基于机器视觉的银行卡识别系统 - opencv python 计算机竞赛
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的银行卡识别算法设计
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 算法设计流程
银行卡卡号识别技术原理是先对银行卡图像定位,保障获取图像绝对位置后,对图像进行字符分割,然后将分割完成的信息与模型进行比较,从而匹配出与其最相似的数字。主要流程图如图

1.银行卡号图像
由于银行卡卡号信息涉及个人隐私,作者很难在短时间内获取大量的银行卡进行测试和试验,本文即采用作者个人及模拟银行卡进行卡号识别测试。
2.图像预处理
图像预处理是在获取图像后必须优先进行的技术性处理工作,先对银行卡卡号图像进行色彩处理,具体做法与流程是先将图像灰度化,去掉图像识别上无用的信息,然后利用归一化只保留有效的卡号信息区域。
3.字符分割
字符分割是在对图像进行预处理后,在获取有效图像后对有效区域进行进一步细化处理,将图像分割为最小识别字符单元。
4.字符识别
字符识别是在对银行卡卡号进行字符分割后,利用图像识别技术来对字符进行分析和匹配,本文作者利用的模板匹配方法。
2.1 颜色空间转换
由于银行卡卡号识别与颜色无关,所以银行卡颜色是一个无用因素,我们在图像预处理环节要先将其过滤掉。另外,图像处理中还含有颜色信息,不仅会造成空间浪费,增加运算量,降低系统的整体效率,还会给以后的图像分析和处理带来干扰。因此,有必要利用灰度处理来滤除颜色信息。
灰度处理的实质是将颜色信息转化为亮度信息,即将原始的三维颜色信息还原为一维亮度信息。灰度化的思想是用灰度值g来表示原始彩色图像的R(绿色)、g(红色)和B(蓝色)分量的值,具体的流程设计如图
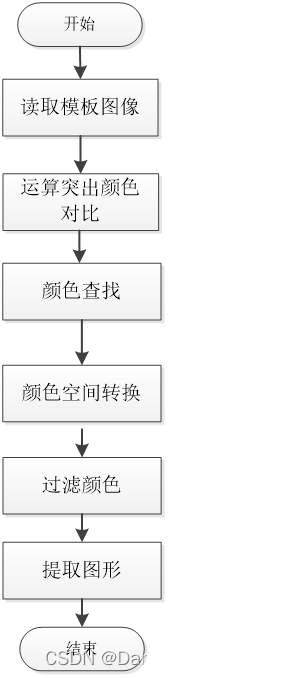
2.2 边缘切割
对于采集到的银行卡号图像,由于背景图案的多样性和卡号字体的不同,无法直接对卡号图像进行分割。分割前要准确定位卡号,才能得到有效区域。数字字符所在的区域有许多像素。根据该特征,通过设置阈值来确定原始图像中卡号图像的区域。银行卡图像的切边处理设计如图
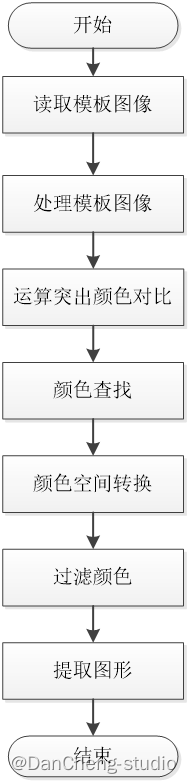
2.3 模板匹配
模板匹配是一种将需要识别的字符与已有固定模板进行匹配的算法技术,该技术是将已经切割好的字符图像逐个与模板数字图像进行对比分析,其原理就是通过数字相似度来衡量两个字符元素,将目标字符元素逐个与模板数字图像进行匹配,找到最接近的数字元素即可。匹配计算量随特征级别的增加而减少。根据第一步得到的特征,选择第二种相关计算方法来解决图像匹配问题。银行卡模板匹配流程设计如图
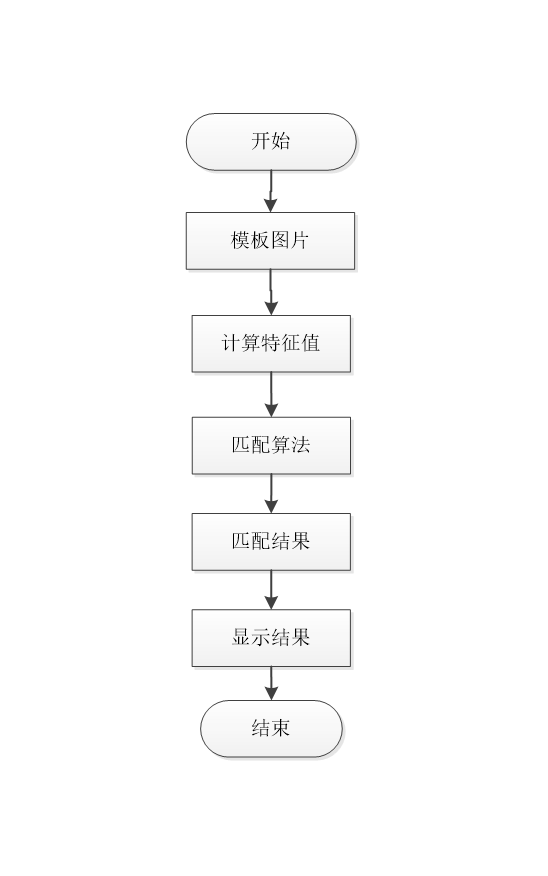
2.4 卡号识别
银行卡卡号识别有其独有的特性,因为目前市面上大多数银行卡卡号是凹凸不平的数字形式,如果使用传统的计算机字符识别技术已显然不适用,本文针对银行卡此类特点,研究了解决此类问题的识别方案。从银行卡待识别的凸凹字符进行预处理,然后根据滑块算法逐个窗口对银行卡字符进行匹配识别,卡号识别一般从切割后的图像最左端开始,设定截图选定框大小为64*48像素,因为银行卡所需要识别的字符一般为45像素左右。故而以此方式循环对卡片上所有数字进行匹配、识别,如果最小值大于设置的阈值,我们将认为这里没有字符,这是一个空白区域,并且不输出字符。同时,窗口位置J向下滑动,输出f<19&&j;+20<图像总长度并判断,最后循环得到字符数f、j。
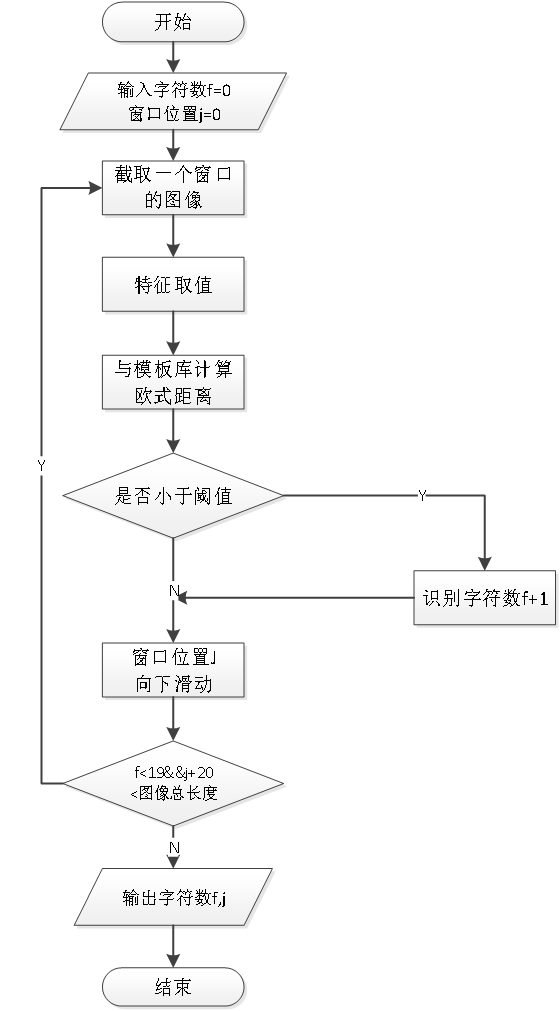
3 银行卡字符定位 - 算法实现
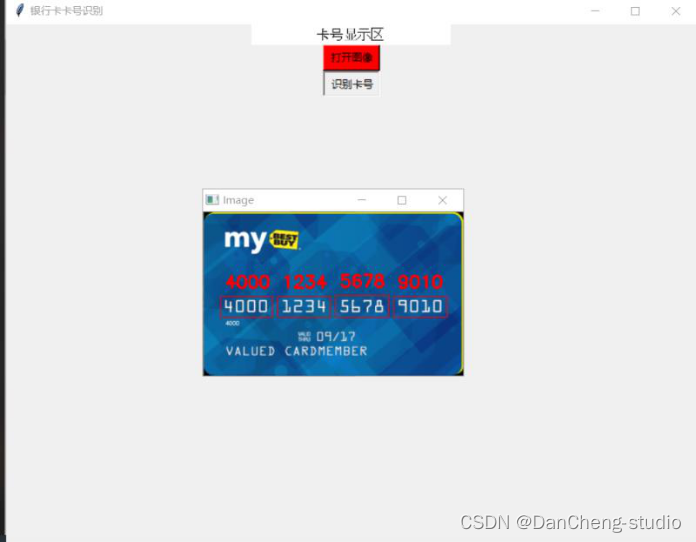
首先就是将整张银行卡号里面的银行卡号部分进行识别,且分出来,这一个环节学长用的技术就是faster-rcnn的方法
将目标识别部分的银行卡号部门且分出来,进行保存
主程序的代码如下(非完整代码):
#!/usr/bin/env pythonfrom __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionimport argparseimport osimport cv2import matplotlib.pyplot as pltimport numpy as npimport tensorflow as tffrom lib.config import config as cfgfrom lib.utils.nms_wrapper import nmsfrom lib.utils.test import im_detectfrom lib.nets.vgg16 import vgg16from lib.utils.timer import Timeros.environ["CUDA_VISIBLE_DEVICES"] = '0' #指定第一块GPU可用config = tf.ConfigProto()config.gpu_options.per_process_gpu_memory_fraction = 0.8 # 程序最多只能占用指定gpu50%的显存config.gpu_options.allow_growth = True #程序按需申请内存sess = tf.Session(config = config)CLASSES = ('__background__','lb')NETS = {'vgg16': ('vgg16_faster_rcnn_iter_70000.ckpt',), 'res101': ('res101_faster_rcnn_iter_110000.ckpt',)}DATASETS = {'pascal_voc': ('voc_2007_trainval',), 'pascal_voc_0712': ('voc_2007_trainval+voc_2012_trainval',)}def vis_detections(im, class_name, dets, thresh=0.5):"""Draw detected bounding boxes."""inds = np.where(dets[:, -1] >= thresh)[0]if len(inds) == 0:returnim = im[:, :, (2, 1, 0)]fig, ax = plt.subplots(figsize=(12, 12))ax.imshow(im, aspect='equal')sco=[]for i in inds:score = dets[i, -1]sco.append(score)maxscore=max(sco)# print(maxscore)成绩最大值for i in inds:# print(i)score = dets[i, -1]if score==maxscore:bbox = dets[i, :4]# print(bbox)#目标框的4个坐标img = cv2.imread("data/demo/"+filename)# img = cv2.imread('data/demo/000002.jpg')sp=img.shapewidth = sp[1]if bbox[0]>20 and bbox[2]+20<width:cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0]-20):int(bbox[2])+20] # 裁剪坐标为[y0:y1, x0:x1]if bbox[0]<20 and bbox[2]+20<width:cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0]):int(bbox[2])+20] # 裁剪坐标为[y0:y1, x0:x1]if bbox[0] > 20 and bbox[2] + 20 > width:cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0] - 20):int(bbox[2])] # 裁剪坐标为[y0:y1, x0:x1]path = 'cut1/'# 重定义图片的大小res = cv2.resize(cropped, (1000, 100), interpolation=cv2.INTER_CUBIC) # dsize=(2*width,2*height)cv2.imwrite(path+str(i)+filename, res)ax.add_patch(plt.Rectangle((bbox[0], bbox[1]),bbox[2] - bbox[0],bbox[3] - bbox[1], fill=False,edgecolor='red', linewidth=3.5))ax.text(bbox[0], bbox[1] - 2,'{:s} {:.3f}'.format(class_name, score),bbox=dict(facecolor='blue', alpha=0.5),fontsize=14, color='white')ax.set_title(('{} detections with ''p({} | box) >= {:.1f}').format(class_name, class_name,thresh),fontsize=14)plt.axis('off')plt.tight_layout()plt.draw()def demo(sess, net, image_name):"""Detect object classes in an image using pre-computed object proposals."""# Load the demo imageim_file = os.path.join(cfg.FLAGS2["data_dir"], 'demo', image_name)im = cv2.imread(im_file)# Detect all object classes and regress object boundstimer = Timer()timer.tic()scores, boxes = im_detect(sess, net, im)timer.toc()print('Detection took {:.3f}s for {:d} object proposals'.format(timer.total_time, boxes.shape[0]))# Visualize detections for each classCONF_THRESH = 0.1NMS_THRESH = 0.1for cls_ind, cls in enumerate(CLASSES[1:]):cls_ind += 1 # because we skipped backgroundcls_boxes = boxes[:, 4 * cls_ind:4 * (cls_ind + 1)]cls_scores = scores[:, cls_ind]# print(cls_scores)#一个300个数的数组#np.newaxis增加维度 np.hstack将数组拼接在一起dets = np.hstack((cls_boxes,cls_scores[:, np.newaxis])).astype(np.float32)keep = nms(dets, NMS_THRESH)dets = dets[keep, :]vis_detections(im, cls, dets, thresh=CONF_THRESH)def parse_args():"""Parse input arguments."""parser = argparse.ArgumentParser(description='Tensorflow Faster R-CNN demo')parser.add_argument('--net', dest='demo_net', help='Network to use [vgg16 res101]',choices=NETS.keys(), default='vgg16')parser.add_argument('--dataset', dest='dataset', help='Trained dataset [pascal_voc pascal_voc_0712]',choices=DATASETS.keys(), default='pascal_voc')args = parser.parse_args()return argsif __name__ == '__main__':args = parse_args()# model pathdemonet = args.demo_netdataset = args.dataset#tfmodel = os.path.join('output', demonet, DATASETS[dataset][0], 'default', NETS[demonet][0])tfmodel = r'./default/voc_2007_trainval/cut1/vgg16_faster_rcnn_iter_8000.ckpt'# 路径异常提醒if not os.path.isfile(tfmodel + '.meta'):print(tfmodel)raise IOError(('{:s} not found.\nDid you download the proper networks from ''our server and place them properly?').format(tfmodel + '.meta'))# set configtfconfig = tf.ConfigProto(allow_soft_placement=True)tfconfig.gpu_options.allow_growth = True# init sessionsess = tf.Session(config=tfconfig)# load networkif demonet == 'vgg16':net = vgg16(batch_size=1)# elif demonet == 'res101':# net = resnetv1(batch_size=1, num_layers=101)else:raise NotImplementedErrornet.create_architecture(sess, "TEST", 2,tag='default', anchor_scales=[8, 16, 32])saver = tf.train.Saver()saver.restore(sess, tfmodel)print('Loaded network {:s}'.format(tfmodel))# # 文件夹下所有图片进行识别# for filename in os.listdir(r'data/demo/'):# im_names = [filename]# for im_name in im_names:# print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')# print('Demo for data/demo/{}'.format(im_name))# demo(sess, net, im_name)## plt.show()# 单一图片进行识别filename = '0001.jpg'im_names = [filename]for im_name in im_names:print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')print('Demo for data/demo/{}'.format(im_name))demo(sess, net, im_name)plt.show()效果如下:


