【ElasticSearch系列-05】SpringBoot整合elasticSearch
ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【三】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【四】ElasticSearch的聚合查询操作 | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【五】SpringBoot整合elasticSearch | https://blog.csdn.net/zhenghuishengq/article/details/134212200 |
SpringBoot整合elasticSearch
- 一,SpringBoot整合ElasticSearch
- 1,需要的依赖以及版本
- 2,创建config配置类并测试连接
- 3,增删改查测试
- 3.1,索引插入数据
- 3.2,根据id查询数据
- 3.3,删除一条数据
- 4,普通查询
- 4.1,match条件查询
- 4.2,term精确匹配
- 4.3,prefix前缀查询
- 4.4,通配符查询wildcard
- 4.5,范围查询
- 4.6,fuzzy模糊查询
- 4.7,highlight高亮查询
- 5,聚合查询
- 5.1,aggs聚合查询
- 5.2,获取最终结果
一,SpringBoot整合ElasticSearch
前面几篇讲解了es的安装,dsl语法,聚合查询等,接下来这篇主要就是讲解通过java的方式来操作es,这里选择通过springboot的方式整合ElasticSearchSearch
在学习这个整合之前,可以查看对应的官网资料:https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/7.17/connecting.html
1,需要的依赖以及版本
首先创建springboot项目,然后需要的依赖如下,我前面用的是7.7.0的版本,因此这里继续使用这个版本。其他的依赖根据个人需要选择
<properties><java.version>8</java.version><elasticsearch.version>7.7.0</elasticsearch.version>
</properties>
<dependencies><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.7.0</version></dependency>
</dependencies>
2,创建config配置类并测试连接
随后创建一个config的配置类,用于连接上ElasticSearch,我这边是单机版,并没有集群
/*** 连接es的工具类*/
@Configuration
public class ElasticSearchConfig { public static final RequestOptions COMMON_OPTIONS;static {RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();COMMON_OPTIONS = builder.build();}@Beanpublic RestHighLevelClient esRestClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("xx.xx.xx.xx", 9200, "http")));return client;}
}
在创建好了之后,可以直接在test类中进行测试,看能否连接成功
@RunWith(SpringRunner.class)
@SpringBootTest
public class StudyApplicationTests {@Resourceprivate RestHighLevelClient client;@Testpublic void contextLoads() {System.out.println(restHighLevelClient);}
}
在运行之后,如果打印出了以下这句话,表示整合成功
org.elasticsearch.client.RestHighLevelClient@7d151a
3,增删改查测试
3.1,索引插入数据
首先先创建一个users的索引,并向里面插入一条数据。插入和更新都可以用这个方法
//创建一个user索引,并且插入一条数据
@Test
public void addData() throws IOException {//创建一个索引IndexRequest userIndex = new IndexRequest("users");User user = new User();user.setId(1);user.setUsername("Tom");user.setPassword("123456");user.setAge(18);user.setSex("女");//添加数据userIndex.source(JSON.toJSONString(user), XContentType.JSON);IndexResponse response = client.index(userIndex, ElasticSearchConfig.COMMON_OPTIONS);//响应数据System.out.println(response);
}
随后再在kibana中查询这个索引,可以看到这条数据是已经插入成功的,并且索引页创建成功
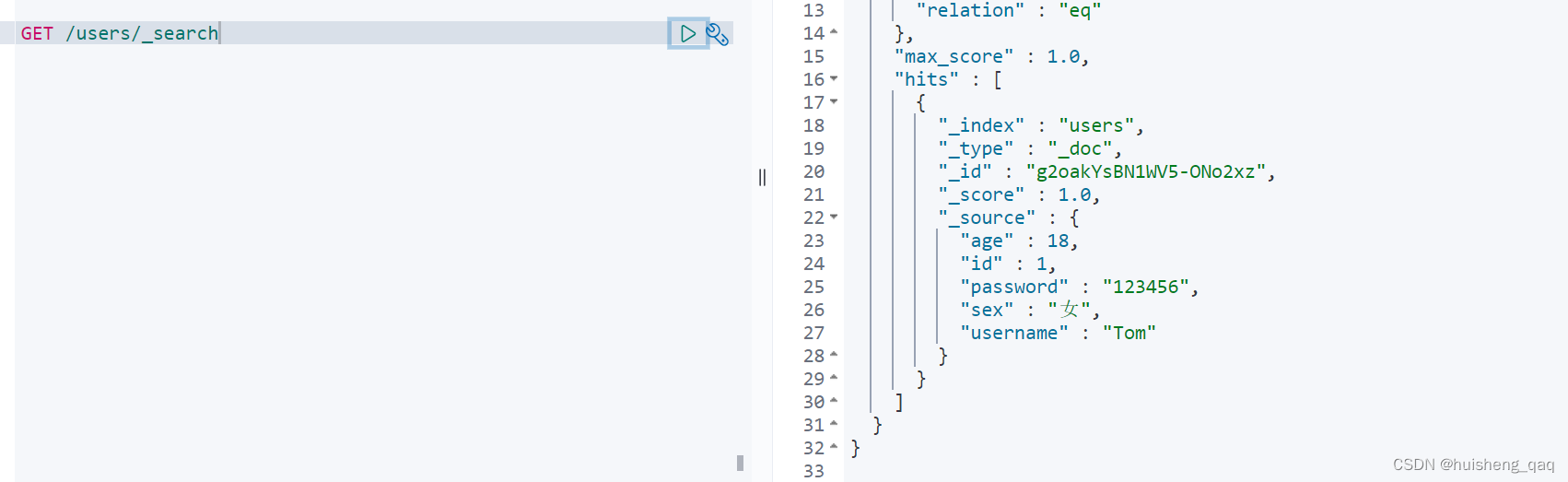
3.2,根据id查询数据
查询id为1的数据,需要通过QueryBuild构造器查询
@Test
public void getById() throws IOException {SearchRequest request = new SearchRequest("users");SearchSourceBuilder builder = new SearchSourceBuilder();builder.query(QueryBuilders.matchQuery("id", "1"));request.source(builder);SearchResponse response = client.search(request, RequestOptions.DEFAULT);System.out.println(response);
}
3.3,删除一条数据
删除刚刚创建的这条数据,这里直接设置id为1即可
@Test
public void deleteById() throws Exception{DeleteRequest request = new DeleteRequest("users");request.id("1");DeleteResponse delete = client.delete(request, ElasticSearchConfig.COMMON_OPTIONS);System.out.println(delete);
