Intel oneAPI笔记(3)--jupyter官方文档(SYCL Program Structure)学习笔记
前言
本文是对jupyterlab中oneAPI_Essentials/02_SYCL_Program_Structure文档的学习记录,包含对Device Selector、Data Parallel Kernel、Host Accessor、Buffer Destruction、的介绍,最后还有一个小关于向量(Vector)加法的实例
设备(Device)
设备类包含用于查询设备信息的成员函数,这对于创建多个设备的SYCL程序很有用,成员函数get_info,可以获取包括以下的信息:
名称,供应商,版本号,本地和全局工作编号,宽度内置类型,时钟频率,缓存宽度和大小,在线或离线等

设备选择器(Device Selector)
这个类允许在运行时根据用户提供的启发式方法选择特定设备来执行内核。下面的代码示例显示了标准设备选择器的使用

运行结果

队列(Queue)
队列类提交要由SYCL运行时执行的命令组。队列是一种将工作提交给设备的机制。一个队列映射到一个设备,多个队列可以映射到同一个设备

内核(Kernel)
内核对象不是由用户显式构造的,而是在调用parallel_for等内核调度函数时构造的,用于在设备上执行代码的方法和数据

Scope
Application scope和command group scope
执行在主机上的代码,在这个scope中可以使用c++全部代码
Kernel scope
执行在设备(Device)上的代码,这个scope中可以无法使用部分c++的功能
Parallel Kernels
并行内核允许一个操作的多个实例并行执行。这对于offload的基本for循环的并行执行非常有用,因为for循环中的每个迭代都是完全独立的,并且按任意顺序执行。并行内核是用parallel_for函数表示的。c++应用程序中的一个简单的'for'循环编写如下

用下面这种方法,可以offload到一个加速器(accelerator)中

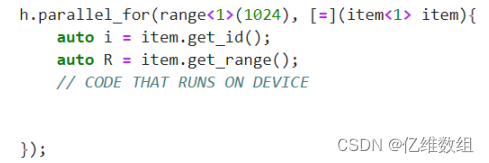
基本并行内核的功能主要包含range、id和item类。Range类用于描述并行执行的迭代空间,id类用于在并行执行中索引内核的单个实例

上述的i可以换成item,这样的话,可以通过相关函数不仅得到原来的索引值i,还可以在这个循环内部得到range
Nd Range Kernels
基本并行内核是并行for循环的简单方法,但不允许在硬件级别进行性能优化。ND-Range内核是表达并行性的另一种方式,它通过提供对本地内存的访问和将执行映射到硬件上的计算单元来实现低级性能调优。整个迭代空间被分成称成很多工作组,工作组中的工作项被安排在硬件上的单个计算单元上
nd_range内核的功能通过nd_range和nd_item类公开。Nd_range类表示使用全局执行范围和每个工作组的本地执行范围的分组执行范围。Nd_item类表示内核函数的单个实例,并允许查询工作组范围和索引

比如上面这个例子,第一个range<1>(1024)表示全局执行范围是1024个工作单元,第二个range<1>(64)表示每个工作组的本地执行范围是64,也就是一个工作组有64个单元,也照应了图上的(4*4*4)区域
Buffer Model
缓冲区在跨设备和主机的SYCL应用程序中封装数据。访问器是访问缓冲区数据的机器
SYCL的代码开头内容:
![]()
SYCL程序是标准的c++。该程序在主机上调用,并将计算offload到加速器上。程序员使用SYCL的队列、缓冲区、设备和内核抽象来指示应该卸载哪些部分的计算和数据
SYCL程序的第一步,我们创建一个队列。我们通过将任务提交到队列,将计算量转移到设备上。程序员可以通过选择器选择CPU、GPU、FPGA等器件。这个程序在这里使用默认的q,这意味着SYCL运行时通过使用默认选择器来选择运行时可用的最有能力的设备。但下面是一个简单的SYCL程序
设备和主机可以共享物理内存,也可以拥有不同的内存。当内存不同时,offload计算需要在主机和设备之间复制数据。SYCL不要求程序员管理数据副本。通过创建缓冲区和访问器,SYCL确保数据对主机和设备可用,而无需程序员的任何努力。SYCL还允许程序员在需要实现最佳性能时显式控制数据移动
在SYCL程序中,我们定义了一个内核(就是device 运行的那部分代码)。对于像这样的简单程序,索引空间直接映射到数组的元素。内核被封装在一个c++ lambda函数中。lambda函数在索引空间中以坐标数组的形式传递一个点。对于这个简单的程序,索引空间坐标与数组索引相同。下面程序中的parallel_for将lambda应用到索引空间。索引空间在parallel_for的第一个参数中定义为从0到N-1的一维范围