4 字符分割
将切分出来的图片进行保存,然后就是将其进行切分:
主程序的代码和上面第一步的步骤原理是相同的,不同的就是训练集的不同设置
效果图如下:
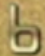
5 银行卡数字识别
仅部分代码:
import osimport tensorflow as tffrom PIL import Imagefrom nets2 import nets_factoryimport numpy as npimport matplotlib.pyplot as plt# 不同字符数量CHAR_SET_LEN = 10# 图片高度IMAGE_HEIGHT = 60# 图片宽度IMAGE_WIDTH = 160# 批次BATCH_SIZE = 1# tfrecord文件存放路径TFRECORD_FILE = r"C:\workspace\Python\Bank_Card_OCR\demo\test_result\tfrecords/1.tfrecords"# placeholderx = tf.placeholder(tf.float32, [None, 224, 224])os.environ["CUDA_VISIBLE_DEVICES"] = '0' #指定第一块GPU可用config = tf.ConfigProto()config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 程序最多只能占用指定gpu50%的显存config.gpu_options.allow_growth = True #程序按需申请内存sess = tf.Session(config = config)# 从tfrecord读出数据def read_and_decode(filename):# 根据文件名生成一个队列filename_queue = tf.train.string_input_producer([filename])reader = tf.TFRecordReader()# 返回文件名和文件_, serialized_example = reader.read(filename_queue)features = tf.parse_single_example(serialized_example,features={'image' : tf.FixedLenFeature([], tf.string),'label0': tf.FixedLenFeature([], tf.int64),})# 获取图片数据image = tf.decode_raw(features['image'], tf.uint8)# 没有经过预处理的灰度图image_raw = tf.reshape(image, [224, 224])# tf.train.shuffle_batch必须确定shapeimage = tf.reshape(image, [224, 224])# 图片预处理image = tf.cast(image, tf.float32) / 255.0image = tf.subtract(image, 0.5)image = tf.multiply(image, 2.0)# 获取labellabel0 = tf.cast(features['label0'], tf.int32)return image, image_raw, label0# 获取图片数据和标签image, image_raw, label0 = read_and_decode(TFRECORD_FILE)# 使用shuffle_batch可以随机打乱image_batch, image_raw_batch, label_batch0 = tf.train.shuffle_batch([image, image_raw, label0], batch_size=BATCH_SIZE,capacity=50000, min_after_dequeue=10000, num_threads=1)# 定义网络结构train_network_fn = nets_factory.get_network_fn('alexnet_v2',num_classes=CHAR_SET_LEN * 1,weight_decay=0.0005,is_training=False)with tf.Session() as sess:# inputs: a tensor of size [batch_size, height, width, channels]X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1])# 数据输入网络得到输出值logits, end_points = train_network_fn(X)# 预测值logits0 = tf.slice(logits, [0, 0], [-1, 10])predict0 = tf.argmax(logits0, 1)# 初始化sess.run(tf.global_variables_initializer())# 载入训练好的模型saver = tf.train.Saver()saver.restore(sess, '../Cmodels/model/crack_captcha1.model-6000')# saver.restore(sess, '../1/crack_captcha1.model-2500')# 创建一个协调器,管理线程coord = tf.train.Coordinator()# 启动QueueRunner, 此时文件名队列已经进队threads = tf.train.start_queue_runners(sess=sess, coord=coord)for i in range(6):# 获取一个批次的数据和标签b_image, b_image_raw, b_label0 = sess.run([image_batch,image_raw_batch,label_batch0])# 显示图片img = Image.fromarray(b_image_raw[0], 'L')plt.imshow(img)plt.axis('off')plt.show()# 打印标签print('label:', b_label0)# 预测label0 = sess.run([predict0], feed_dict={x: b_image})# 打印预测值print('predict:', label0[0])# 通知其他线程关闭coord.request_stop()# 其他所有线程关闭之后,这一函数才能返回coord.join(threads)最终实现效果:
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
基于机器视觉的银行卡识别系统 - opencv python 计算机竞赛
1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的银行卡识别算法设计 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng…...

