Python库学习(十二):数据分析Pandas[下篇]
接着上篇《Python库学习(十一):数据分析Pandas[上篇]》,继续学习Pandas
1.数据过滤
在数据处理中,我们经常会对数据进行过滤,为此Pandas中提供mask()和where()两个函数;
-
mask(): 在 满足条件的情况下替换数据,而不满足条件的部分则保留原始数据; -
where(): 在 不满足条件的情况下替换数据,而满足条件的部分则保留原始数据;
from datetime import datetime, timedelta
import random
import pandas as pd
def getDate() -> str:
"""
用来生成日期
:return:
"""
# 随机减去天数
tmp = datetime.now() - timedelta(days=random.randint(1, 100))
# 格式化时间
return tmp.strftime("%Y-%m-%d")
if __name__ == '__main__':
# 准备数据 水果
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄"]
rows = 3
today = datetime.now()
data_dict = {
"fruit": [random.choice(fruits) for _ in range(rows)],
"date": [getDate() for _ in range(rows)],
"price": [round(random.uniform(1, 5), 2) for _ in range(rows)], # 随机生成售价,并保留两位小数
}
data = pd.DataFrame(data_dict)
# 复制数据,方便后续演示
data_tmp = data.copy()
print("-------------- 生成数据预览 ------------------")
print(data)
print("-------------- 普通条件:列出价格大于3.0的水果 ------------------")
condition = data["price"] > 3.0
# 列出价格大于3.0的水果
fruit_res = data[condition]["fruit"]
print("价格大于3.0的水果:", fruit_res.to_numpy())
print("-------------- 使用mask:把价格大于3.0设置成0元 ------------------")
# 把价格大于3.0设置成0元
data["price"] = data["price"].mask(data["price"] > 3.0, other=0)
print(data)
print("-------------- 使用where:把价格不大于3.0设置成0元 ------------------")
# 把价格不大于3.0设置成0元
data_tmp["price"] = data_tmp["price"].where(data_tmp["price"] > 3.0, other=0)
print(data_tmp)
"""
-------------- 生成数据预览 ------------------
fruit date price
0 橘子 2023-10-16 3.52
1 苹果 2023-09-08 1.07
2 葡萄 2023-09-27 2.69
-------------- 普通条件:列出价格大于3.0的水果 ------------------
价格大于3.0的水果: ['橘子']
-------------- 使用mask:把价格大于3.0设置成0元 ------------------
fruit date price
0 橘子 2023-10-16 0.00
1 苹果 2023-09-08 1.07
2 葡萄 2023-09-27 2.69
-------------- 使用where:把价格不大于3.0设置成0元 ------------------
fruit date price
0 橘子 2023-10-16 3.52
1 苹果 2023-09-08 0.00
2 葡萄 2023-09-27 0.00
"""
@注:从功能上可以看出,mask()和where()是正好两个相反的函数
2. 数据遍历
if __name__ == '__main__':
# 数据生成参考上面
print("-------------- 生成数据预览 ------------------")
print(data)
print("-------------- 遍历dataframe数据 ------------------")
for index, row in data.iterrows():
print("index:{} 水果:{} 日期:{} 售价:{}".format(index, row["fruit"], row["date"], row["price"]))
print("-------------- 遍历Series数据 ------------------")
series_data = pd.Series({"name": "张三", "age": 20, "height": 185})
for k, v in series_data.items():
