【深度学习基础】专业术语汇总(欠拟合和过拟合、泛化能力与迁移学习、调参和超参数、训练集、测试集和验证集)
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨
📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】
📢:文章若有幸对你有帮助,可点赞 👍 收藏 ⭐不迷路🙉
📢:内容若有错误,敬请留言 📝指正!原创文,转载请注明出处
文章目录
- 欠拟合和过拟合
- 泛化能力与迁移学习
- 查准率和查全率
- 调参和超参数
- 训练集、测试集和验证集
- 端到端的概念
- 卷积神经网络
- 其他
欠拟合和过拟合
欠拟合的概念:
原因是模型训练次数不够,导致模型太简单,一般一开始的模型就是欠拟合模型。解决办法:充分训练。
过拟合的概念:
模型在训练集上表现良好,表现为对训练集的识别或是检测精度随着不断训练越来越高,但在测试数据集上表现不好,表现为离100%的精度还有很大差距。也就是只能拟合训练数据,不能很好拟合其他数据。
过拟合的原因:
1.模型拥有大量参数、表现力太强。
2.训练数据太少。
解决过拟合的办法:
1.数据增强法:图像缩放,图像随机截取,随机翻转;图像亮度、对比度、颜色调整
2.学习率衰减:一开始设置一个比较大的学习率,让模型快速靠近最优解附近,然后使用比较小的学习率慢慢收敛到达最优解。
3.权值衰减:通过在学习过程中对大的权重进行惩罚,来抑制过拟合。
4.dropout:在学习过程中,随机删除神经元的方法
泛化能力与迁移学习
泛化能力:对未知数据有非常好的检测效果。
迁移学习(transfer leaning):机器像人一样能够举一反三的学习,借鉴前人的经验,使用很少时间完成相似任务。训练好的模型(预训练模型)已经具备对图片的理解能力,根据实际应用,修改部分网络层,而不改变其提取的特征,也就是在全连接层做分类的修改。卷积神经网络利用数据、模型、任务之间的相似性,将训练好的内容应用到新的任务上,被称为迁移学习,被迁移的对象称为源域,被赋予的对象称为目标域,迁移学习不是具体的模型,更像是解题思路,简单来说就是站在巨人的肩膀上。意义:目标领域的数据太少,需要标注数据更多的源域的帮助,节约训练时间,实现个性化应用等。
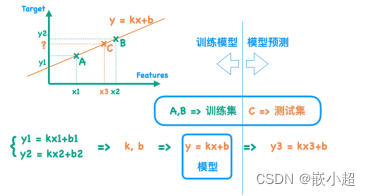
模型训练的概念:将数据集扔给我们需要预测的函数中,来求取模型参数。对训练机器学习模型的理解,从图可以理解:训练集就是A和B的坐标,测试集就是C的坐标,而模型就是由A和B得到的函数
查准率和查全率
上采样:即是反卷积(Deconvolution)
特征图:卷积层的输入输出数据成为特征图。
查准率:等于精确率。它表示预测为正的样本中多少是真正的正样本;
查全率:等于召回率。 TP、FN 和 FP :分别表示真阳性、假阴性和假阳性。真阳性是指预测为正,实际为正;假阴性是指预测为负,实际为正;假阳性是指预测为正,实际为负。
超参数:初始参数,人为给定。包括卷积层中的卷积核和数量;池化层中的池化方式、步长;全连接层中的神经元个数等等。 神经元的数量、batch大小、参数更新时的学习率或是权值衰减。
调参和超参数
调参:优化微调超参数。调参主要是调学习率,调的好能慢慢到损失函数的谷底。
学习率:衰减系数设置为XX ,学习率随着迭代次数在逐渐下降。学习率:表示学习的速度。
学习率对梯度下降的影响:为了能够使得梯度下降法有较好的性能,我们需要把学习率的值设定在合适的范围内。学习率决定了参数移动到最优值的速度快慢。如果学习率过大,很可能会越过最优值;反而如果学习率过小,优化的效率可能过低,长时间算法无法收敛。所以学习率对于算法性能的表现至关重要。因此学习率大小决定模型训练时长。
