力扣日记10.31-【栈与队列篇】前 K 个高频元素
力扣日记:【栈与队列篇】前 K 个高频元素
日期:2023.10.31
参考:代码随想录、力扣
347. 前 K 个高频元素
题目描述
难度:中等
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
- 1 <= nums.length <= 105
- k 的取值范围是 [1, 数组中不相同的元素的个数]
- 题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
进阶:你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
题解
class Solution {
#define SOLUTION 2
public:vector<int> topKFrequent(vector<int>& nums, int k) {
#if SOLUTION == 1// 时间复杂度: O(n) + O(n) + O(nlogn) + O(k) = O(nlogn)// 空间复杂度: O(n+n)unordered_map<int, int> cnt;for (const auto& n: nums) {cnt[n]++;}// 将哈希表的内容复制到 vector// 使用迭代器范围构造函数(iterator range constructor)创建 sortedVector// 这个构造函数接受两个迭代器,它会遍历 cnt 中的元素,然后复制它们到 sortedVector 中vector<pair<int, int>> sortedVector(cnt.begin(), cnt.end());// 按第二个值的大小对 vector 进行排序(从大到小)sort(sortedVector.begin(), sortedVector.end(), [](const pair<int, int>& a, const pair<int, int>& b) { // 匿名函数作为比较器参数return a.second > b.second; // 前者大于后者时返回true,表示前者应该在后者前面(大在前、小在后)});// 取前k个元素int count = 0;vector<int> result;for (const auto& pair : sortedVector) {result.push_back(pair.first);count++;if (count >= k) break;}return result;}
#elif SOLUTION == 2// unordered_map + 小顶堆// O(nlogk), O(n+k)// 之所以用堆,是因为没必要对n个元素都进行排序,只需要维护前k个元素即可// 1. 首先用map遍历一遍数组,确定每个数出现的频率unordered_map<int, int> cnt;for (const auto& n: nums) {cnt[n]++;}// 2. 使用小顶堆遍历map,维护出现频率最高的前k个元素// 小顶堆:本质是一个二叉树,每个父结点的值小于子结点,即根结点的值是最小的,值从小到大排列// 关于为什么用小顶堆而不是用大顶堆:/*如果是大顶堆的话,由于其仅维护k个元素,每次push进元素时都需要pop掉根结点元素而根结点是值最大的元素,这样的话会导致最后大顶堆中都是出现频率最低的前k个元素所以要用小顶堆,每次pop元素弹出值最小的元素,维护出现频率最高的前k个元素*/// 小顶堆通过优先级队列实现priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;// 用固定大小为k的小顶堆,扫面所有频率的数值for (unordered_map<int, int>::iterator it = cnt.begin(); it != cnt.end(); it++) {pri_que.push(*it); // 把it指向的<key,value>放进队列if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为kpri_que.pop();}}// 3. 找出前K个高频元素,因为小顶堆先弹出的是最小的,所以倒序来输出到数组vector<int> result(k);for (int i = k - 1; i >= 0; i--) {result[i] = pri_que.top().first;pri_que.pop();}return result;}// 小顶堆class mycomparison {public:bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {return lhs.second > rhs.second; // 为什么是>(大的在前,小的在后???)}};
