Java使用Spark入门级非常详细的总结
目录
Java使用Spark入门
环境准备
安装JDK
安装Spark
编写Spark应用程序
创建SparkContext
读取文本文件
计算单词出现次数
运行Spark应用程序
总结
Java使用Spark入门
本文将介绍如何使用Java编写Spark应用程序。Spark是一个快速的、通用的集群计算系统,它可以处理大规模数据。Spark提供了一个简单的编程接口,可以使用Java、Scala、Python和R等语言编写应用程序。
环境准备
在开始编写Spark应用程序之前,需要准备以下环境:
Java开发环境(JDK)
Spark安装包
安装JDK
如果您还没有安装Java开发环境,请先下载并安装JDK。您可以从Oracle官网下载JDK安装包:https://www.oracle.com/java/technologies/javase-downloads.html
安装Spark
您可以从Spark官网下载Spark安装包:https://spark.apache.org/downloads.html
下载完成后,解压缩安装包到您的本地文件系统中。
编写Spark应用程序
在本节中,我们将编写一个简单的Spark应用程序,该程序将读取一个文本文件并计算单词出现的次数。
创建SparkContext
首先,我们需要创建一个SparkContext对象。SparkContext是Spark应用程序的入口点,它负责与集群通信并管理应用程序的资源。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
public class WordCount {
public static void main(String[] args) {
// 创建SparkConf对象
SparkConf conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local");
// 创建JavaSparkContext对象
JavaSparkContext sc = new JavaSparkContext(conf);
// TODO: 编写应用程序代码
// 关闭JavaSparkContext对象
sc.close();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在上面的代码中,我们创建了一个SparkConf对象,并设置了应用程序的名称和运行模式。然后,我们创建了一个JavaSparkContext对象,并传递SparkConf对象作为参数。
读取文本文件
接下来,我们需要读取一个文本文件。Spark提供了多种方式来读取数据,例如从本地文件系统、HDFS、Amazon S3等。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class WordCount {
public static void main(String[] args) {
// 创建SparkConf对象
SparkConf conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local");
// 创建JavaSparkContext对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文本文件
JavaRDD<String> lines = sc.textFile("input.txt");
// TODO: 编写应用程序代码
// 关闭JavaSparkContext对象
sc.close();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在上面的代码中,我们使用JavaSparkContext对象的textFile方法读取了一个名为input.txt的文本文件,并将其存储在一个JavaRDD对象中。
计算单词出现次数
最后,我们需要编写代码来计算单词出现的次数。我们可以使用flatMap和reduceByKey方法来实现这个功能。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
import java.util.Map;
public class WordCount {
public static void main(String[] args) {
// 创建SparkConf对象
SparkConf conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local");
// 创建JavaSparkContext对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取文本文件
JavaRDD<String> lines = sc.textFile("input.txt");
// 计算单词出现次数
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaRDD<String> filteredWords = words.filter(word -> !word.isEmpty());
JavaPairRDD<String, Integer> wordCounts = filteredWords.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((x, y) -> x + y);
Map<String, Integer> wordCountsMap = wordCounts.collectAsMap();
// 输出结果
for (Map.Entry<String, Integer> entry : wordCountsMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 关闭JavaSparkContext对象
sc.close();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
在上面的代码中,我们使用flatMap方法将每行文本拆分成单词,并使用filter方法过滤掉空单词。然后,我们使用mapToPair方法将每个单词映射为一个键值对,其中键为单词,值为1。最后,我们使用reduceByKey方法将具有相同键的键值对合并,并计算每个单词出现的次数。最后,我们使用collectAsMap方法将结果收集到一个Map对象中,并输出结果。
运行Spark应用程序
在完成Spark应用程序的编写后,我们可以使用以下命令来运行它:
$ spark-submit --class WordCount --master local WordCount.jar
1
其中,WordCount是应用程序的类名,WordCount.jar是应用程序的打包文件。
总结
本文介绍了如何使用Java编写Spark应用程序。我们首先创建了一个SparkContext对象,然后使用textFile方法读取了一个文本文件,并使用flatMap和reduceByKey方法计算了单词出现的次数。最后,我们使用spark-submit命令运行了应用程序。
————————————————
版权声明:本文为CSDN博主「AcerMr」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_37480069/article/details/130959383
相关文章:

Java使用Spark入门级非常详细的总结
目录 Java使用Spark入门 环境准备 安装JDK 安装Spark 编写Spark应用程序 创建SparkContext 读取文本文件 计算单词出现次数 运行Spark应用程序 总结 Java使用Spark入门 本文将介绍如何使用Java编写Spark应用程序。Spark是一个快速的、通用的集群计算系统,它可以处理…...
kubernetes集群编排——k8s存储
configmap 字面值创建 kubectl create configmap my-config --from-literalkey1config1 --from-literalkey2config2kubectl get cmkubectl describe cm my-config 通过文件创建 kubectl create configmap my-config-2 --from-file/etc/resolv.confkubectl describe cm my-confi…...

