深度学习_2 数据操作之数据预处理
数据操作
机器学习包括的核心组件有:
- 可以用来学习的数据(data);
- 如何转换数据的模型(model);
- 一个目标函数(objective function),用来量化模型的有效性;
- 调整模型参数以优化目标函数的算法(algorithm)。
我们要从数据中提取出特征,机器学习、深度学习通过特征来进一步计算得到模型。因此下面主要介绍的是对数据要做哪些操作。
基本操作
深度学习里最多操作的数据结构是N维的数组。
0维:一个数,一个标量,比如1.
1维:比如一个一维数组,他的数据是一个一维的向量(特征向量)。
2维:比如二维数组(特征矩阵)。
当然还有更多维度,比如视频的长,宽,时间,批量大小,通道……
如果我们想创建这样一个数组,需要明确的因素:
- 数组结构,比如3*4.
- 数组数据类型,浮点?整形?
- 具体每个元素的值。
访问元素的方式:
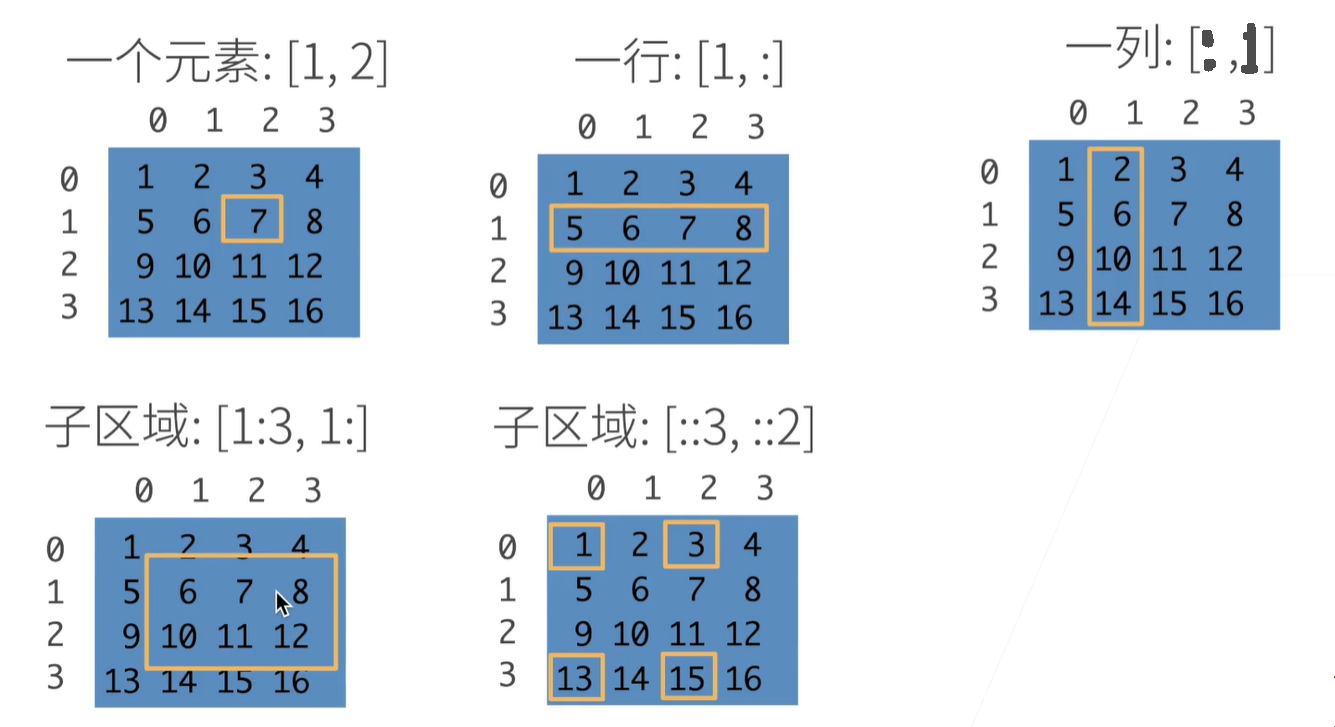
1:3 是左闭右开,表示不包含第3行。
双冒号是跳着访问,后跟步长。比如 ::3 表示从第0行开始访问,每3行访问一次。
明白了这些,那接下来我们就创建一个数组。在机器学习中这种数据的容器一般被称作张量.
创建张量
这部分代码在 jupyter/pytorch/chapter_preliminaries/ndarray.ipynb 里。
在其中可以运行尝试代码部分,创建一维张量:
import torch
X = torch.arange(12) # 自动创建 0-11 的一维张量。输入 X 查看 X 内元素数据,输出:
# tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
X.shape # 查看向量形状。输出 torch.Size([12]),指长12的一维向量
X.numel() # 只获取长度,输出12
X = X.reshape(3, 4) # 重新改成了3行4列形状。变成了0123 4567 891011
torch.zeros((2, 3, 4)) # 创建了一个形状为(2,3,4)的全0张量
# tensor([[[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]],
#
# [[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]]])
# torch.ones 同理,是全1的
# torch.randn 是取随机数,随机数是均值=0,方差=1的一个高斯分布中取
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]) # 给定值创建
torch.exp(X) # 求e^x中每个元素值得到的新张量
reshape 很有意思,它不是复制原数组后重新开辟了一片空间,而是还是对原数组元素的操作(只不过原来是连续12个数,现在我们把他们视作4个一行的3行元素。存储空间都是连续的)。因此如果我们对 reshape 后的数组赋值,原数组值也会改变。
算术运算
对于两个相同形状的向量可以进行+ - * / **(求幂运算)运算。
x = torch.tensor([1.0, 2, 4, 8]) # 1.0 为了让这个数组变成浮点数组
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
# Output:
(tensor([ 3., 4., 6., 10.]),tensor([-1., 0., 2., 6.]),tensor([ 2., 4., 8., 16.]),tensor([0.5000, 1.0000, 2.0000, 4.0000]),tensor([ 1., 4., 16., 64.]))
x==y # 每一项分别判断是否相等。我试了一下,数据类型不影响。2.0==2
x.sum() # 所有元素求和
张量连接
X = torch.arange(12, dtype=torch.float32).reshape((3,4)) # 创建 float32 位的张量
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1) # 行和列两个维度的拼接
# Output:
(tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]]),tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
# 这里我看到弹幕前辈的讲解,感觉很受用。行是样例,列是特征属性,这个类似 MySQL 的关系数据库理解
广播机制
即使两个张量形状不同,也有可能通过广播机制进行按元素操作。
