数仓分层能减少重复计算,为啥能减少?如何减少?这篇文章包懂!
很多时候,看一些数据领域的文章,说到为什么做数据仓库、数据仓库要分层,我们经常会看到一些结论:因为有ABCD…等等理由,比如降低开发成本、减少重复计算等等好处
然后,多数人就记住了ABCD。但是,每每被问起来,为什么,有什么案例,你是怎么理解的,就被问住,傻眼了。
概念套概念,没意思,不如返璞归真,从生活案例重新理解起~
01 从统计班级人数开始
本文将用生活化案例,结合粒度的概念,帮你理解常说的减少重复计算。
假如,你带一个班级,你是班主任,你上第一节课。但你不知道班上到了多少人,于是,让同学们报数,班上有 30 人,从 1 报到 30,每个人报一次数,一共30 次。

第二节课,来了科任老师 A, 他也想知道班级人数,于是也让同学们报数,从1 报到 30,又是 30 次。
第三节课,来了科任老师 B,他也想知道人数,于是…
第四节课,来了科任老师 C,他也想… 好,一次又一次地报数,同学们烦了。于是有个聪明人记录下来,写到黑板上。
第五节课,等到科任老师 E 面带微笑地走进教室,问班里一共多少人,笑着说,同学们,要不我们来报数吧?
孩子们异口同声地对老师说:老师,请看黑板!

你看,把结果记录和存储下来,就不用再从 1 报到 30才能知道结果了。
这就是减少重复计算了!
02 思考思考粒度
我们再看看粒度。
关于粒度,我曾在数据仓库的文章里讲过,可以回看下:数仓避坑-整明白懂粒度
按照报数规则,一个人只能往另一个人的报数上加一,班级人数这个数字每加一,背后对应的就是一个新的人。
人不可再分,最小就是1,不存在0.5个人,班级人数这个数字的最小粒度,就是人。
粗一点的粒度是什么?以班级为粒度单位报人数,可以只用报一次。
粒度还可以是组,班级里面,我们可以按照不同的方式给同学们分成不同的组。常见的,按照列分组。
其实,这种分组,是按照同学们所坐位置的物理空间来划分的。

我们还可以划分其他的组,比如,按照出生月份,住的小区,兴趣爱好,等等进行分组。
当我们想知道,某个组有多少人,并不需要每次都从最小粒度去统计人数,都去报数,我们都可以把组,这个相对人来说,更粗的粒度的数字统计出来,记录下来, 下次再有类似的提问/请求,直接拿粗粒度的统计结果,也就是直接回答,这个组有多少人。
这就是,减少重复计算的生活化案例,是不是比构建指标体系、搭建中台、减少重复开发、重复计算,要具象多啦~
03当问题开始复杂,分层的好处出现
刚刚,我们解决了班级粒度的事情,现在,你是校长了。
你的管理范围变大了,至少,统计人数,你先核心是关注更大层面的统计数据,比如全校人数,各年级人数,然后当有一些班级人数分配不均匀的时候,再细致看某个班的人数。
有了班级、年级人数,那么全校人数就好办啦~层层往上汇总累加就好了,总不至于全校开大会,从头报到尾吧。
管理的场景,问题是多如牛毛的,不同场景,所需要的统计数据、分组,都不尽相同。
在招生期间,你要知道每个学区给定的学生名额数,还有一些特长生的名额;
在日常管理期间,你要知道不同年级学生出勤、上课的情况。
更重要的是,你得了解学生的成绩情况。不同年级、不同学科、不同类型的学生,绝对分数,分数的变化趋势。
虽然咱们搞素质教育,不对外暴露这些信息,避免攀比和比较,但是最终落到学校的升学人数、升学率的时候,这些过程性的数据又是我们不得不关注的。
所谓的分层,是分而治之,分而算之。
光讲好处,问题就没有了吗?肯定是有的,比如,我们要额外地记录一些数据,要保证这些分而算的数据的准确性,相当于是信任这个分层数据的提供者。
整个过程中,还要从分析的角度出发,去设计很多分层里面的相关维度、共性维度。关于维度,可以看这篇:数仓避坑-想清楚维度
04 企业里的重复计算
回到企业的环境里,我们会对用户的观看图片、看视频、看直播的行为事件进行统计、计数,看了几次,看了多长时间。
我们也非常关心用户看完这些,到底花了多少钱,送了多少个礼物,买了多少直播间里的商品。
我们会从各种角度对这些过程行为、消费结果进行拆解和统计。
于是乎,企业里会有非常多需要统计、计数的数据。
比如,埋点会上报某个用户在某市某刻观看了A视频,用的手机是苹果,操作系统的版本是IOS7.x,用户所在的IP解析出来是在一线城市。
观看完之后,进入到了讲某个商品的直播间B,系统也会记录,在直播间B下单购买了商品C,金额是99,购买的个数是4个。
当我们要去统计,一线城市的用户观看A图片的次数,购买商品C的数量和金额的时候。
我们会跟之前统计班级人数、分组人数一样,要统计这些结果。
我们可以提前把一些结果提前记录下来,然后每次其他人要查询相同信息的时候,就不用每次都要「报数」了~
比如,今年小米发的双十一战报。

