大数据技术之集群数据迁移
文章目录
- 数据治理之集群迁移数据
数据治理之集群迁移数据
准备两套集群,我这使用apache集群和CDH集群。
启动集群
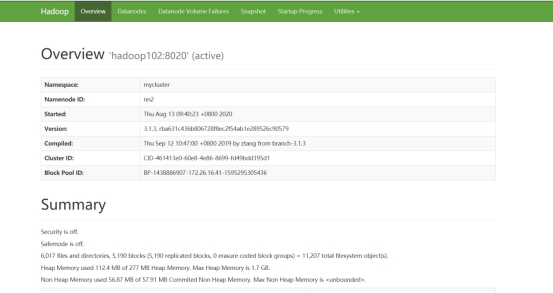
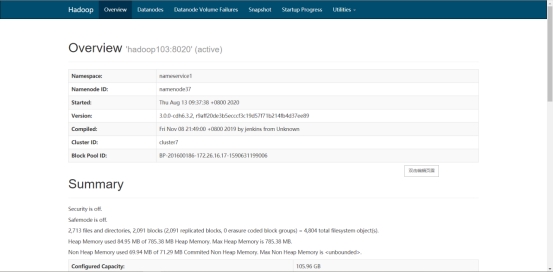
启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群
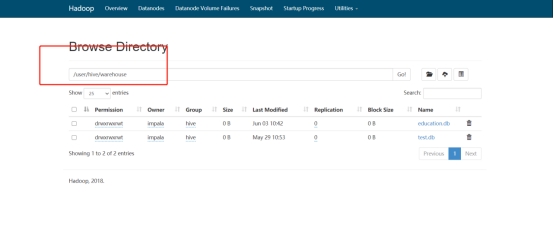
在apache集群里hosts加上CDH Namenode对应域名并分发给各机器
[root@hadoop101 ~]# vim /etc/hosts

[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
因为集群都是HA模式,所以需要在apache集群上配置CDH集群,让distcp能识别出CDH的nameservice
[root@hadoop101 hadoop]# vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
dfs.nameservices
mycluster,nameservice1
dfs.internal.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2,nn3
dfs.namenode.rpc-address.mycluster.nn1
hadoop101:8020
dfs.namenode.rpc-address.mycluster.nn2
hadoop102:8020
dfs.namenode.rpc-address.mycluster.nn3
hadoop103:8020
dfs.ha.namenodes.nameservice1
namenode30,namenode37
dfs.namenode.rpc-address.nameservice1.namenode30
hadoop104:8020
dfs.namenode.rpc-address.nameservice1.namenode37
hadoop106:8020
dfs.namenode.http-address.nameservice1.namenode30
hadoop104:9870
dfs.namenode.http-address.nameservice1.namenode37
hadoop106:9870
dfs.client.failover.proxy.provider.nameservice1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.namenode.http-address.mycluster.nn1
hadoop101:9870
dfs.namenode.http-address.mycluster.nn2
hadoop102:9870
dfs.namenode.http-address.mycluster.nn3
hadoop103:9870
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
修改CDH hosts
[root@hadoop101 ~]# vim /etc/hosts

进行分发,这里的hadoop104,hadoop105,hadoop106,分别对应apache的hadoop101,hadoop102,hadoop103
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
同样修改CDH集群配置,在所有hdfs-site.xml文件里修改配置

