【机器学习基础】机器学习的模型评估(评估方法及性能度量原理及主要公式)
🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~
💡往期推荐:
【机器学习基础】机器学习入门(1)
【机器学习基础】机器学习入门(2)
【机器学习基础】机器学习的基本术语
💡本期内容:上一篇文章介绍了机器学习的基本术语,离完成学习又近了一步!这篇文章在正式开始算法模型的介绍之前,先说一下机器学习的模型评估,主要包括研究问题、相关文献综述、主要理论公式和案例解释。快来学习吧!!!
文章目录
- 1 引言
- 2 相关文献综述
- 3 模型评估主要理论、评估方法及性能度量
- 3.1 模型评估的引出及思考
- 3.2 学习器真的如我们想要的一样吗
- 3.3 评估方法
- 3.3.1 留出法(Holdout Method)
- 3.3.2 交叉验证法 (Cross-Validation Method)
- 3.3.3 自助法 (Bootstrap Method)
- 3.4 性能度量
- 3.4.1查准率、查全率与F1
- 3.4.2 P-R曲线
- 3.4.3 ROC与AUC
- 3.4.4 代价敏感错误率与代价矩阵
1 引言
机器学习模型评估是机器学习领域中的一个重要研究方向,其研究背景在于随着大数据时代的到来,人们面临着越来越多的数据分析和处理任务,而机器学习作为一种高效的数据处理技术,在很多领域都得到了广泛应用。然而,机器学习模型的效果评估是机器学习应用过程中一个非常关键的问题,因此机器学习模型评估的研究具有非常重要的意义。
- 研究问题:
机器学习模型评估的研究问题主要包括:如何选择合适的评估指标、如何确定评估的实验设计、如何利用评估结果对模型进行优化等。此外,由于机器学习模型的复杂性和多样性,评估方法的选择和设计也是需要解决的重要问题。
- 研究意义:
机器学习模型评估的研究意义在于:
- 提高模型的预测精度和泛化能力;
- 帮助我们更好地理解模型的内部机制和性能;
- 为模型优化和改进提供依据;
- 应用于实际问题的解决,提高生产力和效率。
2 相关文献综述
- 机器学习模型评估概述:
机器学习模型评估是对模型性能进行量化和优化的过程。评估不仅涉及对模型在训练集上的性能考察,还包括在测试集上的表现评估。训练集用于训练模型,测试集则用于验证模型在新数据上的泛化能力。此外,为了充分了解模型的性能,还常常采用交叉验证等技术进行评估。
- 模型评估的性能度量指标:
性能度量指标是评估机器学习模型性能的关键工具。常用的性能度量指标包括准确率、精确率、召回率、F1分数、ROC AUC面积等。这些指标可用于二分类、多分类和回归等不同类型的机器学习问题。
准确率表示预测正确的样本数占总样本数的比例,精确率和召回率则分别表示预测为正且确实为正的样本数以及预测为负且确实为负的样本数所占的比例。
F1分数是精确率和召回率的调和平均数,用于综合考虑二者的性能。
ROC、AUC面积则是一种常用的分类性能指标,它表示在所有可能的分类阈值下模型的ROC曲线与y=x线之间的面积。

