Azure机器学习 - 在 Azure 机器学习中上传、访问和浏览数据
目录
- 一、环境准备
- 二、设置内核
- 三、下载使用的数据
- 四、创建工作区的句柄
- 五、将数据上传到云存储空间
- 六、访问笔记本中的数据
- 七、创建新版本的数据资产
- 八、清理资源
机器学习项目的开始阶段通常涉及到探索性数据分析 (EDA)、数据预处理(清理、特征工程)以及生成机器学习模型原型来验证假设,本教程介绍如何执行下列操作:将数据上传到云存储空间,创建 Azure 机器学习数据资产,访问笔记本中的数据以进行交互式开发, 创建新版本的数据资产。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、环境准备
-
若要使用 Azure 机器学习,你首先需要一个工作区。 如果没有工作区,请完成创建开始使用所需的资源以创建工作区并详细了解如何使用它。
-
登录到工作室,选择工作区(如果尚未打开)。
-
在工作区中打开或创建一个笔记本:
- 如果要将代码复制/粘贴到单元格中,请创建新的笔记本。
- 或者从工作室的“示例”部分打开 tutorials/get-started-notebooks/explore-data.ipynb。 然后选择“克隆”,将笔记本添加到你的“文件”。
二、设置内核
- 在打开的笔记本上方的顶部栏中,创建一个计算实例(如果还没有计算实例)。

