pandas教程:GroupBy Mechanics 分组机制
文章目录
- Chapter 10 Data Aggregation and Group Operations(数据汇总和组操作)
- 10.1 GroupBy Mechanics(分组机制)
- 1 Iterating Over Groups(对组进行迭代)
- 2 Selecting a Column or Subset of Columns (选中一列,或列的子集)
- 3 Grouping with Dicts and Series(用Dicts与Series进行分组)
- 4 Grouping with Functions(用函数进行分组)
- 5 Grouping by Index Levels (按索引层级来分组)
Chapter 10 Data Aggregation and Group Operations(数据汇总和组操作)
这一章的内容:
- 把一个
pandas对象(series或DataFrame)按key分解为多个 - 计算组的汇总统计值(
group summary statistics),比如计数,平均值,标准差,或用户自己定义的函数 - 应用组内的转换或其他一些操作,比如标准化,线性回归,排序,子集选择
- 计算透视表和交叉列表
- 进行分位数分析和其他一些统计组分析
10.1 GroupBy Mechanics(分组机制)
Hadley Wickham,是很多R语言有名库的作者,他描述group operation(组操作)为split-apply-combine(分割-应用-结合)。第一个阶段,存储于series或DataFrame中的数据,根据不同的keys会被split(分割)为多个组。而且分割的操作是在一个特定的axis(轴)上。例如,DataFrame能按行(axis=0)或列(axis=1)来分组。之后,我们可以把函数apply(应用)在每一个组上,产生一个新的值。最后,所以函数产生的结果被combine(结合)为一个结果对象(result object)。下面是一个图示:
每一个用于分组的key能有很多形式,而且keys也不必都是一种类型:
- 含有值的
list或array的长度,与按axis分组后的长度是一样的 - 值的名字指明的是
DataFrame中的列名 - 一个
dict或Series,给出一个对应关系,用于对应按轴分组后的值与组的名字 - 能在
axis index(轴索引)上被调用的函数,或index上的labels(标签)
注意后面三种方法都是用于产生一个数组的快捷方式,而这个数组责备用来分割对象(split up the object)。不用担心这些很抽象,这一章会有很多例子来帮助我们理解这些方法。先从一个例子来开始吧,这里有一个用DataFrame表示的表格型数据集:
import numpy as np
import pandas as pd
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],'key2' : ['one', 'two', 'one', 'two', 'one'], 'data1' : np.random.randn(5), 'data2' : np.random.randn(5)})
df
| data1 | data2 | key1 | key2 | |
|---|---|---|---|---|
| 0 | 1.364533 | 0.633262 | a | one |
| 1 | 1.353368 | 0.361008 | a | two |
| 2 | 0.253311 | -1.107940 | b | one |
| 3 | -1.513444 | -1.038035 | b | two |
| 4 | -0.920317 | 2.037712 | a | one |
假设我们想要,通过使用key1作为labels,来计算data1列的平均值。有很多方法可以做到这点,一种是访问data1,并且使用列(a series)在key1上,调用groupby。(译者:其实就是按key1来进行分组,但只保留data1这一列):
grouped = df['data1'].groupby(df['key1'])
grouped
<pandas.core.groupby.SeriesGroupBy object at 0x111db3710>
这个grouped变量是一个GroupBy object(分组对象)。实际上现在还没有进行任何计算,除了调用group key(分组键)df['key1']时产生的一些中间数据。整个方法是这样的,这个GroupBy object(分组对象)已经有了我们想要的信息,现在需要的是对于每一个group(组)进行一些操作。例如,通过调用GroupBy的mean方法,我们可以计算每个组的平均值:
grouped.mean()
key1
a 0.599194
b -0.630067
Name: data1, dtype: float64
之后我们会对于调用.mean()后究竟发生了什么进行更详细的解释。重要的是,我们通过group key(分组键)对数据(a series)进行了聚合,这产生了一个新的Series,而且这个series的索引是key1列中不同的值。
得到的结果中,index(索引)也有’key1’,因为我们使用了df['key1']。
如果我们传入多个数组作为一个list,那么我们会得到不同的东西:
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means
key1 key2
a one 0.222108two 1.353368
b one 0.253311two -1.513444
Name: data1, dtype: float64
这里我们用了两个key来分组,得到的结果series现在有一个多层级索引,这个多层索引是根据key1和key2不同的值来构建的:
means.unstack()
| key2 | one | two |
|---|---|---|
| key1 | ||
| a | 0.222108 | 1.353368 |
| b | 0.253311 | -1.513444 |
在上面的例子里,group key全都是series,即DataFrame中的一列,当然,group key只要长度正确,可以是任意的数组:
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states, years]).mean()
California 2005 1.3533682006 0.253311
Ohio 2005 -0.0744562006 -0.920317
Name: data1, dtype: float64
df['data1'].groupby([states, years])
<pandas.core.groupby.SeriesGroupBy object at 0x112530e48>
df['data1']
0 1.364533
1 1.353368
2 0.253311
3 -1.513444
4 -0.920317
Name: data1, dtype: float64
df
| data1 | data2 | key1 | key2 | |
|---|---|---|---|---|
| 0 | 1.364533 | 0.633262 | a | one |
| 1 | 1.353368 | 0.361008 | a | two |
| 2 | 0.253311 | -1.107940 | b | one |
| 3 | -1.513444 | -1.038035 | b | two |
| 4 | -0.920317 | 2.037712 | a | one |
其中分组信息经常就在我们处理的DataFrame中,在这种情况下,我们可以传入列名(可以是字符串,数字,或其他python对象)作为group keys:
df.groupby('key1').mean()
| data1 | data2 | |
|---|---|---|