- 主要模型评估方法:
主要的模型评估方法包括内部评估和外部评估。
内部评估主要基于训练集和测试集进行,如准确率、精确率、召回率和F1分数等。
外部评估则通过比较模型与其他基准模型的性能来进行评估,如ROC AUC面积和交叉验证等。此外,为了充分了解模型的性能,还常常采用交叉验证等技术进行评估。
- 现有研究不足与问题:
尽管已经有很多关于机器学习模型评估的研究,但仍存在一些不足和问题。首先,不同的评估指标可能导致评估结果的差异和误解,因此需要谨慎选择合适的指标。其次,由于数据的复杂性和模型的多样性,现有评估方法可能无法全面反映模型的性能,因此需要开发更加鲁棒和泛化的评估方法。
此外,现有研究还缺乏对不同模型评估方法的比较和分析,因此需要进行更加深入的研究以找出最佳的评估策略。
3 模型评估主要理论、评估方法及性能度量
3.1 模型评估的引出及思考
- 精度与错误率
我们通常将分类错误的样本数占总样本数的比例称为“错误率”,也即当在m个样本中有α个样本分类错误时,错误率E等于α除以m。相应地,1减去错误率就是精度,也即“精度=1-错误率”。更一般地,我们将学习器的实际预测输出与样本的真实输出之间的差异称为“误差”。
- 训练误差和泛化误差——我要得到什么?
我们还可以将学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称为“泛化误差”。显然,我们希望得到泛化误差小的学习器。然而,由于我们事先并不知道新样本是什么样的,所以实际上我们只能尽力使经验误差最小化。
- 精度越大越好?
在很多情况下,我们可以学习到经验误差很小、在训练集上表现很好的学习器。
例如,甚至可以对所有训练样本都分类正确,也即分类错误率为零,分类精度为100%。然而,这样的学习器是否是我们想要的呢?遗憾的是,这样的学习器在多数情况下都不理想。
3.2 学习器真的如我们想要的一样吗
我们实际希望的,是在新样本上能表现得很好的学习器。为了实现这一目标,我们应该从训练样本中学习出适用于所有潜在样本的普遍规律,以便在遇到新样本时能够做出正确的判断。
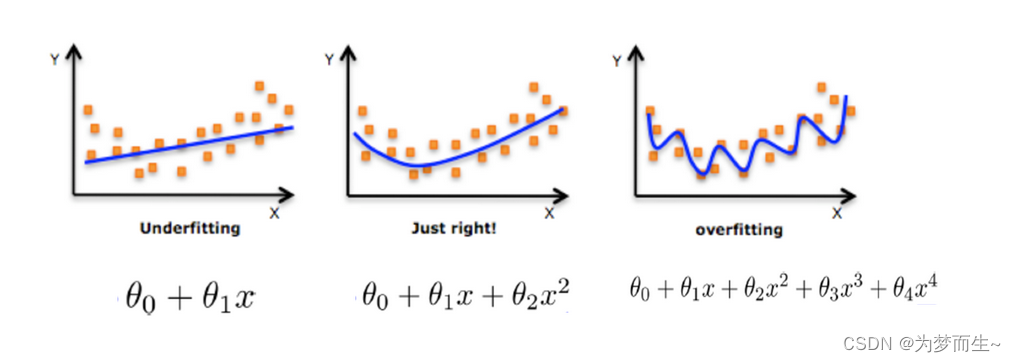
- 过拟合与欠拟合
然而,当学习器过于适应训练样本时,它可能会将训练样本自身的某些特点视为所有潜在样本都具有的一般性质,从而导致泛化性能下降。这种现象在机器学习中称为“过拟合”。与之相对的是“欠拟合”,这意味着学习器尚未完全掌握训练样本的一般性质。

如果出现过拟合与欠拟合,需要使用正则化等方法来进行挽救,具体方法后面会讲到。
然而必须认识到,过拟合是无法彻底避免的,我们所能做的只是"缓解"或者说减小其风险。关于这一点,可大致这样理解:机器学习面临的问题通常是 NP 难甚至更难,而有效的学习算法必然是在多项式时间内运行完 ,若可彻底避免过拟合, 则通过经验误差最小化就能获最优解,这就意味着我们构造性地证明了“P=NP” ;因此,只要相信 "P≠NP”,过拟合就不可避免。
- 如何选择?
在现实任务中,我们往往有多种学习算法供选择,甚至对同一个学习算法,当使用不同的参数配置 ?也会产生不同的模型那么,我们该选用哪个学习算法、使用哪种参数配置呢?这就是机器学习中的"模型选择" (model selection) 问题。
理想的解决方案当然是对候选模型的泛化误差进行评估,然后选择泛化误差最小的那个模型。
然而如上面所讨论的,我们无法直接获得泛化误差,而训练误差又由于过拟合现象的存在而不适合作为标准,那么,在现实中如何进行模型评估与选择呢?
3.3 评估方法
测试样本为什么要尽可能不出现在训练集中呢?
为理解这一点,不妨考虑这样一个场景:老师出了10道习题供同学们练习,考试时老师又用同样的这10道题作为试题,这个考试成绩能否有效反映出同学们学得好不好呢?答案是否定的,可能有的同学只会做这10道题却能得高分。
希望得到泛化性能强的模型,好比是希望同学们对课程学得很好、获得了对所学知识“举一反三”的能力;训练样本相当于给同学们练习的习题,测试过程则相当于考试.显然,若测试样本被用作训练了,则得到的将是过于“乐观”的估计结果.
3.3.1 留出法(Holdout Method)
‘留出法’ 直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T即D=S∪T,S∩T≠∅. 在S上训练出模型后,用T来评估其测试误差,作为泛化误差的估计需要注意的是,训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响,在分类任务中要保持样本类别比例相似,取样通常采用的是【分层抽样】

