C++11 多线程学习笔记
1. thread — 线程篇
所需头文件:<thread>
1.1 构造函数
// 1 默认构造函数
thread() noexcept;
// 2 移动构造函数,把other的所有权转移给新的thread对象,之后 other 不再表示执行线程。
thread( thread&& other ) noexcept;
// 3 f参数可选:普通函数,类成员函数,匿名函数,仿函数
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args );
// 4 使用 =delete 显示删除拷贝构造, 不允许线程对象之间的拷贝
thread( const thread& ) = delete;
第三种创建: 创建线程对象,并在该线程中执行函数 f 中的业务逻辑,args 是要传递给函数 f 的参数
任务函数 f 的可选类型有很多,具体如下:
- 普通函数,类成员函数,匿名函数,仿函数(这些都是可调用对象类型)
- 可以是可调用对象包装器类型,也可以是使用绑定器绑定之后得到的类型(仿函数)
- 类成员函/变量作参数,
thread(类函数/成员地址, 类实例对象地址, 类函数参数),参数列表类似于 std::bind(),博客最后有实例
f 一般返回值指定为 void,因为子线程在调用这个函数的时候不会处理其返回值。
1.2 公共成员函数
get_id()
应用程序启动之后默认只有一个线程,这个线程一般称之为主线程或父线程,通过线程类创建出的线程一般称之为子线程,每个被创建出的线程实例都对应一个线程ID,这个ID是唯一的,可以通过这个ID来区分和识别各个已经存在的线程实例。
调用命名空间std::this_thread中的get_id()方法可以得到当前线程的线程ID,在主函数中调用即可得到主线程ID,在线程中调用即可得到子线程ID。
void func(){cout << "子线程: " << this_thread::get_id() << endl;
}
// main()
cout << "主线程: " << this_thread::get_id() << endl;
thread t(func); // 创建子线程
t.get_id(); // 在主函数中获得子线程ID
t.join();
当启动了一个线程(创建了一个thread对象)之后,在这个线程结束的时候(std::terminate()),我们如何去回收线程所使用的资源呢?thread库给我们两种选择:
- 加入式(join())
- 分离式(detach())
join()
join()字面意思是连接一个线程,意味着主动地等待线程的终止(线程阻塞)。在某个线程中通过子线程对象调用join()函数,调用这个函数的线程被阻塞,但是子线程对象中的任务函数会继续执行,当任务执行完毕之后,join()会清理当前子线程中的相关资源然后返回,同时,调用该函数的线程解除阻塞继续向下执行。join()函数在哪个线程中被执行,那么哪个线程就被阻塞。
// 子线程
void func(){cout << "子线程 " << endl;
}
// 主线程
cout << "主线程" << endl;
thread t(func); // 创建子线程
t.join(); // main线程中调用线程 t 的join函数,main线程随之被阻塞,不会向下执行
int x = 1;
调用 join() 有两种情况:
- 如果任务函数
func()还没执行完毕,主线程阻塞,直到子线程执行完毕,主线程解除阻塞,继续向下运行 - 如果任务函数
func()已经执行完毕,主线程不会阻塞,继续向下运行
总的来说,t.join() 语句使得只有在子线程 t 完成执行之后,才能执行 int x = 1; 语句。
线程执行完毕后,join() 会清理(回收)当前子线程的相关资源
detach()
detach() 函数的作用是进行线程分离,分离主线程和创建出的子线程。在线程分离之后,主线程退出也会一并销毁创建出的所有子线程,在主线程退出之前,它可以脱离主线程继续独立的运行,任务执行完毕之后,这个子线程会自动释放自己占用的系统资源。
注意事项:线程分离函数detach()不会阻塞线程,子线程和主线程分离之后,在主线程中就不能再对这个子线程做任何控制了,比如调用get_id()获取子线程的线程ID。
joinable()
joinable() 函数用于判断主线程和子线程是否处理关联(连接)状态,一般情况下,二者之间的关系处于关联状态,该函数返回一个布尔类型,有连接关系返回值为 true,否则返回 false。
实例:
void foo(){cout << "thread starts" << endl;
}thread t; // 在创建的子线程对象的时候,如果没有指定任务函数,那么子线程不会启动,主线程和这个子线程也不会进行连接
cout << "before starting, joinable: " << t.joinable() << endl; // 0t = thread(foo); // 指定了任务函数,子线程启动并执行任务,主线程和这个子线程自动连接成功
cout << "after starting, joinable: " << t.joinable() << endl;// 1t.join();// 线程t任务处理完毕后,这时join()会清理(回收)当前子线程的相关资源,所以这个子线程和主线程的连接也就断开了
// 因此,调用join()之后再调用joinable()会返回false。
cout << "after joining, joinable: " << t.joinable() << endl;// 0thread t1(foo);// 在创建的子线程对象的时候,如果指定了任务函数,子线程启动并执行任务,主线程和这个子线程自动连接成功
cout << "after starting, joinable: " << t1.joinable() << endl;// 1
t1.detach();// 子线程调用了detach()函数之后,父子线程分离,同时二者的连接断开,调用joinable()返回false
cout << "after detaching, joinable: " << t1.joinable() << endl;// 0
operator=
线程中的资源是不能被复制的 ,因此通过=操作符进行赋值操作最终并不会得到两个完全相同的对象。
// move (1)
thread& operator= (thread&& other) noexcept;
// copy [deleted] (2)
thread& operator= (const other&) = delete;
实例:
void foo(){cout << "thread starts" << endl;
}thread t1(foo); // 因为下边有资源所有权转移,这里的t1线程并不会执行
t1.join(); // error, 同一份资源不能回收两次,会抛出异常
thread t2(move(t1)); // 将线程t1的资源所有权的转移给t2
t2.join(); // t2线程执行完进行,join() 会进行资源回收
1.3 静态函数(获取CPU核心数)
thread 线程类还提供了一个静态方法,用于获取当前计算机的CPU核心数,根据这个结果在程序中创建出数量相等的线程,每个线程独自占有一个CPU核心,这些线程就不用分时复用CPU时间片,此时程序的并发效率是最高的。
int num = thread::hardware_concurrency();
cout << "CPU number: " << num << endl;
1.4 命名空间 - this_thread
get_id()
关于命名空间里的 get_id() 前别已经涉及过,这里就不再赘述。
简答来说直接调用可以得到当前线程的线程ID,this_thread::get_id()
sleep_for()
进程创建完成后有 5 种状态,同样地线程被创建后也有这五种状态:创建态,就绪态,运行态,阻塞态(挂起态),退出态(终止态) ,关于状态之间的转换是一样的。
命名空间this_thread中提供了一个休眠函数sleep_for(),调用这个函数的线程会马上从运行态变成阻塞态并在这种状态下休眠一定的时长,因为阻塞态的线程已经让出了CPU资源,代码也不会被执行,所以线程休眠过程中对CPU来说没有任何负担。
参数需要指定一个休眠时长,一般配合<chrono> 库使用,时间长度 duration类型
#include <chrono>
#include <thread>
void func(){this_thread::sleep_for(chrono::seconds(1)); // 当前线程进入阻塞态1s
}
thread t(func);
t.join();
sleep_until()
指定线程到某一个指定的时间点time_point类型,之后解除阻塞
作用其实和sleep_for() 差不多
void func(){auto now = chrono::system_clock::now();// 获取当前系统时间点chrono::seconds sec(2);// 时间间隔为2sthis_thread::sleep_until(now + sec);// 当前时间点之后休眠两秒
}
thread t(func);
t.join();
yeild()
调用yeild函数会使处于运行态的线程会主动让出自己已经抢到的CPU时间片,最终变为就绪态
使用这个函数的时候需要注意一点,线程调用了yield()之后会主动放弃CPU资源,但是这个变为就绪态的线程会马上参与到下一轮CPU的抢夺战中,不排除它能继续抢到CPU时间片的情况,这是概率问题。
结论:
std::this_thread::yield()的目的是避免一个线程长时间占用CPU资源,从而导致多线程处理性能下降std::this_thread::yield()是让当前线程主动放弃了当前自己抢到的CPU资源,但是在下一轮还会继续抢
2. 线程同步篇
2.1 call_once
