7-爬虫-中间件和下载中间件(加代理,加请求头,加cookie)、scrapy集成selenium、源码去重规则(布隆过滤器)、分布式爬虫
0 持久化(pipelines.py)使用步骤
1 爬虫中间件和下载中间件
1.1 爬虫中间件(一般不用)
1.2 下载中间件(代理,加请求头,加cookie)
1.2.1 加请求头(加到请求对象中)
1.2.2 加cookie
1.2.3 加代理
2 scrapy集成selenium
3 源码去重规则(布隆过滤器)
3.1 布隆过滤器
4 分布式爬虫
持久化(pipelines.py)使用步骤
# 1 scrapy 框架,安装,创建项目,创建爬虫,运行爬虫
# 2 scrapy架构
# 3 解析数据1 response对象有css方法和xpath方法-css中写css选择器 response.css('')-xpath中写xpath选择 response.xpath('')2 重点1:-xpath取文本内容'.//a[contains(@class,"link-title")]/text()'-xpath取属性'.//a[contains(@class,"link-title")]/@href'-css取文本'a.link-title::text'-css取属性'img.image-scale::attr(src)'3 重点2:.extract_first() 取一个.extract() 取所有
# 4 继续爬取- 下一页的地址:Request(url=next, callback=self.parse)- 详情地址:Request(url=url, callback=self.detail_parser)-额外去写detail_parser内的解析# 5 数据传递-解析中有数据---》下个解析中还能拿到Request(url=url, callback=self.detail_parser,meta={'item':item})----》给了Response对象的meta属性# 6 配置文件-基础配置-高级配置--》提高爬虫效率# 7 持久化---》把数据保存到磁盘上:文件,mysql-管道-使用步骤-1 写个类:items.py,里面写字段class CnblogItem(scrapy.Item):name = scrapy.Field()author = scrapy.Field()url = scrapy.Field()img = scrapy.Field()desc_content = scrapy.Field()# 文本详情text = scrapy.Field()-2 配置文件配置(管道,配置多个,存在多个位置)ITEM_PIPELINES = {"scrapy_demo.pipelines.CnblogPipeline": 300,"scrapy_demo.pipelines.CnblogMysqlPipeline": 200,}-3 爬虫解析中:yield item-3 pipelines.py中写类:open_spider,close_spider,process_item

1 爬虫中间件和下载中间件
1.1 爬虫中间件(一般不用)
# 第一步:写个爬虫中间件类class ScrapyDemoSpiderMiddleware:@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return s# 走架构图第1步,会触发这里def process_spider_input(self, response, spider):# Called for each response that goes through the spider# middleware and into the spider.# Should return None or raise an exception.return None# 架构图,第1,7步走这里def process_spider_output(self, response, result, spider):# Called with the results returned from the Spider, after# it has processed the response.# Must return an iterable of Request, or item objects.for i in result:yield idef process_spider_exception(self, response, exception, spider):# Called when a spider or process_spider_input() method# (from other spider middleware) raises an exception.# Should return either None or an iterable of Request or item objects.pass# 架构图第一步def process_start_requests(self, start_requests, spider):# Called with the start requests of the spider, and works# similarly to the process_spider_output() method, except# that it doesn’t have a response associated.