计算机视觉:人脸识别与检测
目录
前言
识别检测方法
本文方法
项目解析
完整代码及效果展示
前言
人脸识别作为一种生物特征识别技术,具有非侵扰性、非接触性、友好性和便捷性等优点。人脸识别通用的流程主要包括人脸检测、人脸裁剪、人脸校正、特征提取和人脸识别。人脸检测是从获取的图像中去除干扰,提取人脸信息,获取人脸图像位置,检测的成功率主要受图像质量,光线强弱和遮挡等因素影响。下图是整个人脸检测过程。
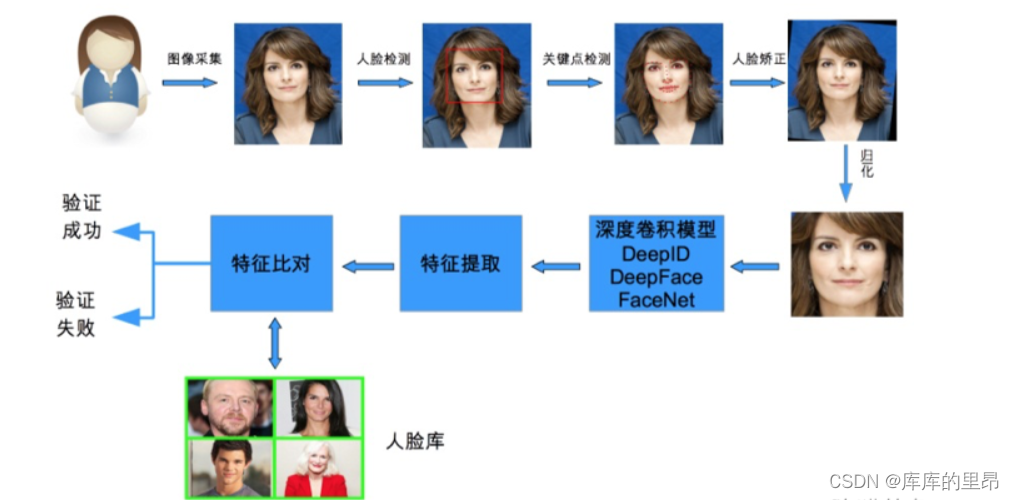
识别检测方法
-
传统识别方法
(1)基于点云数据的人脸识别
(2)基于面部特征的3D人脸识别 -
深度学习识别方法
(1)基于深度图的人脸识别
(2)基于RGB-3DMM的人脸识别
(3)基于RGB-D的人脸识别
本文方法
关键点定位概述
一般人脸中有5个关键点,其中包括眼睛两个,鼻子一个,嘴角两个。还可以细致的分为68个关键点,这样的话会概括的比较全面,我们本次研究就是68个关键点定位。