| key1 | ||
| a | 0.599194 | 1.010661 |
| b | -0.630067 | -1.072987 |
df.groupby(['key1', 'key2']).mean()
| data1 | data2 | ||
|---|---|---|---|
| key1 | key2 | ||
| a | one | 0.222108 | 1.335487 |
| two | 1.353368 | 0.361008 | |
| b | one | 0.253311 | -1.107940 |
| two | -1.513444 | -1.038035 |
我们注意到第一个例子里,df.groupby('key1').mean()的结果里并没有key2这一列。因为df['key2']这一列不是数值型数据,我们称这种列为nuisance column(有碍列),这种列不会出现在结果中。默认,所有的数值型列都会被汇总计算,但是出现有碍列的情况的话,就会过滤掉这种列。
一个很有用的GroupBy方法是size,会返回一个包含group size(组大小)的series:
df.groupby(['key1', 'key2']).size()
key1 key2
a one 2two 1
b one 1two 1
dtype: int64
另外一点需要注意的是,如果作为group key的列中有缺失值的话,也不会出现在结果中。
1 Iterating Over Groups(对组进行迭代)
GroupBy对象支持迭代,能产生一个2-tuple(二元元组),包含组名和对应的数据块。考虑下面的情况:
for name, group in df.groupby('key1'):print(name)print(group)
adata1 data2 key1 key2
0 1.364533 0.633262 a one
1 1.353368 0.361008 a two
4 -0.920317 2.037712 a one
bdata1 data2 key1 key2
2 0.253311 -1.107940 b one
3 -1.513444 -1.038035 b two
对于有多个key的情况,元组中的第一个元素会被作为另一个元组的key值
for (k1, k2), group in df.groupby(['key1', 'key2']):print((k1, k2))print(group)
('a', 'one')data1 data2 key1 key2
0 1.364533 0.633262 a one
4 -0.920317 2.037712 a one
('a', 'two')data1 data2 key1 key2
1 1.353368 0.361008 a two
('b', 'one')data1 data2 key1 key2
2 0.253311 -1.10794 b one
('b', 'two')data1 data2 key1 key2
3 -1.513444 -1.038035 b two
当然,也可以对数据的一部分进行各种操作。一个便利的用法是,用一个含有数据片段(data pieces)的dict来作为单行指令(one-liner):
pieces = dict(list(df.groupby('key1')))
pieces
{'a': data1 data2 key1 key20 1.364533 0.633262 a one1 1.353368 0.361008 a two4 -0.920317 2.037712 a one, 'b': data1 data2 key1 key22 0.253311 -1.107940 b one3 -1.513444 -1.038035 b two}
pieces['b']
| data1 | data2 | key1 | key2 | |
|---|---|---|---|---|
| 2 | 0.253311 | -1.107940 | b | one |
| 3 | -1.513444 | -1.038035 | b | two |
groupby默认作用于axis=0,但是我们可以指定任意的轴。例如,我们可以按dtype来对列进行分组:
df.dtypes
data1 float64
data2 float64
key1 object
key2 object
dtype: object
grouped = df.groupby(df.dtypes, axis=1)
for dtype, group in grouped:print(dtype)print(group)
float64data1 data2
0 1.364533 0.633262
1 1.353368 0.361008
2 0.253311 -1.107940
3 -1.513444 -1.038035
4 -0.920317 2.037712
objectkey1 key2
0 a one
1 a two
2 b one
3 b two
4 a one
2 Selecting a Column or Subset of Columns (选中一列,或列的子集)
如果一个GroupBy对象是由DataFrame创建来的,那么通过列名或一个包含列名的数组来对GroupBy对象进行索引的话,就相当于对列取子集做聚合(column subsetting for aggregation)。这句话的意思是:
df.groupby('key1')['data1']
df.groupby('key1')[['data2']]
上面的代码其实就是下面的语法糖(Syntactic sugar):
df['data1'].groupby(df['key1'])
df[['data2']].groupby(df['key1'])
语法糖(Syntactic sugar),是由Peter J. Landin(和图灵一样的天才人物,是他最先发现了Lambda演算,由此而创立了函数式编程)创造的一个词语,它意指那些没有给计算机语言添加新功能,而只是对人类来说更“甜蜜”的语法。语法糖往往给程序员提供了更实用的编码方式,有益于更好的编码风格,更易读。不过其并没有给语言添加什么新东西。
尤其是对于一些很大的数据集,这种用法可以聚集一部分列。例如,在处理一个数据集的时候,想要只计算data2列的平均值,并将结果返还为一个DataFrame,我们可以这样写:
df
| data1 | data2 | key1 | key2 | |
|---|---|---|---|---|
| 0 | 1.364533 | 0.633262 | a | one |
| 1 | 1.353368 | 0.361008 | a | two |
| 2 | 0.253311 | -1.107940 | b | one |
| 3 | -1.513444 | -1.038035 | b | two |
| 4 | -0.920317 | 2.037712 | a | one |
df.groupby(['key1', 'key2'])[['data2']].mean()
| data2 | ||
|---|---|---|
| key1 | key2 | |
| a | one | 1.335487 |
| two | 0.361008 | |
| b | one | -1.107940 |
| two | -1.038035 |
如果一个list或一个数组被传入,返回的对象是一个分组后的DataFrame,如果传入的只是单独一个列名,那么返回的是一个分组后的grouped:
s_grouped = df.groupby(['key1', 'key2'])['data2']
s_grouped
<pandas.core.groupby.SeriesGroupBy object at 0x1125309e8>
s_grouped.mean()
key1 key2
a one 1.335487two 0.361008
b one -1.107940two -1.038035
Name: data2, dtype: float64
