图及谱聚类商圈聚类中的应用
背景
在O2O业务场景中,有商圈的概念,商圈是业务运营的单元,有对应的商户BD负责人以及配送运力负责任。这些商圈通常是一定地理围栏构成的区域,区域内包括商户和用户,商圈和商圈之间就通常以道路、河流等围栏进行分隔。
对某些业务应用,商圈可能太小,需要将几个到十几个商圈划成一片,按商圈片进行运营。这类划分通常无法纯粹按照商圈地理位置来划分,因为商圈是一个连着一个的。因此,还需要找到商圈之间的其他关联指标,从业务上来说,如果两个商圈的用户重合度很高(比如A商圈中的80%的用户也是B商圈的用户,反之亦然)或者两个商圈的配送运力重合度和高(比如A商圈中的80%的骑手也是B商圈的骑手),那么这两个商圈可以划成一类,因此,用户、配送运力重合度都可以作为商圈之间的关联指标。
本文介绍了一种使用谱聚类对商圈进行聚类的方法。
商圈之间关系图构造
把商圈和商圈之间的联系构造为图,具体为:每个商圈是图中的节点,商圈和商圈之间共享用户数占比或者运力占比作为图的边,就可以得到一个城市所有商圈两两之间关系图。
比如,商圈之间的关系数据如下:
| 商圈-source | 商圈-target | 商圈关联指标-weight |
| 73***8 | 9***7 | 71.3% |
| 73***8 | 9***1 | 70.1% |
| 73***8 | 1***51 | 66.2% |
| 73***8 | ... | ... |
| 73***8 | 1***27 | 0.6% |
| 73***8 | 1***95 | 0.6% |
| 73***8 | 7***0 | 0.6% |
使用networkx可以将上述数据转化为关系图。networkx是Python的一个包,用于构建和操作复杂的图结构,提供分析图的算法。图是由顶点、边和可选的属性构成的数据结构,顶点表示数据,边是由两个顶点唯一确定的,表示两个顶点之间的关系。
对于networkx创建的无向图,允许一条边的两个顶点是相同的,即允许出现自循环,但是不允许两个顶点之间存在多条边,即出现平行边。边和顶点都可以有自定义的属性,属性称作边和顶点的数据,每一个属性都是一个Key:Value对。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx# 从数据构造图
g = nx.Graph()
g.add_weighted_edges_from(df_cluster.values)# 图可视化方法一