可能很多人都想要这个结果,用于宣传或者分析,那我们直接把这个数据存下来,当别人要的时候,直接拿出来就好了(图片里面,还备注了数据的统计口径)
具体的一些后台报表,我就不去举例了,大家体会到重复计算到底是怎么回事,就可以了。
关于这些数据是怎么存储的,可以了解数据仓库维度模型:数仓避坑-搞懂维度模型
–END–
结合生活案例,去剖析拆解每一个你从他人那里听来的、借鉴来的、但其实自己并不了解的抽象词,这样就是真的吃透了~
以上,感谢阅读~
欢迎点赞、收藏、转发!
也欢迎关注我的公众号:数据产品小lee
相关文章:
数仓分层能减少重复计算,为啥能减少?如何减少?这篇文章包懂!
很多时候,看一些数据领域的文章,说到为什么做数据仓库、数据仓库要分层,我们经常会看到一些结论:因为有ABCD…等等理由,比如降低开发成本、减少重复计算等等好处 然后,多数人就记住了ABCD。但是࿰…...

【Linux】基础IO之文件操作(文件fd)——针对被打开的文件
系列文章目录 文章目录 系列文章目录前言浅谈文件的共识 一、 回忆c语言对文件操作的接口1.fopen接口和cwd路径2.fwrite接口和"w","a"方法3.fprintf接口和三个默认打开的输入输出流(文件) 二、过渡到系统,认识…...

什么是超算数据中心
超算数据中心是基于超级计算机或者是大规模的计算集群的数据中心,它具备高性能、高可靠性、高可用性和高扩展性这些特点,能够提供大规模计算、存储和网络服务的功能,在人工智能、科学计算、数据分析等等领域应用比较广泛。 超算数据中心有以下…...

阿里云服务器省钱购买和使用方法(图文详解)
阿里云服务器使用教程包括云服务器购买、云服务器配置选择、云服务器开通端口号、搭建网站所需Web环境、安装网站程序、域名解析到云服务器公网IP地址,最后网站上线全流程,新手站长xinshouzhanzhang.com分享阿里云服务器详细使用教程: 一&am…...

Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題
Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題 新搭建的FLINK集群出现的问题汇总 1.新搭建的Flink集群和Hadoop集群无法正常启动Flink任务 查看这个提交任务的日志无法发现有用的错误信息。 进一步查看yarn日志: 发现只有JobManager的错误日志出现了如下的…...
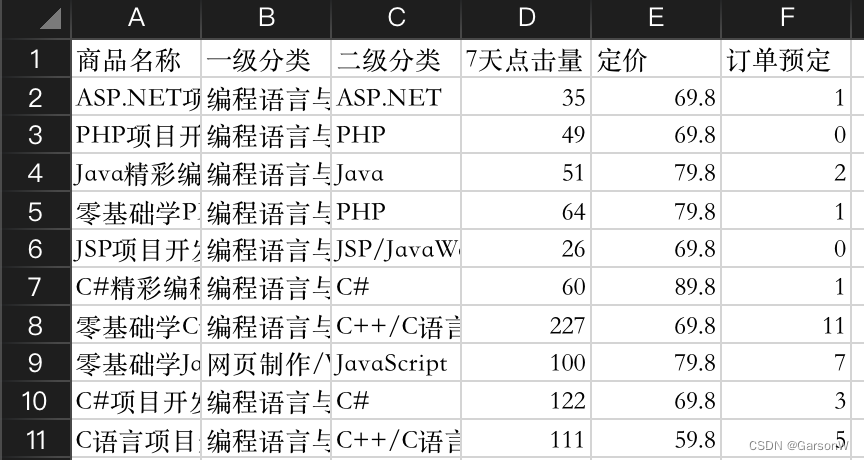
pandas - 数据分组统计
1.分组统计groupby()函数 对数据进行分组统计,主要适用DataFrame对象的groupby()函数。其功能如下。 (1)根据特定条件,将数据拆分成组 (2)每个组都可以独立应用函数(如求和函数sum()࿰…...

Git简介和安装
一,Git简介 Git 是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理。通过Git 仓库来存储和管理这些文件,Git 仓库分为两种: 本地仓库:开发人员自己电脑上的 Git 仓库 远程仓库:远程…...

思维模型 布里丹毛驴效应
本系列文章 主要是 分享 思维模型,涉及各个领域,重在提升认知。犹豫不决是病,得治~ 1 布里丹毛驴效应的应用 1.1 犹豫不决的产品“施乐 914” 20 世纪 60 年代,美国一家名为施乐(Xerox)的公司…...
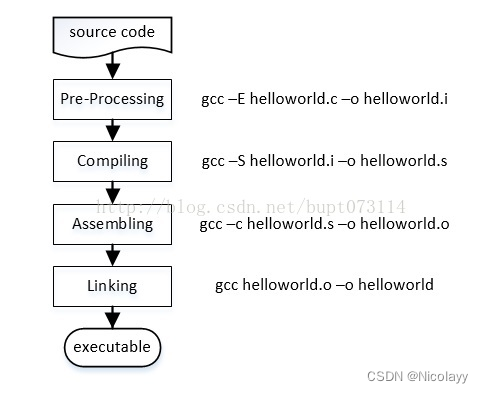
预处理、编译、汇编、链接
1.预处理 宏替换去注释引入头文件 #之后的语句都是预处理语句, #include<iostream> 将该文件的内容拷贝到现有文件中, 2.编译 3.汇编 4.链接 gcc 基于C/C的编译器 补充说明 gcc命令 使用GNU推出的基于C/C的编译器,是开放源代…...

面试问题?
1.面向对象的特征? 2.开放闭合 3.java中的泛型可以用基本类型吗? 4.重载和重写的区别? 5.string、stringbuffer、stringbuilder? 6.单例模式的实现方式有哪几种? 7.volicate除了保证 8.sy是重量级锁还是轻量级锁ÿ…...