迭代次数:指的是模型所有数据样本都进行训练的轮数,模型收敛的迭代次数往往和数据量和模型的复杂程度成正相关,模型越复杂、数据样本越多就需要越多的迭代次数。
batch_size:批大小,BATCH_SIZE = self.IMAGES_PER_GPU * self.GPU_COUNT,内存小的话IMAGES_PER_GPU = 1,因此训练设置的batch_size=1。steps_per_epoch:一轮epoch包含的步数,steps_per_epoch = total_samples//(batch_size)。
残差模块:预测值和真实值之间的差值。加入偏差(残差)就会使原始数据更加接近真实值。残差神经网络越深,从图像中提取的特征就会越丰富。残差块使得很深的网络更加容易训练,甚至可以训练一千层的网络。
残差模块组成:一个主干层,包括卷积层和激活函数;一个支路做恒等映射。残差网络中一部分快捷连接是虚线,一部分是实线。实线部分表示输入输出通道维度相同,可直接进行相加,因此采用计算方式为
H(x)=F(x)+x。虚线部分表示通道不同,需要进行维度调整,采用的计算方式为
H(x)=F(x)+Wx。由于恒等映射的存在,减少网络的梯度消失,加快收敛速度,提高训练精度。
训练集、测试集和验证集
训练集:训练模型,求f(x)中的参数
测试集:求各个样本对应的预测集,对模型进行评估。注意:测试集不能用于训练。
验证集(validation):通过验证集对各个模型进行评估,从而选出这一个具体问题得分最高的机器学习算法和超参,然后再在训练集上重新训练模型,从而得到最终的模型,最后用在测试上预测。
划分比例:训练集、验证集、测试集的比例一般为:6:2:2;8:1:1;7;2;1
端到端的概念
而深度学习模型在训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束,这是端到端的。
卷积神经网络
卷积层作用:替代传统使用先验模型的方式进行特征提取。 输入特征图和输出特征图:卷积层输入输出的数据。
卷积运算:卷积层进行的处理就是卷积运算。滤波器对输入的数据按照一定间隔滑动,在各个位置上滤波器的元素和输入的对应元素相乘,然后再求和。有时还需要加上偏置,将这个结果保存到输出的对应位置。将这个过程在所有位置上都进行一遍,就得到卷积运算的输出。
滤波器:又称卷积核,用于卷积运算对输入数据的滤波处理。 填充的概念:在卷积运算前,在输入数据的周围填入固定的数据。
1X1卷积层的作用:不改变特征图的大小,只改变通道数。特征图进行降维,减少网络参数。同理也可以对特征图进行升维。
填充的作用:调整输出的大小。 步幅:滤波器的位置间隔成为步幅。 偏置:在输出数据前,在每个元素中都加上某个固定值。池化层的作用:减少原特征图的尺寸,但同时不过多丢失特征信息。减少了网络的参数量,提高网络运算效率。 池化层的类型:最大池化、均值池化。
池化层的特征:1.没有要学习的参数;2.通道数不发生变化;3.对微小位置的变化具有鲁棒性。 全连接层的作用:全连接层的作用主要就是实现分类
流程:通过对卷积层获得的物体所有细节特征进行归纳,判断是否符合某个物体,借助置信度这个值进行量化评判,值越高,说明越接近这个物体。
激活函数的作用:决定如何来激活输入信号的总和。用于信号转换。 激活函数的类型:Sigmoid函数(最早),Relu函数。输出层的作用:根据情况改变输出层的激活函数,实现分类和回归的作用 输出类型:分类和回归,分类一般用softmax函数;回归使用恒等函数。
恒等函数:会将输入按照原样输出,对于输入的信息,不加以任何改动直接输出。