【软件STM32cubeIDE下H73xx配置串口uart1+中断接收/DMA收发+HAL库+简单数据解析-基础样例】
#【软件STM32cubeIDE下H73xx配置串口uart1中断接收/DMA收发HAL库简单数据解析-基础样例】 1、前言2、实验器件3-1、普通收发中断接收实验第一步:代码调试-基本配置(1)基本配置(3)时钟配置(4)保存…...

jdk8和jdk9中接口的新特性
jdk8之前:声明抽象方法,修饰为public abstract。 jdk8:添加声明静态方法,默认方法。 jdk9:添加声明私有方法 jdk8: ①接口中声明的静态方法只能被接口来调用,不能使用其实现类进行调用 静态方法的声明&…...

1-爬虫-requests模块快速使用,携带请求参数,url 编码和解码,携带请求头,发送post请求,携带cookie,响应对象, 高级用法
1 爬虫介绍 2 requests模块快速使用 3 携带请求参数 4 url 编码和解码 4 携带请求头 5 发送post请求 6 携带cookie 7 响应对象 8 高级用法 1 爬虫介绍 # 爬虫是什么?-网页蜘蛛,网络机器人,spider-在互联网中 通过 程序 自动的抓取数据 的过程…...
java商城免费搭建 VR全景商城 saas商城 b2b2c商城 o2o商城 积分商城 秒杀商城 拼团商城 分销商城 短视频商城
1. 涉及平台 平台管理、商家端(PC端、手机端)、买家平台(H5/公众号、小程序、APP端(IOS/Android)、微服务平台(业务服务) 2. 核心架构 Spring Cloud、Spring Boot、Mybatis、Redis 3. 前端框架…...
【TS篇一】TypeScript介绍、使用场景、环境搭建、类和接口
文章目录 一、TypeScript 介绍1. TypeScript 是什么1.2 静态类型和动态类型1.3 Why TypeScript1.4 TypeScript 使用场景1.5 TypeScript 不仅仅用于开发 Angular 应用1.6 前置知识 二、如何学习 TypeScript2.1 相关链接 三、起步3.1 搭建 TypeScript 开发环境3.2 编辑器的选择3.…...

Tuna: Instruction Tuning using Feedback from Large Language Models
本文是LLM系列文章,针对《Tuna: Instruction Tuning using Feedback from Large Language Models》的翻译。 Tuna:使用来自大型语言模型的反馈的指令调优 摘要1 引言2 方法3 实验4 相关工作5 结论局限性 摘要 使用更强大的LLM(如Instruction GPT和GPT-…...

uni-app 应对微信小程序最新隐私协议接口要求的处理方法
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一,问题起因 最新在开发小程序的时候,调用微信小程序来获取用户信息的时候经常报错一个问题 fail api scope is not declared in the privacy agreement,api更具公告…...
PostgreSQL 进阶 - 使用foreign key,使用 subqueries 插入,inner joins,outer joins
1. 使用foreign key 创建 table CREATE TABLE orders( order_id SERIAL PRIMARY KEY, purchase_total NUMERIC, timestamp TIMESTAMPTZ, customer_id INT REFERENCES customers(customer_id) ON DELETE CASCADE);“order_id”:作为主键的自增序列,使用 …...