nx.draw(g, with_labels = True) ### 画可视化方法二
durations = [i['weight'] for i in dict(g.edges).values()]
labels = {i:i for i in dict(g.nodes).keys()}fig, ax = plt.subplots(figsize=(10,6))
pos = nx.spring_layout(g)
nx.draw_networkx_nodes(g, pos, ax = ax, label = True)
nx.draw_networkx_edges(g, pos, width = durations, ax = ax)
_ = nx.draw_networkx_labels(g, pos, labels, ax = ax)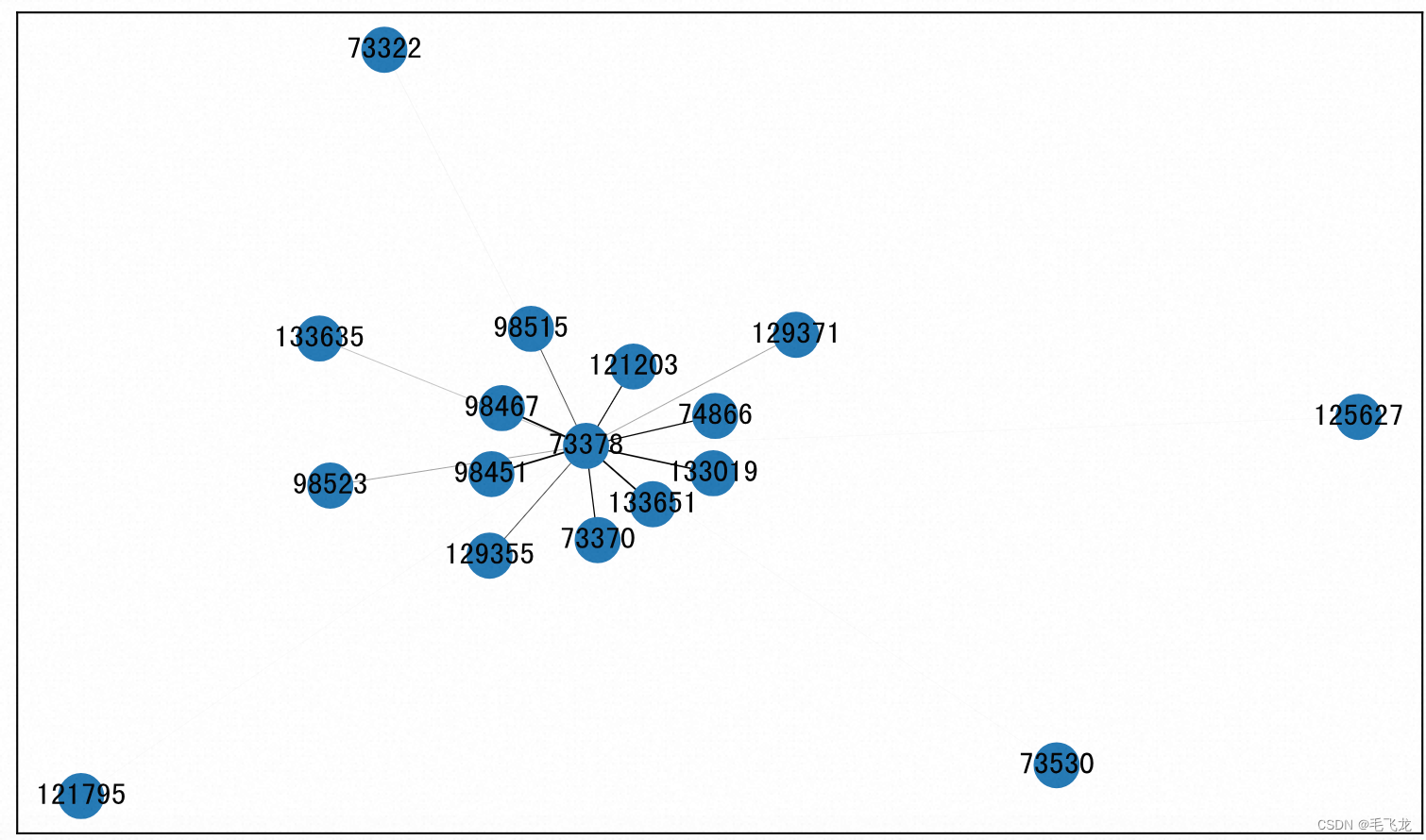
商圈聚类
基本思想
这里使用谱聚类的方法。谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。如果把这些连线加上一个权重,就叫做加权图。
如果连线越长则权重越小,连线越短则权重越大,然后把权重最小的边切断,使得一个图变成两个图,便完成了一次聚类,这就是谱算法的基本思路,而其基本流程,就是构图->切图。
所以,问题来了,如何构图?若将所有的点都连接起来,这显然有些离谱,毕竟这种平方级别的复杂度不是一般内存能吃得消的,作为有一点聚类基础的人,第一时间就会想到KNN算法,即k近邻。
由于谱聚类中,两个点是否要被切断,最关键的因素是短边而非长边,所以只要将点与其最近的k个点连接起来就行了。这样得到的图有一个问题,即x最近的k个点中可能有y,但y最近的k个点中可能没有x,像极了女神和你。
对此有两种解决方案,一种是x也不要y了,另一种是强制让x加入到y的近邻中。
除了k近邻之外,还可以定死一个距离r,凡是距离小于r的都连线,大于r的都不连线。由于点和点之间的距离往往相差较大,故其权重一般会在距离的基础上做一些变换,这个变换在下文乘坐权重函数。
数据转换
这里使用sklearn.cluster.SpectralClustering进行聚类,需要将图g的数据转换为sklearn.cluster.SpectralClustering输入的形式,可以通过临接矩阵来实现。
from sklearn.cluster import SpectralClustering# 得到图的邻接矩阵