# Must return only requests (not items).for r in start_requests:yield rdef spider_opened(self, spider):spider.logger.info("Spider opened: %s" % spider.name)# 2 配置文件配置SPIDER_MIDDLEWARES = {"scrapy_demo.middlewares.ScrapyDemoSpiderMiddleware": 543,
}
1.2 下载中间件(代理,加请求头,加cookie)
class ScrapyDemoDownloaderMiddleware:@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):# - return None: 继续执行当次请求,继续走下一个中间件---》如果中间件没了---》执行下载# - return Response :直接把Response返回给引擎,引擎交给爬虫去解析# - return Request :把request返回给引擎,引擎给调度器,等待下一次被爬取# - 直接抛异常: 触发process_exception执行return Nonedef process_response(self, request, response, spider):# Must either;# - return Response:正常爬取完---》给引擎---》引擎给爬虫去解析# - return Request: 爬取失败--》给引擎--》引擎给调度器--》等待下次爬取# - 抛异常 :走到process_exceptionreturn responsedef process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpassdef spider_opened(self, spider):spider.logger.info("Spider opened: %s" % spider.name)
1.2.1 加请求头(加到请求对象中)
# faker 模块 :随机生成假数据
# pip install fake_useragent:随机生成请求头### 加referer,加token 加 user-agent
def process_request(self, request, spider):#### 加请求头print(request.headers)request.headers['referer'] = 'http://www.lagou.com'request.headers['token'] = 'asdfasdf.asdfads.asfdasfd'# user-agent--->写死了---》想随机请求头from fake_useragent import UserAgentua = UserAgent()request.headers['User-Agent'] = str(ua.random)print(request.headers)return None1.2.2 加cookie
def process_request(self, request, spider):print(request.cookies)request.cookies['name']='lqz'return None
1.2.3 加代理
# 在下载中间件的def process_request(self, request, spider):写代码# 第一步:-在下载中间件写process_request方法def get_proxy(self):import requestsres = requests.get('http://127.0.0.1:5010/get/').json()if res.get('https'):return 'https://' + res.get('proxy')else:return 'http://' + res.get('proxy')def process_request(self, request, spider):#request.meta['proxy'] = self.get_proxy()request.meta['proxy'] = 'http://192.168.11.11:8888'return None# 第二步:代理可能不能用,会触发process_exception,在里面写def process_exception(self, request, exception, spider):print('-----',request.url) # 这个地址没有爬return request
2 scrapy集成selenium
