[sd_scripts]之train
https://github.com/kohya-ss/sd-scripts/blob/main/docs/train_README-zh.md![]() https://github.com/kohya-ss/sd-scripts/blob/main/docs/train_README-zh.md
https://github.com/kohya-ss/sd-scripts/blob/main/docs/train_README-zh.md
支持模型fine-tune,dreambooth,lora,textual inversion。
1.数据准备
在任意多个文件夹中准备好训练的图像文件,不需要预处理,勿使用极小的图像,不要使用过大的图像如3000x3000以上的。正则化图像:"正则项图像"对应Dreambooth论文中的prior-preservation图像,用来防止模型过拟合。通过自己先生成一些图像,依赖论文中loss的prior-preservation term对训练过程正则化,来解决过拟合与语言漂移问题。
1.1 dreambooth、class+identifier(可使用正则化图像)
将训练目标与特定单词(identifier)相关联进行训练,无需准备caption,要学习特定的角色,但由于训练数据的所有元素斗鱼identifier相关联,因此在生成时可能出现无法更换特定服饰的情况。
1.2 dreambooth、caption(可使用正则化图像)
给每张图片写caption,存放到文本文件中,进行训练,例如,通过将图像详细信息(如穿着白色衣服的角色A、穿着红色衣服的角色B)记录在caption中,可以将角色和其他元素分离,并期望模型更准确的学习角色。
1.3 finetune(不可使用正则化)
将caption收集到元数据中。

如果要想训练lora、textual inversion而不准备caption,则建议使用dreambooth class+identifier,如果能够准备caption,则dreambooth caption更好,如果有大量训练并不使用正则化的话,则考虑fine-tuning。这里就是fine-tune/train_network/train_textual_inversion用fine-tuning,train_db主要用前两类。
2.每种方法的指定方式
2.1 dreambooth,class+identifier方法(可使用正则化图像)
在该方法中,每个图像都被视为与class identifier相同的标题进行训练(shs dog),相当于每张图片都使用shs dog进行训练。
2.1.1 确定identifier和class
class是训练目标的一般类别,例如,要学习特定品种的狗,则class是dog,对于动漫角色,根据模型不同,可能是boy或girl。identifier是用于识别训练目标并进行学习的单词。可以使用任何单词,但根据dreambooth论文,tokenizer生成的3个或更少字符的罕见单词最好。
使用identifier和class,例如 shs dog可以将模型训练为从class中识别学习所需的目标。在图像生成时,使用shs dog将生成所学习的狗的图像,
作为identifier,一些参考是“shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny”等。
2.1.2 决定是否使用正则化图像,并在使用时生成正则化图像
正则化图像是为防止语言漂移,即整个类别被拉扯成为训练目标而生成的图像。如果不使用正则化图像,例如在 shs 1girl 中学习特定角色时,即使在简单的 1girl 提示下生成,也会越来越像该角色。这是因为 1girl 在训练时的标题中包含了该角色的信息。通过同时学习目标图像和正则化图像,类别仍然保持不变,仅在将标识符附加到提示中时才生成目标图像。
如果只想在LoRA或DreamBooth中使用特定的角色,则可以不使用正则化图像。在Textual Inversion中也不需要使用(如果要学习的token string不包含在标题中,则不会学习任何内容)。
一般情况下,使用在训练目标模型时只使用类别名称生成的图像作为正则化图像是常见的做法(例如 1girl)。但是,如果生成的图像质量不佳,可以尝试修改提示或使用从网络上另外下载的图像。由于正则化图像也被训练,因此其质量会影响模型。
通常,准备数百张图像是理想的(图像数量太少会导致类别图像无法被归纳,特征也不会被学习)。如果要使用生成的图像,生成图像的大小通常应与训练分辨率(更准确地说,是bucket的分辨率)相匹配。
2.1.3 设置文件的描述
[general]
enable_bucket = true # 是否使用Aspect Ratio Bucketing[[datasets]]
resolution = 512 # 训练分辨率
batch_size = 4 # 批次大小[[datasets.subsets]]image_dir = 'C:\hoge' # 指定包含训练图像的文件夹class_tokens = 'hoge girl' # 指定标识符类num_repeats = 10 # 训练图像的重复次数# 以下仅在使用正则化图像时进行描述。不使用则删除[[datasets.subsets]]is_reg = trueimage_dir = 'C:\reg' # 指定包含正则化图像的文件夹class_tokens = 'girl' # 指定classnum_repeats = 1 # 正则化图像的重复次数,基本上1就可以了1.训练分辨率,指定一个数字表示正方形,如果是512,则为512x512,如果使用方括号和逗号分隔的两个数字,则表示横向x纵向([512,768],则为512x768),在sd1.x中,原始训练分辨率为512,在sd2.x 768中,分辨率为768.