adj_matrix = nx.adjacency_matrix(g) # 将节点之间的边信息转换为矩阵的形式,比如matrix[0]表示第1个样本和其他样本之间的关联信息# 可以用nx.adjacency_matrix(g).todense()看邻接矩阵的具体内容nx.adjacency_matrix(g).todense()[0]matrix([[0. , 0.10247934, 0.10582011, 0.27272727, 0.41962422,0.01342282, 0.0210728 , 0.0075188 , 0.48453608, 0.4038055 ,0.04 , 0.43896104, 0.0528109 , 0.00930233, 0.02754821,0.00704225, 0.14554795, 0.03125 , 0.03814714, 0.03878116,0.36616162, 0.0083682 , 0.008 , 0.00487805, 0.12539185,0. , 0. , 0. , 0. , 0. ,0. , 0. , 0. , 0. , 0. ,0. , 0. , 0. , 0. , 0. ,0. , 0. , 0. , 0. , 0. ,0. , 0. , 0. , 0. , 0. ,0. , 0. , 0. , 0. , 0. ,0. , 0. ]])聚类
# 调用谱聚类模型
sc_model = SpectralClustering(n_clusters=3, # 非常重要的超参数affinity='precomputed',assign_labels='discretize', random_state=0)
clustering = sc_model.fit(adj_matrix)# 聚类结果
print(clustering.labels_)[2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0 0 1 1 2 1 2 1 1 1 1 2 1 2 2 2 2 2 2 22 2 2 2 2 2 2 2 2 2 2 2 2 2 0 0 2 2 2 2 2 2 2 2 2 0 0 2 0 2 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 2 2 2 2 2 0 2 2 22 1 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 2 0]注意,上述聚类结果中对于模型的超参数n_clusters,我们直接设置成了3,这是非常随意的。如果事前没有聚类数的目标期望,一般我们可以尝试不同的的聚类数,然后基于一定的评估标准(此处选择轮廓分),选择最好的聚类数进行聚类。