# 使用scrapy默认下载器---》类似于requests模块发送请求,不能执行js,有的页面拿回来数据不完整# 想在scrapy中集成selenium,获取数据更完整,获取完后,自己组装成 Response对象,就会进爬虫解析,现在解析的是使用selenium拿回来的页面,数据更完整# 集成selenium 因为有的页面,是执行完js后才渲染完,必须使用selenium去爬取数据才完整# 保证整个爬虫中,只有一个浏览器器
# 只要爬取 下一页这种地址,使用selenium,爬取详情,继续使用原来的# 第一步:在爬虫类中写
from selenium import webdriver
class CnblogsSpider(scrapy.Spider):bro = webdriver.Chrome() # 使用无头bro.implicitly_wait(10)def close(spider, reason):spider.bro.close() #浏览器关掉# 第二步:在中间件中def process_request(self, request, spider):# 爬取下一页这种地址---》用selenium,但是文章详情,就用原来的if 'sitehome/p' in request.url:spider.bro.get(request.url)from scrapy.http.response.html import HtmlResponseresponse = HtmlResponse(url=request.url, body=bytes(spider.bro.page_source, encoding='utf-8'))return responseelse:return None
3 源码去重规则(布隆过滤器)
# 如果爬取过的地址,就不会再爬了,scrapy 自带去重# 调度器可以去重,研究一下,如何去重的---》使用了集合# 要爬取的Request对象,在进入到scheduler调度器排队之前,先执行enqueue_request,它如果return False,这个Request就丢弃掉,不爬了----》如何判断这个Request要不要丢弃掉,执行了self.df.request_seen(request),它来决定的-----》RFPDupeFilter类中的方法----》request_seen---》会返回True或False----》如果这个request在集合中,说明爬过了,就return True,如果不在集合中,就加入到集合中,然后返回False# 调度器源码
from scrapy.core.scheduler import Scheduler# 这个方法如果return True表示这个request要爬取,如果return False表示这个网址就不爬了(已经爬过了)def enqueue_request(self, request: Request) -> bool:# request当次要爬取的地址对象if self.df.request_seen(request):# 有的请情况,在爬虫中解析出来的网址,不想爬了,就就可以指定# yield Request(url=url, callback=self.detail_parse, meta={'item': item},dont_filter=True)# 如果符合这个条件,表示这个网址已经爬过了 return Falsereturn True# self.df 去重类 是去重类的对象 RFPDupeFilter--》配置文件配置的-在配置文件中如果配置了:DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'表示,使用它作为去重类,按照它的规则做去重-RFPDupeFilter的request_seendef request_seen(self, request: Request) -> bool:# request_fingerprint 生成指纹fp = self.request_fingerprint(request) #request当次要爬取的地址对象#判断 fp 在不在集合中,如果在,return Trueif fp in self.fingerprints:return True#如果不在,加入到集合,return Falseself.fingerprints.add(fp)return False# 传进来是个request对象,生成的是指纹-爬取的网址:https://www.cnblogs.com/teach/p/17238610.html?name=lqz&age=19-和 https://www.cnblogs.com/teach/p/17238610.html?age=19&name=lqz-它俩是一样的,返回的数据都是一样的,就应该是一条url,就只会爬取一次-所以 request_fingerprint 就是来把它们做成一样的(核心原理是把查询条件排序,再拼接到后面)-生成指纹,指纹是什么? 