print("key:{} value:{}".format(k, v))
"""
-------------- 生成数据预览 ------------------
fruit date price
0 橘子 2023-10-14 3.71
1 橘子 2023-10-03 3.74
2 香蕉 2023-09-06 1.17
3 葡萄 2023-08-30 1.16
4 榴莲 2023-10-21 1.47
-------------- 遍历dataframe数据 ------------------
index:0 水果:橘子 日期:2023-10-14 售价:3.71
index:1 水果:橘子 日期:2023-10-03 售价:3.74
index:2 水果:香蕉 日期:2023-09-06 售价:1.17
index:3 水果:葡萄 日期:2023-08-30 售价:1.16
index:4 水果:榴莲 日期:2023-10-21 售价:1.47
-------------- 遍历Series数据 ------------------
key:name value:张三
key:age value:20
key:height value:185
"""
3. 分层索引
分层索引(MultiIndex)是Pandas 中一种允许在一个轴上拥有多个(两个或更多)级别的索引方式。这种索引方式适用于多维数据和具有多个层次结构的数据。
3.1 使用set_index
from datetime import datetime, timedelta
import random
import pandas as pd
if __name__ == '__main__':
# 创建一个示例 DataFrame
fruits = ["苹果", "苹果", "橘子", "橘子", "橘子", "百香果"]
rows = len(fruits)
today = datetime.now()
dict_var = {
'fruit': fruits,
'date': [(today - timedelta(days=i)).strftime("%Y-%m-%d") for i in range(rows)],
'price': [round(random.uniform(1, 5), 2) for _ in range(rows)],
'num': [round(random.uniform(10, 500), 2) for _ in range(rows)]
}
sale_data = pd.DataFrame(dict_var)
# 设置多层次索引
sale_data.set_index(['fruit', 'date'], inplace=True)
print("----------------------------- 创建多层次索引-----------------------------------")
print(sale_data)
print("----------------------------- 打印索引信息-----------------------------------")
index_info = sale_data.index
print(index_info)
print("----------------------------- 使用loc 访问多层次索引-----------------------------------")
search_price = sale_data.loc[('苹果', '2023-11-02'), 'price']
print(search_price)
print("----------------------------- 使用xs 访问多层次索引-----------------------------------")
search_xs = sale_data.xs(key=('苹果', '2023-11-02'), level=['fruit', 'date'])
print(search_xs)
"""
----------------------------- 创建多层次索引-----------------------------------
price num
fruit date
苹果 2023-11-02 1.08 211.31
2023-11-01 1.35 308.87
橘子 2023-10-31 3.25 180.84
2023-10-30 2.53 115.14
2023-10-29 2.61 146.49
百香果 2023-10-28 1.36 246.01
----------------------------- 打印索引信息-----------------------------------
MultiIndex([( '苹果', '2023-11-02'),
( '苹果', '2023-11-01'),
( '橘子', '2023-10-31'),
( '橘子', '2023-10-30'),
( '橘子', '2023-10-29'),
('百香果', '2023-10-28')],
names=['fruit', 'date'])
----------------------------- 使用loc 访问多层次索引-----------------------------------
1.08
