[黑马程序员Pandas教程]——DataFrame数据的增删改操作
目录:
- 学习目标
- DataFrame添加列
- 直接赋值添加列数据
- 删除与去重
- 删除
- df.drop删除行数据
- df.drop删除列数据
- 数据去重
- Dataframe去重
- Seriers去重
- 删除
- 修改DataFrame中的数据
- 直接修改数据
- replace函数替换数据
- 按条件使用布尔值修改数据
- 执行自定义函数修改数据
- Series.apply()函数遍历每一个值同时执行自定义函数
- df.apply()函数遍历每一列同时执行自定义函数
- df.apply()函数遍历每一行同时执行自定义函数
- 了解函数向量化
- 总结
- 项目地址
1.学习目标
-
知道drop函数删除df的行或列数据
-
知道drop_duplicates函数对df或series进行数据去重
-
知道unique函数对series进行数据去重
-
知道apply函数的使用方法
-
了解numpy.vectorize(func)函数向量化
2.DataFrame添加列
直接赋值添加列数据
import pandas as pddf = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df2 = df.head()# 拷贝一份df
df3 = df2.copy()# 一列数据都是固定值
df3['new col 1'] = 33# 新增列数据数量必须和行数相等
df3['new col 2'] = [1, 2, 3, 4, 5]
df3['new col 3'] = df3.year * 2# 分别查看增加数据列之后的df和原df
print(df3)
print(df2)
3.删除与去重
删除
df.drop删除行数据
import pandas as pddf = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df2 = df.head()# 拷贝一份df
df3 = df2.copy()print(df3)# 默认删除行,按索引值删除,不会在原df上删除,添加参数inplace=True,此时就在原df上进行删除
df4 = df3.drop([0])
print(df4)
# 在原df上进行删除
df3.drop([0], inplace=True)
print(df3)
# 可以删除多行
df5 = df3.drop([2, 4])
print(df5)
# 对series对象按索引值删除
print(df3.GDP)df6 = df3.GDP.drop([1, 3])
print(df6)
df.drop删除列数据
-
df.drop默认删除指定索引值的行
axis=0或axis='index';如果添加参数axis=1或axis='columns',则删除指定列名的列
import pandas as pddf = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df2 = df.head()# 拷贝一份df
df3 = df2.copy()# 一列数据都是固定值
df3['new col 1'] = 33# 新增列数据数量必须和行数相等
df3['new col 2'] = [1, 2, 3, 4, 5]
df3['new col 3'] = df3.year * 2print(df3)df4 = df3.drop(['new col 3'], axis=1)
print(df4)
数据去重
Dataframe去重
-
运行下面的代码获取具有重复数据的df(代码中使用的append函数会在后边《合并与变形》章节中详细介绍)
import pandas as pddf = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df2 = df.head()
print(df2)df4 = pd.concat([df2] * 2).reset_index(drop=True)
print(df4)# 去除重复的数据
# 默认对所有列进行去重,可以通过参数 subset=['列名1','列名2'...] 对指定的列进行去重
df5 = df4.drop_duplicates()
print(df5)
Seriers去重
import pandas as pddf = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df2 = df.head()
print(df2)df4 = pd.concat([df2] * 2).reset_index(drop=True)
print(df4)# Seriers对象使用drop_duplicates函数进行去重,返回Series对象
print(df4.country)
df5 = df4.country.drop_duplicates()
print(df5)# Seriers对象还可以使用unique函数进行去重,返回的ndarray数组
df6 = df4.country.unique()
print(df6)
4.修改DataFrame中的数据
直接修改数据