上图就是我们定位人脸的68个关键点,其中他的顺序是要严格的进行排序的。从1到68点的顺序不能错误。
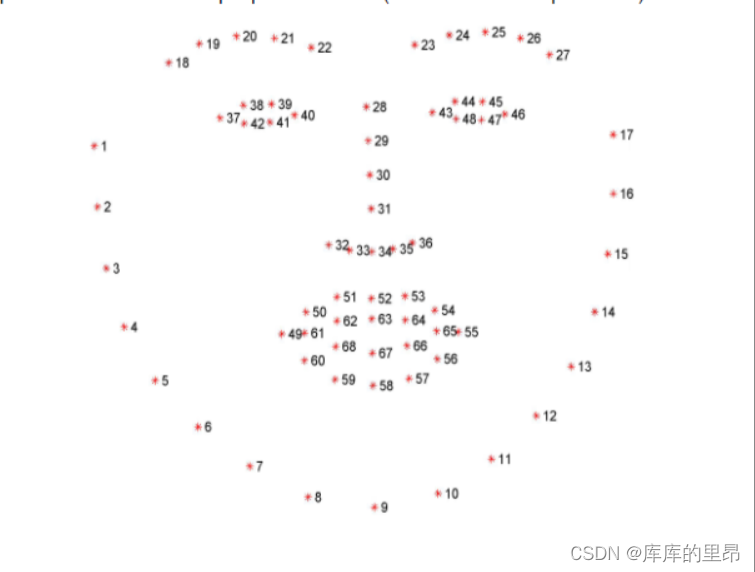
项目解析
使用机器学习框架dlib做本次的项目。首先我们要指定参数时,要把dlib中的68关键点人脸定位找到。设置出来的68关键点人脸定位找到。并且设置出来。
from collections import OrderedDict
import numpy as np
import argparse
import dlib
import cv2
首先我们导入工具包。其中dlib库是通过这个网址http://dlib.net/files/进行下载的。然后我们导入参数。
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,help="path to input image")
args = vars(ap.parse_args())
这里我们要设置参数,
--shape-predictor shape_predictor_68_face_landmarks.dat --image images/lanqiudui.jpg。如果一张图像里面有多个人脸,那么我们分不同部分进行检测,裁剪出来所对应的ROI区域。我们的整体思路就是先检测人脸所在的一个区域位置,然后检测鼻子相对于人脸框所在的一个位置,比如说人的左眼睛在0.2w,0.2h的人脸框处。
FACIAL_LANDMARKS_68_IDXS = OrderedDict([("mouth", (48, 68)),("right_eyebrow", (17, 22)),("left_eyebrow", (22, 27)),("right_eye", (36, 42)),("left_eye", (42, 48)),("nose", (27, 36)),("jaw", (0, 17))
])
这个是68个关键点定位的各个部位相对于人脸框的所在位置。分别对应着嘴,左眼、右眼、左眼眉、右眼眉、鼻子、下巴。
FACIAL_LANDMARKS_5_IDXS = OrderedDict([("right_eye", (2, 3)),("left_eye", (0, 1)),("nose", (4))
])
如果是5点定位,那么就需要定位左眼、右眼、鼻子。0、1、2、3、4分别表示对应的5个点。
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
加载人脸检测与关键点定位。加载出来。其中detector默认的人脸检测器。然后通过传入参数返回人脸检测矩形框4点坐标。其中predictor以图像的某块区域为输入,输出一系列的点(point location)以表示此图像region里object的姿势pose。返回训练好的人脸68特征点检测器。
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
width=500
r = width / float(w)
dim = (width, int(h * r))
image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
这里我们把数据读了进来,然后进行需处理,提取h和w,其中我们自己设定图像的w为500,然后按照比例同比例设置h。然后进行了resize操作,最后转化为灰度图。
rects = detector(gray, 1)
这里调用了detector的人脸框检测器,要使用灰度图进行检测,这个1是重采样个数。这里面返回的是人脸检测矩形框4点坐标。然后对检测框进行遍历
for (i, rect) in enumerate(rects):# 对人脸框进行关键点定位# 转换成ndarrayshape = predictor(gray, rect)shape = shape_to_np(shape)
这里面返回68个关键点定位。shape_to_np这个函数如下。
def shape_to_np(shape, dtype="int"):# 创建68*2coords = np.zeros((shape.num_parts, 2), dtype=dtype)# 遍历每一个关键点# 得到坐标for i in range(0, shape.num_parts):coords[i] = (shape.part(i).x, shape.part(i).y)return coords
这里shape_to_np函数的作用就是得到关键点定位的坐标。
for (name, (i, j)) in FACIAL_LANDMARKS_68_IDXS.items():clone = image.copy()cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,0.7, (0, 0, 255), 2) # 根据位置画点for (x, y) in shape[i:j]:cv2.circle(clone, (x, y), 3, (0, 0, 255), -1)# 提取ROI区域(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))roi = image[y:y + h, x:x + w](h, w) = roi.shape[:2]width=250r = width / float(w)dim = (width, int(h * r))roi = cv2.resize(roi, dim, interpolation=cv2.INTER_AREA)# 显示每一部分cv2.imshow("ROI", roi)cv2.imshow("Image", clone)cv2.waitKey(0)
这里字典FACIAL_LANDMARKS_68_IDXS.items()是同时提取字典中的key和value数值。然后遍历出来这几个区域,并且进行显示具体是那个区域,并且将这个区域画圆。随后提取roi区域并且进行显示。后面部分就是同比例显示w和h。然后展示出来。
output = visualize_facial_landmarks(image, shape)cv2.imshow("Image", output)cv2.waitKey(0)
最后展示所有区域。
其中visualize_facial_landmarks函数就是:
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):# 创建两个copy# overlay and one for the final output imageoverlay = image.copy()output = image.copy()# 设置一些颜色区域if colors is None:colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),(168, 100, 168), (158, 163, 32),(163, 38, 32), (180, 42, 220)]# 遍历每一个区域for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()):# 得到每一个点的坐标(j, k) = FACIAL_LANDMARKS_68_IDXS[name]pts = shape[j:k]# 检查位置if name == "jaw":# 用线条连起来for l in range(1, len(pts)):ptA = tuple(pts[l - 1])ptB = tuple(pts[l])cv2.line(overlay, ptA, ptB, colors[i], 2)# 计算凸包else:hull = cv2.convexHull(pts)cv2.drawContours(overlay, [hull], -1, colors[i], -1)# 叠加在原图上,可以指定比例cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)return output
