模型应用系实习生-模型训练笔记(更新至线性回归、Ridge回归、Lasso回归、Elastic Net回归、决策树回归、梯度提升树回归和随机森林回归)
sklearn机械学习模型步骤以及模型
- 一、训练准备(x_train, x_test, y_train, y_test)
- 1.1 导包
- 1.2 数据要求
- 1.21 导入数据
- 1.22 数据类型查看检测以及转换
- 1.22 划分数据
- 二、回归
- 2.1 线性回归
- 2.2 随机森林回归
- 2.3 GradientBoostingRegressor梯度提升树回归
- 2.4 Lasso回归
- 2.5 Ridge岭回归
- 2.6 Elastic Net回归
- 2.7 DecisionTreeRegressor决策树模型
- 自动化模型加评估
- 三、分类
- ...未完待续
本次训练的变量是一致对应的,训练准备通过后,后续建模都不会有报错的!
一、训练准备(x_train, x_test, y_train, y_test)
1.1 导包
scikit-learn包以及镜像
pip3 install --index-url https://pypi.douban.com/simple scikit-learn
1.2 数据要求
必须全部为数字类型且无空值才能进行训练,关于非数据类型需要进行相对处理例如:可以采用独热编码或者label编码进行处理。
本文演示的是pandas 的dataframe数据类型的操作,转换成别的类型也同理
1.21 导入数据
import pandas as pd
df = pd.read_csv('data.csv')
df.head(5) #查看数据前五条
1.22 数据类型查看检测以及转换
1. 通过df.info()查看类型以及缺失值情况
df.info()
2. label编码
使用sklearn中的LabelEncoder类,将标签分配给分类变量的不同类别,并将其转换为整数标签。
from sklearn.preprocessing import LabelEncoder
Label_df[i] = LabelEncoder().fit_transform(Label_df[i])
3. 独热编码
pd.get_dummies函数是Pandas中用于执行独热编码的函数。它将类别变量转换为独热编码的形式,其中每个类别将被转换为新的二进制特征,表示原始特征中是否存在该类别。这对于机器学习模型处理分类数据时非常有用。
例如,如果有一个类别特征"color",包含红色、蓝色和绿色三个类别。使用pd.get_dummies函数可以将这个特征转换为三个新的特征"color_red"、“color_blue"和"color_green”,它们的取值为0或1,表示原始特征中是否包含对应的颜色。
df_one_hot = pd.get_dummies(df, columns=['color'])
df_one_hot.replace({False: 0, True: 1})
4. 缺失值处理
直接删除
#删除指定列缺失值
df.dropna(subset=['身份证号'],inplace = True)
#删除NaN值
df.dropna(axis=0,inplace=True)
#全部为空就删除此行
df.dropna(axis=0,how="all",inplace=True)
#有一个为空就删除此行
df.dropna(axis=0, how='any', inplace=True)
填充
#数据填充
df.fillna(method='pad', inplace=True) # 填充前一条数据的值
df.fillna(method='bfill', inplace=True) # 填充后一条数据的值
df.fillna(df['cname'].mean(), inplace=True) # 填充平均值
5. 检测函数这里是我自己定义的高效快速便捷方式
检测函数,输入dataframe用for循环对每列检测和操作, 自动检测空值,object类型数据,并且进行默认操作,
df.fillna(method=‘pad’, inplace=True) # 填充前一条数据的值
df.fillna(method=‘bfill’, inplace=True) # 填充后一条数据的值
独热编码
df_one_hot = pd.get_dummies(df, columns=[‘color’])
返回处理好的dataframe
def process_dataframe(df):df.fillna(method='pad', inplace=True) # 填充前一条数据的值df.fillna(method='bfill', inplace=True) # 填充后一条数据的值df_one_hot = df.copy()for i in df.columns:if df[i].dtype == object:df_one_hot = pd.get_dummies(df, columns=[i]) # 独热编码return df_one_hot
更多dataframe操作可以看一下鄙人不才总结的小处理
http://t.csdnimg.cn/iRbFj
1.22 划分数据
from sklearn.model_selection import train_test_split
x_data = df.iloc[:, 0:-1]
y_data = df.iloc[:, -1]
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3, random_state=42)
二、回归
2.1 线性回归
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html#sklearn.linear_model.LinearRegression
训练以及简单预测
from sklearn.linear_model import LinearRegression
from sklearn import metrics#加载模型训练
Linear_R = LinearRegression()
Linear_R.fit(x_train, y_train)# 预测
y_pred = Linear_R.predict(x_test)# 评估
MAE_lr = metrics.mean_absolute_error(y_test, y_pred)
MSE_lr = metrics.mean_squared_error(y_test, y_pred)
RMSE_lr = metrics.mean_squared_error(y_test, y_pred, squared=False)
R2_Score_lr = r2_score(y_test, y_pred)
print("LinearRegression 评估")
print("MAE: ", MAE_lr)
print("MSE: ", MSE_lr)
print("RMSE: ", RMSE_lr)
print("R2 Score: ", R2_Score_lr)2.2 随机森林回归
from sklearn.ensemble import RandomForestRegressor