- 如果计算实例已停止,请选择“启动计算”,并等待它运行。

- 确保右上角的内核为
Python 3.10 - SDK v2。 如果不是,请使用下拉列表选择此内核。

- 如果看到一个横幅,提示你需要进行身份验证,请选择“身份验证”。
三、下载使用的数据
本文使用此 CSV 格式的信用卡客户数据示例作为示例。 我们可以看到 Azure 机器学习资源中的步骤继续执行。 在该资源中,我们将直接在此笔记本所在的文件夹下创建一个本地文件夹,并使用建议的名称“data”。
- 选择三点下方的“打开终端”,如此图所示:
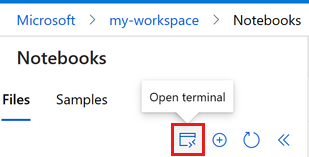
-
终端窗口将在新选项卡中打开。
-
请确保
cd此笔记本所在的同一文件夹。 例如,如果笔记本位于名为 get-started-notebooks 的文件夹中:
cd get-started-notebooks # modify this to the path where your notebook is located
- 在终端窗口中输入以下命令,将数据复制到计算实例:
mkdir datacd data # the sub-folder where you'll store the datawget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv
- 现在可以关闭终端窗口。
四、创建工作区的句柄
在深入了解代码之前,需要一种方法来引用工作区。 你将为工作区句柄创建 ml_client。 然后,你将使用 ml_client 来管理资源和作业。
在下一个单元格中,输入你的订阅 ID、资源组名称和工作区名称。 若要查找这些值:
- 在右上方的 Azure 机器学习工作室工具栏中,选择你的工作区名称。
- 将工作区、资源组和订阅 ID 的值复制到代码中。
- 需要复制一个值,关闭区域并粘贴,然后返回下一个值。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes# authenticate
credential = DefaultAzureCredential()# Get a handle to the workspace
ml_client = MLClient(credential=credential,subscription_id="<SUBSCRIPTION_ID>",resource_group_name="<RESOURCE_GROUP>",workspace_name="<AML_WORKSPACE_NAME>",
)
五、将数据上传到云存储空间
Azure 机器学习使用统一资源标识符 (URI),它们指向云中的存储位置。 使用 URI 可以轻松访问笔记本和作业中的数据。 数据 URI 格式类似于在 Web 浏览器中用于访问网页的 Web URL。 例如:
- 从公共 https 服务器访问数据:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - 从 Azure Data Lake Gen 2 访问数据:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Azure 机器学习数据资产类似于 Web 浏览器书签(收藏夹)。 可以创建数据资产,然后使用易记名称访问该资产,而无需记住指向最常用数据的冗长存储路径 (URI)。
通过创建数据资产,还可以创建对数据源位置的引用及其元数据的副本。 由于数据保留在其现有位置中,因此不会产生额外的存储成本,也不会损害数据源的完整性。 可以从 Azure 机器学习数据存储、Azure 存储、公共 URL 和本地文件创建数据资产。
下一个笔记本单元格会创建数据资产。 此代码示例将原始数据文件上传到指定的云存储资源。
每次创建数据资产时,都需要为其创建唯一版本。 如果版本已存在,则会收到错误。 在此代码中,我们将对数据第一次读取使用“initial”。 如果该版本已存在,我们将跳过再次创建它。
还可以省略 version 参数,版本号会为你生成,从 1 开始,然后递增。
