深度学习入门(二)之 简单手写数字识别实现
文章目录
- 引入MINIST数据脚本
- 读入MNIST数据
- 神经网络推理处理
- 批处理
引入MINIST数据脚本
load_mnist为重要关注函数
params:
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
# coding: utf-8
try:import urllib.request
except ImportError:raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as npurl_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {'train_img': 'train-images-idx3-ubyte.gz','train_label': 'train-labels-idx1-ubyte.gz','test_img': 't10k-images-idx3-ubyte.gz','test_label': 't10k-labels-idx1-ubyte.gz'
}dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784def _download(file_name):file_path = dataset_dir + "/" + file_nameif os.path.exists(file_path):returnprint("Downloading " + file_name + " ... ")urllib.request.urlretrieve(url_base + file_name, file_path)print("Done")def download_mnist():for v in key_file.values():_download(v)def _load_label(file_name):file_path = dataset_dir + "/" + file_nameprint("Converting " + file_name + " to NumPy Array ...")with gzip.open(file_path, 'rb') as f:labels = np.frombuffer(f.read(), np.uint8, offset=8)print("Done")return labelsdef _load_img(file_name):file_path = dataset_dir + "/" + file_nameprint("Converting " + file_name + " to NumPy Array ...")with gzip.open(file_path, 'rb') as f:data = np.frombuffer(f.read(), np.uint8, offset=16)data = data.reshape(-1, img_size)print("Done")return datadef _convert_numpy():dataset = {}dataset['train_img'] = _load_img(key_file['train_img'])dataset['train_label'] = _load_label(key_file['train_label'])dataset['test_img'] = _load_img(key_file['test_img'])dataset['test_label'] = _load_label(key_file['test_label'])return datasetdef init_mnist():download_mnist()dataset = _convert_numpy()print("Creating pickle file ...")with open(save_file, 'wb') as f:pickle.dump(dataset, f, -1)print("Done!")def _change_one_hot_label(X):T = np.zeros((X.size, 10))for idx, row in enumerate(T):row[X[idx]] = 1return Tdef load_mnist(normalize=True, flatten=True, one_hot_label=False):"""读入MNIST数据集Parameters----------normalize : 将图像的像素值正规化为0.0~1.0one_hot_label : one_hot_label为True的情况下,标签作为one-hot数组返回one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组flatten : 是否将图像展开为一维数组Returns-------(训练图像, 训练标签), (测试图像, 测试标签)"""if not os.path.exists(save_file):init_mnist()with open(save_file, 'rb') as f:dataset = pickle.load(f)if normalize:for key in ('train_img', 'test_img'):dataset[key] = dataset[key].astype(np.float32)dataset[key] /= 255.0if one_hot_label:dataset['train_label'] = _change_one_hot_label(dataset['train_label'])dataset['test_label'] = _change_one_hot_label(dataset['test_label'])if not flatten:for key in ('train_img', 'test_img'):dataset[key] = dataset[key].reshape(-1, 1, 28, 28)return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])if __name__ == '__main__':init_mnist()
知识补充:
sys.path.append(os.pardir) 为了导入父目录中的文件而进行的设定
读入MNIST数据
调用mnist.py中的load_mnist()函数读入MNIST数据
# coding: utf-8
import sys, ossys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
from dataset.mnist import load_mnist # 打开dataset文件夹下的mnist.py模块并导入其中的load_mnist方法
from PIL import Image # 导入模块PIL中的Image方法
import matplotlib.pyplot as plt# 该函数仅为了把图片展示出来,别的也没啥用
def img_show(img):plt.imshow(img) # 对图片image进行数据处理plt.show() # 将图片显示出来# 以下是看看这第一个图像的真面目