3 Grouping with Dicts and Series(用Dicts与Series进行分组)
分组信息可以不是数组的形式。考虑下面的例子:
people = pd.DataFrame(np.random.randn(5, 5),columns=['a', 'b', 'c', 'd', 'e'],index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])people.iloc[2:3, [1, 2]] = np.nan # Add a few NA values
people
| a | b | c | d | e | |
|---|---|---|---|---|---|
| Joe | 1.358054 | -0.124378 | 0.159913 | -0.006129 | -1.116065 |
| Steve | 0.926572 | -0.281652 | -0.586583 | -0.266538 | -0.216959 |
| Wes | 0.277803 | NaN | NaN | 0.820144 | -0.002076 |
| Jim | 1.623214 | 0.109414 | 2.967603 | 0.075661 | 1.085864 |
| Travis | -0.578750 | 1.252605 | 0.757412 | 0.352343 | -1.342396 |
假设我们有一个组,对应多个列,而且我们想要按组把这些列的和计算出来:
mapping = {'a': 'red', 'b': 'red', 'c': 'blue','d': 'blue', 'e': 'red', 'f': 'orange'}
现在,我们可以通过这个dict构建一个数组,然后传递给groupby,但其实我们可以直接传入dict(可以注意到key里有一个'f',这说明即使有,没有被用到的group key,也是ok的):
by_column = people.groupby(mapping, axis=1)
by_column.sum()
| blue | red | |
|---|---|---|
| Joe | 0.153784 | 0.117611 |
| Steve | -0.853121 | 0.427961 |
| Wes | 0.820144 | 0.275727 |
| Jim | 3.043264 | 2.818492 |
| Travis | 1.109754 | -0.668541 |
这种用法同样适用于series,这种情况可以看作是固定大小的映射(fixed-size mapping):
map_series = pd.Series(mapping)
map_series
a red
b red
c blue
d blue
e red
f orange
dtype: object
people.groupby(map_series, axis=1).count()
| blue | red | |
|---|---|---|
| Joe | 2 | 3 |
| Steve | 2 | 3 |
| Wes | 1 | 2 |
| Jim | 2 | 3 |
| Travis | 2 | 3 |
4 Grouping with Functions(用函数进行分组)
比起用dict或series定义映射关系,使用python的函数是更通用的方法。任何一个作为group key的函数,在每一个index value(索引值)上都会被调用一次,函数计算的结果在返回的结果中会被用做group name。更具体一点,考虑前一个部分的DataFrame,用人的名字作为索引值。假设我们想要按照名字的长度来分组;同时我们要计算字符串的长度,使用len函数会变得非常简单:
people.groupby(len).sum() # len函数在每一个index(即名字)上被调用了
| a | b | c | d | e | |
|---|---|---|---|---|---|
| 3 | 3.259071 | -0.014964 | 3.127516 | 0.889676 | -0.032277 |
| 5 | 0.926572 | -0.281652 | -0.586583 | -0.266538 | -0.216959 |
| 6 | -0.578750 | 1.252605 | 0.757412 | 0.352343 | -1.342396 |
混合不同的函数、数组,字典或series都不成问题,因为所有对象都会被转换为数组:
key_list = ['one', 'one', 'one', 'two', 'two']
people.groupby([len, key_list]).min()
| a | b | c | d | e | ||
|---|---|---|---|---|---|---|
| 3 | one | 0.277803 | -0.124378 | 0.159913 | -0.006129 | -1.116065 |
| two | 1.623214 | 0.109414 | 2.967603 | 0.075661 | 1.085864 | |
| 5 | one | 0.926572 | -0.281652 | -0.586583 | -0.266538 | -0.216959 |
| 6 | two | -0.578750 | 1.252605 | 0.757412 | 0.352343 | -1.342396 |
5 Grouping by Index Levels (按索引层级来分组)
最后关于多层级索引数据集(hierarchically indexed dataset),一个很方便的用时是在聚集(aggregate)的时候,使用轴索引的层级(One of the levels of an axis index)。看下面的例子:
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'], [1, 3, 5, 1, 3]], names=['cty', 'tenor'])
columns
MultiIndex(levels=[['JP', 'US'], [1, 3, 5]],labels=[[1, 1, 1, 0, 0], [0, 1, 2, 0, 1]],names=['cty', 'tenor'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df
| cty | US | JP | |||
|---|---|---|---|---|---|
| tenor | 1 | 3 | 5 | 1 | 3 |
| 0 | -0.898073 | 0.156686 | -0.151011 | 0.423881 | 0.336215 |
| 1 | 0.736301 | 0.901515 | 0.081655 | 0.450248 | -0.031245 |
| 2 | -1.619125 | -1.041775 | 0.129422 | 1.222881 | -0.717410 |
| 3 | 0.998536 | -1.373455 | 1.724266 | -2.084529 | 0.535651 |
要想按层级分组,传入层级的数字或者名字,通过使用level关键字:
hier_df.groupby(level='cty', axis=1).count()
| cty | JP | US |
|---|---|---|
| 0 | 2 | 3 |
| 1 | 2 | 3 |
| 2 | 2 | 3 |
| 3 | 2 | 3 |
相关文章:

pandas教程:GroupBy Mechanics 分组机制
文章目录 Chapter 10 Data Aggregation and Group Operations(数据汇总和组操作)10.1 GroupBy Mechanics(分组机制)1 Iterating Over Groups(对组进行迭代)2 Selecting a Column or Subset of Columns (选中…...
