python中transform和apply的区别是什么
文章目录
- 1. 介绍
- `transform`:
- `apply`:
- 2. 应用示例
- 示例数据
- 使用`transform`进行向量化操作
- 使用`apply`进行更复杂的操作
- 性能比较
- 3. 示例输出
- 使用 `transform` 进行向量化操作
- 使用 `apply` 进行更复杂的操作
- 4. transform再举例
- 示例数据
- 使用`transform`计算平均销售额
- 输出
1. 介绍
在Pandas中,transform和apply都可以用于对分组数据进行操作,但它们有不同的使用场景和性能特性:
transform:
- 返回与输入相同大小的DataFrame:
transform函数应用于每个分组后,会将结果广播到原始数据的大小,这通常使得transform更高效。 - 性能优化:
transform通常会尝试用更高效的内部机制来执行向量化操作。 - 限制:由于结果会被广播到原始数据的大小,因此
transform应用的函数应返回标量值或与输入组相同大小的数组。
apply:
- 更为通用:
apply适用于更复杂的操作,包括改变DataFrame的大小。 - 灵活性:
apply可以用于执行更多种类的操作,例如,可以返回DataFrame、Series或标量。 - 可能性能较低:
apply的通用性通常意味着它在性能上不如transform高效,尤其是在需要广播结果到原始数据大小的场景。
因此,当操作可以使用transform完成时,通常更推荐使用transform,以获取更好的性能。当需要更大的灵活性时(例如,改变输出的形状或进行更复杂的计算),则可以使用apply。
2. 应用示例
当然,以下是一些应用示例来说明transform和apply的不同用途和性能特性。
示例数据
假设我们有以下DataFrame,它表示三个不同产品在不同日期的销售额:
import pandas as pddata = {'Date': ['2021-01-01', '2021-01-01', '2021-01-02', '2021-01-02', '2021-01-03', '2021-01-03'],'Product': ['A', 'B', 'A', 'A', 'B', 'C'],'Revenue': [100, 150, 200, 50, 300, 400]}
df = pd.DataFrame(data)
使用transform进行向量化操作
如果我们想要在原DataFrame中添加一个新列,该列表示每个产品的总销售额,我们可以使用transform:
df['Total_Revenue_By_Product'] = df.groupby('Product')['Revenue'].transform('sum')
transform将自动广播每个组的结果(即每个产品的总销售额)到该组内所有行。
使用apply进行更复杂的操作
假设我们想要获得每个产品最高单日销售额的日期,这是一个更复杂的操作,可以使用apply:
def get_max_revenue_date(group):return group.loc[group['Revenue'].idxmax(), 'Date']max_revenue_date = df.groupby('Product').apply(get_max_revenue_date)
这里,apply允许我们对每个组使用更复杂的函数,并且返回一个与输入形状不同的结果。
性能比较
通常,在可以使用transform的场合,使用transform会更高效。例如,如果我们有一个非常大的DataFrame,使用transform来计算组平均值通常会比使用apply更快。
3. 示例输出
当然,让我说明一下各个示例的输出。
使用 transform 进行向量化操作
如果我们运行这段代码:
df['Total_Revenue_By_Product'] = df.groupby('Product')['Revenue'].transform('sum')
df 会被更新,新增了一个列 Total_Revenue_By_Product,它包含每个产品的总销售额,并会广播到该产品的所有记录。
更新后的 df 如下:
Date Product Revenue Total_Revenue_By_Product
0 2021-01-01 A 100 350
1 2021-01-01 B 150 450
2 2021-01-02 A 200 350
3 2021-01-02 A 50 350
4 2021-01-03 B 300 450
5 2021-01-03 C 400 400
如您所见,产品A、B、和C的总销售额分别是350、450和400,这些值被广播到了每一行对应的产品。
使用 apply 进行更复杂的操作
如果我们运行这段代码:
def get_max_revenue_date(group):return group.loc[group['Revenue'].idxmax(), 'Date']max_revenue_date = df.groupby('Product').apply(get_max_revenue_date)
max_revenue_date 会是一个 Series,其中包含每个产品销售额最高的日期:
Product
A 2021-01-02
B 2021-01-03
C 2021-01-03
dtype: object
这里,我们可以看到产品A、B、和C销售额最高的日期分别是 2021-01-02、2021-01-03 和 2021-01-03。
4. transform再举例
当然,下面是另一个使用transform的例子。这次,我们将计算每个产品的平均销售额,并将该信息添加为新的列。
示例数据
我们还是使用相同的数据集:
data = {'Date': ['2021-01-01', '2021-01-01', '2021-01-02', '2021-01-02', '2021-01-03', '2021-01-03'],'Product': ['A', 'B', 'A', 'A', 'B', 'C'],'Revenue': [100, 150, 200, 50, 300, 400]}
df = pd.DataFrame(data)
使用transform计算平均销售额
df['Average_Revenue_By_Product'] = df.groupby('Product')['Revenue'].transform('mean')
运行这行代码后,df会更新,新增一个列Average_Revenue_By_Product,其中包含每个产品的平均销售额。
输出
更新后的df会是这样:
Date Product Revenue Average_Revenue_By_Product
0 2021-01-01 A 100 116.666667
1 2021-01-01 B 150 225.000000
2 2021-01-02 A 200 116.666667
3 2021-01-02 A 50 116.666667
4 2021-01-03 B 300 225.000000
5 2021-01-03 C 400 400.000000
如您所见,产品A、B、和C的平均销售额分别是约116.67、225和400,这些值被广播到了每一行对应的产品。
相关文章:
python中transform和apply的区别是什么
文章目录 1. 介绍transform:apply: 2. 应用示例示例数据使用transform进行向量化操作使用apply进行更复杂的操作性能比较 3. 示例输出使用 transform 进行向量化操作使用 apply 进行更复杂的操作 4. transform再举例示例数据使用transform计算平均销售额…...