对访问器(Accessor)的隐式依赖
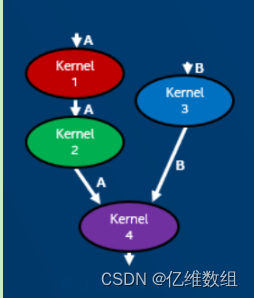
访问器在SYCL图中创建对内核执行排序的数据依赖关系,如果两个内核使用相同的缓冲区,第二个内核需要等待第一个内核完成,以避免竞争条件,比如下面这个图,必须在kernel1运行完之后,缓冲区A才能空闲,然后才能继续运行kernel2
样例
%%writefile lab/buffer_sample.cpp
//==============================================================
// Copyright © Intel Corporation
//
// SPDX-License-Identifier: MIT
// =============================================================
#include <sycl/sycl.hpp>constexpr int num=16;
using namespace sycl;int main() {auto R = range<1>{ num };//Create Buffers A and Bbuffer<int> A{ R }, B{ R };//Create a device queuequeue Q;//Submit Kernel 1Q.submit([&](handler& h) {//Accessor for buffer Aaccessor out(A,h,write_only);h.parallel_for(R, [=](auto idx) {out[idx] = idx[0]; }); });//Submit Kernel 2Q.submit([&](handler& h) {//This task will wait till the first queue is completeaccessor out(A,h,write_only);h.parallel_for(R, [=](auto idx) {out[idx] += idx[0]; }); });//Submit Kernel 3Q.submit([&](handler& h) { //Accessor for Buffer Baccessor out(B,h,write_only);h.parallel_for(R, [=](auto idx) {out[idx] = idx[0]; }); });//Submit task 4Q.submit([&](handler& h) {//This task will wait till kernel 2 and 3 are completeaccessor in (A,h,read_only);accessor inout(B,h);h.parallel_for(R, [=](auto idx) {inout[idx] *= in[idx]; }); }); // And the following is back to device codehost_accessor result(B,read_only);for (int i=0; i<num; ++i)std::cout << result[i] << "\n"; return 0;
}运行结果

结果解释:并行运行kerne11和kernel3,在缓冲区A和B中分别写入0--15这16个数,然后运行kernel2,让缓冲区A中的数翻二倍,最后运行kernel4,让缓冲区A中的0--30这16个数和缓冲区B中的0--15这16个数相乘,最后输出
Host Accessor
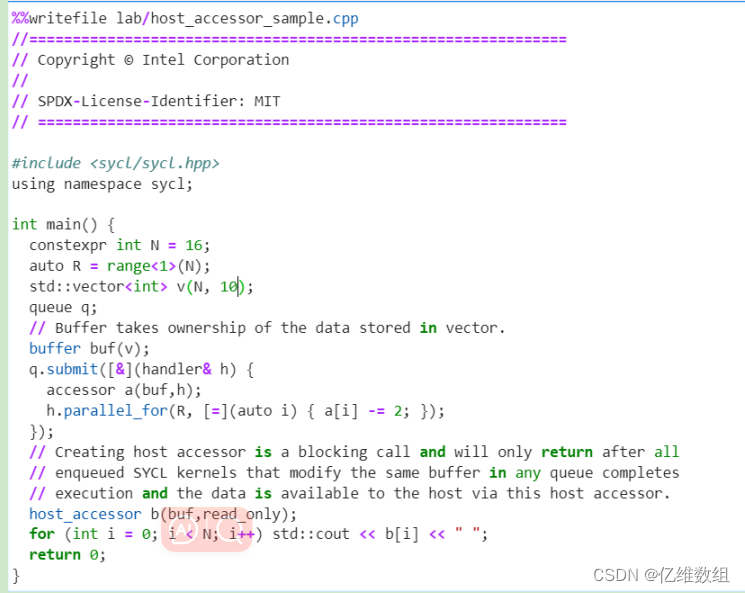
主机访问器是使用主机缓冲区访问目标的访问器。它是在命令组的作用域之外创建的,它们用于通过构造主机访问器对象将数据同步回主机。缓冲区销毁是将数据同步回主机的另一种方法
缓冲区获取存储在vector中的数据的所有权。创建主机访问器是一个阻塞调用,只有在所有队列中修改同一缓冲区的SYCL内核完成执行并且主机可以通过该主机访问器访问数据之后才会返回
运行结果