Softmax函数:公式,注意事项:1.指数运算可能存在数字过大导致溢出的问题,解决办法:分子分母均减去输出信号的最大值。2.神经网络只把输出值最大的神经元对于的类别作为识别结果,不用softmax也可以判断类别。在实际的问题中,由于函数运算的匀速需要一定的计算量,因此输出层softmax函数一般会被忽略。
其他
残差网络设计初衷:在增加网络层的同时能改变精度,通过残差块加入快速通道。所谓残差指的是预测值与真实值之间的偏差。针对网络退化现象,而研发该网络,解决网络退化问题,所谓网络退化指的是模型在验证集和测试集上误差都比浅层网络的高,因此不能一味地将网络堆地很深。
Ground Truth:放到机器学习里面,再抽象点可以把它理解为真值、真实的有效值或者是标准的答案。
网络退化:在测试集和训练集的误差都很高。在目标检测领域,深度残差网络取得了优异的成绩。随着网络深度的增加,在深层网络能够收敛的前提下,正确率开始饱和甚至下降,这称之为网络退化问题
梯度爆炸和梯度消失:随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了
卷积层数:resnet18、34、51、101,其中的数字表示卷积层数。
增加卷积层数的意义:网络越深从图像中提取的层次就越丰富,这样各类计算机视觉任务都可以使用这个深度网络提取的底层特征,或是多层次特征从中获益。
鲁棒性:在机器学习,训练模型时,工程师可能会向算法内添加噪声(如对抗训练),以便测试算法的「鲁棒性」。可以将此处的鲁棒性理解述算法对数据变化的容忍度有多高。
损失函数:将卷积神经网络推理的结果跟真实结果进行误差计算,就是损失函数,损失函数越小,表明越接近真实结果。
如何降低损失函数:通过修改卷积核的参数与神经元的权重,使得误差最小。通过给卷积神经网络“喂”大数据,它就能自己计算出最合适的卷积核,权重等参数,使得误差降到最低。这也就是不用人为给定参数,它自己学习的过程-------机器学习。
激活函数:神经网络至少需要一层隐藏层和足够的神经元,利用非线性的激活函数便可以模拟任何复杂的连续函数。
激活函数的选择:在实际应用中,隐藏层的默认推荐激活函数通常为relu函数,大于0时是线性的,能很好解决梯度消失问题,其整体的非线性能够在神经网络中拟合任何复杂的连续函数。但是小于0时,其输出值为0,这意味着神经元处于熄灭状态,且在逆向参数调整过程中不产生梯度调整值。
机器学习的具体方法:使用梯度下降法,对损失函数求导,最小值处就是损失降到最低的点(波谷),寻找最小值的过程就是学习过程,最终找到该值说明学习(模型训练)成功。
反向传播:就是BP(back propagation)算法。设计思想:神经网络的优异程度是神经元之间连接的权重和神经元的阈值,确定这些数字的办法大部分时间在用反向传播的方法,也就是BP算法。每个神经网络的初始参数是随机赋予的,根据网络输出的答案与正确答案之间的误差,不断调整网络的参数。从最后一层开始逐层向前调整神经网络的参数,如果误差值为负就提示权重,反之降低权重,调整的程度受到学习率的制约,在一次次输入数据和反向调整中,网络就能给出不错的输出。由于强大的调整能力,BP算法控制下的神经网络很容易过拟合。BP:逆向参数调整。
相关文章:
【深度学习基础】专业术语汇总(欠拟合和过拟合、泛化能力与迁移学习、调参和超参数、训练集、测试集和验证集)
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
【C语言:函数栈帧的创建与销毁】
文章目录 前言一、前期准备1.寄存器2.汇编指令3.测试代码 二、解开函数栈帧的神秘面纱1.栈帧大体轮廓2.main函数栈帧的创建3.main函数内执行有效代码4.烫烫烫5.函数参数的传递6.add函数栈帧的创建7.add函数内执行有效代码8.add是如何获得参数的9. add函数栈帧的销毁10.main函数…...