生成的指纹放到集合中去重-www.cnblogs.com?name=lqz&age=19-www.cnblogs.com?age=19&name=lqz-上面的两种地址生成的指纹是一样的# 测试指纹from scrapy.utils.request import RequestFingerprinterfrom scrapy import Requestfingerprinter = RequestFingerprinter()request1 = Request(url='http://www.cnblogs.com?name=lqz&age=20')request2 = Request(url='http://www.cnblogs.com?age=20&name=lqz')res1 = fingerprinter.fingerprint(request1).hex()res2 = fingerprinter.fingerprint(request2).hex()print(res1)print(res2)# 集合去重,集合中放
# a一个bytes
# 假设爬了1亿条url,放在内存中,占空间非常大
a6af0a0ffa18a9b2432550e1914361b6bffcff1a
a6af0a0ffa18a9b2432550e191361b6bffc34f1a# 想一种方式,极小内存实现去重---》布隆过滤器
https://zhuanlan.zhihu.com/p/94668361
3.1 布隆过滤器
# 极小内存实现去重:
# 应用场景:爬虫去重,避免缓存穿透,垃圾邮件过滤# bloomfilter:是一个通过多哈希函数映射到一张表的数据结构,能够快速的判断一个元素在一个集合内是否存在,具有很好的空间和时间效率。(典型例子,爬虫url去重)
#布隆案例# from pybloom_live import ScalableBloomFilter
# bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
# url = "www.cnblogs.com"
# url2 = "www.liuqingzheng.top"
# bloom.add(url)
# print(url in bloom)
# print(url2 in bloom)from pybloom_live import BloomFilter
bf = BloomFilter(capacity=1000)
url='www.baidu.com'
bf.add(url)
print(url in bf)
print("www.liuqingzheng.top" in bf)
from scrapy.dupefilters import BaseDupeFilter
from scrapy.utils.request import RequestFingerprinter
from pybloom_live import ScalableBloomFilterclass MyPDupeFilter(BaseDupeFilter):fingerprints = ScalableBloomFilter(initial_capacity=100, error_rate=0.001,mode=ScalableBloomFilter.LARGE_SET_GROWTH)fingerprinter = RequestFingerprinter()def request_seen(self, request):print('zoule')fp = self.request_fingerprint(request)if fp in self.fingerprints:return Trueself.fingerprints.add(fp)return Falsedef request_fingerprint(self, request) -> str:return self.fingerprinter.fingerprint(request).hex()
4 分布式爬虫
# 原来scrapy的Scheduler维护的是本机的任务队列(待爬取的地址)+本机的去重队列(放在集合中)---》在本机内存中
# 如果把scrapy项目,部署到多台机器上,多台机器爬取的内容是重复的# 所以实现分布式爬取的关键就是,找一台专门的主机上运行一个共享的队列比如Redis,
然后重写Scrapy的Scheduler,让新的Scheduler到共享队列存取Request,并且去除重复的Request请求,所以总结下来,实现分布式的关键就是三点:#1、多台机器共享队列#2、重写Scheduler,让其无论是去重还是任务都去访问共享队列#3、为Scheduler定制去重规则(利用redis的集合类型)# scrapy-redis实现分布式爬虫-公共的去重-公共的待爬取地址队列# 使用步骤0 下载:pip2 install scrapy-redis1 把之前爬虫类,继承class CnblogsSpider(RedisSpider):2 去掉起始爬取的地址,加入一个类属性redis_key = 'myspider:start_urls' # redis列表的key,后期我们需要手动插入起始地址3 配置文件中配置DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # scrapy redis去重类,使用redis的集合去重# 