from sklearn import metrics# 设置不同的聚类数超参数,通过轮廓分评估标准选择最佳聚类数n_clusters_list=[2,3,4,5,6,8,10,12,14,16,18,20]
score_list=[]
for k in n_clusters_list:sc_model = SpectralClustering(n_clusters=k, affinity='precomputed',assign_labels='discretize', random_state=0)clustering = sc_model.fit(adj_matrix)pred_y=sc_model.fit_predict(adj_matrix)score=metrics.silhouette_score(adj_matrix,pred_y)score_list.append(score)plt.xlabel("n_clusters")
plt.ylabel("silhouette_score")
plt.scatter(x = n_clusters_list, y = score_list)
plt.show()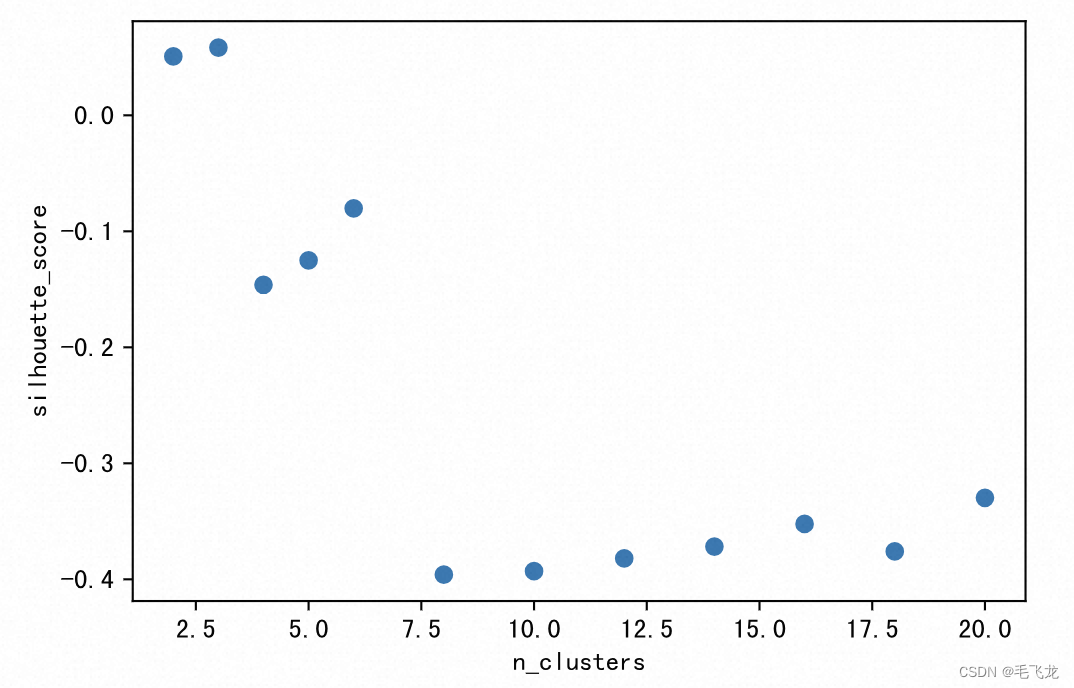
可见,本例中n_clusters = 3的轮廓分最高,因此我们可以设置聚类数为3。
结果展示
如果有商圈围栏的经纬度坐标数据,则可以使用keplergl来查看聚类后的效果。
# 聚类结果可视化check
import keplergl
amap = keplergl.KeplerGl(height = 800)
amap.add_data(data = df['scope_geojson','center_lng','center_lat','cluster_label'])
amap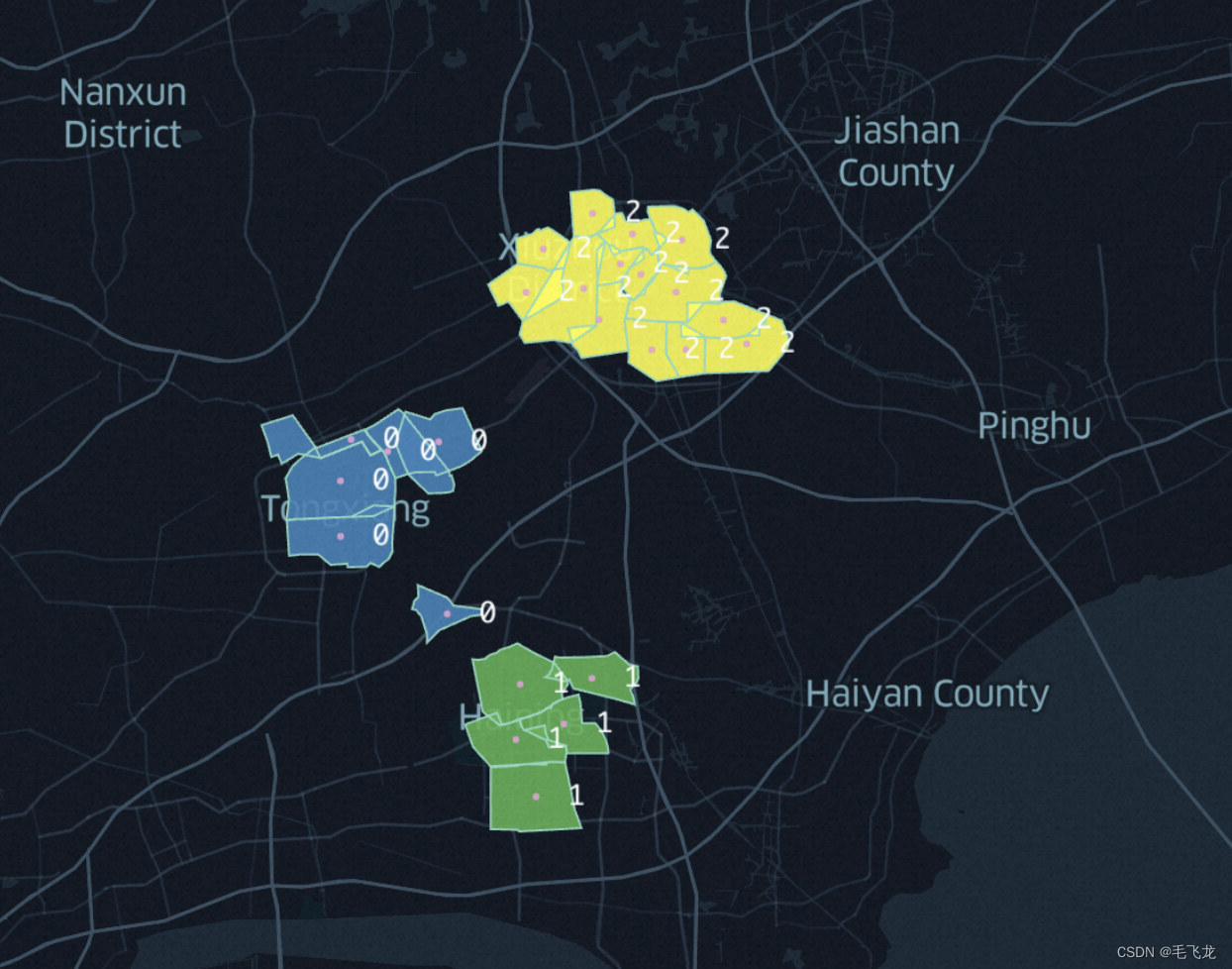
相关文章:
图及谱聚类商圈聚类中的应用
背景 在O2O业务场景中,有商圈的概念,商圈是业务运营的单元,有对应的商户BD负责人以及配送运力负责任。这些商圈通常是一定地理围栏构成的区域,区域内包括商户和用户,商圈和商圈之间就通常以道路、河流等围栏进行分隔。…...