dfs.nameservices
mycluster,nameservice1
dfs.internal.nameservices
nameservice1
dfs.ha.namenodes.mycluster
nn1,nn2,nn3
dfs.namenode.rpc-address.mycluster.nn1
hadoop104:8020
dfs.namenode.rpc-address.mycluster.nn2
hadoop105:8020
dfs.namenode.rpc-address.mycluster.nn3
hadoop106:8020
dfs.namenode.http-address.mycluster.nn1
hadoop104:9870
dfs.namenode.http-address.mycluster.nn2
hadoop105:9870
dfs.namenode.http-address.mycluster.nn3
hadoop106:9870
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
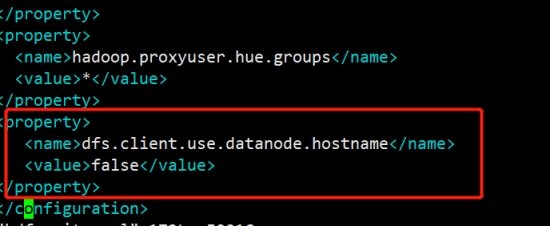
最后注意:重点由于我的Apahce集群和CDH集群3台集群都是hadoop101,hadoop102,hadoop103,所以要关闭域名访问,使用ip访问
CDH把钩去了

apache设置为false
再使用hadoop distcp命令进行迁移,-Dmapred.job.queue.name指定队列,默认是default队列。上面配置集群都配了的话,那么在CDH和apache集群下都可以执行这个命令
[root@hadoop101 hadoop]# hadoop distcp -Dmapred.job.queue.name=hive webhdfs://mycluster:9070/user/hive/warehouse/dwd.db/ hdfs://nameservice1/user/hive/warehouse

会启动一个mr任务,正在迁移

查看cdh 9870 http地址


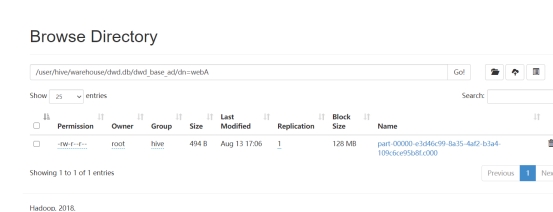
数据已经成功迁移。数据迁移成功之后,接下来迁移hive表结构,编写shell脚本
[root@hadoop101 module]# vim exportHive.sh
#!/bin/bash
hive -e “use dwd;show tables”>tables.txt
cat tables.txt |while read eachline
do
hive -e “use dwd;show create table $eachline”>>tablesDDL.txt
echo “;” >> tablesDDL.txt
done
执行脚本后将tablesDDL.txt文件分发到CDH集群下
[root@hadoop101 module]# scp tablesDDL.txt hadoop104:/opt/module/
然后CDH下导入此表结构,先进到CDH的hive里创建dwd库
[root@hadoop101 module]# hive
hive> create database dwd;
创建数据库后,边界tablesDDL.txt,在最上方加上use dwd;
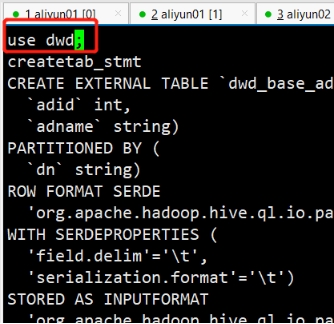
并且将createtab_stmt都替换成空格
[root@hadoop101 module]# sed -i s"#createtab_stmt# #g" tablesDDL.txt
最后执行hive -f命令将表结构导入
[root@hadoop101 module]# hive -f tablesDDL.txt
最后将表的分区重新刷新下,只有刷新分区才能把数据读出来,编写脚本
[root@hadoop101 module]# vim msckPartition.sh
#!/bin/bash
hive -e “use dwd;show tables”>tables.txt
cat tables.txt |while read eachline
do
hive -e “use dwd;MSCK REPAIR TABLE $eachline”
done
[root@hadoop101 module]# chmod +777 msckPartition.sh
[root@hadoop101 module]# ./msckPartition.sh
刷完分区后,查询表数据

相关文章:
大数据技术之集群数据迁移
文章目录 数据治理之集群迁移数据 数据治理之集群迁移数据 准备两套集群,我这使用apache集群和CDH集群。 启动集群 启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群 在apache集群里hosts加上CDH Namenode对应域名并…...