在某些特定情况下,某些函数只能在多线程环境下调用一次,比如:要初始化某个对象,而这个对象只能被初始化一次,就可以使用std::call_once()来保证函数在多线程环境下只能被调用一次。使用call_once()的时候,需要一个once_flag作为call_once()的传入参数。
once_flag g_flag; // 全局定义
std::call_once(once_flag flag, 回调函数,回调函数的参数);
多线程操作过程中,std::call_once() 内部的回调函数只会被执行一次
#include <mutex>once_flag g_flag;
void do_once(int a){cout << "age: " << a << endl;
}
void do_something(int age){static int num = 1;call_once(g_flag, do_once, 19);cout << "do_something() function num = " << num++ << endl;
}thread t1(do_something, 20);
thread t2(do_something, 19);
t1.join();
t2.join();
虽然运行的两个线程中都执行了任务函数do_something(),但是call_once()中指定的回调函数只被执行了一次。
2.1 利用互斥锁(mutex)进行线程同步
进行多线程编程,如果多个线程需要对同一块内存进行操作,比如:同时读、同时写、同时读写对于后两种情况来说,如果不做任何的人为干涉就会出现各种各样的错误数据。这是因为线程在运行的时候需要先得到CPU时间片,时间片用完之后需要放弃已获得的CPU资源,这种并发执行是 “执行–简短–执行” 的间断性活动,并且由于多线程可以共享变量,这样失去了封闭性,导致运行的结果具有不可再现性。
解决多线程数据混乱的方案就是进行线程同步,最常用的就是互斥锁,在C++11中一共提供了四种互斥锁:
std::mutex:独占的互斥锁,不能递归使用std::timed_mutex:带超时的独占互斥锁,不能递归使用std::recursive_mutex:递归互斥锁,不带超时功能std::recursive_timed_mutex:带超时的递归互斥锁
互斥锁在有些资料中也被称之为互斥量,二者是一个东西。
线程同步大概思路
使用互斥锁进行线程同步的主要分为以下几步:
- 1)找到多个线程操作的共享资源(全局变量、堆内存、类成员变量等),也可以称之为
临界资源 - 2)找到和共享资源有关的上下文代码,也就是
临界区(下图中的黄色代码部分) - 3)在临界区的上边调用互斥锁类的
lock()方法 - 4)在临界区的下边调用互斥锁的
unlock()方法 - 5)线程同步的目的是让多线程按照顺序依次执行临界区代码,这样做线程对共享资源的访问就从并行访问变为了线性访问,访问效率降低了,但是保证了数据的正确性。
std::mutex(普通互斥锁)
lock()
lock()函数用于给临界区加锁,并且只能有一个线程获得锁的所有权,它有阻塞线程的作用。
独占互斥锁对象有两种状态:锁定和未锁定。如果互斥锁是打开的,调用lock()函数的线程会得到互斥锁的所有权,并将其上锁,其它线程再调用该函数的时候由于得不到互斥锁的所有权,就会被lock()函数阻塞。当拥有互斥锁所有权的线程将互斥锁解锁,此时被lock()阻塞的线程解除阻塞,抢到互斥锁所有权的线程加锁并继续运行,没抢到互斥锁所有权的线程继续阻塞。
try_lock()
除了使用lock()还可以使用try_lock()获取互斥锁的所有权并对互斥锁加锁,二者的区别在于try_lock() 不会阻塞线程,lock() 会阻塞线程:
- 如果互斥锁是未锁定状态,得到了互斥锁所有权并加锁成功,函数返回 true
- 如果互斥锁是锁定状态,无法得到互斥锁所有权加锁失败,函数返回 false
try_lock() 如果被调用时没有获得锁则直接返回 false,一个尝试动作,返回 false 不会阻塞线程。
unlock()
当互斥锁被锁定之后可以通过unlock()进行解锁,但是需要注意的是只有拥有互斥锁所有权的线程也就是对互斥锁上锁的线程才能将其解锁,其它线程是没有权限做这件事情的。
当线程对互斥锁对象加锁,并且执行完临界区代码之后,一定要使用这个线程对互斥锁解锁,否则最终会造成线程的死锁。死锁之后当前应用程序中的所有线程都会被阻塞,并且阻塞无法解除,应用程序也无法继续运行。
线程同步实例
int g_num = 0; // 为 g_num_mutex 所保护
mutex g_num_mutex;void slow_increment(int id){for (int i = 0; i < 3; ++i){g_num_mutex.lock(); // 临界区的上边加锁++g_num;cout << id << " => " << g_num << endl;g_num_mutex.unlock(); // // 临界区的下边解锁this_thread::sleep_for(chrono::seconds(1));}
}thread t1(slow_increment, 0);
thread t2(slow_increment, 1);
t1.join();
t2.join();
另外需要注意一点:
- 在所有线程的任务函数执行完毕之前,互斥锁对象是不能被析构的,一定要在程序中保证这个对象的可用性。
- 互斥锁的个数和共享资源的个数相等,也就是说
每一个共享资源都应该对应一个互斥锁对象。互斥锁对象的个数和线程的个数没有关系。
std::lock_guard<> (模板类简化互斥锁写法)
lock_guard 是C++11新增的一个模板类,使用这个类,可以简化互斥锁lock()和unlock()的写法,同时也更安全。
lock_guard 工作原理:在lock_guard的构造函数里调用了mutex的lock()成员函数,在lock_guard的析构函数里调用了mutex的unlock()成员函数。
也就是lock_guard在使用上面提供的这个构造函数构造对象时,会自动锁定互斥量,而在退出作用域后进行析构时就会自动解锁,从而保证了互斥量的正确操作,避免忘记unlock()操作而导致线程死锁。
lock_guard 使用了RAII技术,就是在类构造函数中分配资源,在析构函数中释放资源,保证资源出了作用域就释放。
lock_guard<mutex> lock(g_num_mutex); // 用已经定义好的锁初始化类模板
int g_num = 0; // 为 g_num_mutex 所保护
mutex g_num_mutex;void slow_increment(int id){for (int i = 0; i < 3; ++i) {// 使用哨兵锁管理互斥锁lock_guard<mutex> lock(g_num_mutex); ++g_num;cout << id << " => " << g_num << endl;this_thread::sleep_for(chrono::seconds(1));}
}thread t1(slow_increment, 0);
thread t2(slow_increment, 1);
t1.join();
t2.join();
这种方式看起来方便,但是也有弊端,在上面的示例程序中整个for循环的体都被当做了临界区,多个线程是线性的执行临界区代码的,因此临界区越大程序效率越低。把一次for循环的所有资源当成临界区,而mutex可以只锁定一部分为临界区。
std::unique_lock<> (比 lock_guard 更灵活)
unique_lock 是一个类模板,它与lock_guard 一样,在用互斥锁初始化完之后,自动进行加锁解锁,但是比lock_guard 更灵活。lock_guard 里边并没有封装功能函数,但是 unique_lock 里边封装了很多函数。
// 无第二参数
unique_lock<mutex> u_mutex(g_num_mutex);// 如果拿不到锁就一直卡在这(执行流程不往下走)unique_lock<mutex> u_mutex(g_num_mutex,第二参数);
这里的g_num_mutex 是 mutex 类型的变量名
unique_lock 的第二参数有三个:
std::adopt_lock,作用暂时没弄懂std::try_to_lock,初始化时尝试加锁,如果没有成功则立刻返回,不进行阻塞std::defer_lock,初始化完并不加锁,可自行决定加锁时机
int g_num = 0; // 为 g_num_mutex 所保护
mutex g_num_mutex;
void test() {unique_lock<mutex> u_mutex(g_num_mutex, std::defer_lock); // 初始化完并没有加锁u_mutex.lock(); // 可以自行加锁g_num++;u_mutex.unlock();// 可删除的语句,unique_lock能够自动解锁,也可以手动解锁
}
std::recursive_mutex(允许互斥锁递归)
递归互斥锁std::recursive_mutex允许同一线程多次获得互斥锁,可以用来解决同一线程需要多次获取互斥量时死锁的问题,在下面的例子中使用独占非递归互斥量会发生死锁:
struct Calculate{Calculate() : m_i(6) {}void mul(int x){//lock_guard<mutex> locker(m_mutex);lock_guard<recursive_mutex> locker(m_mutex);m_i *= x;}void div(int x){//lock_guard<mutex> locker(m_mutex);lock_guard<recursive_mutex> locker(m_mutex);m_i /= x;}void both(int x, int y){//lock_guard<mutex> locker(m_mutex);lock_guard<recursive_mutex> locker(m_mutex);mul(x);div(y);}int m_i;//mutex m_mutex;recursive_mutex m_mutex;
};Calculate cal;
cal.both(6, 3); // 调用后就会发生死锁