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
# Output:
(tensor([[0],[1],[2]]),tensor([[0, 1]]))a + b # 把a按列复制2份,b按行复制3份,都变成3*2的张量进行操作
# Output:
tensor([[0, 1],[1, 2],[2, 3]])
索引
X[-1], X[1:3] # 这里和前面介绍的概念一样。-1 是倒数第一个元素(一个n-1维度张量),1:3 是第2,第3个元素不包括第4个元素。
# Output:
(tensor([ 8., 9., 10., 11.]),tensor([[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]]))
X[1,2]=9 # 写入
X[0:2, :] = 12 # 批量写入,给0-1行,所有列写成12
X
# Output:
tensor([[12., 12., 12., 12.],[12., 12., 12., 12.],[ 8., 9., 10., 11.]])
节省内存
有一些操作会分配新内存。比如 Y=Y+X,并不是直接在 Y 的原地址上加了X,而是在新地址上计算得到 Y+X,让 Y 指向新地址。
可以通过 id(X) 函数来查看地址。
Y[:]=Y+X 或者 Y+=X 会在原地执行计算,Y 地址不变。
类型转换
转换为 numpy 张量:A=X.numpy()
张量转换为标量:
a=torch.tensor([3.5])
a.item() # 3.5
float(a) # 3.5
int(a) # 3
数据预处理
实际处理数据的时候我们并不是从张量数据类型开始的,我们可能得到一个 excel 文件,自己把它转换成 python 张量。以及在转换之前,我们可能对数据进行预处理,比如把其中的空值统一赋值为0之类的操作。以下是转换步骤。
首先我们创建一个 csv 文件作为原始数据集。
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')
三个属性分别是 room 数量,走廊状态(比如铺了地板),价格。
然后我们把这个数据读入 python,加载原始数据集。
# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
import pandas as pddata = pd.read_csv(data_file)
这个数据集里还是有很多 NaN 项的,我们要对其进行修改替换。数值类典型处理方式是插值和删除。
首先最后一列数据是完整不需要修改的,那么我们只要处理前两列,我们把前两列数据单独拿出来做完处理最后进行张量拼接。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
然后我们把 NumEooms 中的 NaN 值用均值替代,
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
# Output:NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
对于 Alley 列,只有两种状态:NaN 和 Pave。我们用 pandas 的方法,把 NaN 也视作一个类,自动拆成两列设置值。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
# Output:NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
最后,我们将前两列处理后得到的结果与最后一列转换为张量后进行拼接。
import torchX = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
y=y.reshape(4,1)
torch.cat((X,y),dim=1)
# Output:
tensor([[3.0000e+00, 1.0000e+00, 0.0000e+00, 1.2750e+05],[2.0000e+00, 0.0000e+00, 1.0000e+00, 1.0600e+05],[4.0000e+00, 0.0000e+00, 1.0000e+00, 1.7810e+05],[3.0000e+00, 0.0000e+00, 1.0000e+00, 1.4000e+05]], dtype=torch.float64)
相关文章:
深度学习_2 数据操作之数据预处理
数据操作 机器学习包括的核心组件有: 可以用来学习的数据(data);如何转换数据的模型(model);一个目标函数(objective function),用来量化模型的有效性&…...