CF1265E Beautiful Mirrors
CF1265E Beautiful Mirrors 洛谷CF1265E Beautiful Mirrors 题目大意 Creatnx \text{Creatnx} Creatnx有 n n n面魔镜,每天她会问一面镜子:“我漂亮吗?”,第 i i i面魔镜有 p i 100 \dfrac{p_i}{100} 100pi的概率告诉 Creat…...
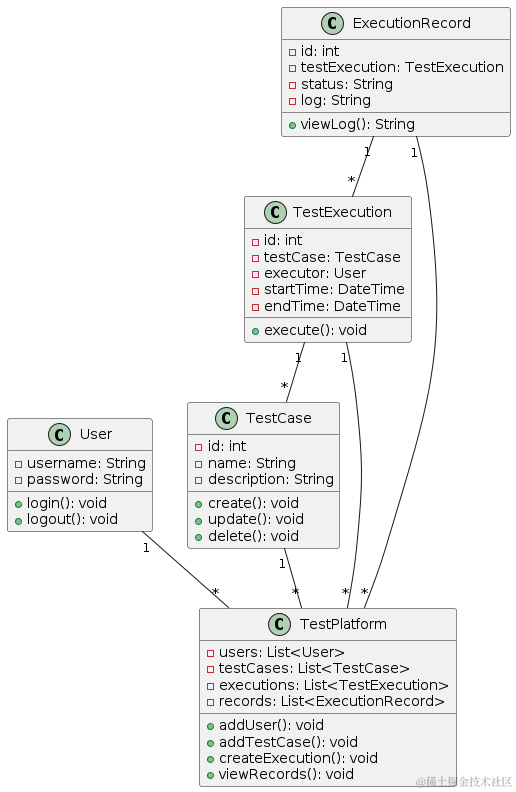
软件测试/测试开发丨利用ChatGPT自动生成架构图
点此获取更多相关资料 简介 架构图通过图形化的表达方式,用于呈现系统、软件的结构、组件、关系和交互方式。一个明确的架构图可以更好地辅助业务分析、技术架构分析的工作。架构图的设计是一个有难度的任务,设计者必须要对业务、相关技术栈都非常清晰…...