在both()中已经对互斥锁加锁了,继续调用mult()函数,已经得到互斥锁所有权的线程再次获取这个互斥锁的所有权就会造成死锁(在C++中程序会异常退出,使用C库函数会导致这个互斥锁永远无法被解锁,最终阻塞所有的线程)。要解决这个死锁的问题,一个简单的办法就是使用递归互斥锁std::recursive_mutex,它允许一个线程多次获得互斥锁的所有权。
虽然递归互斥锁可以解决同一个互斥锁频繁获取互斥锁资源的问题,但是还是建议少用,主要原因如下:
- 使用递归互斥锁的场景往往都是可以简化的,使用递归互斥锁很容易放纵复杂逻辑的产生,从而导致bug的产生
- 递归互斥锁比非递归互斥锁效率要低一些。
- 递归互斥锁虽然允许同一个线程多次获得同一个互斥锁的所有权,但最大次数并未具体说明,一旦超过一定的次数,就会抛出
std::system错误。
std::timed_mutex (不像lock一样一直阻塞)
std::timed_mutex 是超时独占互斥锁,主要是在获取互斥锁资源时增加了超时等待功能,因为不知道获取锁资源需要等待多长时间,为了保证不一直等待下去,设置了一个超时时长,超时后线程就可以解除阻塞去做其他事情了。
std::timed_mutex比std::_mutex多了两个成员函数:try_lock_for()和try_lock_until()。两个函数是对 lock() 函数的延申,返回true 时就代表已经获取到互斥锁资源。
try_lock_for()函数是当线程获取不到互斥锁资源的时候,在给定的时间长度内,允许线程为尝试获得资源而阻塞。参数对应sleep_for()try_lock_until()函数是当线程获取不到互斥锁资源的时候,在给定的时间节点之前,允许线程为尝试获得资源而阻塞。参数对应sleep_until()
关于两个函数的返回值(bool):在未达到限定情况时,得到互斥锁的所有权之后,函数会马上解除阻塞,返回 true;如果阻塞的时长用完或者到达指定的时间点之后,函数也会解除阻塞,返回 false。
std::recursive_timed_mutex
关于递归超时互斥锁std::recursive_timed_mutex的使用方式和std::timed_mutex是一样的,只不过它可以允许一个线程多次获得互斥锁所有权,而std::timed_mutex只允许线程获取一次互斥锁所有权。另外,递归超时互斥锁std::recursive_timed_mutex也拥有和std::recursive_mutex一样的弊端,不建议频繁使用。
2.3 使用条件变量进行线程同步(配合锁才行)
通过实例来理解引用条件变量的意义
#include <iostream>
#include <thread>
#include <mutex>
#include <list>
using namespace std;
// 模拟简化的网络游戏服务器
// 线程1:从玩家那里收集发送来的命令(数据),并把这些数据写到一个队列中
// 线程2:从队列中取出命令,进行解析,然后执行命令对应的动作class A {
public:// 把收到的消息(玩家命令)放入到一个队列的线程void inMsgRecvQueue() {for (int i = 0; i < 10; ++i) {unique_lock<mutex> sbguard1(my_mutex);cout << "向消息队列插入一个元素:" << i << '\n';msgRecvQueue.push_back(i);//this_thread::sleep_for(chrono::milliseconds(1300));}}bool outMsgLuLproc(int& command) {if (msgRecvQueue.empty()) { // 队列为空没必要去读取return false;}unique_lock<mutex> sbguard1(my_mutex);if (!msgRecvQueue.empty()) {command = msgRecvQueue.front();msgRecvQueue.pop_front();return true;}return false;}void outMsgRecvQueue() {int command = 0;for (int i = 0; i < 200; ++i) {// 不断尝试去队列中取元素// 队列为空时,不断调用outMsgLuLproc函数,也是一定的资源浪费bool res = outMsgLuLproc(command);if (res) {cout << "从消息队列中取出一个元素\n";}else {cout << "目前消息队列是空的\n";}}}
private:list <int> msgRecvQueue; // 命令队列mutex my_mutex;
};int main() {A myobj;thread my_out_thread(&A::outMsgRecvQueue, &myobj);thread my_in_thread(&A::inMsgRecvQueue, &myobj);my_out_thread.join();my_in_thread.join();return 0;
}
my_in_thread 线程中会有大量的 outMsgLuLproc() 函数调用,尝试去取队列中的命令,但是大部分的调用都是徒劳的。为了避免不断地判断消息队列是否为空,而改为当消息队列不为空的时候做一个通知,这样得到通知后再去取数据。这时候就引用了 std::condition_variable ,这是一个类,一个和条件相关的类,用于等待一个条件的达成。
两种条件变量
条件变量是C++11提供的另外一种用于等待的同步机制,它能阻塞一个或多个线程,直到收到另外一个线程发出的通知或者超时时,才会唤醒当前阻塞的线程。条件变量需要和互斥量配合起来使用,C++11提供了两种条件变量:
condition_variable:需要配合std::unique_lock<std::mutex>进行wait操作,也就是阻塞线程的操作,而且可以在任何时候自由地释放互斥锁。condition_variable_any:可以和任意带有lock()、unlock()语义的mutex搭配使用,也就是说有四种:std::mutex、std::timed_mutex、std::recursive_mutex、std::recursive_timed_mutex
condition_variable
所需头文件: <condition_variable>
condition_variable 的成员函数主要分为两部分:线程等待(阻塞)函数 和线程通知(唤醒)函数
等待函数
调用wait()函数的线程会被阻塞,下边给出 wait 函数形式
void wait (unique_lock<mutex>& lck); // 调用该函数的线程直接被阻塞template <class Predicate>
void wait (unique_lock<mutex>& lck, Predicate pred);
// 关于 pred
// 该函数的第二个参数是一个判断条件,是一个返回值为布尔类型的函数
// 表达式返回false当前线程被阻塞,表达式返回true当前线程不会被阻塞,继续向下执行
// 该参数可以传递一个有名函数的地址,也可以直接指定一个匿名函数
独占的互斥锁对象不能直接传递给wait()函数,需要通过模板类unique_lock进行二次处理
还有两个与 wait() 函数功能相同的函数
wait_for()函数,指定阻塞时长wait_until()函数,指定让线程阻塞到某一个时间点
假设阻塞期间内的线程没有被其他线程唤醒,当到条件后,线程就会自动解除阻塞,继续向下执行。
通知函数
notify_one():唤醒一个被当前条件变量阻塞的线程,如果有多个wait线程,唤醒哪个其实是不确定的notify_all():唤醒全部被当前条件变量阻塞的线程
condition_variable_any
condition_variable_any用法与condition_variable基本相同,其wait()函数可以配合四种类型的互斥量直接作为参数,condition_variable对象只能配合unique_lock<mutex>,然后再传入 wait 函数。除此之外,它们的用法是相同的。
队列模拟多线程读写数据实例(condition_variable)
本质上就是生产者消费者模型,使用条件变量进行同步
#include <iostream>
#include <thread>
#include <mutex>
#include <list>
using namespace std;
// 模拟简化的网络游戏服务器
// 线程1:从玩家那里收集发送来的命令(数据),并把这些数据写到一个队列中
// 线程2:从队列中取出命令,进行解析,然后执行命令对应的动作class A {
public:// 把收到的消息(玩家命令)放入到一个队列的线程void inMsgRecvQueue() {for (int i = 0; i < 10000; ++i) {unique_lock<mutex> u_mutex(my_mutex);cout << "向消息队列插入一个元素:" << i << '\n';msgRecvQueue.push_back(i);my_cond.notify_one();// 尝试把处于阻塞在wait()的线程唤醒,但是根据函数名,显然只会唤醒一个数据}}void outMsgRecvQueue() {int command = 0;for (; 1; ) {// 不断尝试去队列中取元素unique_lock<mutex> u_mutex(my_mutex); // condition_variable 需要配合unique_lock使用// 如果wait()第二个参数的lambda表达式返回true,那么wait()直接返回// 返回false,那么wait()将解锁互斥量并在此句阻塞,直至有线程调用notigy_one() 通知为止// 如果不指定第二个参数,那么跟lambda表达式返回false的情况一样,直接等待其他线程调用notify_one()my_cond.wait(u_mutex, [this] {if (msgRecvQueue.empty()) return false; // 存在虚假唤醒,万无一失写法return true;});cout << "thread id = " << this_thread::get_id() << endl;// 现在互斥量是锁着的,执行到此队列里一定有数据command = msgRecvQueue.front();msgRecvQueue.pop_front();cout << "取出元素 " << command << endl;u_mutex.unlock(); // 做完事情可以手动解锁,体现出unique_lock的灵活性// 让刚得到锁的线程睡一下,两个线程就交替取数据了//this_thread::sleep_for(chrono::milliseconds(200));}}
