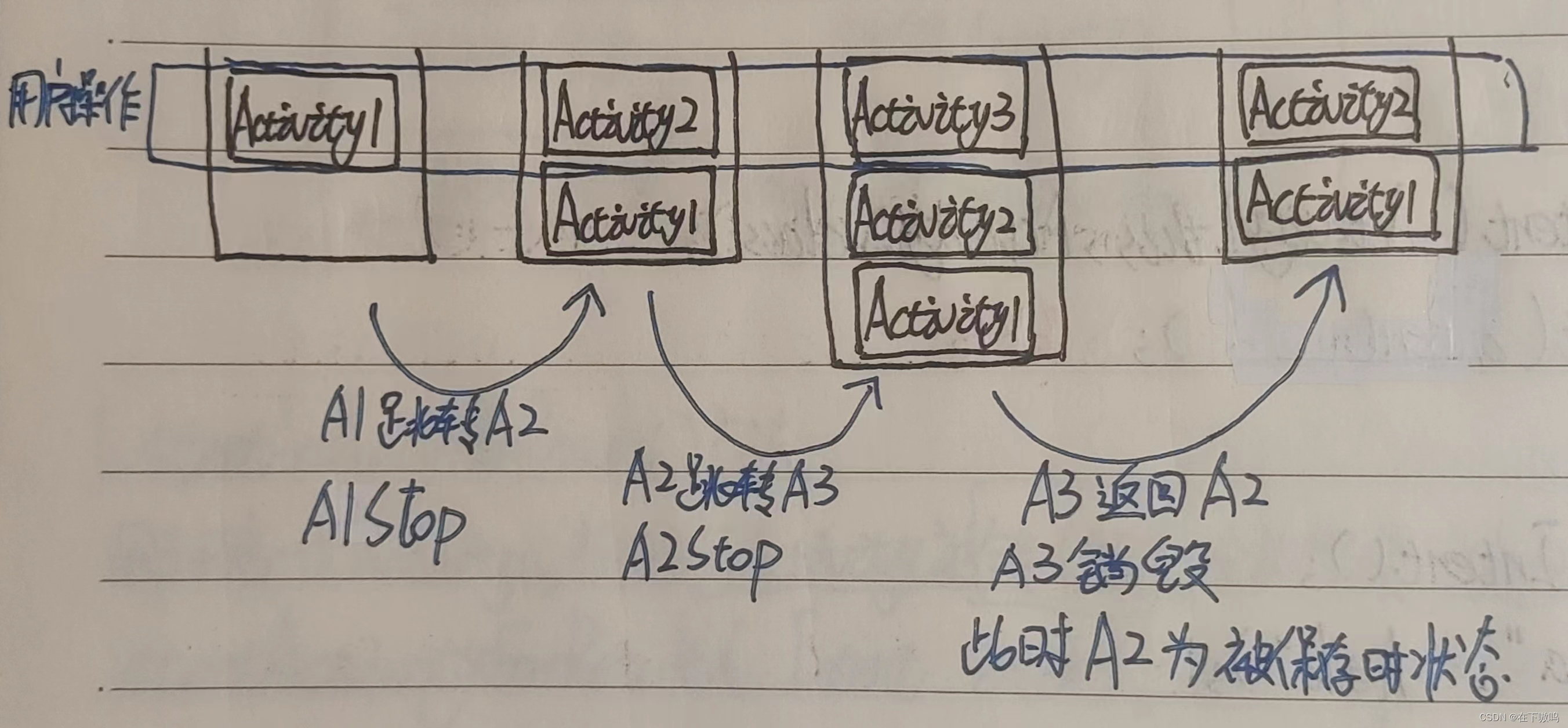
Android任务栈和启动模式
Andrcid中的任务栈是一种用来存放Activity实倒的容器。任务最大的特点就是先进后出,它主要有两个基本操作,分别是压栈和出栈。通常Andaid应用程序都有一个任务栈,每打开一个Activity时,该Activity就会被压入任务栈。每销毁一个Act…...
电脑加密软件哪个好?电脑加密软件推荐
电脑是我们办公离不开的工具,而为了保护电脑数据安全,我们可以使用专业的电脑加密软件来进行加密保护。那么,电脑加密软件哪个好呢?下面我们就来了解一下。 文件加密——超级加密3000 想要安全加密电脑重要文件,我们可…...

如何优雅地单元测试 Kotlin/Java 中的 private 方法?
翻译自 https://medium.com/mindorks/how-to-unit-test-private-methods-in-java-and-kotlin-d3cae49dccd ❓如何单元测试 Kotlin/Java 中的 private 方法❓ 首先,开发者应该测试代码里的 private 私有方法吗? 直接信任这些私有方法,测试到…...