下面介绍,主机和设备数据同步的另一种方法:缓冲区销毁
Buffer Destruction
在下面的示例中,缓冲区创建发生在单独的函数作用域中。当执行超出此函数作用域时,调用缓冲区析构函数,从而放弃数据的所有权并将数据复制回主机内存

运行结果
![]()
Custom Device Selector
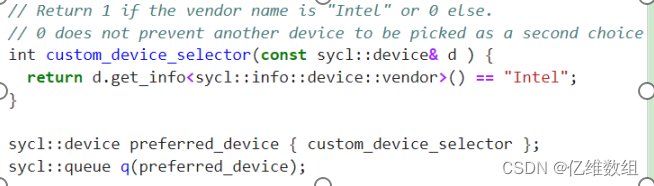
自定义设备选择器使用您自己的逻辑(评分机制)自定义设备选择器
特定供应商名称的自定义设备选择器
具有GPU和特定设备名称的自定义设备选择器

基于设备的优先级的自定义设备选择器

下面是基于上种情况的案例
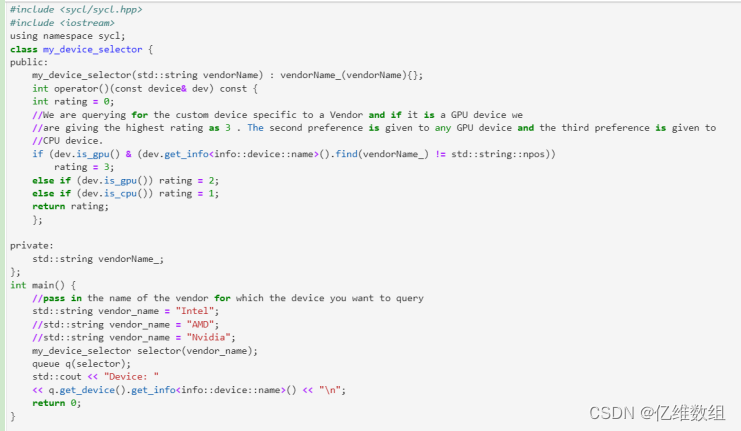
运行结果

Lab Exercise: Vector Add
下面是官方文档中向量相加这个练习
下面是我已经补全的代码
#include <sycl/sycl.hpp>
using namespace sycl;
int main() {const int N = 256;//# Initialize a vector and print valuesstd::vector<int> vector1(N, 10);std::cout<<"\nInput Vector1: "; for (int i = 0; i < N; i++) std::cout << vector1[i] << " ";//# STEP 1 : Create second vector, initialize to 20 and print values//# YOUR CODE GOES HEREstd::vector<int> vector2(N, 20);std::cout<<"\nInput Vector2: ";for (int i = 0; i < N; i++) std::cout << vector2[i] << " ";//# Create Bufferbuffer vector1_buffer(vector1);//# STEP 2 : Create buffer for second vector //# YOUR CODE GOES HEREbuffer vector2_buffer(vector2);//# Submit task to add vectorqueue q;q.submit([&](handler &h) {//# Create accessor for vector1_bufferaccessor vector1_accessor (vector1_buffer,h);//# STEP 3 - add second accessor for second buffer//# YOUR CODE GOES HEREaccessor vector2_accessor (vector2_buffer,h);h.parallel_for(range<1>(N), [=](id<1> index) {//# STEP 4 : Modify the code below to add the second vector to first onevector1_accessor[index] += vector2_accessor[index];});});//# Create a host accessor to copy data from device to hosthost_accessor h_a(vector1_buffer,read_only);//# Print Output values std::cout<<"\nOutput Values: ";for (int i = 0; i < N; i++) std::cout<< vector1[i] << " ";std::cout<<"\n";return 0;
}运行结果

相关文章:
Intel oneAPI笔记(3)--jupyter官方文档(SYCL Program Structure)学习笔记
前言 本文是对jupyterlab中oneAPI_Essentials/02_SYCL_Program_Structure文档的学习记录,包含对Device Selector、Data Parallel Kernel、Host Accessor、Buffer Destruction、的介绍,最后还有一个小关于向量(Vector)加法的实例 …...

verilog——移位寄存器
在Verilog中,你可以使用移位寄存器来实现数据的移位操作。移位寄存器是一种常用的数字电路,用于将数据向左或向右移动一个或多个位置。这在数字信号处理、通信系统和其他应用中非常有用。以下是一个使用Verilog实现的简单移位寄存器的示例: m…...