不使用原生的调度器了,使用scrapy_redis提供的调度器,它就是使用了redis的列表SCHEDULER = "scrapy_redis.scheduler.Scheduler"REDIS_HOST = 'localhost' # 主机名REDIS_PORT = 6379 # 端口ITEM_PIPELINES = {# 'mysfirstscrapy.pipelines.MyCnblogsPipeline': 300,'mysfirstscrapy.pipelines.MyCnblogsMySqlPipeline': 301,'scrapy_redis.pipelines.RedisPipeline': 400,}4 再不同多台机器上运行scrapy的爬虫,就实现了分布式爬虫5 写入到redis的列表中起始爬取的地址:列表key:myspider:start_urlsrpush myspider:start_urls https://www.cnblogs.com相关文章:
7-爬虫-中间件和下载中间件(加代理,加请求头,加cookie)、scrapy集成selenium、源码去重规则(布隆过滤器)、分布式爬虫
0 持久化(pipelines.py)使用步骤 1 爬虫中间件和下载中间件 1.1 爬虫中间件(一般不用) 1.2 下载中间件(代理,加请求头,加cookie) 1.2.1 加请求头(加到请求对象中) 1.2.2 加cookie 1.2.3 加代理 2 scrapy集成selenium 3 源码去重…...

创建自己的nas服务,从远端拉取所需文件
一、前言 创建一个nas文件存储,然后需要的时候随时从远端或者其他终端拉取所需文件是不是一件很帅气的工作。 二、准备工作 一台服务器(云的更好),没了。 首先安装docker和docker-compose 此处省略docker的安装(改天更新)&…...

智慧化城市内涝的预警,万宾科技内涝积水监测仪
随着城市化进程的加速,伴随的是城市内涝问题日益凸显。频繁的暴雨和积水给市民的生活带来了诸多不便,也给城市的基础设施带来了巨大压力。如何解决这一问题,成为智慧城市建设的重要课题和政府管理的工作主题,只要内涝问题得到缓解…...

7-18 调用一个函数
分数 2 作者 Yiping 单位 广东东软学院 现有如下程序,请将注释后带??的代码补充完整: import mathdef normalize(normal):x normal[0]y normal[1]z normal[2]s math.sqrt(x**2 y**2 z**2)x / sy / sz / sreturn (x, y, z)if __name__ __mai…...
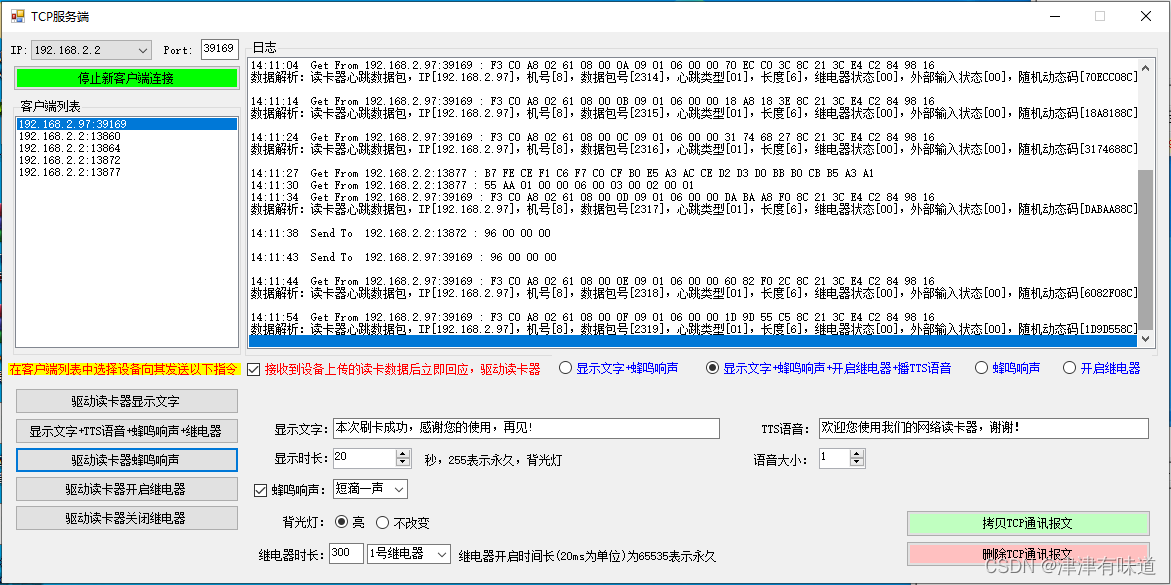
VB.net TCP服务端监听端口接收客户端RFID网络读卡器上传的读卡数据
本 示例使用设备介绍:WIFI/TCP/UDP/HTTP协议RFID液显网络读卡器可二次开发语音播报POE-淘宝网 (taobao.com) Imports System.Threading Imports System.Net Imports System.Net.Sockets Public Class Form1Dim ListenSocket As SocketDim Dict As New Dictionary(Of…...

Springboot 集成 MongoDB
在SpringBoot项目中集成MongoDB后的一些基本操作。 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 前言 本文介绍的内容是Springboot如何集成MongoDB,以及对MongoDB进行基本的增加、查询数据的操作。 提示:以下是本篇…...

AM@定积分的定义求某些类型的极限
文章目录 定积分定义求极限步骤例 定积分表示为极限 定积分定义求极限 容易从定积分的定义: ∫ a b f ( x ) d x \int_{a}^{b}f(x)\mathrm{d}x ∫abf(x)dx lim λ → 0 ∑ i 1 n f ( ξ i ) Δ x i \lim\limits_{\lambda\to{0}}\sum_{i1}^{n}f{(\xi_{i})}\Delta{x_i} λ→…...

Perl爬虫程序的框架
Perl爬虫程序的框架,这个框架可以用来爬取任何网页的内容。 perl #!/usr/bin/perl use strict; use warnings; use LWP::UserAgent; use HTML::TreeBuilder; # 创建LWP::UserAgent对象 my $ua LWP::UserAgent->new; # 设置代理信息 $ua->proxy(http, ); …...

15. 机器学习——聚类
机器学习面试题汇总与解析——聚类 本章讲解知识点 什么是聚类K-means 聚类算法均值偏移聚类算法DBSCAN 聚类算法高斯混合模型(GMM)的期望最大化(EM)聚类层次聚类算法本专栏适合于Python已经入门的学生或人士,有一定的编程基础。 本专栏适合于算法工程师、机器学习、图像…...