通过右键用WebStorm、Idea打开某个文件夹或者在某一文件夹下右键打开当前文件夹用上述两个应用
通过右键用WebStorm、Idea打开某个文件夹或者在某一文件夹下右键打开当前文件夹用上述两个应用 通过右键点击某个文件夹用Idea打开 首先打开注册表 win R 输入 regedit 然后找到HKEY_CLASSES_ROOT\Directory\shell 然后右键shell 新建一个项名字就叫 Idea 第一步…...

Android 10.0 framework层设置后台运行app进程最大数功能实现
1. 前言 在10.0的定制开发中,在系统中,对于后台运行的app过多的时候,会比较耗内存,导致系统运行有可能会卡顿,所以在系统优化的 过程中,会限制后台app进程运行的数量,来保证系统流畅不影响体验,所以需要分析下系统中关于限制app进程的相关源码来实现 功能 2.framewo…...
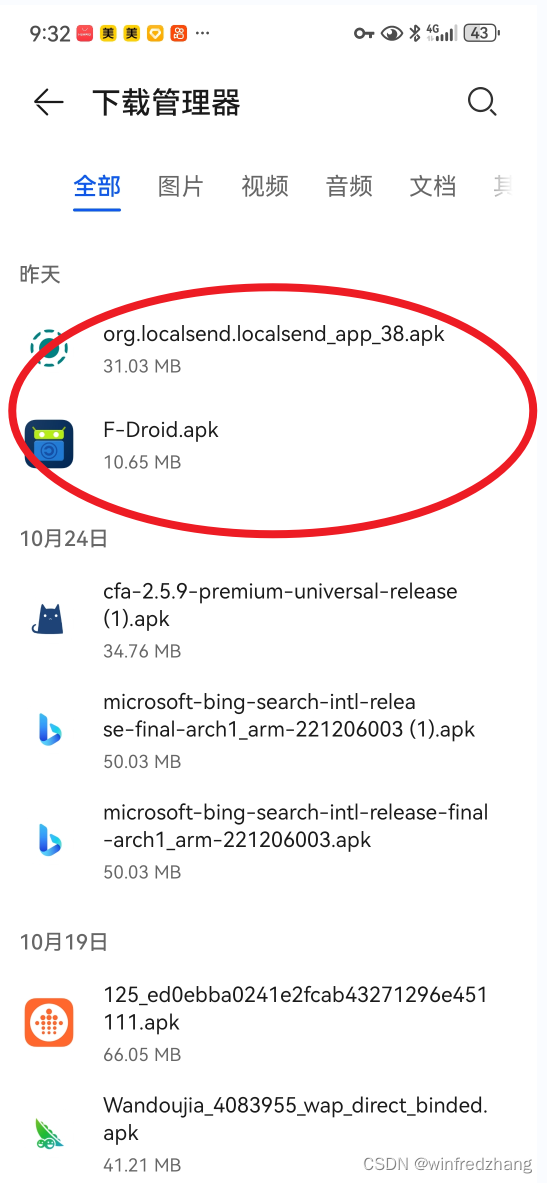
如何快速找到华为手机中下载的文档
手机的目录设置比较繁杂,尤其是查找刚刚下载的文件,有时候需要捣鼓半天,如何快速找到这些文件呢?以下提供了几种方法: 方法一: 文件管理-》搜索文档 方法二: 文件管理-》最近 方法三…...
