【入门Flink】- 02Flink经典案例-WordCount
WordCount
需求:统计一段文字中,每个单词出现的频次
添加依赖
<properties><flink.version>1.17.0</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency></dependencies>
1.批处理
基本思路:先逐行读入文件数据,然后将每一行文字拆分成单词;接着按照单词分组,统计每组数据的个数。
1.1.数据准备
resources目录下新建一个 input 文件夹,并在下面创建文本文件words.txt
words.txt
hello flink
hello world
hello java
1.2.代码编写
public class BatchWordCount {public static void main(String[] args) throws Exception {// 1. 创建执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)String filePath = Objects.requireNonNull(BatchWordCount.class.getClassLoader().getResource("input/words.txt")).getPath();DataSource<String> lineDS = env.readTextFile(filePath);// 3. 转换数据格式FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Long>> out) {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}});// 4. 按照 word 进行分组UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);// 5. 分组内聚合统计AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);// 6. 打印结果sum.print();}
}
打印结果如下:(结果正确)

上述代码是基于 DataSet API 的,也就是对数据的处理转换,是看作数据集来进行操作的。
事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的 API 来实现。从Flink 1.12 开始,官方推荐的做法是直接使用 DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理:
bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
2.流处理
DataStreamAPI可以直接处理批处理和流处理的所有场景
2.1读取文件
还是上述words.txt文件
代码实现:
public class StreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读取文件String filePath = Objects.requireNonNull(StreamWordCount.class.getClassLoader().getResource("input/words.txt")).getPath();DataStreamSource<String> lineStream = env.readTextFile(filePath);// 3. 转换、分组、求和,得到统计结果SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}}).keyBy(data -> data.f0).sum(1);// 4. 打印sum.print();// 5. 执行env.execute();}
}
与批处理程序BatchWordCount有几点不同:
- 创建执行环境的不同,流处理程序使用的是
StreamExecutionEnvironment。 - 转换处理之后,得到的数据对象类型不同。
- 分组操做调用的是 keyBy 方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key。
- 最后执行execute方法,开始执行任务。
2.2读取Socket文件流
实际生产中,真正的数据多是无界的,需要持续地捕获数据。为了模拟这种场景,可以监听 socket 端口,然后向该端口不断的发送数据。
- 简单改动,只需将StreamWordCount 代码中读取文件数据的
readTextFile方法,替换成读取socket文本流的方法socketTextStream。
public class StreamSocketWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2.读取文件DataStreamSource<String> lineStream = env.socketTextStream("124.222.253.33", 7777);// 3. 转换、分组、求和,得到统计结果SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}}).keyBy(data -> data.f0).sum(1);// 4. 打印sum.print();// 5. 执行env.execute();}
}
- 在 Linux 环境的主机 124.222.253.33 上,执行下列命令,发送数据进行测试
nc -lk 7777
注意:要先启动端口,后启动 StreamSocketWordCount 程序,否则会报超时连接异常。
- 从Linux发送数据
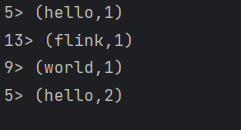
1、输入“hello flink”,输出如下内容

2、再输入“hello world”,输出如下内容
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的,对于 flatMap 里传入的 Lambda 表达式,系统只能推断出返回的是Tuple2类型,而无法得到 Tuple2<String, Long>。需要显式地告诉系统当前的返回类型,才能正确地解析出完整数据
相关文章:
【入门Flink】- 02Flink经典案例-WordCount
WordCount 需求:统计一段文字中,每个单词出现的频次 添加依赖 <properties><flink.version>1.17.0</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><…...

go语言将cmd stdout和stderr作为字符串返回而不是打印到控制台
go语言将cmd stdout和stderr作为字符串返回而不是打印到控制台 1、直接打印到控制台 从 golang 应用程序中执行 bash 命令,现在 stdout 和 stderr 直接进入控制台: cmd.Stdout os.Stdout cmd.Stderr os.Stderrpackage mainimport ("fmt"…...

