有效降低数据库存储成本方案与实践 | 京东云技术团队
背景
随着平台的不断壮大,业务的不断发展,后端系统的数据量、存储所使用的硬件成本也逐年递增。从发展的眼光看,业务与系统要想健康的发展,成本增加的问题必须重视起来。目前业界普遍认同开源节流大方向,很多企业部门也针对数据库存储降低成本进行了尝试,有的删数据、有的删索引、有的做压缩、有的做冷热分离,方式方法层出不穷,不一而足,然而不是因为收效甚微而导致没有达到预期,就是由于改造成本过大,投入周期过长,导致投产比不高,虚耗人力。笔者目前所在部门也正好面临同一问题,一个账单系统,存储数据超过100T,占用40台物理机,40库,一个分表就有20480张,这样的分表有4个,这种存储架构相对臃肿,要想实践降低成本的诉求,难度很高。
本文主要介绍方法,方案也会涉及,但不会特别细致的展开。
挑战
核心挑战有以下几个:
数据安全问题:无论是删数据,做压缩,冷热分离,对于已经占据100T磁盘空间的存储系统都是困难的操作,一个不小心,数据丢失了,或者无法正常获取数据了,这些问题对部门、对公司都会造成巨大损失。
系统稳定性问题:一些有效的降低存储空间的方案,如数据序列化、压缩等,无外乎是用时间换空间,牺牲性能换取磁盘空间的降低,那么从实际业务影响来看,用户看到页面的耗时增高了(读延时),或用户看到自己的数据迟迟未更新(写延时),用户的使用体验会降低。从系统影响的角度来看,读写耗时的增高,对于系统本身饱和度会产生影响,写方面,吞吐量下降了,读方面,耗时增加了,这些变化会导致系统线程数增高甚至导致线程堆积,cpu占用也会相应增高,最终可能会产生系统拒绝请求,系统夯住等问题。
收益问题:中文互联网上,数据库存储成本降低方案永远能看到一些词汇,如“删索引”,“元数据清理”,“冷热分离”等,这些眼熟的词汇,看似收益不错,大家也常提起。然而,删索引的收益受到实际使用索引的情况,收益浮动非常之大。我们都知道索引有单字段索引,有多字段的联合索引,联合索引会产生笛卡尔积的复杂度,如5岁的张三,6岁的张三,5岁的李四,10岁的李四等等,这样则不好测算删除某个索引所带来的正向收益。因此删除索引这个方案通常是在索引滥用的情况下使用,在清理滥用索引的过程中,附带降低了一些磁盘占用。而“冷热分离”是另一种极端,它改变了原有系统的存储架构,架构合理性也许会提升,但这个系统改造成本是巨大的,如冷热数据的同步机制,冷数据的迁移方案,原数据库冷数据清理方案,冷数据压缩方案、生产灰度方案等。改造成本非常高,周期长,耗费人力大,风险还非常高,唯一值得欣慰的是效果通常能够达到预期。
体系化方法
| 字段 | 表 | 库 | |
|---|---|---|---|
| 删 | 删除无效表 | ||
| 减 | 减少无效数据 减少无效索引 | ||
| 缩 | 大字段压缩 | 大表压缩 | 冷热分离 |
中文互联网上的缩减数据库磁盘空间的方案很多,但大多是方案的陈述,对于如何针对目标系统制定适合的缩减方案的内容很少,其实按照麦肯锡切分法的逻辑切分法就可进行一个方法总结。上图的九宫格,就是按照笔者的实践经验,总结出一个体系化成本降低的方法。
九宫格
按逻辑梳理的办法,方案可针对字段、表和库3个维度,结合删、减、缩3种策略进行梳理,如删除表、清理部分表数据、压缩部分表的存储空间等。结合系统的实际情况,按照表格进行梳理,就能得到适合目标系统的成本降低方案了。
笔者通过表格,结合账单系统实际情况,梳理出的执行的方案,1、大表压缩,2、大JSON字段序列化,3、删除无效数据,4、无效表删除,5、无效索引删除,6、冷热分离。
这么多的方案,总不能囫囵吞枣的瞎干吧,优先干哪个呢?他们的收益又是怎么样的呢?
收益测算
在实际的方案阶段,都需要对方案产生的收益进行度量,再按照投产比,决定方案执行的优先级。
测算方法
无论何种方案,测算起来无外乎抽样、估算减少量、计算占比几个过程。
举个例子
以大JSON字段序列化为例,某个字段存储的是大json串,占用的字符比较多,因此对该字段做压缩,能够有效的降低磁盘占用空间。这个方案如何测算呢?思路是这样的,首先计算出目标大json字段占一条数据字符长度的比例,然后根据压缩比,得出压缩后该字段减少的字符数占比,之后抽样此表的data文件占的磁盘空间(如3g),得出单表通过压缩后下降的磁盘空间(如1.2g),最终再乘以该表的数量(如20480),就能估算出最终减少的磁盘空间。最终计算公式: [压缩后减少的字符数/总字符数]_单表空间_表数量=[大json字符数*(1-压缩比)/总字符数]_单表空间_表数量=12t 磁盘减少占比:12t/95.9t=12%
如何得到字段的字符数?
可运用select LENGTH语法得出。具体计算可参照下表:

最终账单系统各方案的测算结果,大表压缩32%,大JSON字段序列化12%,删除无效数据10%,无效表删除与无效索引删除都在1%左右。通过测算情况,我们就可以建立方案执行的优先级了,step1大表压缩,step2大JSON字段序列化,step3删除无效数据等。冷热分离有收益,但是成本太高,可在日后架构升级中,再去考虑。
数据安全与系统稳定性
前文提到过,无论采用何种方案,数据安全与系统稳定性都需要验证的,数据丢失、或系统不可用、或降低用户体验下降过多都是不可接受的。因此需要保障这些情况尽量不要发生,或即使发生了,问题也在可控、可接受范围内。
方法
黄金指标
任何稳定性或安全性问题,都可通过google SRE的4个黄金指标去归纳,即异常(exception)、耗时(tp99等)、流量(tps)、饱和度(cpu、内存、磁盘、网络等)。
可以结合目标系统的关键时段来看这4个黄金指标,例如大表压缩方案,那就可以关注压缩时的异常、耗时等,压缩后的异常耗时等等。
结合实际验证项
压缩时:1、读写耗时是否增加?2、吞吐量是否受到影响?3、压缩是否会产生异常?4、异常后压缩过程能否正常回滚?5、压缩是否会导致数据丢失?
压缩后&大促高峰期:1、读写耗时是否增加?2、吞吐量是否受到影响?3、压缩后大促流量是否能够应对?
这些问题如果有一项未验证或验证未通过,都不能执行压缩方案,因为方案执行后可能会对数据安全与系统稳定造成影响。
如何验证呢?
最严重的问题压缩是否会导致数据丢失,想通过一些方法验证这个问题非常困难的,只能通过mysql的压缩过程原理去分析。

从官方文档中提炼出了Online DDL的4个步骤,从图中可看出,在任何阶段原表数据都不会丢失,直到完成切换后,原表才会被定期清理,因此压缩过程中数据是安全的。
第二个需要验证的是压缩时、压缩后与大促高峰期整个系统的读写耗时与吞吐量。
第一步:搭建等比验证环境
以文中账单系统实践为例,将生产的一个分库完全复制到一个新的物理机上,这样就以20:1的比例搭建了验证库。

第二步:模拟流量
这一步,需要结合目标系统的实际情况,完全模拟系统高峰期的流量,文中的账单系统是通过改造代码来达到流量预期的,如果所在部门原本就具备压测条件,可直接调整压测robot的流量开启压测程序来达到流量预期。