private:list <int> msgRecvQueue; // 命令队列mutex my_mutex;condition_variable my_cond;
};int main() {A myobj;// 搞两个取数据的线程,运行可以发现 notify_one() 只会唤醒一个thread my_out_thread1(&A::outMsgRecvQueue, &myobj);thread my_out_thread2(&A::outMsgRecvQueue, &myobj);thread my_in_thread(&A::inMsgRecvQueue, &myobj);my_out_thread1.join();my_out_thread2.join();my_in_thread.join();return 0;
}
用于生产者和消费者模型的大致过程
条件变量通常用于生产者和消费者模型,大致使用过程如下:
- 拥有条件变量的线程获取互斥量
- 消费者:循环检查某个条件,如果条件不满足阻塞当前线程,否则线程继续向下执行
\quad 产品的数量达到上限,生产者阻塞,否则生产者一直生产
\quad 产品的数量为零,消费者阻塞,否则消费者一直消费 - 生产者:条件满足之后,可以调用
notify_one()或者notify_all()唤醒一个或者所有被阻塞的线程
\quad 由消费者唤醒被阻塞的生产者,生产者解除阻塞继续生产
\quad 由生产者唤醒被阻塞的消费者,消费者解除阻塞继续消费
生产者和消费者模型实例(condition_variable)
无限进行取放的实例,加上睡眠可以让取放交替进行
#include <iostream>
#include <thread>
#include <mutex>
#include <list>
#include <functional>
#include <condition_variable>
using namespace std;class SyncQueue
{
public:SyncQueue(int maxSize) : m_maxSize(maxSize) {}void put(){for (int i = 0; ; ++i) {if (i >= m_maxSize) i = 0;unique_lock<mutex> locker(m_mutex); // 配合unique_lock使用m_notFull.wait(locker, [this]() {return m_queue.size() != m_maxSize;});m_queue.push_back(i);cout << i << " 被生产" << endl;m_notEmpty.notify_one();locker.unlock();//this_thread::sleep_for(chrono::milliseconds(800));}}void take(){while (1) {unique_lock<mutex> locker(m_mutex);m_notEmpty.wait(locker, [this]() {return !m_queue.empty();});int x = m_queue.front();m_queue.pop_front();m_notFull.notify_one();cout << x << " 被消费" << endl;locker.unlock();//this_thread::sleep_for(chrono::milliseconds(800));}}private:list<int> m_queue; // 存储队列数据mutex m_mutex; // 互斥锁condition_variable m_notEmpty; // 不为空的条件变量condition_variable m_notFull; // 没有满的条件变量int m_maxSize; // 任务队列的最大任务个数
};int main()
{SyncQueue taskQ(50);thread my_put(&SyncQueue::put, &taskQ);thread my_take(&SyncQueue::take, &taskQ);my_put.join();my_take.join();return 0;
}
2.4 使用原子变量实现线程同步(不需要锁)
C++11提供了一个原子类型std::atomic<T>,这是一个类模板,可以用来封装某类型的值,通过这个原子类型管理的内部变量就可以称之为原子变量,我们可以给原子类型指定bool、char、int、long、指针等类型作为模板参数(不支持浮点类型和复合类型)。
原子指的是一系列不可被CPU上下文交换的机器指令,这些指令组合在一起就形成了原子操作。在多核CPU下,当某个CPU核心开始运行原子操作时,会先暂停其它CPU内核对内存的操作,以保证原子操作不会被其它CPU内核所干扰。
由于原子操作是通过指令提供的支持,因此它的性能相比锁和消息传递会好很多。相比较于锁而言,原子类型不需要开发者处理加锁和释放锁的问题,同时支持修改,读取等操作,还具备较高的并发性能,几乎所有的语言都支持原子类型。
可以看出原子类型是无锁类型,但是无锁不代表无需等待,因为原子类型内部使用了CAS循环,当大量的冲突发生时,该等待还是得等待!但是总归比锁要好。CAS全称是Compare and swap, 它通过一条指令读取指定的内存地址,然后判断其中的值是否等于给定的前置值,如果相等,则将其修改为新的值。
C++11内置了整形的原子变量,这样就可以更方便的使用原子变量了。在多线程操作中,使用原子变量之后就不需要再使用互斥量来保护该变量了,用起来更简洁。因为对原子变量进行的操作只能是一个原子操作(atomic operation),原子操作指的是不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何的上下文切换。多线程同时访问共享资源造成数据混乱的原因就是因为CPU的上下文切换导致的,使用原子变量解决了这个问题,因此互斥锁的使用也就不再需要了。
所需头文件:<atomic>
构造函数
atomic() noexcept = default; // 默认无参构造函数
constexpr atomic( T desired ) noexcept; // 使用 desired 初始化原子变量的值
atomic( const atomic& ) = delete; // 使用=delete显示删除拷贝构造函数, 不允许进行对象之间的拷贝std::atomic<int> g_mycount = 0;
// 也可以这样写,std::atomic<int> g_mycount(0);
// 封装一个类型为int的值,可以像操作int变量一样操作 g_mycount 这个原子变量// 原子操作
g_mycount+; ++g_mycount; g_mycount += 1; g_mycount -= 1;
g_mycount &= 1; g_mycount |= 1; g_mycount ^= 1;
// 不是原子操作
g_mycount = g_mycount + 1;
原子操作针对的一个变量,互斥量针对的是代码片段
3. 线程异步
C++11中增加的线程类,使得我们能够非常方便的创建和使用线程,但有时会有些不方便,比如需要获取线程返回的结果,就不能通过join()得到结果,只能通过一些额外手段获得,比如:定义一个全局变量,在子线程中赋值,在主线程中读这个变量的值,整个过程比较繁琐。C++提供的线程库中提供了一些类用于访问异步操作的结果。
我们去星巴克买咖啡,因为都是现磨的,所以需要等待,但是我们付完账后不会站在柜台前死等,而是去找个座位坐下来玩玩手机打发一下时间,当店员把咖啡磨好之后,就会通知我们过去取,这就叫做异步。
- 顾客(主线程)发起一个任务(子线程磨咖啡),磨咖啡的过程中顾客去做别的事情了,有两条时间线(
异步) - 顾客(主线程)发起一个任务(子线程磨咖啡),磨咖啡的过程中顾客没去做别的事情而是死等,这时就只有一条时间线(
同步),此时效率相对较低。
因此多线程程序中的任务大都是异步的,主线程和子线程分别执行不同的任务,如果想要在主线中得到某个子线程任务函数返回的结果可以使用C++11提供的std:future类,这个类需要和其他类或函数搭配使用。
异步操作的主要目的是让调用方法的主线程不需要同步等待调用函数,从而可以让主线程继续执行它下面的代码。因此异步操作无须额外的线程负担,使用回调的方式进行处理。在设计良好的情况下,处理函数可以不必或者减少使用共享变量,减少了死锁的可能。当需要执行I/O操作时,使用异步操作比使用线程+同步 I/O操作更合适。
异步和多线程并不是一个同等关系,异步是目的,多线程是实现异步的一个手段。实现异步可以采用多线程或交给另外的进程来处理。
C++11中的异步操作主要有std::future、std::async、std::promise、std::packaged_task。
3.1 std:future(底层对象)
构造函数
std::future 对象是std::async、std::promise、std::packaged_task的底层对象,用来传递其他线程中操作的数据结果,它是一个模板类,可以存储任意指定类型的数据。