}
4,普通查询
这里主要是结合本人写的第三篇Query DSL的语法,通过java的方式写出依旧是先创建一个员工的信息索引,并且设置字段得我属性
PUT /employees
{"mappings": {"properties": {"name":{"type": "keyword"},"job":{"type": "keyword"},"salary":{"type": "integer"}}}
}
随后批量的插入10条数据
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "huisheng1","job":"python","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "huisheng2","job":"java","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "huisheng3","job":"python","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "huisheng4","job":"java","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "huisheng5","job":"javascript","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "huisheng6","job":"javascript","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "huisheng7","job":"c++","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "huisheng8","job":"c++","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "huisheng9","job":"java","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "huisheng10","job":"java","salary": 9000}
4.1,match条件查询
首先是分页查询,分页查询的queryDSL的语法如下
GET /employees/_search
{"query": {"match": {"job": "java"}}
}
java的语法如下
SearchRequest request = new SearchRequest("employees");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("job", "java"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
短语匹配的语法如下
builder.query(QueryBuilders.matchPhraseQuery("job","java"));
多字段查询的语法如下
String fields[] = {"job","name"};
builder.query(QueryBuilders.multiMatchQuery("java",fields));
queryString的语法如下
builder.query(QueryBuilders.queryStringQuery("java"));
4.2,term精确匹配
GET /employees/_search
{"query": {"term": {"job": "java"}}
}
精确匹配通过java的方式如下
builder.query(QueryBuilders.termQuery("job","java"));
4.3,prefix前缀查询
PUT /employees/_search
{"query":{"prefix":{"name":{"value":"huisheng1"}}}
}
前缀查询的java方式如下
builder.query(QueryBuilders.prefixQuery("name","huisheng1"));
4.4,通配符查询wildcard
GET /employees/_search
{"query": {"wildcard": {"job": {"value": "*py*"}}}
}
通配符查询的java方式如下
builder.query(QueryBuilders.wildcardQuery("job","py"));
4.5,范围查询
POST /employees/_search
{"query": {"range": {"salary": {"gte": 25000}}}
}
范围查询的java方式如下
builder.query(QueryBuilders.rangeQuery("salary").gte(25000));
4.6,fuzzy模糊查询
GET /employees/_search
{"query": {"fuzzy": {"job": {"value": "javb","fuzziness": 1 //表示允许错一个字}}}
}
模糊查询的java方式如下
builder.query(QueryBuilders.fuzzyQuery("job","javb").fuzziness(Fuzziness.ONE));
4.7,highlight高亮查询
GET /employees/_search
{"query": {"term": {"job": {"value": "java"}}},"highlight": {"fields": {"*":{}}}
}
高亮查询的java方式如下
builder.query(QueryBuilders.termQuery("job","java"));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("job");
builder.highlighter(highlightBuilder);
5,聚合查询
5.1,aggs聚合查询
先通过job进行分组查询,再拿到结果后再进行stats查询,求最大值,最小值,平均值等
POST /employees/_search
{"size": 0,"aggs": {"name": {"terms": {"field": "job"},"aggs": {"stats_salary": {"stats": {"field": "salary"}}}}}
}