这个函数是计算cv2.convexHull凸包的,也就是下图这个意思。

这个函数cv2.addWeighted是做图像叠加的。
src1, src2:需要融合叠加的两副图像,要求大小和通道数相等
alpha:src1 的权重
beta:src2 的权重
gamma:gamma 修正系数,不需要修正设置为 0
dst:可选参数,输出结果保存的变量,默认值为 None
dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如 RGB 用三个字节表示,则为 24 位),选默认值 None 表示与源图像保持一致。
dst = src1 × alpha + src2 × beta + gamma;上面的式子理解为,结果图像 = 图像 1× 系数 1+图像 2× 系数 2+亮度调节量。
完整代码及效果展示
from collections import OrderedDict
import numpy as np
import argparse
import dlib
import cv2ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,help="path to input image")
args = vars(ap.parse_args())FACIAL_LANDMARKS_68_IDXS = OrderedDict([("mouth", (48, 68)),("right_eyebrow", (17, 22)),("left_eyebrow", (22, 27)),("right_eye", (36, 42)),("left_eye", (42, 48)),("nose", (27, 36)),("jaw", (0, 17))
])FACIAL_LANDMARKS_5_IDXS = OrderedDict([("right_eye", (2, 3)),("left_eye", (0, 1)),("nose", (4))
])def shape_to_np(shape, dtype="int"):# 创建68*2coords = np.zeros((shape.num_parts, 2), dtype=dtype)# 遍历每一个关键点# 得到坐标for i in range(0, shape.num_parts):coords[i] = (shape.part(i).x, shape.part(i).y)return coordsdef visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):# 创建两个copy# overlay and one for the final output imageoverlay = image.copy()output = image.copy()# 设置一些颜色区域if colors is None:colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),(168, 100, 168), (158, 163, 32),(163, 38, 32), (180, 42, 220)]# 遍历每一个区域for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()):# 得到每一个点的坐标(j, k) = FACIAL_LANDMARKS_68_IDXS[name]pts = shape[j:k]# 检查位置if name == "jaw":# 用线条连起来for l in range(1, len(pts)):ptA = tuple(pts[l - 1])ptB = tuple(pts[l])cv2.line(overlay, ptA, ptB, colors[i], 2)# 计算凸包else:hull = cv2.convexHull(pts)cv2.drawContours(overlay, [hull], -1, colors[i], -1)# 叠加在原图上,可以指定比例cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)return output# 加载人脸检测与关键点定位
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])# 读取输入数据,预处理
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
width=500
r = width / float(w)
dim = (width, int(h * r))
image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 人脸检测
rects = detector(gray, 1)# 遍历检测到的框
for (i, rect) in enumerate(rects):# 对人脸框进行关键点定位# 转换成ndarrayshape = predictor(gray, rect)shape = shape_to_np(shape)# 遍历每一个部分for (name, (i, j)) in FACIAL_LANDMARKS_68_IDXS.items():clone = image.copy()cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,0.7, (0, 0, 255), 2) # 根据位置画点for (x, y) in shape[i:j]:cv2.circle(clone, (x, y), 3, (0, 0, 255), -1)# 提取ROI区域(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))roi = image[y:y + h, x:x + w](h, w) = roi.shape[:2]width=250r = width / float(w)dim = (width, int(h * r))roi = cv2.resize(roi, dim, interpolation=cv2.INTER_AREA)# 显示每一部分cv2.imshow("ROI", roi)cv2.imshow("Image", clone)cv2.waitKey(0)# 展示所有区域output = visualize_facial_landmarks(image, shape)cv2.imshow("Image", output)cv2.waitKey(0)