# 展开输入图像为一维数组并正规化"""读入MNIST数据集Parameters----------normalize : 将图像的像素值正规化为0.0~1.0one_hot_label : one_hot_label为True的情况下,标签作为one-hot数组返回one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组flatten : 是否将图像展开为一维数组Returns-------(训练图像, 训练标签), (测试图像, 测试标签)"""
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)# 将训练图像的第一个数据赋值给img(大小为28*28像素=784)
img = x_train[0]
# 将训练标签的第一个数据赋值给label
label = t_train[0]
print(label) # 第一个数据标签是5
print(img.shape) # 第一个图像的形状是(784,)img = img.reshape(28, 28) # 把图像的形状变为原来的(28*28)尺寸,更改numpy数组的形状
print(img.shape) # (28, 28)img_show(img)
神经网络推理处理
神经网络的输入层有784个神经元,输出层有10个神经元。784来源于图像的大小28*28,10来源于10类数,这个神经网络有2个隐藏层,第一个隐藏层有50个神经元,第二个隐藏层有100个神经元.50和100可以设置为任意值。
init_network函数会读入学习到的权重参数,这个文件中以字典的形式保存了权重和偏置参数。这节省略过参数的学习。
predict函数进行分类,以numpy数组的形式输出各个标签的概率,比如[0.1,0.5,0.1…],1的概率为0.5,最后取出这个数组的最大值的索引作为预测结果,最后比较预测结果和正确答案,将回答正确的概率作为识别精度。
将图像的各个像素除以255,使得数据的值在0.0~1.0的范围中,对数据限定到某个范围内的处理为正规化处理,另外对神经的输入数据进行某种转化称为预处理,这里可以说为对输入图像的一种预处理,进行了正规化
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax#获取训练图集,训练标签
def get_data():(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)return x_test, t_test# 读入保存在pickle文件sample_weight.pkl中的学习到的权重参数,返回network参数,里面包含权重和偏置
def init_network():with open("sample_weight.pkl", 'rb') as f:network = pickle.load(f)return network# 数据处理生成预测结果
def predict(network, x):W1, W2, W3 = network['W1'], network['W2'], network['W3']b1, b2, b3 = network['b1'], network['b2'], network['b3']# 输入层到第一隐藏层a1 = np.dot(x, W1) + b1z1 = sigmoid(a1)# 第一隐藏层到第二隐藏层a2 = np.dot(z1, W2) + b2z2 = sigmoid(a2)# 第二隐藏层到输出层a3 = np.dot(z2, W3) + b3y = softmax(a3)return y# 获取测试图像和测试标签 x.shape (10000,784) t.shape(10000) t为标签
x, t = get_data()
# 生成网络,获取权重参数
network = init_network()# 精度初始化
accuracy_cnt = 0# 逐一取出x测试图像中的值 len(x)为10000
for i in range(len(x)):# 得到x[i]的预测结果为y ,y为一个数组,y=[0.1,0.3,.....],y.shape=10y = predict(network, x[i])p= np.argmax(y) # 获取概率最高的元素的索引if p == t[i]: # t[i]表示当前图像的真实值accuracy_cnt += 1
# 正确个数/总数据个数
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))Accuracy:0.9352
最后输出精确度为93%
批处理
用predict()函数一次性打包100张图片进行处理,可以把之前输入1*784变为100 * 784,
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmaxdef get_data():(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)return x_test, t_testdef init_network():with open("sample_weight.pkl", 'rb') as f:network = pickle.load(f)return networkdef predict(network, x):w1, w2, w3 = network['W1'], network['W2'], network['W3']b1, b2, b3 = network['b1'], network['b2'], network['b3']a1 = np.dot(x, w1) + b1z1 = sigmoid(a1)a2 = np.dot(z1, w2) + b2z2 = sigmoid(a2)a3 = np.dot(z2, w3) + b3y = softmax(a3)return yx, t = get_data()
network = init_network()batch_size = 100 # 批数量
accuracy_cnt = 0for i in range(0, len(x), batch_size):x_batch = x[i:i+batch_size] # x_batch[0:100] # x_batch.shape = (100, 784)y_batch = predict(network, x_batch) #y_batch.shape = (100, 10)"""axis = 1,指定在100*10数组中,沿着行方向找到值最大的元素的索引0:列方向1:行方向"""p = np.argmax(y_batch, axis=1 # p.shape = (100,)accuracy_cnt += np.sum(p == t[i:i+batch_size]) # 计算true的个数
# 正确个数/总数据个数
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
相关文章:
之 简单手写数字识别实现)
深度学习入门(二)之 简单手写数字识别实现
文章目录 引入MINIST数据脚本读入MNIST数据神经网络推理处理批处理 引入MINIST数据脚本 load_mnist为重要关注函数 params: normalize : 将图像的像素值正规化为0.0~1.0 one_hot_label : one_hot_label为True的情况下,标签作为one-hot数组返回 one-hot数…...
USART HMI串口屏+单片机通讯上手体验
USART HMI串口屏单片机通讯上手体验 🔖本文采用淘晶驰4.3寸IPS串口屏实物验证,HMI串口屏经简单配置即可快速实现,串口通讯效果。串口屏上手简单,有独立的开发套件,容易上手,驱动显示和功能代码独立。本文仅…...