【Python 千题 —— 基础篇】地板除计算
题目描述 题目描述 编写一个程序,接受用户输入的两个数字,然后计算这两个数字的地板除(整除)结果,并输出结果。 输入描述 输入两个数字,用回车隔开两个数字。 输出描述 程序将计算这两个数字的地板除…...
函数)
【随手记】np.random.choice()函数
np.random.choice() 是 NumPy 中的一个随机抽样函数,用于从给定的一维数组中随机抽取指定数量或指定概率的元素。该函数可以用于构建模拟实验、生成随机数据集、数据抽样等应用场景。 np.random.choice(a, sizeNone, replaceTrue, pNone) 的参数如下: …...
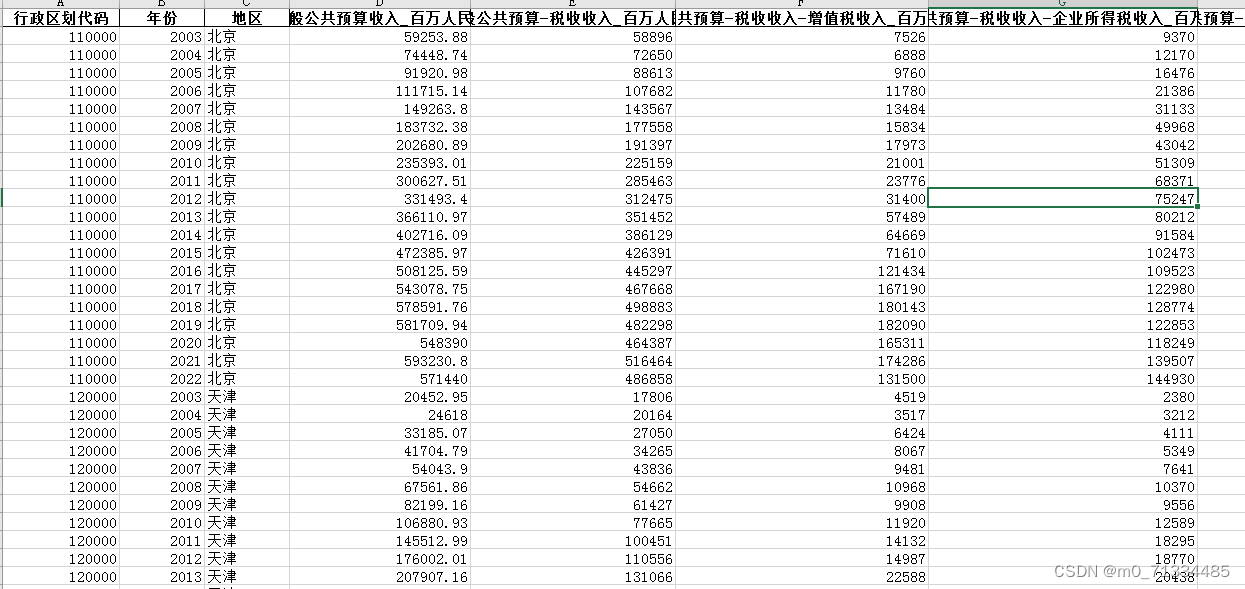
2003-2022年地级市-财政收支明细数据(企业、个人所得税、科学、教育、医疗等)
2003-2022年地级市-财政收支明细数据(企业、个人所得税、科学、教育、医疗等) 1、时间:2003-2022年 2、指标:行政区划代码、年份、地区、一般公共预算收入、一般公共预算-税收收入、一般公共预算-税收收入-增值税收入、一般公共…...

影响服务器正常使用的有哪些因素
对于网站优化来说,网站服务器的优化绝对是基础。不管是用户还是搜索引擎对于网站的打开速度都是没有太多耐心的, 所以网站优化的就是要保证网站服务器稳定,网站正常且快速的打开 1.用户体验较差 现在越来越强调用户体验,设想一下…...

NLP学习笔记:使用 Python 进行NLTK
一、说明 本文和接下来的几篇文章将介绍 Python NLTK 库。NLTK — 自然语言工具包 — NLTK 是一个强大的开源库,用于 NLP 的研究和开发。它内置了 50 多个文本语料库和词汇资源。它支持文本标记化、词性标记、词干提取、词形还原、命名实体提取、分割、分类、语义推…...

突破性技术!开源多模态模型—MiniGPT-5
多模态生成一直是OpenAI、微软、百度等科技巨头的重要研究领域,但如何实现连贯的文本和相关图像是一个棘手的难题。 为了突破技术瓶颈,加州大学圣克鲁斯分校研发了MiniGPT-5模型,并提出了全新技术概念“Generative Vokens ",…...
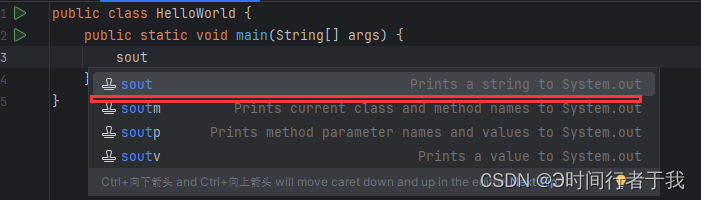
IntelliJ IDEA快捷键sout不生效
1.刚下载完idea编辑器时,可能idea里的快捷键打印不生效。这时你打开settings 2.点击settings–>Live Templates–>找到Java这个选项,点击展开 3.找到sout 4.点击全选,保存退出就可以了 5.最后大功告成!...

用C++QT实现一个modbus rtu通讯程序框架
下面是一个简单的Modbus RTU通讯程序框架的示例,使用C和QT来实现: #include <QCoreApplication> #include <QSerialPort> #include <QModbusDataUnit> #include <QModbusRtuSerialMaster>int main(int argc, char *argv[]) {QC…...