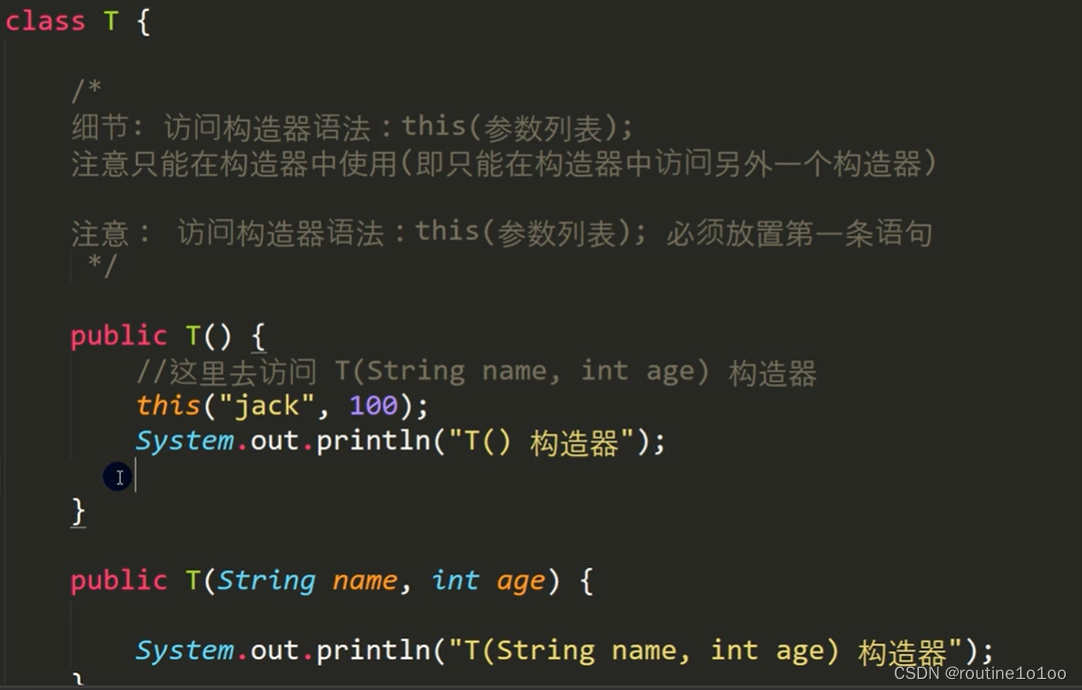
Java学习笔记(六)——面向对象编程(基础)
一、类与对象 (一)类与对象的概念 (二)对象内存布局 编辑 对象分配机制 编辑 (三)属性/成员变量 (四)创建对象与访问属性 二、成员方法 (一)方法…...
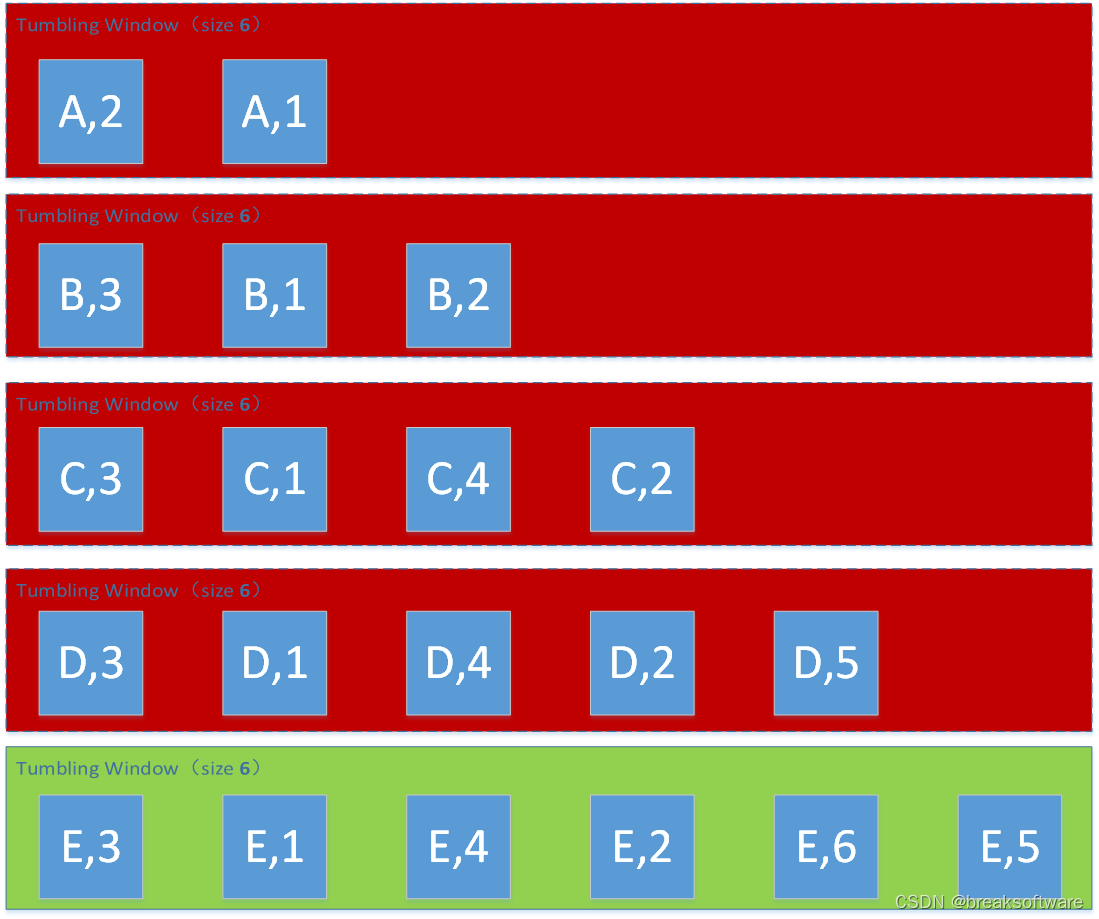
0基础学习PyFlink——个数滚动窗口(Tumbling Count Windows)
大纲 Tumbling Count WindowsmapreduceWindow Size为2Window Size为3Window Size为4Window Size为5Window Size为6 完整代码参考资料 之前的案例中,我们的Source都是确定内容的数据。而Flink是可以处理流式(Streaming)数据的,就是…...