C++11 多线程学习笔记
1. thread — 线程篇 所需头文件:<thread> 1.1 构造函数 // 1 默认构造函数 thread() noexcept; // 2 移动构造函数,把other的所有权转移给新的thread对象,之后 other 不再表示执行线程。 thread( thread&& other ) noex…...
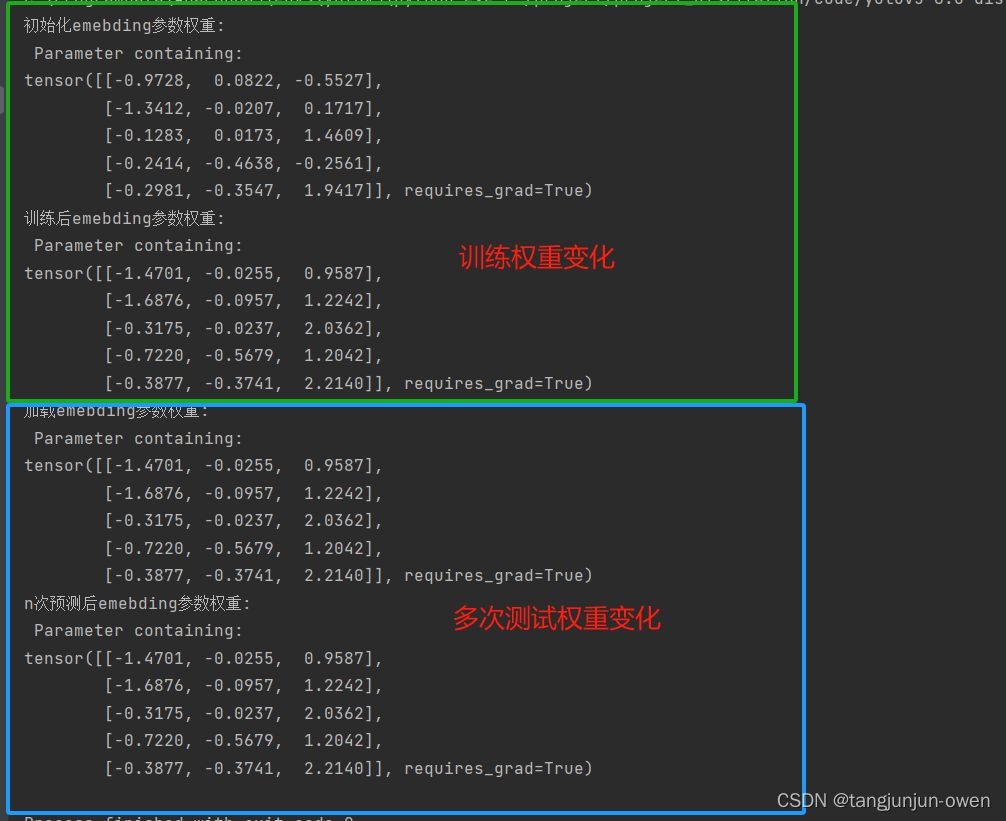
nn.embedding函数详解(pytorch)
提示:文章附有源码!!! 文章目录 前言一、nn.embedding函数解释二、nn.embedding函数使用方法四、模型训练与预测的权重变化探讨 前言 最近发现prompt工程(如sam模型),也有transform的detr模型等都使用了nn.Embedding函…...

gitee.com[0: xxx.xx.xxx.xx]: errno=Unknown error
git在提交或拉取代码的时候,遇到以下报错信息: Unable to connect to gitee.com[0: xxx.xx.xxx.xx]: errnoUnknown error 解决问题步骤: 1、找到自己的电脑上的git用户配置文件 文件位置位于:C:\Users\用户名\.gitconfig 比如我…...