from sklearn import metrics#加载模型训练
RandomForest_R = RandomForestRegressor()
RandomForest_R.fit(x_train, y_train)# 预测
y_pred = RandomForest_R.predict(x_test)# 评估
MAE_Forest= metrics.mean_absolute_error(y_test, y_pred)
MSE_Forest = metrics.mean_squared_error(y_test, y_pred)
RMSE_Forest = metrics.mean_squared_error(y_test, y_pred, squared=False)
R2_Score_Forest = r2_score(y_test, y_pred)
print("LinearRegression 评估")
print("MAE: ", MAE_Forest)
print("MSE: ", MSE_Forest)
print("RMSE: ", RMSE_Forest)
print("R2 Score: ", R2_Score_Forest)
2.3 GradientBoostingRegressor梯度提升树回归
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html
这里是引用梯度提升树(GradientBoosting)是一种集成学习方法,通过构建多个弱预测模型(通常是决策树),然后将它们组合成一个强预测模型。梯度提升树通过迭代的方式训练决策树模型,每一次迭代都会针对之前迭代的残差进行拟合。它通过梯度下降的方式逐步改进模型,以最小化损失函数。
梯度提升树在每一轮迭代中,通过拟合一个新的弱模型来纠正之前模型的错误。在每一轮迭代中,它会计算出模型的负梯度(残差),然后用新的弱模型去拟合这个负梯度,使得之前模型的残差得到修正。最终,多个弱模型组合成一个强模型,可以用于回归问题和分类问题。在Scikit-Learn中,GradientBoostingRegressor是基于梯度提升树的回归模型。它可以通过调节树的数量、树的深度以及学习率等超参数来控制模型的复杂度和泛化能力。梯度提升树在处理各种类型的数据集时都表现良好,并且常被用于解决回归问题。
from sklearn.ensemble import GradientBoostingRegressor
from sklearn import metrics#加载模型训练
GradientBoosting_R = GradientBoostingRegressor()
GradientBoosting_R.fit(x_train, y_train)# 预测
y_pred = GradientBoosting_R.predict(x_test)# 评估
MAE_GradientBoosting= metrics.mean_absolute_error(y_test, y_pred)
MSE_GradientBoosting = metrics.mean_squared_error(y_test, y_pred)
RMSE_GradientBoosting = metrics.mean_squared_error(y_test, y_pred, squared=False)
R2_Score_GradientBoosting = r2_score(y_test, y_pred)
print("GradientBoostingRegressor 评估")
print("MAE: ", MAE_GradientBoosting)
print("MSE: ", MSE_GradientBoosting)
print("RMSE: ", RMSE_GradientBoosting)
print("R2 Score: ", R2_Score_GradientBoosting)
2.4 Lasso回归
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html#sklearn.linear_model.Lasso
Lasso回归(Least Absolute Shrinkage and Selection Operator Regression)是一种线性回归方法,它利用L1正则化来限制模型参数的大小,并倾向于产生稀疏模型。与传统的最小二乘法不同,Lasso回归在优化目标函数时,不仅考虑到数据拟合项,还考虑到对模型参数的惩罚项。
Lasso回归的优化目标函数是普通最小二乘法的损失函数加上L1范数的惩罚项
from sklearn.linear_model import Lasso
from sklearn import metrics#加载模型训练
Lasso_R = Lasso()
Lasso_R.fit(x_train, y_train)# 预测
y_pred = Lasso_R.predict(x_test)# 评估
MAE_Lasso= metrics.mean_absolute_error(y_test, y_pred)
MSE_Lasso = metrics.mean_squared_error(y_test, y_pred)
RMSE_Lasso = metrics.mean_squared_error(y_test, y_pred, squared=False)
R2_Score_Lasso = r2_score(y_test, y_pred)
print("Lasso 评估")
print("MAE: ", MAE_Lasso)
print("MSE: ", MSE_Lasso)
print("RMSE: ", RMSE_Lasso)
print("R2 Score: ", R2_Score_Lasso)
2.5 Ridge岭回归
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html#sklearn.linear_model.Ridge
from sklearn.linear_model import Ridge
from sklearn import metrics#加载模型训练
Ridge_R = Ridge()
Ridge_R.fit(x_train, y_train)# 预测
y_pred = Ridge_R.predict(x_test)# 评估
MAE_Ridge= metrics.mean_absolute_error(y_test, y_pred)
MSE_Ridge = metrics.mean_squared_error(y_test, y_pred)
RMSE_Ridge = metrics.mean_squared_error(y_test, y_pred, squared=False)
R2_Score_Ridge = r2_score(y_test, y_pred)
print("RidgeCV 评估")
print("MAE: ", MAE_Ridge)
print("MSE: ", MSE_Ridge)
print("RMSE: ", RMSE_Ridge)
print("R2 Score: ", R2_Score_Ridge)
2.6 Elastic Net回归