- 主要步骤:
- 将原始数据集分成两个部分:训练集和测试集。通常,训练集用于训练模型,测试集用于评估模型。
- 使用训练集训练模型。
- 使用测试集评估模型,计算模型的各项性能指标,如准确率、精确率、召回率等。
- 根据测试集的评估结果,对模型进行调整和优化。
- 重复步骤b-d,直到模型性能达到满意的水平。
3.3.2 交叉验证法 (Cross-Validation Method)
Cross Validation:简言之,就是进行多次train_test_split划分;
每次划分时,在不同的数据集上进行训练、测试评估,从而得出一个评价结果;如果是5折交叉验证,意思就是在原始数据集上,进行5次划分,每次划分进行一次训练、评估,最后得到5次划分后的评估结果,一般在这几次评估结果上取平均得到最后的评分。k-fold cross-validation ,其中,k一般取5或10。
- 交叉验证的优点:
-
原始采用的train_test_split方法,数据划分具有偶然性;交叉验证通过多次划分,大大降低了这种由一次随机划分带来的偶然性,同时通过多次划分,多次训练,模型也能遇到各种各样的数据,从而提高其泛化能力;
-
与原始的train_test_split相比,对数据的使用效率更高。train_test_split,默认训练集、测试集比例为3:1,而对交叉验证来说,如果是5折交叉验证,训练集比测试集为4:1;10折交叉验证训练集比测试集为9:1。数据量越大,模型准确率越高!