bug: https://aip.baidubce.com/oauth/2.0/token报错blocked by CORS policy
还是跟以前一样,我们先看报错点:(注意小编这里是H5解决跨域的,不过解决跨域的原理都差不多) Access to XMLHttpRequest at https://aip.baidubce.com/oauth/2.0/token from origin http://localhost:8000 has been blo…...
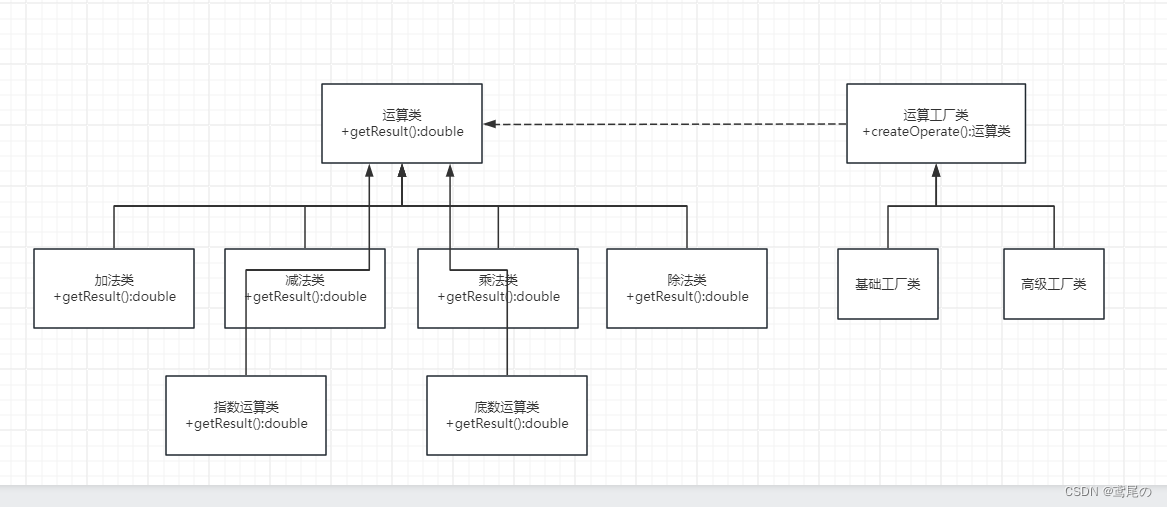
简单工厂VS工厂方法
工厂方法模式–制造细节无需知 前面介绍过简单工厂模式,简单工厂模式只是最基本的创建实例相关的设计模式。在真实情况下,有更多复杂的情况需要处理。简单工厂生成实例的类,知道了太多的细节,这就导致这个类很容易出现难维护、灵…...

使用VSCODE链接Anaconda
打代码还是在VSCODE里得劲 所以得想个办法在VSCODE里运行py文件 一开始在插件商店寻找插件 但是没有发现什么有效果的 幸运的是VSCODE支持自己选择Python的编译器 打开VSCODE 按住CtrlShiftP 输入Select Interpreter 如果电脑已经安装上了Python的环境 VSCODE会默认选择普通…...
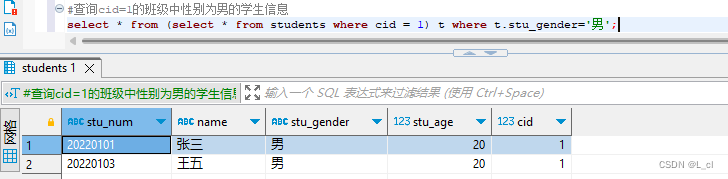
Mysql数据库 9.SQL语言 查询语句 连接查询、子查询
连接查询 通过查询多张表,用连接查询进行多表联合查询 关键字:inner join 内连接 left join 左连接 right join 右连接 数据准备 创建新的数据库:create database 数据库名; create database db_test2; 使用数据库:use 数据…...
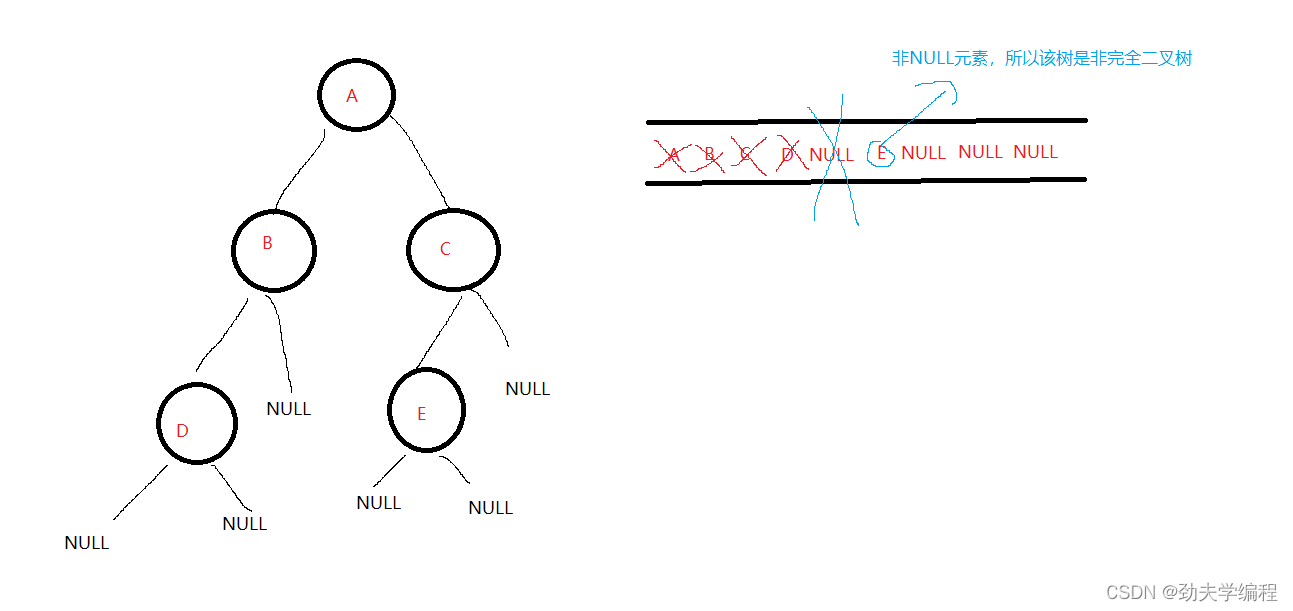
二叉树按二叉链表形式存储,试编写一个判别给定二叉树是否是完全二叉树的算法
完全二叉树:就是每层横着划过去是连起来的,中间不会断开 比如下面的左图就是完全二叉树 再比如下面的右图就是非完全二叉树 那我们可以采用层序遍历的方法,借助一个辅助队列 当辅助队列不空的时候,出队头元素,入队头…...
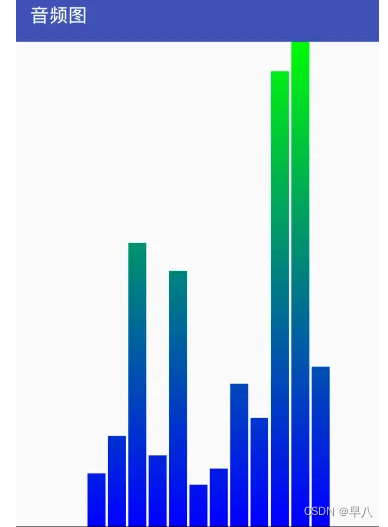
Android自定义控件
目录 Android自定义控件一、对现有控件进行扩展二、创建复合控件1 定义属性2 组合控件3 引用UI模板 三、重写View来实现全新控件1 弧线展示图1.1 具体步骤: 2 音频条形图2.1 具体步骤 四、补充:自定义ViewGroup Android自定义控件 ref: Android自定义控件…...