Linux进程概念(1)
📟作者主页:慢热的陕西人 🌴专栏链接:Linux 📣欢迎各位大佬👍点赞🔥关注🚓收藏,🍉留言 本博客主要内容为进程的概念做铺垫,主要介绍冯诺依曼体系结…...
uniapp 查看安卓第三方插件抛出的异常
0.安装好andriod studio 和hbuilder 1.配置环境变量 鼠标右键此电脑-》设置》关于》高级系统设置》环境变量》系统变量》path中加入 具体的hbuildr adb目录看个人 2.在cmd中输入命令adb version 查看是否配置成功 出现版本号就是配置成功了 3.去hbuilder中,导航栏运…...
美妆造型教培服务预约小程序的作用是什么
美业市场规模很高,细分类目更是比较广,而美妆造型就是其中的一类,从业者也比较多,除了学校科目外,美妆造型教培机构也有生意。 对机构来说主要目的是拓客引流-转化及赋能,而想要完善路径却是不太容易&…...

Pytorch常用函数
Pytorch 1 一些操作含义2 常用函数torch.squeezetorch.unsqueezetorch.transpose随机数生成Tensor详细内容 1 一些操作含义 下划线后缀含义: 在touch中函数后面加下划线代表是原位(In-place)操作,也就是内存的位置不变化,比如torch.add(valu…...

如何利用python连接讯飞的星火大语言模型
星火大模型是科大讯飞推出的一款人工智能语言模型,它采用了华为的昇腾910 AI处理器。这款处理器是一款人工智能处理器,具有强大的计算能力和高效的能耗控制能力。 华为昇腾910 AI处理器采用了创新的Da Vinci架构,这种架构在设计上充分考虑了…...
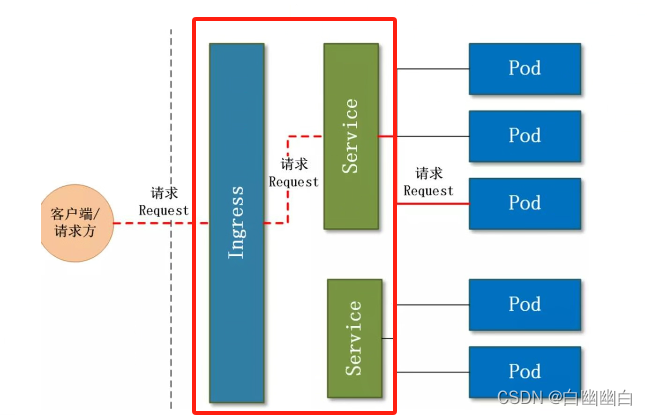
【Kubernetes 基本概念】Kubernetes 的架构和核心概念
目录 一、Kurbernetes1.1 简介1.2 为什么要用K8s?1.3 K8s的特性 二、Kurbernetes集群架构与组件三、Kurbernetes的核心组件3.1 Master组件3.1.1 Kube-apiserver3.1.2 Kube-controller-manager3.1.3 Kube-scheduler 3.2 配置存储中心——etcd3.3 Node组件3.3.1 Kubelet3.3.2 Ku…...