#endif
};
复杂度
- 哈希map + 快排:
- 时间复杂度:O(nlogn)
- 空间复杂度:O(n)
- 哈希map + 小顶堆
- 时间复杂度:O(nlogk)
- 空间复杂度:O(n)
思路总结
- 解法1:哈希map + 快排
- 哈希map不能直接排序,要转换为vector才能进行排序
- 1.将哈希表的内容复制到 vector
- 2.使用迭代器范围构造函数(iterator range constructor)创建 sortedVector
- 这个构造函数接受两个迭代器,它会遍历 cnt 中的元素,然后复制它们到 sortedVector 中
vector<pair<int, int>> sortedVector(cnt.begin(), cnt.end());
- 3.按第二个值的大小对 vector 进行排序(从大到小)
sort(sortedVector.begin(), sortedVector.end(), [](const pair<int, int>& a, const pair<int, int>& b) { // 匿名函数作为比较器参数return a.second > b.second; // 前者大于后者时返回true,表示前者应该在后者前面(大在前、小在后)});
- 哈希map不能直接排序,要转换为vector才能进行排序
- 解法2:哈希map + 小顶堆
- 之所以用小顶堆而不用快排,是因为没必要对n个元素都进行排序,只需要维护前k个元素即可(快排需要对n个元素进行排序,O(nlogn),小顶堆每次pop和push一个元素只需要logk,即对所有元素的总时间复杂度为O(nlogk)
- 思路步骤:
- 1.首先用map遍历一遍数组,确定每个数出现的频率
- 2.使用小顶堆遍历map,维护出现频率最高的前k个元素
- 小顶堆:本质是一个二叉树,每个父结点的值小于子结点,即根结点的值是最小的,值从小到大排列
- 关于为什么用小顶堆而不是用大顶堆:
如果是大顶堆的话,由于仅维护k个元素,每次push进元素时都需要pop掉根结点元素
而根结点是值最大的元素,这样的话会导致最后大顶堆中都是出现频率最低的前k个元素
所以要用小顶堆,每次pop元素弹出值最小的元素,维护出现频率最高的前k个元素 - 小顶堆通过优先级队列实现:其中比较器设置为"左值>右值"(可能与优先级队列的底层实现有关)—— 注意这与快排cmp是相反的,快排cmp“左值>右值"是从大到小降序排列,而优先级队列"左值>右值"是小顶堆(根小子大)
- 3.找出前K个高频元素,因为小顶堆先弹出的是最小的(取first即元素的键),所以倒序来输出到数组
- 学会小顶堆的实现以及小顶堆遍历的写法:
// 小顶堆实现
class mycomparison {
public:bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {return lhs.second > rhs.second;}
};
// 优先级队列定义与遍历
priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pri_que;
// 参数1:优先级队列的元素类型,参数2:优先级队列自身类型,参数3:优先级队列的比较器(决定是小顶堆还是大顶堆)
for (unordered_map<int, int>::iterator it = cnt.begin(); it != cnt.end(); it++) {pri_que.push(*it); // 把it指向的<key,value>放进队列if (pri_que.size() > k) { // 如果堆的大小大于了K,则队列弹出,保证堆的大小一直为kpri_que.pop();}
}
相关文章:

力扣日记10.31-【栈与队列篇】前 K 个高频元素
力扣日记:【栈与队列篇】前 K 个高频元素 日期:2023.10.31 参考:代码随想录、力扣 347. 前 K 个高频元素 题目描述 难度:中等 给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意…...

TensorFlow案例学习:简单的音频识别
前言 以下内容均来源于官方教程:简单的音频识别:识别关键字 音频识别 下载数据集 下载地址:http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 可以直接浏览器访问下载。 下载完成后将其解压到项目…...

css小程序踩坑记录
写标签设置距离 一直设置不动 写个双层 设置动了 神奇 好玩...

Android sqlite分页上传离线订单后删除
1、判断订单表的的总数是否大于0,如果大于0开始上传订单 public int getOrderCount() {String query "SELECT COUNT(*) FROM " TABLE_NAME;Cursor cursor db.rawQuery(query, null);int count 0;if (cursor.moveToFirst()) {count cursor.getInt(0);…...
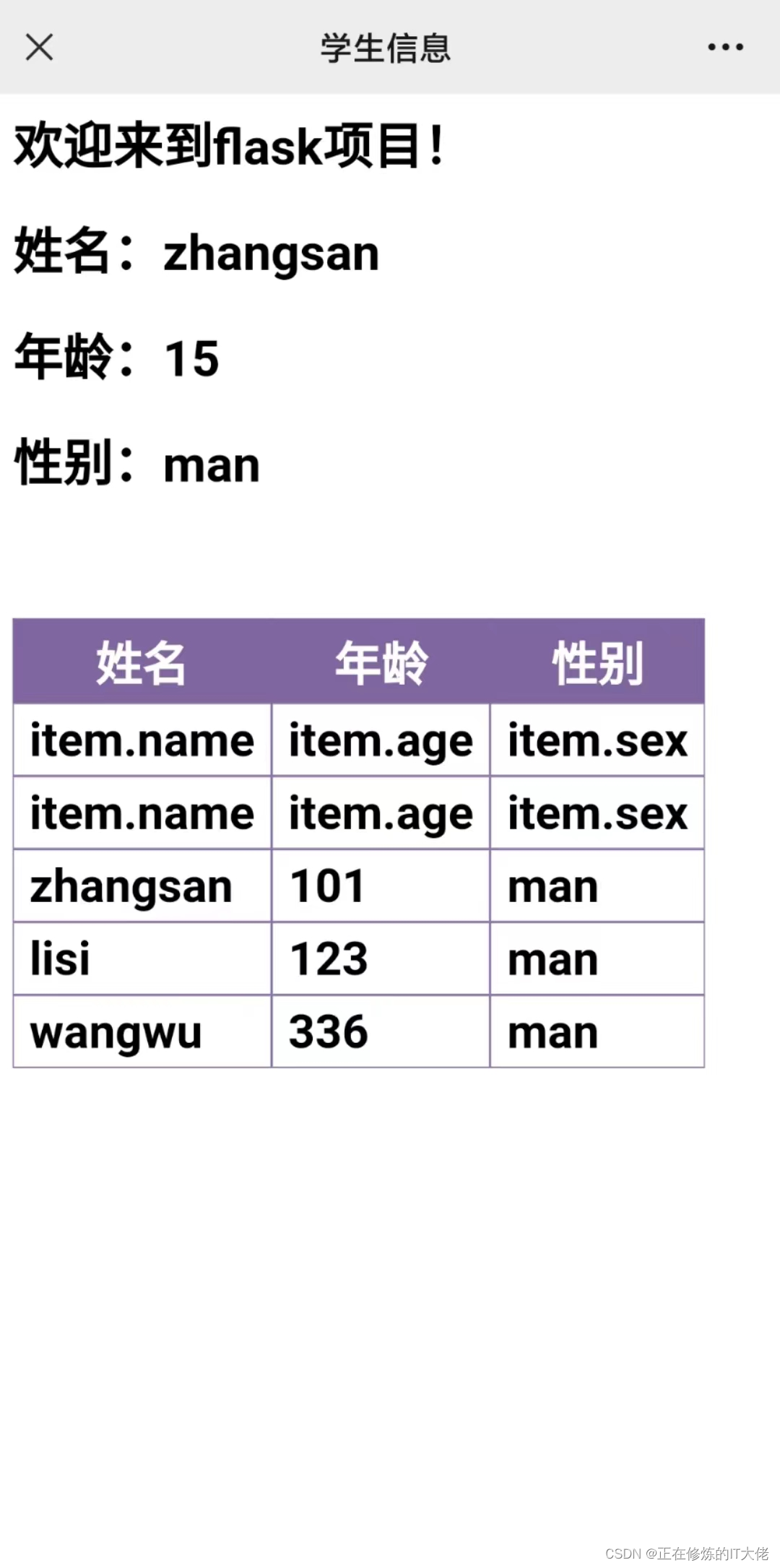
Flask基本教程以及Jinjia2模板引擎简介
flask基本使用 直接看代码吧,非常容易上手: # 创建flask应用 app Flask(__name__)# 路由 app.route("/index", methods[GET]) def index():return "FLASK:欢迎访问主页!"if __name__ "__main__"…...
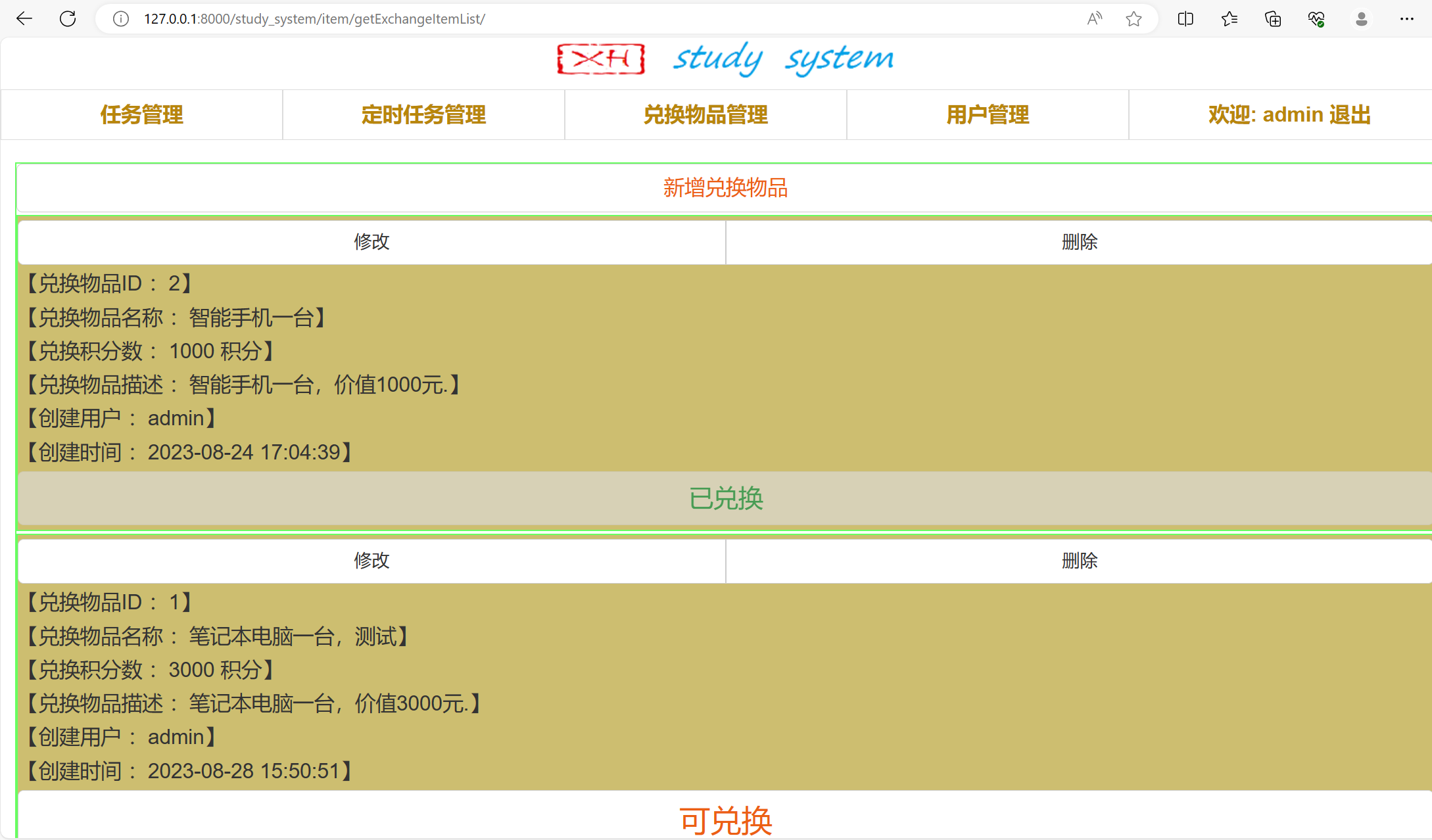
Django实战项目-学习任务系统-兑换物品管理
接着上期代码框架,开发第5个功能,兑换物品管理,再增加一个学习兑换物品表,主要用来维护兑换物品,所需积分,物品状态等信息,还有一个积分流水表,完成任务奖励积分,兑换物品…...