Java 中的 Cloneable 接口和深拷贝
引言: 在 Java 中,深拷贝是一种常见的需求,它可以创建一个对象的完全独立副本。Cloneable 接口提供了一种标记机制,用于指示一个类实例可以被复制。本文将详细介绍 Java 中的 Cloneable 接口和深拷贝的相关知识࿰…...
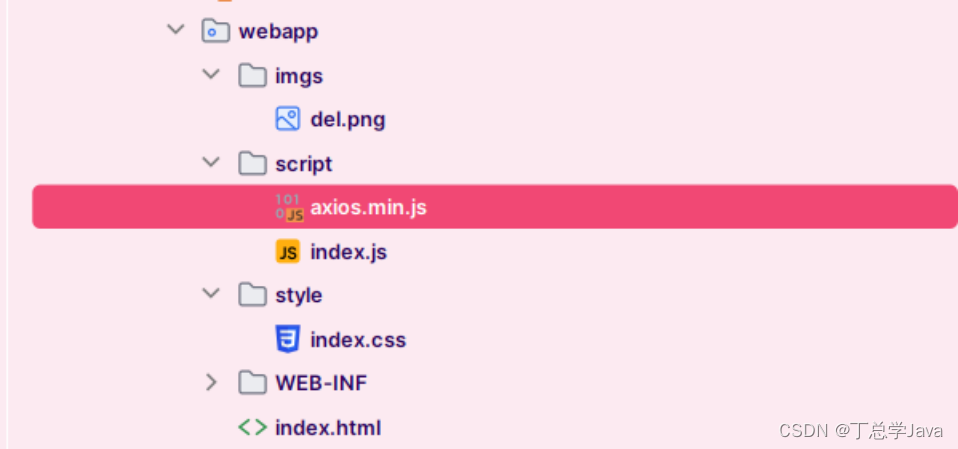
项目实战:通过axios加载水果库存系统的首页数据
1、创建静态页面 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><link rel"stylesheet" href"style/index.css"><script src"script/axios.mi…...
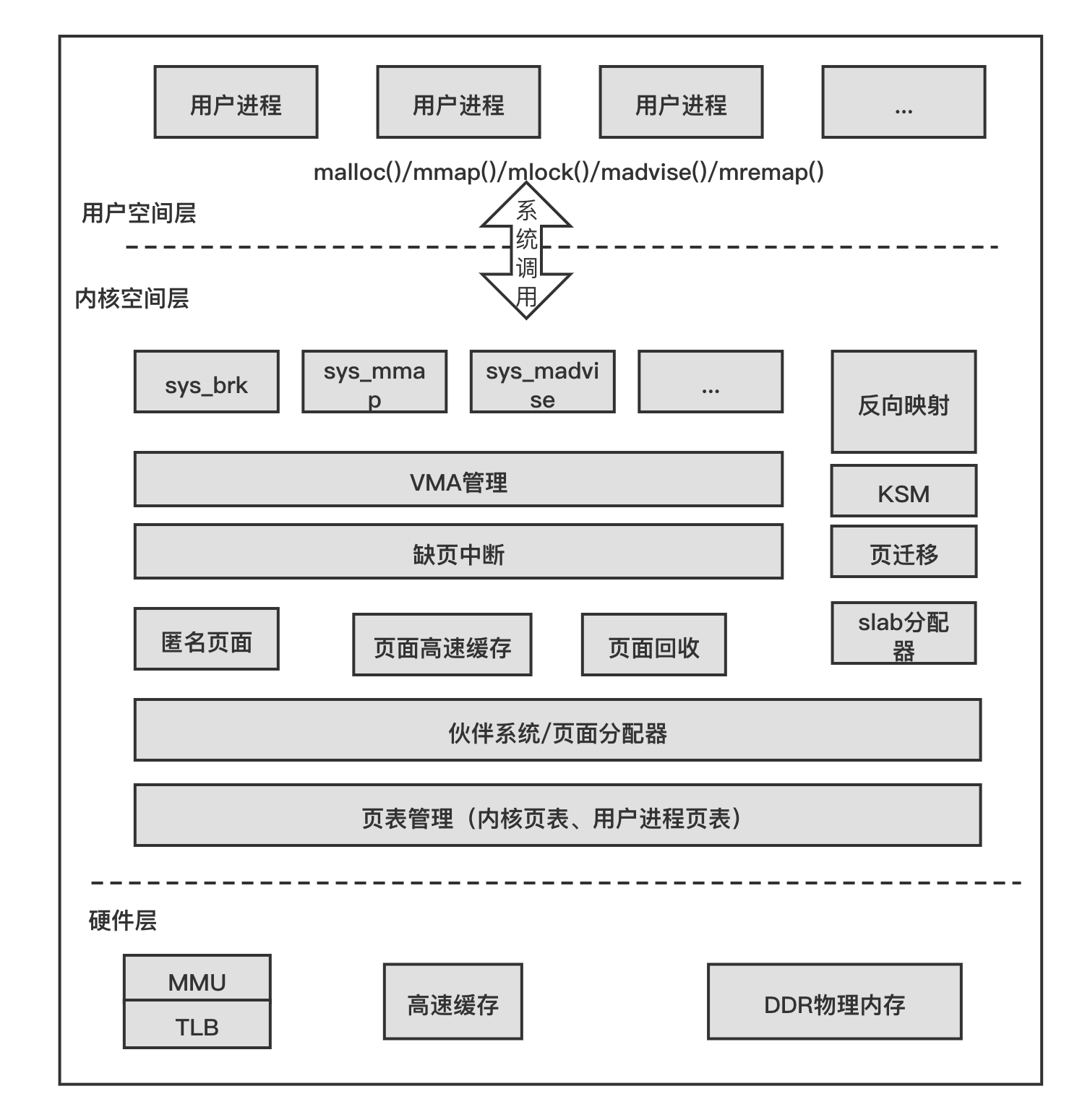