OpenGL ES入门教程(二)之绘制一个平面桌子
OpenGL ES入门教程(二)之绘制一个平面桌子 前言0. OpenGL绘制图形的整体框架概述1. 定义顶点2. 定义着色器3. 加载着色器4. 编译着色器5. 将着色器链接为OpenGL程序对象6. 将着色器需要的数据与拷贝到本地的数组相关联7. 在屏幕上绘制图形8. 让桌子有边框…...
el-select 搜索无选项时 请求接口添加输入的值
el-select 搜索无选项时 请求接口添加输入的值 <template><div class"flex"><el-select class"w250" v-model"state.brand.id" placeholder"请选择" clearable filterable :filter-method"handleQu…...

基于单片机的商场防盗防火系统设计
收藏和点赞,您的关注是我创作的动力 文章目录 概要 一、系统分析二、系统总设计2.1基于单片机的商场防火防盗系统的总体功能2.2系统的组成 三 软件设计4.1软件设计思路4.2软件的实现4.2.1主控模块实物 四、 结论五、 文章目录 概要 本课题设计一种商场防火防盗报警…...

【Java|golang】2103. 环和杆---位运算
总计有 n 个环,环的颜色可以是红、绿、蓝中的一种。这些环分别穿在 10 根编号为 0 到 9 的杆上。 给你一个长度为 2n 的字符串 rings ,表示这 n 个环在杆上的分布。rings 中每两个字符形成一个 颜色位置对 ,用于描述每个环: 第 …...

[SSD综述 1.4] SSD固态硬盘的架构和功能导论
依公知及经验整理,原创保护,禁止转载。 专栏 《SSD入门到精通系列》 <<<< 返回总目录 <<<< 前言 机械硬盘的存储系统由于内部结构, 其IO访问性能无法进一步提高,CPU与存储器之间的性能差距逐渐扩大。以Nand Flash为存储介质的固态硬盘技术的发展,…...

【C++那些事儿】类与对象(1)
君兮_的个人主页 即使走的再远,也勿忘启程时的初心 C/C 游戏开发 Hello,米娜桑们,这里是君兮_,我之前看过一套书叫做《明朝那些事儿》,把本来枯燥的历史讲的生动有趣。而C作为一门接近底层的语言,无疑是抽象且难度颇…...
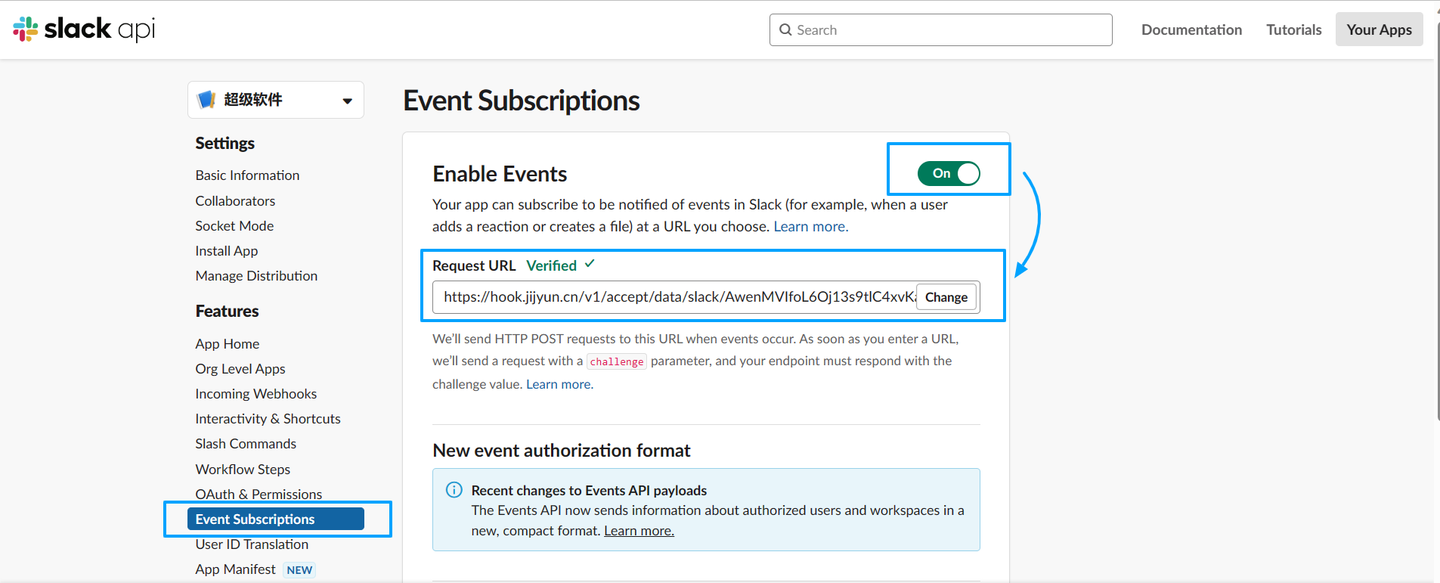
集简云x slack(自建)无需API开发轻松连接OA、电商、营销、CRM、用户运营、推广、客服等近千款系统
slack是一个工作效率管理平台,让每个人都能够使用无代码自动化和 AI 功能,还可以无缝连接搜索和知识共享,并确保团队保持联系和参与。在世界各地,Slack 不仅受到公司的信任,同时也是人们偏好使用的平台。 官网&#x…...

