【NLP】理解 Llama2:KV 缓存、分组查询注意力、旋转嵌入等

LLaMA 2.0是 Meta AI 的开创性作品,作为首批高性能开源预训练语言模型之一闯入了 AI 场景。值得注意的是,LLaMA-13B 的性能优于巨大的 GPT-3(175B),尽管其尺寸只是其一小部分。您无疑听说过 LLaMA 令人印象深刻的性能,但您是否想知道是什么让它如此强大? 
图 1:原始 Transformer 和 LLama 之间的架构差异
检查图 1 揭示了从原始 Transformer 到突破性的 LLaMA 架构的深刻转变。LLaMA 2.0 牢固地植根于 Transformer 框架的基础,但它引入了独特的创新——SwiGLU激活函数、旋转位置嵌入、均方根层归一化和键值缓存。在这篇博客中,我们将揭开 LLaMA 成功背后的秘密,并带您踏上实践之旅,从头开始编写新架构。
快速开始
要立即采取行动,我们的第一步是安装必要的库并导入所需的包。为了快速上手,我将首先从 Hugging Face下载一个紧凑的数据集,为我们提供一组文本句子。这些句子将使用“ daryl149/llama-2–7b-chat-hf ”中的预构建标记器转换为标记,该标记器与 LLaMA 预训练期间使用的标记器完全相同。
!pip install transformers datasets SentencePieceimport random
import math
import numpy as np
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.utils.data import Dataset
from torch.utils.data.dataloader import DataLoader
from transformers import LlamaTokenizer
from datasets import load_dataset该代码库作为运行推理的简明示例,并强调了LLaMA 2.0 架构引入的范式转变。对于为微调量身定制的全面实现。在此演示中,我们将从数据集中获取一批随机数据,无需构建pytorch DataLoader,因为我们不会在这里训练模型。
model_id = "daryl149/llama-2-7b-chat-hf"
tokenizer = LlamaTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_tokenconfig = {'vocab_size': tokenizer.vocab_size,'n_layers': 1,'embed_dim': 2048,'n_heads': 32,'n_kv_heads': 8,'multiple_of': 64,'ffn_dim_multiplier': None,'norm_eps': 1e-5,'max_batch_size': 16,'max_seq_len': 64,'device': 'cuda',
}dataset = load_dataset('glue', 'ax', split='test')
dataset = dataset.select_columns(['premise', 'hypothesis'])test_set = tokenizer(random.sample(dataset['premise'], config['max_batch_size']),truncation=True,max_length=config['max_seq_len'],padding='max_length',return_tensors='pt'
)旋转位置嵌入
LLaMA2 的基本进步之一是采用旋转位置嵌入 (RoPE)代替传统的绝对位置编码。RoPE 的与众不同之处在于它能够将显式相对位置依赖性无缝集成到模型的自注意力机制中。这种动态方法具有几个关键优势:
- 序列长度的灵活性:传统的位置嵌入通常需要定义最大序列长度,限制了它们的适应性。另一方面,RoPE 非常灵活。它可以为任意长度的序列即时生成位置嵌入。
- 减少代币间的依赖关系:RoPE 在对代币之间的关系进行建模方面非常聪明。随着令牌在序列中彼此距离越来越远,RoPE 自然会减少它们之间的令牌依赖性。这种逐渐衰退与人类理解语言的方式更加一致,早期单词的重要性往往会减弱。
- 增强的自注意力:RoPE 为线性自注意力机制配备了相对位置编码,这是传统绝对位置编码中不存在的功能。此增强功能允许更精确地利用令牌嵌入。
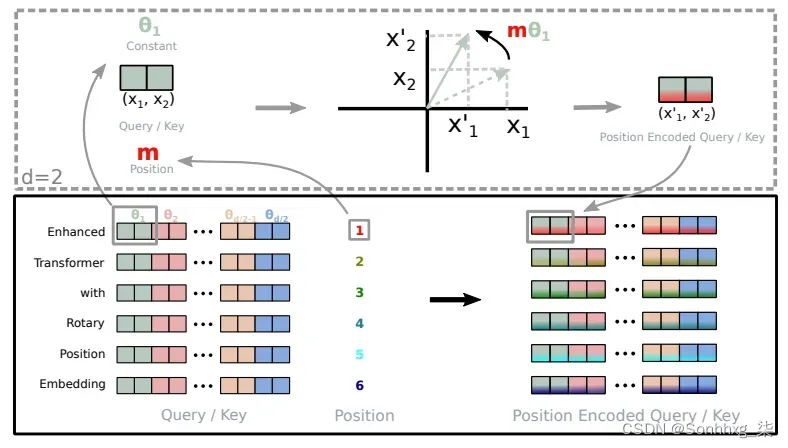
旋转嵌入的实现(取自Roformer)
传统的绝对位置编码类似于指定单词出现在位置 3、5 或 7,而与上下文无关。相比之下,RoPE 让模型了解单词之间是如何相互关联的。它认识到单词 A 经常出现在单词 B 之后和单词 C 之前。这种动态理解增强了模型的性能。
def precompute_theta_pos_frequencies(head_dim, seq_len, device, theta=10000.0):# theta_i = 10000^(-2(i-1)/dim) for i = [1, 2, ... dim/2]# (head_dim / 2)theta_numerator = torch.arange(0, head_dim, 2).float()theta = 1.0 / (theta ** (theta_numerator / head_dim)).to(device)# (seq_len)m = torch.arange(seq_len, device=device)# (seq_len, head_dim / 2)freqs = torch.outer(m, theta).float()# complex numbers in polar, c = R * exp(m * theta), where R = 1:# (seq_len, head_dim/2)freqs_complex = torch.polar(torch.ones_like(freqs), freqs)return freqs_complexdef apply_rotary_embeddings(x, freqs_complex, device):# last dimension pairs of two values represent real and imaginary# two consecutive values will become a single complex number# (m, seq_len, num_heads, head_dim/2, 2)x = x.float().reshape(*x.shape[:-1], -1, 2)# (m, seq_len, num_heads, head_dim/2)x_complex = torch.view_as_complex(x)# (seq_len, head_dim/2) --> (1, seq_len, 1, head_dim/2)freqs_complex = freqs_complex.unsqueeze(0).unsqueeze(2)# multiply each complex number# (m, seq_len, n_heads, head_dim/2)x_rotated = x_complex * freqs_complex# convert back to the real number# (m, seq_len, n_heads, head_dim/2, 2)x_out = torch.view_as_real(x_rotated)# (m, seq_len, n_heads, head_dim)x_out = x_out.reshape(*x.shape)return x_out.type_as(x).to(device)让我们分解旋转位置嵌入 (RoPE) 的代码以了解它是如何实现的。