怎么在C++中实现云端存储变量
随着云计算技术的快速发展,现在我们可以将数据存储在云端,以便于在不同设备和地点访问。在C中,我们也可以通过一些方法来实现这个功能。本文将详细介绍如何在C中实现云端存储变量。 首先,我们需要理解,C本身并没有直接…...

短视频矩阵营销系统工具如何助力商家企业获客?
1.批量剪辑技术研发 做的数学建模算法,数学阶乘的组合乘组形式,采用两套查重机制,一套针对素材进行查重抽帧素材,一套针对成片进行抽帧素材打分制度查重,自动滤重计入打分。 2.账号矩阵分发开发 多平台,…...

PCL 计算一个平面与包围盒体素的相交线
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 基于之前计算的包围盒体素(PCL 包围盒体素化显示),这里使用一个平面与其进行相交,并求出与其中体素单元的相交线。 二、实现代码 //标准文件 #include <iostream> #include <thread>//PCL...

面向教育的计算机视觉和深度学习5
面向教育的计算机视觉和深度学习5 1. 好处智能内容(Smart Content)任务自动化(Task Automation)缩小技能差距(Closing Skill Gap) 2. 应用程序学生学习与福利(Student Learning and Welfare&…...

FPGA芯片内部结构
参考链接:FPGA的进阶之第二章FPGA芯片内部结构(2)...
人工智能AI创作系统ChatGPT网站系统源码+AI绘画系统支持GPT4.0/支持Midjourney局部重绘
一、前言 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建…...

Google 开源项目风格指南
目录 C 风格指南 Objective-C 风格指南 Python 风格指南 Shell 风格指南 TypeScript 风格指南 Javascript 风格指南 HTML/CSS 风格指南 C 风格指南 C 风格指南 - 内容目录 — Google 开源项目风格指南 Objective-C 风格指南 Objective-C 风格指南 - 内容目录 — Googl…...

无限上下文,多级内存管理!突破ChatGPT等大语言模型上下文限制
目前,ChatGPT、Llama 2、文心一言等主流大语言模型,因技术架构的问题上下文输入一直受到限制,即便是Claude 最多只支持10万token输入,这对于解读上百页报告、书籍、论文来说非常不方便。 为了解决这一难题,加州伯克利…...

学习剑指jvm
一直弱,jvm 1、主要解决运行状态的线上系统突然卡死,造成系统无法访问,甚至直接内存溢出异常(Out of Memory,OOM) 2、希望解决线上JVM垃圾回收的相关问题,但无从下手。 3、新项目上线,对设置…...
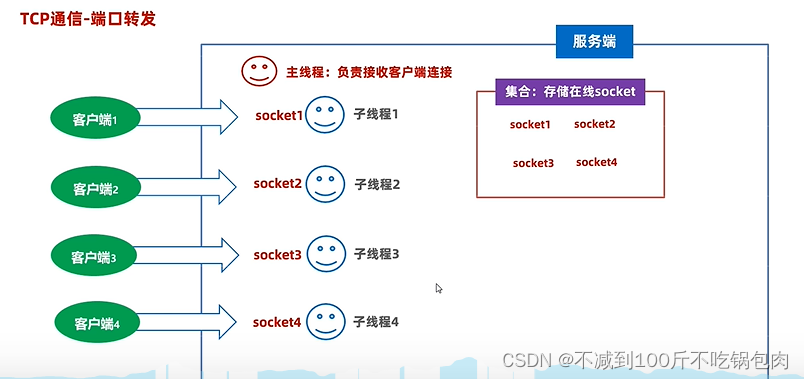
java网络通信
浏览器中输入:“www.woaijava.com”之后都发生了什么? 请详细阐述 由域名→IP地址 寻找IP地址的过程依次经过了浏览器缓存、系统缓存、hosts文件、路由器缓存、 递归搜索根域名服务器。 建立TCP/IP连接(三次握手具体过程) 由浏览…...

Three.js之加载外部三维模型
参考资料 建模软件绘制3D场景…加载.gltf文件(模型加载全流程) 知识点 注:基于Three.jsv0.155.0 三维建模软件gltf格式加载.gltf文件 三维建模软件 D美术常用的三维建模软件,比如Blender、3dmax、C4D、maya等等 Blender(轻量开源)3dmaxC4Dmaya 特…...