import pandas as pddf = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
# 拷贝一份数据
df5 = df.head().copy()
print(df5)df5['GDP'] = [5, 4, 3, 2, 1]
print(df5)
replace函数替换数据
import pandas as pd# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df6 = df.head().copy()
print(df6)# series对象替换数据,返回的还是series对象,不会对原来的df造成修改
df7 = df6.year.replace(1960, 19600)
print(df7)# 如果加上inplace=True参数,则会修改原始df
df6.country.replace('日本', '扶桑', inplace=True)
print(df6)# df也可以直接调用replace函数,用法和s.replace用法一致,只是返回的是df对象
df8 = df6.replace(1960, 19600)
print(df8)
按条件使用布尔值修改数据
-
我们可以利用
[s对象的判断表达式]来选取df中的数据,再进行赋值修改
import pandas as pd# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df7 = df.head().copy()
print(df7)
# 如果country是日本 那就修改GDP为7777
df7['GDP'][df7['country'] == '日本'] = 7777
print(df7)# 上述步骤解析
# df7['country'] == '日本'
# [df7['country'] == '日本']
# df7['GDP'][df7['country'] == '日本']
执行自定义函数修改数据
- 有时需要我们对df或s对象中的数据做更加精细化的修改动作,并将修改操作封装成为一个自定义的函数;这时我们就可以利用
<s / df>.apply()来调用我们自定义的函数
Series.apply()函数遍历每一个值同时执行自定义函数
import pandas as pd# 加载数据,构造示例df对象
# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df8 = df.head()
print(df8)# Series对象使用apply调用自定义的函数,返回新的Series对象
# 自定义函数必须接收一个参数
def foo(x):# x此时是s对象中一个数据# 本自定义函数返回的也是一个数据if x == '美国':return '美利坚'return xdf9 = df8['country'].apply(lambda x: foo(x))
print(df9)# Series对象使用apply调用自定义的函数,并向自定义函数中传入参数
# 自定义函数必须接收一个参数
def foo(x, arg1):# x此时是s对象中一个数据# 本自定义函数返回的也是一个数据if x == '美国':return '美利坚'return arg1df10 = df8['country'].apply(lambda x: foo(x, arg1='其他国家'))
print(df10)
df.apply()函数遍历每一列同时执行自定义函数
import pandas as pd# 加载数据,构造示例df对象
# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df8 = df.head()
print(df8)def foo(s, arg1):# 此时s参数就是df中的一列数据,s对象# 函数也必须返回一列数据,s对象try:return s + arg1except:return s# 返回df对象
df9 = df8.apply(lambda x: foo(x, arg1=1))
print(df9)
df.apply()函数遍历每一行同时执行自定义函数
-
使用参数
axis=1,使df.apply()调用的自定义函数按行执行
import pandas as pd# 加载数据,构造示例df对象
# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df8 = df.head()
print(df8)def foo(s, arg1):# 此时s参数就是df中的一行数据,s对象# 函数也必须返回一行数据,s对象# print(s)if s['country'] == arg1:s.GDP = 6666return sreturn s# 返回df对象
df9 = df8.apply(lambda x: foo(x, arg1='美国'), axis=1)
print(df9)
小结:
-
s.apply(自定义函数名, arg1=xx, ...)对s对象中的每一个值,都执行自定义函数,且该自定义函数除了固定接收每一个值作为第一参数以外,还可以接收其他自定义参数 -