----------------------------- 使用xs 访问多层次索引-----------------------------------
price num
fruit date
苹果 2023-11-02 1.08 211.31
"""
3.2 使用**MultiIndex**
if __name__ == '__main__':
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"]
date_list = ['2023-03-11', '2023-03-13', '2023-03-15']
cols = pd.MultiIndex.from_product([date_list, ["售卖价", "成交量"]], names=["日期", "水果"])
list_var = []
for i in range(len(fruits)):
tmp = [
round(random.uniform(1, 5), 2), round(random.uniform(1, 100), 2),
round(random.uniform(1, 5), 2), round(random.uniform(1, 100), 2),
round(random.uniform(1, 5), 2), round(random.uniform(1, 100), 2),
]
list_var.append(tmp)
print("--------------------------------创建多层次索引--------------------------------")
multi_data = pd.DataFrame(list_var, index=fruits, columns=cols)
print(multi_data)
print("--------------------------------打印多层次索引--------------------------------")
print(multi_data.index)
print(multi_data.columns)
# 搜行
print("----------------------------- 使用filter-- 行搜索-----------------------------------")
print(multi_data.filter(like='苹果', axis=0))
print("----------------------------- 使用filter-- 列搜索-----------------------------------")
# 搜列
print(multi_data.filter(like='2023-03-11', axis=1))
"""
--------------------------------创建多层次索引--------------------------------
日期 2023-03-11 2023-03-13 2023-03-15
水果 售卖价 成交量 售卖价 成交量 售卖价 成交量
苹果 2.54 69.40 3.27 18.89 1.93 3.37
香蕉 1.99 53.33 1.88 92.77 3.64 26.60
橘子 2.48 27.81 3.20 8.71 2.58 85.44
榴莲 3.15 47.89 1.09 93.15 2.51 85.30
葡萄 4.59 35.58 4.88 77.02 3.08 64.96
雪花梨 3.17 9.58 4.48 44.17 4.15 88.94
百香果 3.05 7.65 3.51 82.03 3.97 52.06
--------------------------------打印多层次索引--------------------------------
Index(['苹果', '香蕉', '橘子', '榴莲', '葡萄', '雪花梨', '百香果'], dtype='object')
MultiIndex([('2023-03-11', '售卖价'),
('2023-03-11', '成交量'),
('2023-03-13', '售卖价'),
('2023-03-13', '成交量'),
('2023-03-15', '售卖价'),
('2023-03-15', '成交量')],
names=['日期', '水果'])
----------------------------- 使用filter-- 行搜索-----------------------------------
日期 2023-03-11 2023-03-13 2023-03-15
水果 售卖价 成交量 售卖价 成交量 售卖价 成交量
苹果 2.54 69.4 3.27 18.89 1.93 3.37
----------------------------- 使用filter-- 列搜索-----------------------------------
日期 2023-03-11
水果 售卖价 成交量
苹果 2.54 69.40
香蕉 1.99 53.33
橘子 2.48 27.81
榴莲 3.15 47.89
葡萄 4.59 35.58
雪花梨 3.17 9.58
百香果 3.05 7.65
"""
4. 数据读写
4.1 写入表格
from datetime import datetime, timedelta
import random
import pandas as pd