RK3568平台 内存的基本概念
一.Linux的Page Cache page cache,又称pcache,其中文名称为页高速缓冲存储器,简称页高缓。page cache的大小为一页,通常为4K。在linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访…...
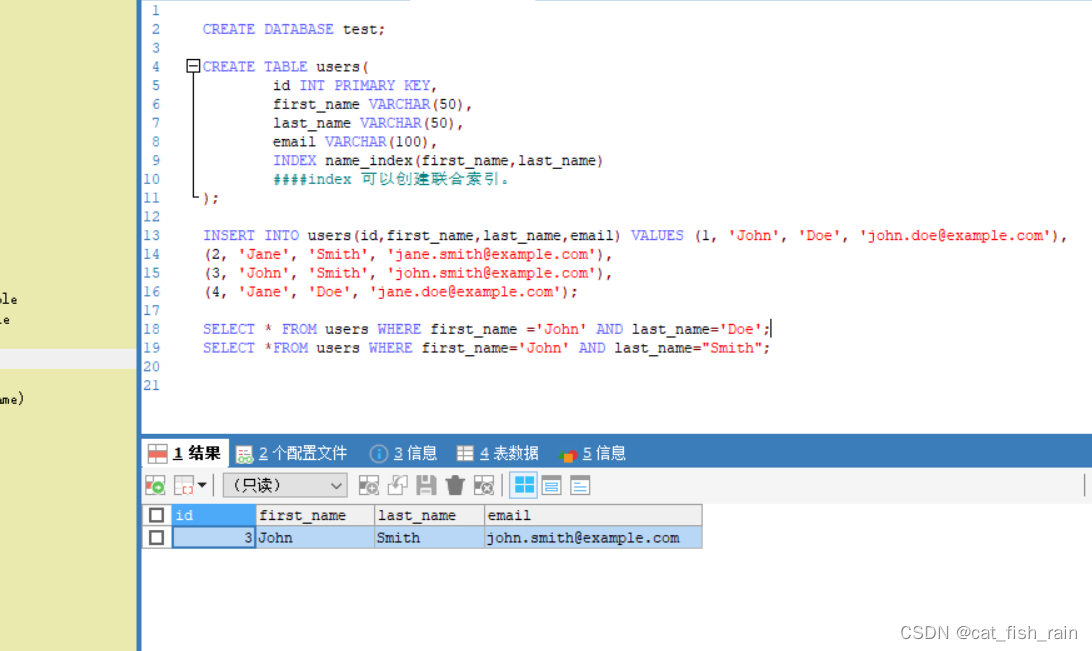
mysql联合索引和最左匹配问题。
1引言: 如果频繁地使⽤相同的⼏个字段查询,就可以考虑建⽴这⼏个字段的联合索引来提⾼查询效率。⽐如对 于联合索引 test_col1_col2_col3,实际建⽴了 (col1)、(col1, col2)、(col, col2, col3) 三个索引。联合 索引的主要优势是减少结果集数量…...