- 交叉验证法的主要步骤:
- 将原始数据集分成k个部分,其中k-1个部分作为训练集,剩余的部分作为测试集。
- 使用k-1个部分训练模型。
- 使用剩余的部分测试模型,计算模型的各项性能指标。
- 重复步骤b-c,直到每个部分都被用作测试集一次。
- 对所有的测试结果进行平均,得到模型的最终性能指标。
- 根据最终性能指标,对模型进行调整和优化。
- 重复步骤b-f,直到模型性能达到满意的水平。
3.3.3 自助法 (Bootstrap Method)
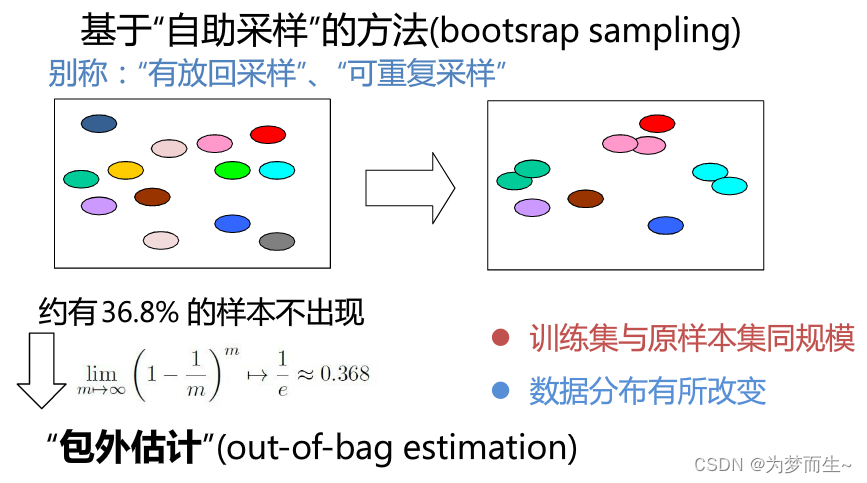
自助法是一种常用的模型评估方法,它通过从原始数据集中有放回地随机抽取样本来构建新数据集进行训练和测试。由于每次抽样可能会产生重复的样本,因此新数据集的大小与原始数据集相同,但是其中大约有36.8%的样本没有出现在新数据集中。这些没有出现在新数据集中的样本被用作测试集,而出现在新数据集中的样本则被用作训练集。
自助法的优点是能够从有限的数据集中产生多个不同的训练集和测试集,从而更好地评估模型的性能。但是,由于每次抽样都会产生不同的数据集,因此自助法会引入额外的随机性,使得模型评估的结果更加不稳定。
- 自助法的步骤:
- 从原始数据集中随机选择n个样本构成一个新的数据集。
- 使用新的数据集训练模型。
- 使用原始数据集测试模型,计算模型的各项性能指标。
- 重复步骤a-c多次(如1000次),得到每个性能指标的平均值和标准偏差。
- 根据平均值和标准偏差,对模型进行调整和优化。
- 重复步骤a-e,直到模型性能达到满意的水平。
3.4 性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量(performance measure).
常用的性能度量包括准确度、灵敏度、特异性、精确度、召回率、F度量和G均值等。不同的性能度量会导致不同的评估结果。其中,准确度是指分类正确的样本数占总样本数的比例;灵敏度是指真实为正例的样本中被正确预测为正例的比例;特异性是指真实为负例的样本中被正确预测为负例的比例;精确度是指被正确预测为正例的样本数占所有预测为正例的样本数的比例;召回率是指真实为正例的样本中被正确预测为正例的比例;F度量是精确度和召回率的加权调和平均数;G均值是灵敏度和特异性的乘积的平方根。
3.4.1查准率、查全率与F1
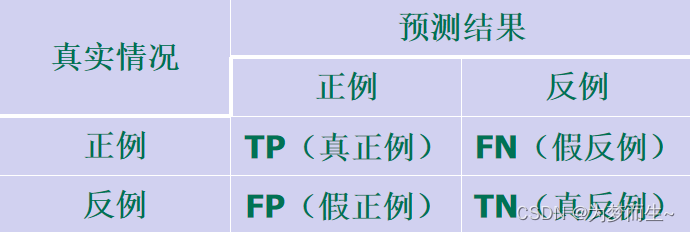
- 查准率(Precision):是指预测结果中真正例(True Positive,TP)占所有预测结果中正例(Positive,TP+FP)的比例。公式为:Precision = TP / (TP + FP)。查准率越高,说明模型预测结果中真正例的比例越高,模型对于正样本的识别能力越强。
- 查全率(Recall):是指预测结果中真正例(True Positive,TP)占所有实际正例(Positive,TP+FN)的比例。公式为:Recall = TP / (TP + FN)。查全率越高,说明模型能够成功预测出的正样本比例越高,模型的识别能力越全面。
- F1值:是查准率和查全率的调和均值,用于综合评价模型的性能。公式为:F1 = 2 * (Precision * Recall) / (Precision + Recall)。F1值越高,说明模型在准确性和可靠性方面的表现都较好。


3.4.2 P-R曲线
查准率和查全率是一对矛盾的度量.一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
在很多情形下,我们可根据学习器的预测结果对样例进行排序,排在前面的是学习器认为“最可能”是正例的样本,排在最后的则是学习器认为“最不可能”是正例的样本。
按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查全率、查准率。
以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称“P-R曲线”,显示该曲线的图称为“P-R图”.

3.4.3 ROC与AUC
ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)常被用来评价一个二值分类器(binary classifier)的优劣。ROC曲线也称为受试者工作特征曲线(receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。
- ROC曲线:它通过将真正例率(True Positive Rate,TPR)和假正例率(False Positive Rate,FPR)作为横纵坐标来描绘分类器在不同阈值下的性能。
与P-R曲线相似,根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图,就得到了ROC曲线,与P-R曲线使用查准率、查全率为纵、横轴不同,ROC曲线的纵轴是真正例率TPR,横轴是假正例率FPR

AUC:AUC是ROC曲线下的面积,常用于评估模型在二分类问题中的性能。
进行学习器的比较时,与P-R 图相似若一个学习器的 ROC 曲线被另个学习器的曲线完全“包住”,则可断言后者的性能优于前者; 若两个学习器的 ROC 曲线发生交叉则难以一般性地断言两者孰优敦劣.此时如果一定要进行比较.则较为合理的判据是比较 ROC 曲线下的面积即AUC(Area Under ROC Curve)