流量达标后,通过观察压缩时或压缩后系统的吞吐量、写入的耗时以及慢sql等情况,来判断压缩对系统及数据库的影响。如果此步发现了明显的慢sql或吞吐量异常,就需要考量这些情况是否会影响系统的SLA指标,同时还要考量系统及业务能否容忍压缩所带来的负面影响。
压缩回滚问题
账单系统在做模拟流量压测时,意外的发生了异常,导致了压缩过程回滚。这也变相验证了,压缩过程是可回滚的。异常比较常见,duplicate key,这个异常是唯一索引重复导致。这个问题需要重视,因为账单系统会接收各种业务方的mq消息,难免会有这种重复下发过来的mq,如果经常出现这种异常,最坏的情况是某些相关表永远无法压缩成功。如下图
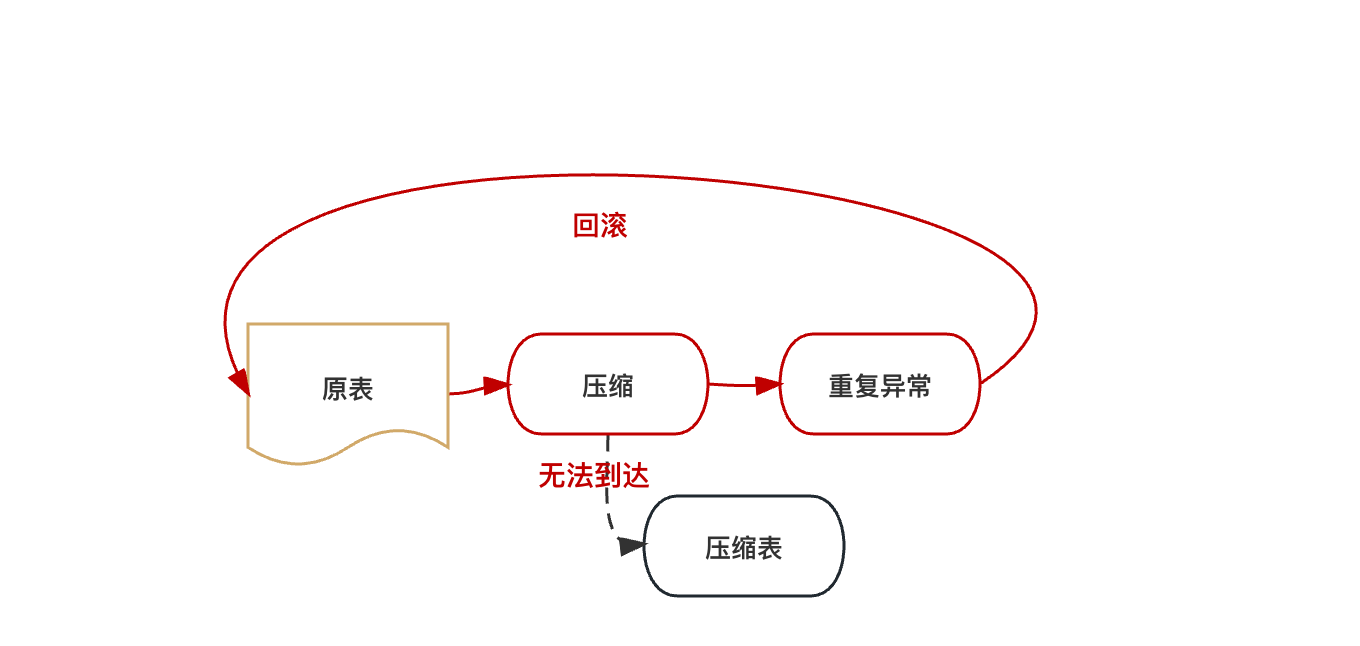
解决这个问题的方法很多,这里不赘述,但异常情况是做压缩过程中必须避免的。
方案落地
灰度
在方案的落地过程中,需要有灰度过程,来观察方案在生产环境中的执行是否会产生意料之外的问题。灰度的方法应视具体情况而定,但任何的灰度方案都应该至少考虑故障、业务与性能3个方面。
(故障)影响范围控制:以小见大,第一阶段的灰度一定是以最细颗粒度方案进行落地的,以便观察系统是否稳定、业务是否正常,这样即使出现意料之外的问题,影响的用户也是非常少的,不至于引起舆情。以表压缩为例,刚开始只压缩一张表,观察情况,随时准备回滚。
(业务)全场景安全:遵循灰度周期递减的方式,第一阶段灰度开始时,经历的时间要足够长,确保新的内容已经经历过所有生产场景(all story)的考验,这样能够保障新的内容在业务上是正确的,之后可以逐步的缩短验证周期,加快灰度进程。
(性能)高流量验证:高峰期考验,每个灰度阶段都至少经历一个流量高峰期,来验证新内容的性能是否能够承受高峰流量。为什么每个灰度阶段都要经历高峰期流量,第一阶段灰度的时候已经经历过一次高峰期流量验证了吗?