最终将7个人的人脸都依次的检测到了。并且根据关键点定位到了。

如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!
相关文章:
计算机视觉:人脸识别与检测
目录 前言 识别检测方法 本文方法 项目解析 完整代码及效果展示 前言 人脸识别作为一种生物特征识别技术,具有非侵扰性、非接触性、友好性和便捷性等优点。人脸识别通用的流程主要包括人脸检测、人脸裁剪、人脸校正、特征提取和人脸识别。人脸检测是从获取的图…...
【NLP】理解 Llama2:KV 缓存、分组查询注意力、旋转嵌入等
LLaMA 2.0是 Meta AI 的开创性作品,作为首批高性能开源预训练语言模型之一闯入了 AI 场景。值得注意的是,LLaMA-13B 的性能优于巨大的 GPT-3(175B),尽管其尺寸只是其一小部分。您无疑听说过 LLaMA 令人印象深刻的性能,但您是否想知…...
ctyunos 与 openeuler
ctyunos-2.0.1-220311-aarch64-dvd ctyunos-2.0.1-220329-everything-aarch64-dvd glibc python3 对应openEuler 20.03 LTS SP1...

跟着GPT学设计模式之工厂模式
工厂模式(Factory Design Pattern)分为三种更加细分的类型:简单工厂、工厂方法和抽象工厂。在这三种细分的工厂模式中,简单工厂、工厂方法原理比较简单,在实际的项目中也比较常用。而抽象工厂的原理稍微复杂点…...
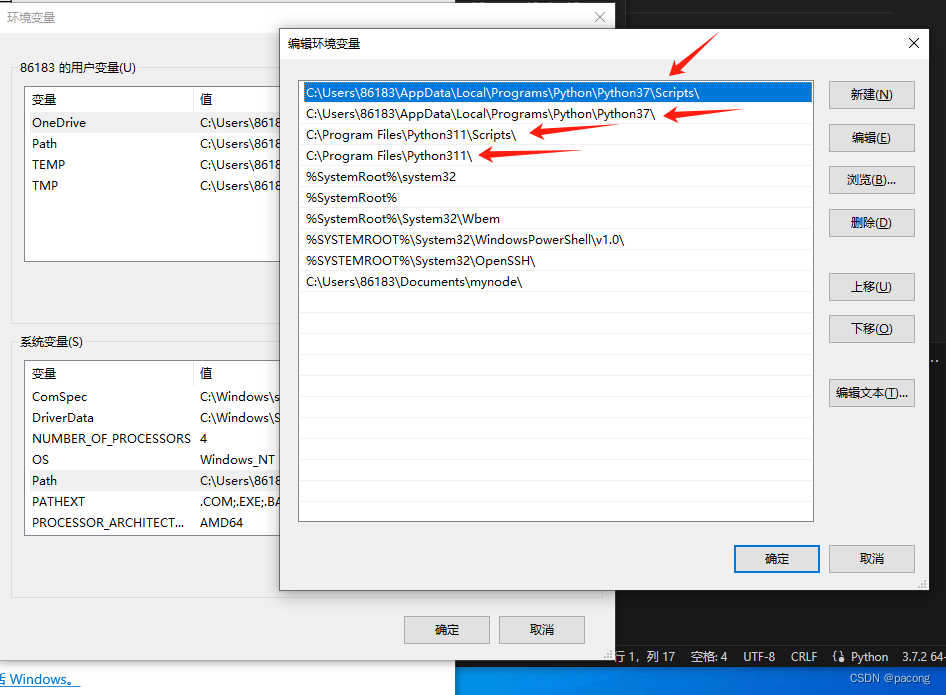
VScode+python开发,多个解释器切换问题
内容:主要VScode使用多个解释器 环境准备 VScode编辑器,两个版本python解释器 python3.7.2 python3.11.6 问题: 目前我们的电脑安装了python3.7.2、python3.11.6两个解释器,在vscode编辑器中,无法切换解释器使用如…...
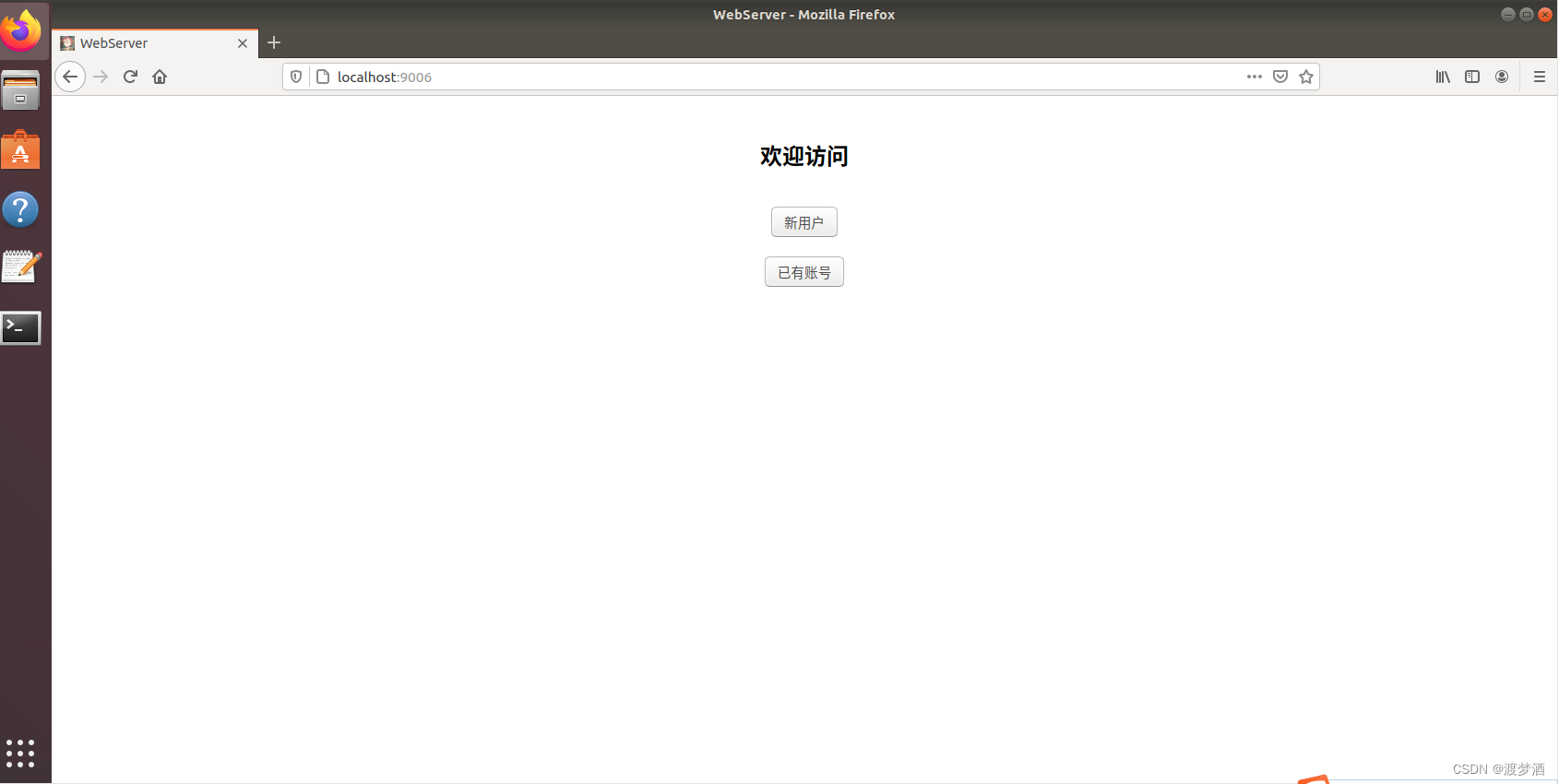
c++ 经典服务器开源项目Tinywebserver如何运行
第一次直接按作者的指示,运行sh ./build.sh,再运行./server,发现不起作用,localhost:9006也是拒绝访问的状态,后来摸索成功了发现,运行./server之后,应该是启动状态,就是不会退出,而…...
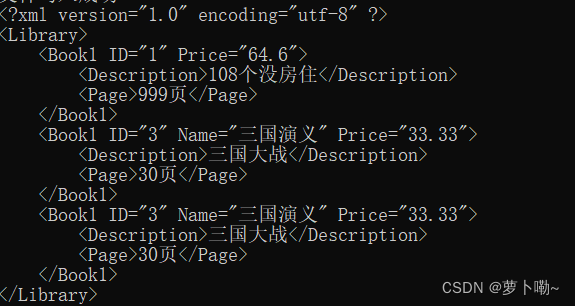
c++之xml的创建,增删改查
c之xml的创建,增删改查 1.创建写入2.添加3.删除4.修改: 1.创建写入 #include <stdio.h> #include <typeinfo> #include "F:/EDGE/tinyxml/tinyxml.h" #include <iostream> #include <string> #include <Winsock2.…...