3.4.4 代价敏感错误率与代价矩阵
在现实任务中常会遇到这样的情况: 不同类型的错误所造成的后果不同。例如在医疗诊断中,错误地把患者诊断为健康人与错误地把健康人诊断为患者看起来都是犯了“一次错误”,但后者的影响是增加了进一步检查的麻烦,前者的后果却可能是丧失了拯救生命的最佳时机:再如门禁系统错误地把可通行人员拦在门外,将使得用户体验不佳,但错误地把陌生人放进门内,则会造成严重的安全事故.为权衡不同类型错误所造成的不同损失可为错误赋予“非均等代价”(unequal cost)。

costij表示将第i类样本预测为第j类样本的代价。
假设将第0类作为正类,第1类作为反类,令D+为正例集,D-为负例集。“代价敏感”(cost-sensitive)错误率为:
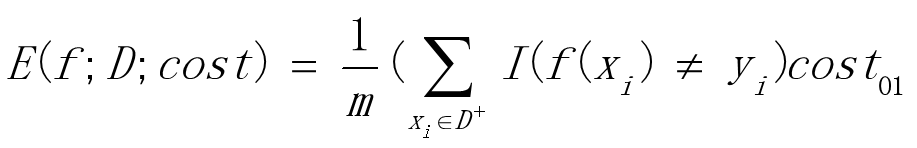
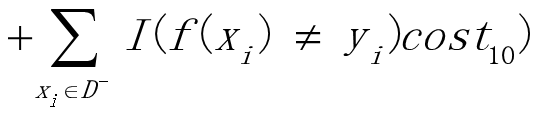

代价曲线画法:
- 设ROC曲线上点的坐标为(FPR,TPR),则可计算出相应的FNR=1-TPR
- 在代价平面上绘制一条从(0, FPR)到(1, FNR)的线段,线段下的面积即表示了该条件下的期望总体代价;
- 如此将ROC曲线上的每个点转化为代价平面上的一条线段,然后去所有线段的下界,围成的面积即为在所有条件下学习期的总体代价。

注:部分内容与图片来自《机器学习》——周志华
相关文章:
【机器学习基础】机器学习的模型评估(评估方法及性能度量原理及主要公式)
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ 💡往期推荐: 【机器学习基础】机器学习入门(1) 【机器学习基…...
:useState)
React hooks(一):useState
1.React hooks React hooks是React16.8的新特性,可以让React函数组件具有状态,并提供类似componentDidMount和componentDidUpdate等生命周期方法。 React 早期版本,类组件可以在shouldComponentUpdate中,通过判断props和state是…...
springboot集成swagger3+解决页面无法访问问题
引入依赖 pom文件引入swagger3依赖 <dependency><groupId>io.springfox</groupId><artifactId>springfox-boot-starter</artifactId><version>3.0.0</version></dependency>配置启动文件 swagger使用ant_pattern_parser解析…...

mapreduce-maven--30.串联所有单词的字串
项目对象模型(Project Object Model,POM):Maven使用POM文件来描述项目的结构、依赖和构建设置。POM是一个XML文件,位于项目根目录下,并包含项目的基本信息、构建设置、依赖管理等。 依赖管理:M…...
)
Hive使用max case when over partition by 实现单个窗口取两个窗口的值(单个开窗函数,实际取两个窗口)
一、Hive开窗函数根据特定条件取上一条最接近时间的数据(单个开窗函数,实际取两个窗口) 针对于就诊业务,一次就诊,多个处方,处方结算时间可能不一致,然后会有多个AI助手推荐用药,会…...
2023年【北京市安全员-B证】试题及解析及北京市安全员-B证证考试
题库来源:安全生产模拟考试一点通公众号小程序 北京市安全员-B证试题及解析根据新北京市安全员-B证考试大纲要求,安全生产模拟考试一点通将北京市安全员-B证模拟考试试题进行汇编,组成一套北京市安全员-B证全真模拟考试试题,学员…...