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ElasticNet.html
Elastic Net回归是一种结合了岭回归(Ridge Regression)和Lasso回归(Lasso
Regression)的线性回归模型。它通过结合L1和L2正则化惩罚项来克服岭回归和Lasso回归各自的限制,以达到更好的预测性能。岭回归使用L2正则化,它通过向损失函数添加一个惩罚项来限制模型参数的大小,防止过拟合。Lasso回归使用L1正则化,它倾向于产生稀疏的模型,即使大部分特征对目标变量没有影响,也会将它们的系数缩减为零。
Elastic
Net回归结合了L1和L2正则化的优点,可以同时产生稀疏模型并减少多重共线性带来的影响。它的损失函数包括数据拟合项和正则化项,其中正则化项是L1和L2范数的线性组合。Elastic Net回归在特征维度很高,且特征之间存在相关性时很有用。它可以用于特征选择和回归分析,尤其适用于处理实际数据集中的复杂问题。
from sklearn.linear_model import ElasticNet
from sklearn import metrics# 使用训练数据拟合模型
elastic_net = ElasticNet()
elastic_net.fit(x_train, y_train)# 预测
y_pred = elastic_net.predict(x_test)# 评估
MAE_ElasticNet= metrics.mean_absolute_error(y_test, y_pred)
MSE_ElasticNet = metrics.mean_squared_error(y_test, y_pred)
RMSE_ElasticNet = metrics.mean_squared_error(y_test, y_pred, squared=False)
R2_Score_ElasticNet = r2_score(y_test, y_pred)
print("ElasticNet 评估")
print("MAE: ", MAE_ElasticNet)
print("MSE: ", MSE_ElasticNet)
print("RMSE: ", RMSE_ElasticNet)
print("R2 Score: ", R2_Score_ElasticNet)
2.7 DecisionTreeRegressor决策树模型
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
from sklearn.tree import DecisionTreeRegressor
from sklearn import metricsdecision_tree = DecisionTreeRegressor()
decision_tree.fit(x_train, y_train)y_pred = decision_tree.predict(x_test)# 评估
MAE_decision_tree= metrics.mean_absolute_error(y_test, y_pred)
MSE_decision_tree = metrics.mean_squared_error(y_test, y_pred)
RMSE_decision_tree = metrics.mean_squared_error(y_test, y_pred, squared=False)
R2_Score_decision_tree = r2_score(y_test, y_pred)
print("DecisionTreeRegressor 评估")
print("MAE: ", MAE_decision_tree)
print("MSE: ", MSE_decision_tree)
print("RMSE: ", RMSE_decision_tree)
print("R2 Score: ", R2_Score_decision_tree)
自动化模型加评估
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.tree import DecisionTreeRegressorfrom sklearn.metrics import mean_absolute_error, mean_squared_error, mean_squared_error, r2_scoremodellist = [LinearRegression,RandomForestRegressor,GradientBoostingRegressor,Lasso,Ridge,ElasticNet,DecisionTreeRegressor]
namelist = ['LinearRegression','RandomForest','GradientBoosting','Lasso','Ridge','ElasticNet','DecisionTree']
RMSE = []
R2_Score = []for i in range(len(modellist)):mymodel = modellist[i]tr_model = mymodel()tr_model.fit(x_train, y_train)y_pred = tr_model.predict(x_train)print(f'{namelist[i]} 模型评估 \n MAE:{mean_absolute_error(y_train, y_pred)} MSE:{mean_squared_error(y_train, y_pred)} RMSE:{mean_squared_error(y_train,y_pred, squared=False)} R2 Score:{r2_score(y_train, y_pred)}')y_pred = tr_model.predict(x_test)RMSE.append(mean_squared_error(y_test,y_pred, squared=False))R2_Score.append(r2_score(y_test, y_pred))
data_show = pd.concat([pd.DataFrame(RMSE),pd.DataFrame(R2_Score),pd.DataFrame(namelist)],axis=1)
data_show.columns = ['RMSE','R2_Score','model']
data_show三、分类
…未完待续
相关文章:
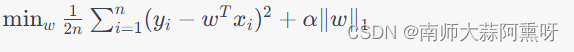
模型应用系实习生-模型训练笔记(更新至线性回归、Ridge回归、Lasso回归、Elastic Net回归、决策树回归、梯度提升树回归和随机森林回归)
sklearn机械学习模型步骤以及模型 一、训练准备(x_train, x_test, y_train, y_test)1.1 导包1.2 数据要求1.21 导入数据1.22 数据类型查看检测以及转换1.22 划分数据 二、回归2.1 线性回归2.2 随机森林回归2.3 GradientBoostingRegressor梯度提升树回归2…...