在美团和阿里6年,很难却也真实...
先简单的说下,本人6年工作经验,曾就职于某大型国企,公司研究院成员,也就职过美团担任高级测试开发工程师,有丰富的高并发大型项目经验。 后端高并发、高性能、高可用性开发,自动化测试框架开发以及软件自动…...
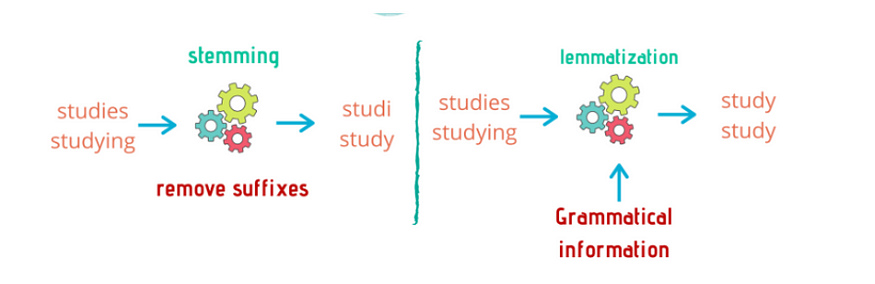
2、NLP文本预处理技术:词干提取和词形还原
一、说明 在上一篇文章中,我们解释了文本预处理的重要性,并解释了一些文本预处理技术。在本文中,我们将介绍词干提取和词形还原主题。 词干提取和词形还原是两种文本预处理技术,用于将单词还原为其基本形式或词根形式。这些技术的…...