jmeter和postman你选哪个做接口测试?
软件测试行业做功能测试和接口测试的人相对比较多。在测试工作中,有高手,自然也会有小白,但有一点我们无法否认,就是每一个高手都是从小白开始的,所以今天我们就来谈谈一大部分人在做的接口测试,小白变高手…...

mac版本 Adobe总是弹窗提示验证问题如何解决
来自: mac软件下载macsc站 mac电脑使用过程中总是弹出Adobe 的弹窗提示,尤其是打开Adobe的软件,更是频繁的弹出提示: Your Adobe app is not genuine. Adobe reserves the right to disable this software after a 0 grace period…...

钡铼技术ARM工控机在机器人控制领域的应用
ARM工控机是一种基于ARM架构的工业控制计算机,用于在工业自动化领域中进行数据采集、监控、控制和通信等应用。ARM(Advanced RISC Machine)架构是一种低功耗、高性能的处理器架构,广泛应用于移动设备、嵌入式系统和物联网等领域。…...

HTML+CSS+JS实现计算器
🙈作者简介:练习时长两年半的Java up主 🙉个人主页:程序员老茶 🙊 ps:点赞👍是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全栈,…...
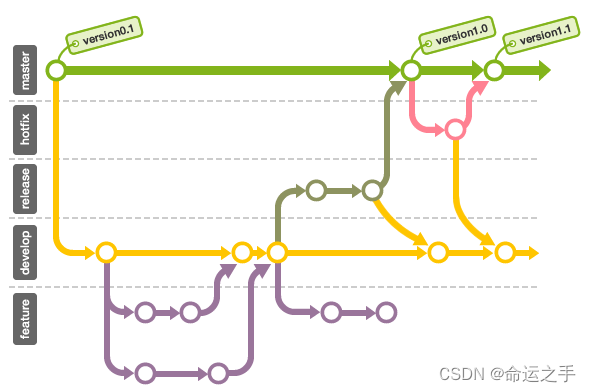
Git工作原理和常见问题处理方案
博客定位Git工作区域工作区域划分暂存区设计目的 Git基本操作核心操作初始化和配置指令 HEAD指针Git版本回滚指令介绍reset模式reset hard使用场景reset soft使用场景reset mixed使用场景reset使用注意事项checkout使用场景 Git分支管理什么是分支分支应用场景分支相关指令被合…...
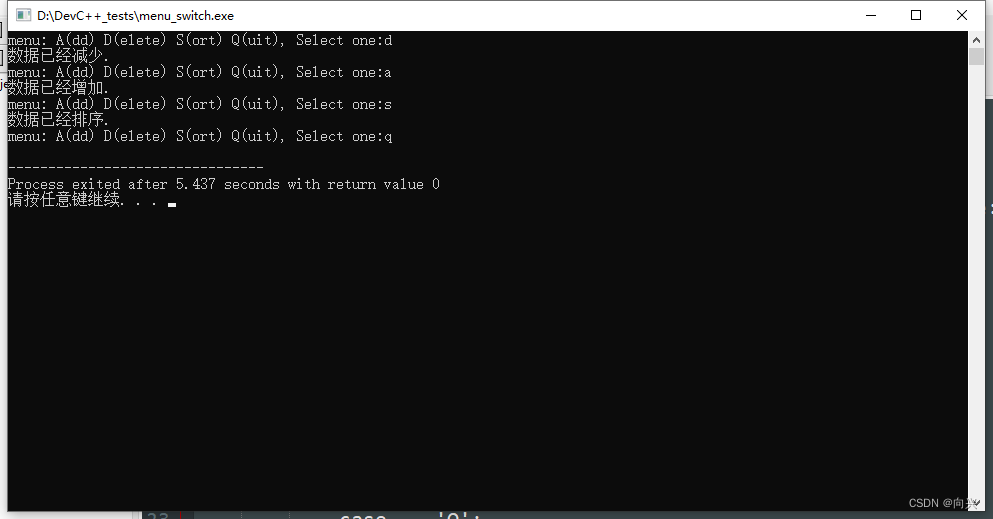
C++-实现一个简单的菜单程序
C-实现一个简单的菜单程序 1,if-else语句实现1.1,代码实现1.2,功能检测 2,switch语句实现2.1,代码实现2.2,功能检测 1,if-else语句实现 实现一个简单的菜单程序,运行时显示"Men…...