其java代码如下,需要注意的点就是,如果存在二级聚合,那么需要调用这个 subAggregation 方法,如果只需要聚合的结果而不需要查询的结果,可以直接在SearchSourceBuilder的实例设置为0即可。
@Test
public void toAgg() throws Exception{//创建检索请求SearchRequest searchRequest = new SearchRequest();//指定索引searchRequest.indices("employees");//构建检索条件SearchSourceBuilder builder = new SearchSourceBuilder();//构建聚合条件TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("jobData").field("job");aggregationBuilder.subAggregation(AggregationBuilders.stats("salaryData").field("salary"));//将聚合条件加入到检索条件中builder.aggregation(aggregationBuilder);//只要聚合的结果,不需要查询的结果builder.size(0);searchRequest.source(builder);//执行检索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println("检索结果:" + searchResponse);
}
打印的结果如下,和预期要打印的结果是一致的
{"took":4,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":10,"relation":"eq"},"max_score":null,"hits":[]},"aggregations":{"sterms#jobData":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"java","doc_count":4,"stats#salaryData":{"count":4,"min":9000.0,"max":50000.0,"avg":25750.0,"sum":103000.0}},{"key":"c++","doc_count":2,"stats#salaryData":{"count":2,"min":20000.0,"max":20000.0,"avg":20000.0,"sum":40000.0}},{"key":"javascript","doc_count":2,"stats#salaryData":{"count":2,"min":18000.0,"max":25000.0,"avg":21500.0,"sum":43000.0}},{"key":"python","doc_count":2,"stats#salaryData":{"count":2,"min":18000.0,"max":35000.0,"avg":26500.0,"sum":53000.0}}]}}}
除了上面的state求全部的最大值,最小值等,还可以分别的求最大值,最小值,平均值,个数等,求平均值的的示例如下,需要使用到这个 AvgAggregationBuilder 构造器
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("salaryData").field("salary");
//将聚合条件加入到检索条件中
builder.aggregation(avgAggregationBuilder);
求最大值的示例如下,需要使用到这个 MaxAggregationBuilder 构造器
MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("maxData").field("salary");
//将聚合条件加入到检索条件中builder.aggregation(maxAggregationBuilder);
求最小值的示例如下,需要使用到这个 MinAggregationBuilder 构造器
MinAggregationBuilder minAggregationBuilder = AggregationBuilders.min("minData").field("salary");
//将聚合条件加入到检索条件中
builder.aggregation(minAggregationBuilder);
求总个数的示例如下,需要使用到这个 ValueCountAggregationBuilder 构造器
ValueCountAggregationBuilder countBuilder = AggregationBuilders.count("countData").field("salary");
//将聚合条件加入到检索条件中
builder.aggregation(countBuilder);
5.2,获取最终结果
上面在查询之后,会获取 SearchResponse 的对象,这里面就值执行查询后返回的结果
SearchResponse searchResponse
随后可以直接过滤结果,通过for循环去遍历这个 getHits
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {String sourceAsString = searchHit.getSourceAsString();Employees employees = JSON.parseObject(sourceAsString, Employees.class);System.out.println(employees);}
或者直接获取聚合操作结果的值
//获取jobData聚合。还有Avg、Max、Min等
Terms maxData = aggregations.get("jobData");
for (Terms.Bucket bucket : maxData.getBuckets()) {String keyAsString = bucket.getKeyAsString();System.out.println("job职业:" + keyAsString + " 数量==> " + bucket.getDocCount());
}
相关文章:
【ElasticSearch系列-05】SpringBoot整合elasticSearch
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

C/S架构学习之广播
广播:一台主机可以将一个数据包同时发送给同一局域网内所有主机;在IPV4中,广播地址是本网段最大的IP地址或者“255.255.255.255”;注意:广播本质上是UDP通信技术;只有用户数据报套接字才能使用广播的方式&a…...