单元测试,集成测试,系统测试的区别是什么?
实际的测试工作当中,我们会从不同的角度对软件测试的活动进行分类,题主说的“单元测试,集成测试,系统测试”,是按照开发阶段进行测试活动的划分。这种划分完整的分类,其实是分为四种“单元测试,…...
第十八节 串(KMP算法))
数据结构(超详细讲解!!)第十八节 串(KMP算法)
1.BF算法 算法在字符比较不相等,需要回溯(即ii-j1):即退到s中的下一个字符开始进行继续匹配。 最好情况下的时间复杂度为O(m)。 最坏情况下的时间复杂度为O(nm)。 平均的时间复杂度为O(nm)。 2.KMP算法 KMP算法是D.E.Knuth、…...

软考_软件设计师
算法: 1、直接插入排序 详解:https://blog.csdn.net/qq_44616044/article/details/115708056 void insertSort(int data[],int n){int i,j,temp;for(i1;i<n;i){if(data[i]<data[i-1]){temp data[i];data[i] data[i-1];for(ji-1;j>0&&am…...

大数据之LibrA数据库系统告警处理(ALM-12004 OLdap资源异常)
告警解释 当Manager中的Ldap资源异常时,系统产生此告警。 当Manager中的Ldap资源恢复,且告警处理完成时,告警恢复。 告警属性 告警参数 对系统的影响 Ldap资源异常,Manager和组件WebUI认证服务不可用,无法对Web上层…...
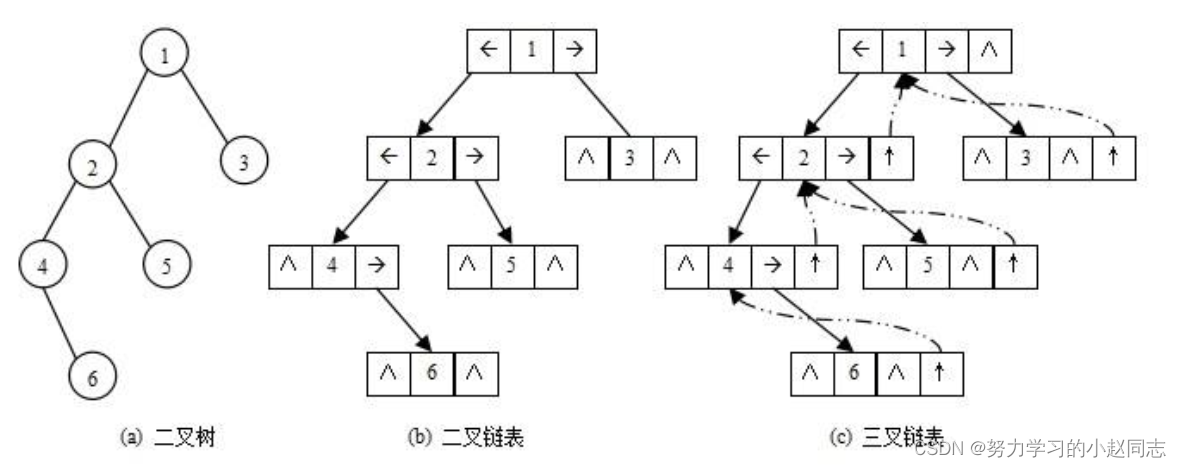
详解—数据结构《树和二叉树》
目录 一.树概念及结构 1.1树的概念 1.2树的表示 二.二叉树的概念及结构 2.1概念 2.2二叉树的特点 2.3现实中的二叉树 2.4数据结构中的二叉树 2.5 特殊的二叉树 2.6二叉树的存储结构 2.6.1二叉树的性质 2.6.2 顺序结构 2.6.3链式存储 三. 二叉树的链式结构的遍历 …...
菜单管理中icon图标回显
<el-table-column prop"icon" label"图标" show-overflow-tooltip algin"center"><template v-slot"{ row }"><el-icon :class"row.icon"></el-icon></template></el-table-column>...

Postman如何导出接口的几种方法
本文主要介绍了Postman如何导出接口的几种方法,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下 前言: 我的文章还是一贯的作风,简确用风格(简单确实有用)&…...
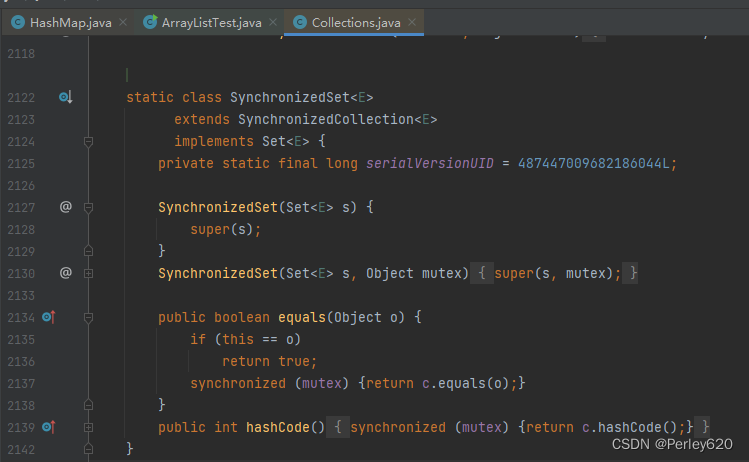
Java进阶(Set)——面试时Set常见问题解读 结合源码分析
前言 List、Set、HashMap作为Java中常用的集合,需要深入认识其原理和特性。 本篇博客介绍常见的关于Java中Set集合的面试问题,结合源码分析题目背后的知识点。 关于List的博客文章如下: Java进阶(List)——面试时L…...