if __name__ == '__main__':
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"]
rows = 20
today = datetime.now()
print(today.strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
dict_var = {
'水果': [random.choice(fruits) for _ in range(rows)],
'进价': [round(random.uniform(1, 5), 4) for _ in range(rows)],
'售价': [round(random.uniform(1, 5), 4) for _ in range(rows)],
'日期': [(today - timedelta(days=i)).strftime("%Y-%m-%d") for i in range(rows)],
'销量': [round(random.uniform(10, 500), 4) for _ in range(rows)]
}
sale_data = pd.DataFrame(dict_var)
print(sale_data)
# 保存,浮点数保留两位小数
sale_data.to_excel("./test.xlsx", float_format="%.2f")
a.主要参数说明:
-
excel_writer:Excel文件名或ExcelWriter对象。如果是文件名,将创建一个ExcelWriter对象,并在退出时自动关闭文件。 -
sheet_name: 字符串,工作表的名称,默认为Sheet1。 -
na_rep: 用于表示缺失值的字符串,默认为空字符串。 -
float_format: 用于设置浮点数列的数据格式。默认为None,表示使用Excel默认的格式,当设置%.2f表示保留两位。 -
columns: 要写入的列的列表,默认为None。如果设置为None,将写入所有列;如果指定列名列表,将只写入指定的列。 -
header: 是否包含列名,默认为True。如果设置为False,将不写入列名。 -
index: 是否包含行索引,默认为True。如果设置为False,将不写入行索引。 -
index_label: 用于指定行索引列的名称。默认为None。 -
startrow: 数据写入的起始行,默认为0。 -
startcol: 数据写入的起始列,默认为0。 -
freeze_panes: 值是一个元组,用于指定要冻结的行和列的位置。例如,(2, 3)表示冻结第 2 行和第 3 列。默认为None,表示不冻结任何行或列。
4.2 读取表格
import pandas as pd
if __name__ == '__main__':
# ------------------------------ 读取表格 ----------------------------------
print("----------------------------- 读取全部数据 -----------------------")
# 读取全部数据
read_all_data = pd.read_excel("./test.xlsx")
print(read_all_data)
print("----------------------------- 只读取第1、2列数据 -----------------------")
# 只读取第1、2列数据
read_column_data = pd.read_excel("./test.xlsx", usecols=[1, 2])
print(read_column_data)
print("----------------------------- 只读取列名为:日期、销量 的数据 -----------------------")
# 读取
read_column_data2 = pd.read_excel("./test.xlsx", usecols=['日期', '销量'])
print(read_column_data2)
"""
----------------------------- 读取全部数据 -----------------------
Unnamed: 0 水果 进价 售价 日期 销量
0 0 榴莲 3.74 2.35 2023-11-03 217.03
1 1 百香果 2.08 3.64 2023-11-02 311.40
2 2 百香果 2.17 4.94 2023-11-01 404.55
3 3 橘子 2.41 2.71 2023-10-31 431.20
4 4 葡萄 2.78 3.99 2023-10-30 323.01
5 5 苹果 4.79 1.68 2023-10-29 161.26
6 6 百香果 1.61 2.78 2023-10-28 407.27
7 7 榴莲 1.56 4.08 2023-10-27 44.74
8 8 雪花梨 1.60 3.02 2023-10-26 119.13
9 9 葡萄 3.03 1.08 2023-10-25 152.87
----------------------------- 只读取第1、2列数据 -----------------------
水果 进价
0 榴莲 3.74
1 百香果 2.08
2 百香果 2.17
3 橘子 2.41
4 葡萄 2.78