【Verilog】7.2.1 Verilog 并行 FIR 滤波器设计
FIR(Finite Impulse Response)滤波器是一种有限长单位冲激响应滤波器,又称为非递归型滤波器。 FIR 滤波器具有严格的线性相频特性,同时其单位响应是有限长的,因而是稳定的系统,在数字通信、图像处理等领域…...

【音视频 | wav】wav音频文件格式详解——包含RIFF规范、完整的各个块解析、PCM转wav代码
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

人工智能基础_机器学习012_手写梯度下降代码演示_手动写代码完成梯度下降_并实现梯度下降可视化---人工智能工作笔记0052
可以看到上面我们那个公式,现在我们用梯度下降实现一下,比如我们有一堆数据,但是没有方程的情况下,我们来看一下如果计算,对应的w值也就是seta值对吧,没有方程我们可以使用梯度下降 这里首先我们可以设置一个0.0001.我们知道梯度下降的公式, 梯度下降刚开始的时候,下降会快,然…...

Docker安装部署[8.x]版本Elasticsearch+Kibana+IK分词器
文章目录 Docker安装部署elasticsearch拉取镜像创建数据卷创建网络elasticsearch容器,启动!踩坑:虚拟机磁盘扩容 Docker安装部署Kibana拉取镜像Kibana容器,启动! 安装IK分词器安装方式一:直接从github上下载…...

折纸达珠峰高度(forwhile循环)
对折0.1mm厚度的纸张多少次,高度可达珠峰高度8848180mm。 (本笔记适合熟悉循环和列表的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅…...