车载终端构筑智慧工厂:无人配送车的高效物流体系
随着科技的不断进步和应用,智能化已经成为许多领域的关键词。在物流行业中,随着无人配送车的兴起和智慧工厂的崛起,车载终端正引领着无人配送车的科技变革之路。 文章同款:https://www.key-iot.com/iotlist/sv900.html 车载终端…...

插件_日期_lunar-calendar公历农历转换
现在存在某需求,需要将公历、农历日期进行相互转换,在此借助lunar-calendar插件完成。 下载 [1] 通过npm安装 npm install lunar-calendar[2]通过文件方式引入 <script type"text/javascript" src"lib/LunarCalendar.min.js">…...

【FreeRTOS】【STM32】08 FreeRTOS 消息队列
简单来说 消息队列是一种数据结构 任务操作队列的基本描述 1.如果队列未满或者允许覆盖入队,FreeRTOS会将任务需要发送的消息添加到队列尾。 2.如果队列满,任务会阻塞(等待)。 3.用户可以指定等待时间。 4.当其它任务从其等待的队列中读取入了数据(这时候队列未满…...
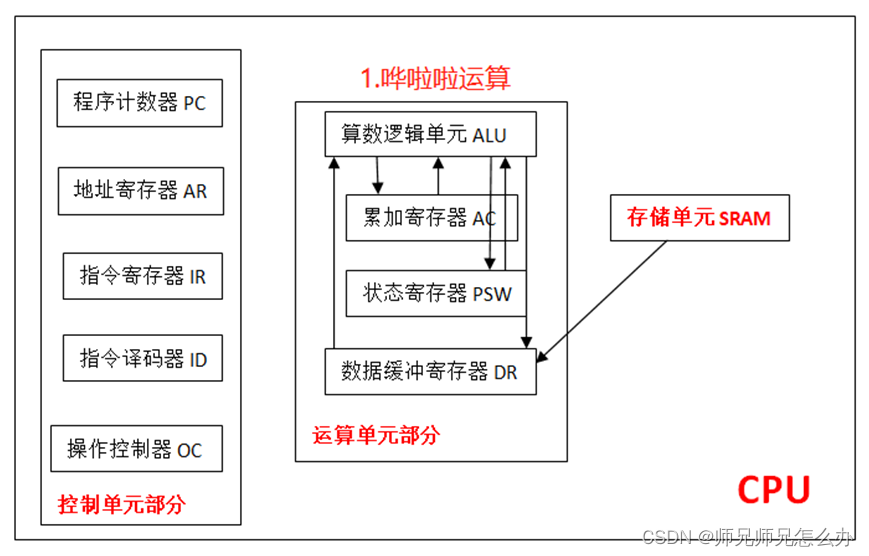
【计算机组成原理】CPU的工作原理
一.CPU的组成结构 CPU主要有运算器、控制器、寄存器和内部总线等组成,其大概的样子长这样: 看不懂没关系,我们将采用自顶而下的方法来讲解CPU的具体工作原理,我们首先来说一下什么叫寄存器,顾名思义,寄存器…...
部署ELK
一、elasticsearch #拉取镜像 docker pull elasticsearch:7.12.1 #创建ELK docker网络 docker network create elk #启动ELK docker run -d --name es --net elk -P -e "discovery.typesingle-node" elasticsearch:7.12.1 #拷贝配置文件 docker cp es:/usr/share/el…...