2.批量大小。同时训练多少个数据。
3.文件夹,训练和正则化图像的文件夹。
4.num_repeats。重复次数用于调整正则化图像和训练用图像的数量。由于正则化图像的数量多于训练用图像,因此需要重复使用训练用图像来达到一对一的比例,从而实现训练,重复次数指定为训练用图像的重复次数x训练用图像的数量>=正则化图像的重复次数x正则化图像的数量,一般10就可以了。1个epoch,训练数据过一遍,如果正则化数据比训练数据多,则多余的正则化数据不使用。
2.1.4 训练
#!/bin/bash
# Dreambooth train script
script_name="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/tools/sd_lora/sd-scripts/train_db.py"# 设置训练用模型、数据
is_v2_model=0 # SD2.0 model | SD2.0模型 2.0模型下 clip_skip 默认无效
parameterization=0 # parameterization | 参数化 本参数需要和 V2 参数同步使用 实验性功能
dataset_config="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/tools/sd_lora/config/dreambooth.toml"
pretrained_model_name_or_path="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/stable-diffusion-webui/models/Stable-diffusion/DreamShaper_8_pruned.safetensors"# 输出设置
output_name="sn_logo" # output model name | 模型保存名称
output_dir="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/outputs/"
save_model_as="safetensors" # model save ext | 模型保存格式 ckpt, pt, safetensors
logging_dir="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/outputs/"# 网络设置# 训练相关参数
resolution="512,512" # image resolution w,h. 图片分辨率,宽,高。支持非正方形,但必须是 64 倍数。
batch_size=1 # batch size
max_train_epochs=10 # max train epoches | 最大训练 epoch
save_every_n_epochs=2 # save every n epochs | 每 N 个 epoch 保存一次
stop_text_encoder_training=0 # stop text encoder training | 在第N步时停止训练文本编码器
noise_offset="0" # noise offset | 在训练中添加噪声偏移来改良生成非常暗或者非常亮的图像,如果启用,推荐参数为0.1
keep_tokens=0 # keep heading N tokens when shuffling caption tokens | 在随机打乱 tokens 时,保留前 N 个不变。
min_snr_gamma=0 # minimum signal-to-noise ratio (SNR) value for gamma-ray | 伽马射线事件的最小信噪比(SNR)值 默认为 0# 学习率
lr="1e-4" # learning rate | 学习率,在分别设置下方 U-Net 和 文本编码器 的学习率时,该参数失效
lr_scheduler="cosine_with_restarts" # "linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup", "adafactor"
lr_warmup_steps=0 # warmup steps | 学习率预热步数,lr_scheduler 为 constant 或 adafactor 时该值需要设为0。
lr_restart_cycles=1 # cosine_with_restarts restart cycles | 余弦退火重启次数,仅在 lr_scheduler 为 cosine_with_restarts 时起效。# 优化器
optimizer_type="AdamW" # Optimizer type | 优化器类型 默认为 AdamW8bit,可选:AdamW AdamW8bit Lion Lion8bit SGDNesterov SGDNesterov8bit DAdaptation AdaFactor prodigy# 恢复训练设置
save_state=0 # save state | 保存训练状态 名称类似于 <output_name>-??????-state ?????? 表示 epoch 数
resume="" # resume from state | 从某个状态文件夹中恢复训练 需配合上方参数同时使用 由于规范文件限制 epoch 数和全局步数不会保存 即使恢复时它们也从 1 开始 与 network_weights 的具体实现操作并不一致L# 其他设置
min_bucket_reso=256 # arb min resolution | arb 最小分辨率
max_bucket_reso=1024 # arb max resolution | arb 最大分辨率
persistent_data_loader_workers=1 # persistent dataloader workers | 保留加载训练集的worker,减少每个 epoch 之间的停顿
clip_skip=2 # clip skip | 玄学 一般用 2
multi_gpu=2 # multi gpu | 多显卡训练 该参数仅限在显卡数 >= 2 使用
lowram=0 # lowram mode | 低内存模式 该模式下会将 U-net 文本编码器 VAE 转移到 GPU 显存中 启用该模式可能会对显存有一定影响# 远程记录设置
use_wandb=0 # use_wandb | 启用wandb远程记录功能
wandb_api_key="" # wandb_api_key | API,通过 https://wandb.ai/authorize 获取
log_tracker_name="" # log_tracker_name | wandb项目名称,留空则为"network_train"# =======================================================================================================================
extArgs=()
launchArgs=()
if [[ $multi_gpu == 1 ]]; then launchArgs+=("--multi_gpu"); fiif [[ $is_v2_model == 1 ]]; thenextArgs+=("--v2")
fi
if [[ $parameterization == 1 ]]; then extArgs+=("--v_parameterization"); fiif [[ $stop_text_encoder_training -ne 0 ]]; then extArgs+=("--stop_text_encoder_training $stop_text_encoder_training"); fi
if [[ $noise_offset != "0" ]]; then extArgs+=("--noise_offset $noise_offset"); fi
if [[ $min_snr_gamma -ne 0 ]]; then extArgs+=("--min_snr_gamma $min_snr_gamma"); fi#if [[ $optimizer_type ]]; then extArgs+=("--optimizer_type $optimizer_type"); fi
#if [[ $optimizer_type == "DAdaptation" ]]; then extArgs+=("--optimizer_args decouple=True"); fiif [[ $save_state == 1 ]]; then extArgs+=("--save_state"); fi