探索网络攻防技术:自学之道
在当今数字化时代,网络攻防技术的重要性日益凸显。无论是个人用户还是企业组织,都需要具备一定的网络安全意识和基本技能来应对日益复杂的网络威胁。自学网络攻防技术成为许多人的选择,今天我们将探讨如何高效、有序地自学网络攻防技术。 如果…...

图像二值化阈值调整——cv2.threshold方法
二值化阈值调整:调整是指在进行图像二值化处理时,调整阈值的过程。阈值决定了将图像中的像素分为黑色和白色的界限,大于阈值的像素被设置为白色,小于等于阈值的像素被设置为黑色。 方法一: 取阈值为 127,…...

【C++代码】背包问题,完全背包,多重背包,打家劫舍,动态规划--代码随想录
爬楼梯(plus) 一步一个台阶,两个台阶,三个台阶,…,直到 m个台阶。问有多少种不同的方法可以爬到楼顶呢? 1阶,2阶,… m阶就是物品,楼顶就是背包。每一阶可以重复使用,例如…...

阿里云创始人王坚:云计算和GPT的关系,就是电和电机的关系
10月31日,在2023云栖大会,中国工程院院士、阿里云创始人王坚以《云计算的第三次浪潮》为主题发表演讲,他认为人工智能和云计算的结合,带来云计算的第三次浪潮,它不会在一年、两年完成,它可能会给我们十年、…...

python爬取豆瓣电影Top250数据
本次爬虫案例使用Python语言编写,使用了requests库进行网页请求,使用了BeautifulSoup库进行网页解析,使用了openpyxl库进行数据的保存。 案例中的爬虫目标是豆瓣电影Top250,通过循环访问不同页面进行数据的爬取。在每个页面上&am…...
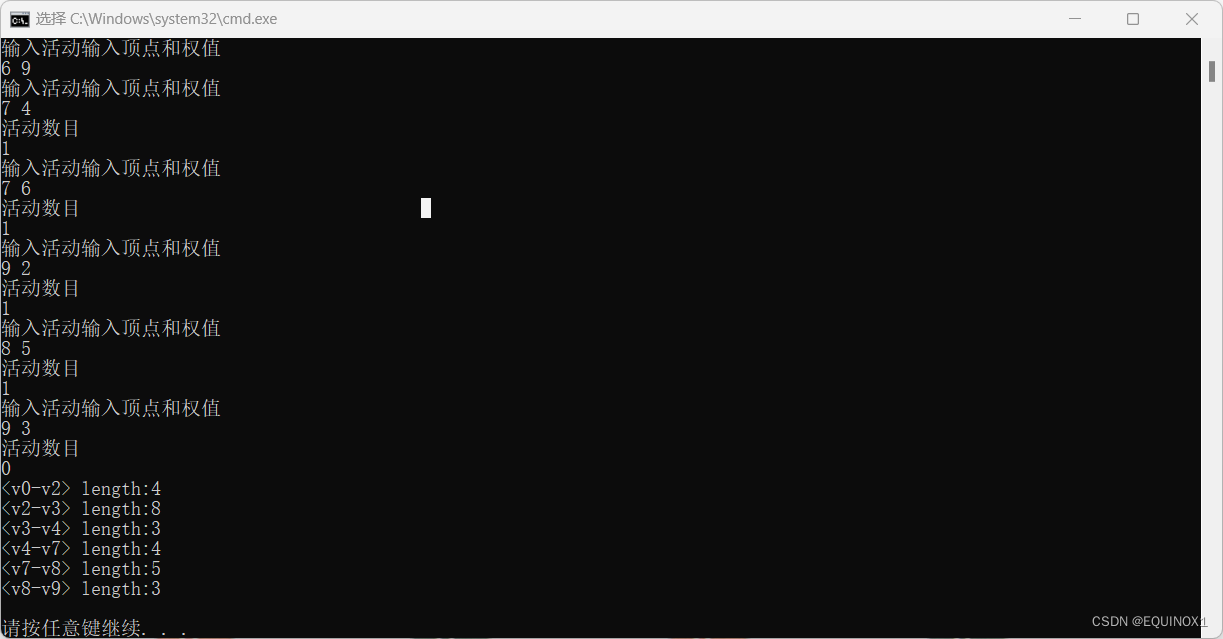
关键路径及关键路径算法[C/C++]
文章目录 关键路径引例AOE网关键路径与关键活动关键路径算法引例与原理关键路径算法的实现边的存储结构代码实现运行示例 关键路径 关于拓扑排序的内容见拓扑排序详解 引例 通过拓扑排序我们可以解决一个工程是否可以顺序进行的问题,拓扑排序把一个工程分成了若干…...