在本文中,我们使用名称“initial”作为第一个版本。 创建生产机器学习管道教程也将使用此版本的数据,因此在这里,我们使用你将在该教程中再次看到的值。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystemmy_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"my_data = Data(name="credit-card",version=v1,description="Credit card data",path=my_path,type=AssetTypes.URI_FILE,
)## create data asset if it doesn't already exist:
try:data_asset = ml_client.data.get(name="credit-card", version=v1)print(f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}")
except:ml_client.data.create_or_update(my_data)print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
可以通过选择左侧的“数据”来查看上传的数据。 你将看到数据已上传且数据资产已创建:
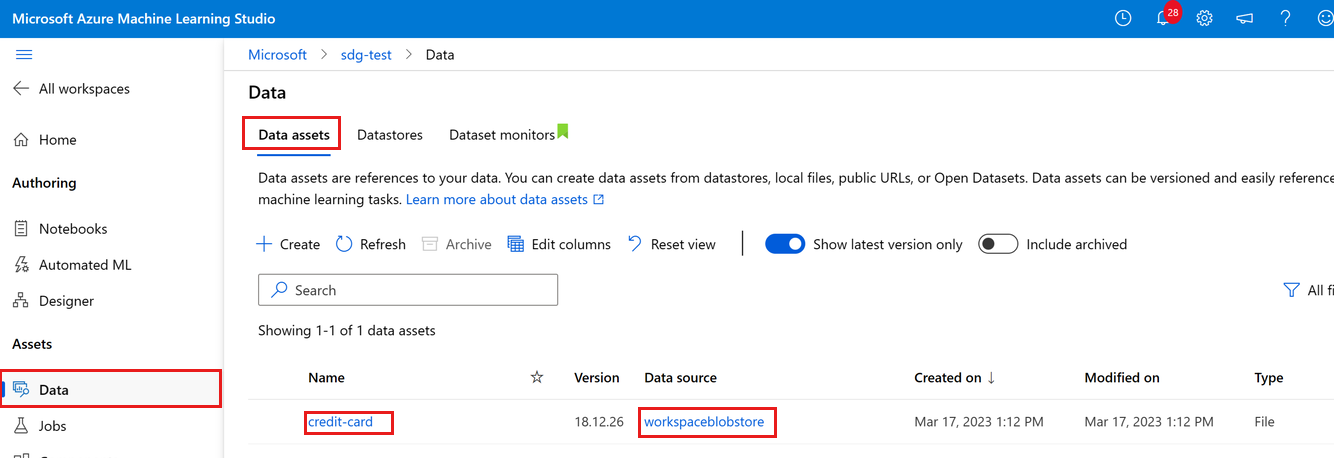
此数据命名为 credit-card,在“数据资产”选项卡中,可以在“名称”列中看到它。 此数据上传到工作区的默认数据存储 workspaceblobstore,显示在“数据源”列中。
Azure 机器学习数据存储是对 Azure 上现有存储帐户的引用。 数据存储具有以下优势:
- 一种通用且易用的 API,可以与不同的存储类型(Blob/文件/Azure Data Lake Storage)和身份验证方法进行交互。
- 一种在团队协作时更轻松地发现有用的数据存储的方式。
- 在你的脚本中,隐藏基于凭据的数据访问连接信息的方法(服务主体/SAS/密钥)。
六、访问笔记本中的数据
Pandas 直接支持 URI - 此示例演示如何从 Azure 机器学习数据存储读取 CSV 文件:
import pandas as pddf = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
# 但是,如前所述,可能很难记住这些 URI。 此外,必须手动将 **pd.read\_csv** 命令中的所有 **<_substring_\>** 值替换为资源的实际值。
# 需要为经常访问的数据创建数据资产。 下面是在 Pandas 中访问 CSV 文件的更简单的方法:
%pip install -U azureml-fsspec
import pandas as pd# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")# read into pandas - note that you will see 2 headers in your data frame - that is ok, for nowdf = pd.read_csv(data_asset.path)
df.head()
阅读在交互式开发期间从 Azure 云存储访问数据,详细了解笔记本中的数据访问。
七、创建新版本的数据资产
你可能已注意到,数据需要稍微清理一下,使其适合训练机器学习模型。 它具有:
- 两个标头
- 客户端 ID 列;我们不会在机器学习中使用此功能
- 响应变量名称中的空格
此外,与 CSV 格式相比,Parquet 文件格式成为存储此数据的更好方法。 Parquet 可提供压缩,并维护架构。 因此,若要清理数据并将其存储在 Parquet 中,请使用:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