precompute_theta_pos_frequencies函数计算RoPE 的特殊值。首先定义一个名为 的超参数theta,控制旋转的幅度。较小的值会产生较小的旋转。然后,它使用计算一组旋转角度theta。该函数还创建序列中的位置列表,并通过获取位置列表和旋转角度的外积来计算每个位置应旋转的程度。最后,它将这些值转换为具有固定大小的极坐标形式的复数,这就像表示位置和旋转的密码。apply_rotary_embeddings函数采用数值并用旋转信息增强它们。它首先将输入值的最后一个维度分成代表实部和虚部的对。然后将这些对组合成单个复数。接下来,该函数将预先计算的复数与输入相乘,从而有效地应用旋转。最后,它将结果转换回实数并重塑数据,为进一步处理做好准备。
均方根标准值
Llama2采用均方根层归一化(RMSNorm),通过替换现有的层归一化(LayerNorm)来增强变压器架构。LayerNorm 有利于提高训练稳定性和模型收敛性,因为它重新居中并重新缩放输入和权重矩阵值。然而,这种改进是以计算开销为代价的,这会减慢网络速度。
简化的 LayerNorm 公式:从输入中减去均值并除以标准差
另一方面,RMSNorm 保留了重新缩放不变性,同时简化了计算。它使用均方根 (RMS) 调节神经元的组合输入,提供隐式学习率自适应。这使得 RMSNorm 的计算效率比 LayerNorm 更高。
均方根归一化 (RMSNorm) 公式,其中 gi 是增益参数,用于重新缩放标准化求和输入
跨各种任务和网络架构的大量实验表明,RMSNorm 的性能与 LayerNorm 一样有效,同时将计算时间减少了 7% 至 64%。
class RMSNorm(nn.Module):def __init__(self, dim, eps=1e-6):super().__init__()self.eps = epsself.weight = nn.Parameter(torch.ones(dim))def _norm(self, x: torch.Tensor):# (m, seq_len, dim) * (m, seq_len, 1) = (m, seq_len, dim)# rsqrt: 1 / sqrt(x)return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, x: torch.Tensor):# weight is a gain parameter used to re-scale the standardized summed inputs# (dim) * (m, seq_len, dim) = (m, seq_Len, dim)return self.weight * self._norm(x.float()).type_as(x)该自定义脚本首先x通过将输入除以其均方根来标准化输入,从而使其对缩放变化保持不变。学习到的权重参数self.weight应用于标准化张量中的每个元素。此操作根据学习的缩放因子调整值的大小。
键值KV缓存
键值 (KV) 缓存是一种用于加速机器学习模型中的推理过程的技术,特别是在 GPT 和 Llama 等自回归模型中。在这些模型中,逐个生成令牌是一种常见做法,但计算成本可能很高,因为它在每一步都会重复某些计算。为了解决这个问题,KV 缓存就发挥了作用。它涉及缓存以前的 Keys 和 Values,因此我们不需要为每个新令牌重新计算它们。这显着减少了计算中使用的矩阵的大小,使矩阵乘法更快。唯一的代价是 KV 缓存需要更多的 GPU 内存(如果不使用 GPU,则需要 CPU 内存)来存储这些 Key 和 Value 状态。
使用和不使用 KV 缓存的 Aattention
class KVCache:def __init__(self, max_batch_size, max_seq_len, n_kv_heads, head_dim, device):self.cache_k = torch.zeros((max_batch_size, max_seq_len, n_kv_heads, head_dim)).to(device)self.cache_v = torch.zeros((max_batch_size, max_seq_len, n_kv_heads, head_dim)).to(device)def update(self, batch_size, start_pos, xk, xv):self.cache_k[:batch_size, start_pos :start_pos + xk.size(1)] = xkself.cache_v[:batch_size, start_pos :start_pos + xv.size(1)] = xvdef get(self, batch_size, start_pos, seq_len):keys = self.cache_k[:batch_size, :start_pos + seq_len]values = self.cache_v[:batch_size, :start_pos + seq_len]return keys, values在推理过程中,该过程一次对一个令牌进行操作,保持序列长度为 1。这意味着,对于 Key、Value 和 Query,线性层和旋转嵌入都专门针对特定位置的单个标记。Key 和 Value 的注意力权重被预先计算并存储为缓存,确保这些计算仅发生一次并且其结果被缓存。脚本get方法检索过去的 Key 和 Value 直到当前位置的注意力权重,将其长度扩展到 1 以上。在缩放点积运算期间,输出大小与查询大小匹配,这仅生成单个标记。
分组查询注意力
Llama 采用了一种称为分组查询注意力 (GQA) 的技术来解决Transformer 模型自回归解码期间的内存带宽挑战。主要问题源于需要在每个处理步骤加载解码器权重和注意键/值,这会消耗过多的内存。
作为回应,引入了两种策略:
- 多查询注意力(MQA)涉及利用具有单个键/值头的多个查询头,这可以加速解码器推理。但它也存在质量下降、训练不稳定等缺点。
- 分组查询注意力(GQA)是 MQA 的演变,通过使用中间数量的键值头(多于一个但少于查询头)来达到平衡。GQA 模型像
n_heads原始的多头注意力机制一样,有效地将查询分成片段,并且将键和值分为n_kv_heads组,使得多个键值头能够共享相同的查询。
通过重复键值对以提高计算效率,GQA 方法在保持质量的同时优化了性能,正如代码实现所证明的那样。
不同Attention Method概述
提供的代码用于使用 Transformer 模型在自回归解码器的上下文中实现分组查询注意 (GQA)。值得注意的是,在推理过程中,序列长度 (seq_len) 始终设置为 1。
def repeat_kv(x, n_rep):batch_size, seq_len, n_kv_heads, head_dim = x.shapeif n_rep == 1:return xelse:# (m, seq_len, n_kv_heads, 1, head_dim)# --> (m, seq_len, n_kv_heads, n_rep, head_dim)# --> (m, seq_len, n_kv_heads * n_rep, head_dim)return (x[:, :, :, None, :].expand(batch_size, seq_len, n_kv_heads, n_rep, head_dim).reshape(batch_size, seq_len, n_kv_heads * n_rep, head_dim))class SelfAttention(nn.Module):def __init__(self, config):super().