if [[ $resume ]]; then extArgs+=("--resume $resume"); fiif [[ $persistent_data_loader_workers == 1 ]]; then extArgs+=("--persistent_data_loader_workers"); fi
if [[ $lowram ]]; then extArgs+=("--lowram"); fiif [[ $use_wandb == 1 ]]; thenextArgs+=("--log_with=all")
elseextArgs+=("--log_with=tensorboard")
fi
if [[ $wandb_api_key ]]; then extArgs+=("--wandb_api_key $wandb_api_key"); fi
if [[ $log_tracker_name ]]; then extArgs+=("--log_tracker_name $log_tracker_name"); fi# =====================================================================================================================
python -m accelerate.commands.launch "${launchArgs[@]}" --num_cpu_threads_per_process=4 "$script_name" \--pretrained_model_name_or_path="$pretrained_model_name_or_path" \--dataset_config="$dataset_config" \--output_dir="$output_dir" \--output_name="$output_name" \--save_model_as="$save_model_as" \--logging_dir="$logging_dir" \--log_prefix="$output_name" \--prior_loss_weight=1.0 \\--resolution "$resolution" \--max_train_epochs "$max_train_epochs" \--train_batch_size "$batch_size" \--save_every_n_epochs "$save_every_n_epochs" \--keep_tokens "$keep_tokens" \\--optimizer_type="$optimizer_type" \--clip_skip="$clip_skip" \\--learning_rate="$lr" \--lr_scheduler="$lr_scheduler" \--lr_warmup_steps="$lr_warmup_steps" \--lr_scheduler_num_cycles="$lr_restart_cycles" \\--min_bucket_reso="$min_bucket_reso" \--max_bucket_reso="$max_bucket_reso" \\--mixed_precision="fp16" \--cache_latents \--gradient_checkpointing \--huggingface_path_in_repo "/root/.cache" "${extArgs[@]}"
2.2 dreambooth、caption方式,可使用正则化
这个意义不大,使用dreambooth,其实就是想有具体的实体被描述。
2.3 fine-tune
fine-tune通常是指sd的全量微调,但它和lora的训练基本是一致的。
2.3.1 准备数据
将caption数据和标签整合到元数据中,.json
1.blip添加caption,也可以使用deepdanbooru、WD14Tagger
2.预处理caption和标签信息,将caption和标签作为元数据合并到一个文件中
3.清洗标签,标签中可能存在下划线等,
#!/bin/bash
# make caption script
script_caption_name="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/tools/sd_lora/sd-scripts/finetune/make_captions.py"
script_merge_name="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/tools/sd_lora/sd-scripts/finetune/merge_captions_to_metadata.py"
script_clean_name="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/tools/sd_lora/sd-scripts/finetune/clean_captions_and_tags.py"caption=0
train_data_dir="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/sn/banner/"
batch_size=8merge=1
merge_name="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/sn/banner/meta_cap.json"clean=1
clean_name="/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/sn/banner/meta_clean.json"if [[ $caption == 1 ]]; thenpython "$script_caption_name" \--batch_size "$batch_size" "$train_data_dir"
fiif [[ $merge == 1 ]]; thenpython "$script_merge_name" \--full_path "$train_data_dir" "$merge_name"
fiif [[ $clean == 1 ]]; thenpython "$script_clean_name" \"$merge_name" "$clean_name"
fi
[general]
enable_bucket = true # 是否使用Aspect Ratio Bucketing
shuffle_caption = true
keep_tokens = 1[[datasets]]
resolution = 512 # 训练分辨率
batch_size = 4 # 批次大小[[datasets.subsets]]image_dir = "/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/sn/banner/" # 指定包含训练图像的文件夹metadata_file = '/home/image_team/image_team_docker_home/lgd/e_commerce_sd/data/sn/banner/meta_clean.json'2.3.2 训练
这里的训练可以包括除dreambooth之外的所有的训练方式,主要就是因为数据格式只有两种,包括dreambooth和lora等这两种方式,fine-tune类的都是统一格式,直接调用py即可。
相关文章:
[sd_scripts]之train
https://github.com/kohya-ss/sd-scripts/blob/main/docs/train_README-zh.mdhttps://github.com/kohya-ss/sd-scripts/blob/main/docs/train_README-zh.md 支持模型fine-tune,dreambooth,lora,textual inversion。 1.数据准备 在任意多个…...

samba 共享目录write permission deny问题修复 可读取内容但不可修改 删除 新增文件
关于 update/delete/write permission deny问题修复 0.首先在服务器端执行testparm -s ,测试 Samba 配置并显示结果。需确保服务器端参数 read only No ,共享目录有写入权限 一、若配置了允许匿名访问,使用匿名访问来操作smb需要做如下处理…...

UDP主要丢包原因及具体问题分析
一、主要丢包原因 1、接收端处理时间过长导致丢包:调用recv方法接收端收到数据后,处理数据花了一些时间,处理完后再次调用recv方法,在这二次调用间隔里,发过来的包可能丢失。对于这种情况可以修改接收端,将包接收后存入…...