nginx http 跳转到https
改 Nginx 配置文件 在您安装了 SSL 证书之后,您需要修改 Nginx 的配置文件以启用 HTTPS 和 HTTP 自动跳转 HTTPS。 打开 Nginx 配置文件(通常位于 /etc/nginx/nginx.conf),找到您的网站配置块。在该配置块中添加以下内容&#x…...

可靠的互联网兼职平台,平常可以做副业充实生活
在互联网时代,越来越多的人开始通过网络来寻找兼职副业的机会,能够更灵活地安排自己的时间,实现自己的收入增值。那么找到一个正规可靠的线上兼职平台就是一个比较重要的事情,这里分享几个正规靠谱的线上兼职副业平台,…...
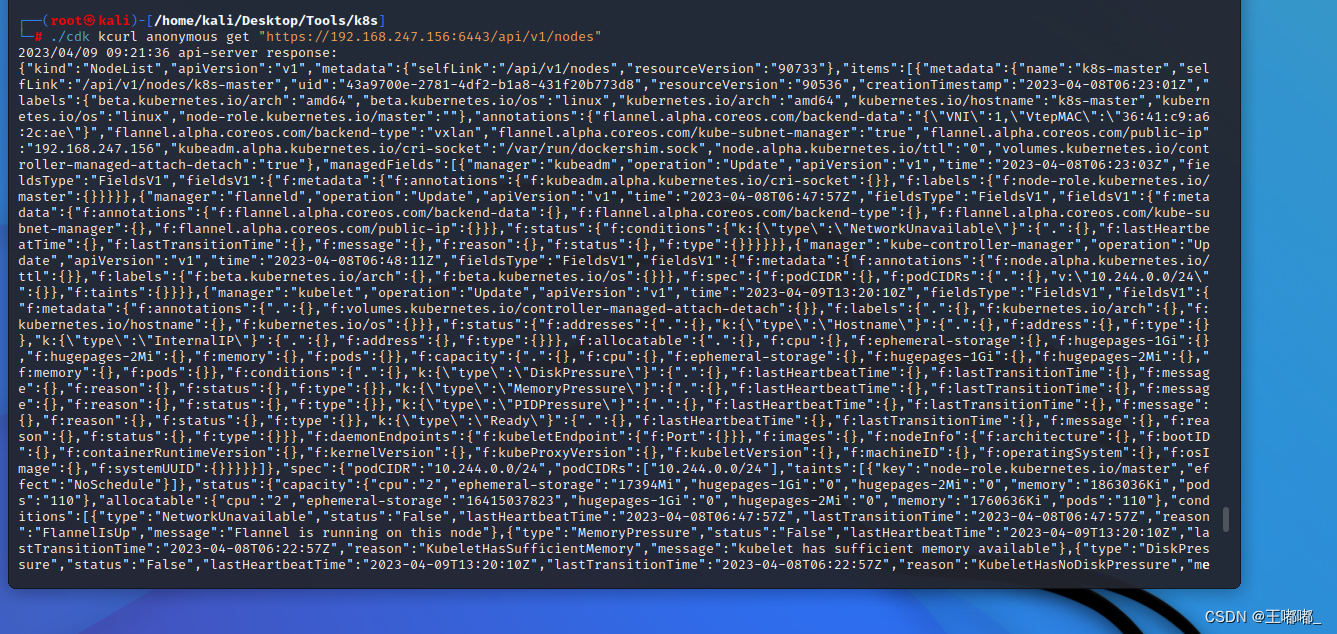
云安全—K8s APi Server 6443 攻击面
0x00 前言 在未授权的一文中,详细描述了k8s api中的8080端口未授权的问题,那么本篇主要来说6443端口的利用。 0x01 API连接攻击面 1.匿名用户访问 匿名开放方式:kubectl create clusterrolebinding cluster-system-anonymous --clusterro…...