二维码智慧门牌管理系统升级解决方案:流量监控引领服务卓越
文章目录 前言一、流量监控功能概述二、流量监控的益处三、应用案例和成功故事四、实施和支持 前言 随着科技的不断发展,二维码智慧门牌管理系统在其便捷高效的管理方式下,深受广大用户喜爱。为了更好地满足用户需求,提升服务质量࿰…...
)
Linux内核面试题(1)
整理了一些网上的linux驱动岗位相关面试题,如果错误,欢迎指正。 1硬件中断号和Linux内核的IRQ号它们是如何映射的? irq驱动会从dts获取硬件中断号,dts里的interrupts字段,使用gic_irq_domain_translate函数。 然后使…...

wpr -start generalprofile -start pool -filemode 这句命令具体是什么意思
注意事项: 总体而言,WPR 和 WPA 是强大的性能分析工具,通过它们,你可以深入了解系统运行时的性能特性,找出潜在问题并进行优化。 查看详细信息: wpr -start generalprofile -start pool -filemode 对应的结…...

C/CPP基础练习题多维数组,矩阵转置,杨辉三角详解
多维数组 1. 矩阵转置 输入一个数字构成的矩形, 将矩形的值进行转置后打印 输入: 第一行 正整数n(1<n<10), 表示矩阵的边长 随后输入一个矩阵 输出: 转置后的矩阵 样例输入: 3 1 2 3 4 5 6 7 8 9 样例输出: 1 4 7 2 5 8 3 6 9 2. 颈椎病治疗 最近云海学长一…...
父组件用ref获取子组件数据
子组件 Son/index.vue 子组件的数据和方法一定要记得用defineExpose暴露,不然父组件用ref是获取不到的!!! <script setup> import { ref } from "vue"; const sonNum ref(1); const changeSon () > {sonNum.…...