npx 和 npm 区别
文章目录 背景作用执行流程 背景 解决 npm 之前的执行包中的命令行需要先下载的问题,如果有多个不同版本的包就需要下载多次比如已经装了全局的 webpack 1.x 版本并且还要继续使用,还需要装个 webpack 4.x 使用的其相应功能,这个时候可以不装在全局&…...
HTML_案例1_注册页面
用纯html页面,不用css画一个注册页面。 最终效果如下: html页面代码如下: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>注册页面</title> </head>…...
Adobe After Effects 2024(Ae2024)在新版本中的升级有哪些?
After Effects 2024是Adobe公司推出的一款视频处理软件,它适用于从事设计和视频特技的机构,包括电视台、动画制作公司、个人后期制作工作室以及多媒体工作室。通过After Effects,用户可以高效且精确地创建无数种引人注目的动态图形和震撼人心…...

超越 GLIP! | RegionSpot: 识别一切区域,多模态融合的开放世界物体识别新方法
本文的主题是多模态融合和图文理解,文中提出了一种名为RegionSpot的新颖区域识别架构,旨在解决计算机视觉中的一个关键问题:理解无约束图像中的各个区域或patch的语义。这在开放世界目标检测等领域是一个具有挑战性的任务。 关于这一块&…...
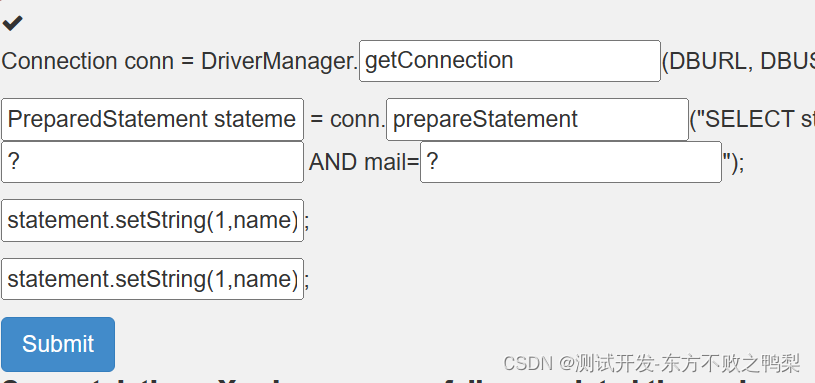
webgoat-(A1)injection
SQL Injection (intro) SQL 命令主要分为三类: 数据操作语言 (DML)DML 语句可用于请求记录 (SELECT)、添加记录 (INSERT)、删除记录 (DELETE) 和修改现有记录 ÿ…...

