深度图(Depth Map)
文章目录
- 深度图
- 深度图是什么
- 深度图的获取方式
- 激光雷达或结构光等传感器的方法
- 激光雷达
- RGB-D相机
- 双目或多目相机的视差信息计算深度
- 采用深度学习模型估计深度
- 深度图的应用场景
- 扩展阅读
深度图
深度图是什么
深度图(depth map)是一种灰度图像,其中每个像素点距离相机的距离信息。它是计算机视觉中常用的一种图像表示方式,用于描述场景的三维结构。

用张图简单直白的表示就是,越红的地方,代表距离观察者(即屏幕)的距离越近。看到图片中的锥体,距离我们观察的位置举例会比较近,所以颜色的更红。而图中的面具,由于是倾斜摆放的,其底部距离我们会更近一点,所以其底部的颜色要比顶部的颜色更红一些。
深度图的获取方式
深度图的发展历史可以追溯到20世纪60年代。最初,深度图像是通过手工标注或利用先验知识推测出来的。随着计算机视觉技术的发展,深度图像的获取方法和算法也不断进步和完善。
深度图的获取方式有多种,常见的方法包括:
-
通过激光雷达或结构光等传感器获取深度信息,再将其转换为深度图像。
-
利用双目或多目相机的视差信息计算深度,再将其转换为深度图像。
-
利用先验知识或模型对图像进行分析,推测出每个像素点的深度信息。
激光雷达或结构光等传感器的方法
激光雷达或结构光等传感器获得的深度,可以得到绝对深度,因为他们的数据是测出来的,根据TOF计算得到的真实距离。所以在连续的图片序列中,由于深度是绝对的,他们具有一样的参考价值。
激光雷达
这种方法也被叫做TOF方法(Time Of Fly)即通过激光/雷达波发出和收到的时间差,结合光速,计算信号在这段时间所走过的路程,所以也就能获得不同物体距离激光发射点的距离了。

RGB-D相机
另外,除了雷达之外激光雷达相机也可以实现类似的效果,也可以利用激光雷达和结构光的配合,获得更加精准的深度数值


双目或多目相机的视差信息计算深度
我们可以模拟人眼的工作方式,使用两个摄像机,这种方法被称为立体视觉。
在下图中,p是空间一点,z是其深度,Ol和Or是左右两个相机,对应上述的O和O’。f是相机焦距。
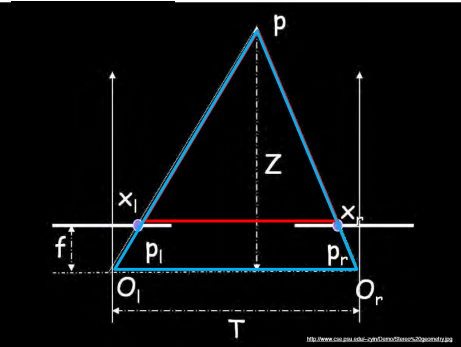
根据相似三角形的公式:
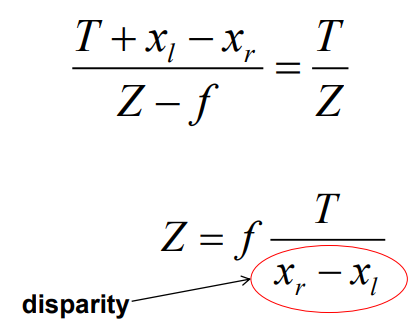
相机的焦距,两相机的距离都是已知的,这样我们可以轻松地知道一个点的深度与x和x’的查成反比,从而得到图中所有点的深度图。
OpenCV也提供了相关的计算函数:

这样我们就能够大致计算出图中的深度了:

可能你会想问,上面的深度图片都是彩色的,为什么这张变成和黑白的,但实际上
这才是深度图本来的样子
我们通过OpenCV的apploycolor map函数对灰度图进行了颜色的映射,让结果看起来更加的生动和fancy。
下面给一个示例来说明applyColorMap的作用:
def ColorMap_demo():img = cv.imread("lena.jpg",cv.IMREAD_GRAYSCALE)if img.shape[0]==0:print("load image fail!")returnwindowname="applyColorMap"cv.namedWindow(windowname,cv.WINDOW_AUTOSIZE)pos=0cv.createTrackbar("Type",windowname,pos,22,callback_trackbar)while True:pos = cv.getTrackbarPos("Type",windowname)imgdst = np.copy(img)if pos != 0 :imgdst = cv.applyColorMap(img,pos-1)cv.imshow(windowname,imgdst)if cv.waitKey(10) == 27:break
if __name__ == "__main__":ColorMap_demo()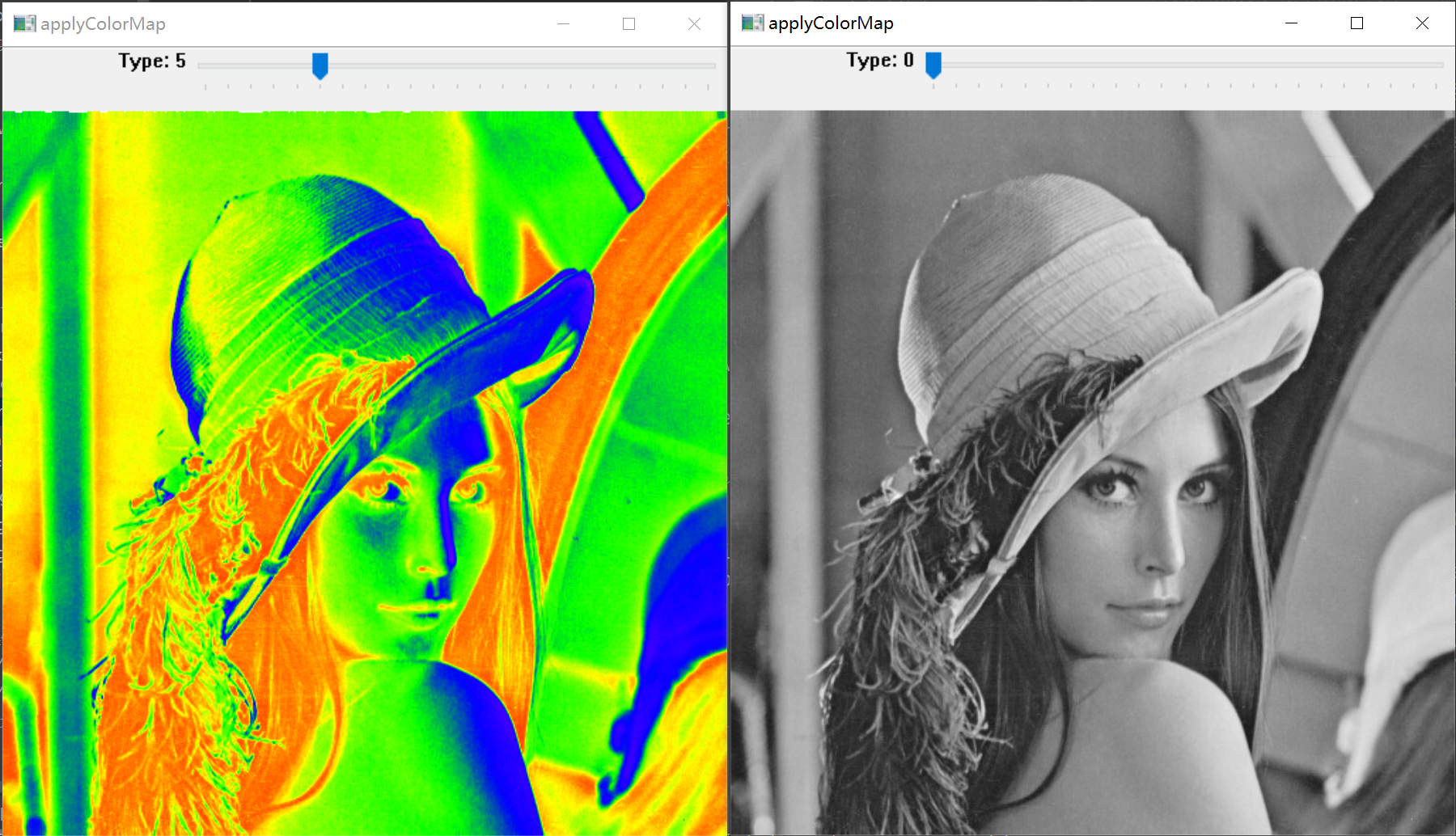