future() noexcept; //默认无参构造函数future( future&& other ) noexcept; // 移动构造函数,转移资源的所有权future( const future& other ) = delete; // 使用=delete显示删除拷贝构造函数, 不允许进行对象之间的拷贝
通过构造函数可知,future 类不允许进行对象之间的拷贝,但是由移动构造函数可知,传入右值可以转移所有权,因此 = 右边是右值也可以转移资源的所有权。
成员函数
get():阻塞当前线程,子线程的数据就绪后解除阻塞就能得到传出的数值。wait():阻塞当前线程,子线程执行完毕时接触阻塞wait_until():阻塞一定的时长wait_for():阻塞到某一指定的时间点
当wait_until()和wait_for()函数返回之后,并不能确定子线程当前的状态,因此我们需要判断函数的返回值,这样就能知道子线程当前的状态了。
实例:
std::future<int> result = std::async(work, 1);
std::future_status status = result.wait_for(chrono::seconds(1));if (status == std::future_status::timeout) {// 超时线程还没执行完cout << "超时线程没有执行完毕" << endl;
}
else if (status == std::future_status::ready) {// 线程返回成功cout << "线程成功执行完并返回" << endl;
}
else if (status == std::future_status::deferred) { // 如果 async 的第一个参数被设置为 std::launch::deferred,则本条件成立cout << "线程被延迟执行" << endl;
}
3.2 std::async (创建异步线程)
针对需要线程返回一个值的情况,返回值是一个 std::future 类型。
std::thread 是直接的创建线程,在系统资源紧张的情况下,调用 std::thread 可能会导致创建线程失败,程序也会随之崩溃。
而std::async 其实是叫创建异步任务,它可能创建线程,也可能不创建线程。同时 std::async 还有一个优点:这个异步任务返回的值程序员可以通过 std::future 对象在将来某个时刻(程序执行完)直接拿到手。当然,如果不关注异步任务的结果,只是简单地等待任务完成的话,可以调用 std::future 类的wait()或者wait_for()方法,这样功能就和 std::thread 差不多了。
另外,std::async 不需要 join()
int work(int x) {return x;
}
// 根据返回值确定future模板参数
std::future<int> result = std::async(work, 1); // 流程并不会卡在这里
cout << result.get() << endl; // 卡在这里等待线程执行完,但是这个 get 只能使用一次
如果类的成员作线程入口函数,参见本文开头的线程构造函数,async(类函数/成员地址, 类实例对象地址, 类函数参数)
async额外参数
std::launch::deferred:该参数表示线程入口函数的执行被延迟到std::future的wait或者get函数调用时,如果都没有被调用,那么这个线程就不执行了std::launch::async:强制立即执行
std::future<int> result = std::async(std::launch::deferred, work, 1); // 流程并不会卡在这里
result.get(); // 线程由此开始执行
3.3 std::packaged_task (保存的是一个可调用对象)
从字面意思理解,std::packaged_task 是打包任务,或者说把任务包装起来的意思。
这是一个类模板,它的模板参数是各种可调用对象。通过 std::packaged_task 把各种可调用对象包装起来,方便将来作为线程入口函数来调用。需要配合 std::ref,将包装完的对象转化为引用包装器。
通过调用get_future()方法就可以得到一个std::future对象,基于这个对象就可以得到传出的数据了。
实例:
int work(int x) {return x;
}
std::packaged_task<int(int)> mypt(work); // 1. 把函数work包装起来// 这里的ref作用是将一个对象转换成一个引用包装器对象
std::thread t1(std::ref(mypt), 1); // 2. 以引用的形式,作为参数传入线程, 第二参数作为线程入口函数的参数
t1.join(); // thread创建的线程需要 join() 一下std::future<int> result = mypt.get_future(); // 3. future对象里含有线程入口函数的返回结果
// 这里用 result 保持 work() 函数的返回结果
cout << result.get() << endl; // 4. 输出结果
thread 启动的线程记得要 join() 一下
如果把上面代码中的 join 注释掉,虽然程序会卡在 result.get() 行一直等待线程返回,但是整个程序会报异常。当然,把 join 放到 get 之后也是可以的。
join和get谁先出现,执行流程就会卡在其所在的行等待线程返回。- 程序中需要
join的调用,否则执行后程序会报异常。
std::packaged_task 也可以包装一个 lambda 表达式
std::packaged_task<int(int)> mypt([] {cout << 1 << endl;});
3.4 std::promise(保存一个共享状态的值)
这是一个类模板,这个类模板的作用是:能够在某个线程中为其赋值,然后就可以在其他线程中,把这个值取出来使用。
std::promise是一个协助线程赋值的类,可以通过 std::promise 保存一个值,在将来的某个时刻通过把一个std::future 绑到这个 promise 上来得到这个绑定的值。
通过promise传递数据的过程一共分为5步:
实例:
// 必须以引用参数的形式传递 promise
void work(promise<int> &tmp_prom, int x) {x *= x;tmp_prom.set_value(x); // 3. 在子线程任务函数中给`std::promise`对象赋值
}std::promise<int> myprom; // 1. 在主线程中创建 std::promise 对象
std::thread t1(work, std::ref(myprom), 10); // 2. 将这个std::promise对象通过引用的方式传递给子线程的任务函数
t1.join(); // 记得join
std::future<int> ful = myprom.get_future(); // 4. 在主线程中通过std::promise对象取出绑定的future实例对象
int res = ful.get(); // 5. 通过得到的future对象取出子线程任务函数中返回的值。
cout << res << endl;
可以看出比 std::packaged_task 的方式多了一步,在子线程中进行赋值的操作,而用std::packaged_task 方式的子线程函数是有返回值的。
子线程的函数需要设置promise<int> &tmp_prom ,promise 类型的引用参数。
下边通过两个例子来理解 std::promise 的作用
子线程任务函数执行期间,让状态就绪
promise<int> pr;
thread t1([](promise<int> &p) {p.set_value(100);this_thread::sleep_for(chrono::seconds(3));cout << "睡醒了...." << endl;
}, ref(pr));future<int> f = pr.get_future();
int value = f.get();
cout << "value: " << value << endl;t1.join(); // 一定要放在最后,不然join会阻塞到子线程执行完毕// 执行结果
/*
value: 100
睡醒了....
*/
子线程的任务函数指定的是一个匿名函数,在这个匿名的任务函数执行期间通过 p.set_value(100) 传出了数据并且激活了状态,数据就绪后,外部主线程中的 int value = f.get() 解除阻塞,并将得到的数据打印出来,3 秒钟之后子线程休眠结束,匿名的任务函数执行完毕。
子线程任务函数执行结束,让状态就绪
promise<int> pr;
thread t1([](promise<int> &p) {p.set_value_at_thread_exit(100);this_thread::sleep_for(chrono::seconds(3));cout << "睡醒了...." << endl;
}, ref(pr));future<int> f = pr.get_future();
int value = f.get();
cout << "value: " << value << endl;t1.join();// 执行结果
/*
睡醒了....
value: 100
*/
在示例程序中,子线程的这个匿名的任务函数中通过 p.set_value_at_thread_exit(100) 在执行完毕并退出之后才会传出数据并激活状态,数据就绪后,外部主线程中的 int value = f.get() 解除阻塞,并将得到的数据打印出来,因此子线程在休眠5秒钟之后主线程中才能得到传出的数据。
相关文章:

C++11 多线程学习笔记
1. thread — 线程篇 所需头文件:<thread> 1.1 构造函数 // 1 默认构造函数 thread() noexcept; // 2 移动构造函数,把other的所有权转移给新的thread对象,之后 other 不再表示执行线程。 thread( thread&& other ) noex…...