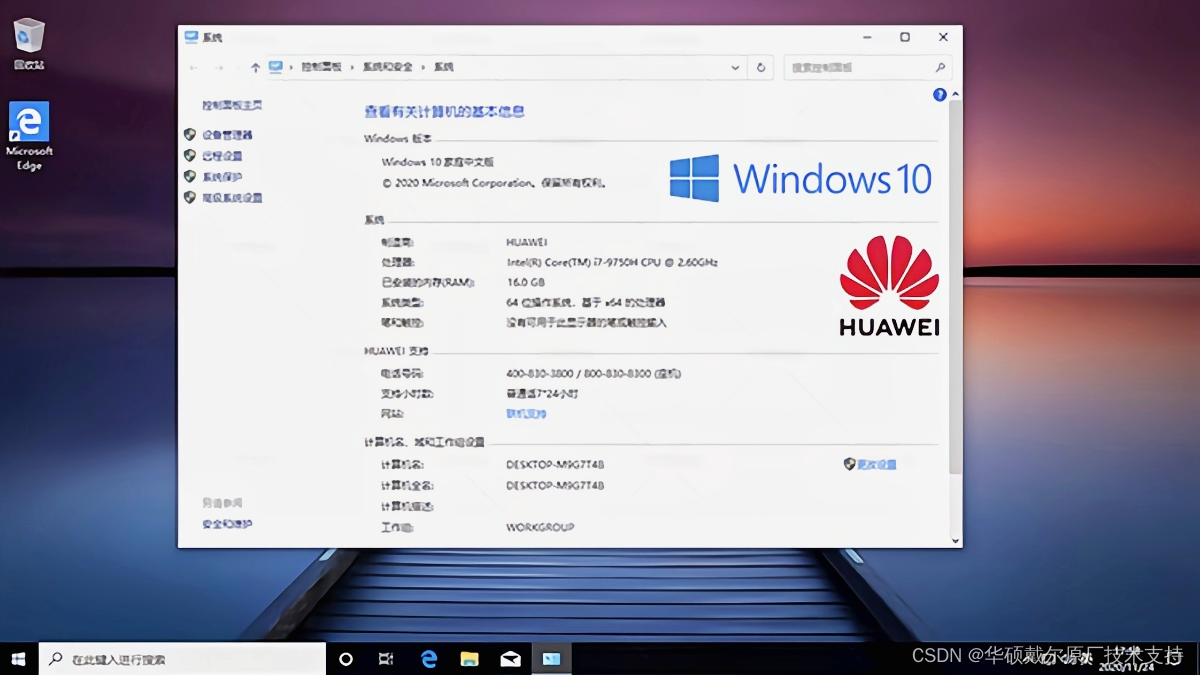
华为笔记本电脑原装win10/win11系统恢复安装教程方法
华为电脑matebook 14原装Win11系统带F10智能还原 安装恢复教程: 1.安装方法有两种,一种是用PE安装,一种是华为工厂包安装(安装完成自带F10智能还原) 若没有原装系统文件,请在这里获取:https:…...

计算机毕业设计 基于SpringBoot的养老院管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

Python数据容器(序列操作)
序列 1.什么是序列 序列是指:内容连续、有序。可以使用下标索引的一类数据容器 列表、元组、字符串。均可以视为序列 2.序列的常用操作 - 切片 语法:序列[起始下标:结束下标:步长]起始下标表示从何处开始,可以留空,留空视作从…...
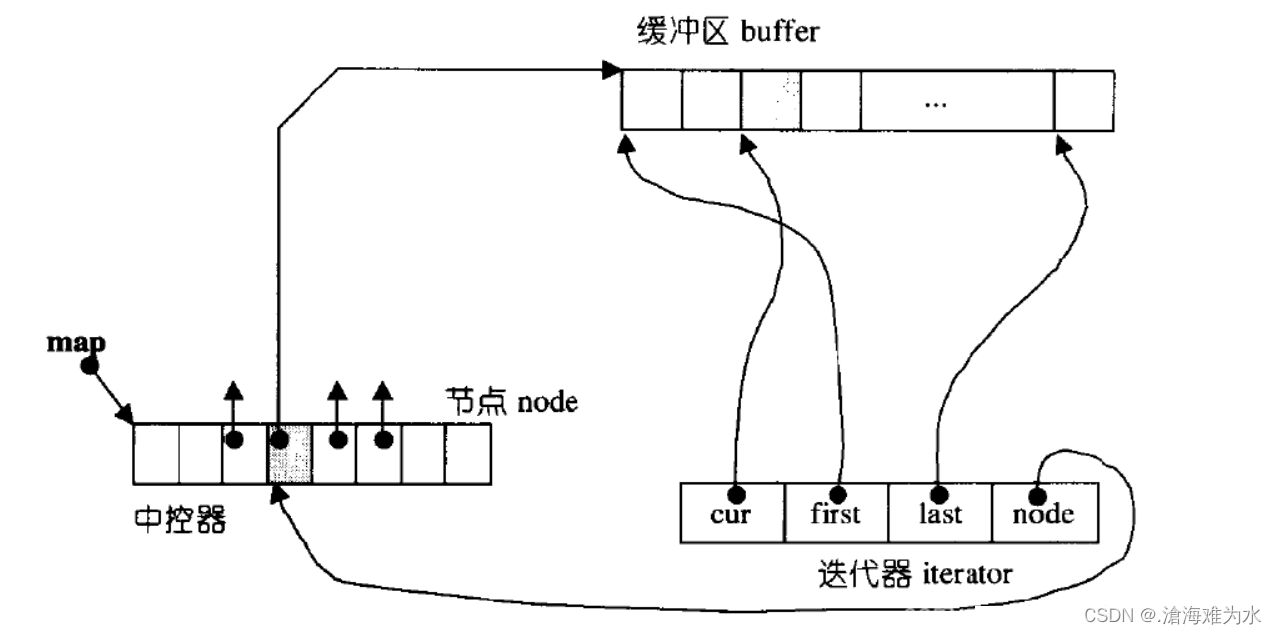
【C++】stack,queue和deque
stack的介绍 stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定 的成…...