通过双目或多目相机获得的深度,也是绝对的深度,因为其原理是通过固定位置相机的相似三角形计算距离的。所以在连续的图片序列中,由于深度是绝对的,他们具有一样的参考价值。
采用深度学习模型估计深度
典型的采用深度学习的方式来估计RGB图像的深度的方法如下所示:
- 从RGBD相机的输出结果中,获取深度分量,得到真实的深度图。
- 仅输入RGB图,让模型生成对应的深度估计图
- 对模型的深度估计图和实际的深度图求差,获取估计的误差
- 深度学习网络的优化目标即为减小估计深度与实际深度的误差
- 在经过大量的训练之后,就能获得一个可以根据RGB图估计深度图的网络了

这里主要是指用模型估计图片中的物体深度,这样的方式获得的结果,在一张图片中不同的像素点之间的相对深度差,但是在在连续的图片序列中,两帧之间的深度估计结果没有必然的联系。例如,假设上面的面具是一个视频序列,在第一帧面具左眼的深度为100,面具右眼的深度估计为110.第二帧中,面具的左眼的深度可能是1000,而右眼的深度可能为1010。
可以发现,两帧之间同一区域的深度,在采用深度学习模型估计的时候,其绝对值结果是没有参考价值的:例如同样都是左眼,在第一帧中的深度和第二帧的深度估计数值甚至不在一个量级。
但是一帧内的不同位置,其相对深度是具有参考性的:例如不论在哪一帧,左眼和右眼的深度差始终为10.
这也正是由于深度学习模型训练的时候的策略所导致的,单目预测深度基本都是这种的拟合回归,本身数学上就是一个病态问题,不可能从单张2D的图片恢复出三维的信息。因为本身就是缺少信息的。
深度图的应用场景
-
三维重建:深度图可用于创建三维模型,例如建筑物、雕塑、人体等。
-
虚拟现实:深度图可用于创建虚拟现实环境,例如游戏、培训模拟器等。
-
自动驾驶:深度图可用于帮助自动驾驶汽车识别道路、障碍物和其他车辆。
-
医学成像:深度图可用于医学成像,例如X射线、CT扫描和MRI。
-
图层分隔:判断图片素材中物体的远近关系,实现图层前后信息的获取。
这里可以举一个自动驾驶的例子,即通过激光雷达获取周围的环境信息,用来感知各种物体与车体的距离。

扩展阅读
显著图(Saliency Map)
相关文章:
深度图(Depth Map)
文章目录 深度图深度图是什么深度图的获取方式激光雷达或结构光等传感器的方法激光雷达RGB-D相机 双目或多目相机的视差信息计算深度采用深度学习模型估计深度 深度图的应用场景扩展阅读 深度图 深度图是什么 深度图(depth map)是一种灰度图像…...

Ubuntu下Anaconda安装
Ubuntu下Anaconda安装 进入anaconda官网 https://www.anaconda.com/ 下载Linux64位版本; 将下载好的".sh"文件放入虚拟机中; 运行指令sudo bash Anaconda3-2023.09-0-Linux-x86_64.sh 此后会自动加载安装程序,中途会停止两次&am…...
目标检测回归损失函数(看情况补...)
文章目录 L1 loss-平均绝对误差(Mean Absolute Error——MAE)L2 loss-均方误差(Mean Square Error——MSE)Smooth L1 LossMAE、MSE、Smooth L1对比IoU LossGIoU LossDIoU Loss、CIoU LossE-IoU Loss、Focal E-IoU LossReferenceL1 loss-平均绝对误差(Mean Absolute Error——…...
将 Figma 轻松转换为 Sketch 的免费方法
最近浏览网站的时候,发现很多人不知道Figma是怎么转Sketch的。众所周知,Figma支持Sketch文件的导入,但不支持Sketch的导出,那么Figma是如何转Sketch的呢?不用担心,建议使用神器即时设计。它是一个可以实现在…...