此表显示了在前面的步骤中下载的原始 default_of_credit_card_clients.csv .CSV 文件中的数据结构。 上传的数据包含 23 个解释变量和 1 个响应变量,如下所示:
| 列名 | 变量类型 | 说明 |
|---|---|---|
| X1 | 解释型 | 给予的信贷金额(新台币):它包括个人消费信贷和他们的家庭(附加)信贷。 |
| X2 | 解释型 | 性别(1 = 男性;2 = 女性)。 |
| X3 | 解释型 | 教育(1 = 研究生;2 = 本科;3 = 高中;4 = 其他)。 |
| X4 | 解释型 | 婚姻状况(1 = 已婚;2 = 单身;3 = 其他)。 |
| X5 | 解释型 | 年龄(年)。 |
| X6-X11 | 解释型 | 过去付款的历史记录。 我们跟踪了过去的每月付款记录(从 2005 年 4 月到 9 月)。 -1 = 按期付款;1 = 付款延迟一个月;2 = 付款延迟两个月; . 8 = 付款延迟 8 个月;9 = 付款延迟 9 个月及以上。 |
| X12-17 | 解释型 | 2005 年 4 月到 9 月账单金额流水(新台币)。 |
| X18-23 | 解释型 | 2005 年 4 月到 9 月的先前付款金额(新台币)。 |
| Y | 响应 | 默认付款(是 = 1,否 = 0) |
接下来,创建数据资产的新_版本_(数据会自动上传到云存储空间)。 对于此版本,我们将添加一个时间值,以便每次运行此代码时,都会创建不同的版本号。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"# Define the data asset, and use tags to make it clear the asset can be used in trainingmy_data = Data(name="credit-card",version=v2,description="Default of credit card clients data.",tags={"training_data": "true", "format": "parquet"},path=my_path,type=AssetTypes.URI_FILE,
)## create the data assetmy_data = ml_client.data.create_or_update(my_data)print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
清理的 parquet 文件是最新版本的数据源。 此代码先显示 CSV 版本结果集,然后显示 Parquet 版本:
import pandas as pd# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))# print the v2 data
print("_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
八、清理资源
停止计算实例
如果不打算现在使用它,请停止计算实例:
- 在工作室的左侧导航区域中,选择“计算”。
- 在顶部选项卡中,选择“计算实例”
- 在列表中选择该计算实例。
- 在顶部工具栏中,选择“停止”。
删除所有资源
如果你不打算使用已创建的任何资源,请删除它们,以免产生任何费用:
-
在 Azure 门户中,选择最左侧的“资源组” 。
-
从列表中选择你创建的资源组。
-
选择“删除资源组”。
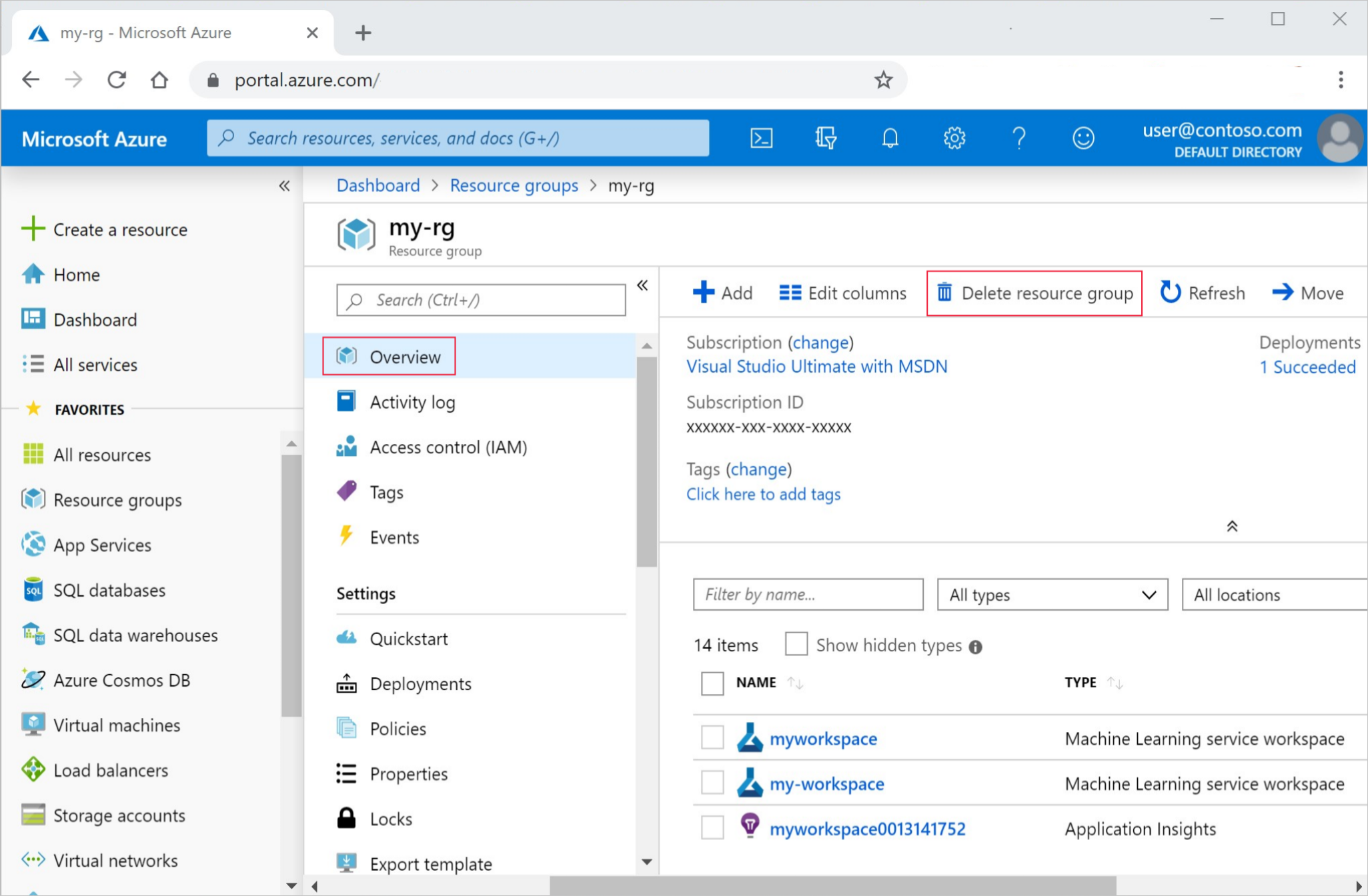
- 输入资源组名称。 然后选择“删除”。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
Azure机器学习 - 在 Azure 机器学习中上传、访问和浏览数据
目录 一、环境准备二、设置内核三、下载使用的数据四、创建工作区的句柄五、将数据上传到云存储空间六、访问笔记本中的数据七、创建新版本的数据资产八、清理资源 机器学习项目的开始阶段通常涉及到探索性数据分析 (EDA)、数据预处理(清理、特征工程)以…...