全球发布|首个AI视角下的生态系统架构解读—《生态系统架构--人工智能时代从业者的新思维》重磅亮相!
点击可免费注册下载 👇 人工智能时代的企业架构师必读系列 《生态系统架构--人工智能时代从业者的新思维》 Philip Tetlow、Neal Fishman、Paul Homan、Rahul著 The Open Group Press 2023年11月出版 这本书可以很好地帮助全球架构师使用人工智能来构建、开发和…...

解决torch.hub.load加载网络模型异常
1 torch.hub.load 加载网络模型错误 通过网络使用torch.hub.load加载模型代码如下: self.model torch.hub.load("facebookresearch/dinov2", dinov2_vits14, sourcegithub).to(self.device) 运行网上的项目,经常会卡住或者超时,…...
如何获取HuggingFace的Access Token;如何获取HuggingFace的API Key
Access Token通过编程方式向 HuggingFace 验证您的身份,允许应用程序执行由授予的权限范围(读取、写入或管理)指定的特定操作。您可以通过以下步骤获取: 1.首先,你需要注册一个 Hugging Face 账号。如果你已经有了账号…...

How to resolve jre-openjdk and jre-openjdk-headless conflicts?
2023-11-05 Archlinux 执行 pacman -Syu 显示 failed to prepare transaction;jre-openjdk and jre-openjdk-headless conflicts 解决 archlinux sudo pacman -Sy jdk-openjdk...

setTimeout和setImmediate以及process.nextTick的区别?
目录 前言 setTimeout 特性和用法 setImmediate 特性和用法 process.nextTick 特性和用法 区别和示例 总结 在Node.js中,setTimeout、setImmediate和process.nextTick是用于调度异步操作的三种不同机制。它们之间的区别在于事件循环中的执行顺序和优先级。…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

【DeepSeek测试用例生成实战指南】:20年QA专家亲授5大高覆盖率生成模式与3个避坑红线
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的核心价值与适用边界 DeepSeek系列大模型在代码理解与生成任务中展现出显著的上下文建模能力,其测试用例生成功能并非通用“黑盒测试器”,而是聚焦于**单元级、函…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...