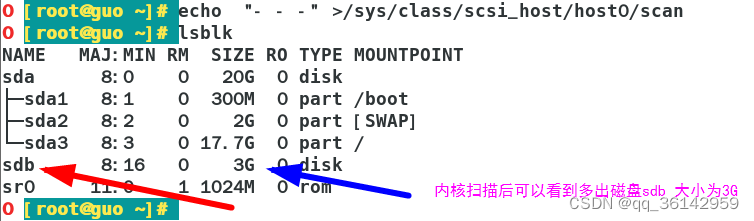
Linux centos系统中添加磁盘
为了学习与训练文件系统或磁盘的分区、格式化和挂载/卸载,我们需要为虚拟机添加磁盘。根据需要,可以添加多块不同大小的磁盘。具体操作讨论如下,供参考。 一、添加 1.开机前 有两个地方,可选择打开添加硬盘对话框 (1)双击左侧…...
java网络编程之UDP协议
文章目录 UDP简介一发一收客户端:服务端: 多发多收实现多开客户端:服务端 UDP简介 UDP(User Datagram Protocol) DatagramSocket 用于创建客户端、服务端DatagramSocket() :创建客户端的Socket对象,系统随…...

几百封钓鱼邮件如何分析?一个简单的方法告诉你!
前几天的时候收到一批钓鱼邮件需要分析,打开一看就傻了眼,大概有几百封,而且基本上每一封都是钓鱼邮件,第一反应是很崩溃,这么多如何分析?但是客户那边又着急要,那只能先上了: 一、…...

【设计原则篇】聊聊开闭原则
开闭原则 其实就是对修改关闭,对拓展开放。 是什么 OCP(Open/Closed Principle)- 开闭原则。关于开发封闭原则,其核心的思想是:模块是可扩展的,而不可修改的。也就是说,对扩展是开放的…...

LVS面试题
LVS 原理 LVS通过工作于内核的ipvs模块来实现功能,其主要工作于netfilter 的INPUT链上。 而用户需要对ipvs进行操作配置则需要使用ipvsadm这个工具。 ipvsadm主要用于设置lvs模型、调度方式以及指定后端主机。 简述 LVS 三种工作模式,他们的区别 基于 NAT 的 LVS…...
uniapp发行web页面在老版本浏览器打开一片空白
uniapp发行的web页面(菜单->发行->网站-PC Web或手机H5),对于一些老的浏览器(或内核),打开一片空白; 而在新版本的浏览器中打开却正常。这是因为那些版本较低的浏览器不支持ES6的语法和新…...