TCP 协议
文章目录 协议格式1面向连接:1.1三次握手(建立连接)1.2包序管理1.2四次挥手(断开连接) 2可靠传输:一。保证数据可靠有序的到达对端:确认应答机制超时重传机制 二。提高传输效率:1.提升自身发送数据量滑动窗口机制 rwnd滑动窗口丢包…...
Azure机器学习 - 在 Azure 机器学习中上传、访问和浏览数据
目录 一、环境准备二、设置内核三、下载使用的数据四、创建工作区的句柄五、将数据上传到云存储空间六、访问笔记本中的数据七、创建新版本的数据资产八、清理资源 机器学习项目的开始阶段通常涉及到探索性数据分析 (EDA)、数据预处理(清理、特征工程)以…...

新建包含cuda和cudnn的docker
背景:服务器的cudnn版本太低了,没有权限去修改。故新建包含cuda和cudnn的docker 步骤 一、拉取镜像及创建docker 拉取相关的镜像 从镜像列表选出相关版本的镜像https://gitlab.com/nvidia/container-images/cuda/blob/master/doc/supported-tags.md …...
)
Opensips安装配置(以下操作均已centOS 6.3系统为准)
1. 安装依赖软件: a) Yum update //更新系统到最新 b) 安装以下所需依赖软件 gcc bison flex make openssl libmysqlclient-dev mysql-server c) 安装radiusclient: 1. wget http://pkgs.repoforge.org/radiuscli…...

第03章 用户与权限管理
第03章 用户与权限管理 1. 用户管理 1.1 登录MySQL服务器 启动MySQL服务后,可以通过mysql命令来登录MySQL服务器,命令如下: mysql –h hostname|hostIP –P port –u username –p DatabaseName –e "SQL语句"-h参数后面接主机…...

赋能制造业高质量发展,释放采购数字化新活力——企企通亮相武汉2023国际智能制造创新论坛
摘要 “为应对成本上升、供应端不稳定、供应链上下游协同困难、决策无数据依据等问题,利用数字化手段降本增效、降低潜在风险十分关键。在AI等先进技术发展、供应链协同效应和降本诉求等机遇的驱动下,采购供应链数字化、协同化成为企业激烈竞争的优先选…...