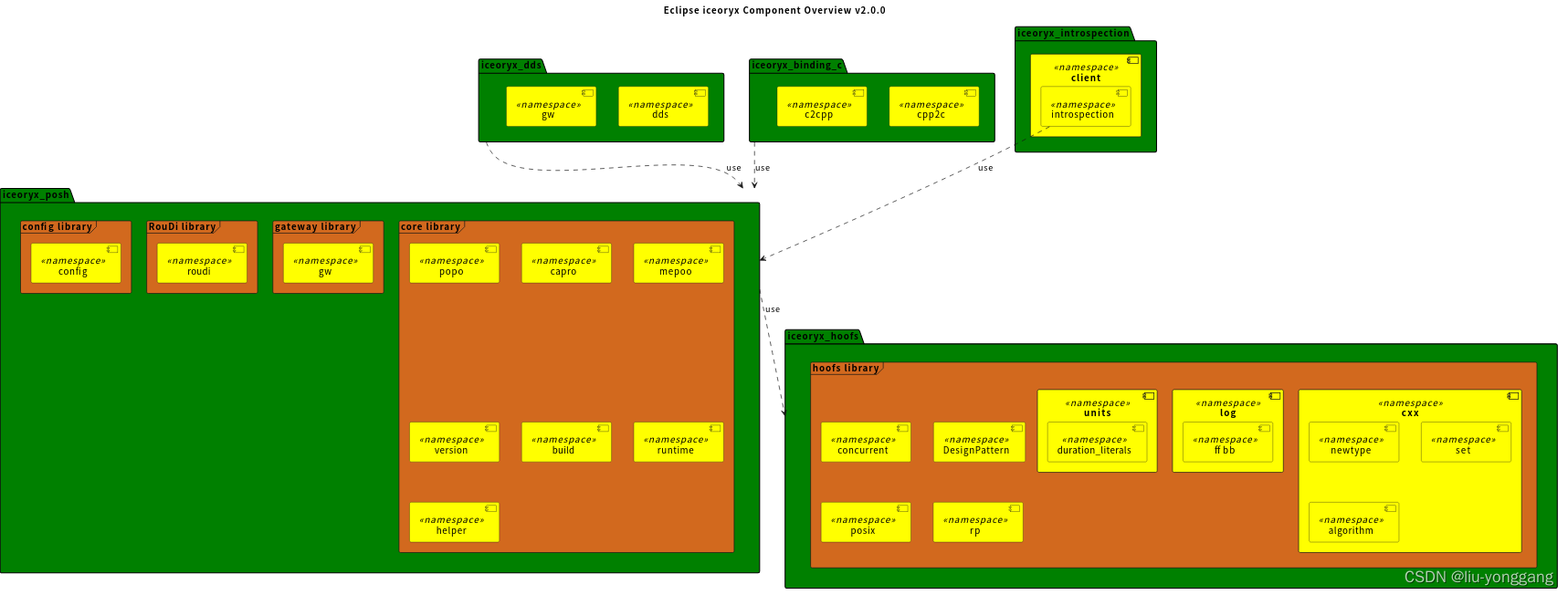
iceoryx(冰羚)-Architecture
Architecture 本文概述了Eclipseiceoryx体系结构,并解释了它的基本原理。 Software layers Eclipse iceoryx所包含的主要包如下所示。 接下来的部分将逐一简要介绍组件及其库。 Components and libraries 下面描述了不同的库及其名称空间。 ### iceoryx hoofs …...
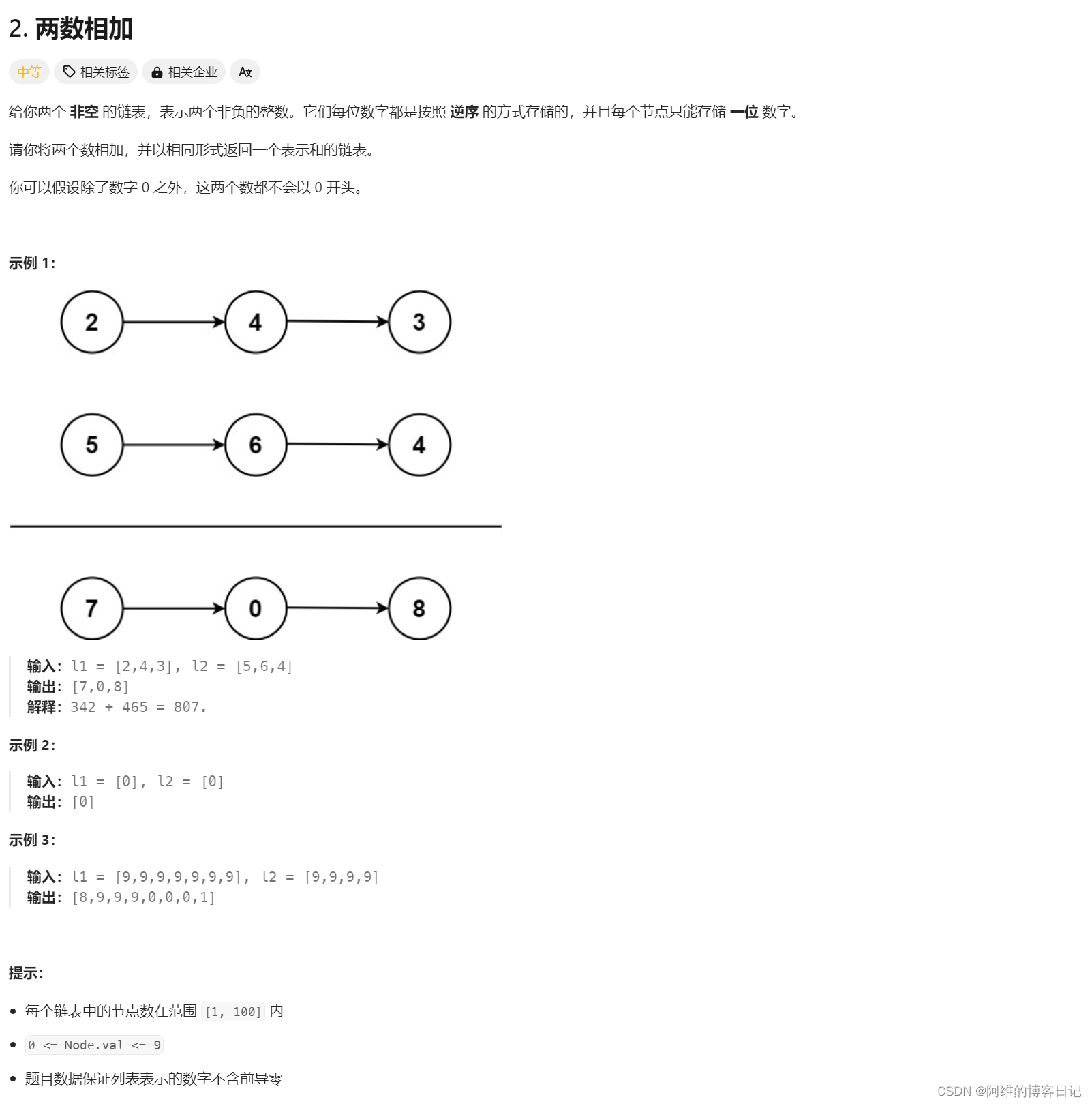
LeetCode2-两数相加
大佬解法 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(int x) { val x; }* }*/ class Solution {public ListNode addTwoNumbers(ListNode l1, ListNode l2) {ListNode pre new ListNode(0);ListNo…...

css 灰质彩色的边框