__init__()self.n_heads = config['n_heads']self.n_kv_heads = config['n_kv_heads']self.dim = config['embed_dim']self.n_kv_heads = self.n_heads if self.n_kv_heads is None else self.n_kv_headsself.n_heads_q = self.n_headsself.n_rep = self.n_heads_q // self.n_kv_headsself.head_dim = self.dim // self.n_headsself.wq = nn.Linear(self.dim, self.n_heads * self.head_dim, bias=False)self.wk = nn.Linear(self.dim, self.n_kv_heads * self.head_dim, bias=False)self.wv = nn.Linear(self.dim, self.n_kv_heads * self.head_dim, bias=False)self.wo = nn.Linear(self.n_heads * self.head_dim, self.dim, bias=False)self.cache = KVCache(max_batch_size=config['max_batch_size'],max_seq_len=config['max_seq_len'],n_kv_heads=self.n_kv_heads,head_dim=self.head_dim,device=config['device'])def forward(self, x, start_pos, freqs_complex):# seq_len is always 1 during inferencebatch_size, seq_len, _ = x.shape# (m, seq_len, dim)xq = self.wq(x)# (m, seq_len, h_kv * head_dim)xk = self.wk(x)xv = self.wv(x)# (m, seq_len, n_heads, head_dim)xq = xq.view(batch_size, seq_len, self.n_heads_q, self.head_dim)# (m, seq_len, h_kv, head_dim)xk = xk.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)xv = xv.view(batch_size, seq_len, self.n_kv_heads, self.head_dim)# (m, seq_len, num_head, head_dim)xq = apply_rotary_embeddings(xq, freqs_complex, device=x.device)# (m, seq_len, h_kv, head_dim)xk = apply_rotary_embeddings(xk, freqs_complex, device=x.device)# replace the entry in the cacheself.cache.update(batch_size, start_pos, xk, xv)# (m, seq_len, h_kv, head_dim)keys, values = self.cache.get(batch_size, start_pos, seq_len)# (m, seq_len, h_kv, head_dim) --> (m, seq_len, n_heads, head_dim)keys = repeat_kv(keys, self.n_rep)values = repeat_kv(values, self.n_rep)# (m, n_heads, seq_len, head_dim)# seq_len is 1 for xq during inferencexq = xq.transpose(1, 2)# (m, n_heads, seq_len, head_dim)keys = keys.transpose(1, 2)values = values.transpose(1, 2)# (m, n_heads, seq_len_q, head_dim) @ (m, n_heads, head_dim, seq_len) -> (m, n_heads, seq_len_q, seq_len)scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)# (m, n_heads, seq_len_q, seq_len)scores = F.softmax(scores.float(), dim=-1).type_as(xq)# (m, n_heads, seq_len_q, seq_len) @ (m, n_heads, seq_len, head_dim) -> (m, n_heads, seq_len_q, head_dim)output = torch.matmul(scores, values)# ((m, n_heads, seq_len_q, head_dim) -> (m, seq_len_q, dim)output = (output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1))# (m, seq_len_q, dim)return self.wo(output)SelfAttention是一个结合了我们已经讨论过的机制的类。该类的关键组件如下:
- 线性变换应用于查询 (xq)、键 (xk) 和值 (xv) 的输入张量。这些转换将输入数据投影为适合处理的形式。
- 使用提供的频率复数将旋转嵌入应用于查询、键和值张量。此步骤增强了模型考虑位置信息和执行注意力计算的能力。
- 键值对(k 和 v)被缓存以有效使用内存。检索缓存的键值对,直到当前位置 (
start_pos + seq_len) - 通过重复键值对次数来准备查询、键和值张量以用于分组查询注意力
n_rep计算,其中n_rep对应于共享相同键值对的查询头的数量。 - 缩放点积注意力计算。注意力分数是通过查询和键的点积计算出来的,然后进行缩放。应用 Softmax 来获得最终的注意力分数。在计算过程中,输出大小与查询大小匹配,也是 1。
wo最后,该模块对输出应用线性变换( ),并返回处理后的输出。
SwiGlu
LLaMA2 模型中使用的 SwiGLU 是一种激活函数,旨在增强 Transformer 架构中位置前馈网络 (FFN) 层的性能。与其他激活函数相比,SwiGLU 的主要优点是:
- 平滑性:SwiGLU 比 ReLU 更平滑,可以带来更好的优化和更快的收敛。
- 非单调性:SwiGLU 是非单调的,这使得它能够捕获输入和输出之间复杂的非线性关系
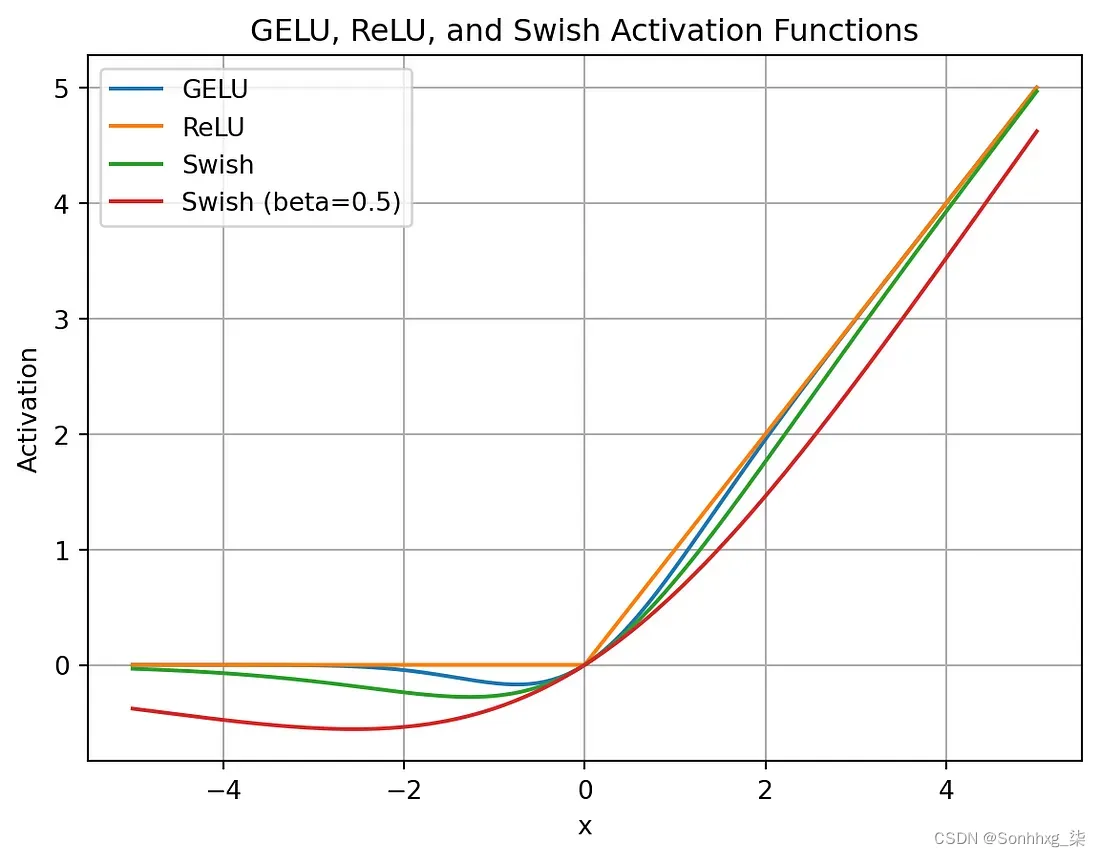
不同 GLU 激活的比较
def sigmoid(x, beta=1):return 1 / (1 + torch.exp(-x * beta))def swiglu(x, beta=1):return x * sigmoid(x, beta)Feedforward
在 Transformer 架构中,前馈层起着至关重要的作用,通常位于注意力层和归一化层之后。前馈层由三个线性变换组成。