5 苹果 4.79
6 百香果 1.61
7 榴莲 1.56
8 雪花梨 1.60
9 葡萄 3.03
----------------------------- 只读取列名为:日期、销量 的数据 -----------------------
日期 销量
0 2023-11-03 217.03
1 2023-11-02 311.40
2 2023-11-01 404.55
3 2023-10-31 431.20
4 2023-10-30 323.01
5 2023-10-29 161.26
6 2023-10-28 407.27
7 2023-10-27 44.74
8 2023-10-26 119.13
9 2023-10-25 152.87
"""
主要参数说明:
-
io: 文件路径、ExcelWriter对象或者类似文件对象的路径/对象。 -
sheet_name: 表示要读取的工作表的名称或索引。默认为 0,表示读取第一个工作表。 -
header: 用作列名的行的行号。默认为 0,表示使用第一行作为列名。 -
names: 覆盖 header 的结果,即指定列名。 -
index_col: 用作行索引的列的列号或列名。 -
usecols: 要读取的列的列表,可以是列名或列的索引。
4.3 更多方法
除了上面的表格读取,还有更多类型的读取方式,方法简单整理如下:

5.数据可视化
Pandas底层对Matplotlib进行了封装,所以可以直接使用Matplotlib的绘图方法;
5.1 折线图
from datetime import datetime, timedelta
import random
import pandas as pd
from matplotlib import pyplot as plt
# 设置字体以便正确显示中文
plt.rcParams['font.sans-serif'] = ['FangSong']
# 正确显示连字符
plt.rcParams['axes.unicode_minus'] = False
if __name__ == '__main__':
# ------------------------------ 生成数据 ----------------------------------
rows = 30
beginDate = datetime(2023, 4, 10)
print("beginDate:", beginDate.strftime("%Y-%m-%d"))
dict_var = {
'日期': [(beginDate + timedelta(days=i)).strftime("%Y-%m-%d") for i in range(rows)],
'进价': [round(random.uniform(1, 4), 2) for _ in range(rows)],
'售价': [round(random.uniform(2, 6), 2) for _ in range(rows)],
}
apple_data = pd.DataFrame(dict_var)
apple_data.plot(x='日期', y=['进价', '售价'], title='苹果销售数据')
plt.show()
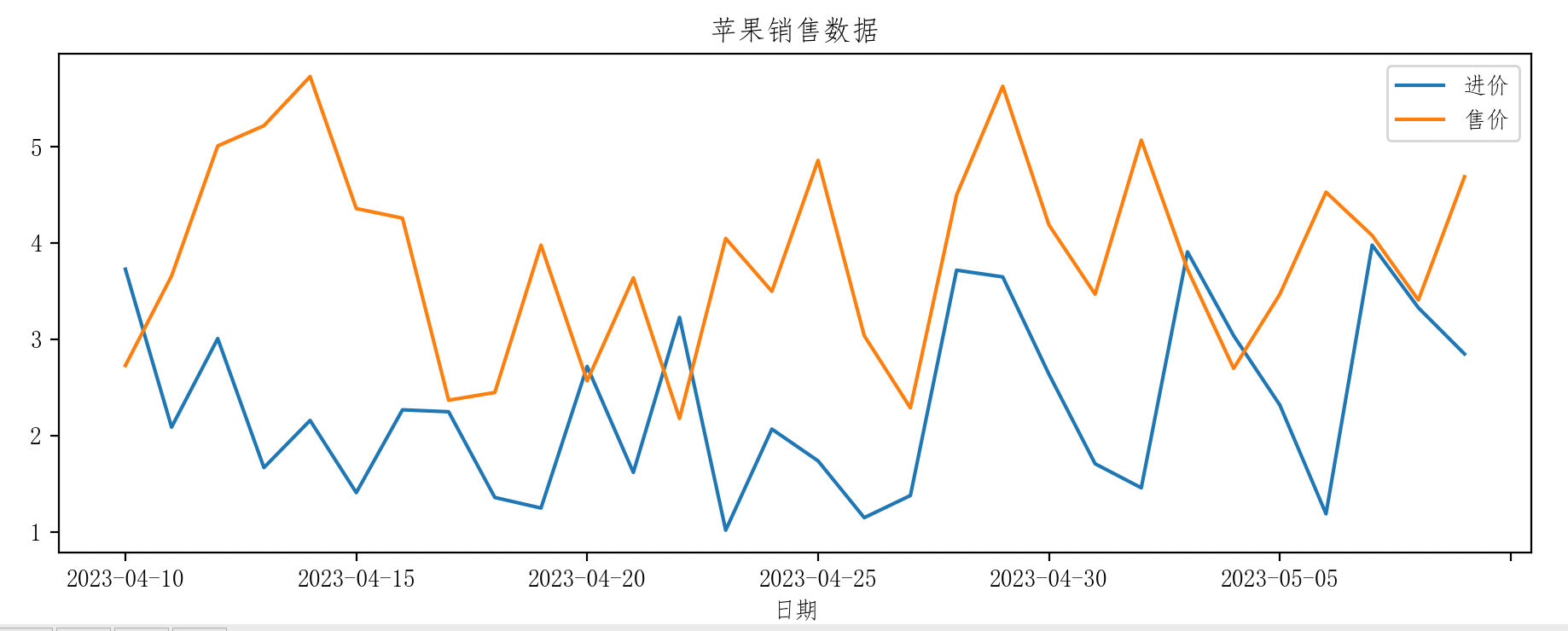
5.2 散点图
from datetime import datetime, timedelta
import random
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 设置字体以便正确显示中文
plt.rcParams['font.sans-serif'] = ['FangSong']
# 正确显示连字符
plt.rcParams['axes.unicode_minus'] = False
if __name__ == '__main__':
# ------------------------------ 生成数据 ----------------------------------
rows = 30
beginDate = datetime(2023, 4, 1)
print("beginDate:", beginDate.strftime("%Y-%m-%d"))
dict_var = {
'日期': [(beginDate + timedelta(days=i)).strftime("%d") for i in range(rows)],
'进价': [round(random.uniform(1, 4), 2) for _ in range(rows)],
'售价': [round(random.uniform(2, 10), 2) for _ in range(rows)],
'销量': [round(random.uniform(10, 500), 4) for _ in range(rows)]
}
apple_data = pd.DataFrame(dict_var)
# 设置颜色
colorList = 10 * np.random.rand(rows)
# 设置
apple_data.plot(x='日期', y='售价', kind='scatter', title='苹果销售数据', color=colorList, s=dict_var['销量'])
plt.show()