border: 4px solid transparent; background-color:#fff; background-clip: padding-box,border-box; background-origin:padding-box, border-box; background-image: linear-gradient(90deg,#F5F6FA,#F5F6FA 42%,#F5F6FA),linear-gradient(151deg,#33e9bf,#c7e58a,#b1e8cc);...
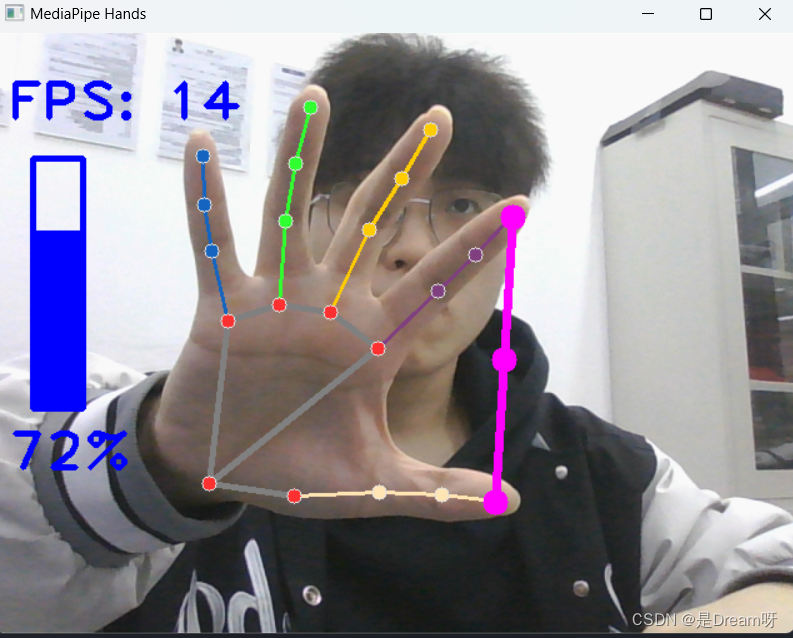
OpenCV实现手势音量控制
前言: Hello大家好,我是Dream。 今天来学习一下如何使用OpenCV实现手势音量控制,欢迎大家一起前来探讨学习~ 一、需要的库及功能介绍 本次实验需要使用OpenCV和mediapipe库进行手势识别,并利用手势距离控制电脑音量。 导入库&am…...

pytorch 深度学习之余弦相似度
文章目录 用处定理代码F.normalize() 和 F.norm() 的区别 用处 此方法特别重要,经常可以用来修改论文,提出创新点. 定理 余弦相似度是通过计算两个向量之间的夹角余弦值来衡量它们的相似性。给定两个非零向量 x 和 y,它们之间的余弦相似度…...