JS模块化,ESM模块规范的 导入、导出、引用、调用详解
JS模块化,ESM模块规范的 导入、导出、引用、调用详解 写在前面实例代码1、模块导出 - export导出之 - 独立导出导出之 - 集中多个导出导出之 - 默认导出导出之 - 集中默认导出导出之 - 混合导出 2、模块导入 - import导入之 - 全部导入导入之 - 默认导入导入之 - 指…...

markdown常用的快捷键
一级标题 #加 空格 是一级标题 二级标题 ##加空格是二级标题 三级标题 字体 * 粗体:两个**号 斜体:一个 斜体加粗:三个 删除:两个~~ 我是字体 我是字体 我是字体 我是字体 引用 箭头符号>加空格 回车 分割线 三个 - …...
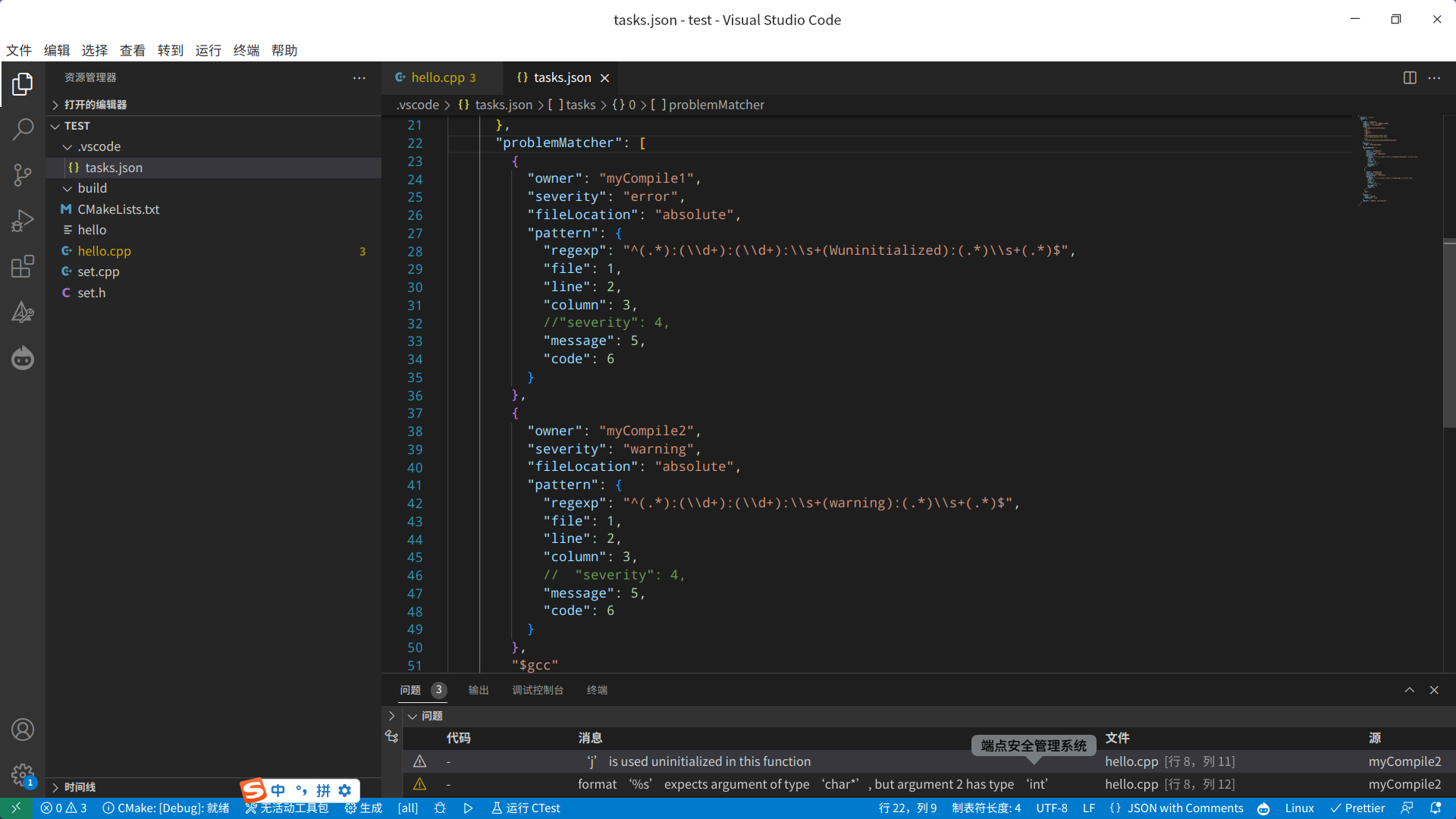
VSCode中的任务什么情况下需要配置多个问题匹配器problemMatcher?多个问题匹配器之间的关系是什么?
☞ ░ 前往老猿Python博客 ░ https://blog.csdn.net/LaoYuanPython 一、简介 在 VS Code 中,tasks.json 文件中的 problemMatcher 字段用于定义如何解析任务输出中的问题(错误、警告等)。 problemMatcher是一个描述问题匹配器的接口&…...