Fabric官方示例测试网络搭建
目录 一、参考文档二、环境依赖三、Fabric源码安装3.1、创建链目录3.2、下载源码3.3、修改安装脚本3.4、开始安装3.4.1、执行安装脚本3.4.2、手动下载ca和二进制配置包 四、启动测试网络五、使用测试网络5.1、创建应用通道5.2、部署链码5.3、发送交易 六、关闭测试网络 一、参考…...

ubuntu20.04 conda pack 打包虚拟环境,直接将其用到其他终端
在本机ubuntu20.04下配置的虚拟环境,想到将其整个放到新建的docker(ubuntu20.04)下使用,操作步骤如下: # 一、在ubuntu1下打包虚拟环境 # 安装conda-pack pip install conda-pack# 进入需要打包的虚拟环境,这里将目标虚拟环境名称为goal_env…...

云原生-AWS EC2使用、安全性及国内厂商对比
目录 什么是EC2启动一个EC2实例连接一个实例控制台ssh Security groups规则默认安全组与自定义安全组 安全性操作系统安全密钥泄漏部署应用安全元数据造成SSRF漏洞出现时敏感信息泄漏网络设置错误 厂商对比参考 本文通过实操,介绍了EC2的基本使用,并在功…...
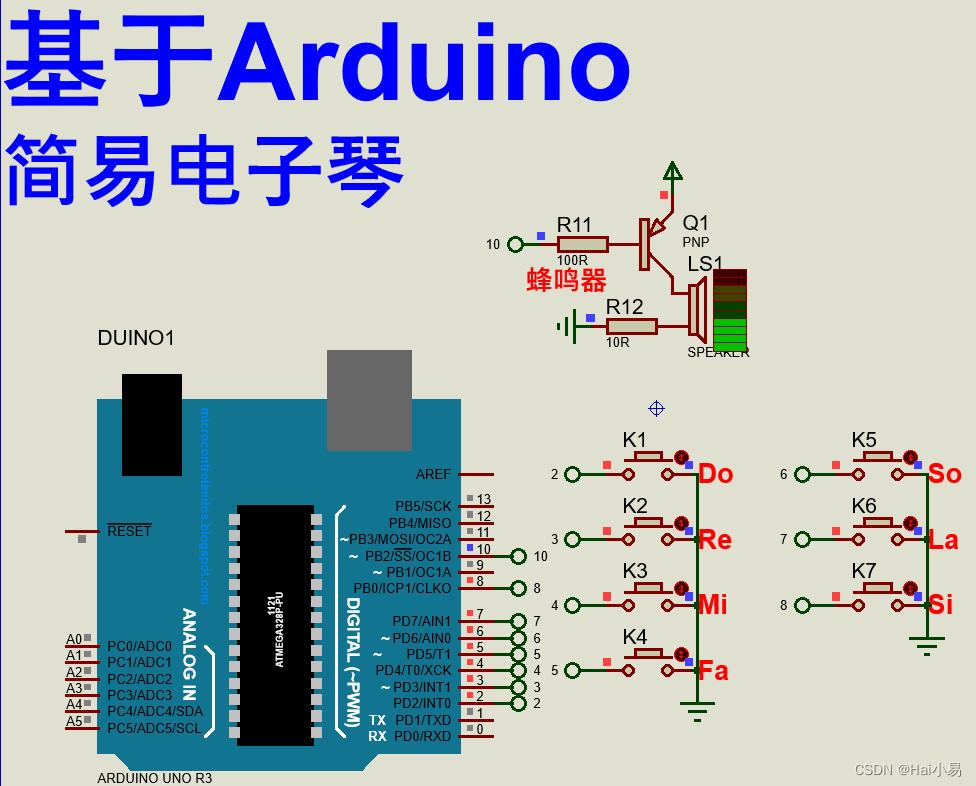
【Proteus仿真】【Arduino单片机】简易电子琴
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真Arduino单片机控制器,使用无源蜂鸣器、按键等。 主要功能: 系统运行后,按下K1-K7键发出不同音调。 二、软件设计 /* 作者:嗨小易&a…...

