[pytorch]手动构建一个神经网络并且训练
0.写在前面
上一篇博客全都是说明类型的,实际代码能不能跑起来两说,谨慎观看.本文中直接使用fashions数据实现softmax的简单训练并且完成结果输出.实现一个预测并且观测到输出结果.
并且更重要的是,在这里对一些训练的过程,数据的形式,以及我们在softmax中主要做什么以及怎么做来进行说明.
前提要求:一些数据包的需求先写在这里了,根据pip3进行按照需求下载即可
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
import pandas
from torch import nn
1.对于数据的下载以及处理
(1)数据的下载:
首先对于数据的下载,这里我们选择的方式是直接在都d2l环境下(D2L是什么请自行进行百度),下载这个名为fashions的数据集合.
#这个就是下载数据集合了,这里获取到了数据集合并且放到内存里面
d2l.use_svg_display()数据下载以后应该是在我们自己的内存里面,在这里我指定的是./data,不同的人大概是不同的目录,请自行参考.
然后接下来对数据进行处理,这个数据集合是一个PIL形式,在这里我们需要把每个图像转化为浮点数形式,这里有个很重要的函数dataset,他可以理解为一种容器,一般是以一个二维数组的方式来存储我们的数据.
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)mnist_train和mnist_test都是我们俗称的一个dataset对象,故名思意,就算数据集合.
虽然这个东西并不是二维数组,但是我们可以使用二维数组的方式进行读取
mnist_train是一个dataset对象,是一个[n,2]形状的二维数组
举个例子[0][0]为一个1×28×28的图像张量,也就是我们的输入input
print(mnist_train[0][1]) label就是一个单独的数字,在这个数据中是一个数字,或者说标量张量
如果我们在python中输出,效果就是这样子的
print(mnist_train[0][0].shape) #Tensor.Size([1,28,28])
print(mnist_train[0][1]) #Tensor(9)#这里需要注意到的问题后面都会解释到位(2)数据的处理
数据的处理其实我们要考虑到两个方面进行处理,一个用来训练的时候,我们需要把这东西转化为张量的形式,而且更重要的是我们不可能一次性投入这么多数据(提示一下,虽然fashion数据集合只有60000条,但是这个想法很重要),主要是在计算损失的时候,要保证低耦合度,一次性寻找适量数目的数据(这个将会在后面有补充)
其次就是,我们需要对整体的情况有一个总览,所以说我们要根据数据的整体计算一个损失,但是问题是dataset对象并不是张量,我们需要对其进行一些简单的处理;
那么首先是第一条:如何对数据进行读取,这也是我们进行遍历训练的时候需要做的事情,这里我们需要知道的另一个很重要的对象dataloader,这个东西吧dataset对象分成多个批次,然后设置成一个迭代器对象,如图所示
batch_size=256
train_iter=data.DataLoader(mnist_train,batch_size=256,shuffle=True,num_workers=4) #将这个数据集划分为256一打,洗牌模式随机抽取,四个线程进行读取
test_iter=data.DataLoader(mnist_test,batch_size=256,shuffle=True,num_workers=4) # 这样就生成一个类似迭代器的东西了,使用for循环可以进行读取
这个iter明显就是一个迭代的意思,很简单,但是有个问题,据我所知这个东西只能for循环来进行读取
如果我们强还行print,那么啥都得不到
print(train_iter)
#dataloader所产生的数据可以使用for循环来进行获取,也只能使用for循环才能得到对象正确的读取方法应该是这样子的,通过这样的方法进行读取数据,这样子能保证每次返回的都是一批张量
for features,labels in train_iter:print(features,labels)在这里需要单独说明,首先我们之前设定为批次是256,并且feature是一个三维张量,label是一个常量张量(注意常量张量和向量张量是完全不同的两个东西),所以这里print出来的张量应该是这两个形状的东西
[256,1,28,28]
[256,1]批次在这里的体现就是,我们把256个作为一个批次,然后合并在一起.
可能你就要问了,唉,256这个多出来的维度不影响训练吗,问题不大吗,因为神经网络有自己的处理方法
-----------------------------------------------
另一个需要处理的数据其实就是整体,毕竟我们后面需要用损失函数计算一个整体的估计情况,来确定一个总的训练效果.