大数据工具-kafkaUi-lite
1、kafkaUI-lite v1.0 已经发布,此版本更新内容包括: 可以实现 kafak/zookooper/redis 的界面化操作 kafka: 多环境管理、生产消息、消费消息、创建 topic、删除 topiczookeeper: 多环境管理、查看节点、查看节点数据redis: 多环境管理、查询数据2、kafkaUI-lite 介绍 史上…...

Vdue之模版语法指令过滤器计算属性监听属性
模板语法 Vue.js 使用了基于 HTML 的模板语法,允许开发者声明式地将 DOM 绑定至底层 Vue 实例的数据。所有 Vue.js 的模板都是合法的 HTML ,所以能被遵循规范的浏览器和 HTML 解析器解析。vue将模板编译成虚拟dom, 结合响应系统,V…...
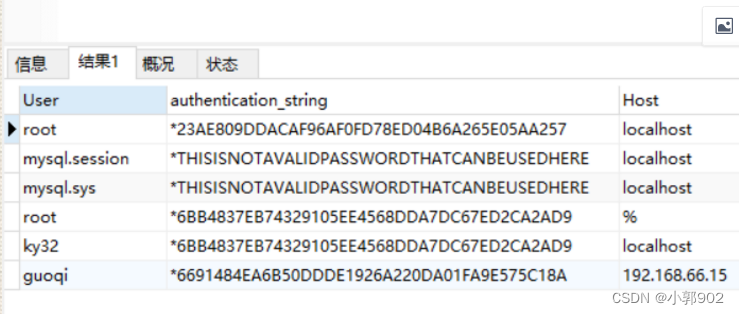
Mysql权限控制语句
1.创建用户 create user ky32localhost IDENTIFIED by 123456 create user:创建用户开头 ky32:用户名 localhost 新建的用户可以在哪些主机上登录 即可以使用ip地址,网段主机名 ky32localhost ky32192.168.233.22 ky32192.168.233.0/2…...