QT5.15.2 for Android 真机调试
一、准备就绪 1、一台安卓手机 1)手机需要进入开发者选项 2)准备一根USB线,需要用usb线连接电脑 2、QT5需要 Android搭建好环境(教程可以访问我另一篇文章) 二、调试 1、用usb线连接好电脑并进入开发者选项&…...

Mysql my.cnf配置文件参数详解
Linux 操作系统中 MySQL 的配置文件是 my.cnf,一般会放在 /etc/my.cnf 或 /etc/mysql/my.cnf 目录下。 如果你使用 rpm 包安装 MySQL 找不到 my.cnf 文件,可参考如下: 第一步: 通过cd命令 cd /usr/share/mysql 来到这个目录&#…...

linux下构建rocketmq-dashboard多架构镜像——筑梦之路
接上篇:linux上构建任意版本的rocketmq多架构x86 arm镜像——筑梦之路-CSDN博客 这里来记录下构建rocketmq-dashboard多架构镜像的方法步骤。 当前rocketmq-dashboard只有一个版本,源码地址如下: https://dist.apache.org/repos/dist/rele…...
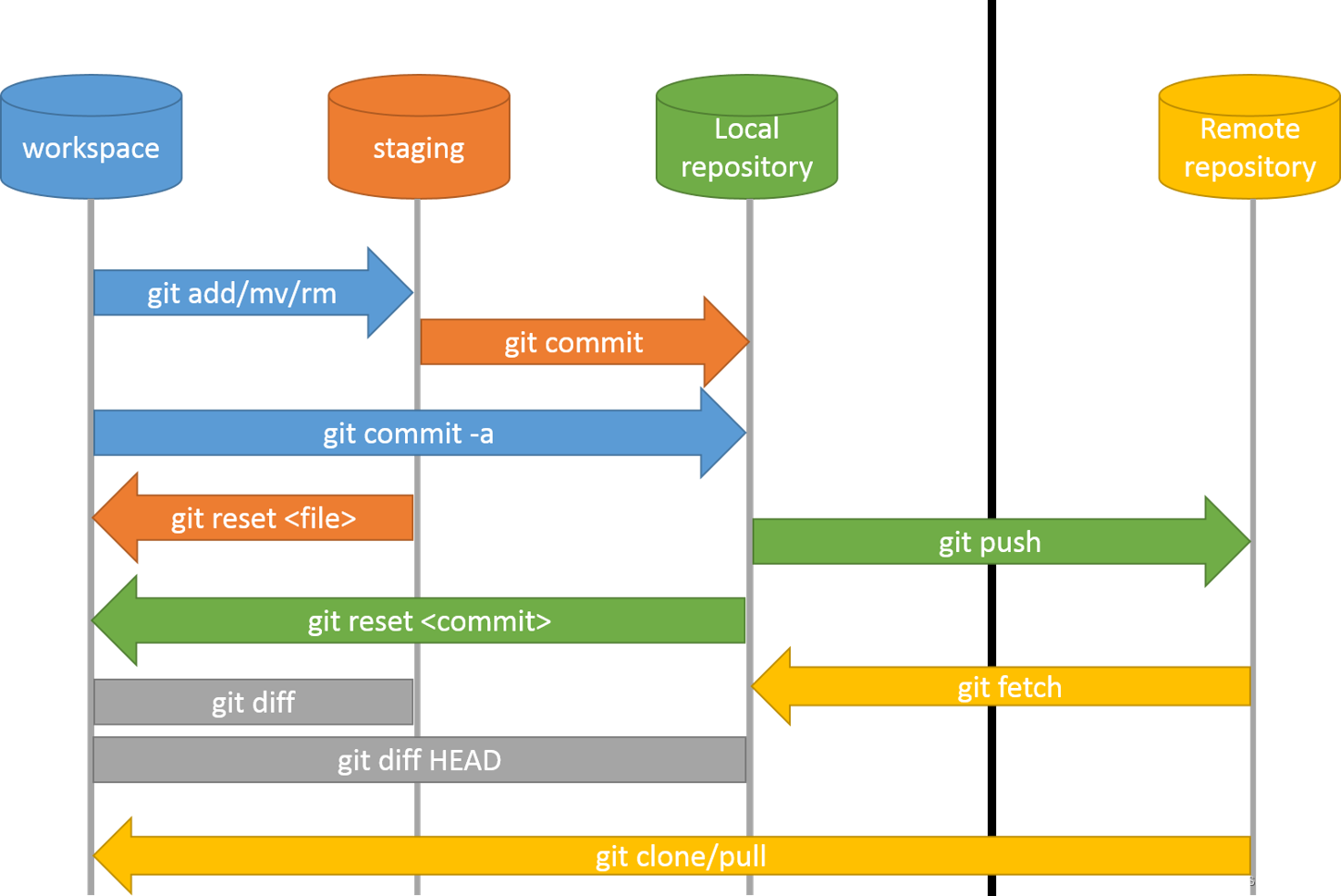
git,ssh,sourcetree代码管理
安装Git并建立与GitHub的ssh连接 1、安装git,设置git的用户信息(需要通过用户信息来显示你是谁) 2、配置SSH, 因为本地Git仓库和GitHub仓库之间的传输是通过SSH加密传输的,GitHub需要识别是否是你推送,Git…...