洗地新天花板:CEYEE希亦顶配机皇T800 Pro洗地机多点发力上市开售
2023年11月1日,CEYEE希亦正式发布高端清洁产品无线洗地机希亦T800 PRO,创新性地实现了洗地场景深度清洁体验的新突破,彻底解决了清洁行业20多年来技术发展难题,颠覆式引领行业向水汽混动时代迈进,推动了整个市场向“智…...
如何创建一个react项目
文章目录 前言前言打开小黑窗口npm init vite后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:react.js 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现错误&am…...
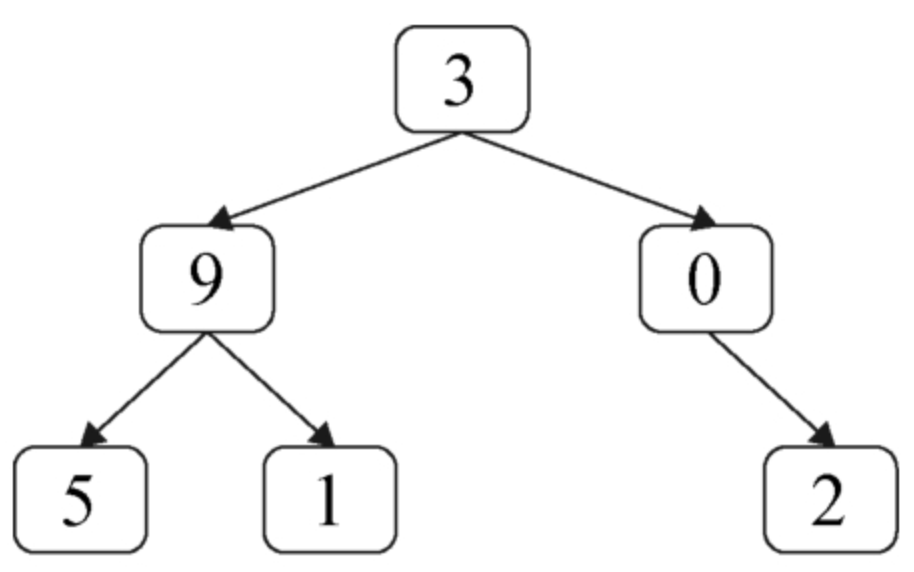
面试算法49:从根节点到叶节点的路径数字之和
题目 在一棵二叉树中所有节点都在0~9的范围之内,从根节点到叶节点的路径表示一个数字。求二叉树中所有路径表示的数字之和。例如,图8.4的二叉树有3条从根节点到叶节点的路径,它们分别表示数字395、391和302,这3个数字…...

http1,https,http2,http3总结
1.HTTP 当我们浏览网页时,地址栏中使用最多的多是https://开头的url,它与我们所学的http协议有什么区别? http协议又叫超文本传输协议,它是应用层中使用最多的协议, http与我们常说的socket有什么区别吗? …...
stable-diffusion-webui环境部署
stable-diffusion-webui环境部署 1. 环境创建2. 安装依赖库3.下载底模4. 获取lora参数文件5.运行代码6. 报错信息报错1报错2 1. 环境创建 创建虚拟环境 conda create -n env_stable python3.10.0进入虚拟环境 conda activate env_stableclone源码 git clone https://github.com…...

使用Ansible中的playbook
目录 1.Playbook的功能 2.YAML 3.YAML列表 4.YAML的字典 5.playbook执行命令 6.playbook的核心组件 7.vim 设定技巧 示例 1.Playbook的功能 playbook 是由一个或多个play组成的列表 Playboot 文件使用YAML来写的 2.YAML #简介# 是一种表达资料序列的格式,类似XML #特…...
模型应用系实习生-模型训练笔记(更新至线性回归、Ridge回归、Lasso回归、Elastic Net回归、决策树回归、梯度提升树回归和随机森林回归)
sklearn机械学习模型步骤以及模型 一、训练准备(x_train, x_test, y_train, y_test)1.1 导包1.2 数据要求1.21 导入数据1.22 数据类型查看检测以及转换1.22 划分数据 二、回归2.1 线性回归2.2 随机森林回归2.3 GradientBoostingRegressor梯度提升树回归2…...

【Verilog】7.2.1 Verilog 并行 FIR 滤波器设计
FIR(Finite Impulse Response)滤波器是一种有限长单位冲激响应滤波器,又称为非递归型滤波器。 FIR 滤波器具有严格的线性相频特性,同时其单位响应是有限长的,因而是稳定的系统,在数字通信、图像处理等领域…...