class FeedForward(nn.Module):def __init__(self, config):super().__init__()hidden_dim = 4 * config['embed_dim']hidden_dim = int(2 * hidden_dim / 3)if config['ffn_dim_multiplier'] is not None:hidden_dim = int(config['ffn_dim_multiplier'] * hidden_dim)# Round the hidden_dim to the nearest multiple of the multiple_of parameterhidden_dim = config['multiple_of'] * ((hidden_dim + config['multiple_of'] - 1) // config['multiple_of'])self.w1 = nn.Linear(config['embed_dim'], hidden_dim, bias=False)self.w2 = nn.Linear(config['embed_dim'], hidden_dim, bias=False)self.w3 = nn.Linear(hidden_dim, config['embed_dim'], bias=False)def forward(self, x: torch.Tensor):# (m, seq_len, dim) --> (m, seq_len, hidden_dim)swish = swiglu(self.w1(x))# (m, seq_len, dim) --> (m, seq_len, hidden_dim)x_V = self.w2(x)# (m, seq_len, hidden_dim)x = swish * x_V# (m, seq_len, hidden_dim) --> (m, seq_len, dim)return self.w3(x)在前向传递过程中,输入张量x经历多层线性变换。第一次转换后应用的SwiGLU激活函数增强了模型的表达能力。最终的变换将张量映射回其原始维度。SwiGLU 激活和多个前馈层的这种独特组合增强了模型的性能。
最终Transformer模型
Llama2 的最终巅峰是一个强大的Transformer模型,汇集了我们迄今为止讨论的一系列先进技术。DecoderBlock 是该模型的基本构建块,它结合了 KV 缓存、分组查询注意力、SwiGLU 激活和旋转嵌入的知识,创建了一个高效且有效的解决方案。
class DecoderBlock(nn.Module):def __init__(self, config):super().__init__()self.n_heads = config['n_heads']self.dim = config['embed_dim']self.head_dim = self.dim // self.n_headsself.attention = SelfAttention(config)self.feed_forward = FeedForward(config)# rms before attention blockself.attention_norm = RMSNorm(self.dim, eps=config['norm_eps'])# rms before feed forward blockself.ffn_norm = RMSNorm(self.dim, eps=config['norm_eps'])def forward(self, x, start_pos, freqs_complex):# (m, seq_len, dim)h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_complex)# (m, seq_len, dim)out = h + self.feed_forward.forward(self.ffn_norm(h))return outclass Transformer(nn.Module):def __init__(self, config):super().__init__()self.vocab_size = config['vocab_size']self.n_layers = config['n_layers']self.tok_embeddings = nn.Embedding(self.vocab_size, config['embed_dim'])self.head_dim = config['embed_dim'] // config['n_heads']self.layers = nn.ModuleList()for layer_id in range(config['n_layers']):self.layers.append(DecoderBlock(config))self.norm = RMSNorm(config['embed_dim'], eps=config['norm_eps'])self.output = nn.Linear(config['embed_dim'], self.vocab_size, bias=False)self.freqs_complex = precompute_theta_pos_frequencies(self.head_dim, config['max_seq_len'] * 2, device=(config['device']))def forward(self, tokens, start_pos):# (m, seq_len)batch_size, seq_len = tokens.shape# (m, seq_len) -> (m, seq_len, embed_dim)h = self.tok_embeddings(tokens)# (seq_len, (embed_dim/n_heads)/2]freqs_complex = self.freqs_complex[start_pos:start_pos + seq_len]# Consecutively apply all the encoder layers# (m, seq_len, dim)for layer in self.layers:h = layer(h, start_pos, freqs_complex)h = self.norm(h)# (m, seq_len, vocab_size)output = self.output(h).float()return outputmodel = Transformer(config).to(config['device'])
res = model.forward(test_set['input_ids'].to(config['device']), 0)
print(res.size())Transformer 模型包含一堆DecoderBlock,以创建强大且高效的深度学习架构。随附的代码展示了DecoderBlock及其SelfAttention、FeedForward和RMSNorm层如何有效处理数据。该代码还强调了更大的 Transformer 架构的结构,包括令牌嵌入、层堆叠和输出生成。此外,预计算频率和先进技术的使用,与定制配置相结合,确保了模型在各种自然语言理解任务中的卓越性能和多功能性。
结论
在这次全面了解 Llama2 Transformers 先进技术的旅程中,我们深入研究了理论和复杂的代码实现。然而,值得注意的是,我们讨论的代码主要不是用于训练或生产用途,而是更多地作为 Llama 卓越推理能力的演示和展示。它强调了如何在现实世界中应用这些先进技术,并展示了 Llama2 在增强各种自然语言理解任务方面的潜力。
相关文章:
【NLP】理解 Llama2:KV 缓存、分组查询注意力、旋转嵌入等
LLaMA 2.0是 Meta AI 的开创性作品,作为首批高性能开源预训练语言模型之一闯入了 AI 场景。值得注意的是,LLaMA-13B 的性能优于巨大的 GPT-3(175B),尽管其尺寸只是其一小部分。您无疑听说过 LLaMA 令人印象深刻的性能,但您是否想知…...
ctyunos 与 openeuler
ctyunos-2.0.1-220311-aarch64-dvd ctyunos-2.0.1-220329-everything-aarch64-dvd glibc python3 对应openEuler 20.03 LTS SP1...