这里就没什么奇怪的东西了,需要手动操作,把从mnist_train和muist_test中遍历出来的数据转化出来,变成一个我们能接受的张量的性质
#使用方法把完整的数据集合改成张量
# 定义空的张量用于存储输入和输出
inputs = []
outputs = []# 遍历数据集的每个样本
for sample in mnist_train:image = sample[0] # 图像数据label = sample[1] # 标签数据# 将图像数据和标签数据分别添加到张量中inputs.append(image)outputs.append(label)# 将列表转换为张量对象
inputs = torch.stack(inputs)
outputs = torch.tensor(outputs)# 打印张量的形状,这里一共检测到60000个数据
print("输入张量的形状",inputs.shape) # 输入张量的形状
print("输出张量的形状",outputs.shape) # 输出张量的形状至于这两个东西后面怎么用,我们后面会详细解释
2.关于神经网络的构建
(1)大致构建以及对于数据的处理
首先是我们在这个代码中构建的神经网络的大致结构
net=nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10),nn.Softmax(dim=1)
)
先解释一下神经网络是干什么的,在这个神经网络中,首先使用一个Flatten对于张量进行展平,展平的效果就是这样子的,
[256,1,28,28] => [256,784]然后经过两个密集层,就变成了
[256,10]=====>内部大致的结构如下:
0:[1,2,3,4,5,6,7,8,9,10]
1:[1,2,3,4,5,6,7,8,9,10]
..........
255:[1,2,3,4,5,6,7,8,9,10]最后softmax函数在这里我们就不加解释了,在这里我们注明了dim=1.也就是沿着行的生长方向进行softmax归一化操作
0:[0.1,0.3,............]
1:[0.4,................]
2:[....................]
.............
当然这里很容易遇到两个问题:首先是第一个,我们的数据是被绑定成了一个巨大的张量,把256个数据绑定在了一起,这也就是我们想要在这里说明的事情.
首先是第一点,前向传播这个过程中,我们可以很清楚的看到(事实上你对於每个层进行这种操作也会发现一个肥肠类似的结果)对于一个层{linear([256,10])}来说,如果我们传入的是Size=[60000,256]这样的一个尺寸的张量 , 则我们可以得到一个向前传播的计算结果[60000,10], 仅仅是对最后一个维度实现了神经元上的收敛,别的好像没什么.
这是因为神经网络的一个重要特性,在代码中我们经常是按照批次来传入的,这就要求批次处理好数量.因此pytorch中秉持的原则就是,在向前传播的时候,只对最后一层的维度进行计算.
然后是第二点,可以看到在传入的时候把数据传输为一个[256,1,28,28]的部分,第一步我们进行的是一个展平的操作,但是要注意的一点是,我们对某个层进行单独的操作以后,可以看到最终在内部进行输出结果的是[256,784].因为flatten这个展平,永远不会操作第一个维度
所以综上所述我们可以看到一个东西,net对批量数据的操作其实是依赖于一些层和函数本身的性质/数学运算,而不是net的刻意的准备.这样我们就结合矩阵运算,实现了一个批量计算
(2)关于权重的配置
首先要说明一点,对于这种神经网络初始化权重的方法有很多,可以直接对某一层的属性进行访问和配置.当然我们更多是借用神经网络对象的apply函数.