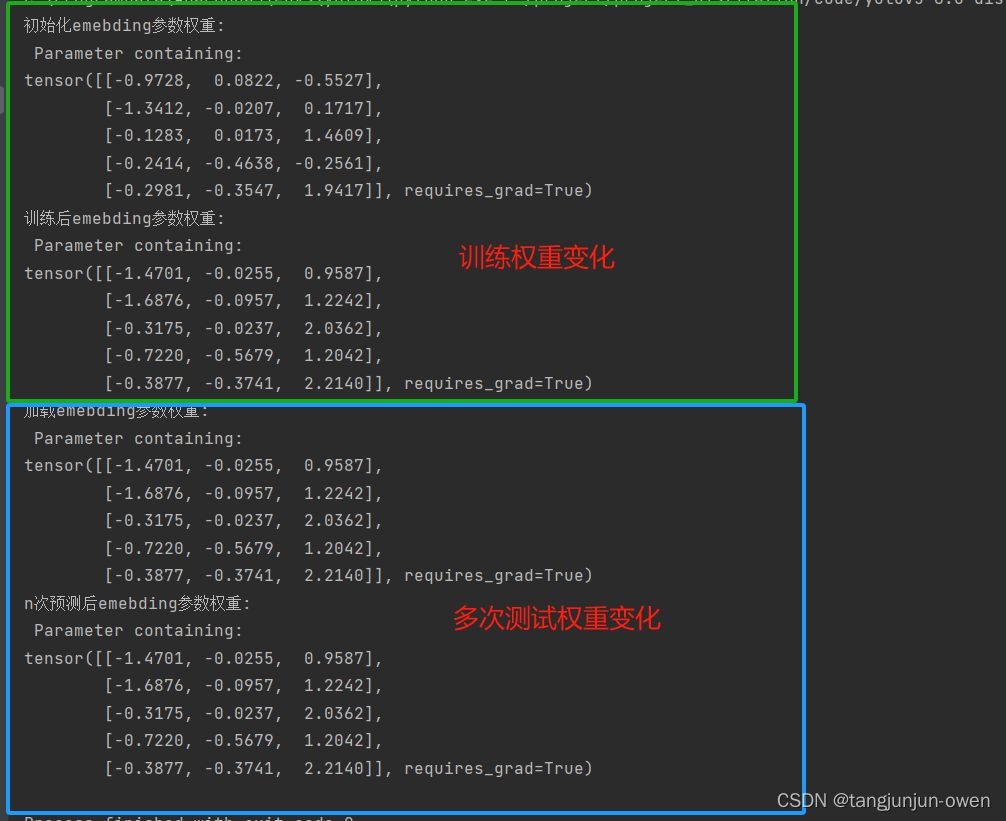
nn.embedding函数详解(pytorch)
提示:文章附有源码!!! 文章目录 前言一、nn.embedding函数解释二、nn.embedding函数使用方法四、模型训练与预测的权重变化探讨 前言 最近发现prompt工程(如sam模型),也有transform的detr模型等都使用了nn.Embedding函…...

gitee.com[0: xxx.xx.xxx.xx]: errno=Unknown error
git在提交或拉取代码的时候,遇到以下报错信息: Unable to connect to gitee.com[0: xxx.xx.xxx.xx]: errnoUnknown error 解决问题步骤: 1、找到自己的电脑上的git用户配置文件 文件位置位于:C:\Users\用户名\.gitconfig 比如我…...

bug: https://aip.baidubce.com/oauth/2.0/token报错blocked by CORS policy
还是跟以前一样,我们先看报错点:(注意小编这里是H5解决跨域的,不过解决跨域的原理都差不多) Access to XMLHttpRequest at https://aip.baidubce.com/oauth/2.0/token from origin http://localhost:8000 has been blo…...
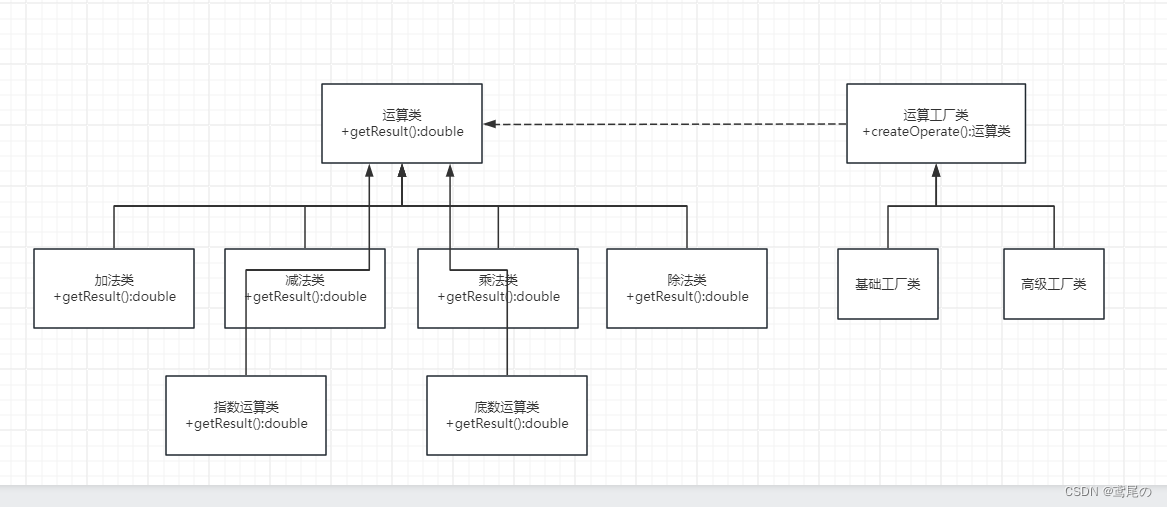
简单工厂VS工厂方法
工厂方法模式–制造细节无需知 前面介绍过简单工厂模式,简单工厂模式只是最基本的创建实例相关的设计模式。在真实情况下,有更多复杂的情况需要处理。简单工厂生成实例的类,知道了太多的细节,这就导致这个类很容易出现难维护、灵…...

使用VSCODE链接Anaconda
打代码还是在VSCODE里得劲 所以得想个办法在VSCODE里运行py文件 一开始在插件商店寻找插件 但是没有发现什么有效果的 幸运的是VSCODE支持自己选择Python的编译器 打开VSCODE 按住CtrlShiftP 输入Select Interpreter 如果电脑已经安装上了Python的环境 VSCODE会默认选择普通…...
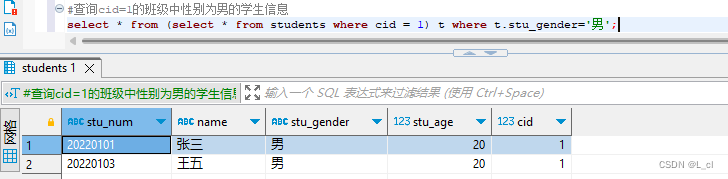
Mysql数据库 9.SQL语言 查询语句 连接查询、子查询
连接查询 通过查询多张表,用连接查询进行多表联合查询 关键字:inner join 内连接 left join 左连接 right join 右连接 数据准备 创建新的数据库:create database 数据库名; create database db_test2; 使用数据库:use 数据…...