【前端开发】JS Vue React中的通用递归函数
目录 前言 一、递归函数的由来 二、功能实现 1.后台数据 2.处理数据 3.整体代码 总结 🙂博主:冰海恋雨. 🙂文章核心:【前端开发】JS Vue React中的通用递归函数 前言 大家好,今天和大家分享一下在前端开发中j…...
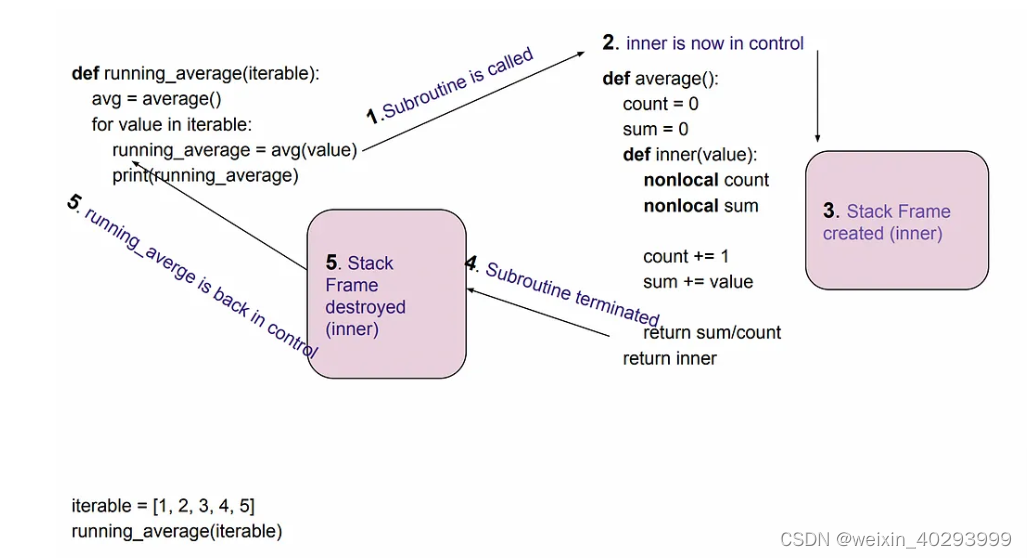
【python 生成器 面试必备】yield关键字,协程必知必会系列文章--自己控制程序调度,体验做上帝的感觉 1
python生成器系列文章目录 第一章 yield — Python (Part I) 文章目录 python生成器系列文章目录前言1. Generator Function 生成器函数2.并发和并行,抢占式和协作式2.Let’s implement Producer/Consumer pattern using subroutine: 生成器的状态 generator’s st…...

头哥实践平台之MapReduce基础实战
一. 第1关:成绩统计 编程要求 使用MapReduce计算班级每个学生的最好成绩,输入文件路径为/user/test/input,请将计算后的结果输出到/user/test/output/目录下。 先写命令行,如下: 一行就是一个命令 touch file01 echo Hello World Bye Wor…...

Linux基础知识——tmux和vim
Linux基础知识——tmux和vim 文章目录 Linux基础知识——tmux和vim一、tmux1. 功能2. 结构3. 操作 二、vim功能模式操作 一、tmux tmux配置:~/.tmux.conf修改为如下 set-option -g status-keys vi setw -g mode-keys visetw -g monitor-activity on# setw -g c0-cha…...
Java Web——TomcatWeb服务器
目录 1. 服务器概述 1.1. 服务器硬件 1.2. 服务器软件 2. Web服务器 2.1. Tomcat服务器 2.2. 简单的Web服务器使用 1. 服务器概述 服务器指的是网络环境下为客户机提供某种服务的专用计算机,服务器安装有网络操作系统和各种服务器的应用系统服务器的具有高速…...
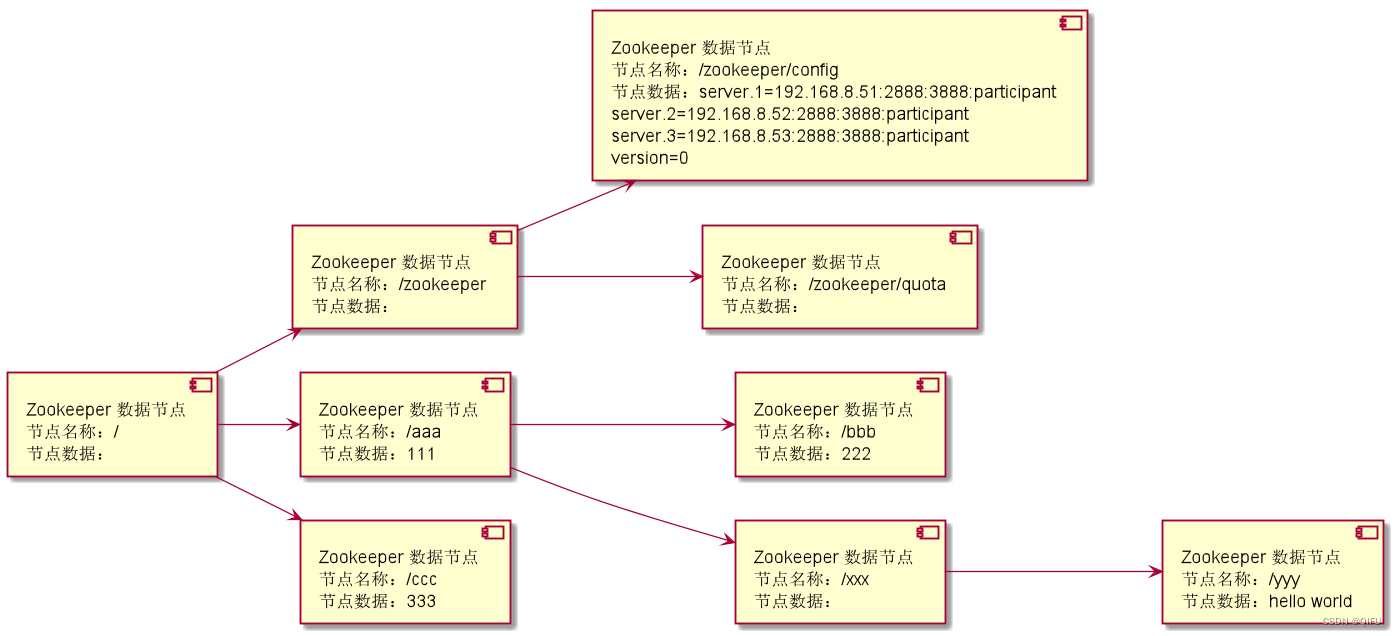
Zookeeper 命令使用和数据说明
文章目录 一、概述二、命令使用2.1 登录 ZooKeeper2.2 ls 命令,查看目录树(节点)2.3 create 命令,创建节点2.4 delete 命令,删除节点2.5 set 命令,设置节点数据2.6 get 命令,获取节点数据 三、数…...