#但是这里首先也需要初始化一下 nn.init.normal_(m.weight, std=0.01),这个是比较重要的初始化吧
def init(m):if type(m)==nn.Linear:nn.init.normal_(m.weight,std=0.1)nn.init.constant_(m.bias,0.1)#apply函数会保证每个层都能用的上这个初始化函数
net.apply(init)其中,apply自动会对每个层都执行一遍这个函数.只要我们判断出这一层是神经网络层,就进行这种操作
init.normal_主要用来给权重初始随机数值
init.constant_是给权重一个固定数值
(3)关于一些其他函数的配置
首先是训练函数,也就是迭代器,我们使用随机梯度下降的函数,并且传入net的参数
#训练函数
train = torch.optim.SGD(net.parameters(), lr=0.03) 然后是损失计算函数,损失计算函数其实是可以自己进行编写的,但是写好了为啥不用
监狱我们使用softmax进行一个数据的计算,所以这里我们使用"交叉熵损失函数"
这个函数大致的原理:
softmax这种分类问题最好用到别的损失函数,比如交叉商损失函数nn.CrossEntropyLoss(reduction='none')
这里解释一下输入 [0.7,0.2,0.1],[0.1,0.1,0.8] (每种可能性标签的概率) 和标签[0,2](真实的标签应该是什么),然后这个函数会返回一个张量形式的东西
这个公式其实是整理过一次了,在之前写过的csdn里面,这里的计算结果就是
1×log(0.7)+ 0×log(0.2)+ 0*log(0.1),以及
0×log(0.1)+ 0×log(0.2)+ 1*log(0.8),这两个元素,形成一维张量
其公式是这样子的,对于第c个输入和输出数据,假设其中第i个标签为真实的,并且对这个标签的预测概率为yci, 则这个数据的损失是
则对于总的这一批数据n,我们需要取平均值,就能找到其cost,这个在这里就不演示了
(4)模式
在开始训练之前,net对象其实存在有两个模式
net.train() # 训练模式
net.eval() #评估模式训练模式会存储梯度,而评估模式不会存储,也就是对应了一个用来训练一个用来评估
3.训练过程,数据处理
其实训练过程都是大同小异:计算损失,清除梯度,计算梯度,更新四步,如果有需要,可以对每一个循环增加的时候进行检查loss
epoch_num=10
for epoch in range(epoch_num):for X,y in train_iter:l=loss(net(X),y).mean() train.zero_grad()l.backward() train.step()l=loss(net(inputs),outputs)print(f'epoch {epoch + 1}, loss {l.mean():f}')对于这里就要注意两点
(1)不同的loss对于输入和输出的要求是不一样的.比如交叉熵损失函数要求的输入和输出分别是:
举个例子
[0.7,0.2,0.1],[0.1,0.1,0.8] (每种可能性标签的概率) 和标签[0,2](真实的标签应该是什么),然后这个函数会返回一个张量形式的东西
但是对于MSLoss这种损失函数,我们得到的结果则完全不一样,输入和输出都是同样尺寸的一维数组,然后直接计算出一个纳米孔数据.
(2)反向传播只能针对一个数字的标量张量计算,这也就是我们使用mean和sum这种函数压缩计算得到的结果.
4.一点小小的总结和完整代码
一点简单的小小总结:
1.首先是关于net:
net可以接受小批量,甚至是一个完整那个的数据list的输入的,也就是说我们传入的小批量其实是[256,1,28,28]
然后我们最终的输出结果为[256,1],虽然这不是我们要的东西
其实net本质就是一个张量处理机,’压缩‘成需要的格式
张量处理机:一开是的猜测是会根据批量逐一处理那些张量,但是事实是net本身并不会对其进行太多的区分
传入进来的仍然是一个整体张良,需要在net中自己操作dim得到需要的结果以及形式
而且那个自定义层因为没有可训练的参数,所以可能不被接受?因此在训练的过程中,loss没有发生任何变化
另外注意一个问题,Fattern是无法展平dim=0这个维度的,这也就是为什么小批量的size保持了稳定
2.还有一个问题,其实在计算的时候大多问题就出在loss上面,这个函数计算误差的时候,最基本的要求就是输入和输出是同一个形式的,比如这里
loss希望net(x)和y都是长度一样的Size[256],然后自动进行sum计算,但是因为第一层无法折叠,所以net(x)为[256,1],所以我们在loss计算的时候就是用reshape([-1])来进行处理
很多时候都是这样的问题,所以要进行一点处理
3.在估算整体误差的时候要转化成张量,这里用函数处理成张量
这个有点复杂,但是记住net只是一个tensor压缩机
4.dataset对象是可以通过二维数组的方法获取标签和数据
dataloader可以转化为一个迭代器iter,迭代器通过for循环(或许有别的手段)得到的是小批量数据,而且是张量格式
5.最后就是lr记得小一点,不然就爆炸了
爆炸以后直接nan,我做梦都没想到在js没踩过的坑,在这里实现了,这是因为最开始梯度设置为0.5太大而导致的
6.另外记住两个初始化函数,用来给某个层初始化权重的
nn.init.normal_(m.weight,std=0.1) 用来随机赋值,一般是w