51单片机-中断
文章目录 前言 前言 #include <reg52.h> #include <intrins.h>sbit key_s2P3^0; sbit flagP3^7;void delay(unsigned int z){unsigned int x,y;for(xz;x>0;x--)for(y114;y>0;y--); }void int_init(){EA1;EX11;IT11;}void main(){int_init();while(1){if (key…...

Canvas 梦幻树生长动画
canvas可以制作出非常炫酷的动画,以下是一个梦幻树的示例。 效果图 源代码 <!DOCTYPE> <html> <head> <meta http-equiv"Content-Type" content"text/html; charsetutf-8" /> <title>梦幻数生长动画</title&…...
Unity之UI、模型跟随鼠标移动(自适应屏幕分辨率、锚点、pivot中心点)
一、效果 UI跟随鼠标移动, 动态修改屏幕分辨率、锚点、pivot等参数也不会受到影响。同时脚本中包含3d物体跟随ui位置、鼠标位置移动 二、屏幕坐标、Canvas自适应、锚点、中心点 在说原理之前我们需要先了解屏幕坐标、Canvas自适应、锚点、中心的特性和之间的关系。 1.屏幕坐标…...
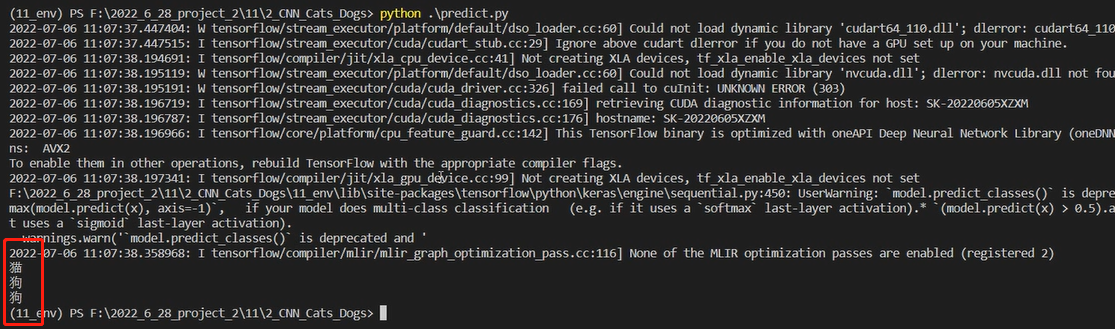
竞赛 深度学习猫狗分类 - python opencv cnn
文章目录 0 前言1 课题背景2 使用CNN进行猫狗分类3 数据集处理4 神经网络的编写5 Tensorflow计算图的构建6 模型的训练和测试7 预测效果8 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习猫狗分类 ** 该项目较为新颖&a…...