GPU推理提速4倍!FlashDecoding++技术加速大模型推理
推理大模型(LLM)是AI服务提供商面临的巨大经济挑战之一,因为运营这些模型的成本非常高。FlashDecoding 是一种新的技术,旨在解决这一问题,它通过提高LLM推理速度和降低成本,为使用大模型赚钱提供了新的可能…...
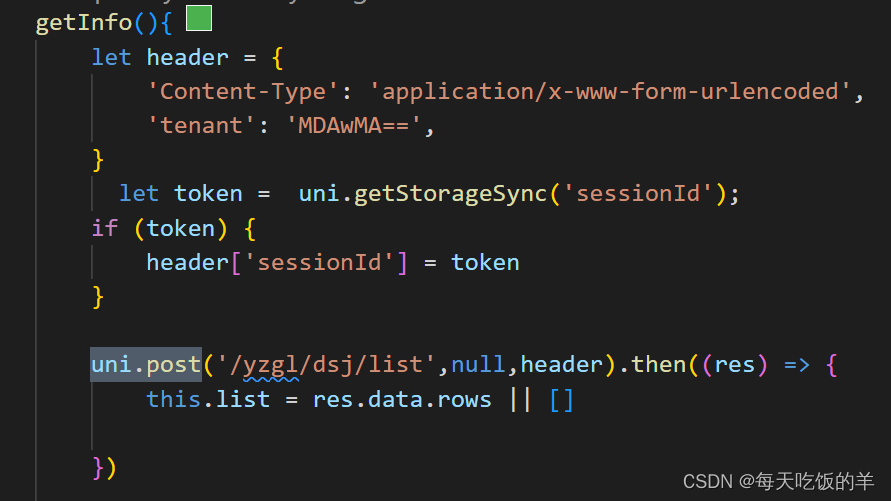
class类默认导出,header字段在请求中的位置
这是封装好的,没封装的如下 如果没有用uni.post那么就是如下的结构 let header {Content-Type: application/x-www-form-urlencoded,tenant: MDAwMA, } request({url:/sal/formula/validFormula,method:post,data:{},header })...

PHP将pdf转为图片后用OCR识别
1.确保apt包是最新 sudo apt update 2.使用apt安装 sudo apt install tesseract-ocr 3.检查版本 tesseract --version 4.pdf转成图片,这边需要安装imagick插件 $pdf new Imagick(); $pdf->setResolution(150, 150); $pdf->readImage(..$temp); $pdf->…...

IDEA 函数下边出现红色的波浪线,提示报错
Inferred annotations: Method makeOkResult: org.jetbrains.annotations.Contract("_, _, _, _ -> new") org.jetbrains.annotations.NotNull Parameter headers: org.jetbrains.annotations.NotNull 出现这个提示,我应该怎么处理这个函数࿱…...
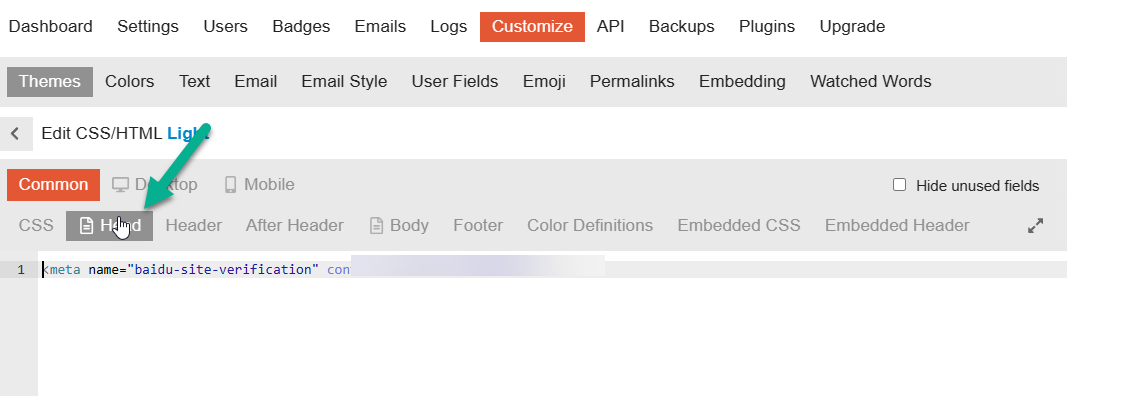
Discourse 如何在 header 上添加 HTML
虽然现在大部分网站都开始支持使用 CDN 的网站校验了。 但还有些网站在你需要他们提供服务的时候要求使用 header 的 meta 数据校验。 Discourse 是可以轻松的实现上面的功能的。 添加方法 选择你的 Discourse 网站下的自定义。 然后在左侧选择你需要添加的主题。 为了方便…...