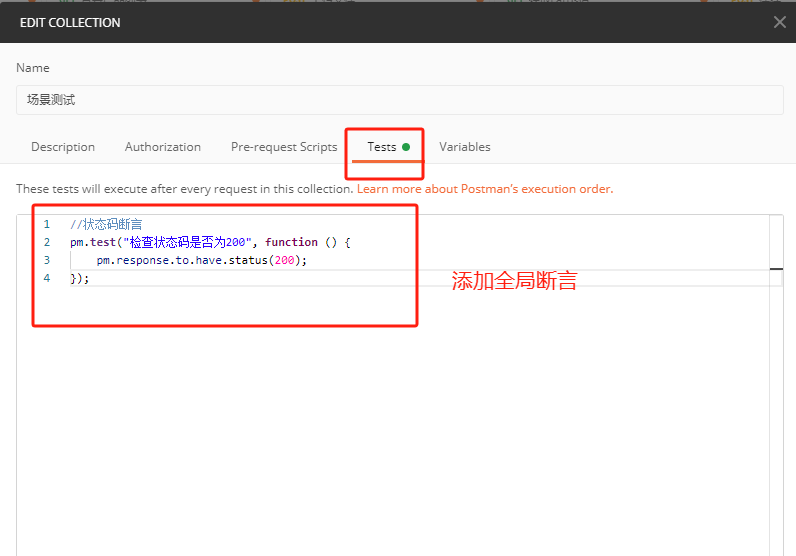
Postman的常规断言/动态参数断言/全局断言
近期在复习Postman的基础知识,在小破站上跟着百里老师系统复习了一遍,也做了一些笔记,希望可以给大家一点点启发。 断言,包括状态码断言和业务断言,状态码断言有一个,业务断言有多个。 一)常规的…...
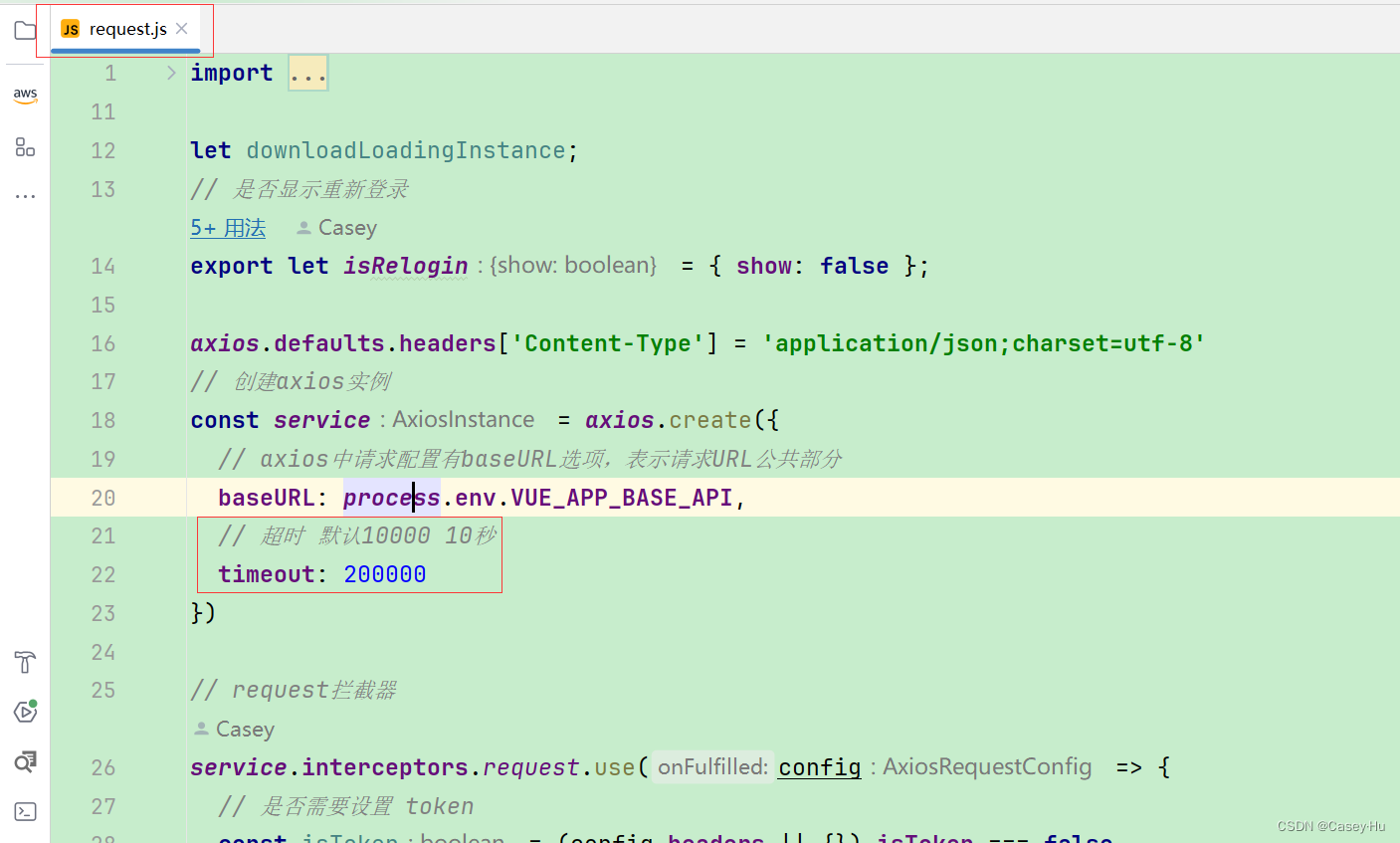
ruoyi若依前端请求接口超时,增加响应时长
问题: 前端查询请求超时 解决: 找到request.js的timeout属性由10秒改成了20秒,因为默认是10秒,请求肯定是超出了10秒 祝您万事顺心,没事点个赞呗,关注一下也行啊,有啥要求您评论哈...