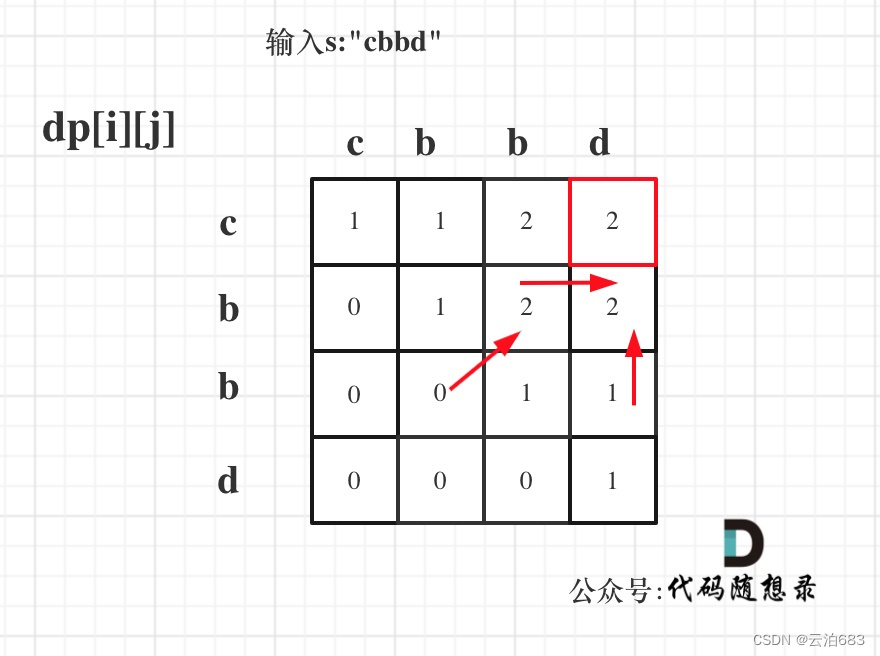
647. 回文子串 516.最长回文子序列
647. 回文子串 题目: 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 具有不同开始位置或结束位置的子串,即使是由相…...

点云从入门到精通技术详解100篇-双传感器模式的非结构化环境检测与识别
目录 前言 国内外研究现状 可通行区域检测的研究 障碍物检测的研究...

Nginx-反向代理
反向代理 1 语法 server {listen 82; server_name www.liyong.f.com;location ~* .*(css|js|html|images). {proxy_pass http://11.22.19.81:8088; } 上面的示例的意思是: 当访问:http://www.liyong.f.com:82/static/css/OneMap.b728e2e4.css 转发到 …...
Java封装一个根据指定的字段来获取子集的工具类
工具类 ZhLambdaUtils SuppressWarnings("all") public class ZhLambdaUtils {/*** METHOD_NAME*/private static final String METHOD_NAME "writeReplace";/*** 获取到lambda参数的方法名称** param <T> parameter* param function functi…...

【HUST】网安纳米|2023年研究生纳米技术考试参考
目录 1 纳米材料是什么 2 纳米材料的结构特性 3 纳米结构的其他特性 4 纳米结构的检测技术 5 纳米材料的应用 打印建议:PPT彩印(这样重点比较突出),每面12张PPT,简单做一下关键词目录,亲测可以看清。如…...

【移远QuecPython】EC800M物联网开发板的MQTT协议腾讯云数据上报
【移远QuecPython】EC800M物联网开发板的MQTT协议腾讯云数据上报 文章目录 导入库初始化设置MQTT注册回调订阅发布功能开启服务发送消息函数打包调用测试效果附录:列表的赋值类型和py打包列表赋值BUG复现代码改进优化总结 py打包 导入库 from TenCentYun import TX…...
关灯游戏及扩展
7.8 图形界面应用案例——关灯游戏 题目: [案例]游戏初步——关灯游戏。 关灯游戏是很有意思的益智游戏,玩家通过单击关掉(或打开)一盏灯。如果关(掉(或打开)一个电灯,其周围(上下左右)的电灯也会触及开关,成…...
)
深度解析:用Python爬虫逆向破解dappradar的URL加密参数(最详细逆向实战教程,小白进阶高手之路)
特别声明:本篇文章仅供学习与研究使用,不得用做任何非法用途,请大家遵守相关法律法规 目录 一、逆向目标二、准备工作三、逆向分析 - 太详细了!3.1 逆向前的一些想法3.1.1 加密字符串属性猜测3.1.2 是否可以手动复制加密API?3.2 XHR断点调试3.3 加密前各参数属性的变化情况…...