索尼RSV文件怎么恢复为MP4视频
索尼相机RSV是什么文件? 如果您的相机是索尼SONY A7S3,A7M4,FX3,FX3,FX6,或FX9等,有时录像会产生一个RSV文件,而没有MP4视频文件。RSV其实是MP4的前期文件,经我对RSV文件…...
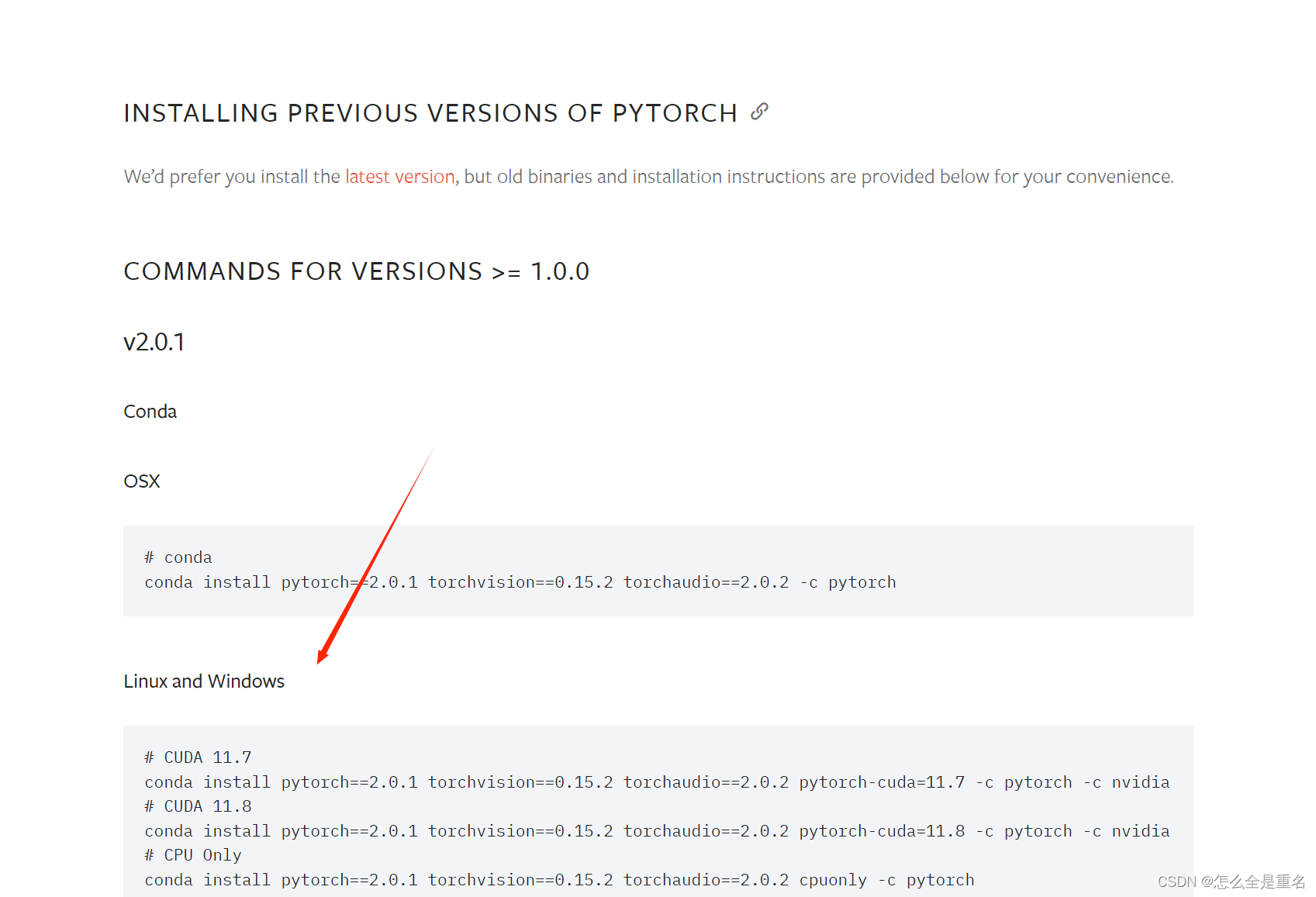
pytorch-gpu(Anaconda3+cuda+cudnn)
文章目录 下载Anaconda3安装,看着点next就行比较懒所以自动添加path测试 cuda安装的时候不能改路径如果出现报错,关闭杀毒软件一直下一步就好取消勾选“CUDA”中的“Visual Studio Intergration”一直下一步即可测试安装成功 cudnn解压后将这三个文件夹复…...
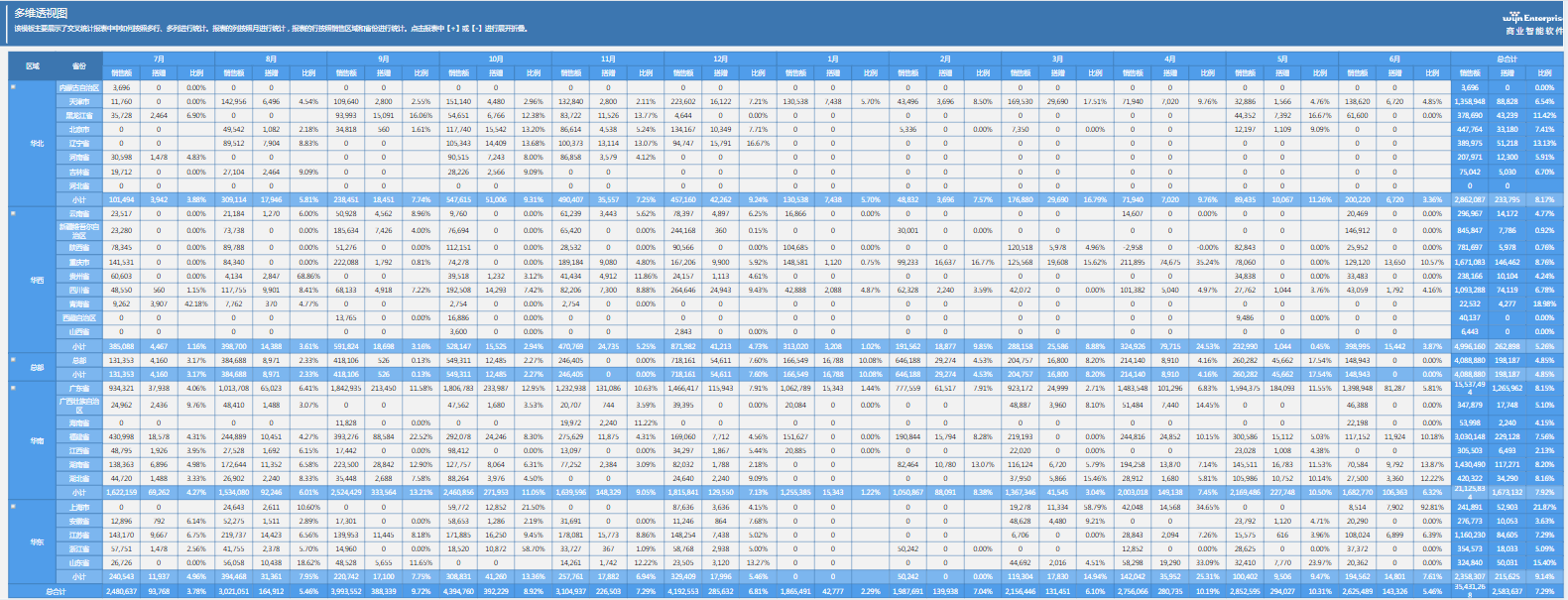
解析数据洁净之道:BI中数据清理对见解的深远影响
本文由葡萄城技术团队发布。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 前言 随着数字化和信息化进程的不断发展,数据已经成为企业的一项不可或缺的重要资源。然而,这…...
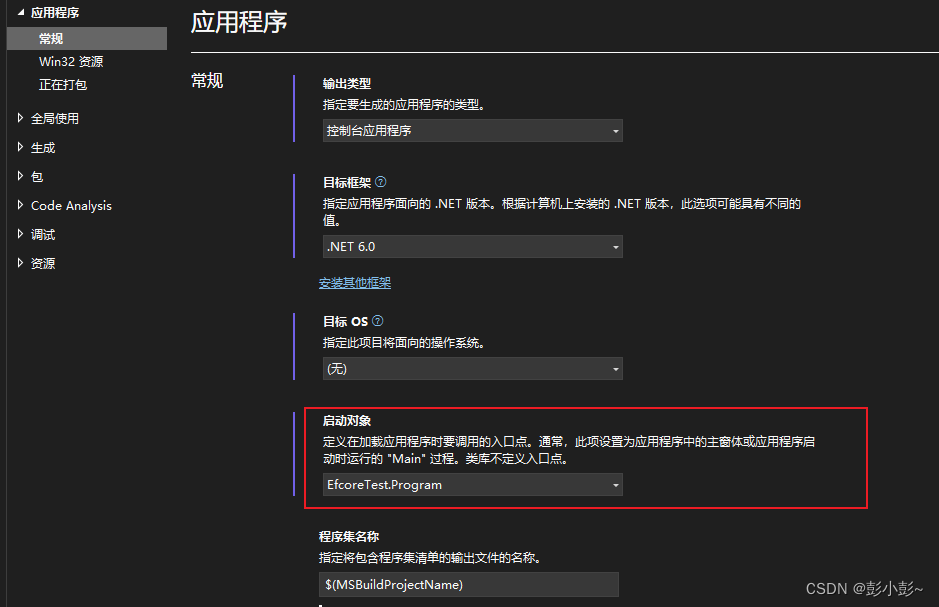
efcore反向共工程,单元测试
1.安装efcore需要的nuget <PackageReference Include"Microsoft.EntityFrameworkCore" Version"6.0.24" /> <PackageReference Include"Microsoft.EntityFrameworkCore.SqlServer" Version"6.0.24" /> <PackageRefere…...