跟着GPT学设计模式之工厂模式
工厂模式(Factory Design Pattern)分为三种更加细分的类型:简单工厂、工厂方法和抽象工厂。在这三种细分的工厂模式中,简单工厂、工厂方法原理比较简单,在实际的项目中也比较常用。而抽象工厂的原理稍微复杂点…...
VScode+python开发,多个解释器切换问题
内容:主要VScode使用多个解释器 环境准备 VScode编辑器,两个版本python解释器 python3.7.2 python3.11.6 问题: 目前我们的电脑安装了python3.7.2、python3.11.6两个解释器,在vscode编辑器中,无法切换解释器使用如…...
c++ 经典服务器开源项目Tinywebserver如何运行
第一次直接按作者的指示,运行sh ./build.sh,再运行./server,发现不起作用,localhost:9006也是拒绝访问的状态,后来摸索成功了发现,运行./server之后,应该是启动状态,就是不会退出,而…...
c++之xml的创建,增删改查
c之xml的创建,增删改查 1.创建写入2.添加3.删除4.修改: 1.创建写入 #include <stdio.h> #include <typeinfo> #include "F:/EDGE/tinyxml/tinyxml.h" #include <iostream> #include <string> #include <Winsock2.…...

【前端开发】JS Vue React中的通用递归函数
目录 前言 一、递归函数的由来 二、功能实现 1.后台数据 2.处理数据 3.整体代码 总结 🙂博主:冰海恋雨. 🙂文章核心:【前端开发】JS Vue React中的通用递归函数 前言 大家好,今天和大家分享一下在前端开发中j…...
【python 生成器 面试必备】yield关键字,协程必知必会系列文章--自己控制程序调度,体验做上帝的感觉 1
python生成器系列文章目录 第一章 yield — Python (Part I) 文章目录 python生成器系列文章目录前言1. Generator Function 生成器函数2.并发和并行,抢占式和协作式2.Let’s implement Producer/Consumer pattern using subroutine: 生成器的状态 generator’s st…...

头哥实践平台之MapReduce基础实战
一. 第1关:成绩统计 编程要求 使用MapReduce计算班级每个学生的最好成绩,输入文件路径为/user/test/input,请将计算后的结果输出到/user/test/output/目录下。 先写命令行,如下: 一行就是一个命令 touch file01 echo Hello World Bye Wor…...

