HDFS工作流程和机制
HDFS写数据流程(上传文件)
核心概念--Pipeline管道
HDFS在上传文件写数据过程中采用的一种传输方式。
线性传输:客户端将数据写入第一个数据节点,第一个数据节点保存数据之后再将快复制到第二个节点,第二节点复制给第三节点。
ACK应达响应:确认字符
在数据通信中,接受方发给发送方的一种传输类控制字符。表示发来的数据已经确认接受无误。
在HDFS Pipeline管道传输数据过程中,传输的反方向会进行ACK校验,确保数据传输安全。
默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefualt指定
第一块副本:优先客户端本地,否则随机
第二块副本:不同于第一块副本的不同机柜
第三块副本:第二块副本相同机架不同机器
流程
1.HDFS客户端创建实例对象DistributedFileSystem,该对象中封装了与HDFS文件系统操作的相关方法
2.调用DistributedFileSystem对象的Create()方法,通过RPC请求NameNode创建文件。NameNode执行各种检查判断:目标文件是否存在,父目录是否存在,客户端是否具有创建该文件的权限。检查通过,NameNode就会成为本次请求下一条记录,返回FSDataOutPutStream输入流对象给客户端用于写入数据。
3.客户端通过FSDateOutput输入流开始写入数据
4.客户端写入数据时,将数据分成一个个数据包默认64K,内部组件DataStream请求N阿门哦的挑选出合适的存储数据副本DataNode地址,默认是3副本存储。
5.传输的反方向上,会通过ACK机制校验数据数据包传输是否成功;
6.客户端完成写入后,在FSDDataOutPutStream输出流上调用close()方法关闭
7.DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
MapReduce的核心思想(先分后合,分而治之)
1.Map表示第一个阶段,负责拆分“拆分”,即把复杂的任务分解成若干个“简单的子任务”来并行处理。可以进行拆分的前提是这些小任务可以进行并行计算,彼此间没有依赖关系。