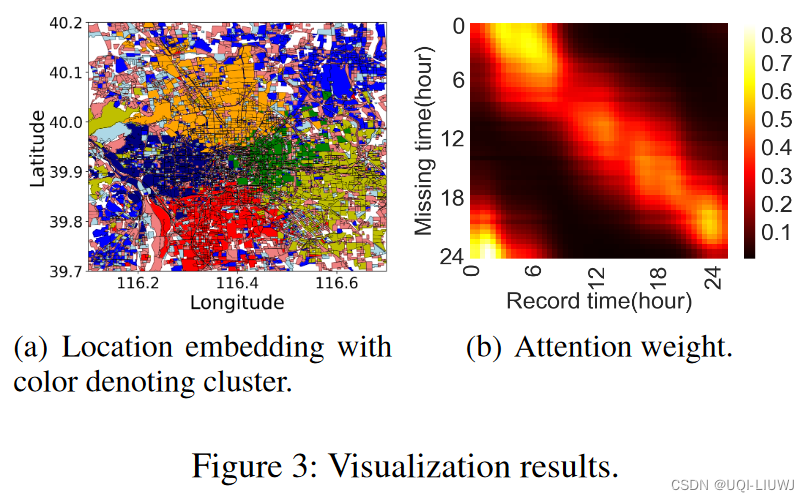
论文笔记:AttnMove: History Enhanced Trajectory Recovery via AttentionalNetwork
AAAI 2021 1 intro 1.1 背景 将用户稀疏的轨迹数据恢复至细粒度的轨迹数据是十分重要的恢复稀疏轨迹数据至细粒度轨迹数据是非常困难的 已观察到的用户位置数据十分稀疏,使得未观察到的用户位置存在较多的不确定性真实数据中存在大量噪声,如何有效的挖…...

Django之视图层
目录 一、三板斧的使用 二、JsonReponse序列化类的使用 三、 form表单上传文件 数据准备 数据处理 (1)post请求数据 (2)文件数据获取 四、 FBV与CBV 五、CBV的源码分析 as_view 方法 一、三板斧的使用 HttpResponse 返回字符串类型render 渲染html页面,并…...
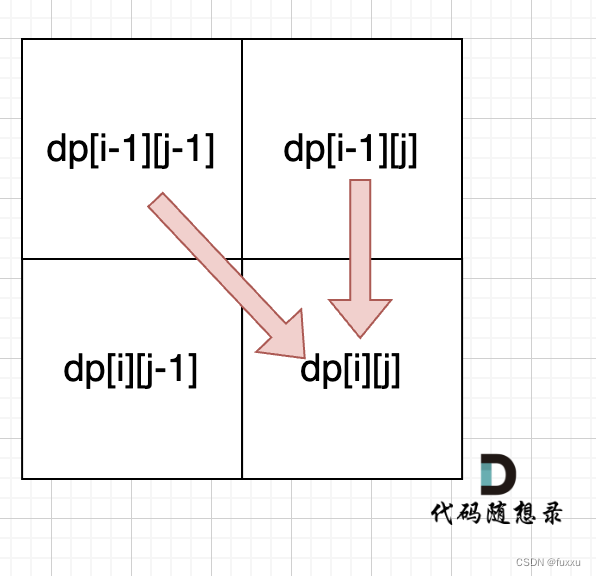
DAY54 392.判断子序列 + 115.不同的子序列
392.判断子序列 题目要求:给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是…...
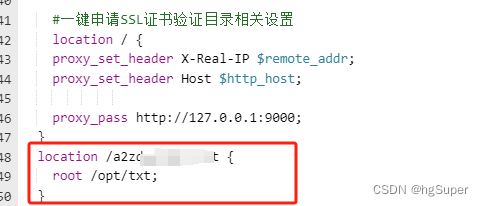
【Nginx】nginx | 微信小程序验证域名配置
【Nginx】nginx | 微信小程序验证域名配置 一、说明二、域名管理 一、说明 小程序需要添加头条的功能,内容涉及到富文本内容显示图片资源存储在minio中,域名访问。微信小程序需要验证才能显示。 二、域名管理 服务器是阿里云,用的宝塔管理…...

大数据Doris(二十二):数据查看导入
文章目录 数据查看导入 数据查看导入 Broker load 导入方式由于是异步的,所以用户必须将创建导入的 Label 记录,并且在查看导入命令中使用 Label 来查看导入结果。查看导入命令在所有导入方式中是通用的,具体语法可执行 HELP SHOW LOAD 查看。 show load order by create…...

STM32 I2C详解
STM32 I2C详解 I2C简介 I2C(Inter IC Bus)是由Philips公司开发的一种通用数据总线 两根通信线: SCL(Serial Clock)串行时钟线,使用同步的时序,降低对硬件的依赖,同时同步的时序稳定…...
)
软考 系统架构设计师系列知识点之云计算(1)
所属章节: 第11章. 未来信息综合技术 第6节. 云计算和大数据技术概述 大数据和云计算已成为IT领域的两种主流技术。“数据是重要资产”这一概念已成为大家的共识,众多公司争相分析、挖掘大数据背后的重要财富。同时学术界、产业界和政府都对云计算产生了…...
VS Code画流程图:draw.io插件
文章目录 简介快捷键 简介 Draw.io是著名的流程图绘制软件,开源免费,对标Visio,用过的都说好。而且除了提供常规的桌面软件之外,直接访问draw.io就可以在线使用,堪称百分之百跨平台,便捷性直接拉满。 那么…...