[深入理解SSD] 总目录
SSD 综述 [SSD综述 1.1] 导论_SSD让开机击败99%的电脑 [SSD综述 1.2] 固态硬盘(SSD)和机械硬盘(HDD)区别对比介绍? [SSD综述 1.3] SSD及固态存储技术30年简史 [SSD综述 1.4] SSD固态硬盘的结构 [SSD综述 1.5] SSD 主控和固件核心功能详解 [S…...
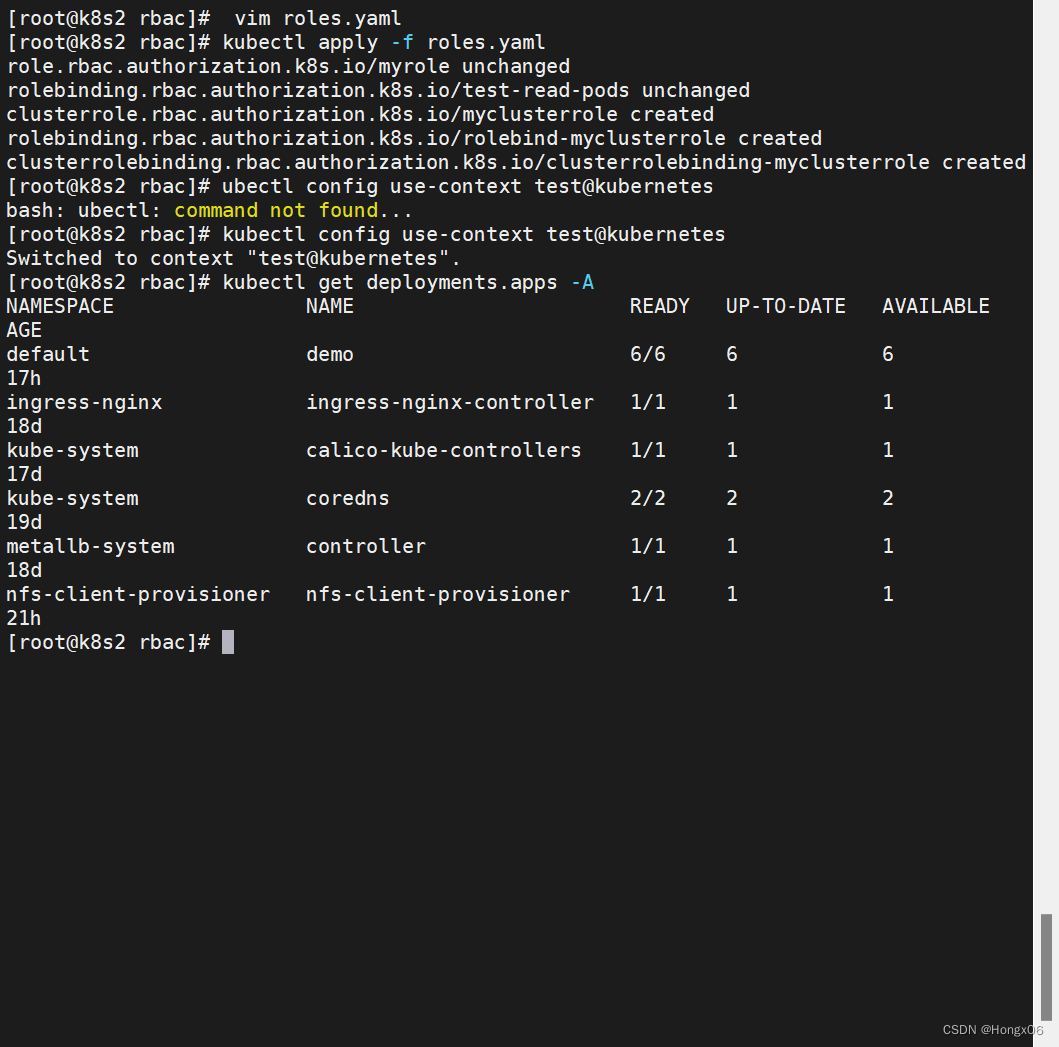
kubernetes集群编排(7)
目录 k8s认证授权 pod绑定sa 认证 授权 k8s认证授权 pod绑定sa [rootk8s2 ~]# kubectl create sa admin //在当前 Kubernetes 集群中创建一个名为 "admin" 的新服务账户[rootk8s2 secret]# vim pod3.yaml apiVersion: v1 kind: Pod metadata:name: mypod spec…...

mfc 下的OpenGL
建立一个SDI 的MFC工程,然后按freeglut 在mfc 下的编译_leon_zeng0的博客-CSDN博客 一文设置好include lib 路径 在view 中建立这2个函数: // Standard OpenGL Init StuffBOOL CmfcOpenglDemoView::SetupPixelFormat() {static PIXELFOR…...