2.reduce是第二阶段,负责合并:即对map阶段的结果进行全局汇总
3.这两个阶段合起来正是MapReduce的思想
Hadoop MapReduce 的设置构思
Map:对一组数据元素进行某种重复式的处理
Reduce:对Map的中间结果进行某种进一步的结果整理
分布式式计算是一种方法,和集中计算是相对的。
分布式计算是将应用分解成许多晓得部分,分配给多个多台计算机进行处理
MapReduce实例进程
一个完整的MapReduce程序在分布式运行时有三类
1.MRAppMaster:负责整个MR程序的过程调度及状态协调
2.MapTask:负责map阶段的整个数据;流程
3.ReduceTask:负责reduce阶段的整个数据处理流程
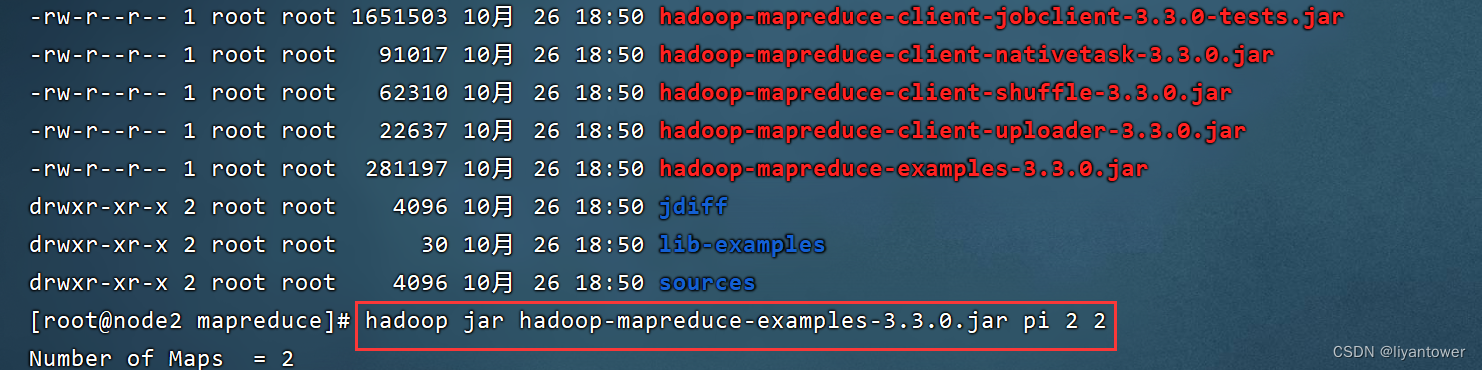
Hadoop MapReduce官方示例--圆周率PI评估
1.运行MapReduce程序评估一下圆周率的值,执行中可以去Yarn页面上观察程序的执行情况。
第一个参数:pi表示MapReduce执行圆周率计算任务
第二个参数:用于指定map阶段运行任务task次数,并发度,这里是0;
第三个参数:用于指定每个map任务取样的个数。这里是50。
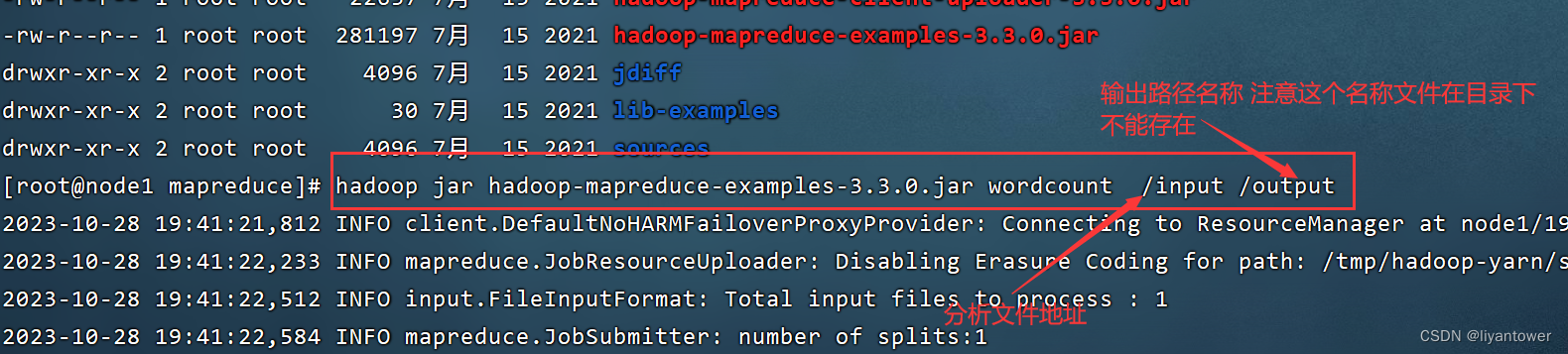
第二个实例wordcount单词词频统计
wordcount算是大数据计算领域经典的入门案列,相当于Helloworld
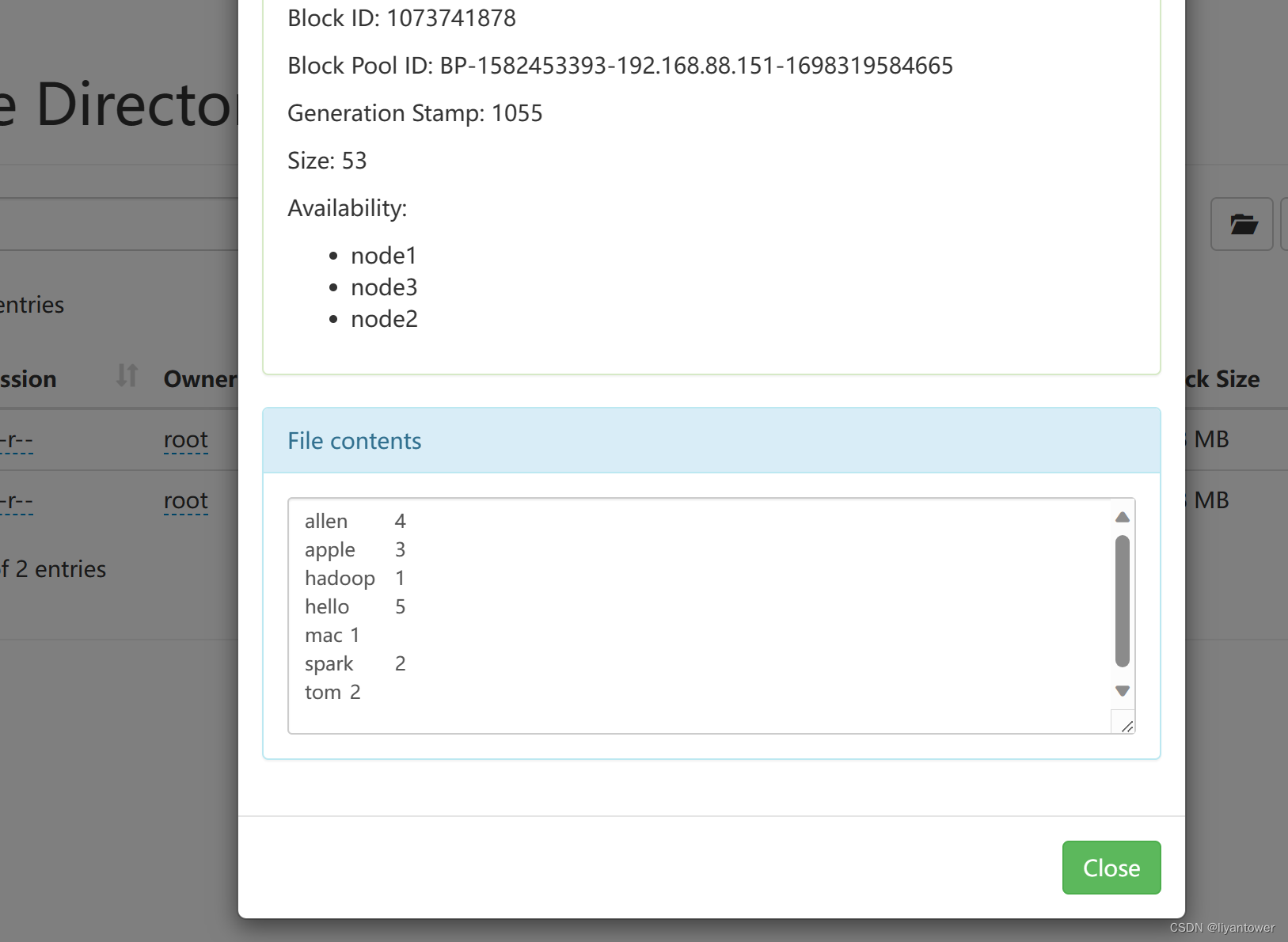
map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是单词《单词,1》
shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对
reduce阶段核心:处理shuffle完的一组数据,该数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总词数。
map阶段执行过程
第一个阶段:把输入目录下文件按照一定的标准逐个逻辑切片,形成逻辑切片。默认是128MB,每一个切片由一个MapTask处理。