新建包含cuda和cudnn的docker
背景:服务器的cudnn版本太低了,没有权限去修改。故新建包含cuda和cudnn的docker 步骤 一、拉取镜像及创建docker 拉取相关的镜像 从镜像列表选出相关版本的镜像https://gitlab.com/nvidia/container-images/cuda/blob/master/doc/supported-tags.md …...
)
Opensips安装配置(以下操作均已centOS 6.3系统为准)
1. 安装依赖软件: a) Yum update //更新系统到最新 b) 安装以下所需依赖软件 gcc bison flex make openssl libmysqlclient-dev mysql-server c) 安装radiusclient: 1. wget http://pkgs.repoforge.org/radiuscli…...

第03章 用户与权限管理
第03章 用户与权限管理 1. 用户管理 1.1 登录MySQL服务器 启动MySQL服务后,可以通过mysql命令来登录MySQL服务器,命令如下: mysql –h hostname|hostIP –P port –u username –p DatabaseName –e "SQL语句"-h参数后面接主机…...

赋能制造业高质量发展,释放采购数字化新活力——企企通亮相武汉2023国际智能制造创新论坛
摘要 “为应对成本上升、供应端不稳定、供应链上下游协同困难、决策无数据依据等问题,利用数字化手段降本增效、降低潜在风险十分关键。在AI等先进技术发展、供应链协同效应和降本诉求等机遇的驱动下,采购供应链数字化、协同化成为企业激烈竞争的优先选…...

洗地新天花板:CEYEE希亦顶配机皇T800 Pro洗地机多点发力上市开售
2023年11月1日,CEYEE希亦正式发布高端清洁产品无线洗地机希亦T800 PRO,创新性地实现了洗地场景深度清洁体验的新突破,彻底解决了清洁行业20多年来技术发展难题,颠覆式引领行业向水汽混动时代迈进,推动了整个市场向“智…...
如何创建一个react项目
文章目录 前言前言打开小黑窗口npm init vite后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:react.js 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现错误&am…...
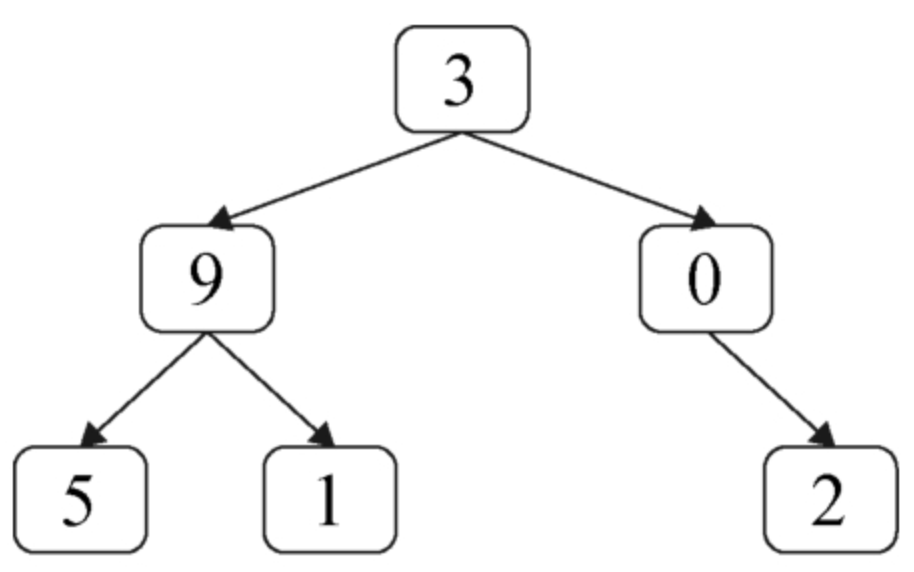
面试算法49:从根节点到叶节点的路径数字之和
题目 在一棵二叉树中所有节点都在0~9的范围之内,从根节点到叶节点的路径表示一个数字。求二叉树中所有路径表示的数字之和。例如,图8.4的二叉树有3条从根节点到叶节点的路径,它们分别表示数字395、391和302,这3个数字…...