Docker安装部署Elasticsearch+Kibana+IK分词器
Docker安装部署ElasticsearchKibanaIK分词器 Docker安装部署elasticsearch拉取镜像创建数据卷创建网络elasticsearch容器,启动! Docker安装部署Kibana拉取镜像Kibana容器,启动! 安装IK分词器安装方式一:直接从github上…...
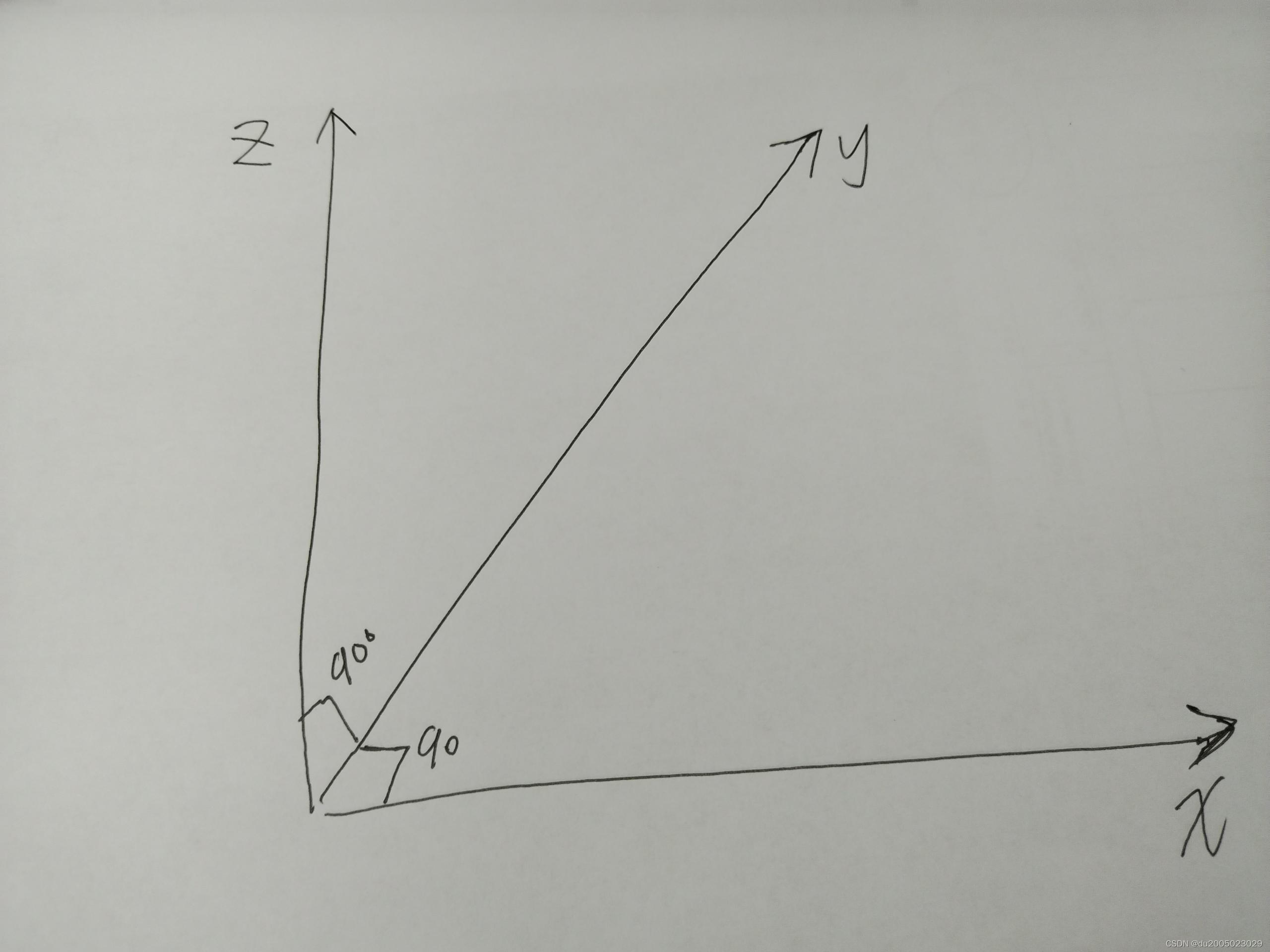
PCL setCameraPosition 参数讲解
setCameraPosition 的原型如下void setCameraPosition (double pos_x, double pos_y, double pos_z,double view_x, double view_y, double view_z,double up_x, double up_y, double up_z, int viewport 0);pos_x pos_y pos_z为相机所在的位置view_x view_y view_z 是焦点所…...