第二阶段:对切片中的数据按照一定的规则读取解析返回《key,Value》默认的是按行读取数据
第三阶段:调用Mapper中类中的map方法处理数据,调用一次map方法处理数据
第四个阶段:按照一定的规则对Map输出的键值进行分区parting。默认不分区,因为只有一个reducetask分区的数量就是reducetask运行的数量。
第五个阶段:Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候进行key进行排序sort
第六阶段:对所有溢出文件进行最终的merge合并,成为一个文件。
reduce阶段执行流程
第一阶段:reducetask会主动从MapTask复制拉取属于自己处理的数据
第二阶段:把拉取来的数据,全部进行合并merge,即把分散的数据合并成一个大的数据,在对合并后的数据进行拍讯
第三阶段:对排序后的键值对调用reduce方法,键排序的键值对调用一次的reduce方法。最后把这些输出的键值,写入到HDFS文件中。
Shuffle阶段执行流程
map产生的输出开始到Reduce取得的数据作为输入之前的过程称为shuffle
1.Mapshuffle:MapReduce任务中的Map输出进行分区、排序和合并。Mapshuffle将Map输出按照键进行划分,然后将每个键分配给某个Reducer任务处理。同时,Mapshuffle还可以对Map输出进行排序,可以按照键或值进行排序。排序可以使得Reducer任务更容易合并相同键的记录,减少网络传输和磁盘I/O开销。最终,Mapshuffle将分好组、排序好的Map输出传递给Reducer任务进行处理。
2.Reduceshuffle:Copy阶段-Merge阶段-Sort阶段
shuffle中频繁涉及到数据在内存、磁盘之间的多次往复。
相关文章:
HDFS工作流程和机制
HDFS写数据流程(上传文件) 核心概念--Pipeline管道 HDFS在上传文件写数据过程中采用的一种传输方式。 线性传输:客户端将数据写入第一个数据节点,第一个数据节点保存数据之后再将快复制到第二个节点,第二节点复制给…...