Haskell添加HTTP爬虫ip编写的爬虫程序
下面是一个简单的使用Haskell编写的爬虫程序示例,它使用了HTTP爬虫IP,以爬取百度图片。请注意,这个程序只是一个基本的示例,实际的爬虫程序可能需要处理更多的细节,例如错误处理、数据清洗等。 import Network.HTTP.Cl…...
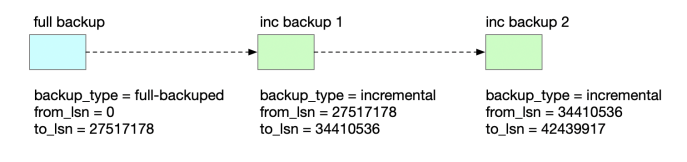
MySQL 社区开源备份工具 Xtrabackup 详解
文章目录 前言1. Xtrabackup 介绍1.1 物理备份与逻辑备份区别1.2 Xtrabackup 系列版本 2. Xtrabackup 部署2.1 下载安装包2.2 二进制部署2.3 程序文件介绍2.4 备份需要的权限 3. Xtrabackup 使用场景3.1 本地全量备份3.2 本地压缩备份3.3 全量流式备份3.3.1 备份到远程主机3.3.…...
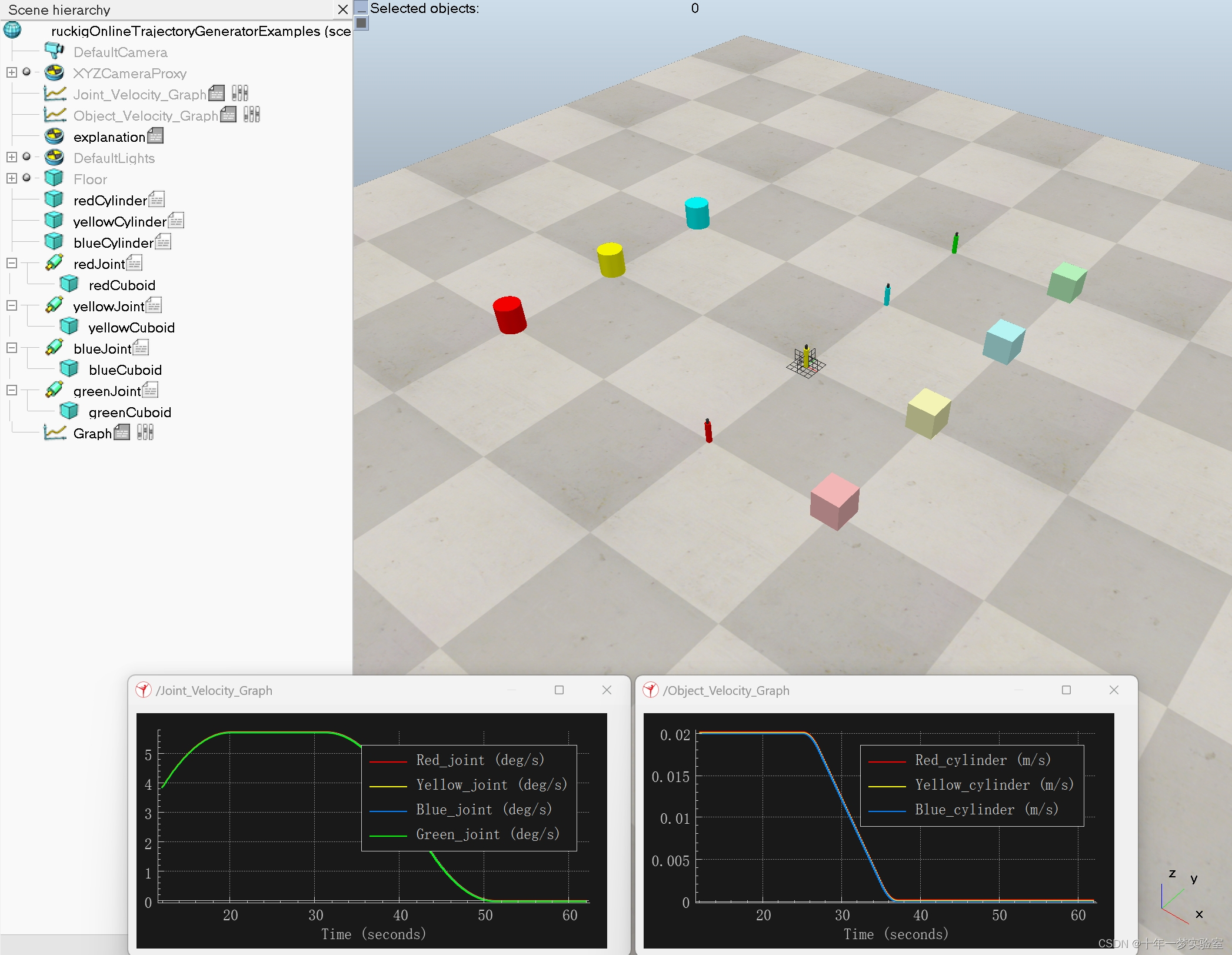
【仿真】ruckig在线轨迹生成器示例
该场景说明了使用 CoppeliaSim 中提供的 Ruckig 在线轨迹生成功能的各种方法: 1. 在线程脚本内使用单个阻塞函数(红色) 2. 在线程脚本中使用多个非阻塞函数(黄色) 3. 在非线程脚本中使用多个非阻塞函数(…...