机器翻译目前广泛应用于文档翻译以及硬件翻译
机器翻译(Machine Translation,MT)是一种自动化技术,用于将一种语言的文本转换为另一种语言的文本。它通常被用于跨语言交流和全球化的需求。 机器翻译目前可分为软件和硬件,软件常用的则是文档翻译、文字翻译、图片翻…...

木材加工工厂数字孪生可视化管理平台,赋能传统木材制造业数字化高质转型
数字化是当今经济发展的主流话题,以赋能传统制造业转型升级的需求最为迫切、效果最为显著。目前世界各国正积极发力智能制造,力求争夺智能制造领先位置,而构建适应传统制造业转型的数字化平台成为当务之急。数字化、智能化已成为木材加工行业…...

企业级低代码开发,科技赋能让企业具备“驾驭软件的能力”
科技作为第一生产力,其强大的影响力在各个领域中都有所体现。数字技术,作为科技领域中的一股重要力量,正在对传统的商业模式进行深度的变革,为各行业注入新的生命力。随着数字技术的不断发展和应用,企业数字化转型的趋…...
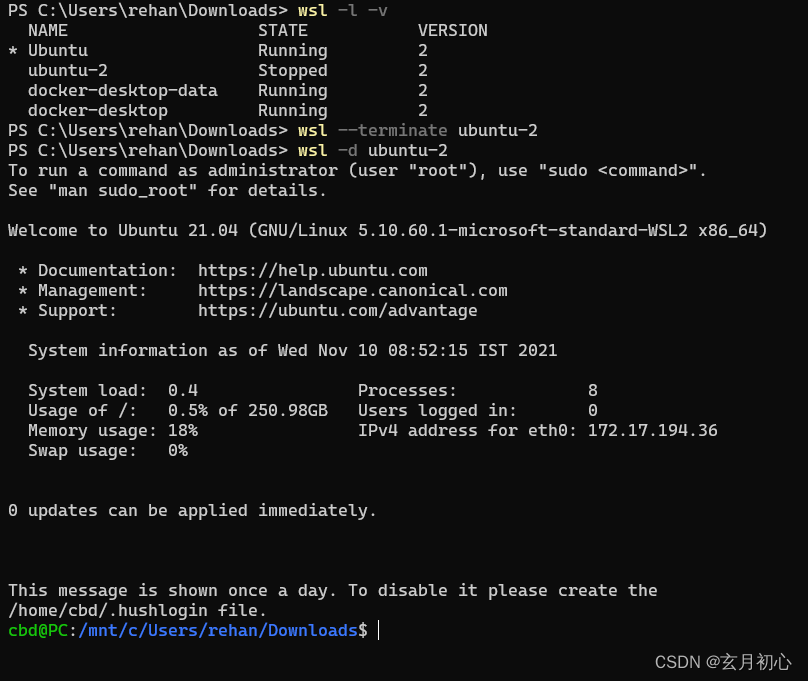
在WSL2中安装多个Ubuntu实例
参考:How to install multiple instances of Ubuntu in WSL2 本文主要内容 第一步:在 WSL2 中安装最新的 Ubuntu第二步:下载适用于 WSL2 的 Ubuntu 压缩包第三步:在 WSL2 中安装第二个 Ubuntu 实例第四步:登录到第二个…...

java--实体javaBean
1.什么是实体类 1.就是一种特殊形式的类 2.这个类中的成员变量都要私有,并且要对外提供相应的getXXX,setXXX方法 3.类中必须要有一个公共的无参的构造器 2.实体类有啥应用场景 实体类只负责数据存取,而对数据的处理交给其他类来完成&…...

重温设计模式之什么是设计模式?
设计面向对象软件比较困难,而设计可复用的面向对象软件就更加困难。你必须找到相关的对象,以适当的粒度将它们归类,再定义类的接口和继承层次,建立对象之间的基本关系。你的设计应该对手头的问题有针对性,同时对将来的…...