nn.init.constant_(m.bias,0.1) 用来常量赋值,一般是b
7.最后总结一下这段流程
神经网络构建(sequential)===》参数设置(使用方法,然后对模型apply)===》损失函数设置(使用库函数即可)===》优化函数设置(传入net的参数parameter)===》训练
训练就是:计算损失===》梯度清零以后进行反响传播计算===》执行优化迭代
数据就是:从文件中读取dataset对象(这个对象是保存了数据[][]),然后使用dataloader获取可以用来训练的迭代器
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
import pandas
from torch import nn#这个就是下载数据集合了,这里获取到了数据集合并且放到内存里面
d2l.use_svg_display()# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)batch_size=256
train_iter=data.DataLoader(mnist_train,batch_size=256,shuffle=True,num_workers=4) #将这个数据集划分为256一打,洗牌模式随机抽取,四个线程进行读取
test_iter=data.DataLoader(mnist_test,batch_size=256,shuffle=True,num_workers=4) # 这样就生成一个类似迭代器的东西了,使用for循环可以进行读取
print(train_iter)net=nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10),nn.Softmax(dim=1)#先用softmax处理一下
)# 得出结论,展平层永远对最开始的一层都不起效果#所以上面那一层的问题就是:我们期待的输出是[256],而不是[256,1]#神经元先设定为训练模式
net.train()#损失函数
#loss = nn.MSELoss()
loss = nn.CrossEntropyLoss(reduction='none')#但是这里首先也需要初始化一下 nn.init.normal_(m.weight, std=0.01),这个是比较重要的初始化吧
def init(m):if type(m)==nn.Linear:nn.init.normal_(m.weight,std=0.1)nn.init.constant_(m.bias,0.1)#apply函数会保证每个层都能用的上这个初始化函数
net.apply(init)#训练函数
train = torch.optim.SGD(net.parameters(), lr=0.03) #使用方法把完整的数据集合改成张量
# 定义空的张量用于存储输入和输出
inputs = []
outputs = []# 遍历数据集的每个样本
for sample in mnist_train:image = sample[0] # 图像数据label = sample[1] # 标签数据# 将图像数据和标签数据分别添加到张量中inputs.append(image)outputs.append(label)# 将列表转换为张量对象
inputs = torch.stack(inputs)
outputs = torch.tensor(outputs)# 打印张量的形状,这里一共检测到60000个数据
print("输入张量的形状",inputs.shape) # 输入张量的形状
print("输出张量的形状",outputs.shape) # 输出张量的形状epoch_num=10
for epoch in range(epoch_num):for X,y in train_iter: l=loss(net(X),y).mean() train.zero_grad()l.backward() train.step()l=loss(net(inputs),outputs)print(f'epoch {epoch + 1}, loss {l.mean():f}')#然后把模型切换为评估模式
net.eval()相关文章:
[pytorch]手动构建一个神经网络并且训练
0.写在前面 上一篇博客全都是说明类型的,实际代码能不能跑起来两说,谨慎观看.本文中直接使用fashions数据实现softmax的简单训练并且完成结果输出.实现一个预测并且观测到输出结果. 并且更重要的是,在这里对一些训练的过程,数据的形式,以及我们在softmax中主要做什么以及怎么…...

马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文!
本文原文来自DataLearnerAI官方网站: 马斯克的X.AI平台即将发布的大模型Grōk AI有哪些能力?新消息泄露该模型支持2.5万个字符上下文! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699114783001 马斯克透露xAI…...

spring-session-core排除某些接口不设置session
这里写自定义目录标题 需求实现 需求 今天先写一下如何实现,之后再更新一篇如何发现这个问题的。 我们的项目使用了spring-session-core来存储共享session,存在redis中,然后在cookie中是设置了key为SESSION的session。但是我们有一些开放接口…...