Git更新 fork 的仓库
文章目录 确保本地仓库是最新的配置上游存储库(remote upstream)获取上游存储库的更改合并上游存储库的更改推送更改到你 fork 的仓库 确保本地仓库是最新的 在命令行中,导航到存储库的本地副本所在的目录,并执行以下命令: # 切换到主分支 …...

chorme安装esay scholar及chrome 无法从该网站添加应用、扩展程序和用户脚本解决方案
问题描述 如题,博主想安装easy scholar用于查询论文的分区,结果安装了半天一直出现chrome 无法从该网站添加应用、扩展程序和用户脚本解决方案的问题。 解决方案 先从这个网址下载:https://www.easyscholar.cc/download 然后对下载好的文…...
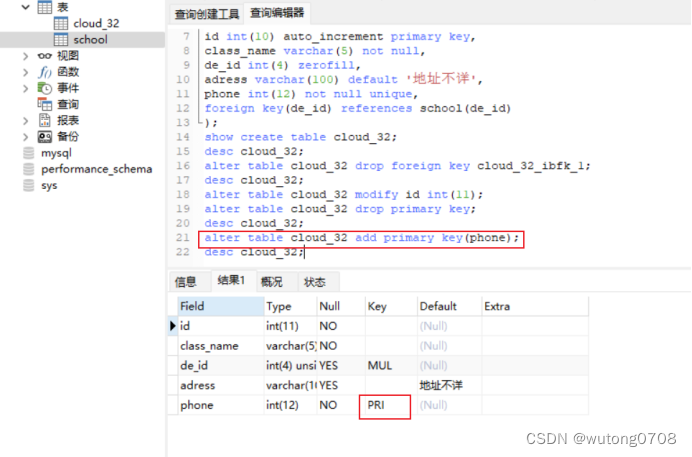
数据库-扩展语句,约束方式
扩展语句: 例: 自增长: auto_increment:表示该字段可以自增长,默认从一开始,每条记录会自动递增1 复制: 通过like这个语法直接复制ky32的表结构,只能复制表结构,不能复制表里面的…...
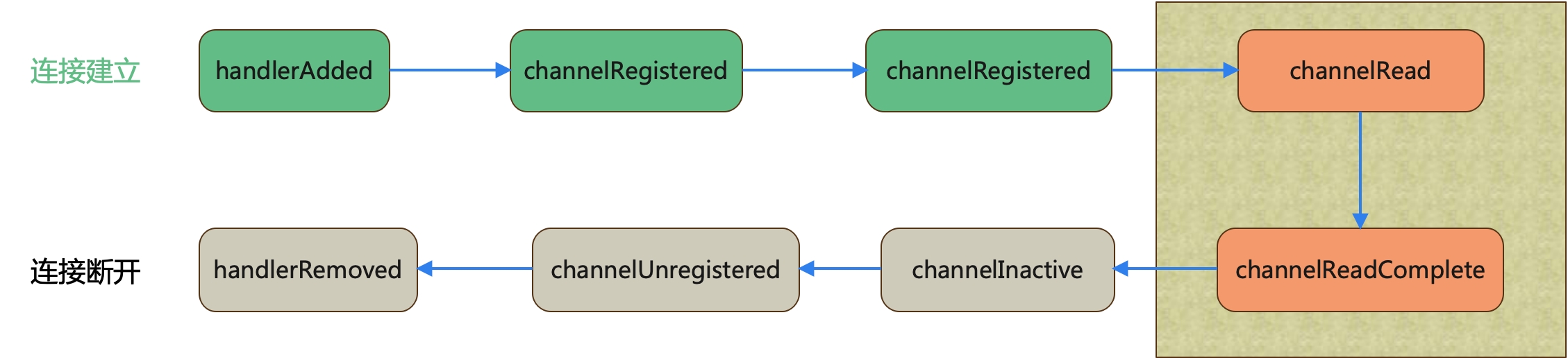
精密数据工匠:探索 Netty ChannelHandler 的奥秘
通过上篇文章(Netty入门 — Channel,把握 Netty 通信的命门),我们知道 Channel 是传输数据的通道,但是有了数据,也有数据通道,没有数据加工也是没有意义的,所以今天学习 Netty 的第四…...

Python四种基本结构的操作
列表 列表的创建有两种方法 SampleList [] SampleList list() 列表中元素的添加 append(obj):在列表末尾添加元素obj extend(seq):在列表末尾添加多个值,使用extend()函数,seq是一个可迭代对象,否则报错。 Inser…...

Eureka:com.netflix.discovery.TimedSupervisorTask - task supervisor timed out
1、原因是spring cloud netflix中,某个服务挂掉了或者是执行某个任务时间过长,而没有发送给Eureka心跳 ,导致调用不到指定的服务,所以检查被调用服务器是否有问题。 2、有可能是某一个微服务自身内部G了,导致没有向eu…...