利用IP风险画像强化金融行业网络安全防御
在数字化时代,金融行业日益依赖互联网和技术创新,但这也使得金融机构成为网络攻击的主要目标。为了应对日益复杂的网络威胁,金融机构迫切需要采用先进的安全技术和工具。其中,IP风险画像技术成为提升网络安全的一项重要策略。 1.…...
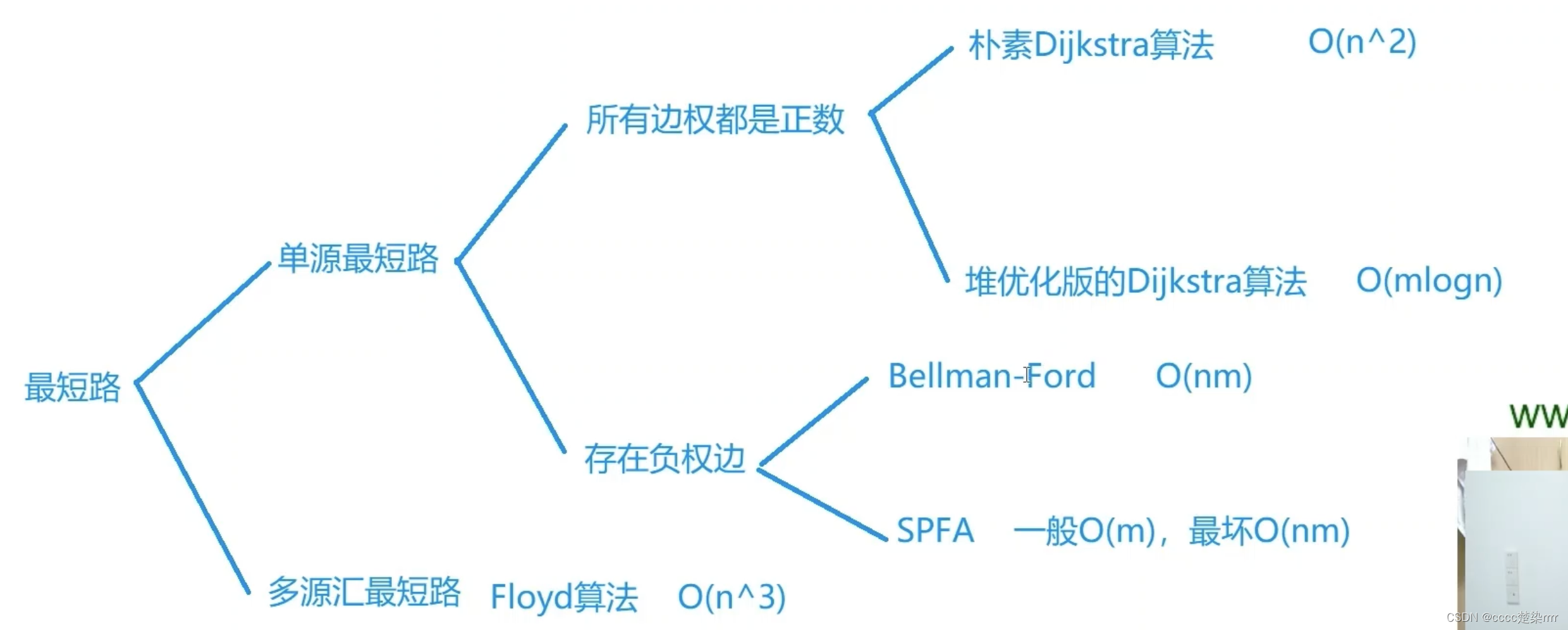
1334. 阈值距离内邻居最少的城市
分析题目两点“阈值距离”、“邻居最少”。 “阈值距离”相当于定了个上界,求节点之间的最短距离。 “邻居最少”相当于能连接的点的数量。 求节点之间的最短距离有以下几种方法: 在这道题当中,n的范围是100以内,所以可以考虑O(n…...