这样做验证逻辑是有漏洞的,系统作为一个整体,当其中大部分内容替换成新内容后,整个系统饱和度会随之产生变化,如表压缩场景,是用时间换空间,因此可能影响系统的吞吐量,起初压缩一张表时,高峰期系统吞吐量可能并没有什么影响,之后压缩100张表后,高峰期系统开始有些流量积压,到最后10000张表压缩后,高峰期系统可能产生大量积压。像吞吐量这种宏观指标,在每个灰度阶段都必须关注。因此每个灰度阶段,都必须经历至少一个流量高峰期,才能证明系统的性能是没问题的。
回滚
在方案的灰度过程中,必须有相应的回滚手段,以便灰度产生问题后,能够及时的回滚止损。回滚方案中,需要注意的有两点,1是及时,2是有效,如压缩方案中的回滚方案是解压缩命令(通过alter),及时提工单即可执行。
总结
本文主要以介绍方法为主,落地过程可以归纳为方案->收益测算->数据安全验证->系统稳定性验证->灰度与回滚。文中的账单系统通过step1大表压缩32%,step2大JSON字段序列化12%,step3删除无效数据10%,3个方案的顺利落地,有效的减少了50.7%的磁盘空间,成本下降也非常显著。最后,希望此文能够给还在迷茫,不知从何处下手落地数据库存储成本降低的同学一些启发和灵感,以上。
作者:京东科技 李阳
来源:京东云开发者社区 转载请注明来源
相关文章:
有效降低数据库存储成本方案与实践 | 京东云技术团队
背景 随着平台的不断壮大,业务的不断发展,后端系统的数据量、存储所使用的硬件成本也逐年递增。从发展的眼光看,业务与系统要想健康的发展,成本增加的问题必须重视起来。目前业界普遍认同开源节流大方向,很多企业部门…...
分布式数据库Schema 变更 in F1 TiDB
分布式数据库Schema 变更 in F1 & TiDB 【转载】TiDB 源码阅读系列文章(十七)DDL 源码解析 | PingCAP 上述文章主要叙述了从DDL语句发起到执行的过程,简单介绍了弄一套相同的模式来后台处理数据回填,从而提高DDL的并发度的一…...