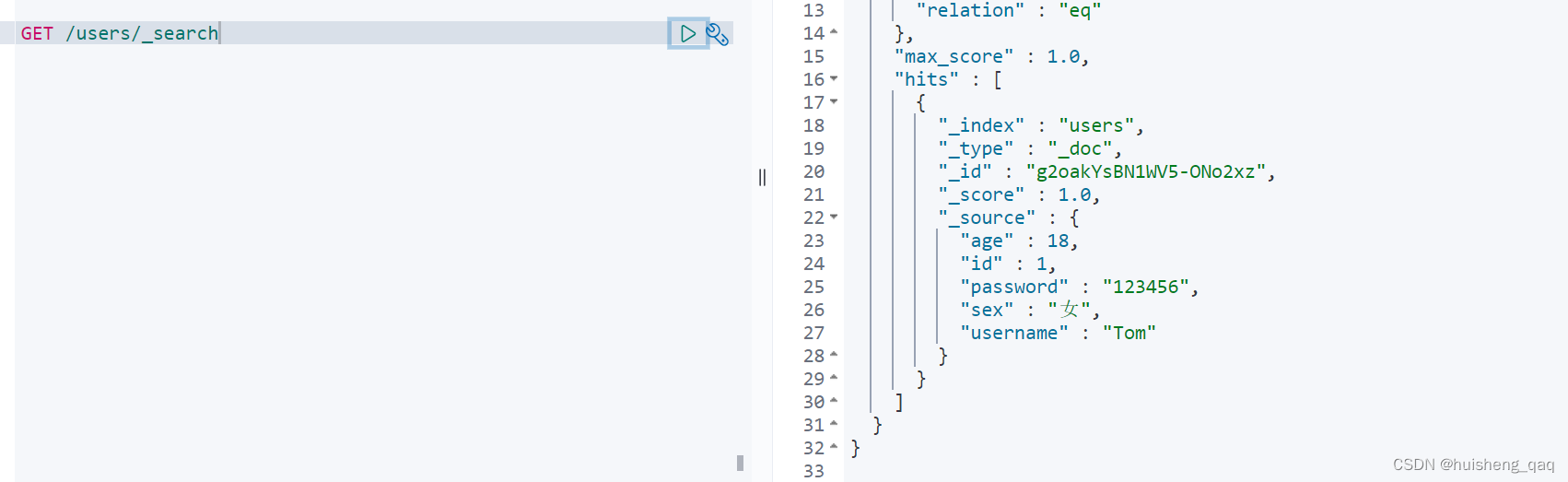
【ElasticSearch系列-05】SpringBoot整合elasticSearch
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

C/S架构学习之广播
广播:一台主机可以将一个数据包同时发送给同一局域网内所有主机;在IPV4中,广播地址是本网段最大的IP地址或者“255.255.255.255”;注意:广播本质上是UDP通信技术;只有用户数据报套接字才能使用广播的方式&a…...
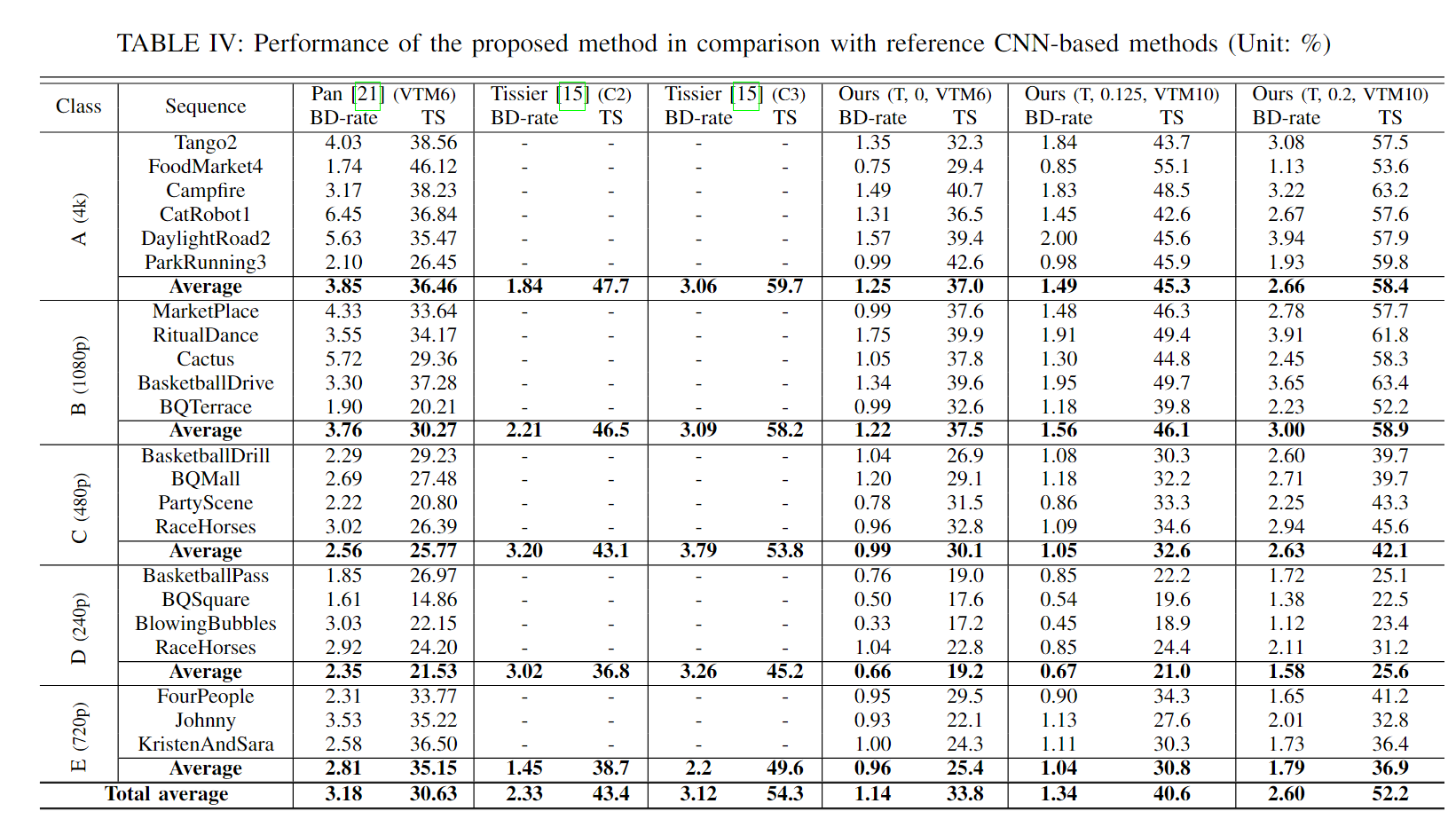
帧间快速算法论文阅读