pytorch 笔记:PAD_PACKED_SEQUENCE 和PACK_PADDED_SEQUENCE
1 PACK_PADDED_SEQUENCE 1.0 功能 将填充的序列打包成一个更加紧凑的形式这样RNN、LSTM和GRU等模型可以更高效地处理它们,因为它们可以跳过不必要的计算 1.2 基本使用方法 torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_firstFalse, enforce_…...
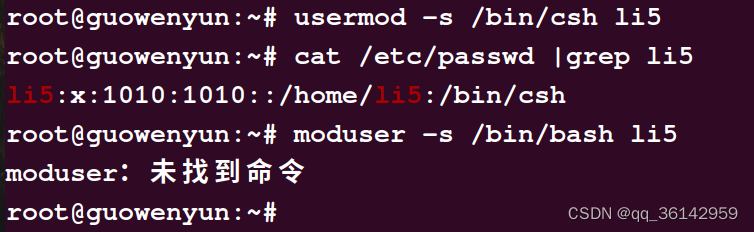
Ubuntu 创建用户
在ubuntu系统中创建用户,是最基本的操作。与centos7相比,有较大不同。 我们通过案例介绍,讨论用户的创建。 我们知道,在linux中,有三类用户:超级管理员 root 具有完全权限;系统用户 bin sys a…...

华为政企路由器产品集
产品类型产品型号产品说明 maintainProductA821 E_2*10GE/GE/FE(o)8*GE/FE(o)8*GE/FE(e),1*交流电源华为企业云端NetEngine A800 E综合业务一体化接入路由器是华为公司面向云时代推出的一款产品,用于企业快速接入网络,具备易部署、易运维、高性能、高…...
性能测试知多少---了解前端性能
我的上一篇博文中讲到了响应时间,我们在做性能测试时,能过工具可以屏蔽客户端呈现时间,通过局域网的高宽带可以忽略数据传输速度的障碍。这并不是说他们不会对系统造成性能影响。相反,从用户的感受来看,虽然传输速度受…...

Docker-compose容器群集编排管理工具
目录 Docker-compose 1、Docker-compose 的三大概念 2、YAML文件格式及编写注意事项 1)使用 YAML 时需要注意下面事项 2)ymal文件格式 3)json格式 3、Docker Compose配置常用字段 4、Docker-compose的四种重启策略 5、Docker Compose…...

Python 深度学习导入的一些包的说明
Python 深度学习导入的一些包的说明 这段代码导入了一些Python库和模块,并定义了一些数据转换操作。 from future import print_function, division:这是一个Python 2和Python 3兼容性的导入语句。它确保在Python 2中使用Python 3的print函数和除法运算符…...

劲升逻辑与安必快、鹏海运于进博会签署合作协议,助力大湾区外贸高质量发展
新中经贸与投资论坛签约现场 中国上海,2023 年 11 月 6 日——第六届进博会期间,由新加坡工商联合总会主办的新中经贸与投资论坛在上海同期举行。跨境贸易数字化领域的领导者劲升逻辑与安必快科技(深圳)有限公司(简称…...
hivesql,sql 函数总结:
1、NVL函数与Coalesce差异 -- select nvl(null,8); -- 结果是 8 -- select nvl(,7); -- 结果是"" -- select coalesce(null,null,9); -- 结果是 9 -- select coalesce("",null,9); -- 结果是 "" 1.2、 NVL函数与Coalesce差异 …...

前端js实现井字游戏和版本号对比js逻辑【适用于vue和react】
// 实现 compareVersion 方法,用于比较两个版本号(version1、version2) * 如果version1 > version2,返回1; * 如果version1 < version2,返回-1; * 其他情况,返回0。 * 版本号规…...

unity 通过Andriod arr 访问 手机自带的浏览器
unity 通过Andriod arr 访问 手机自带的浏览器 using System.Collections; using System.Collections.Generic; using System.IO; using UnityEngine; using UnityEngine.UI;public class OpenURL : MonoBehaviour {public Button button;string url "http://192.168.1.…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...

安卓用户如何免费获取大模型API密钥并开始调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 安卓用户如何免费获取大模型API密钥并开始调用 对于安卓开发者或移动端技术爱好者而言,直接体验和调用多种大模型的能力…...

将Taotoken作为统一AI网关整合进企业现有微服务架构的实践思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为统一AI网关整合进企业现有微服务架构的实践思路 在构建以AI能力驱动的现代应用时,中型及以上的企业常面…...