图形库篇 | EasyX | 图像处理
图形库篇 | EasyX | 图像处理 图像类型 IMAGE表示图像,用于定义一个图像变量,与导入的图片资源一一对应。 IMAGE img;加载与绘制图像 函数功能函数加载图像void loadimage(IMAGE* pDstImg,LPCTSTR pImgFile,int nwidth = 0,int nHeight = 0,bool bResize = false)绘制图像v…...

AWTK UI 自动化测试工具发布
AWTK UI 自动化 提供了兼容 Appium 的接口,可以使用 Appium 的工具来进行 UI 自动化测试。但是使用起来有点麻烦,用的人不多,所以最终决定开发一个 AWTK 专用的 UI 自动化测试工具。相比 Appium,这个工具有下列特点: …...
Java后端开发——JDBC入门实验
JDBC(Java Database Connectivity)是Java编程语言中用于与数据库建立连接并进行数据库操作的API(应用程序编程接口)。JDBC允许开发人员连接到数据库,执行各种操作(如插入、更新、删除和查询数据)…...

LCA
定义 最近公共祖先简称 LCA(Lowest Common Ancestor)。两个节点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。 性质 如果 不为 的祖先并且 不为 的祖先,那么 分别处于 的两棵不同子树中&#…...

ts学习02-数据类型
新建index.html <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> </h…...

javaSE的发展历史以及openjdk和oracleJdk
1 JavaSE 的发展历史 1.1 Java 语言的介绍 SUN 公司在 1991 年成立了一个称为绿色计划(Green Project)的项目,由 James Gosling(高斯林)博士领导,绿色计划的目的是开发一种能够在各种消费性电子产品&…...
【入门Flink】- 10基于时间的双流联合(join)
统计固定时间内两条流数据的匹配情况,需要自定义来实现——可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink 的 DataStrema API 提供了内置的 join 算子。 窗口联结(Window Join) 一…...

【Python Opencv】图片与视频的操作
文章目录 前言一、opencv图片1.1 读取图像1.2 显示图像1.3 写入图像1.4 示例代码 二、Opencv视频2.1 从相机捕获视频获取摄像头一帧一帧读取显示图片VideoCapture 中的get和set函数示例代码 2.2 从文件播放视频示例代码 2.3 保存视频示例代码 总结 前言 在计算机视觉和图像处理…...
【从入门到起飞】JavaAPI—System,Runtime,Object,Objects类
🎊专栏【JavaSE】 🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。 🎆音乐分享【如愿】 🎄欢迎并且感谢大家指出小吉的问题🥰 文章目录 🍔System类⭐exit()⭐currentTimeMillis()🎄用…...
【Git】的分支和标签的讲解及实际应用场景
目录 讲解 环境讲述 分支标签的区别 分支 命令 场景应用 标签 命令 标签规范 讲解 环境讲述 当软件从开发到正式环境部署的过程中,不同环境的作用 开发环境:用于开发人员进行软件开发、测试和调试。在这个环境中,开发人员可以快速地…...
修改django开发环境runserver命令默认的端口
runserver默认8000端口 虽然python manage.py runserver 8080 可以指定端口,但不想每次runserver都添加8080这个参数 可以通过修改manage.py进行修改,只需要加三行: from django.core.management.commands.runserver import Command as Ru…...

kubeadm安装k8s高可用集群
目录 一、环境规划 二、注意事项: 三、环境准备: 1. 关闭防火墙规则,关闭selinux,关闭swap交换: 2. 修改主机名 3. 所有节点修改hosts文件: 4. 所有节点时间同步: 5. 所有节点实现Linux的资…...