【强化学习】12 —— 策略梯度(REINFORCE )
文章目录 前言策略梯度基于策略的强化学习的优缺点Example:Aliased Gridworld策略目标函数策略优化策略梯度利用有限差分计算策略梯度得分函数和似然比策略梯度定理蒙特卡洛策略梯度(Monte-Carlo Policy Gradient)Puck World Example Softmax随机策略 代…...
)
JDK 17 + Hadoop 3.3.5 + Spark 3.3.2 集群搭建保姆级避坑指南(CentOS 8.5 + VMware)
JDK 17 Hadoop 3.3.5 Spark 3.3.2 集群搭建实战避坑手册 当你第一次尝试在本地环境搭建大数据集群时,是否曾被各种兼容性问题、配置错误和莫名其妙的报错折磨得焦头烂额?本文将带你完整走一遍从零开始搭建基于JDK 17、Hadoop 3.3.5和Spark 3.3.2的集群…...

从LVGL官方例程到自定义界面:在Windows上用CodeBlocks模拟器快速玩转GUI设计
从LVGL官方例程到自定义界面:在Windows上用CodeBlocks模拟器快速玩转GUI设计 对于嵌入式开发者而言,图形用户界面(GUI)设计往往需要在硬件平台上反复烧录测试,效率低下。而LVGL模拟器配合CodeBlocks的组合,为开发者提供了一个在PC…...

GJB 128B-2021标准变更深度解析:VDMOS产品试验方法的影响与应对
1. GJB 128B-2021标准变更的核心要点 对于从事VDMOS产品研发和质量控制的工程师来说,2022年3月正式实施的GJB 128B-2021标准带来了不少值得关注的调整。相比旧版标准,这次修订在试验条件、热平衡判定、静电防护等多个关键环节都做出了具体规定。我仔细研…...

模型切换总报错?Trae 在模块四迁移中解决 3 类兼容性问题的配置要点
1. 模型切换总报错?不是模型的问题,是配置没对齐上下文契约 我在三个中型项目里反复遇到同一个现象:刚切完模型,Trae 就在右下角弹出红色提示——“Context initialization failed” 或 “Model adapter mismatch: expected Claude-3-haiku, got DeepSeek-VL-4”。不是模型…...

DWC_ether_qos驱动软复位实战:解决网络丢包与DMA死锁
1. 项目概述:从一次诡异的网络丢包说起最近在调试一块基于某款主流SoC的工控板卡时,遇到了一个让人头疼的问题:设备在长时间高负载运行后,网络会间歇性地出现严重丢包,甚至完全断连。重启网络服务能暂时恢复࿰…...

Linux内核中断处理机制深度解析:中断嵌套与异常打断原理
1. 中断处理中的“打断”迷思:一个内核老兵的深度剖析在Linux内核开发与调试的深水区里,中断处理机制就像一把双刃剑,它赋予了系统响应外部事件的实时性,却也带来了复杂性与不确定性。其中,一个经典且常被误解的问题就…...
,搞懂设备插上后到底经历了什么)
别再只盯着USB3.0速度了!深入链路训练状态机(LTSSM),搞懂设备插上后到底经历了什么
USB3.0链路训练状态机:从插入到识别的技术全景解析 当我们将一个USB3.0设备插入电脑时,那个短暂的"识别"过程背后,隐藏着一套精密的数字握手协议。这个看似简单的动作,实际上触发了物理层到协议层的多阶段协同工作&…...

Spring Boot 面试题详解:Spring Boot 核心原理、自动配置、启动流程、IoC 容器、Web 请求链路、事务、Actuator 与 JVM 线上排障全攻略
1. Spring Boot 到底是什么?为什么 Java 后端几乎绕不开它?1.1 它不是新语言,也不是替代 Spring,而是 Spring 应用的工程化脚手架Spring Boot 的出现,本质上是为了解决传统 Spring 项目启动慢、配置多、依赖难配、上线…...

FPGA硬解 vs 软件模拟:实测MiSTer在延迟和画质上到底强在哪?
FPGA硬解 vs 软件模拟:实测MiSTer在延迟和画质上到底强在哪? 在复古游戏的世界里,每一帧的延迟都可能决定《拳皇97》中一个连招的成败,每一像素的偏差都会影响《魂斗罗》子弹轨迹的判断。当硬核玩家们争论FPGA方案与软件模拟孰优孰…...

GitHub网络加速终极指南:如何实现10倍下载速度的智能优化方案
GitHub网络加速终极指南:如何实现10倍下载速度的智能优化方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾…...