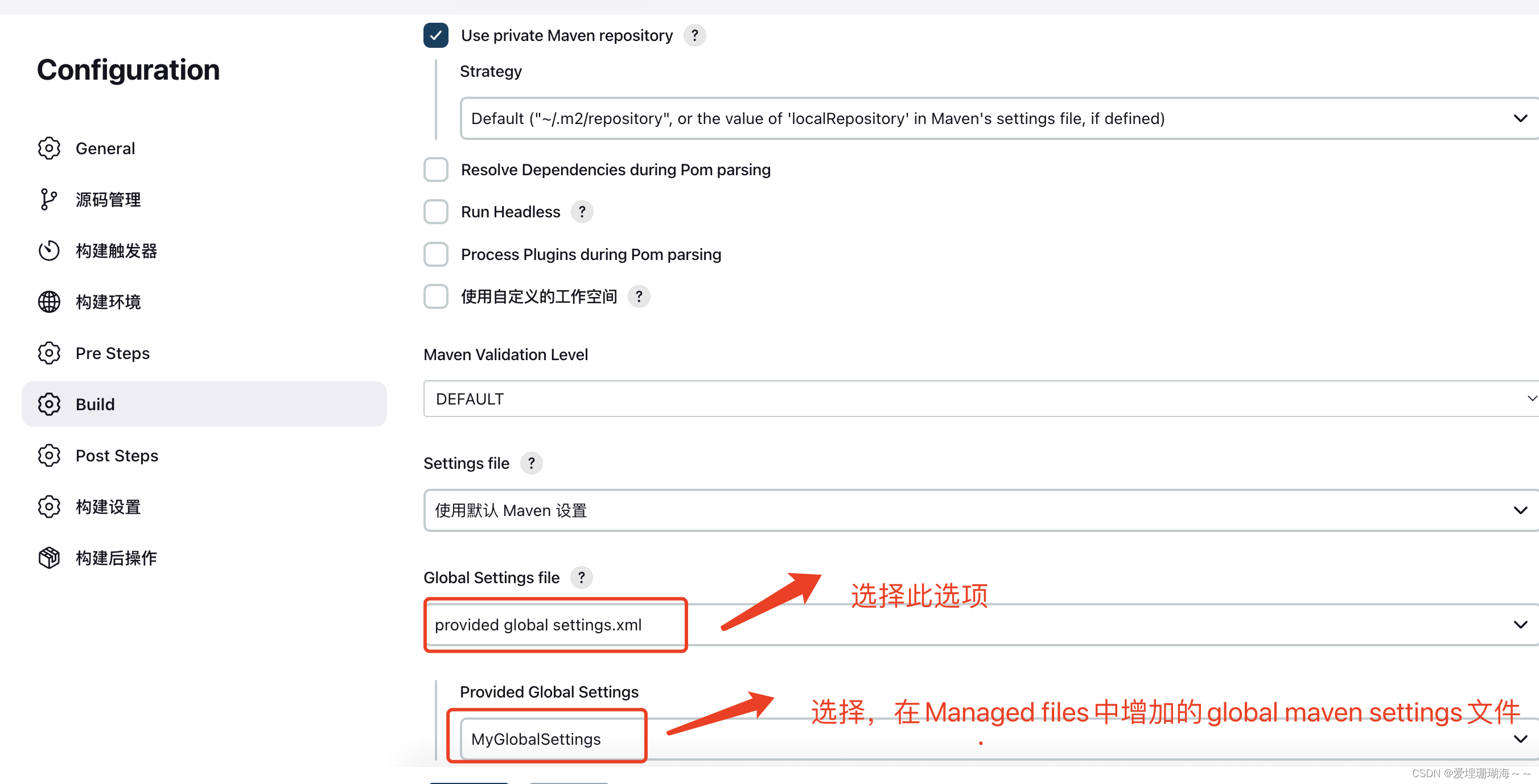
Jenkins中解决下载maven包巨慢的问题
背景介绍 我们在使用jenkins构建maven项目时由于依赖很多第三方jar包,默认会从maven中央仓库下载,由于maven中央仓库服务器是国外的,所以下载很慢,甚至会超时 解决办法 增加jenkins maven 源配置 如下图所示,增加m…...
Redis(11)| 持久化AOF和RDB
一、AOF(Append Only File) Redis 每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里,然后重启 Redis 的时候,先去读取这个文件里的命令,并且执行它。 注意:只会记录写操作命令&am…...
ZYNQ实验---IQ调制实现SSB PART2
一、前言 本文实验在ZYNQ实验—IQ调制实现SSB PART1的基础上进行优化完善。 下图为IQ调制实现SSB PART1中设想实现设计框图 该图设计存在的几个问题: PC-PS的UDP传输存在丢包中断控制发包实际不适合流数据的传输采用的BRAM模块可以存储的空间较小,PC…...
机器学习-特征工程
一、特征工程介绍 1.1 什么是特征 数值特征(连续特征)、文本特征(离散特征) 1.2 特征的种类 1.3 特征工程 特征是机器学习可疑直接使用的,模型和特征之间是一个循环过程; 实际上特征工程就是将原始数据…...