S4.2.4.7 Start of Data Stream Ordered Set (SDS)
一 本章节主讲知识点 1.1 xxx 1.2 sss 1.3 ddd 二 本章节原文翻译 2.1 SDS 数据流开始有序集 SDS 代表传输的数据类型从有序集转为数据流。它会在 Configuration.Idle,Recovery.Idle 和 Tx 的 L0s.FTS 状态发送。Loopback 模式下,主机允许发送 SDS。…...

CentOS操作系统的特点
CentOS操作系统的特点如下: 免费开源:CentOS是一个免费开源的操作系统,完全免费,无需花费任何成本。 稳定性高:CentOS以其出色的稳定性和安全性而闻名。它是一个基于Red Hat Enterprise Linux(RHEL&#x…...
)
Go基础(待更新)
Go基础(待更新) 参考Go 语言教程 文章目录 Go基础(待更新)一、基本语法1、格式化输出2、声明并赋值1)单变量赋值2)多变量赋值 二、math工具包的使用三、函数1、参数传递1)普通传递2)…...

二、Hadoop分布式系统基础架构
1、分布式 分布式体系中,会存在众多服务器,会造成混乱等情况。那如何让众多服务器一起工作,高效且不出现问题呢? 2、调度 (1)架构 在大数据体系中,分布式的调度主要有2类架构模式:…...
数据结构(超详细讲解!!)第二十一节 特殊矩阵的压缩存储
1.压缩存储的目标 值相同的元素只存储一次 压缩掉对零元的存储,只存储非零元 特殊形状矩阵: 是指非零元(如值相同的元素)或零元素分布具有一定规律性的矩阵。 如: 对称矩阵 上三角矩阵 下三角矩阵 对角矩阵 准…...

Python最强自动化神器Playwright!再也不用为爬虫逆向担忧了!
版权说明:本文禁止抄袭、转载,侵权必究! 目录 一、简介+使用场景二、环境部署(准备)三、代码生成器(优势)四、元素定位器(核心)五、追踪查看器(辅助)六、权限控制与认证(高级)七、其他重要功能(进阶)八、作者Info一、简介+使用场景 Playwright是什么?来自Chat…...

为什么 conda 不能升级 python 到 3.12
为什么 conda 不能升级 python 到 3.12 2023-11-05 23:33:29 ChrisZZ 1. 目的 弄清楚为什么执行了如下升级命令后, python 版本还是 3.11? conda update conda conda update python2. 原因 因为 conda forge 没有完成 migration Migration is the …...
0X02
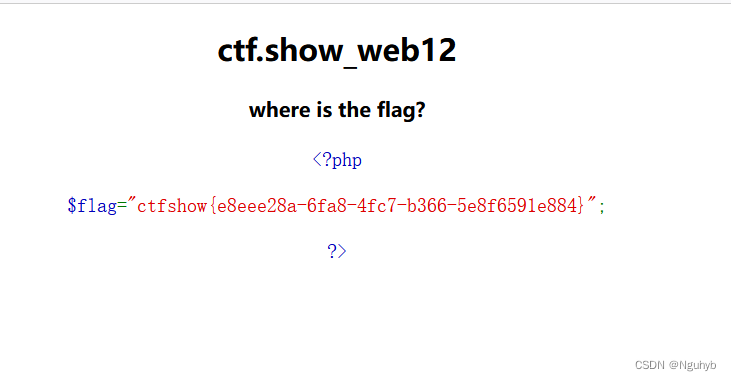
web9 阐释一波密码,依然没有什么 发现,要不扫一下,或者看一看可不可以去爆破密码 就先扫了看看,发现robots.txt 访问看看,出现不允许被访问的目录 还是继续尝试访问看看 就可以下载源码,看看源码 <?php $fl…...

【手写数据库所需C语言基础】可变结构体,结构体成员计算,类型强制转换为统一类型,数据库中使用C语言方法和技巧
专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会定期更新,…...
)
Android Studio(适配器Adapter)
认识适配器 在学完并且在做了一个自主项目后,我对适配器有了以下认识:1. 适配器的作用: 数据驱动的动态页面列表渲染,所以适配器主要就做了两件事:遍历数据,渲染页面(列表项)。比…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...

输电线路在线监测系统|架空线路安全运行的“第一道防线“!
输电线路微气象监测站是专为高压输电线路、电网廊道、杆塔运维量身打造的专利级一体化微气象智能监测设备。依托双专利超声波探测技术、六要素集成传感架构、无启动风速高精测量、智能抗干扰稳控系统,实现输电线路沿线气象24小时全自动捕捉、动态实时监测、大风风险…...

[特殊字符] 高效统计排序数组中目标元素的出现次数
给定一个已排序的数组和一个目标值,如何快速统计该目标值在数组中出现的次数?这是面试中非常经典的一道题,今天就来聊聊两种解法:线性搜索和二分搜索。 问题描述 假设有一个已排序的数组 arr[] 和一个整数 target,需…...

10.刷机变砖、IMEI 丢失、基带未知、触控失灵?一站式终极修复方案
摘要 本文面向具备基础计算机操作能力的维修从业者与高级用户,系统讲解当前主流品牌手机(华为、小米、OPPO、vivo、一加、苹果)的刷机与维修核心流程。内容涵盖底层引导架构差异、Fastboot/Recovery/DFU模式操作规范、分区表保护策略、驱动兼容性处理以及常见硬件故障的软件…...