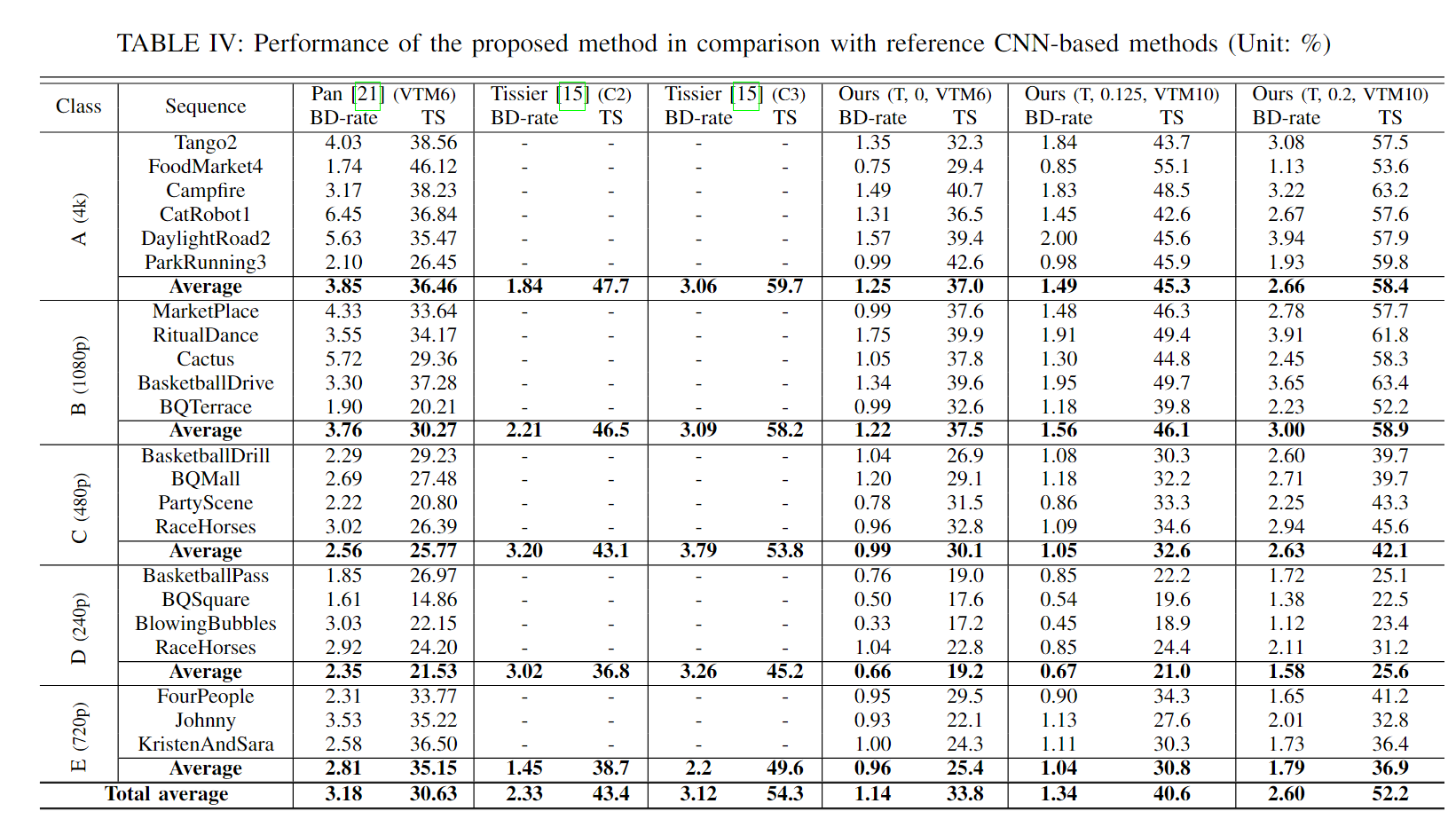
帧间快速算法论文阅读
Low complexity inter coding scheme for Versatile Video Coding (VVC) 通过分析相邻CU的编码区域,预测当前CU的编码区域,以终止不必要的分割模式。 𝐶𝑈1、𝐶𝑈2、𝐶𝑈3、&#x…...