【机器学习】正规方程与梯度下降API及案例预测
正规方程与梯度下降API及案例预测 文章目录 正规方程与梯度下降API及案例预测1. 正规方程与梯度下降正规方程(Normal Equation)梯度下降(Gradient Descent) 2. API3. 波士顿房价预测 1. 正规方程与梯度下降 回归模型是机器学习中…...
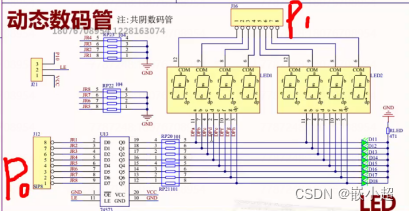
【SOC基础】单片机学习案例汇总 Part2:蜂鸣器、数码管显示
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
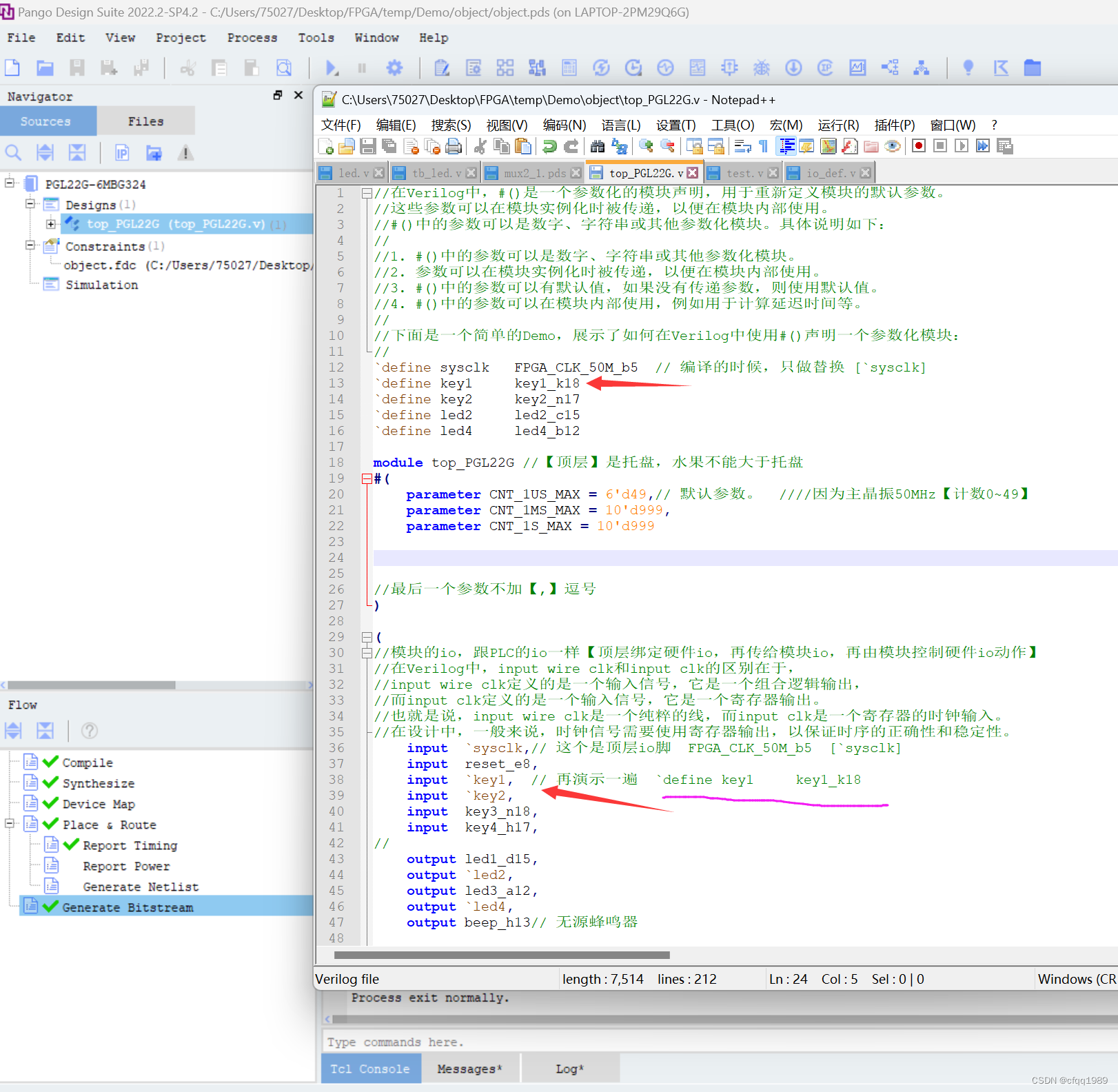
顶层模块【FPGA】
1顶层模块: 不能像C语言的h文件那样,把io的定义放在其他文件。 在Verilog中,顶层模块是整个设计的最高层次,它包含了所有其他模块和子模块。 顶层模块定义了整个设计的输入和输出端口,以及各个子模块之间的连接方式。…...