Low complexity inter coding scheme for Versatile Video Coding (VVC) 通过分析相邻CU的编码区域,预测当前CU的编码区域,以终止不必要的分割模式。 𝐶𝑈1、𝐶𝑈2、𝐶𝑈3、&#x…...

mooc单元测验第一单元
TCP和OSI参考模型对比 OSI参考模型与TCP/IP参考模型(计算机网络)_osi模型 tcpip模型_李桥桉的博客-CSDN博客 会话层和物理层...
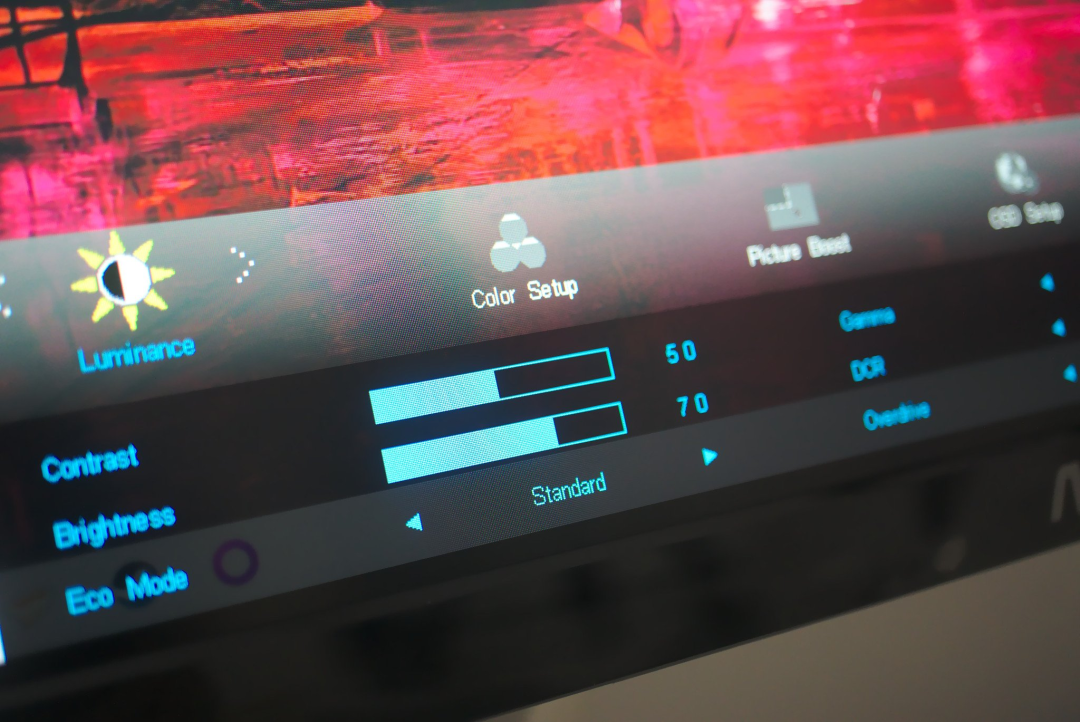
AOC显示器出问题了?别担心,简单重置一下就OK了
你的AOC显示器有问题吗?它是被卡在特定的屏幕上还是根本不显示任何图像?如果你的显示器出现任何问题,只需简单重置即可解决问题。 重置AOC显示器可以帮助解决一系列问题,例如颜色或显示设置问题、输入源检测问题以及其他与软件相…...