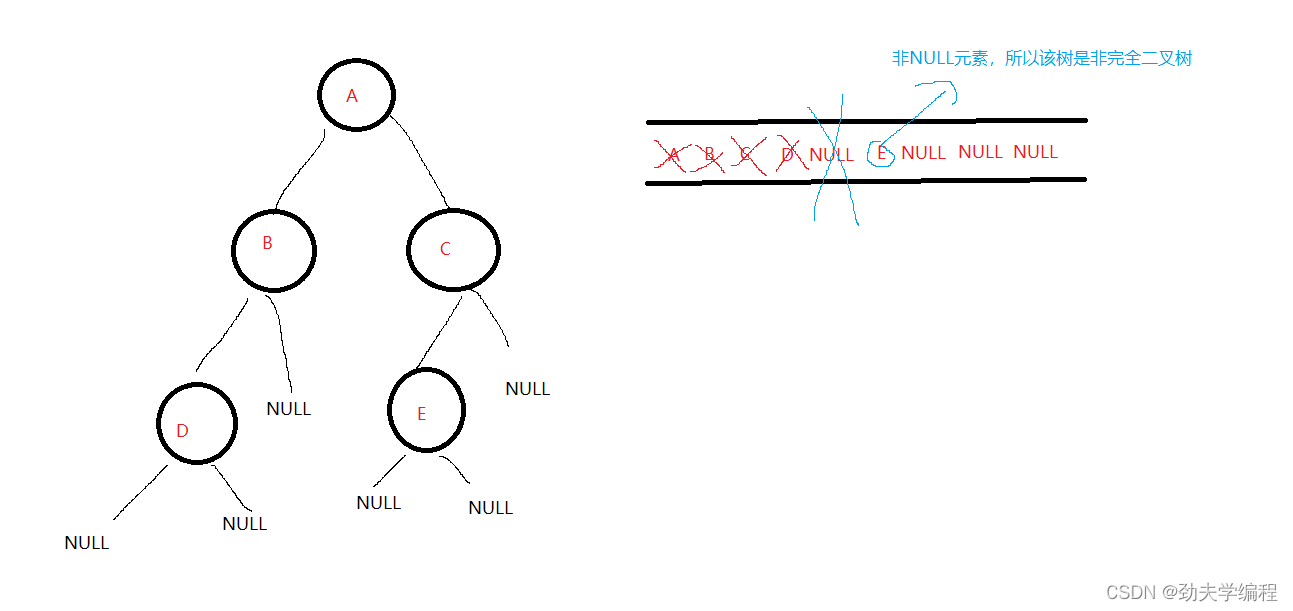
二叉树按二叉链表形式存储,试编写一个判别给定二叉树是否是完全二叉树的算法
完全二叉树:就是每层横着划过去是连起来的,中间不会断开 比如下面的左图就是完全二叉树 再比如下面的右图就是非完全二叉树 那我们可以采用层序遍历的方法,借助一个辅助队列 当辅助队列不空的时候,出队头元素,入队头…...
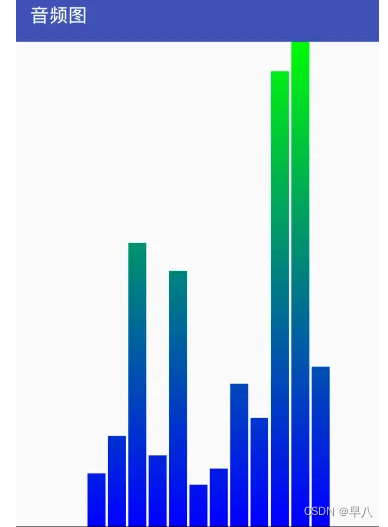
Android自定义控件
目录 Android自定义控件一、对现有控件进行扩展二、创建复合控件1 定义属性2 组合控件3 引用UI模板 三、重写View来实现全新控件1 弧线展示图1.1 具体步骤: 2 音频条形图2.1 具体步骤 四、补充:自定义ViewGroup Android自定义控件 ref: Android自定义控件…...

Java 中的 Cloneable 接口和深拷贝
引言: 在 Java 中,深拷贝是一种常见的需求,它可以创建一个对象的完全独立副本。Cloneable 接口提供了一种标记机制,用于指示一个类实例可以被复制。本文将详细介绍 Java 中的 Cloneable 接口和深拷贝的相关知识࿰…...
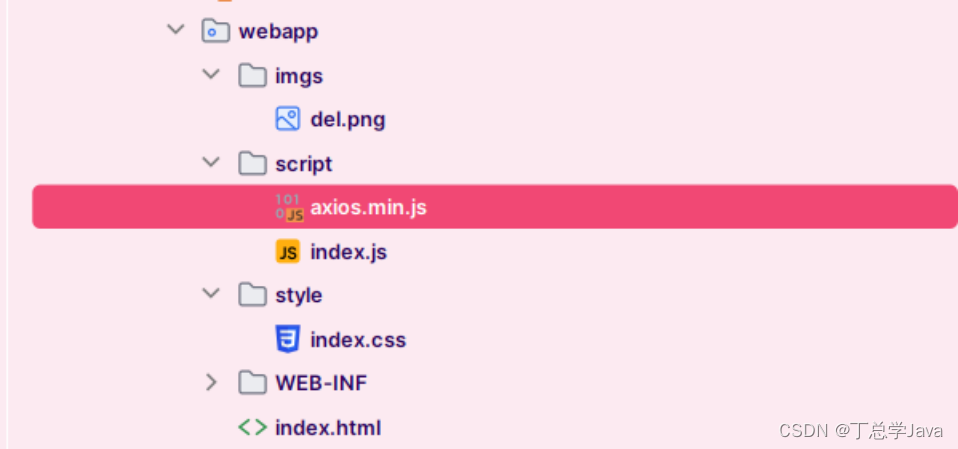
项目实战:通过axios加载水果库存系统的首页数据
1、创建静态页面 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><link rel"stylesheet" href"style/index.css"><script src"script/axios.mi…...
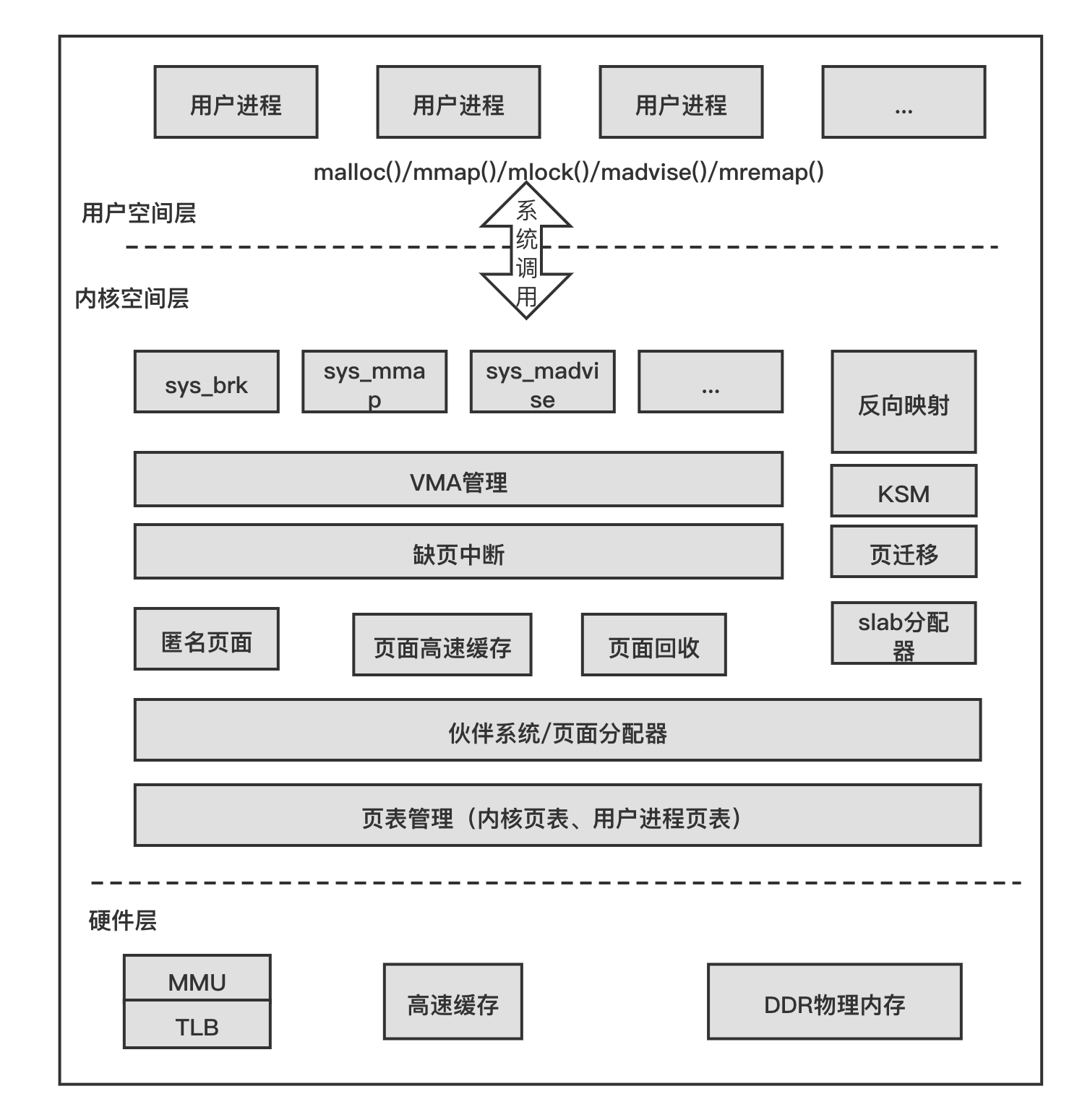
RK3568平台 内存的基本概念
一.Linux的Page Cache page cache,又称pcache,其中文名称为页高速缓冲存储器,简称页高缓。page cache的大小为一页,通常为4K。在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访…...