mooc单元测验第一单元
TCP和OSI参考模型对比 OSI参考模型与TCP/IP参考模型(计算机网络)_osi模型 tcpip模型_李桥桉的博客-CSDN博客 会话层和物理层...
AOC显示器出问题了?别担心,简单重置一下就OK了
你的AOC显示器有问题吗?它是被卡在特定的屏幕上还是根本不显示任何图像?如果你的显示器出现任何问题,只需简单重置即可解决问题。 重置AOC显示器可以帮助解决一系列问题,例如颜色或显示设置问题、输入源检测问题以及其他与软件相…...
ok-解决qt5发布版本,直接运行exe缺少各种库的问题
已实验第二种方法可用。 工具:电脑必备、QT下的windeployqt Qt 官方开发环境使用的动态链接库方式,在发布生成的exe程序时,需要复制一大堆 dll,如果自己去复制dll,很可能丢三落四,导致exe在别的电脑里无法…...
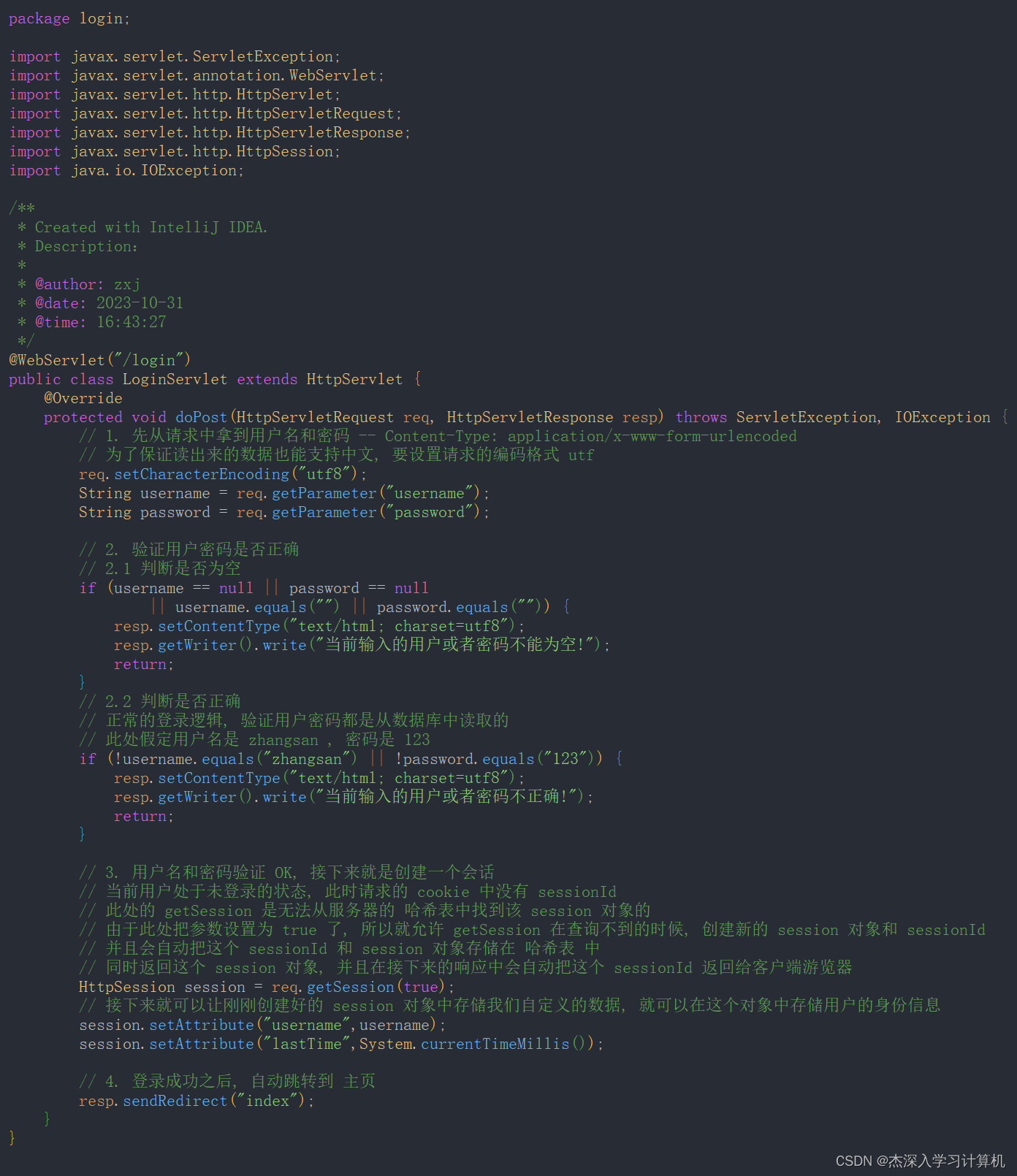
【JavaEE】cookie和session
cookie和session cookie什么是 cookieServlet 中使用 cookie相应的API Servlet 中使用 session 相应的 API代码示例: 实现用户登陆Cookie 和 Session 的区别总结 cookie 什么是 cookie cookie的数据从哪里来? 服务器返回给浏览器的 cookie的数据长什么样? cookie 中是键值对…...

关于CSS的几种字体悬浮的设置方法
关于CSS的几种字体悬浮的设置方法 1. 鼠标放上动态的2. 静态的(位置看上悬浮)2.1 参考QQ邮箱2.2 参考知乎 1. 鼠标放上动态的 效果如下: 代码如下: <!DOCTYPE html> <html lang"en"> <head><met…...