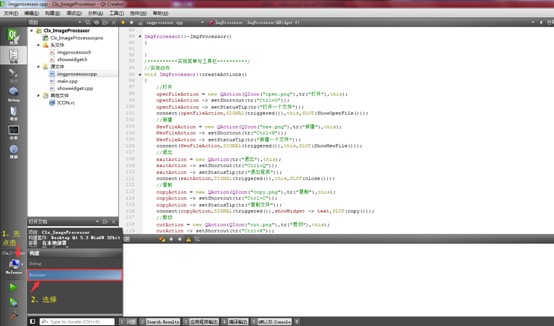
ok-解决qt5发布版本,直接运行exe缺少各种库的问题
已实验第二种方法可用。 工具:电脑必备、QT下的windeployqt Qt 官方开发环境使用的动态链接库方式,在发布生成的exe程序时,需要复制一大堆 dll,如果自己去复制dll,很可能丢三落四,导致exe在别的电脑里无法…...
【JavaEE】cookie和session
cookie和session cookie什么是 cookieServlet 中使用 cookie相应的API Servlet 中使用 session 相应的 API代码示例: 实现用户登陆Cookie 和 Session 的区别总结 cookie 什么是 cookie cookie的数据从哪里来? 服务器返回给浏览器的 cookie的数据长什么样? cookie 中是键值对…...

关于CSS的几种字体悬浮的设置方法
关于CSS的几种字体悬浮的设置方法 1. 鼠标放上动态的2. 静态的(位置看上悬浮)2.1 参考QQ邮箱2.2 参考知乎 1. 鼠标放上动态的 效果如下: 代码如下: <!DOCTYPE html> <html lang"en"> <head><met…...
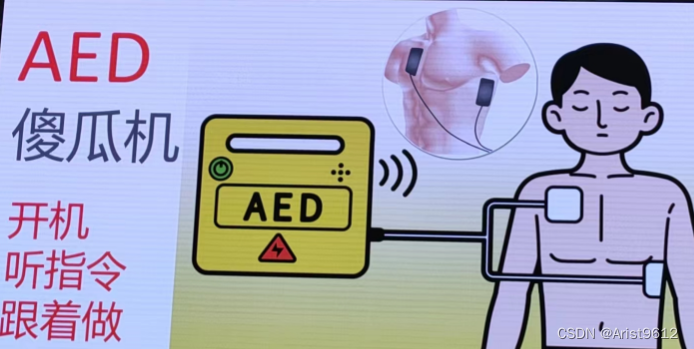
心脏骤停急救赋能
文章目录 0. 背景知识1. 遇到有人突然倒地怎么办1.1 应急反应系统1.2 高质量CPR1.2.1 胸外按压1.2.2 人工呼吸 1.3 AED除颤1.3.1 AED用法 1.4 高级心肺复苏1.5 入院治疗1.6 康复 0. 背景知识 中国每30s就有人倒地,他们可能是工作压力大的年轻人(工程师群…...

Android 13.0 根据app包名授予app监听系统通知权限
1.概述 在13.0的系统rom产品定制化开发中,在一些产品rom定制化开发中,系统内置的第三方app需要开启系统通知权限,然后可以在app中,监听系统所有通知,来做个通知中心的功能,所以需要授权获取系统通知的权限,然后来顺利的监听系统通知。来做系统通知的功能,接下来来实现…...