df.apply(自定义函数名, arg1=xx, ...)对df对象中的每一列,都执行自定义函数,且该自定义函数除了固定接收列对象作为第一参数以外,还可以接收其他自定义参数 -
df.apply(自定义函数名, arg1=xx, ..., axis=1)对df对象中的每一行,都执行自定义函数,且该自定义函数除了固定接收行对象作为第一参数以外,还可以接收其他自定义参数
了解函数向量化
-
运行下面会报错的代码
import pandas as pd# 加载数据,构造示例df对象
# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df8 = df.head()
print(df8)# 运行下面会报错的代码
# 构造全是int类型的df
df9 = df8.drop('country', axis=1)
print(df9)def bar(s):# 此时s参数就是df中的一列数据,s对象# 函数也必须返回一列数据,s对象if s != 1960:return selse:return s + 1# 报错
df10 = df9.apply(lambda x: bar(x))
print(df10)
# 运行上述代码会报错
-
上述错误的代码中,
if s != 1960:报错,s != 1960返回一组bool值(向量),这个判断表达式没有问题,但和if连在一起使用就会报错----if只能与返回单一bool值(标量)的判断表达式放在一起;此时我们就需要这个if可以和向量放在一起使用,那么这个时候我们就可以使用函数向量化:让整个函数中原来不能和向量进行操作的代码变为可以和向量进行操作【这段话啥意思不理解也没关系,看下边的代码】
import pandas as pd
import numpy as np# 加载数据,构造示例df对象
# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df8 = df.head()
print(df8)# 构造全是int类型的df
df9 = df8.drop('country', axis=1)
print(df9)def bar(s):# 此时s参数就是df中的一列数据,s对象# 函数也必须返回一列数据,s对象if s != 1960:return selse:return s + 1# 对原来的bar函数执行np.vectorize(),返回新的函数bar2
bar2 = np.vectorize(lambda x: bar(x))# 再使用新的bar2函数
df10 = df9.apply(bar2)
print(df10)
-
还可以利用装饰器对函数进行向量化
import pandas as pd
import numpy as np# 加载数据,构造示例df对象
# 读取数据选取前5行作为一个新的df
df = pd.read_csv('../datas/data_set/1960-2019全球GDP数据.csv', encoding='gbk')
df8 = df.head()
print(df8)# 构造全是int类型的df
df9 = df8.drop('country', axis=1)
print(df9)# 使用装饰器
@np.vectorize
def bar(s):# 此时s参数就是df中的一列数据,s对象# 函数也必须返回一列数据,s对象if s != 1960:return selse:return s + 1# 再使用被向量化装饰器装饰的bar函数
df10 = df9.apply(bar)
print(df10)
5.总结
-
df['列名'] = 标量或向量修改或添加列 -
<df / s>.drop([索引值1, 索引值2, ...])根据索引删除行数据 -
df.drop([列名1, 列名2, ...], axis=1)根据列名删除列数据 -
<df / s>.drop_duplicates()df或s对象去除重复的行数据 -
s.unique()s对象去除重复的数据 -
<df / s>.replace('原数据', '新数据', inplace=True)替换数据-
df或series对象替换数据,返回的还是原来相同类型的对象,不会对原来的df造成修改
-
如果加上inplace=True参数,则会修改原始df
-
-
df['指定列'][df['列名']=='x'] = y按条件df['列名']=='x'返回True的对应行的指定列的值修改为y -
apply函数-
s.apply(自定义函数名, arg1=xx, ...)对s对象中的每一个值,都执行自定义函数,且该自定义函数除了固定接收每一个值作为第一参数以外,还可以接收其他自定义参数 -
df.apply(自定义函数名, arg1=xx, ...)对df对象中的每一列,都执行自定义函数,且该自定义函数除了固定接收列对象作为第一参数以外,还可以接收其他自定义参数 -
df.apply(自定义函数名, arg1=xx, ..., axis=1)对df对象中的每一行,都执行自定义函数,且该自定义函数除了固定接收行对象作为第一参数以外,还可以接收其他自定义参数
-
-
new_func = numpy.vectorize(func)函数向量化,返回一个新的函数
6.项目地址:
Python: 66666666666666 - Gitee.com
相关文章:

[黑马程序员Pandas教程]——DataFrame数据的增删改操作
目录: 学习目标DataFrame添加列 直接赋值添加列数据删除与去重 删除 df.drop删除行数据df.drop删除列数据数据去重 Dataframe去重Seriers去重修改DataFrame中的数据 直接修改数据replace函数替换数据按条件使用布尔值修改数据执行自定义函数修改数据 Series.apply(…...
【服务器】Java连接redis及使用Java操作redis、使用场景
一、Java连接redis-No-SQL 1、导入依赖 在你的项目里面导入redis的pom依赖 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version> </dependency> 2、连接redis 连接redis …...

Spark 基础知识点
Spark 基础 本文来自 B站 黑马程序员 - Spark教程 :原地址 什么是Spark 什么是Spark 1.1 定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎 Spark最早源于一篇论文 Re…...

动作捕捉系统通过SDK与LabVIEW通信
运动分析、VR、机器人等应用中常使用LabVIEW对动作捕捉数据进行实时解算。NOKOV度量动作捕捉系统支持通过SDK与LabVIEW进行通信,将动作数据传入LabVIEW。 一、软件设置 1、形影软件设置 1、将模式切换到后处理模式 2、加载一个刚体数据 3、打开软件设置 4、选择网…...

【PTE-day02 sqlmap操作】
1、sqlmap简介 🍇sqlmap是一个自动化的SQL注入工具,其主要功能是扫描,发现并利用给定的URL进行SQL注入。目前支持的数据库有MySql、Oracle、Access、PostageSQL、SQL Server、IBM DB2、SQLite、Firebird、Sybase和SAP MaxDB等. Sqlmap采用了以下5种独特的SQL注入技术 (1)…...

2021年03月 Python(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
Python等级考试(1~6级)全部真题・点这里 一、单选题(共25题,每题2分,共50分) 第1题 不超过100个元素的有序数列,使用二分查找能找到指定的元素,可能的查找次数不包括? …...

2023.10.18 信息学日志
1. CF1689D Lena and Matrix 题目描述 n ⋅ m n \cdot m n⋅m 的矩阵,求矩阵上任意一点坐标使得到矩阵上的关键点曼哈顿距离最大值最小。数据范围: ∑ n ⋅ m ≤ 1 0 6 \sum n \cdot m \leq 10^6 ∑n⋅m≤106 题目概况 来源:Codeforces …...
)
Modbus封装库(Com,tcp,udp一应俱全)
自行封装在用的Modbus通迅库,集成了com,tcp,udp, 做个笔记吧, 以下头文件, #pragma once #include <functional> #include <vector> #include <string> #include <memory> #ifdef LIBMODBUS_EXPORTS #define LIBMODBUS_EXPORT_…...

专访HuggingFace CTO:开源崛起、创业故事和AI民主化丨智源独家
导读 HuggingFace CTO Julien Chaumond认为,在大模型时代,AI民主化至关重要。随着大语言模型和复杂人工智能系统的崛起,持续提升AI技术的可及性有助于确保这些技术的获取和控制不集中在少数强大实体手中。技术民主化促进了机会均等࿰…...
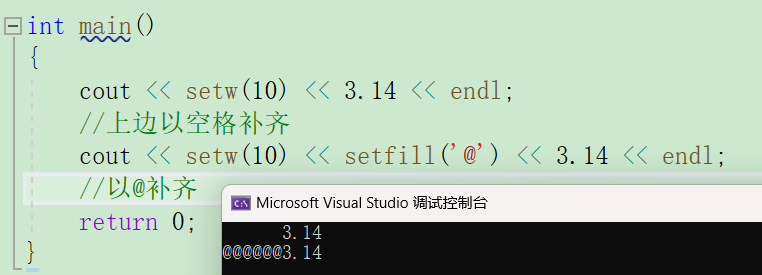
C++常用格式化输出转换
在C语言中可以用printf以一定的格式打印字符,C当然也可以。 输入输出及命名空间还不太了解的小伙伴可以看一看C入门讲解第一篇。 在C中,可以用流操作符(stream manipulators)控制数据的输出格式,这些流操作符定义在2…...

如何使用 Loadgen 来简化 HTTP API 请求的集成测试
引言 在编写 HTTP 服务的过程中,集成测试 1 是保证程序正确性的重要一环,如下图所示,其基本的流程就是不断向服务发起请求然后校验响应的状态和数据等: 为大量的 API 和用例编写测试是一件繁琐的工作,而 Loadgen 2 正…...