1.spark standalone环境安装
概述 环境是spark 3.2.4 hadoop版本 3.2.4,所以官网下载的包为 spark-3.2.4-bin-hadoop3.2.tgz 在具体安装部署之前,需要先下载Spark的安装包,进到 spark的官网,点击download按钮 使用Spark的时候一般都是需要和Hadoop交互的&a…...
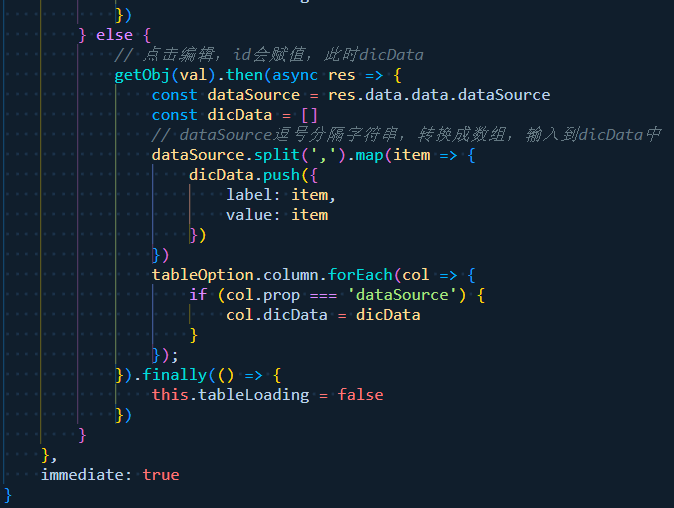
【问题解决】 avue dicUrl 动态参数加载字典数据(已解决)
事情是这样的,用了avue-crud组件,配置了一个option。 现在有一列source属性要展示为 多选的下拉框 ,当然问题不在这而在于,选项是需要根据同级别属性id去拿的。也就是option.column.source 的配置中 需要该行的option.col…...

如何在5分钟内掌握Illustrator智能填充神器Fillinger
如何在5分钟内掌握Illustrator智能填充神器Fillinger 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为复杂的图案填充耗费数小时吗?今天我要为你介绍一款能彻底改变…...

魔兽争霸3终极优化指南:7步让你的经典游戏在现代电脑上焕发新生
魔兽争霸3终极优化指南:7步让你的经典游戏在现代电脑上焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为一款经典的即…...

基于MCP协议构建AI工具服务器:连接Web与AI的标准化适配器
1. 项目概述:一个连接Web与AI的“万能适配器”如果你正在尝试让AI助手(比如ChatGPT、Claude)去访问一个网站、查询实时天气、或者控制你的智能家居,你可能会发现一个核心难题:这些大模型本身是“离线”的,它…...

WindowsCleaner 终极指南:如何轻松解决C盘爆红和系统卡顿问题
WindowsCleaner 终极指南:如何轻松解决C盘爆红和系统卡顿问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经遇到过这样的场景:…...

3步轻松掌握:163MusicLyrics歌词下载完全指南
3步轻松掌握:163MusicLyrics歌词下载完全指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量的LRC歌词而烦恼吗?163MusicLyri…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...

OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程
OpenCore Legacy Patcher终极指南:让老Mac免费运行最新macOS的完整教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

基于大语言模型的本地语义搜索工具LLocalSearch部署与应用指南
1. 项目概述:一个能“读懂”你电脑的本地搜索工具 如果你和我一样,电脑里塞满了各种文档、邮件、聊天记录和代码片段,那么“找东西”这件事,绝对能排进日常最耗时的任务前三。传统的文件搜索,比如Windows自带的搜索或者…...

虚实实景双向映射,升级高端楼宇精细化透明治理
虚实实景双向映射,升级高端楼宇精细化透明治理副标题:原生引擎驱动动态三维场景重构,结合无感化坐标解算、遮挡自适应跨镜接续、身体指纹无源身份匹配,构筑难以复刻、适配极强的楼宇透明化技术壁垒一、方案总览当下高端楼宇运营治…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...