C语言鞍点数组改进版
题目内容: 给定一个n*n矩阵A。矩阵A的鞍点是一个位置(i,j),在该位置上的元素是第i行上的最大数,第j列上的最小数。一个矩阵A也可能没有鞍点。 你的任务是找出A的鞍点。 改进目标: 网络上很多…...
K8s:部署 CNI 网络组件+k8s 多master集群部署+负载均衡及Dashboard k8s仪表盘图像化展示
目录 1 部署 CNI 网络组件 1.1 部署 flannel 1.2 部署 Calico 1.3 部署 CoreDNS 2 负载均衡部署 3 部署 Dashboard 1 部署 CNI 网络组件 1.1 部署 flannel K8S 中 Pod 网络通信: ●Pod 内容器与容器之间的通信 在同一个 Pod 内的容器(Pod 内的容…...
【数据结构】树家族
目录 树的相关术语树家族二叉树霍夫曼树二叉查找树 BST平衡二叉树 AVL红黑树伸展树替罪羊树 B树B树B* 树 当谈到数据结构中的树时,我们通常指的是一种分层的数据结构,它由节点(nodes)组成,这些节点之间以边(…...

Vert.x学习笔记-Vert.x的基本处理单元Verticle
Verticle介绍 Verticle是Vert.x的基本处理单元,Vert.x应用程序中存在着处理各种事件的处理单元,比如负责HTTP API响应请求的处理单元、负责数据库存取的处理单元、负责向第三方发送请求的处理单元。Verticle就是对这些功能单元的封装,Vertic…...
干货分享:基于 LSTM 的广告库存预估算法
近年来,随着互联网的发展,在线广告营销成为一种非常重要的商业模式。出于广告流量商业化售卖和日常业务投放精细化运营的目的,需要对广告流量进行更精准的预估,从而更精细的进行广告库存管理。 因此,携程广告纵横平台…...

dataframe删除某一列
drop import pandas as pd data {‘A’: [1, 2, 3], ‘B’: [4, 5, 6], ‘C’: [7, 8, 9]} df pd.DataFrame(data) #使用drop方法删除列 df df.drop(‘B’, axis1) # 通过指定列名和axis1来删除列 del import pandas as pd data {‘A’: [1, 2, 3], ‘B’: [4, 5, 6]…...