软件测试面试大家是不是一问到项目就不会了?
软件测试面试中,介绍做过的项目,可以说是必不可少的一道面试题了,对于面试的同学来说,该自己发挥呢? 把项目的所有功能噼里啪啦说一遍就完事了?当然不是,我们要搞清楚,面试官问这个…...

伐木猪小游戏
欢迎来到程序小院 伐木猪 玩法:控制小猪点击屏幕左右砍树,不能碰到树枝,考验手速与眼力,记录分数,快去挑战伐木吧^^。开始游戏https://www.ormcc.com/play/gameStart/199 html <script type"text/javascript…...
0007Java安卓程序设计-ssm基于Android的校园新闻管理系统
文章目录 **摘** **要**目 录开发环境 编程技术交流、源码分享、模板分享、网课教程 🐧裙:776871563 摘 要 网络的广泛应用给生活带来了十分的便利。所以把校园新闻管理与现在网络相结合,利用java技术建设校园新闻管理系统app,实…...
git增加右键菜单
有次不小心清理系统垃圾,把git右击菜单搞没了,下面是恢复方法 将下面代码存为.reg文件,双击后导出生效,注意,你安装的git必须是默认C盘的,如果换了地方要改下面注册表文件中相关的位置 Windows Registry …...

openGauss学习笔记-117 openGauss 数据库管理-设置数据库审计-查看审计结果
文章目录 openGauss学习笔记-117 openGauss 数据库管理-设置数据库审计-查看审计结果117.1 前提条件117.2 背景信息117.3 操作步骤 openGauss学习笔记-117 openGauss 数据库管理-设置数据库审计-查看审计结果 117.1 前提条件 审计功能总开关已开启。需要审计的审计项开关已开…...

学习代码20231106
解释代码:os.environ[“OMP_NUM_THREADS“] “1“ 这行代码涉及到 Python 的 os 模块和环境变量。它的作用是设置名为 “OMPNUMTHREADS” 的环境变量的值为 “1”。让我解释一下各部分的含义: 1.os.environ: 这是 Python 中的一个字典,包含…...

turtle绘制分形树-第10届蓝桥杯省赛Python真题精选
[导读]:超平老师的Scratch蓝桥杯真题解读系列在推出之后,受到了广大老师和家长的好评,非常感谢各位的认可和厚爱。作为回馈,超平老师计划推出《Python蓝桥杯真题解析100讲》,这是解读系列的第5讲。 turtle绘制分形树&…...

【大厂招聘试题】__硬件工程师_2021年“美团”校招
目录 匹配职位:硬件工程师 1.(多选题)单处理系统中,进程P1,P2,P3处于就绪队列,进程P4,P6处于等待队列,P5正占用处理器运行,以下对接下来的运行合理的分析是( ÿ…...

算法通关村第七关|黄金挑战|迭代实现二叉树的前、中、后序遍历
1.迭代实现前序遍历 public List<Integer> preOrderTraversal(TreeNode root) {List<Integer> res new ArrayList<Integer>();if (root null) {return res;}Deque<TreeNode> stack new LinkedList<TreeNode>();TreeNode node root;while (!…...

告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略
告别沉浸式白屏!UniApp中iOS/Android底部安全区与顶部状态栏颜色自定义全攻略当开发者尝试在UniApp中实现沉浸式设计时,往往会遇到一个令人头疼的问题——默认的白色安全区和状态栏导致界面元素(如电池图标、信号强度)几乎不可见。…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...
)
ArduPilot飞行模式实战:从代码角度看Stabilize、Acro、Loiter模式如何切换(附避坑指南)
ArduPilot飞行模式深度解析:从状态机到实战避坑指南 在开源飞控领域,ArduPilot以其强大的飞行模式系统著称。不同于普通用户只需了解模式功能,开发者更需要掌握模式切换的底层机制——这直接关系到飞行安全与二次开发效率。本文将带您深入Sta…...