有关YOLOV5在测试时,图片大小被调整的问题
执行detect.py文件,在运行栏中出现以下: detect: weightsyolov5s.pt, sourcedata\images, datadata\coco128.yaml, imgsz[640, 640], conf_thres0.25, iou_thres0.45, max_det1000, device, view_imgFalse, save_txtFalse, save_confFalse, save_cropFa…...

【机器学习】四、计算学习理论
1 基础知识 计算学习理论(computational learning theory):关于通过“计算”来进行“学习”的理论,即关于机器学习的理论基础,其目的是分析学习任务的困难本质,为学习算法体统理论保证,并根据结…...
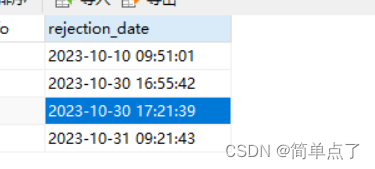
spring解决后端显示时区的问题
spring解决后端显示时区的问题 出现的问题: 数据库中的数据: 解决方法 spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: Asia/Shanghai...

大模型冷思考:企业“可控”价值创造空间还有多少?
文 | 智能相对论 作者 | 叶远风 毫无疑问,大模型热潮正一浪高过一浪。 在发展进程上,从最开始的技术比拼到现在已开始全面强调商业价值变现,百度、科大讯飞等厂商都喊出类似“不能落地的大模型没有意义”等口号。 在模型类型上࿰…...

ctfshow-web入门37-52
include($c);表达式包含并运行指定文件。 使用data伪协议 ?cdata://text/plain;base64,PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKTs/Pg PD9waHAgc3lzdGVtKCdjYXQgZmxhZy5waHAnKTs/Pg 是<?php system(cat flag.php);?> base64加密 源代码查看得到flag 38 多禁用了ph…...

前端项目部署后,需要刷新页面才能看到更新内容
问题背景 前端项目部署更新后,通知业务验证,业务点击收藏的标签,打开网页后没有看到修改的内容,每次都需要手动刷新,用户体验非常不好。 问题原因:缓存未过期,浏览器直接读取本地缓存…...
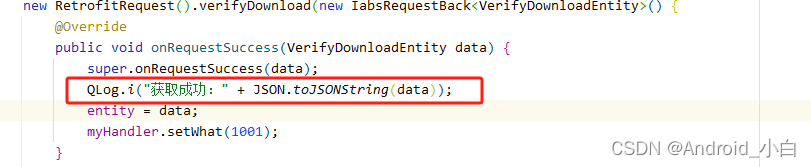
android 13 write javaBean error at *** 错误
报错代码:红框处。 注意:android10 不会报错,运行正常。android13就报错 错误原因:对象中VerifyDownloadEntity,有个Bitmap成员变量 public class VerifyDownloadEntity {private Bitmap bitmap;private String cooki…...

Only fullscreen opaque activities can request orientation
出现Only fullscreen opaque activities can request orientation是谷歌爸爸在安卓8.0版本时为了支持全面屏,增加了一个限制:如果是透明的Activity,则不能固定它的方向,因为它的方向其实是依赖其父Activity的(因为透明…...
前端实验(一)单页面应用的创建
实验目的 掌握使用vite创建vue3单页面程序命令熟悉所创建程序的组织结构熟悉单页面程序运行原理能够编写简单的单页面程序 实验内容 创建一个名为vue-demo的单页面程序编写简单的单页面程序页面运行单页面程序 实验步骤 使用vite创建单页面程序 创建项目名为目录vue-demo的…...