小程序如何导入配送账号
为了提高配送效率和用户体验,可以导入配送账号(包括电子面单快递物流账号、同城外卖配送账号)到小程序中。导入后,可以实现一键发货,无需手动回填单号。而且在小程序中可以查看到物流状态,对于同城配送&…...
ubuntu(18.04) 安装 blast 并在php中调用
1、下载 https://ftp.ncbi.nlm.nih.gov/blast/executables/blast/LATEST/2、解压,配置环境变量 tar zvxf ncbi-blast-2.14.1-x64-linux.tar.gz解压后改名为 blast 配置环境变量,可以不配置 使用的时候直接绝对路径使用(本次使用绝对路径&am…...
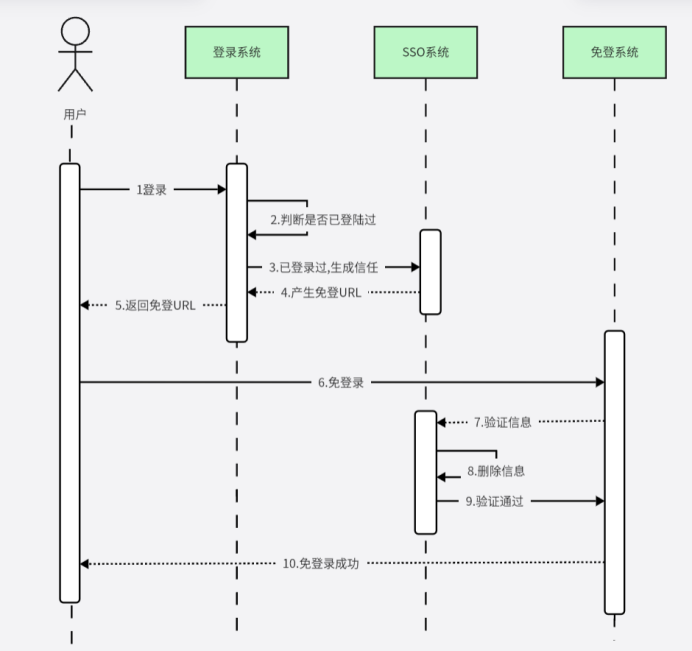
UML—时序图是什么
目录 前言: 什么是时序图: 时序图的组成元素: 1. 角色(Actor) 2. 对象(Object) 3. 生命线(LifeLine) 4. 激活期(Activation) 5. 消息类型(Message) 6.组合片段(Combined fragment) 时序图的绘制规则: 绘制时序图的3步: 1.划清边界…...

【每日一题Day364】LC2003每棵子树内缺失的最小基因值 | dfs
每棵子树内缺失的最小基因值【LC2003】 有一棵根节点为 0 的 家族树 ,总共包含 n 个节点,节点编号为 0 到 n - 1 。给你一个下标从 0 开始的整数数组 parents ,其中 parents[i] 是节点 i 的父节点。由于节点 0 是 根 ,所以 parent…...
 程序烧写完成但是没有现象 (自己做的板子))
调试记录 单片机GD32F103C8T6(兆易创新) 程序烧写完成但是没有现象 (自己做的板子)
1. 单片机GD32F103C8T6 的资料 CPU内核:ARM Cortex-M3 CPU最大主频:108MHz 工作电压范围:2.6V~3.6V 程序存储容量:64KB 程序存储器类型:FLASH RAM, 总容量:20KB GPIO端口数量:37 最…...