来看看电脑上有哪些不为人知的小众软件?
电脑上的各类软件有很多,除了那些常见的大众化软件,还有很多不为人知的小众软件,专注于实用功能,简洁干净、功能强悍。 1.桌面停靠栏工具——BitDock BitDock是一款运行在Windows系统中的桌面停靠栏工具,功能实…...
一个进程最多可以创建多少个线程?
前言 话不多说,先来张脑图~ linux 虚拟内存知识回顾 虚拟内存空间长啥样 在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常见的 32 位和 64 位系统&am…...
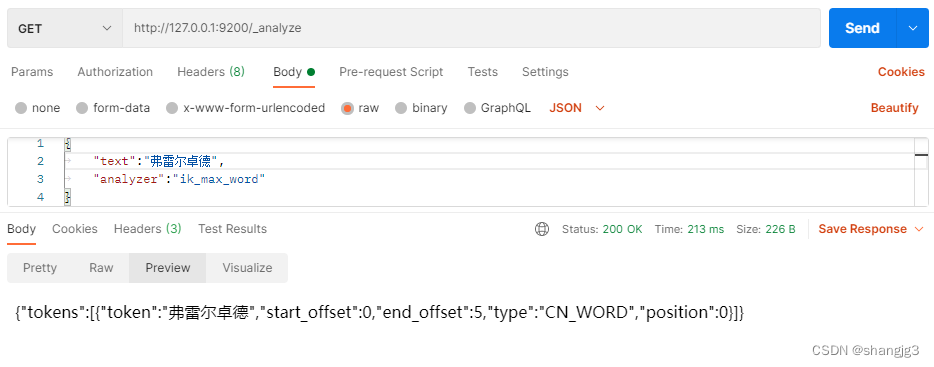
ElasticSearch文档分析
ElasticSearch文档分析 包含下面的过程: 将一块文本分成适合于倒排索引的独立的 词条将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall 分析器执行上面的工作。分析器实际上是将三个功能封装到了一个包里: 字符过滤器 首先&a…...
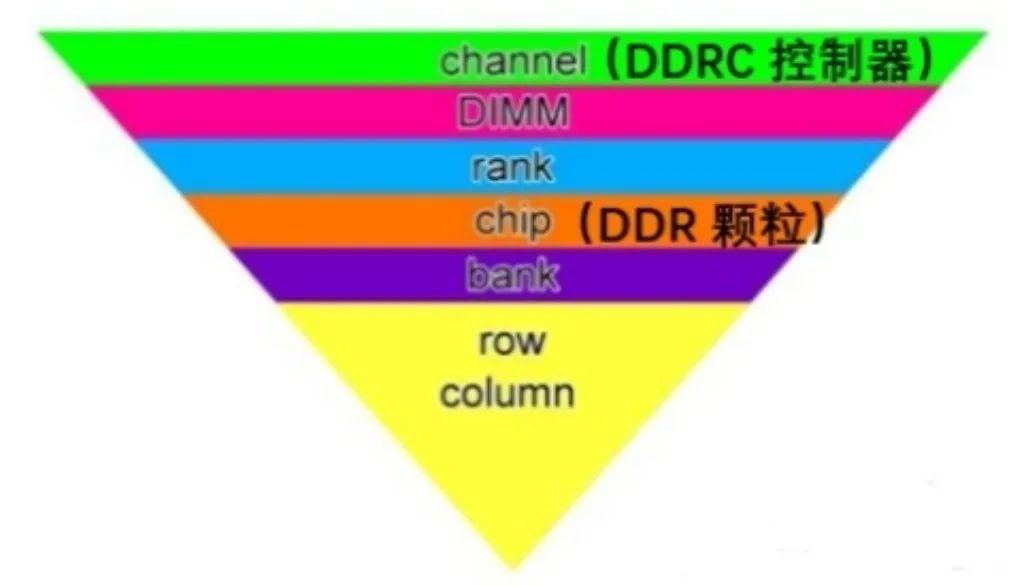
Xilinx FPGA平台DDR3设计详解(一):DDR SDRAM系统框架
DDR SDRAM(双倍速率同步动态随机存储器)是一种内存技术,它可以在时钟信号的上升沿和下降沿都传输数据,从而提高数据传输的速率。DDR SDRAM已经发展了多代,包括DDR、DDR2、DDR3、DDR4和DDR5,每一代都有不同的…...
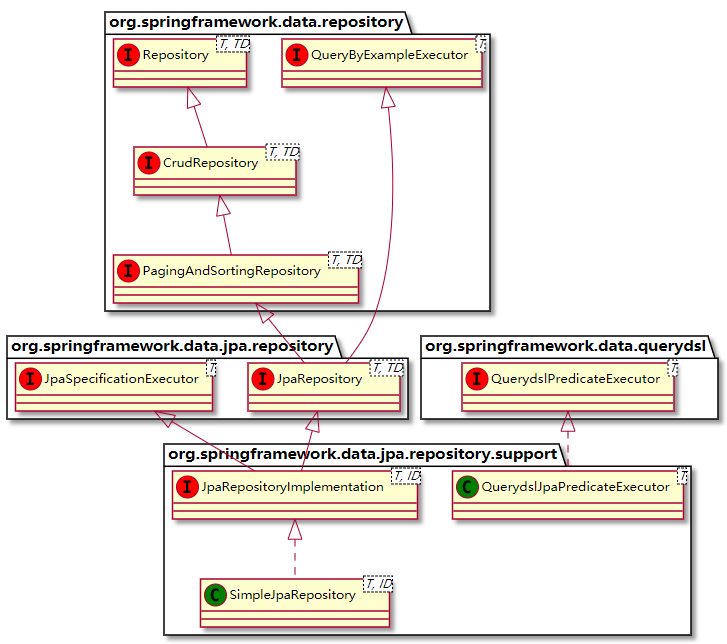
Spring Data JPA方法名命名规则
最近巩固一下JPA,网上看到这些资料,这里记录巩固一下。 一、Spring Data Jpa方法定义的规则 简单条件查询 简单条件查询:查询某一个实体类或者集合。 按照Spring Data的规范的规定,查询方法以find | read | get开头&…...