CMMI/ASPICE认证咨询及工具服务
服务概述 质量专家戴明博士的名言“如果你不能描述做事情的过程,那么你不知道你在做什么”。过程是连接有能力的工程师和先进技术的纽带,因此产品开发过程直接决定了产品的质量和研发的效率。 经纬恒润可结合多体系要求,如IATF16949\ISO26262…...
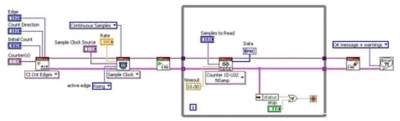
【NI-DAQmx入门】计数器
1.计数器的作用 NI产品的计数器一般来说兼容TTL信号,定义如下:0-0.8V为逻辑低电平,2~5V为高电平,0.8-2V为高阻态,最大上升下降时间为50ns。 计数器可以感测上升沿(从逻辑低到逻辑高的转变)和下降…...

Python爬取读书网的图片链接和书名并保存在数据库中
一个比较基础且常见的爬虫,写下来用于记录和巩固相关知识。 一、前置条件 本项目采用scrapy框架进行爬取,需要提前安装 pip install scrapy# 国内镜像 pip install scrapy -i https://pypi.douban.com/simple 由于需要保存数据到数据库,因…...

js解决加油站
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。 给定两个整数数组 gas 和 cost &…...
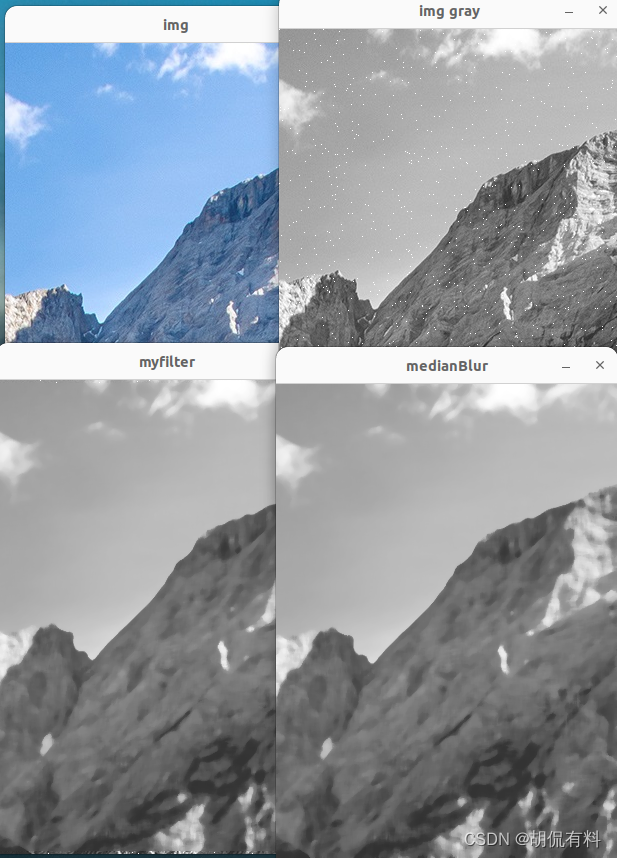
【c++|opencv】二、灰度变换和空间滤波---5.中值滤波
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 1. 中值滤波 #include<iostream> #include<opencv2/opencv.hpp> #include"Salt.h"using namespace cv; using namespace std;voi…...

python之pytorch多进程
目录 1、创建并运行并行进程 2、使用队列(Queue)来共享数据 3、进程池 4、进程锁 5、比较使用多进程和使用单进程执行一段代码的时间消耗 6、共享变量 多进程是计算机科学中的一个术语,它是指同时运行多个进程,这些进程可以…...