Linux基础知识——tmux和vim
Linux基础知识——tmux和vim 文章目录 Linux基础知识——tmux和vim一、tmux1. 功能2. 结构3. 操作 二、vim功能模式操作 一、tmux tmux配置:~/.tmux.conf修改为如下 set-option -g status-keys vi setw -g mode-keys visetw -g monitor-activity on# setw -g c0-cha…...
Java Web——TomcatWeb服务器
目录 1. 服务器概述 1.1. 服务器硬件 1.2. 服务器软件 2. Web服务器 2.1. Tomcat服务器 2.2. 简单的Web服务器使用 1. 服务器概述 服务器指的是网络环境下为客户机提供某种服务的专用计算机,服务器安装有网络操作系统和各种服务器的应用系统服务器的具有高速…...
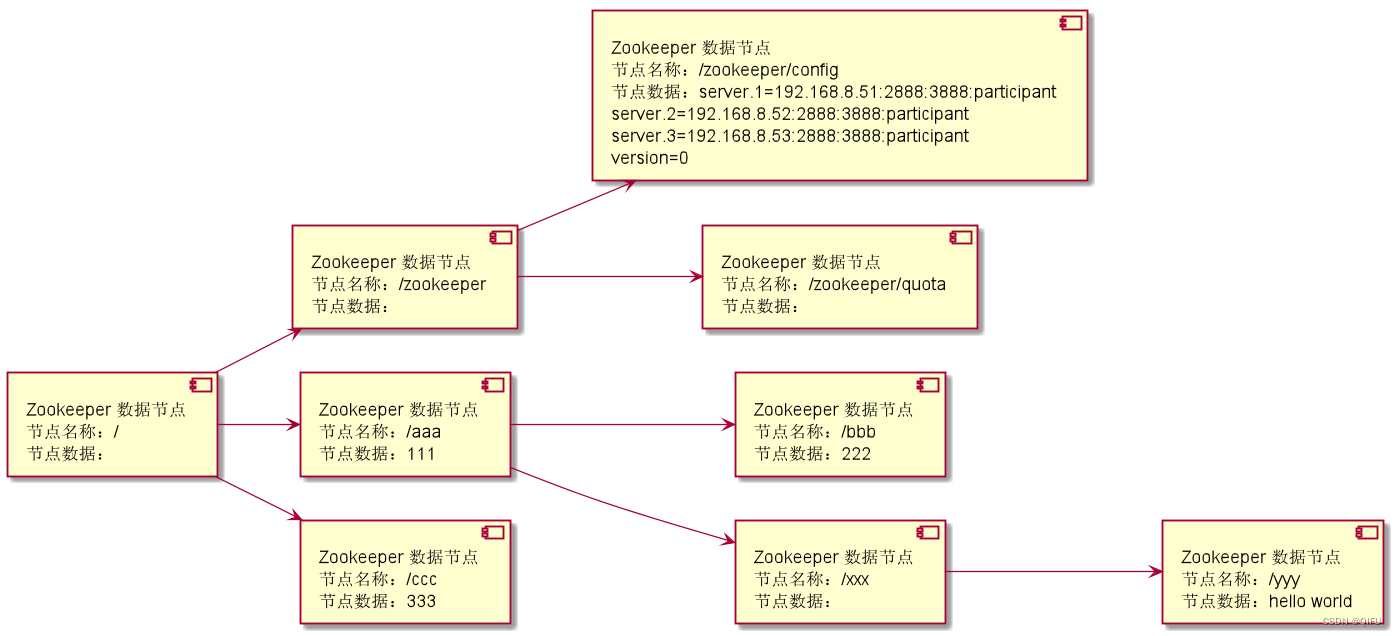
Zookeeper 命令使用和数据说明
文章目录 一、概述二、命令使用2.1 登录 ZooKeeper2.2 ls 命令,查看目录树(节点)2.3 create 命令,创建节点2.4 delete 命令,删除节点2.5 set 命令,设置节点数据2.6 get 命令,获取节点数据 三、数…...