Live800:客服行业的发展历程及未来前景
随着信息技术和互联网的高速发展,客服行业也在不断变革和发展。客服行业是一个服务型的行业,其发展历程也与人们对服务需求的变化密切相关。本文将介绍客服行业的发展历程和未来前景。 客服行业的发展历程 20世纪70年代,客服行业主要以电话服…...

如何用SwiftUI实现macOS自动化点击:技术原理与实战指南
如何用SwiftUI实现macOS自动化点击:技术原理与实战指南 【免费下载链接】macos-auto-clicker A simple auto clicker for macOS Big Sur, Monterey, Ventura, Sonoma and Sequoia. 项目地址: https://gitcode.com/gh_mirrors/ma/macos-auto-clicker macOS自动…...

如何利用APOC插件提升Neo4J的数据处理能力?实战配置指南
如何利用APOC插件释放Neo4J的隐藏潜能?高阶实战手册 当你已经熟练使用Cypher进行常规图数据查询时,是否遇到过这些瓶颈?需要批量处理百万级节点关系却找不到高效方法;想实现复杂图算法但原生函数库不支持;数据导入导出…...

BilibiliDown:突破B站视频离线限制的高效解决方案
BilibiliDown:突破B站视频离线限制的高效解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bi…...

网盘下载速度太慢?8大平台直链解析工具让你告别限速烦恼
网盘下载速度太慢?8大平台直链解析工具让你告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

终极RPG Maker解密工具:零基础快速提取游戏资源完整指南
终极RPG Maker解密工具:零基础快速提取游戏资源完整指南 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp…...

Agentic SOC 全阶成长指南:从零到专家,拿下AI安全运营的黄金赛道
2026年RSAC全球网络安全大会落下帷幕,一个行业共识已经不可逆地形成:Agentic SOC,已经从概念验证阶段,正式成为全球企业安全运营的核心标配。 Gartner最新数据显示,2026年全球Agentic SOC相关市场规模突破127亿美元&am…...

04 月 04 日 AI 每日参考:多厂模型动态频出,产业转向拼用量
今日概览今日 AI 圈迎来多厂模型集中发布,谷歌、微软、阿里等巨头接连推出新模型产品,同时国内 AI 产业规模突破 1.2 万亿元,行业正式从 "拼参数" 转向 "拼用量" 的新阶段。监管层面也同步发力,地方推进 AI 产…...

LTspice2Matlab:如何实现电路仿真数据到MATLAB的无缝迁移终极方案?
LTspice2Matlab:如何实现电路仿真数据到MATLAB的无缝迁移终极方案? 【免费下载链接】ltspice2matlab LTspice2Matlab - Import LTspice data into MATLAB 项目地址: https://gitcode.com/gh_mirrors/lt/ltspice2matlab 电子工程师的数据孤岛困境&…...

Dell G15终极散热控制:tcc-g15开源方案完全指南
Dell G15终极散热控制:tcc-g15开源方案完全指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否厌倦了Dell G15游戏本自带的AWCC软件那臃肿的…...

百度网盘直链解析开源工具完全指南:从入门到精通
百度网盘直链解析开源工具完全指南:从入门到精通 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经历过这样的困扰:明明网络带宽充足ÿ…...