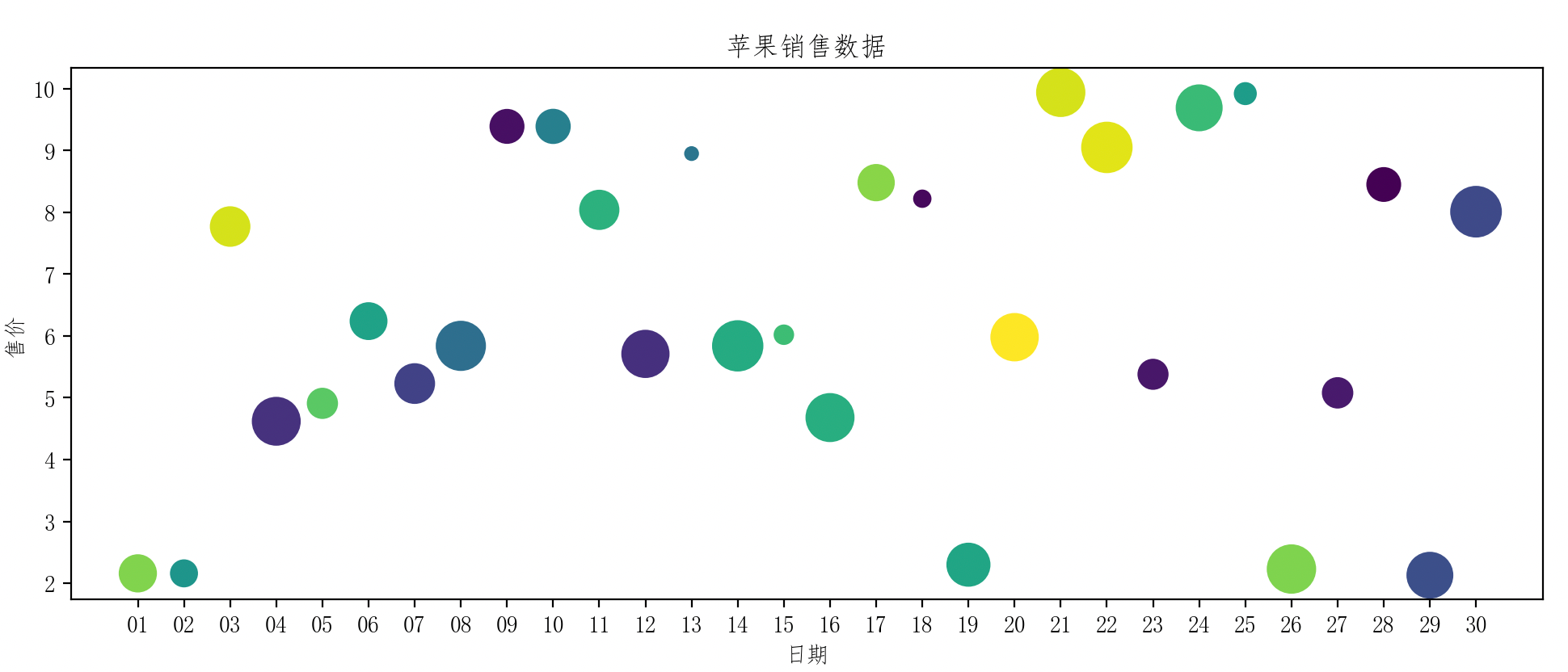
-
color:表示的是颜色,可以使用字符串表示颜色名称,也可以使用十六进制颜色码。 -
s: 散点图特有的属性,表示散点大小。
5.3 柱形图
import random
import pandas as pd
from matplotlib import pyplot as plt
# 设置字体以便正确显示中文
plt.rcParams['font.sans-serif'] = ['FangSong']
# 正确显示连字符
plt.rcParams['axes.unicode_minus'] = False
if __name__ == '__main__':
# ------------------------------ 生成数据 ----------------------------------
fruits = ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"]
rows = 7
beginDate = datetime(2023, 4, 1)
print("beginDate:", beginDate.strftime("%Y-%m-%d"))
dict_var = {
'水果': ["苹果", "香蕉", "橘子", "榴莲", "葡萄", "雪花梨", "百香果"],
'销量': [round(random.uniform(10, 1000), 2) for _ in range(rows)]
}
apple_data = pd.DataFrame(dict_var)
apple_data.plot(x='水果', y='销量', kind='bar', title='水果销售数据')
plt.show()
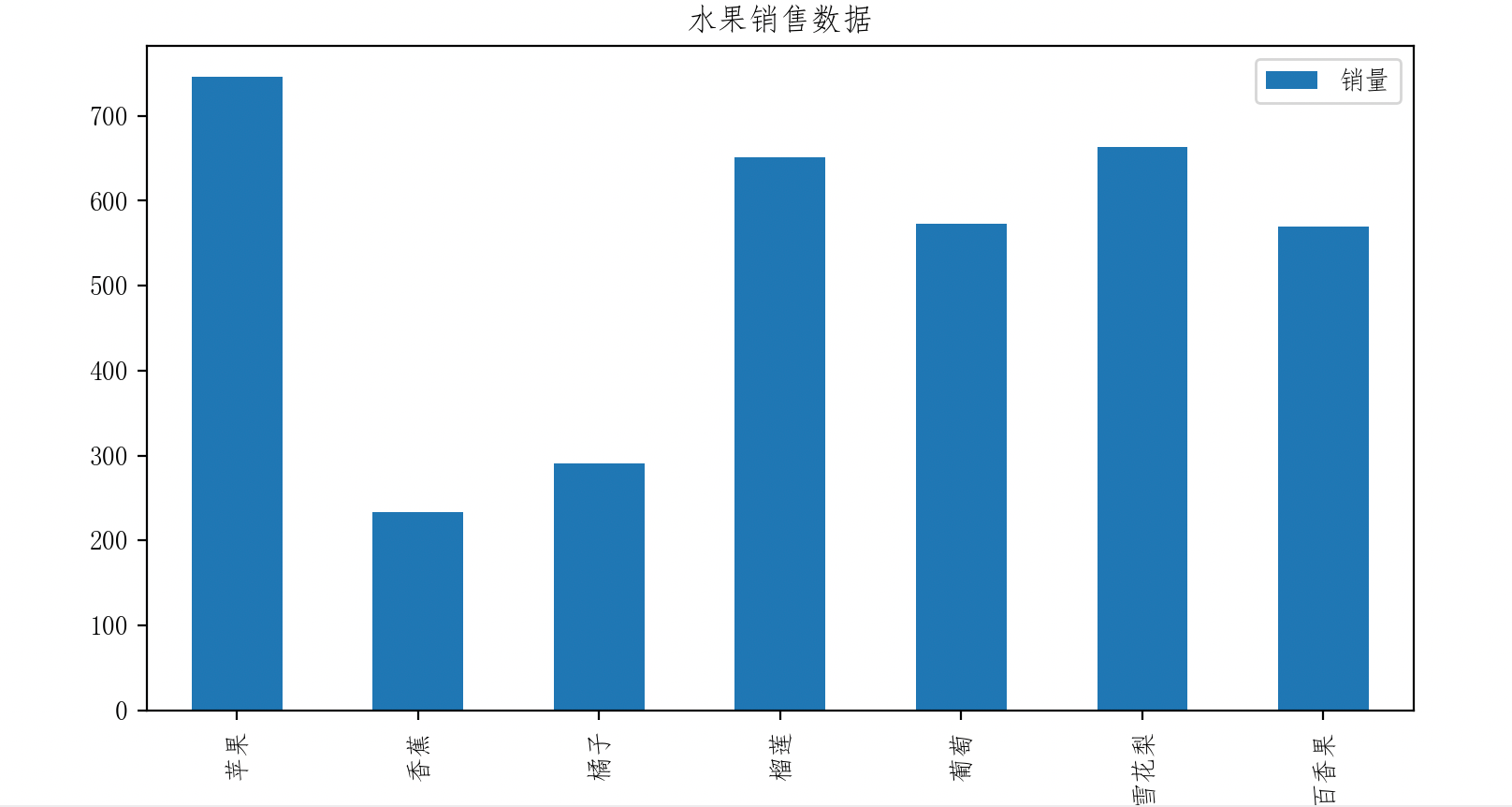
本文由 mdnice 多平台发布
相关文章:
Python库学习(十二):数据分析Pandas[下篇]
接着上篇《Python库学习(十一):数据分析Pandas[上篇]》,继续学习Pandas 1.数据过滤 在数据处理中,我们经常会对数据进行过滤,为此Pandas中提供mask()和where()两个函数; mask(): 在 满足条件的情况下替换数据,而不满足条件的部分…...

工具: MarkDown学习
具体内容看官方教程: Markdown官方教程...
JS逆向爬虫---请求参数加密②【某麦数据analysis参数加密】
主页链接: https://www.qimai.cn/rank analysis逆向 完整参数生成代码如下: const {JSDOM} require(jsdom) const dom new JSDOM(<!DOCTYPE html><p>hello</p>) window dom.windowfunction customDecrypt(n, t) {t t || generateKey(); //…...
基于APM(PIX)飞控和missionplanner制作遥控无人车-从零搭建自主pix无人车无人坦克
前面的步骤和无人机调试一样,可以参考无人机相关专栏。这里不再赘述。 1.安装完rover的固件后,链接gps并进行校准。旋转小车不同方向,完成校准,弹出成功窗口。 2.校准遥控器。 一定要确保遥控器模式准确,尤其是使用没…...
学习笔记)
Vue3的手脚架使用和组件父子间通信-插槽(Options API)学习笔记
Vue CLI安装和使用 全局安装最新vue3 npm install vue/cli -g升级Vue CLI: 如果是比较旧的版本,可以通过下面命令来升级 npm update vue/cli -g通过脚手架创建项目 vue create 01_product_demoVue3父子组件的通信 父传子 父组件 <template>…...

第九章软件管理
云计算第九章软件管理 概述 1RPM包 RPM Package Manager 由Red Hat公司提出被众多Linux发现版所采用 也称二进制无需编译可以直接使用 无法设定个人设置开关功能 软件包示例 认识ROM包 2源码包 source code 需要经过GCC,C编辑环境编译才能运行 可以设定个人设置&…...

Web渗透编程语言基础
Web渗透初学者JavaScript专栏汇总-CSDN博客 Web渗透Java初学者文章汇总-CSDN博客 一 Web渗透PHP语言基础 PHP 教程 | 菜鸟教程 (runoob.com) 一 PHP 语言的介绍 PHP是一种开源的服务器端脚本语言,它被广泛用于Web开发领域。PHP可以与HTML结合使用,创建动态网页。 PHP的特…...
Vue-router 路由的基本使用
Vue-router是一个Vue的插件库,专门用于实现SPA应用,也就是整个应用是一个完整的页面,点击页面上的导航不会跳转和刷新页面。 一、安装Vue-router npm i vue-router // Vue3安装4版本 npm i vue-router3 // Vue2安装3版本 二、引入…...
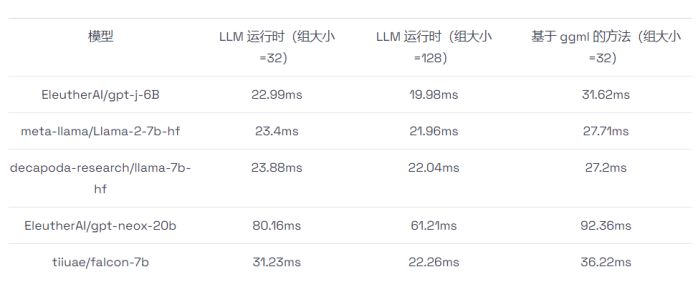
如何在CPU上进行高效大语言模型推理
大语言模型(LLMs)已经在广泛的任务中展示出了令人瞩目的表现和巨大的发展潜力。然而,由于这些模型的参数量异常庞大,使得它们的部署变得相当具有挑战性,这不仅需要有足够大的内存空间,还需要有高速的内存传…...