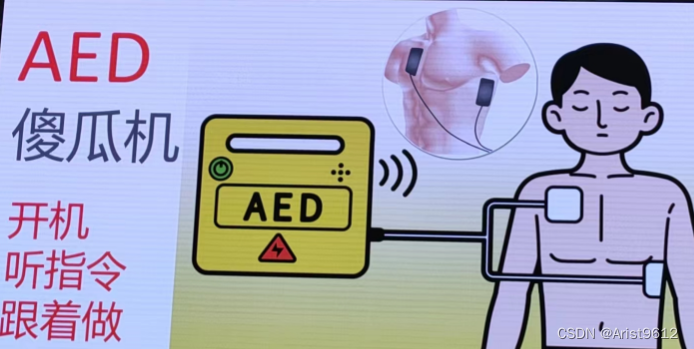
心脏骤停急救赋能
文章目录 0. 背景知识1. 遇到有人突然倒地怎么办1.1 应急反应系统1.2 高质量CPR1.2.1 胸外按压1.2.2 人工呼吸 1.3 AED除颤1.3.1 AED用法 1.4 高级心肺复苏1.5 入院治疗1.6 康复 0. 背景知识 中国每30s就有人倒地,他们可能是工作压力大的年轻人(工程师群…...

Android 13.0 根据app包名授予app监听系统通知权限
1.概述 在13.0的系统rom产品定制化开发中,在一些产品rom定制化开发中,系统内置的第三方app需要开启系统通知权限,然后可以在app中,监听系统所有通知,来做个通知中心的功能,所以需要授权获取系统通知的权限,然后来顺利的监听系统通知。来做系统通知的功能,接下来来实现…...
校园招聘系统
校园管理系统 公共模块学生端游客端企业联系人端校内管理员端超级管理员端企业端 公共模块 登录 用户可以通过验证码、账号密码进行登录。 个人中心 学生端 学生主要为查看招聘信息以及投递等。 首页 简历详情投递 双选会公司详情 公告通知 学生端主要为这些等等…...

SpringBoot-SpringCache缓存
文章目录 Spring Cache 介绍常用注解 Spring Cache 介绍 Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。 Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,…...