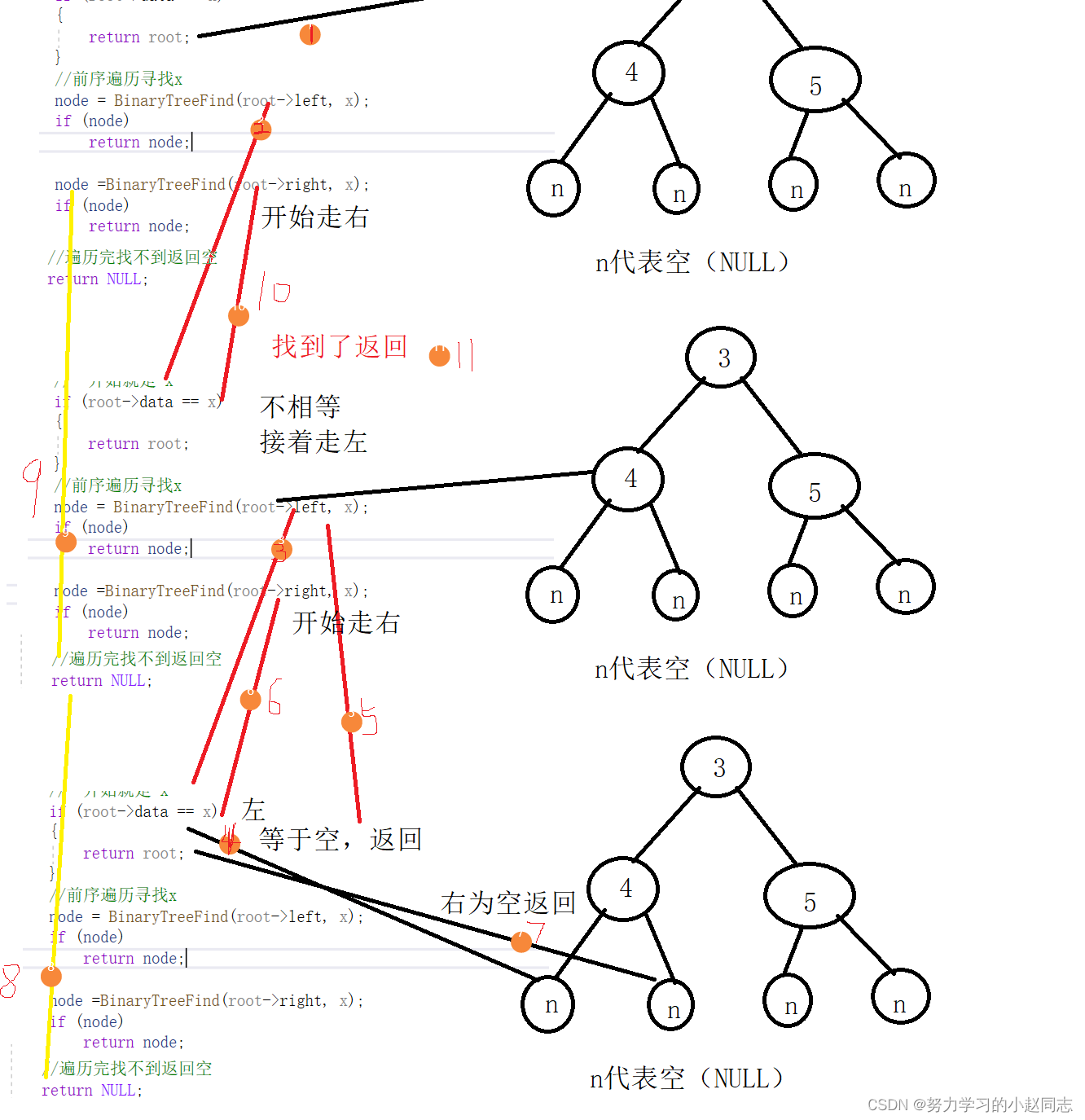
数据结构—二叉树的模拟实现(c语言)
目录 一.前言 二.模拟实现链式结构的二叉树 2.1二叉树的底层结构 2.2通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树 2.3二叉树的销毁 2.4二叉树查找值为x的节点 2.5二叉树节点个数 2.6二叉树叶子节点个数 2.7二叉树第k层节点个数 三.二叉树的遍历 3.1…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...

免费抓包工具选型指南:Wireshark、Fiddler、mitmproxy、Charles实战对比
1. 抓包工具不是“黑科技”,而是网络世界的显微镜很多人第一次听说“抓包”,脑子里立刻浮现出黑客电影里满屏滚动的绿色代码、键盘敲得噼啪作响、三秒破解银行防火墙的画面。其实完全不是这样——抓包(Packet Capture)本质上就是把…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...