【音视频 | wav】wav音频文件格式详解——包含RIFF规范、完整的各个块解析、PCM转wav代码
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

人工智能基础_机器学习012_手写梯度下降代码演示_手动写代码完成梯度下降_并实现梯度下降可视化---人工智能工作笔记0052
可以看到上面我们那个公式,现在我们用梯度下降实现一下,比如我们有一堆数据,但是没有方程的情况下,我们来看一下如果计算,对应的w值也就是seta值对吧,没有方程我们可以使用梯度下降 这里首先我们可以设置一个0.0001.我们知道梯度下降的公式, 梯度下降刚开始的时候,下降会快,然…...

Docker安装部署[8.x]版本Elasticsearch+Kibana+IK分词器
文章目录 Docker安装部署elasticsearch拉取镜像创建数据卷创建网络elasticsearch容器,启动!踩坑:虚拟机磁盘扩容 Docker安装部署Kibana拉取镜像Kibana容器,启动! 安装IK分词器安装方式一:直接从github上下载…...

折纸达珠峰高度(forwhile循环)
对折0.1mm厚度的纸张多少次,高度可达珠峰高度8848180mm。 (本笔记适合熟悉循环和列表的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅…...

探索网络攻防技术:自学之道
在当今数字化时代,网络攻防技术的重要性日益凸显。无论是个人用户还是企业组织,都需要具备一定的网络安全意识和基本技能来应对日益复杂的网络威胁。自学网络攻防技术成为许多人的选择,今天我们将探讨如何高效、有序地自学网络攻防技术。 如果…...

AI算法工程师必学的Python库:这10个库,AI开发必备
对于软件测试从业者来说,随着人工智能技术在测试领域的渗透越来越深——从自动化测试用例生成到缺陷智能预测,从测试结果分析到测试环境智能化调度,掌握AI开发的核心工具链已经成为从功能测试向AI测试开发、智能化测试转型的核心竞争力。Pyth…...

Claude Mythos Preview首月揪万余漏洞、拦截150万美元电诈,网络安全格局将变?
玻璃翼计划首战告捷A厂的玻璃翼计划首战告捷,Mythos 30天内就挖出1万个致命漏洞,甚至拦截了150万美元电诈。面对雪片式的报告,人类程序员崩溃求饶:「求别挖了,根本修不完啊!」就在刚刚,Anthropi…...

红外信号逆向工程:破解电磁炉协议实现抽油烟机智能联动
1. 项目概述:当电磁炉与抽油烟机“对话”厨房里的自动化,听起来像是未来智能家居的专属,但其实很多乐趣和便利就藏在身边已有的设备里。我最近给家里的厨房换上了一台新的电磁炉,在翻阅说明书时,偶然发现了一个名为“h…...
)
Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱)
更多请点击: https://codechina.net 第一章:Midjourney辉光效果失效诊断手册(含12个隐性触发条件与4类GPU显存陷阱) 辉光效果(Glow Effect)在 Midjourney v6 的 --style raw 模式下常被用于强化主体边缘光…...

抖音批量下载工具:免费获取无水印视频的终极解决方案
抖音批量下载工具:免费获取无水印视频的终极解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...
)
独家首发|DeepSeek官方未公开的IP检查API接口文档(含沙箱环境调用密钥获取路径)
更多请点击: https://kaifayun.com 第一章:DeepSeek知识产权检查 DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder、DeepSeek-MoE)由深度求索(DeepSeek)公司自主研发,其权重、训练代码、推…...

WaveTools鸣潮工具箱:3步完成游戏性能优化与配置调校的完整指南
WaveTools鸣潮工具箱:3步完成游戏性能优化与配置调校的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools鸣潮工具箱是一款专为《鸣潮》玩家设计的开源性能优化工具,…...

UE4SS实战指南:虚幻引擎游戏脚本系统的深度解析与应用
UE4SS实战指南:虚幻引擎游戏脚本系统的深度解析与应用 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS …...

解决WSL中RViz全屏闪烁和字体缩小情况
针对WSL中,ROS2-humble打开RViz2全屏后,地图闪烁的情况:我从网上找,问了ai,试了很多种方法,终于找到一种适合我的方法,有相同情况的朋友可以试一试,但是不保证你的问题和解决方法与我…...
的使用场景)
Python运算符:成员运算符(in/not in)的使用场景
Python运算符:成员运算符(in/not in)的使用场景📚 本章学习目标:深入理解成员运算符(in/not in)的使用场景的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最…...