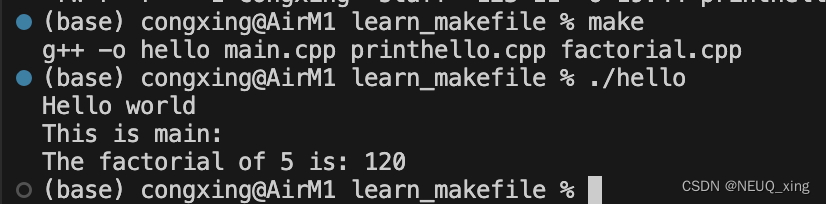
简简单单入门Makefile
笔记来源:于仕琪教授:Makefile 20分钟入门,简简单单,展示如何使用Makefile管理和编译C代码 操作环境 MacosVscode 前提准备 新建文件夹 mkdir learn_makefile新建三个cpp文件和一个头文件 // mian.cpp #include <iostrea…...
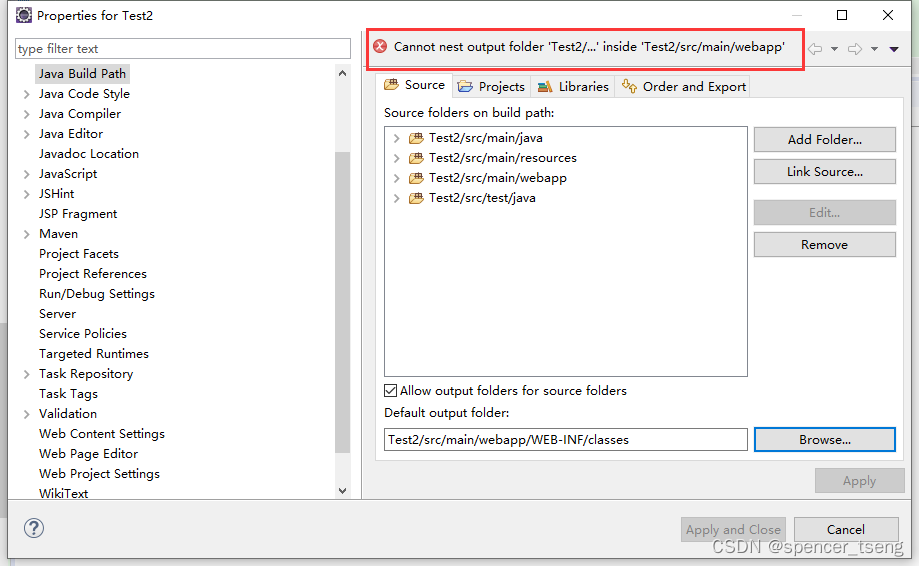
New Maven Project
下面两个目录丢失了: src/main/java(missing) src/test/java(missing) 换个JRE就可以跑出来了 变更目录...
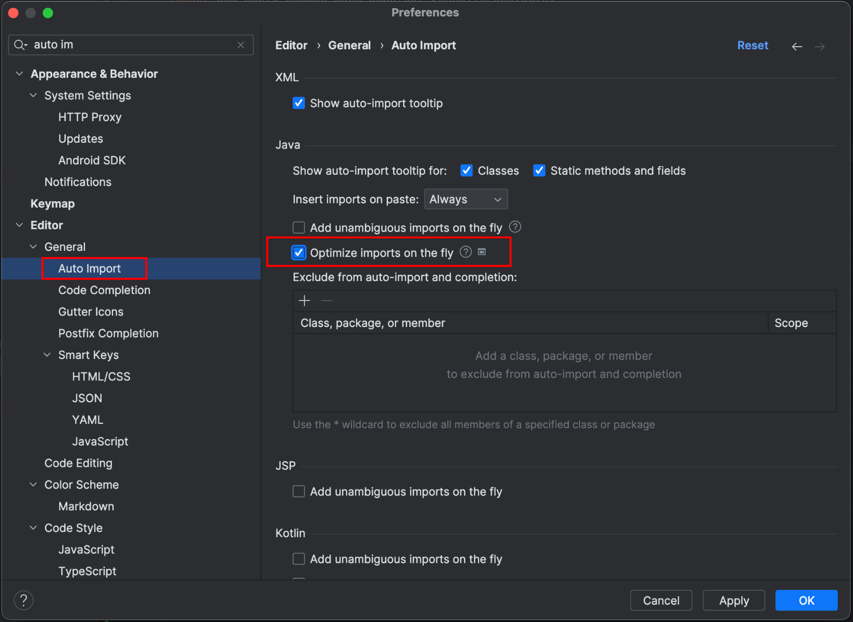
IDEA中如何移除未使用的import
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是全栈工…...
)
第18章_MySQL8新特性之CTE(公用表表达式)
文章目录 新特性:公用表表达式(cte)普通公用表表达式递归公用表表达式小 结 新特性:公用表表达式(cte) 公用表表达式(或通用表表达式)简称为CTE(Common Table Expressions)。CTE是一个命名的临时结果集&am…...

MySQL的备份恢复
数据备份的重要性 1.生产环境中,数据的安全至关重要 任何数据的丢失都会导致非常严重的后果。 2.数据为什么会丢失 :程序操作,运算错误,磁盘故障,不可预期的事件(地震,海啸)&#x…...