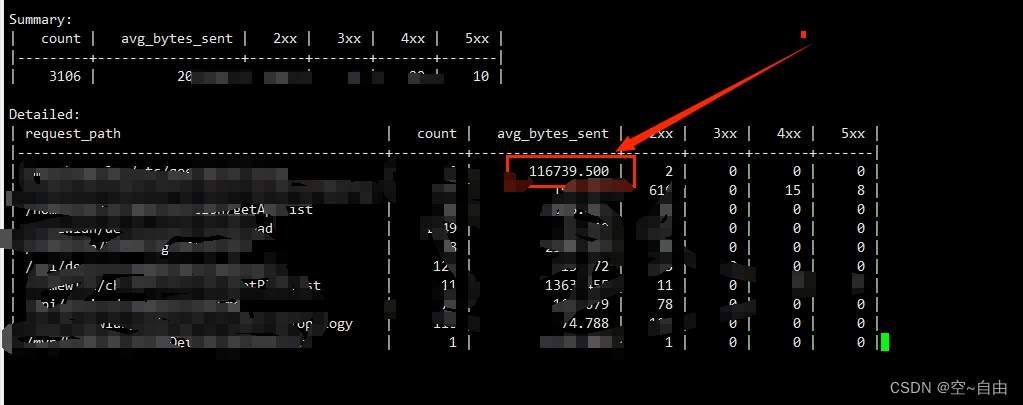
服务器带宽忽然暴增,不停的触发告警
问题: 线上环境,服务器的外网下行带宽达到某个阈值,触发告警,查了下服务器的带宽监控信息,是从某个时间开始突然串上去的,然后监控图形非常有规律,都是每秒达到顶峰后,又立马下去了…...

Linux学习笔记之二(环境变量)
Linux learning note 1、环境变量1.1、修好PATH环境变量 1、环境变量 环境变量(environment variables)即系统运行的一些环境参数。主要的环境变量有以下这些: PATH:决定了系统查找可执行文件的目录范围。HOME:指定当前用户的主目录路径。U…...
)
设计模式——备忘录模式(Memento Pattern)
文章目录 一、备忘录模式定义二、例子2.1 菜鸟例子2.1.1 定义副本类2.1.2 定义对象2.1.3 定义CareTaker 类2.1.3 使用 2.2 JDK —— Date 三、其他设计模式 一、备忘录模式定义 类型: 行为型模式 目的: 保存一个对象的某个状态,以便在适当的…...

C++ 代码实例:多项式除法简单计算工具
文章目录 前言代码仓库代码说明核心片段 结果总结参考资料作者的话 前言 C 代码实例:多项式除法简单计算工具。 代码仓库 yezhening/Programming-examples: 编程实例 (github.com)Programming-examples: 编程实例 (gitee.com) 代码 说明 由于代码篇幅较多&#…...

MySql表自修改报错:You can‘t specify target table ‘student‘ for update in FROM clause
文章目录 一、发现问题二、场景1:在where条件中查询了修改表的数据三、场景2:在set语句中查询了修改表的数据 一、发现问题 在一次准备处理历史数据sql时,出现这么一个问题:You cant specify target table 表名 for update in FR…...
LeetCode 热题100——链表专题
一、俩数相加 2.俩数相加(题目链接) 思路:这题题目首先要看懂,以示例1为例 即 342465807,而产生的新链表为7->0->8. 可以看成简单的从左向右,低位到高位的加法运算,4610,逢…...

植物花粉深度学习图片数据集大合集
最近收集了一波有关于植物花粉的图片数据集,可以用于相关深度学习模型的搭建,废话不多说,上数据集!!! 1、23种花粉类型805张花粉图像数据集 关于此数据:花粉种类和类型的分类是法医抱粉学、考…...
面试算法48:序列化和反序列化二叉树
题目 请设计一个算法将二叉树序列化成一个字符串,并能将该字符串反序列化出原来二叉树的算法。 分析 先考虑如何将二叉树序列化为一个字符串。需要逐个遍历二叉树的每个节点,每遍历到一个节点就将节点的值序列化到字符串中。以前序遍历的顺序遍历二叉…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...

MNE-Python 第9天学习笔记:源定位基础
一、什么是源定位? 1.1 通俗理解 到目前为止,我们分析的是"头皮上的脑电":头皮电极 → 记录头皮表面的电位↓这就像在地球表面测量地震波我们想知道的是:震源在哪里?多深?源定位 从头皮电位反推…...

终极Windows键盘重映射解决方案:SharpKeys完全指南
终极Windows键盘重映射解决方案:SharpKeys完全指南 【免费下载链接】sharpkeys SharpKeys is a utility that manages a Registry key that allows Windows to remap one key to any other key. 项目地址: https://gitcode.com/gh_mirrors/sh/sharpkeys 还在…...