http1,https,http2,http3总结
1.HTTP 当我们浏览网页时,地址栏中使用最多的多是https://开头的url,它与我们所学的http协议有什么区别? http协议又叫超文本传输协议,它是应用层中使用最多的协议, http与我们常说的socket有什么区别吗? …...
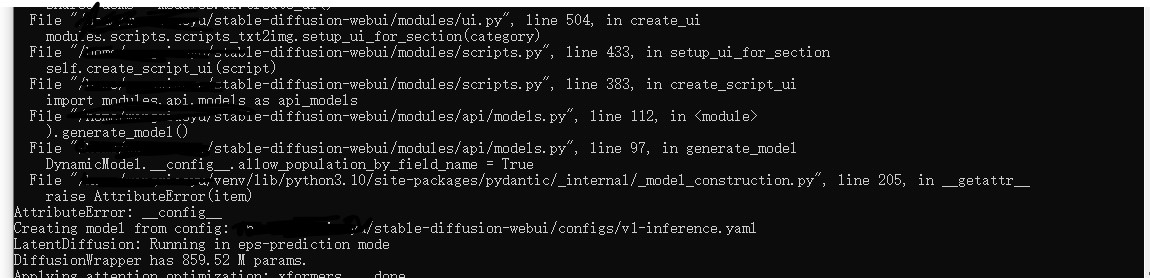
stable-diffusion-webui环境部署
stable-diffusion-webui环境部署 1. 环境创建2. 安装依赖库3.下载底模4. 获取lora参数文件5.运行代码6. 报错信息报错1报错2 1. 环境创建 创建虚拟环境 conda create -n env_stable python3.10.0进入虚拟环境 conda activate env_stableclone源码 git clone https://github.com…...

使用Ansible中的playbook
目录 1.Playbook的功能 2.YAML 3.YAML列表 4.YAML的字典 5.playbook执行命令 6.playbook的核心组件 7.vim 设定技巧 示例 1.Playbook的功能 playbook 是由一个或多个play组成的列表 Playboot 文件使用YAML来写的 2.YAML #简介# 是一种表达资料序列的格式,类似XML #特…...
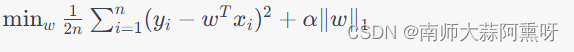
模型应用系实习生-模型训练笔记(更新至线性回归、Ridge回归、Lasso回归、Elastic Net回归、决策树回归、梯度提升树回归和随机森林回归)
sklearn机械学习模型步骤以及模型 一、训练准备(x_train, x_test, y_train, y_test)1.1 导包1.2 数据要求1.21 导入数据1.22 数据类型查看检测以及转换1.22 划分数据 二、回归2.1 线性回归2.2 随机森林回归2.3 GradientBoostingRegressor梯度提升树回归2…...

【Verilog】7.2.1 Verilog 并行 FIR 滤波器设计
FIR(Finite Impulse Response)滤波器是一种有限长单位冲激响应滤波器,又称为非递归型滤波器。 FIR 滤波器具有严格的线性相频特性,同时其单位响应是有限长的,因而是稳定的系统,在数字通信、图像处理等领域…...