sqoop 抽数报错com.mysql.cj.exceptions.WrongArgumentException: HOUR_OF_DAY: 2 -> 3
文章目录 1.sqoop 抽数报错: Caused by: com.mysql.cj.exceptions.WrongArgumentException: HOUR_OF_DAY: 2 -> 3 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructor…...
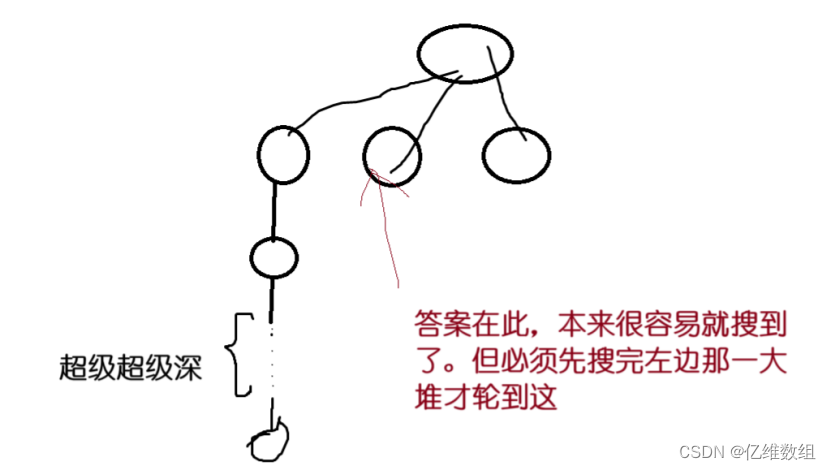
【Acwing170】加成序列(dfs+迭代加深+剪枝)题解和一点感想
本思路来自acwing算法提高课 题目描述 看本文需要准备的知识 1.dfs算法基本思想 2.对剪枝这个词有个简单的认识 迭代加深思想和此题分析 首先,什么是迭代加深呢?当一个问题的解有很大概率出现在递归树很浅的层,但是这个问题的解本身存在…...
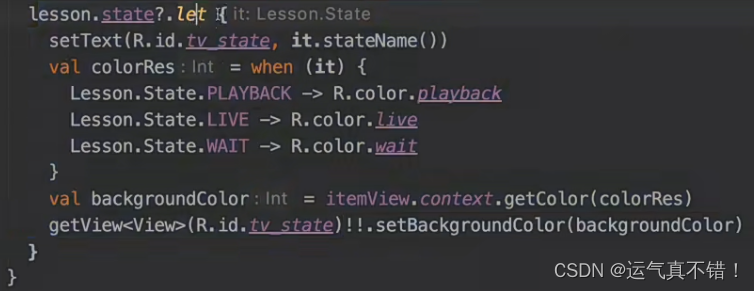
Android开发知识学习——Kotlin进阶
文章目录 次级构造主构造器init 代码块构造属性data class相等性解构Elvis 操作符when 操作符operatorLambdainfix 函数嵌套函数注解使用处目标函数简化函数参数默认值扩展函数类型内联函数部分禁用用内联具体化的类型参数抽象属性委托属性委托类委托 Kotlin 标准函数课后题 次…...

iOS使用AVCaptureSession实现音视频采集
AVCaptureSession配置采集行为并协调从输入设备到采集输出的数据流。要执行实时音视频采集,需要实例化采集会话并添加适当的输入和输出。 AVCaptureSession:管理输入输出音视频流AVCaptureDevice:相机硬件的接口,用于控制硬件特性…...