纯前端实现图片验证码
前言 之前业务系统中验证码一直是由后端返回base64与一个验证码的字符串来实现的,想了下,前端其实可以直接canvas实现,减轻服务器压力。 实现 子组件,允许自定义图片尺寸(默认尺寸为100 * 40)与验证码刷新时间(默认时间为60秒)…...

#django基本常识01#
1、manage.py 所有子命令的入口,比如: python3 manage.py runserver 启动服务 python3 manage.py startapp 创建应用 python3 manage.py migrate 数据库迁移 直接执行python3 manage.py 可显示所有子命令...

什么是物流RPA?物流RPA解决什么问题?物流RPA实施难点在哪里?
RPA指的是机器人流程自动化,它是一套模拟人类在计算机、平板电脑、移动设备等界面执行任务的软件。通过RPA,可以自动完成重复性、繁琐的工作,提高工作效率和质量,降低人力成本。RPA适用于各种行业和场景,例如财务、人力…...

乐鑫工程部署过程记录
一、获取编译环境 1、下载sdk,ESP-IDF 这里有很多发布版本,当前我选择的是4.4.6,可以选择下载压缩包,也可以git直接clone 2、配置编译环境 我选择的是Linux Ubuntu下部署开发环境 查看入门指南 选择对应的芯片,我…...

to 后接ing形式的情况
look forward to seeing you. (期待着见到你) She admitted to making a mistake. (承认犯了个错误) He is accustomed to working long hours. (习惯于长时间工作)...

我做云原生的那几年
背景介绍 在2020年6月,我加入了一家拥有超过500人的企业。彼时,前端团队人数众多,有二三十名成员。在这样的大团队中,每个人都要寻找自己的独特之处和核心竞争力。否则,你可能会沉没于常规的增删改查工作中࿰…...

@EventListener注解使用说明
在Java的Spring框架中,EventListener注解用于监听和处理应用程序中的各种事件。通过使用EventListener注解,开发人员可以方便地实现事件驱动的编程模型,提高代码的灵活性和可维护性。本文将详细探讨EventListener注解的使用方法和作用&#x…...
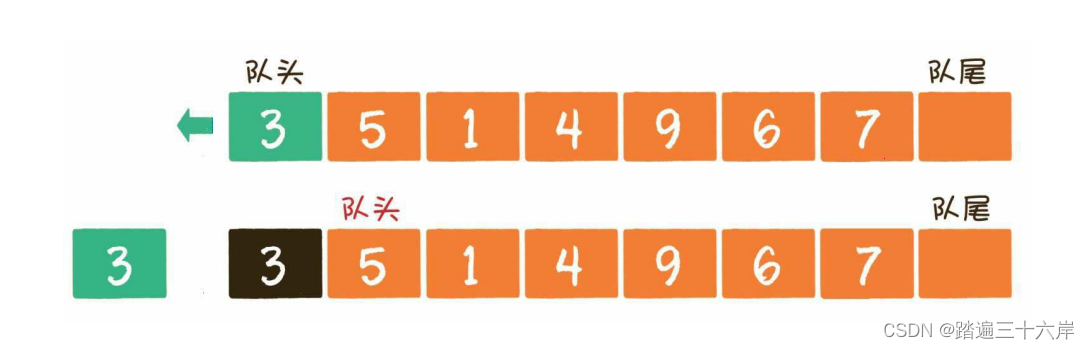
算法通关村第五关-白银挑战实现队列
大纲 队列基础队列的基本概念和基本特征实现队列队列的基本操作Java中的队列 队列基础 队列的基本概念和基本特征 队列的特点是节点的排队次序和出队次序按入队时间先后确定,即先入队者先出队,后入队者后出队,即我们常说的FIFO(first in fi…...

协力共创智能未来:乐鑫 ESP RainMaker 云方案线下研讨会圆满落幕
近日,乐鑫 ESP RainMaker 云方案线下研讨会(深圳)在亚马逊云科技与合作伙伴嘉宾的支持下成功举办,吸引了众多来自智能家电、照明电工、能源和宠物等行业的品牌客户、方案商和制造商。研讨会围绕如何基于乐鑫 ESP RainMaker 硬件连…...