提升ChatGPT答案质量和准确性的方法Prompt engineering
文章目录 怎么获得优质的答案设计一个优质prompt的步骤:Prompt公式:示例怎么获得优质的答案 影响模型回答精确度的因素 我们应该知道一个好的提示词,要具备一下要点: 清晰简洁,不要有歧义; 有明确的任务/问题,任务如果太复杂,需要拆分成子任务分步完成; 确保prompt中…...
SpringBoot + Vue2项目打包部署到服务器后,使用Nginx配置SSL证书,配置访问HTTP协议转HTTPS协议
配置nginx.conf文件,这个文件一般在/etc/nginx/...中,由于每个人的体质不一样,也有可能在别的路径里,自己找找... # 配置工作进程的最大连接数 events {worker_connections 1024; }# 配置HTTP服务 http {# 导入mime.types配置文件…...

别再只会用menuconfig了!手把手教你为ESP32项目定制专属Kconfig配置菜单
从配置使用者到设计者:ESP32项目中的Kconfig高级定制指南 在ESP-IDF开发环境中,menuconfig几乎是每个开发者每天都要接触的工具。但大多数开发者仅仅停留在"使用者"层面——他们知道如何勾选选项、调整参数,却很少思考这些配置菜单…...
)
TVA智能体范式的工业视觉革命(3)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

别被“逻辑“吓退了,入门级数字化认证根本不需要你是学霸
很多人一听到“数字化认证”“AI考试”“逻辑题”,脑子里立刻浮现两种画面:一种是数学特别强的人在刷题,另一种是自己看不懂专业词,直接劝退。可真到企业实习、岗位转型、项目落地时你会发现,职场需要的往往不是“学霸…...

K-Means聚类选K避坑指南:当肘部法则“失灵”,轮廓系数如何救场?
K-Means聚类选K避坑指南:当肘部法则"失灵",轮廓系数如何救场? 在数据科学实践中,K-Means算法因其简洁高效而广受欢迎,但确定最佳聚类数K却常让从业者陷入困境。当面对高维、噪声多或分布不平衡的真实业务数据…...

2026年Java面试,不会背这些八股文真不行
Java 面试 Java 作为编程语言中的 NO.1,选择入行做 IT 做编程开发的人,基本都把它作为首选语言,进大厂拿高薪也是大多数小伙伴们的梦想。以前 Java 岗位人才的空缺,而需求量又大,所以这种人才供不应求的现状,就是 Java 工程师的薪…...

精通yum/dnf:从依赖地狱到高效Linux软件包管理
1. 从“依赖地狱”到“一键管理”:为什么你需要精通yum/dnf在Linux世界里,尤其是Red Hat系(RHEL、CentOS、Fedora、Rocky Linux、AlmaLinux)的用户,软件包管理是绕不开的日常。如果你还在用rpm -ivh一个接一个地手动安…...

如何免费解锁雀魂全角色皮肤:终极完整配置指南
如何免费解锁雀魂全角色皮肤:终极完整配置指南 【免费下载链接】majsoul_mod_plus 雀魂解锁全角色、皮肤、装扮等,支持全部服务器。 项目地址: https://gitcode.com/gh_mirrors/ma/majsoul_mod_plus 还在为无法获得心仪的雀魂角色而烦恼吗&#x…...

解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南
解锁网盘文件下载新体验:LinkSwift直链解析工具完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

【C#vsPython·第一阶段】 Python 的运算符,有些地方真的“骚“
在 C# 里判断一个数在 0 到 10 之间,你得写 x > 0 && x < 10。 在 Python 里?直接写 0 < x < 10。对,就这么简单,编译器...哦不,解释器不会报错。 当我第一次看到这个写法的时候,我心…...

TPS40192与TPS40193多相降压控制器:DCR与CS电流检测方案深度对比与设计实践
1. 项目概述:从两颗芯片说起最近在做一个大电流的分布式电源项目,板子上需要给核心处理器和一堆外围芯片供电,电流需求从几安培到几十安培不等,电压轨也有好几路。这种场景下,传统的线性稳压器(LDO…...