【Leetcode Sheet】Weekly Practice 15
Leetcode Test 2586 统计范围内的元音字符串数(11.7) 给你一个下标从 0 开始的字符串数组 words 和两个整数:left 和 right 。 如果字符串以元音字母开头并以元音字母结尾,那么该字符串就是一个 元音字符串 ,其中元音字母是 a、e、i、o、u…...

WindowsCleaner:终极系统优化解决方案,彻底解决C盘空间不足问题
WindowsCleaner:终极系统优化解决方案,彻底解决C盘空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner WindowsCleaner是一款专为…...

Stable-Diffusion-v1-5-archive行业落地:教育课件配图、自媒体封面、独立游戏素材生成
Stable Diffusion v1.5 Archive:教育课件、自媒体封面与独立游戏素材的生成利器 1. 引言:一个经典模型,三个创意场景 如果你是一位教育工作者,是否曾为找不到合适的课件配图而烦恼?如果你是一名自媒体创作者…...

避开这4个坑,你的FANUC数据采集项目能省一个月:从DLL缺失到状态判断逻辑
FANUC数据采集实战:从DLL缺失到状态机设计的避坑全指南 第一次接触FANUC CNC数据采集时,我天真地以为这不过是调用几个API的简单任务。直到项目延期三周后,我才明白工业设备数据采集的复杂性远超想象——从动态链接库缺失到参数地址定位&…...

QMCDecode:解锁QQ音乐加密格式,让音乐真正属于你
QMCDecode:解锁QQ音乐加密格式,让音乐真正属于你 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,…...

Blender MMD Tools插件完全指南:从入门到精通
Blender MMD Tools插件完全指南:从入门到精通 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools 你是否曾经…...

如何通过 SEO 和 ASO 提高网站和应用的转化率
SEO和ASO:双管齐下提高网站和应用的转化率 在当今数字化时代,网站和应用的成功不仅取决于其功能和用户体验,更在于如何吸引流量并将其转化为实际用户。这就需要我们深入了解和运用搜索引擎优化(SEO)和应用商店优化&am…...

Qwen3-TTS开源镜像部署:RabbitMQ消息队列解耦高并发语音合成任务
Qwen3-TTS开源镜像部署:RabbitMQ消息队列解耦高并发语音合成任务 1. 项目概述与核心价值 Qwen3-TTS-12Hz-1.7B-VoiceDesign是一个功能强大的语音合成模型,支持10种主要语言(中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文和…...

STC8H8K32U按键控制OLED显示
手动按键按下,OLED显示对应键值 气缸前进后退电机正反转本文实现了一个基于STC8H单片机的按键检测与OLED显示系统。系统通过8个独立按键输入信号,采用消抖算法检测有效按键,并在OLED屏幕上实时显示对应按键编号。程序包含OLED初始化、I2C通信协议实现、按…...

基于Qwen3.5-2B的数据库课程设计智能指导系统
基于Qwen3.5-2B的数据库课程设计智能指导系统 1. 课程设计的痛点与解决方案 每到学期末,计算机专业的学生们都会面临一个共同的挑战——数据库课程设计。从选题到ER图设计,再到SQL编写和报告撰写,整个过程往往让学生们感到无从下手。传统的…...
)
Cadence 617 + TSMC 18RF工艺库:手把手教你从仿真曲线中提取MOSFET核心参数(附Python脚本)
Cadence 617 TSMC 18RF工艺库:从仿真曲线自动化提取MOSFET参数的Python实践 在模拟IC设计领域,工艺参数的准确提取直接影响电路性能预测的可靠性。传统手动选点计算Vth、μCox等参数的方法不仅效率低下,还容易引入人为误差。本文将演示如何通…...