校园招聘系统
校园管理系统 公共模块学生端游客端企业联系人端校内管理员端超级管理员端企业端 公共模块 登录 用户可以通过验证码、账号密码进行登录。 个人中心 学生端 学生主要为查看招聘信息以及投递等。 首页 简历详情投递 双选会公司详情 公告通知 学生端主要为这些等等…...

SpringBoot-SpringCache缓存
文章目录 Spring Cache 介绍常用注解 Spring Cache 介绍 Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。 Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,…...
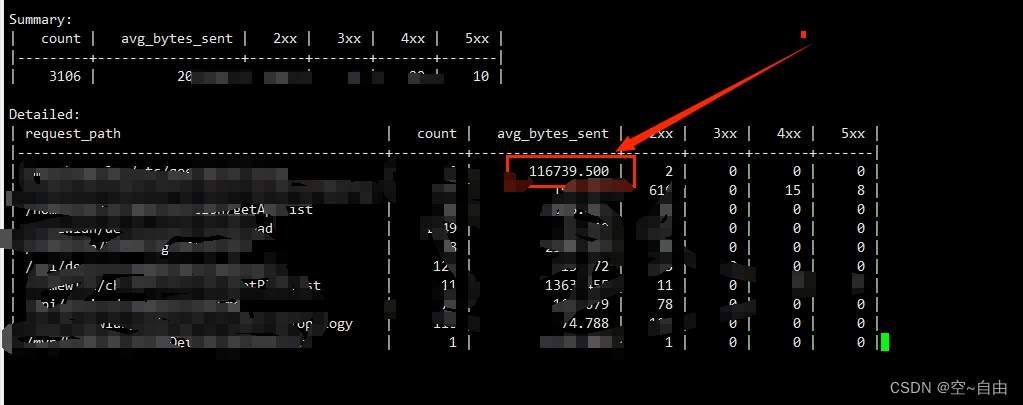
服务器带宽忽然暴增,不停的触发告警
问题: 线上环境,服务器的外网下行带宽达到某个阈值,触发告警,查了下服务器的带宽监控信息,是从某个时间开始突然串上去的,然后监控图形非常有规律,都是每秒达到顶峰后,又立马下去了…...

Linux学习笔记之二(环境变量)
Linux learning note 1、环境变量1.1、修好PATH环境变量 1、环境变量 环境变量(environment variables)即系统运行的一些环境参数。主要的环境变量有以下这些: PATH:决定了系统查找可执行文件的目录范围。HOME:指定当前用户的主目录路径。U…...
)
设计模式——备忘录模式(Memento Pattern)
文章目录 一、备忘录模式定义二、例子2.1 菜鸟例子2.1.1 定义副本类2.1.2 定义对象2.1.3 定义CareTaker 类2.1.3 使用 2.2 JDK —— Date 三、其他设计模式 一、备忘录模式定义 类型: 行为型模式 目的: 保存一个对象的某个状态,以便在适当的…...

C++ 代码实例:多项式除法简单计算工具
文章目录 前言代码仓库代码说明核心片段 结果总结参考资料作者的话 前言 C 代码实例:多项式除法简单计算工具。 代码仓库 yezhening/Programming-examples: 编程实例 (github.com)Programming-examples: 编程实例 (gitee.com) 代码 说明 由于代码篇幅较多&#…...

MySql表自修改报错:You can‘t specify target table ‘student‘ for update in FROM clause
文章目录 一、发现问题二、场景1:在where条件中查询了修改表的数据三、场景2:在set语句中查询了修改表的数据 一、发现问题 在一次准备处理历史数据sql时,出现这么一个问题:You cant specify target table 表名 for update in FR…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...

如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南
如何在浏览器中一键解密所有加密音乐文件:Unlock-Music完全指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

03 - 变量与数据类型
03 - 变量与数据类型 变量是编程里最基础的概念,相当于你往电脑里存东西的"容器"。这章我们把变量的命名规则、Python 的几种基本数据类型都过一遍。 变量是什么 说白了,变量就是一个有名字的盒子。你往里面放个东西,以后想用这个…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...