springboot和flask整合nacos,使用openfeign实现服务调用,使用gateway实现网关的搭建(附带jwt续约的实现)
环境准备: 插件版本jdk21springboot 3.0.11 springcloud 2022.0.4 springcloudalibaba 2022.0.0.0 nacos2.2.3(稳定版)python3.8 nacos部署(docker) 先创建目录,分别创建config,logs…...
深入浅出排序算法之基数排序
目录 1. 前言 1.1 什么是基数排序⭐⭐⭐ 1.2 执行流程⭐⭐⭐⭐⭐ 2. 代码实现⭐⭐⭐ 3. 性能分析⭐⭐ 3.1 时间复杂度 3.2 空间复杂度 1. 前言 一个算法,只有理解算法的思路才是真正地认识该算法,不能单纯记住某个算法的实现代码! 1.…...
CSS选择器、CSS属性相关
CSS选择器 CSS属性选择器 通过标签的属性来查找标签,标签都有属性 <div class"c1" id"d1"></div>id值和class值是每个标签都自带的属性,还有另外一种:自定义属性 <div class"c1" id"d1&…...
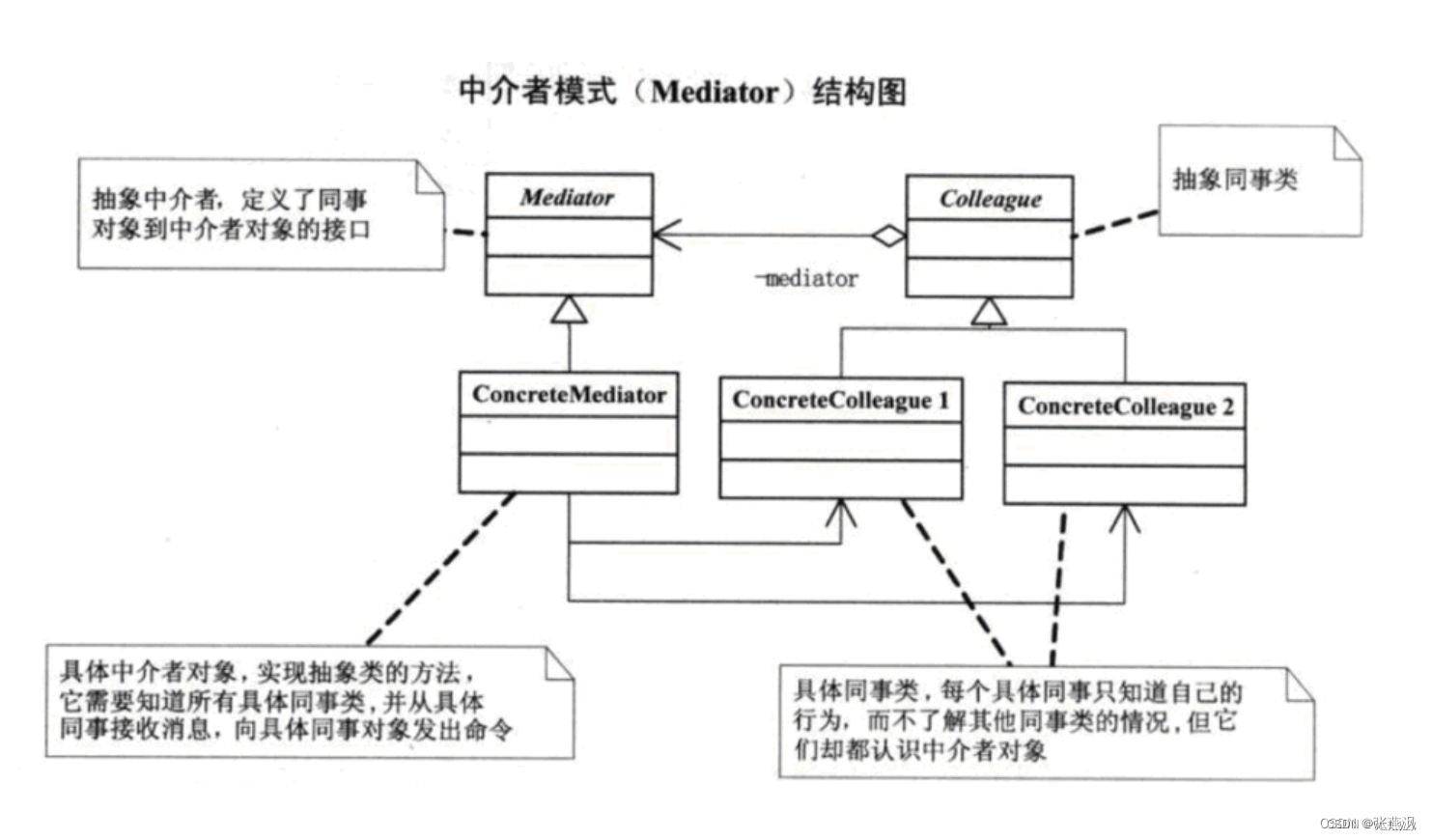
设计模式(21)中介者模式
一、介绍: 1、定义:中介者模式(Mediator Pattern)是一种行为型设计模式,它通过引入一个中介者对象来降低多个对象之间的耦合度。在中介者模式中,各个对象之间不直接进行通信,而是通过中介者对象…...