大数据技术之集群数据迁移
文章目录 数据治理之集群迁移数据 数据治理之集群迁移数据 准备两套集群,我这使用apache集群和CDH集群。 启动集群 启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群 在apache集群里hosts加上CDH Namenode对应域名并…...

CF1265E Beautiful Mirrors
CF1265E Beautiful Mirrors 洛谷CF1265E Beautiful Mirrors 题目大意 Creatnx \text{Creatnx} Creatnx有 n n n面魔镜,每天她会问一面镜子:“我漂亮吗?”,第 i i i面魔镜有 p i 100 \dfrac{p_i}{100} 100pi的概率告诉 Creat…...
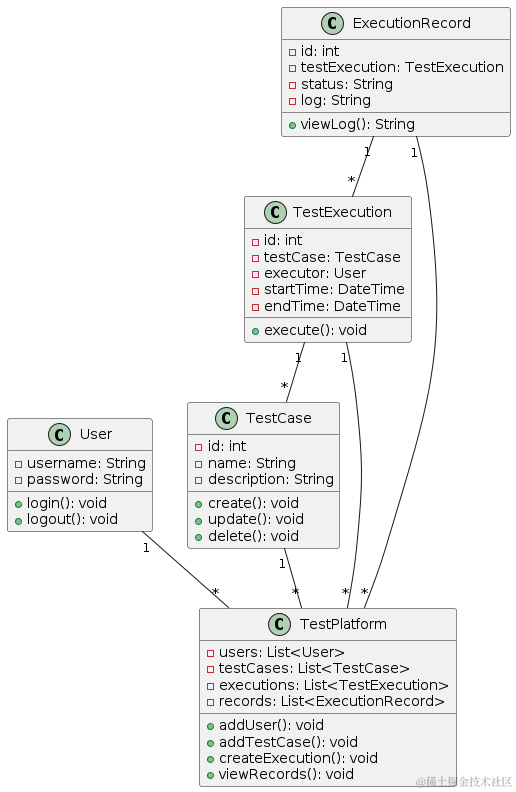
软件测试/测试开发丨利用ChatGPT自动生成架构图
点此获取更多相关资料 简介 架构图通过图形化的表达方式,用于呈现系统、软件的结构、组件、关系和交互方式。一个明确的架构图可以更好地辅助业务分析、技术架构分析的工作。架构图的设计是一个有难度的任务,设计者必须要对业务、相关技术栈都非常清晰…...
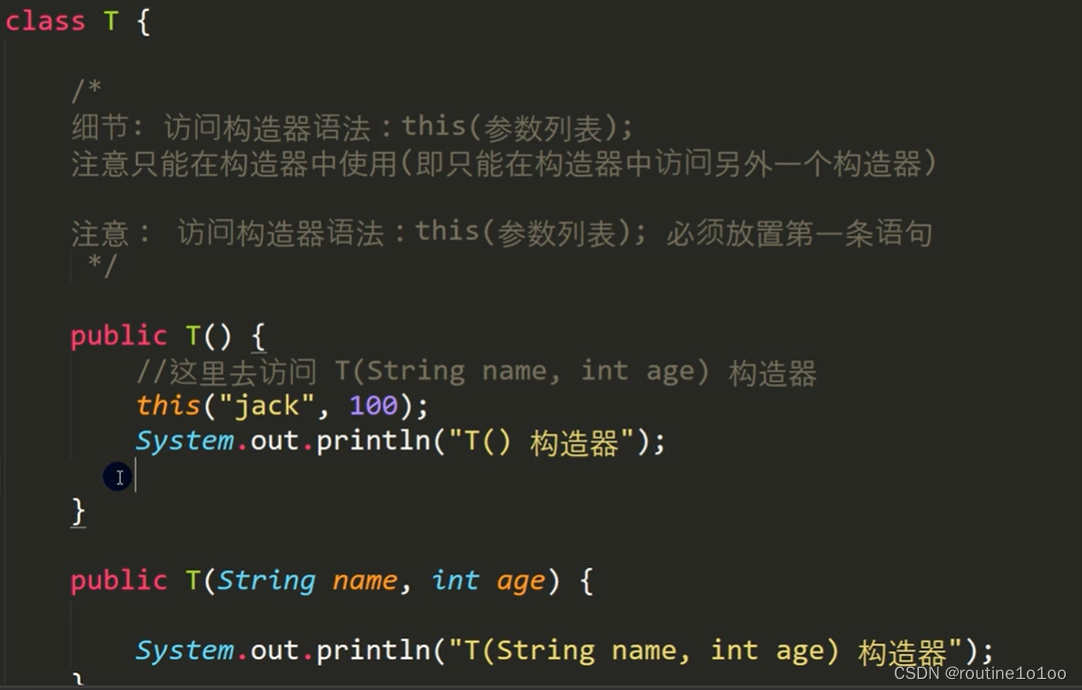
Java学习笔记(六)——面向对象编程(基础)
一、类与对象 (一)类与对象的概念 (二)对象内存布局 编辑 对象分配机制 编辑 (三)属性/成员变量 (四)创建对象与访问属性 二、成员方法 (一)方法…...
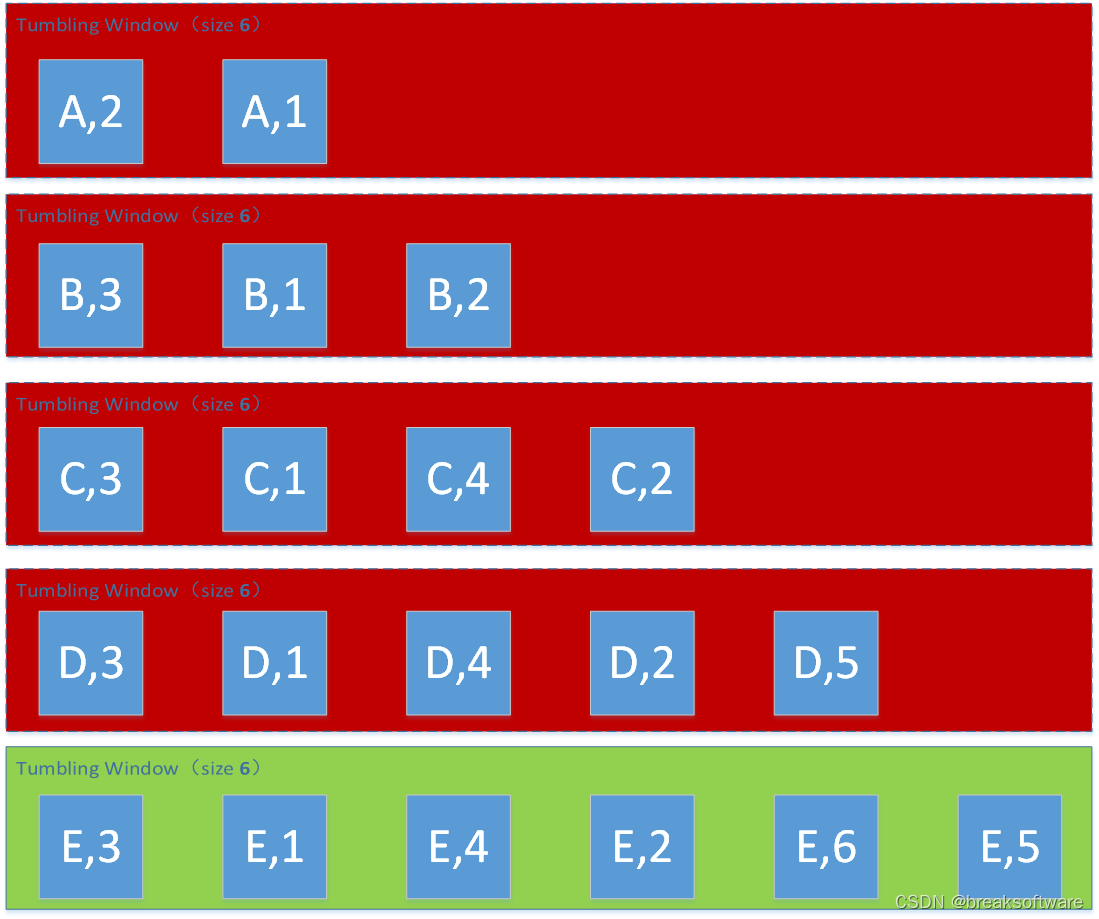
0基础学习PyFlink——个数滚动窗口(Tumbling Count Windows)
大纲 Tumbling Count WindowsmapreduceWindow Size为2Window Size为3Window Size为4Window Size为5Window Size为6 完整代码参考资料 之前的案例中,我们的Source都是确定内容的数据。而Flink是可以处理流式(Streaming)数据的,就是…...