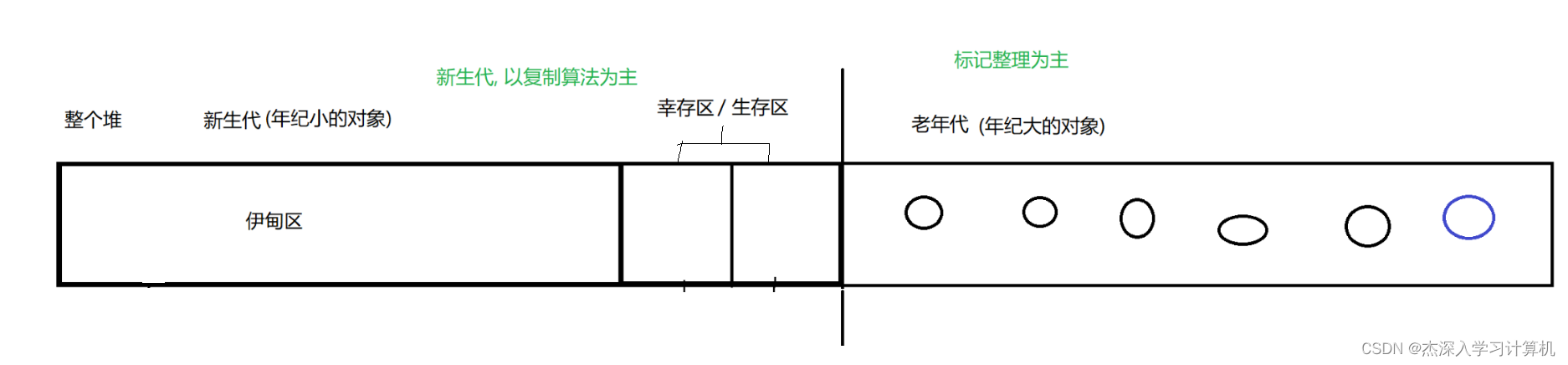
【JavaEE】JVM 剖析
JVM 1. JVM 的内存划分2. JVM 类加载机制2.1 类加载的大致流程2.2 双亲委派模型2.3 类加载的时机 3. 垃圾回收机制3.1 为什么会存在垃圾回收机制?3.2 垃圾回收, 到底实在做什么?3.3 垃圾回收的两步骤第一步: 判断对象是否是"垃圾"第二步: 如何回收垃圾 1. JVM 的内…...
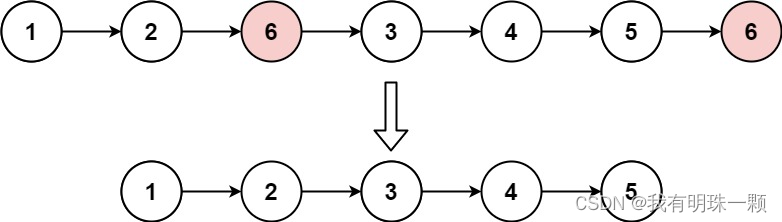
算法题:203. 移除链表元素(递归法、设置虚拟头节点法等3种方法)Java实现创建链表与解析链表
1、算法思路 讲一下设置虚拟头节点的那个方法,设置一个新节点指向原来链表的头节点,这样我们就可以通过判断链表的当前节点的后继节点值是不是目标删除值,来判断是否删除这个后继节点了。如果不设置虚拟头节点,则需要将头节点和后…...

ubuntu18.04 多版本opencv配置记录
多版本OpenCV过程记录 环境 ubuntu18.04 python2.7 python3.6 python3.9 opencv 3.2 OpenCV 4.4.0安装 Ubuntu18.04 安装 Opencv4.4.0 及 Contrib (亲测有效) 暂时不清楚Contrib的作用,所以没安装,只安装最基础的 下载opencv4.4.0并解压 opencv下载…...

Spring Security—OAuth 2.0 资源服务器的多租户
一、同时支持JWT和Opaque Token 在某些情况下,你可能需要访问两种令牌。例如,你可能支持一个以上的租户,其中一个租户发出JWT,另一个发出 opaque token。 如果这个决定必须在请求时做出,那么你可以使用 Authenticati…...

VB.NET—窗体引起的乌龙事件
目录 前言: 过程: 总结: 升华: 前言: 分享一个VB.NET遇到的一个问题,开始一直没有解决,这个问题阻碍了很长时间,成功的变成我路上的绊脚石,千方百计的想要绕过去,但事与愿违怎么也绕不过去,因为运行不了…...

批量新增报错PSQLException: PreparedStatement can have at most 65,535 parameters.
报错信息: org.postgresql.util.PSQLException: PreparedStatement can have at most 65,535 parameters. Please consider using arrays, or splitting the query in several ones, or using COPY. Given query has 661,068 parameters ; SQL []; PreparedStatemen…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

基于窗口比较器与晶体管逻辑的可编程非线性电压指示器设计
1. 项目概述:打造一个可编程的“移动光点”电压指示器在电子制作和仪器仪表领域,我们经常需要一个直观的电压指示器。经典的LM3914点/条图显示驱动芯片大家都很熟悉,它能把一个模拟电压信号转换成10个LED的点亮状态,形成移动的光点…...