【案例实战】NodeJS+Vue3+MySQL实现列表查询功能
这篇文章,给大家带来一个列表查询的功能,从前端到后端的一个综合案例实战。 采用vue3作为前端开发,nodejs作为后端开发。 首先我们先来看一下完成的页面效果。点击分页,可以切换到上一页、下一页。搜索框可以进行模糊查询。 后端…...
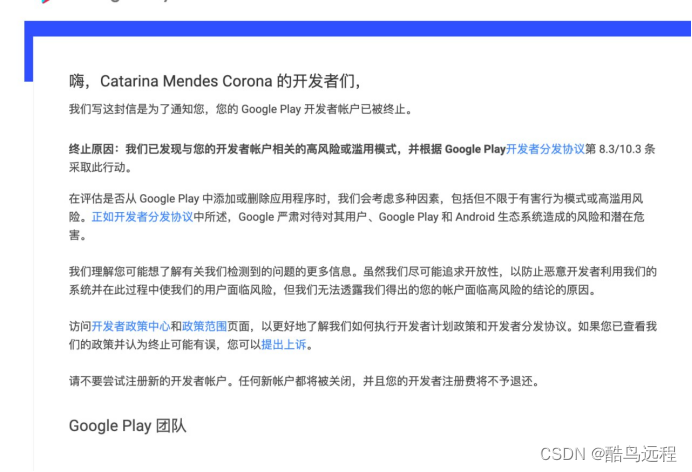
Google play开发者账号被封的几种常见原因及相关解决思路
在Google paly上,每天都有大量的应用被成功发布,同时也有很多开发者账号被封禁。特别是在今年的十月份之前,谷歌的"封号潮"给很多开发者带来了沉重的打击。不过,令人欣慰的是,自十月份之后,情况逐…...