【 Godot 4 学习笔记】命名规范
命名规范类型命名规范示例文件与文件夹snake_case (蛇形)player_controller.gd, assets/类名 / 脚本名PascalCase (大驼峰)PlayerController, YAMLParser场景节点名PascalCase (大驼峰)HitBox, Camera3D, Player函数 / 方法snake_case (蛇形)func load_level():变量 / 信号snak…...

ReAct 循环的 50 行 Go 实现,逐行拆解
ReAct 循环的 50 行 Go 实现,逐行拆解 系列「企业级 AI Agent 实现拆解」第三篇。上一篇讲了 Session 聚合根和状态机——状态怎么迁移、事件怎么发、终态怎么判。但状态机本身是静态的,谁在驱动这些迁移? 答案是 RunTurnHandler.Handle()——…...

工业IoT实战:边缘计算+AI在电机预测性维护中的系统架构设计
前言工业物联网(IIoT)场景下,预测性维护(Predictive Maintenance)是AI技术落地价值最明确的方向之一。本文以杭州沃伦森(WARENSEN)电气的AIESA电机智能安康系统为案例,分析其在边缘计…...

天勤 get_account 资金字段读懂:下单前可用与保证金检查
前言 策略信号对了却下不出去,我第一反应看 get_account():是 available 不够,还是把 balance 当可用去和保证金比了。有次模拟盘「明明没下单」却报资金不足,查了半天是字段读错;还有一次夜盘加仓,白天算好…...
)
Maven依赖管理进阶:如何用dependencyManagement和import scope优雅管理Spring Cloud版本(附父子模块配置实例)
Maven依赖管理进阶:如何用dependencyManagement和import scope优雅管理Spring Cloud版本 在微服务架构盛行的今天,一个项目动辄包含数十个模块已成为常态。我曾接手过一个Spring Cloud Alibaba项目,由于历史原因,各子模块中Spring…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan安装超全攻略
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan安装超全攻略。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

Linux下BepInEx Mod部署原理与实战指南
1. 为什么Linux玩家总在Mod部署上卡住?——BepInEx不是“装上就能用”的玩具 BepInEx、Unity、Linux、Mod框架——这四个词凑在一起,对很多刚从Windows转战Linux的玩家或Mod开发者来说,几乎等于一道默认关闭的门。我第一次在Ubuntu 22.04上尝…...
)
手把手用Python实现μ律/A律压缩算法(附完整代码与波形对比)
手把手用Python实现μ律/A律压缩算法(附完整代码与波形对比) 在数字音频处理领域,动态范围压缩是一个永恒的话题。想象一下,当你录制一段包含轻柔耳语和强烈鼓声的音频时,直接使用线性PCM编码会导致要么小声部分被量化…...
LibreSprite:为什么这款开源像素动画软件能成为独立开发者的首选?
LibreSprite:为什么这款开源像素动画软件能成为独立开发者的首选? 【免费下载链接】LibreSprite Animated sprite editor & pixel art tool -- Fork of the last GPLv2 commit of Aseprite 项目地址: https://gitcode.com/gh_mirrors/li/LibreSpri…...

SillyTavern终极指南:3步搭建你的AI聊天室,轻松管理所有AI模型
SillyTavern终极指南:3步搭建你的AI聊天室,轻松管理所有AI模型 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾想过拥有一个统一的界面来管理所有AI聊天模型…...