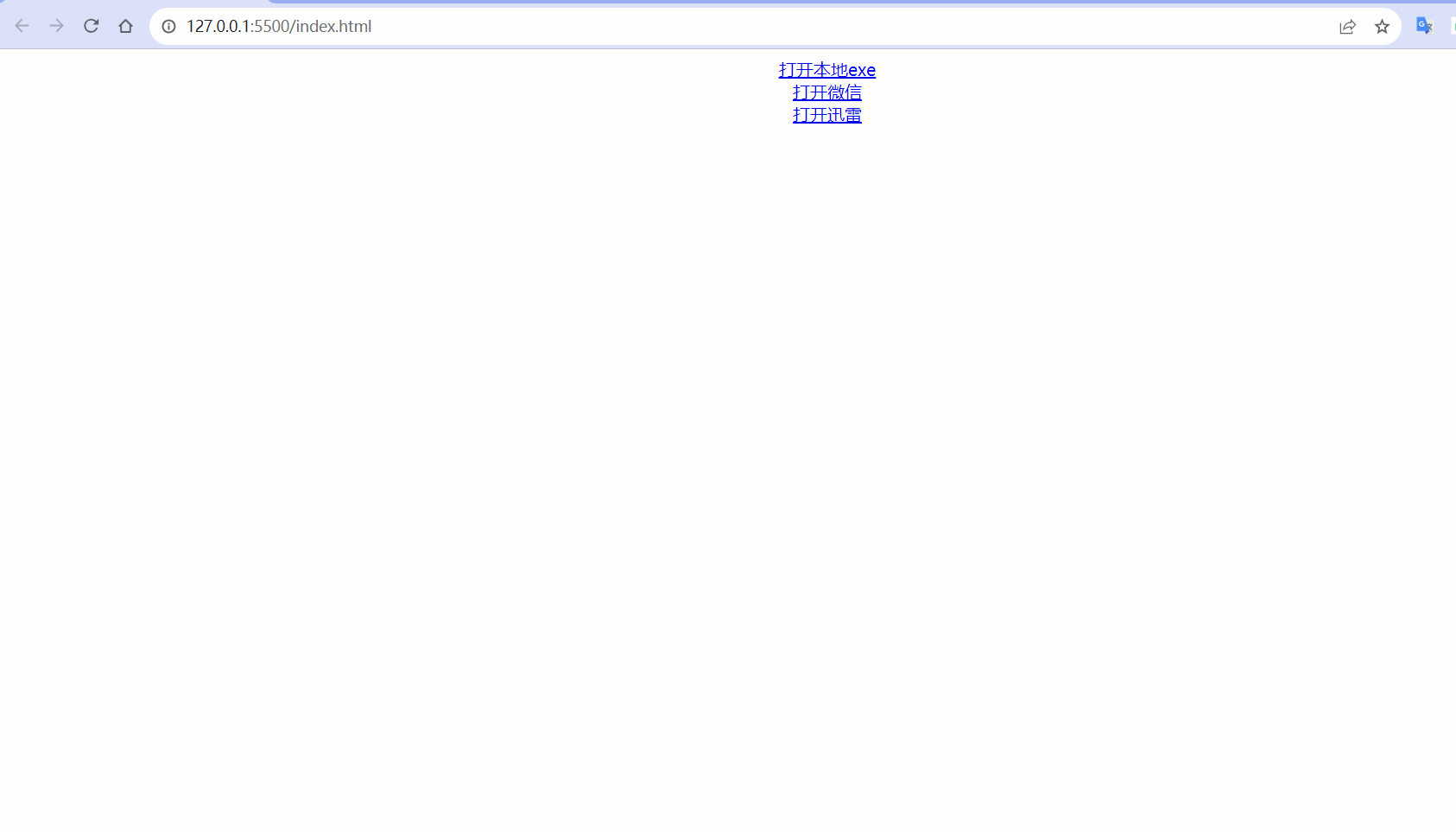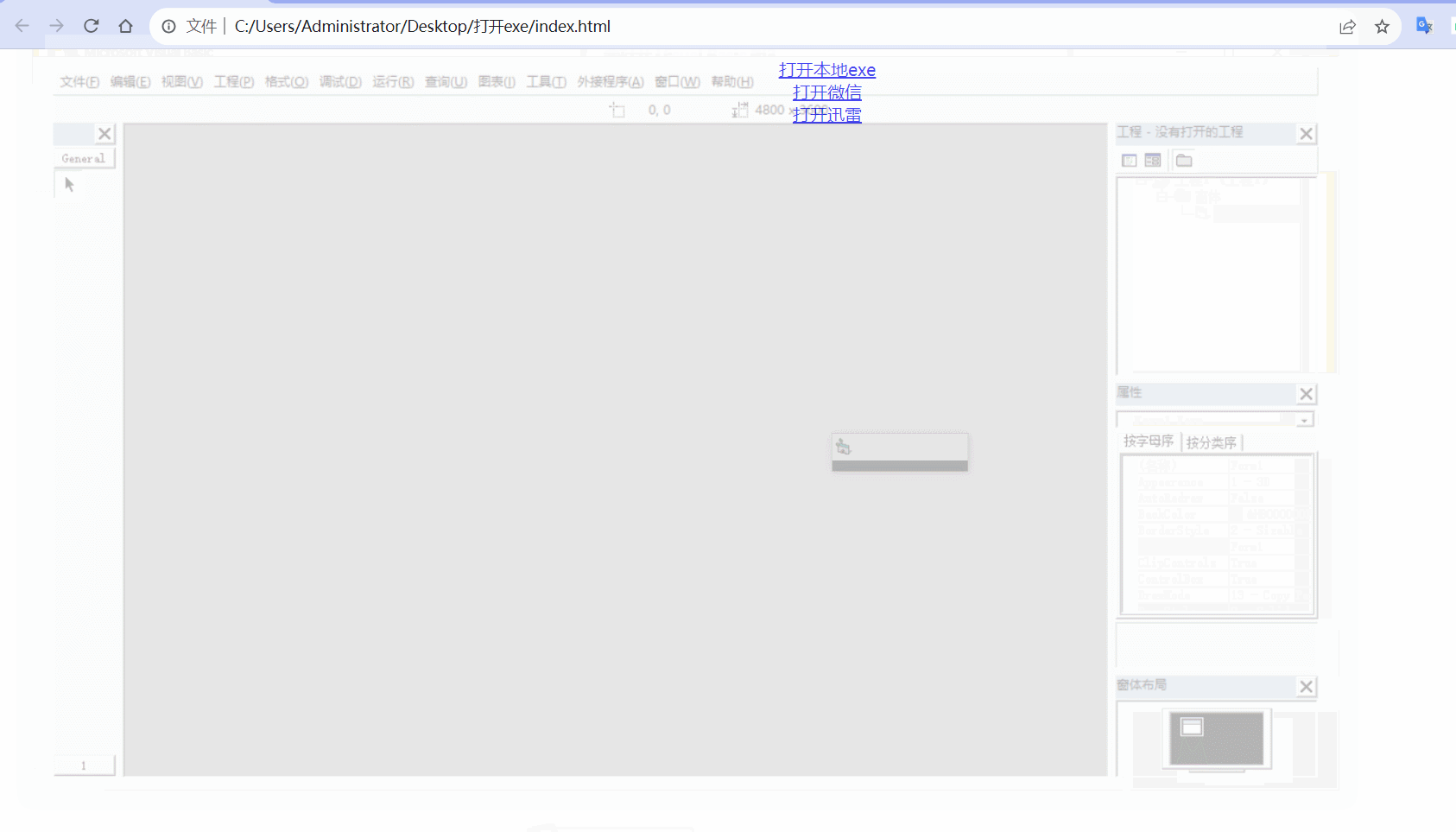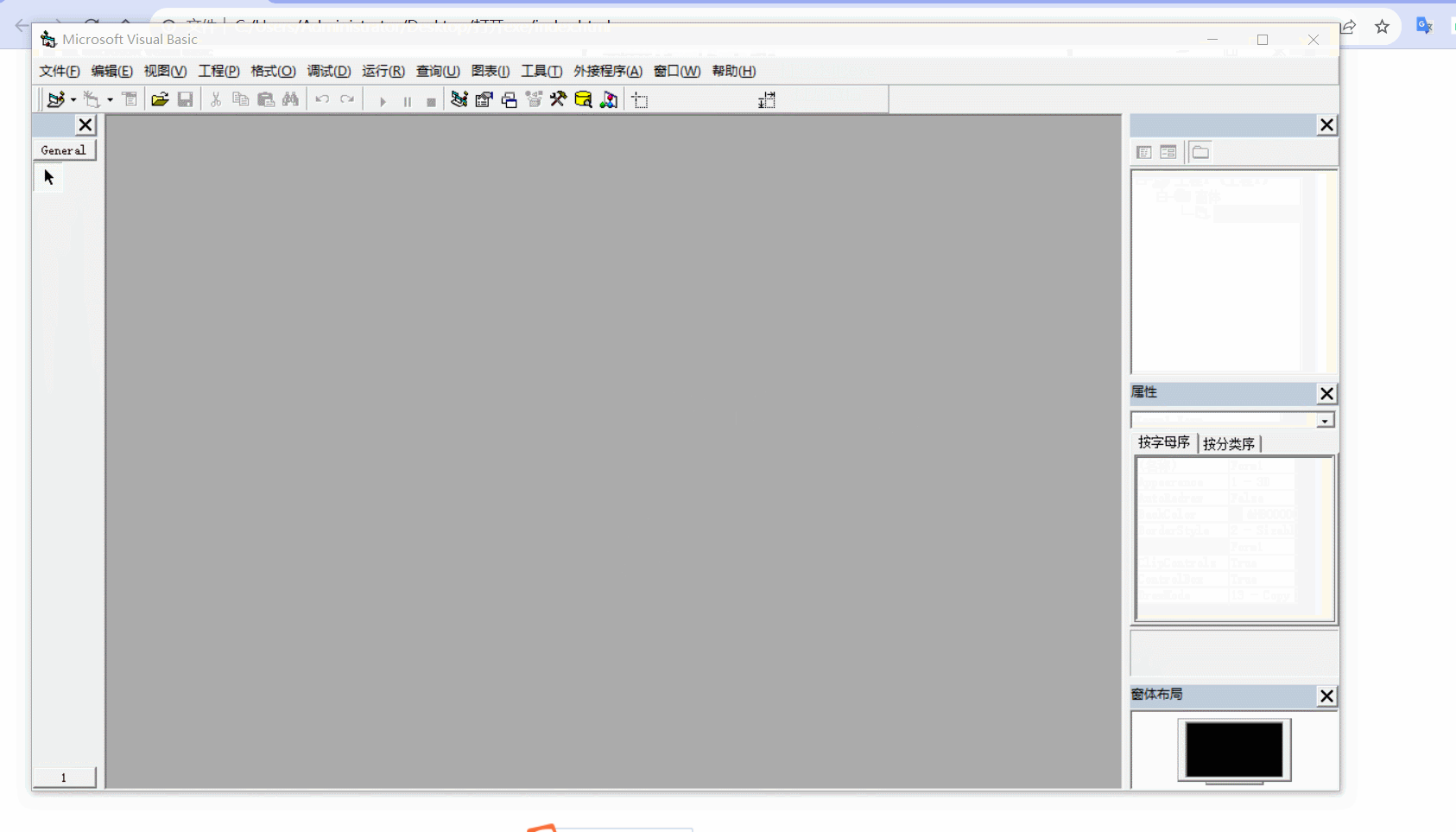