CSS关于默认宽度
所谓的默认宽度,就是不设置width属性时,元素所呈现出来的宽度 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title></title><style>* {margin: 0;padding: 0;}.box {/…...

JDBC(二)
第4章 操作BLOB类型字段 4.1 MySQL BLOB类型 MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器,它能容纳不同大小的数据。 插入BLOB类型的数据必须使用PreparedStatement,因为BLOB类型的数据无法使用字符串拼接写…...
✨)
【flutter for open harmony】第三方库Flutter 鸿蒙版 购物车 实战指南(适配 1.0.0)✨
【flutter for open harmony】第三方库Flutter 鸿蒙版 购物车 实战指南(适配 1.0.0)✨ Flutter 三方库 cached_network_image 的鸿蒙化适配与实战指南 欢迎加入开源鸿蒙跨平台社区: https://openharmonycrossplatform.csdn.net 本文详细介绍…...
)
用Python处理Himawari-8卫星数据:从NC文件到带地理坐标的TIFF(附完整代码)
Python实战:Himawari-8卫星数据全流程处理指南 气象卫星数据就像地球的"CT扫描片",而Himawari-8(向日葵8号)作为东亚地区最重要的静止气象卫星之一,其高频次、高分辨率的观测能力让气象分析和环境监测有了质…...

从修补Boot到反编译锁屏:一个安卓ROM修改新手的完整避坑日记
从修补Boot到反编译锁屏:一个安卓ROM修改新手的完整避坑日记 第一次接触安卓ROM修改时,我像大多数新手一样充满热情却屡屡碰壁。那些看似简单的解包、修改、打包操作背后,隐藏着无数让设备变砖的陷阱。这篇日记记录了我从零开始学习安卓ROM修…...

BBDown深度解析:构建高效B站视频下载工作流的5个关键技术点
BBDown深度解析:构建高效B站视频下载工作流的5个关键技术点 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown BBDown是一个强大的命令行式哔哩哔哩下载器,专为技术…...

3分钟实现Figma全中文界面:设计师的终极汉化指南
3分钟实现Figma全中文界面:设计师的终极汉化指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 你是否曾因为Figma的英文界面而感到困扰?面对"Component&q…...

搞懂5G QoS配置:QCI/5QI、ARP、GBR/MBR参数到底怎么设?一个实战案例说清楚
5G QoS实战指南:从参数解析到企业物联网配置案例 在5G网络部署中,服务质量(QoS)配置直接决定了关键业务的传输质量。不同于4G时代相对简单的带宽分配,5G QoS需要针对不同业务类型(如增强移动宽带eMBB、超可靠低时延通信uRLLC、海量…...

告别Printf:用Qt Creator+GDB Server远程调试ARM程序,实时查看变量和内存
告别Printf:用Qt CreatorGDB Server远程调试ARM程序,实时查看变量和内存 调试嵌入式系统时,最令人沮丧的莫过于反复烧录程序、添加打印语句、重新编译的循环。这种低效的调试方式不仅浪费时间,还容易遗漏关键问题。想象一下&#…...

XAPK转换APK终极指南:3步解决Android应用安装难题 [特殊字符]
XAPK转换APK终极指南:3步解决Android应用安装难题 🚀 【免费下载链接】xapk-to-apk A simple standalone python script that converts .xapk file into a normal universal .apk file 项目地址: https://gitcode.com/gh_mirrors/xa/xapk-to-apk …...

Windows 11任务管理器隐藏技能:教你查看进程的“分页”与“非分页”内存占用
Windows 11任务管理器隐藏技能:深度解析进程内存占用 每次电脑卡顿得像老牛拉破车时,大多数人只会机械地打开任务管理器,盯着CPU和内存百分比发呆。但你知道吗?Windows 11的任务管理器里藏着一把瑞士军刀——它能让你看到更精细的…...
✨)
【flutter for open harmony】第三方库Flutter 鸿蒙版 底部导航栏 实战指南(适配 1.0.0)✨
【flutter for open harmony】第三方库Flutter 鸿蒙版 底部导航栏 实战指南(适配 1.0.0)✨ Flutter 三方库 cached_network_image 的鸿蒙化适配与实战指南 欢迎加入开源鸿蒙跨平台社区: https://openharmonycrossplatform.csdn.net本文详细介…...