IT行业就业分析
1. IT技术发展背景及历程介绍 2. IT行业的就业方向有哪些? IT技术发展背景及历程介绍: IT技术的发展背景和历程可以追溯到上世纪40年代,以下是IT技术的主要发展阶段: 1.计算机的发展:二战期间,计算机作…...

读取用户剪贴板内容
读取用户剪贴板内容 在Web开发中,要读取用户剪贴板的内容,可以使用Clipboard API。这个API提供了一组方法和事件,用于访问和操作用户的剪贴板数据。 HTML <body><button onclick"readClipboard()">读取剪切板内容&l…...
“深入理解Nginx的负载均衡与动静分离“
目录 引言一、Nginx简介1. Nginx的基本概念2. Nginx的特点3. Nginx的安装配置 二、Nginx搭载负载均衡三、前端项目打包四、Nginx部署前后端分离项目,同时实现负载均衡和动静分离总结 引言 在现代互联网应用中,高性能和可扩展性是至关重要的。Nginx作为一…...
JVM 内存和 GC 算法
文章目录 内存布局直接内存执行引擎解释器JIT 即时编译器JIT 分类AOT 静态提前编译器(Ahead Of Time Compiler) GC什么是垃圾为什么要GC垃圾回收行为Java GC 主要关注的区域对象的 finalization 机制GC 相关算法引用计数算法(Reference Count…...

LDDC终极指南:如何快速获取精准的逐字歌词
LDDC终极指南:如何快速获取精准的逐字歌词 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地址: https:/…...

用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战
用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战 黏菌算法(Slime Mould Algorithm, SMA)作为一种新兴的智能优化算法,近年来在工程优化、机器学习参数调优等领域展现出独特优势。本文将带您从生物行为理解到Python实现&a…...

第十章:什么是Agentic AI?——让AI从“回答问题“到“替你办事“
难度级别:★★★★☆ | 预计阅读时间:15分钟 你将学到:Agentic AI的核心能力、技术架构、主流框架对比、PM选型决策框架、以及如何设计一个AI Agent系统 引言:从"工具"到"代理"的跨越 一个真实的痛点 某科技公司的研究员小王,每天需要花3小时完成以…...

Cursor AI助手功能扩展技术实现:5步实现永久免费使用的完整方案
Cursor AI助手功能扩展技术实现:5步实现永久免费使用的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...
一键脚本 + 完整配置)
OpenClaw 3 机集群(Windows + Linux 混合)一键脚本 + 完整配置
集群架构规划(1 主 2 从)统一安装脚本(Windows PowerShell / Linux bash)主节点配置(gateway 调度)从节点配置(worker 注册到主)集群通信、端口、令牌、存储一键启停、扩容、状态检…...

多账号流量内容运营的数据归因与ROI优化:从经验驱动到算法决策的技术转型
📌 当一个团队同时运营20个以上的新媒体账号时,最大的问题不是"怎么发",而是"发了之后怎么知道哪条有用"。本文从数据工程角度,拆解多账号流量内容矩阵如何通过数据归因模型实现ROI优化,以星链引擎…...

人大金仓KingbaseES分区表‘挂载’与‘摘除’功能详解:像搭积木一样管理你的数据
人大金仓KingbaseES分区表‘挂载’与‘摘除’功能实战指南:数据管理的乐高式玩法 想象一下,你的数据库表像一堆积木,可以随时拆解、重组,而无需担心数据丢失或性能下降。这正是人大金仓KingbaseES分区表"挂载(ATTACH)"和…...

MASA模组中文汉化包:为中文玩家打造的完整界面本地化解决方案
MASA模组中文汉化包:为中文玩家打造的完整界面本地化解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft中复杂的英文模组界面而困扰吗?MAS…...

MulimgViewer:高效多图像浏览与对比工具
MulimgViewer:高效多图像浏览与对比工具 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. 项目地址: https://gitcode.com…...

Tidal-Media-Downloader:3分钟掌握终极Tidal音乐下载方案
Tidal-Media-Downloader:3分钟掌握终极Tidal音乐下载方案 【免费下载链接】Tidal-Media-Downloader Download TIDAL Music On Windows/Linux/MacOs (PYTHON/C#) 项目地址: https://gitcode.com/gh_mirrors/ti/Tidal-Media-Downloader 还在为无法随时随地畅享…...