索尼RSV文件怎么恢复为MP4视频
索尼相机RSV是什么文件? 如果您的相机是索尼SONY A7S3,A7M4,FX3,FX3,FX6,或FX9等,有时录像会产生一个RSV文件,而没有MP4视频文件。RSV其实是MP4的前期文件,经我对RSV文件…...
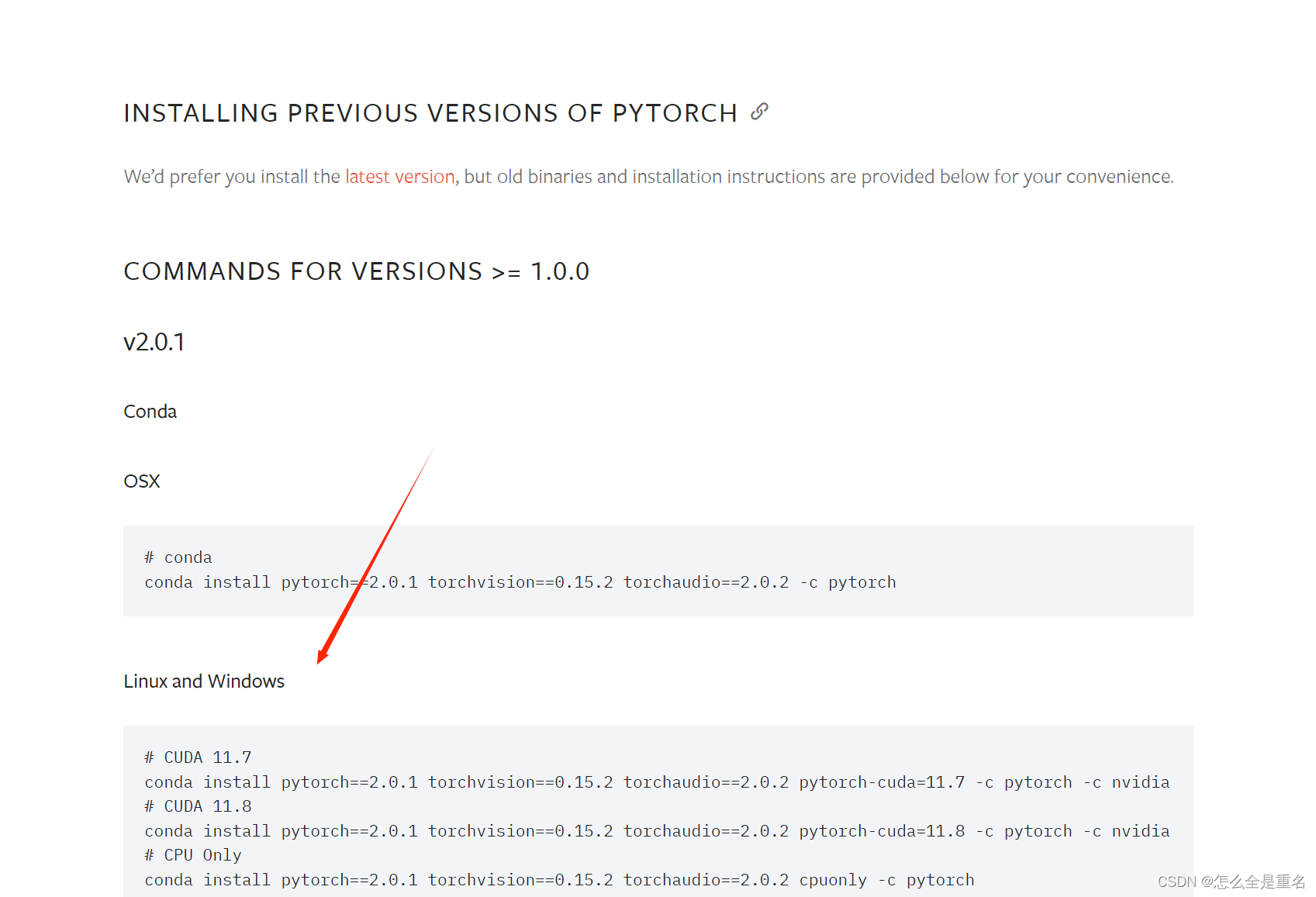
pytorch-gpu(Anaconda3+cuda+cudnn)
文章目录 下载Anaconda3安装,看着点next就行比较懒所以自动添加path测试 cuda安装的时候不能改路径如果出现报错,关闭杀毒软件一直下一步就好取消勾选“CUDA”中的“Visual Studio Intergration”一直下一步即可测试安装成功 cudnn解压后将这三个文件夹复…...
解析数据洁净之道:BI中数据清理对见解的深远影响
本文由葡萄城技术团队发布。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 前言 随着数字化和信息化进程的不断发展,数据已经成为企业的一项不可或缺的重要资源。然而,这…...
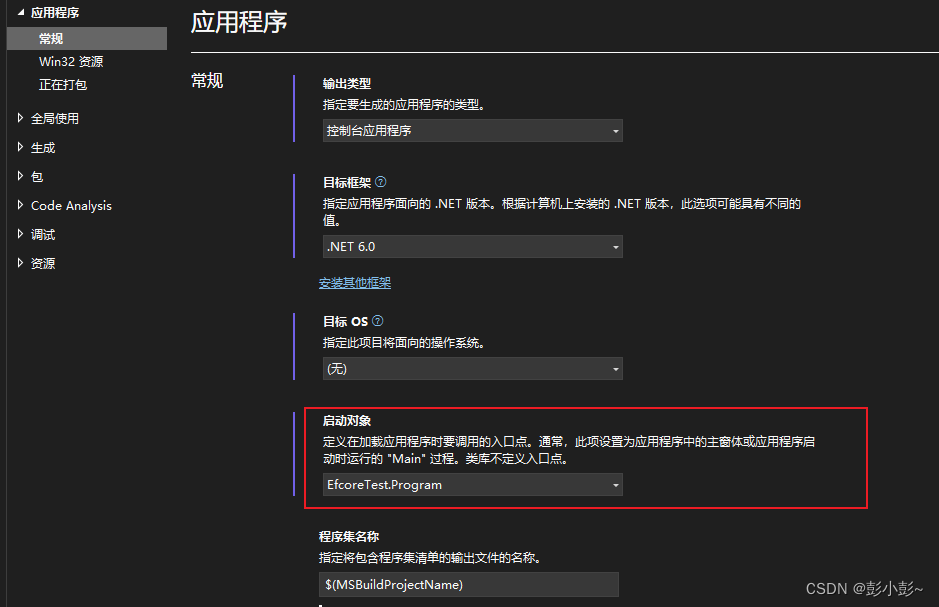
efcore反向共工程,单元测试
1.安装efcore需要的nuget <PackageReference Include"Microsoft.EntityFrameworkCore" Version"6.0.24" /> <PackageReference Include"Microsoft.EntityFrameworkCore.SqlServer" Version"6.0.24" /> <PackageRefere…...

利用IP风险画像强化金融行业网络安全防御
在数字化时代,金融行业日益依赖互联网和技术创新,但这也使得金融机构成为网络攻击的主要目标。为了应对日益复杂的网络威胁,金融机构迫切需要采用先进的安全技术和工具。其中,IP风险画像技术成为提升网络安全的一项重要策略。 1.…...
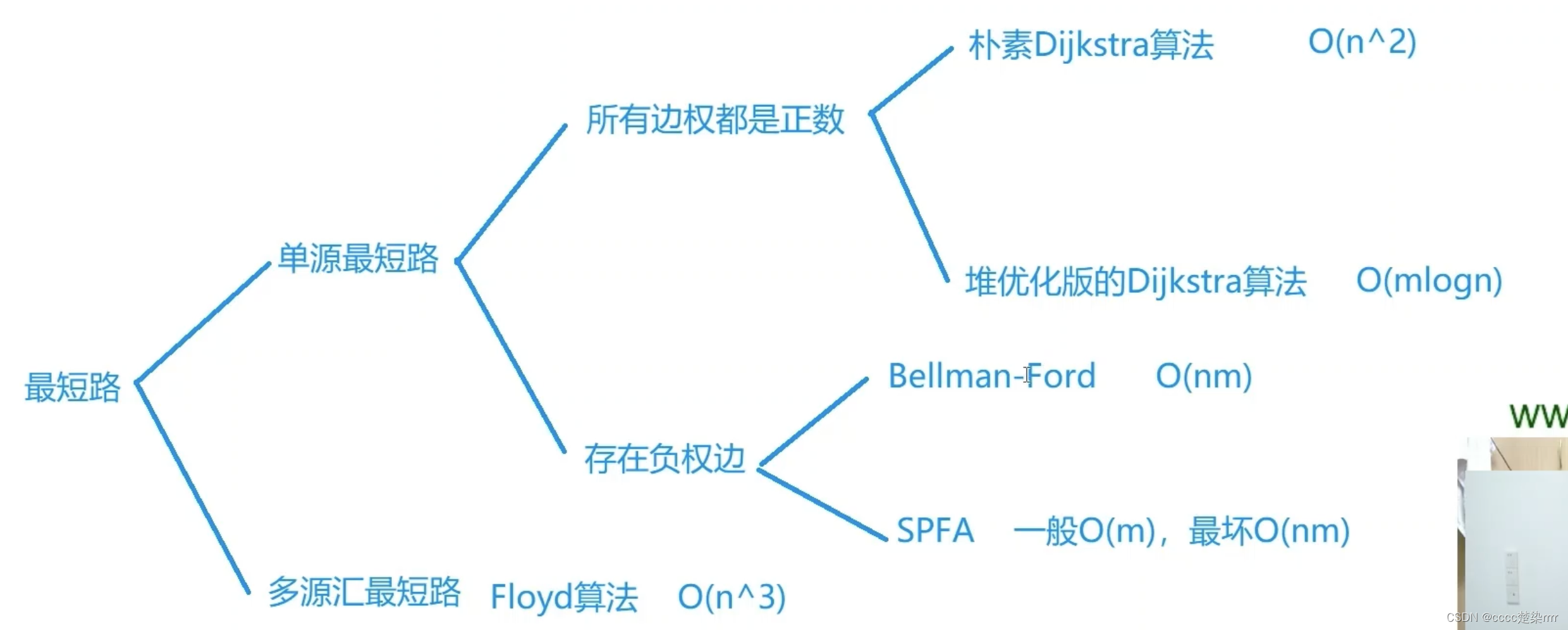
1334. 阈值距离内邻居最少的城市
分析题目两点“阈值距离”、“邻居最少”。 “阈值距离”相当于定了个上界,求节点之间的最短距离。 “邻居最少”相当于能连接的点的数量。 求节点之间的最短距离有以下几种方法: 在这道题当中,n的范围是100以内,所以可以考虑O(n…...