深入理解计算机系统CS213学习笔记
Lecture 01 1. 计算机表示数字 int 整数运算可能会出现错误,超过32位时会出现溢出。 float 浮点数不适用结合律,因为浮点数表示的精度有限。 根其原因,是用有限的位数表示无限的数字空间。 2.利用分层的存储系统,使程序运行更…...
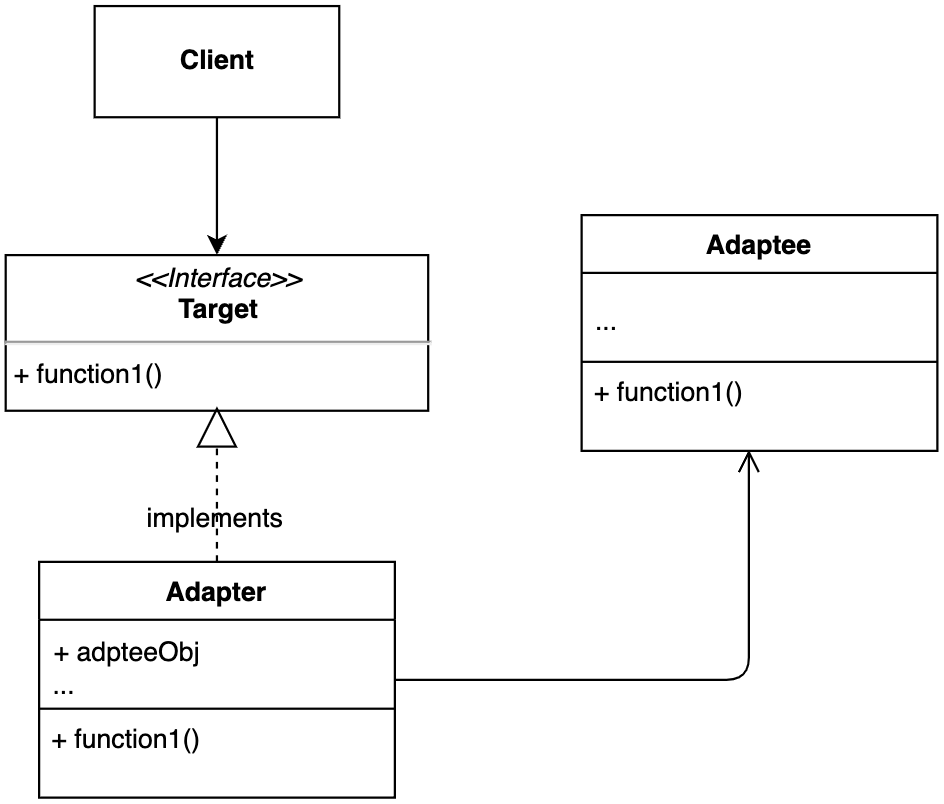
【设计模式】第8节:结构型模式之“适配器模式”
一、简介 适配器模式是用来做适配的,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作。 适配器模式角色: 请求者client:调用服务的角色目标Target:定义了Client要使用的功…...
Stable Diffusion WebUI扩展openpose-editor如何使用
先上地址: GitHub - fkunn1326/openpose-editor: Openpose Editor for AUTOMATIC1111s stable-diffusion-webuiOpenpose Editor for AUTOMATIC1111s stable-diffusion-webui - GitHub - fkunn1326/openpose-editor: Openpose Editor for AUTOMATIC1111s stable-diffusion-webu…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍
Diablo Edit2:3步掌握暗黑破坏神2存档修改的终极秘籍 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神2中刷装备的漫长过程感到疲惫吗?Diablo Edit2这款免费…...

智能知识学习平台
智能知识学习平台项目简介技术架构:问答驱动的开发模式前端架构后端架构核心功能:问答式交互贯穿始终1. 自定义构建知识库2.文档查看3.智能问答:知识触手可及4. 智能题目生成:严格遵循文档内容项目亮点用问答驱动的方式构建智慧学…...

如何永久保存微信聊天记录?WeChatMsg数据导出完整指南
如何永久保存微信聊天记录?WeChatMsg数据导出完整指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

从UE/Unity转战Godot:一个老引擎开发者的踩坑与真香实录
从UE/Unity转战Godot:一个老引擎开发者的踩坑与真香实录 第一次双击Godot图标时,我正坐在堆满Unity参考书的办公桌前。作为用过五年Unity、三年Unreal的"引擎老油条",我带着审视新玩具的心态点开了这个不到100MB的绿色软件——没想…...

2026国安部重磅披露:境外间谍如何利用民用路由器构建窃密跳板?全链路技术解析与防御指南
一、引言:从"网速变慢"到国家级网络窃密 2026年5月20日,国家安全部官方微信公众号发布紧急通报,披露了一起严重的境外间谍情报机关网络窃密案件。与以往直接攻击政府或企业服务器不同,此次攻击者将目标锁定在了最容易被…...

Unity Find Reference2 2.5.2版本深度解析与正确接入指南
1. 这不是普通插件下载:Find Reference2 的真实价值与误用重灾区“Unity Find Reference2 2.5.2版本资源下载”——看到这个标题,很多Unity开发者第一反应是点开就找网盘链接、GitHub Release页面或某论坛的打包附件。我试过不下二十次:复制标…...

UE5 Niagara实战:用‘定位事件’和‘死亡事件’模块,5分钟做出粒子追踪与消散特效
UE5 Niagara实战:5分钟打造魔法飞弹的粒子追踪与消散特效在游戏开发中,粒子特效是营造沉浸感的关键元素之一。想象一下:一枚魔法飞弹划过夜空,身后拖曳着流光溢彩的尾迹,击中目标时爆裂成绚丽的火花——这种动态效果正…...