数字人小灿:始于火山语音,发于 B 端百业
火爆的数字人市场又有新消息来袭:火山语音的数字人小灿来了! 数字人小灿首曝视频 今年以来,在生成式AI浪潮的助推下,大量企业争相布局数字人赛道。市场之所以如此火热,是因为AI数字人已被视为人工智能时代智能交互的入…...
做面部表情,从Blender雕刻到引擎驱动全流程)
别再只用骨骼了!用UE5的Morph Target(BlendShape)做面部表情,从Blender雕刻到引擎驱动全流程
别再只用骨骼了!用UE5的Morph Target(BlendShape)做面部表情,从Blender雕刻到引擎驱动全流程面部动画一直是游戏开发中最具挑战性的领域之一。许多开发者习惯性地认为面部表情必须通过骨骼系统驱动,这种"唯骨骼论…...

ImageSearch与Everything集成:如何利用文件搜索神器提升索引速度10倍
ImageSearch与Everything集成:如何利用文件搜索神器提升索引速度10倍 【免费下载链接】ImageSearch 基于.NET10的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 想要在本地硬盘…...

Atlas-Learn:从点云构建流形图册的工程实践与黎曼优化应用
1. 项目概述:从点云到流形图册的工程实践在机器学习和数据科学领域,我们常常面对一个核心困境:数据点看似散落在高维的欧几里得空间中,但其内在的、有意义的规律却往往存在于一个低维的非线性结构上。想象一下,你有一堆…...
)
生物医药合成生物学解决方案(2026版)
生物医药合成生物学解决方案(2026版) 目录 第1章项目概述 7 1.1项目背景 7 1.2项目目标 8 1.2.1技术目标 8 1.2.2业务目标 8 1.2.3经济目标 9 1.2.4社会目标 9 1.3项目范围 10 1.4项目意义 11 1.4.1产业意义 11 1.4.2技术意义 11 1.4.3经济意义 11 1.4.4社会意义 12 1.5项目…...

图片马与文件包含漏洞:Webshell渗透链路深度解析
1. 为什么一张普通图片能执行PHP代码?——从“图片马”开始讲清Web渗透的底层逻辑你有没有遇到过这样的场景:上传一张JPG格式的图片到网站头像系统,结果服务器返回了500 Internal Server Error,但用Burp Suite抓包一看,…...

机器学习势能面构建实战:从量子化学数据到高精度分子模拟
1. 项目概述:当机器学习“学会”了化学反应的势能面在计算化学的世界里,我们一直面临着一个核心矛盾:精度与效率的权衡。如果你想精确地描述一个化学反应,比如DNA复制过程中碱基对的质子转移,你需要动用量子化学方法&a…...

机器学习系统能源优化:Magneton框架与能效提升实践
1. 机器学习系统中的能源浪费现状在当今大规模机器学习应用场景中,能源效率已成为与计算性能同等重要的关键指标。根据行业实测数据,一个典型的大型语言模型推理任务可能消耗相当于数十个家庭日用电量的能源。这种惊人的能源消耗背后,隐藏着大…...

ComfyUI-Custom-Scripts自动完成功能完整指南:提升AI绘画效率的终极解决方案
ComfyUI-Custom-Scripts自动完成功能完整指南:提升AI绘画效率的终极解决方案 【免费下载链接】ComfyUI-Custom-Scripts Enhancements & experiments for ComfyUI, mostly focusing on UI features 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Custo…...

为什么Rotating-machine-fault-data-set是机械故障诊断研究的必备资源?
为什么Rotating-machine-fault-data-set是机械故障诊断研究的必备资源? 【免费下载链接】Rotating-machine-fault-data-set Open rotating mechanical fault datasets (开源旋转机械故障数据集整理) 项目地址: https://gitcode.com/gh_mirrors/ro/Rotating-machin…...

企业官网后台的工程化设计:内容建模、所见即所得与源码自主可控
企业官网后台的工程化设计:内容建模、所见即所得与源码自主可控 “网站做完我们自己能改吗?要不要技术?”——这个业务问题,在工程层面其实是问:这套 CMS 的内容模型、编辑体验、权限和可维护性设计得怎么样。 后台&qu…...