Python如何设置下载第三方软件包的国内镜像站服务器的地址
使用pip下载第三方python软件包时,如果下载的速度太慢,说明是从国外的服务器上下载的。需要进行一个设置,让pip从国内的镜像站服务器下载。 1. 新建一个纯文本文件,Windows下名字叫做pip.ini;Linux下名字叫做pip.cnf…...
ChatGLM3-6B详细安装过程记录(Linux)
先附上GitHub官方地址: https://github.com/THUDM/ChatGLM3https://github.com/THUDM/ChatGLM3 目录 一、预览 1. 基于 Gradio 的网页版 demo...

ComfyUI v0.21.1:最新版本发布,模型、节点、工作流与稳定性全面升级
ComfyUI v0.21.1 已于 2026年5月14日发布。本次版本说明中明确标注为 Immutable release,也就是说,发布后只能修改 release title 和 notes。这意味着这次更新内容具有较强的定版性质,适合直接作为版本升级参考。 如果用一句话概括这次更新&a…...

AArch64虚拟内存系统架构与64KB粒度地址转换详解
1. AArch64虚拟内存系统架构概述现代处理器架构通过虚拟内存机制实现物理内存与虚拟地址空间的隔离映射,AArch64作为ARMv8/ARMv9架构的64位执行状态,其虚拟内存系统架构(VMSA)采用多级页表机制实现地址转换。与传统x86架构相比&am…...
)
从碰撞到安全路径:在MATLAB里为你的机械臂规划一条无碰撞轨迹(附完整代码)
七轴机械臂无碰撞轨迹规划实战:从MATLAB基础到高级避障策略 机械臂在复杂环境中的自主运动一直是工业自动化和服务机器人领域的核心挑战。想象一下,当一台七轴机械臂需要在布满障碍物的空间里精准抓取物品时,如何确保它不会撞上周围的工作台、…...

为什么很多企业,最后真正被拖垮的,其实是“系统维护成本”?——真正昂贵的,从来不是“开发系统”,而是“长期维护复杂系统”
很多企业第一次做商城系统时,通常都会特别关注: 开发成本高不高上线速度快不快功能够不够多页面交付快不快 因为在业务初期。 大家最关注的: 通常都是: 先把系统上线 所以很多企业最开始都会认为: “开发成本” …...

主流 RAG 架构与方法总结
一. 基础知识库RAG:Naive RAG / Standard RAG 1.1 架构流程 最基础,最常见的 RAG 架构。 文档上传 → 文档解析 → 文本切块 Chunking → Embedding 向量化 → 写入向量库 / 搜索索引 → 用户提问 → 向量检索 Top-K → 拼接上下文 → LLM 生成答案 …...

HT4182:5V 输入 1.6A 同步升压双节锂电充电器,高集成全保护可 P2P 替代
在便携式音箱、POS 机、电子烟、对讲机等采用双节串联锂电池供电的设备中,5V USB 输入升压充电是最主流的方案,市场对充电效率、集成度和可靠性的要求越来越高。HT4182 作为一款专为 5V 输入优化的同步升压型双节锂电池充电器,凭借高转换效率…...

地空协同巡检新范式:elec-ops-inspection 3D空间建模技术
地空协同巡检新范式:elec-ops-inspection 3D空间建模技术 【免费下载链接】elec-ops-inspection elec-ops-inspection 是 CANN 社区 Electrical Engineering SIG(电力行业兴趣小组)旗下的电力装备巡检算子库, 覆盖 CV 视觉检测与具…...

Redis 持久化机制:RDB、AOF 与混合持久化
Redis 持久化机制:RDB、AOF 与混合持久化 面试热度:⭐⭐⭐⭐⭐ 前置知识:Redis 基本数据结构、Linux 进程 fork 概念 📑 目录(点击跳转) 1. 为什么 Redis 需要持久化2. RDB 持久化 2.1 基本原理2.2 RDB 的…...

堆叠集成方法
原文:towardsdatascience.com/the-stacking-ensemble-method-984f5134463a 发现堆叠在机器学习中的力量——一种将多个模型组合成一个单一强大预测器的技术。本文从基础知识到高级技术探讨了堆叠,揭示了它是如何结合不同模型的优势以提高准确性的。无论你…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》005、DEIM模型架构总览——编码器-解码器与动态门控设计
CVPR2025-DEIM创新改进项目实战:DEIM模型架构总览——编码器-解码器与动态门控设计 从一次诡异的梯度爆炸说起 去年冬天调DEIM的早期原型,模型在训练到第47个epoch时突然loss飙到NaN。检查了三天,最后发现是门控模块的sigmoid输出在极端情况下饱和,导致梯度回传时门控信号…...