Leetcode刷题笔记--Hot91--100
1--汉明距离(461) 主要思路: 按位异或,统计1的个数; #include <iostream> #include <vector>class Solution { public:int hammingDistance(int x, int y) {int z x ^ y; // 按位异或int res 0;while(…...

算法训练一——链表
文章目录 已做...

【JAVA】类与对象的重点解析
个人主页:【😊个人主页】 系列专栏:【❤️初识JAVA】 文章目录 前言类与对象的关系JAVA源文件有关类的重要事项static关键字 前言 Java是一种面向对象编程语言,OOP是Java最重要的概念之一。学习OOP时,学生必须理解面向…...

ES6对象扩展
ES6对象扩展是指在ES6中新增的一些对象属性和方法,包括对象属性的简写、计算属性名、对象方法的简写、对象的可迭代性、拓展运算符等。 下面是一些常用的ES6对象扩展: 对象属性的简写 ES6中,当对象的属性名和赋值变量名相同时,…...
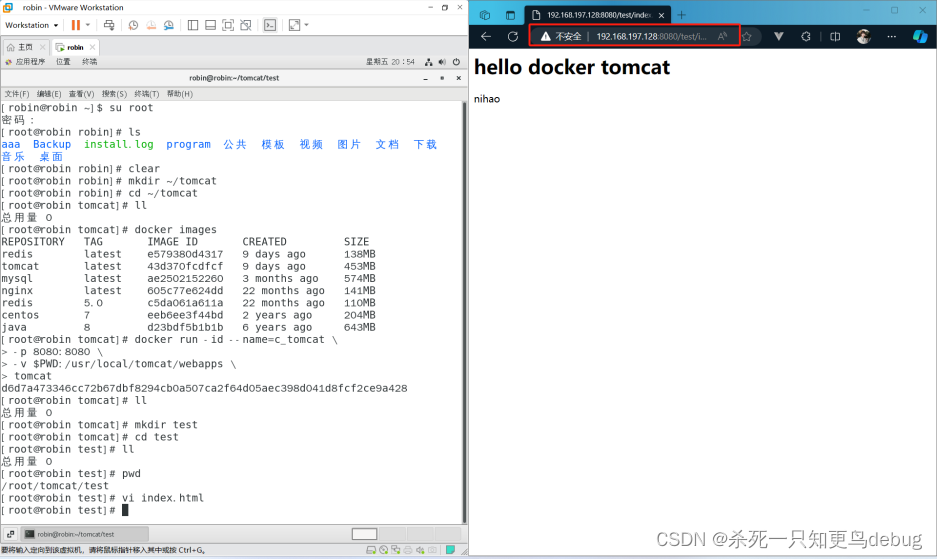
docker应用部署---Tomcat的部署配置
1. 搜索tomcat镜像 docker search tomcat2. 拉取tomcat镜像 docker pull tomcat3. 创建容器,设置端口映射、目录映射 # 在/root目录下创建tomcat目录用于存储tomcat数据信息 mkdir ~/tomcat cd ~/tomcatdocker run -id --namec_tomcat \ -p 8080:8080 \ -v $PWD:…...

TestCenter测试管理工具
estCenter(简称TC)一款广受好评的测试管理工具,让测试工作更规范、更有效率,实现测试流程无纸化,测试数据资产化。 产品概述 TC流程图 产品功能 一、案例库 案例库集中化管理,支持对测试用例集中管理&…...

索引切片复习
# loc方法 data2.loc[:4,[ymd, bWendu]]# iloc方法 —— 连续取字段 data2.iloc[:4,1:3]# iloc方法 —— 非连续取字段 data2.iloc[:4,[1,4]]# 直接选取单个字段 —— Series data2[ymd]# 直接选取单个字段 —— DataFrame data2[[ymd]]# 直接选取多个字段 —— DataFrame data…...

想入门网络安全,这些前置准备要做好!
网上有很多关于网络安全如何学习、如何入门的内容,但是仍然有很多小白不懂网络安全要怎么去学习。这是由于网络安全包含的范围确实比较广,学习的内容也比较多,所以在刚开始了解的时候确实会有点搞不清楚状况。 这里有一个方法,不要…...