LeetCode 面试题 16.22. 兰顿蚂蚁
文章目录 一、题目二、C# 题解 一、题目 一只蚂蚁坐在由白色和黑色方格构成的无限网格上。开始时,网格全白,蚂蚁面向右侧。每行走一步,蚂蚁执行以下操作。 (1) 如果在白色方格上,则翻转方格的颜色,向右(顺时针)转 90 度…...
Docker安装详细步骤及相关环境安装配置(mysql、jdk、redis、自己的私有仓库Gitlab 、C和C++环境以及Nginx服务代理)
目录 一、从空白系统中克隆Centos7系统 二、使用xshell连接docker_tigerhhzz虚拟机编辑 三、在CentOS7基础上安装Docker容器 四、在Docker中进行安装Portainer 4.1、在Docker中安装MySQL 4.2、在Docker中安装JDK8,安装Java环境 4.3、Docker安装redis&#…...
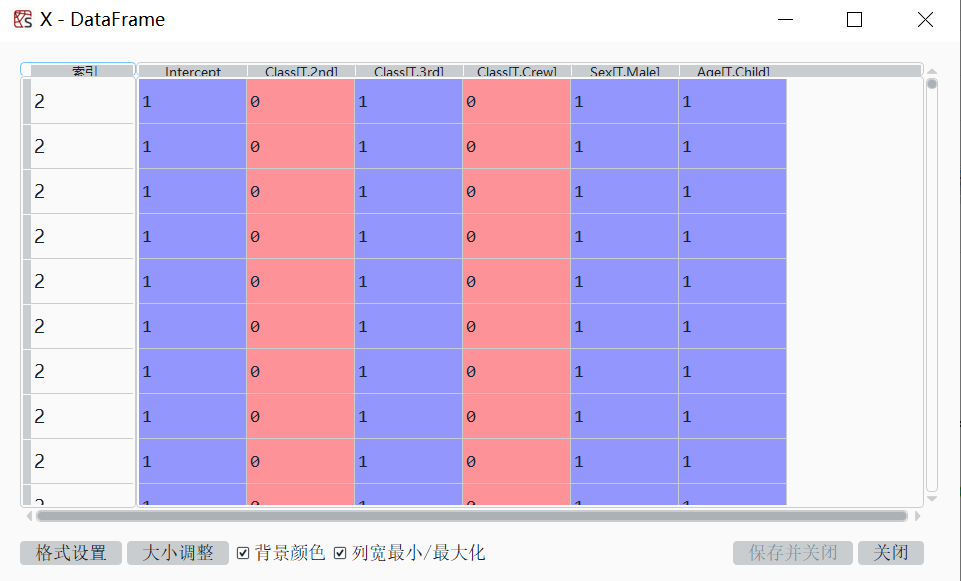
科研学习|研究方法——Python计量Logit模型
一、离散选择模型 莎士比亚曾经说过:To be, or not to be, that is the question,这就是典型的离散选择模型。如果被解释变量时离散的,而非连续的,称为“离散选择模型”。例如,消费者在购买汽车的时候通常会比较几个不…...

灵活运用Vue指令:探究v-if和v-for的使用技巧和注意事项
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 ⭐ 专栏简介 📘 文章引言 一、作…...

nvidia-docker部署pytorch服务【GPU工作站】
文章目录 一、安装 Docker二、安装 NVIDIA Container Toolkit三、宿主机安装 cuda 和 nvidia-driver四、测试一、安装 Docker 可以参考这篇文章 https://blog.csdn.net/weixin_43721000/article/details/124237932 二、安装 NVIDIA Container Toolkit 参考nvidia官方 https:/…...
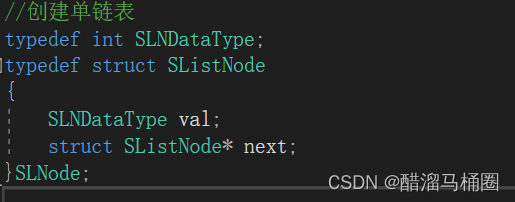
单链表的实现
CSDN主页:醋溜马桶圈_C语言进阶,初始C语言,数据结构-CSDN博客 Gitee主页:mnxcc (mnxcc) - Gitee.com 专栏:数据结构_醋溜马桶圈的博客-CSDN博客 目录 1.认识单链表 2.创建单链表 3.单链表的操作 3.1打印单链表 3.2开辟新空间 3.3尾插 3.4头插…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...

基于IRS2092的200W D类功放设计:从PWM原理到保护电路实战
1. 项目概述与核心思路折腾音响功放,从经典的AB类玩到D类,感觉就像是从燃油车换到了电动车,动力响应和效率完全是两个维度。这次要聊的这块“200W Class-D Audio Power Amplifier [150115]”单板功放,就是一个非常典型的D类功放设…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...

国产麒麟系统上编译GDAL 3.2.1踩坑记:从PROJ6依赖缺失到Qt环境集成
麒麟系统GDAL 3.2.1编译实战:PROJ6依赖修复与Qt工程深度集成在国产操作系统生态中部署地理数据处理工具链,往往会遇到比常规Linux发行版更复杂的依赖问题。最近在麒麟系统上为北斗定位项目编译GDAL 3.2.1时,遭遇了经典的"PROJ 6 symbols…...