JVM虚拟机:通过一个例子解释JVM中栈结构的使用
代码 代码解析 main方法执行,创建栈帧并压栈。 int d8,d为局部变量,是基础类型,它位于虚拟机栈的局部变量表中 然后创建了一个TestDemo的对象,这个对象在堆中,并且这个对象的成员变量(day&am…...
会自动写代码的AI大模型来了!阿里云推出智能编码助手通义灵码
用大模型写代码是什么样的体验?10月31日,杭州云栖大会上,阿里云对外展示了一款可自动编写代码的 AI 助手,在编码软件的对话窗口输入“帮我用 python 写一个飞机游戏”,短短几秒,这款名为“通义灵码”的 AI …...

如何公网远程访问本地WebSocket服务端
本地websocket服务端暴露至公网访问【cpolar内网穿透】 文章目录 本地websocket服务端暴露至公网访问【cpolar内网穿透】1. Java 服务端demo环境2. 在pom文件引入第三包封装的netty框架maven坐标3. 创建服务端,以接口模式调用,方便外部调用4. 启动服务,出现以下信息表示启动成功…...

python 练习 在列表元素中合适的位置插入 输入值
目的: 有一列从小到大排好的数字元素列表, 现在想往其插入一个值,要求: 大于右边数字小于左边数字 列表元素: [1,4,6,13,16,19,28,40,100] # 方法: 往列表中添加一个数值,其目的方便元素位置往后…...
企业级JAVA、数据库等编程规范之命名风格 —— 超详细准确无误
🧸欢迎来到dream_ready的博客,📜相信你对这两篇博客也感兴趣o (ˉ▽ˉ;) 📜 表白墙/留言墙 —— 初级SpringBoot项目,练手项目前后端开发(带完整源码) 全方位全步骤手把手教学 📜 用户登录前后端…...

InsForge:基于Python的Instagram内容自动化创作与发布工具全解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫InsForge。这名字听起来有点“工业锻造”的味道,实际上,它是一个专注于Instagram内容创作与自动化的工具集。简单来说,它试图帮你解决在Instagram上创作、发布、管理内容…...

Fast-GitHub:打破GitHub访问壁垒的智能加速方案
Fast-GitHub:打破GitHub访问壁垒的智能加速方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾因GitHub仓库克…...

VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具
VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,VHDL转Verilog是许多工程师面临的共同挑战。手动转换不仅耗时费力,还容…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

开源技能库构建指南:Git+Markdown+Docsify打造个人技术知识体系
1. 项目概述:一个开源技能库的诞生与价值在技术领域,尤其是软件开发、运维和数据分析等方向,我们每天都在与海量的工具、框架和命令打交道。时间一长,一个很现实的问题就摆在了面前:那些曾经花了好几个小时才调通的复杂…...

U-Boot实战:FAT文件系统五大核心命令详解与应用
1. U-Boot与FAT文件系统基础认知 刚接触嵌入式开发时,我第一次在U-Boot环境下操作FAT文件系统就踩了个大坑——试图用ext4write命令操作FAT32格式的SD卡,结果系统直接报错"Unknown command"。这个经历让我深刻认识到:U-Boot对文件系…...

自托管链接管理平台Linko:Go+React技术栈部署与核心功能解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫monsterxx03/linko。乍一看这个名字,可能有点摸不着头脑,但如果你经常需要管理一堆链接、书签,或者在做内容聚合、个人知识库,那这个工具很可能就是你一直在…...

AI代码管理器:统一多模型编程助手,提升开发效率与代码质量
1. 项目概述:一个面向开发者的多模型代码管理技能最近在折腾AI编程助手,发现一个挺有意思的现象:很多开发者手头可能同时用着Claude、CodeGemini这类工具,但每次切换都得重新配置环境、调整提示词,甚至要处理不同模型输…...
NeoPixel电源设计全攻略:从电流估算到多电源分配
1. 项目概述:为什么NeoPixel电源设计是成败关键如果你玩过NeoPixel或者类似的WS2812B可编程LED,大概率经历过这样的场景:精心设计的动画点亮了十几个灯珠,效果惊艳;但当你兴冲冲地把灯珠数量加到一百个,准备…...

555定时器深度解析:从RC电路到三种工作模式的原理与应用
1. 项目概述在电子设计的工具箱里,有那么几颗芯片,你几乎可以在任何时代的电路板上找到它们的身影。它们可能不是性能最强的,但一定是应用最广、最经久不衰的。今天要聊的555定时器,就是这样一个“活化石”级别的存在。自上世纪70…...