Spark新特性与核心概念
一、Sparkshuffle (1)Map和Reduce 在shuffle过程中,提供数据的称之为Map端(Shuffle Write),接受数据的称之为Redeuce端(Shuffle Read),在Spark的两个阶段中,总…...
设计模式_状态模式
状态模式 介绍 设计模式定义案例问题堆积在哪里解决办法状态模式一个对象 状态可以发生改变 不同的状态又有不同的行为逻辑游戏角色 加载不同的技能 每个技能有不同的:攻击逻辑 攻击范围 动作等等1 状态很多 2 每个状态有自己的属性和逻辑每种状态单独写一个类 角色…...

css 某个元素被挤的显示不完整,如何显示完整
加一行 flex-shrink: 0;解决...

充电桩源头厂家怎么选?五大核心维度教你精准选型
充电桩源头厂家怎么选?五大核心维度教你精准选型新能源充电基础设施建设进入高速发展期,物业、城投、能源企业、物流园区等采购方在选择充电桩源头厂家时,往往陷入“品牌多、难分辨、怕踩坑”的困境:贴牌组装产品质量无保障、小厂…...

Multi-head Self-Attention Machanism
3. 多头自注意力机制(Multi-head Self-Attention Machanism) 多头注意力机制是在自注意力机制的基础上发展起来的,是自注意力机制的变体,旨在增强模型的表达能力和泛化能力。它通过使用多个独立的注意力头,分别计算注…...

【NotebookLM要点提取黄金法则】:20年AI工具实战总结的5大避坑指南与3步精准萃取法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM要点提取方法论全景概览 NotebookLM 是 Google 推出的面向研究者与知识工作者的 AI 原生笔记工具,其核心能力在于对用户上传文档(PDF、TXT、Google Docs)进…...

168MHz Cortex-M4+FPU+1MB Flash:STM32F405RGT6的高性能工业MCU参数解析
STM32F405RGT6:168MHz Cortex-M4工业MCU的高性能标杆在工业控制、电机驱动和物联网网关等嵌入式应用中,微控制器需要在处理性能、存储容量和外设集成度之间取得平衡。STM32F405RGT6是意法半导体STM32F4系列中的经典型号,基于ARM Cortex-M4内核…...

终极指南:使用EdgeRemover专业卸载工具彻底移除Microsoft Edge浏览器
终极指南:使用EdgeRemover专业卸载工具彻底移除Microsoft Edge浏览器 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRem…...

C++ STL set与multiset容器:红黑树实现、核心操作与性能优化指南
1. 容器概览:为什么我们需要 set 和 multiset?在C的日常开发里,尤其是处理需要快速查找、去重或排序的数据集合时,std::set和std::multiset这两个关联容器出场率极高。很多刚从顺序容器(如vector、list)转过…...

图形引擎的跨平台之舞:Skia与Direct2D的深度对话
图形引擎的跨平台之舞:Skia与Direct2D的深度对话 【免费下载链接】skia Skia is a complete 2D graphic library for drawing Text, Geometries, and Images. See documentation for contribution instructions. 项目地址: https://gitcode.com/gh_mirrors/ski/sk…...

listmonk容器资源监控告警:资源使用率阈值
listmonk容器资源监控告警:资源使用率阈值 你是否遇到过listmonk邮件列表管理器在高负载时突然卡顿?或者因服务器资源耗尽导致邮件发送中断?本文将详细介绍如何为listmonk容器配置资源监控与告警阈值,帮助你提前识别并解决资源瓶…...

iPXE脚本编程实战:自动化部署、故障诊断和定制化菜单终极指南
iPXE脚本编程实战:自动化部署、故障诊断和定制化菜单终极指南 【免费下载链接】ipxe iPXE network bootloader 项目地址: https://gitcode.com/gh_mirrors/ip/ipxe iPXE作为领先的开源网络启动引导程序,提供了强大的脚本编程功能,让网…...

OpenClaw Provider Manager:统一管理第三方服务的微服务治理框架
1. 项目概述与核心价值最近在折腾一些自动化流程和微服务治理,发现一个挺普遍但处理起来又有点琐碎的问题:如何高效、统一地管理那些分散在各个角落的第三方服务提供商(Provider)?比如短信发送、邮件推送、对象存储、支…...