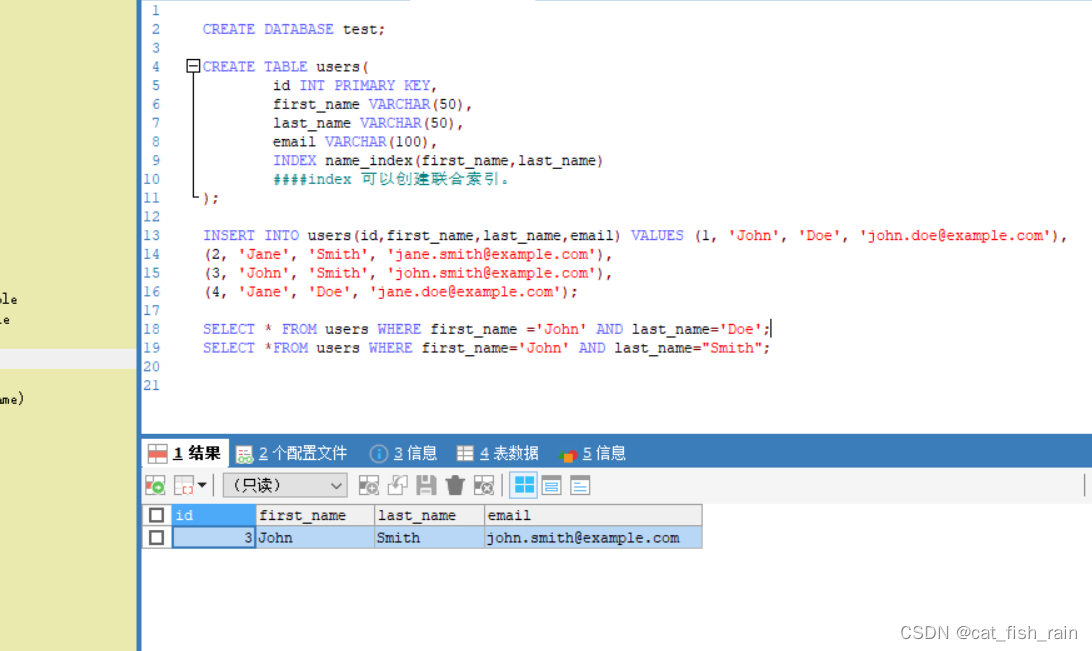
mysql联合索引和最左匹配问题。
1引言: 如果频繁地使⽤相同的⼏个字段查询,就可以考虑建⽴这⼏个字段的联合索引来提⾼查询效率。⽐如对 于联合索引 test_col1_col2_col3,实际建⽴了 (col1)、(col1, col2)、(col, col2, col3) 三个索引。联合 索引的主要优势是减少结果集数量…...

全球发布|首个AI视角下的生态系统架构解读—《生态系统架构--人工智能时代从业者的新思维》重磅亮相!
点击可免费注册下载 👇 人工智能时代的企业架构师必读系列 《生态系统架构--人工智能时代从业者的新思维》 Philip Tetlow、Neal Fishman、Paul Homan、Rahul著 The Open Group Press 2023年11月出版 这本书可以很好地帮助全球架构师使用人工智能来构建、开发和…...

解决torch.hub.load加载网络模型异常
1 torch.hub.load 加载网络模型错误 通过网络使用torch.hub.load加载模型代码如下: self.model torch.hub.load("facebookresearch/dinov2", dinov2_vits14, sourcegithub).to(self.device) 运行网上的项目,经常会卡住或者超时,…...
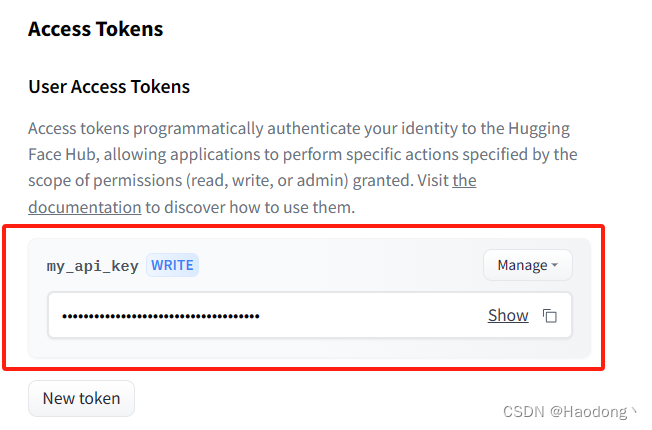
如何获取HuggingFace的Access Token;如何获取HuggingFace的API Key
Access Token通过编程方式向 HuggingFace 验证您的身份,允许应用程序执行由授予的权限范围(读取、写入或管理)指定的特定操作。您可以通过以下步骤获取: 1.首先,你需要注册一个 Hugging Face 账号。如果你已经有了账号…...

How to resolve jre-openjdk and jre-openjdk-headless conflicts?
2023-11-05 Archlinux 执行 pacman -Syu 显示 failed to prepare transaction;jre-openjdk and jre-openjdk-headless conflicts 解决 archlinux sudo pacman -Sy jdk-openjdk...

setTimeout和setImmediate以及process.nextTick的区别?
目录 前言 setTimeout 特性和用法 setImmediate 特性和用法 process.nextTick 特性和用法 区别和示例 总结 在Node.js中,setTimeout、setImmediate和process.nextTick是用于调度异步操作的三种不同机制。它们之间的区别在于事件循环中的执行顺序和优先级。…...

read 方法为什么返回 int 类型
在Java的输入流(InputStream)中,read方法返回int类型的值的原因是为了提供更多的信息和灵活性。虽然这可能看起来有些不直观,但有一些合理的考虑和用途,主要包括以下几点: EOF标志:read方法返回…...

在二维矩阵/数组中查找元素 Leetcode74, Leetcode240
这一类题型中二维数组的元素取值有序变化,因此可以用二分查找法。我们一起来看一下。 一、Leetcode 74 Leetcode 74. 搜索二维矩阵 这道题要在一个二维矩阵中查找元素。该二维矩阵有如下特点: 每行元素 从左到右 按非递减顺序排列。每行的第一个元素 …...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

终极键盘重映射解决方案:3分钟实现职业级游戏操作精度
终极键盘重映射解决方案:3分钟实现职业级游戏操作精度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对抗中,你是否曾因键盘按键冲突而错失关键操作?当同时按下…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...