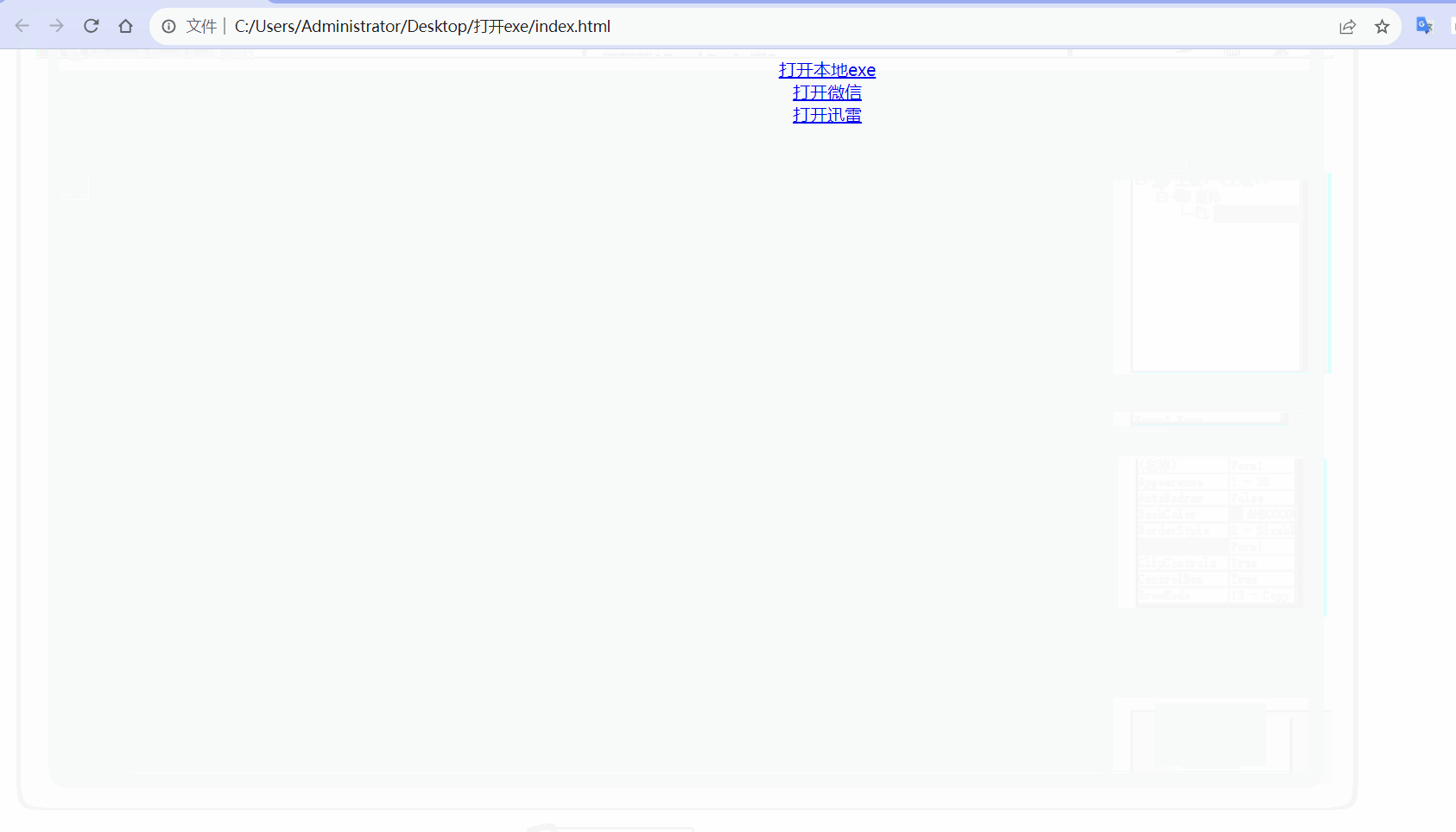
计算机 - - - 浏览器网页打开本地exe程序,网页打开微信,网页打开迅雷
效果 在电脑中安装了微信和迅雷,可以通过在地址栏中输入weixin:打开微信,输入magnet:打开迅雷。 同理:在网页中使用a标签,点击后跳转链接打开weixin:,也会同样打开微信。 运用同样的原理,在网页中点击超…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...