读取谷歌地球的kml文件中的经纬度坐标
最近我在B站上传了如何获取研究边界的视频,下面分享一个可以读取kml中经纬度的matlab函数,如此一来就可以获取任意区域的经纬度坐标了。 1.谷歌地球中划分区域 2.matlab读取kml文件 function [sname,lon,lat] kml2xy(ip_kml) % ip_kml ocean_distubu…...

SQLines数据库迁移工具:从零开始的完整使用指南
SQLines数据库迁移工具:从零开始的完整使用指南 【免费下载链接】sqlines SQLines Open Source Database Migration Tools 项目地址: https://gitcode.com/gh_mirrors/sq/sqlines SQLines是一款功能强大的开源数据库迁移工具,专门用于在不同数据库…...

探索OneMore:解锁OneNote高效笔记的完整指南
探索OneMore:解锁OneNote高效笔记的完整指南 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore OneMore是一款专为OneNote设计的强大插件,通过160…...

保姆级教程:5分钟快速搭建你的DNC服务器,实现Fanuc/西门子数控程序远程传输与管理
数控机床程序远程管理实战:5分钟构建企业级DNC服务 在金属加工车间里,老师傅们弯腰在机床控制面板上手动输入程序的场景正逐渐成为历史。当车间里同时运行着发那科、西门子和三菱等不同品牌的数控设备时,如何高效管理这些设备的加工程序&…...

Richard Socher创业公司获6.5亿美元融资,欲让AI自动化研发引领底层范式转移
Richard Socher创业公司获巨额融资一家创业公司获得了GV(Alphabet旗下VC)和Greycroft共同领投的6.5亿美元早期融资,NVIDIA和AMD也参与本轮融资,它的估值达到了46.5亿美元。这家公司的创始人是Richard Socher,他是AI领域…...

QMCDecode:3步解锁你的QQ音乐收藏,告别格式限制的烦恼
QMCDecode:3步解锁你的QQ音乐收藏,告别格式限制的烦恼 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&#…...

Windows到Linux数据传输实战:WinSCP、SCP、Samba与rsync全解析
1. 项目概述:跨越操作系统的数据搬运在混合开发或运维环境中,从Windows向Linux服务器传输数据,是每个开发者、运维工程师甚至数据分析师都绕不开的日常操作。这看似简单的“复制粘贴”,背后却涉及网络协议、权限管理、文件系统差异…...

如何构建活跃的AI技能社区:Awesome Agent Skills线上线下活动完整指南
如何构建活跃的AI技能社区:Awesome Agent Skills线上线下活动完整指南 【免费下载链接】awesome-agent-skills A curated collection of 1000 agent skills from official dev teams and the community, compatible with Claude Code, Codex, Gemini CLI, Cursor, a…...

兄弟反目成仇?《易经》深挖人性:猜疑才是最大祸根
你有没有过这样的经历?关系最好的朋友或同事,因为一个误会,突然就成了“最熟悉的陌生人”。你解释,他觉得你掩饰;你沉默,他觉得你默认。最后,好好的关系,硬生生被“猜疑”这把刀&…...

把AI的能力拆成乐高积木:如何让Agent真正干成复杂的事
【AI Agent能不能干成复杂的事,不取决于模型有多聪明,而取决于能力怎么编排】AI Agent在2025年成为企业数字化领域的最热词汇。几乎所有企业都在讨论"上Agent",但真正落地之后,大家发现一个尴尬的现实:简单的…...

harmonyos-ai-skill:让 Cursor 按 ArkTS 规范写鸿蒙,不再瞎编 API
端侧 Kit、MCP 接线都写过之后,写代码的人仍会遇到:Cursor 生成「像 React 的 ArkTS」、编造不存在的 Kit 名。社区项目 harmonyos-ai-skill 用可安装知识包,把 API 11 / DevEco 6 约束塞进 AI 工具链。 1. 问题:通用大模型不懂你…...