【音视频 | wav】wav音频文件格式详解——包含RIFF规范、完整的各个块解析、PCM转wav代码
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

人工智能基础_机器学习012_手写梯度下降代码演示_手动写代码完成梯度下降_并实现梯度下降可视化---人工智能工作笔记0052
可以看到上面我们那个公式,现在我们用梯度下降实现一下,比如我们有一堆数据,但是没有方程的情况下,我们来看一下如果计算,对应的w值也就是seta值对吧,没有方程我们可以使用梯度下降 这里首先我们可以设置一个0.0001.我们知道梯度下降的公式, 梯度下降刚开始的时候,下降会快,然…...

Docker安装部署[8.x]版本Elasticsearch+Kibana+IK分词器
文章目录 Docker安装部署elasticsearch拉取镜像创建数据卷创建网络elasticsearch容器,启动!踩坑:虚拟机磁盘扩容 Docker安装部署Kibana拉取镜像Kibana容器,启动! 安装IK分词器安装方式一:直接从github上下载…...

折纸达珠峰高度(forwhile循环)
对折0.1mm厚度的纸张多少次,高度可达珠峰高度8848180mm。 (本笔记适合熟悉循环和列表的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅…...

探索网络攻防技术:自学之道
在当今数字化时代,网络攻防技术的重要性日益凸显。无论是个人用户还是企业组织,都需要具备一定的网络安全意识和基本技能来应对日益复杂的网络威胁。自学网络攻防技术成为许多人的选择,今天我们将探讨如何高效、有序地自学网络攻防技术。 如果…...

图像二值化阈值调整——cv2.threshold方法
二值化阈值调整:调整是指在进行图像二值化处理时,调整阈值的过程。阈值决定了将图像中的像素分为黑色和白色的界限,大于阈值的像素被设置为白色,小于等于阈值的像素被设置为黑色。 方法一: 取阈值为 127,…...

【C++代码】背包问题,完全背包,多重背包,打家劫舍,动态规划--代码随想录
爬楼梯(plus) 一步一个台阶,两个台阶,三个台阶,…,直到 m个台阶。问有多少种不同的方法可以爬到楼顶呢? 1阶,2阶,… m阶就是物品,楼顶就是背包。每一阶可以重复使用,例如…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

基于PIC32单片机实现Android USB音频转SPDIF输出的DIY方案
1. 项目概述:为Android设备打造一个高保真SPDIF音频接口作为一名长期折腾嵌入式音频和家庭影院的玩家,我经常遇到一个痛点:手头那些性能不错的Android手机或平板,其内置的3.5mm耳机孔或者USB-C口的音频输出质量,在连接…...

在数据预处理与分析流水线中集成大模型API进行智能标注与摘要
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在数据预处理与分析流水线中集成大模型API进行智能标注与摘要 对于数据工程师而言,处理海量非结构化文本数据是一项常见…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...
)
Sora 2原生MP4输出不兼容Premiere Pro?揭秘H.264/H.265封装层4大隐性缺陷(附MediaInfo诊断模板+自动修复脚本)
更多请点击: https://codechina.net 第一章:Sora 2原生MP4输出不兼容Premiere Pro的根源定位 Sora 2生成的原生MP4文件虽符合ISO/IEC 14496-14规范,但其底层封装结构与Adobe Premiere Pro对时间码、元数据及视频流编码参数的严格校验逻辑存在…...

告别RaiDrive广告!用开源rclone+Alist,免费把阿里云盘/百度网盘变成电脑本地硬盘
开源方案实战:用rcloneAlist打造无广告的云盘本地化体验 每次打开RaiDrive时弹出的广告窗口是否让您感到困扰?商业软件的收费模式是否让您犹豫不决?今天,我们将彻底解决这些问题。通过开源工具Alist和rclone的组合,您不…...