Live800:客服行业的发展历程及未来前景
随着信息技术和互联网的高速发展,客服行业也在不断变革和发展。客服行业是一个服务型的行业,其发展历程也与人们对服务需求的变化密切相关。本文将介绍客服行业的发展历程和未来前景。 客服行业的发展历程 20世纪70年代,客服行业主要以电话服…...
exsi的安装和配置
直接虚拟真实机 vcent server 管理大量的exsi SXI原生架构模式的虚拟化技术,是不需要宿主操作系统的,它自己本身就是操作系统。因此,装ESXI的时候就等同于装操作系统,直接拿iso映像(光盘)装ESXI就可以了。 VMware vCente…...

避开这3个坑!用Llama-7B低成本部署InteRecAgent的完整指南
低成本部署InteRecAgent的三大误区与实战解决方案 1. 从开源小模型到商业级应用的鸿沟 许多技术团队在尝试构建交互式推荐系统时,往往陷入"拿来即用"的思维陷阱。面对Llama-7B这类开源小模型,最常见的三个认知误区包括:认为预训练模…...

DataSphere Studio:企业级数据开发平台的7大核心优势与完整使用指南
DataSphere Studio:企业级数据开发平台的7大核心优势与完整使用指南 【免费下载链接】DataSphereStudio WeBankFinTech/DataSphereStudio: 是腾讯金融科技的一个数据开发平台,具有强大的数据处理,分析,可视化和机器学习功能&#…...

突破传统切片限制:Excel驱动的GCode设计革命
突破传统切片限制:Excel驱动的GCode设计革命 【免费下载链接】FullControl-GCode-Designer Software for designing GCODE for 3D printing 项目地址: https://gitcode.com/gh_mirrors/fu/FullControl-GCode-Designer 在3D打印领域,GCode设计和参…...

当数字音频遇见时间魔法:FLAC如何为你的音乐收藏施展无损压缩
当数字音频遇见时间魔法:FLAC如何为你的音乐收藏施展无损压缩 【免费下载链接】flac Free Lossless Audio Codec 项目地址: https://gitcode.com/gh_mirrors/fl/flac 你是否曾为音乐收藏占用过多硬盘空间而烦恼?是否在音质与存储效率之间难以抉择…...
实测好用!translategemma-4b-it图文翻译模型快速上手体验
实测好用!translategemma-4b-it图文翻译模型快速上手体验 1. 为什么选择translategemma-4b-it 1.1 轻量级但功能强大 translategemma-4b-it是Google基于Gemma 3架构开发的轻量级翻译模型,仅有4B参数,却支持55种语言的互译任务。最特别的是…...

百度网盘直链解析开源工具完全指南:从入门到精通
百度网盘直链解析开源工具完全指南:从入门到精通 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经历过这样的困扰:明明网络带宽充足ÿ…...

Phi-4-mini-reasoning镜像部署实操:7.2GB模型在24GB显存设备稳定运行
Phi-4-mini-reasoning镜像部署实操:7.2GB模型在24GB显存设备稳定运行 1. 项目概述 Phi-4-mini-reasoning是由微软Azure AI Foundry推出的轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个3.8B参数的模型虽然体积小巧࿰…...

MTKClient深度应用指南:联发科设备底层调试与系统修复全解析
MTKClient深度应用指南:联发科设备底层调试与系统修复全解析 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient 问题诊断:联发科设备典型故障与解决方案 识别设备无法…...

春联生成模型-中文-base环境隔离部署:Anaconda虚拟环境配置指南
春联生成模型-中文-base环境隔离部署:Anaconda虚拟环境配置指南 每次想尝试一个新的AI模型,最头疼的可能不是模型本身,而是环境配置。装了这个包,发现和之前项目的包版本冲突;好不容易跑起来,结果报了一堆…...

Intv_AI_MK11大模型微调实战:使用自有数据定制专属AI
Intv_AI_MK11大模型微调实战:使用自有数据定制专属AI 1. 为什么需要微调大模型 想象一下,你买了一套高级西装,虽然剪裁精良,但总感觉少了点个人特色。大模型就像这套西装,通用性强但缺乏针对性。微调就是为它"量…...