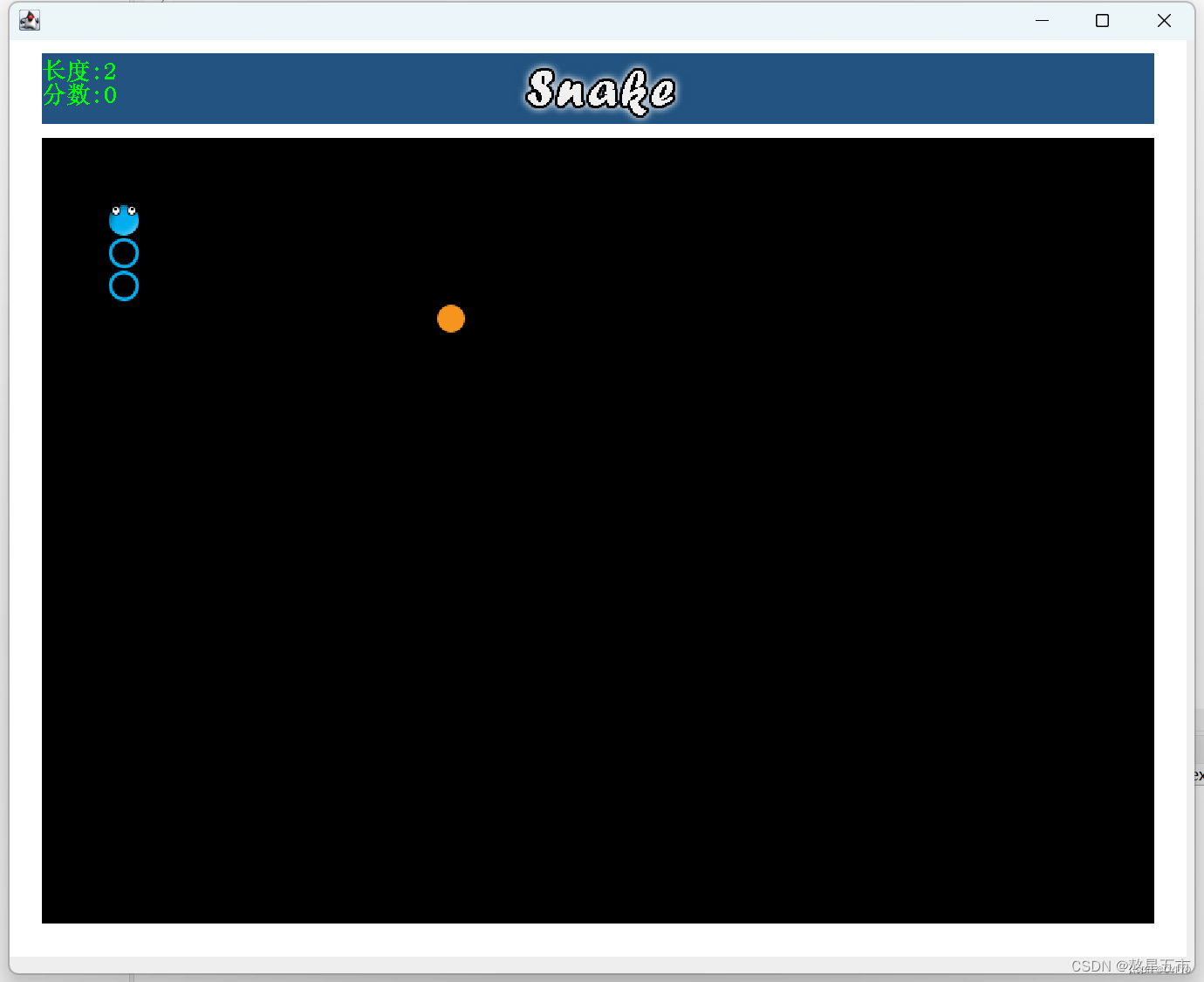
贪吃蛇小游戏
一. 准备工作 首先获取贪吃蛇小游戏所需要的头部、身体、食物以及贪吃蛇标题等图片。、 然后,创建贪吃蛇游戏的Java项目命名为snake_game,并在这个项目里创建一个文件夹命名为images,将图片素材导入文件夹。 再在src文件下创建两个包&#…...

cocos----1
1 前言 刚体(Rigidbody)是运动学(Kinematic)中的一个概念,指在运动中和受力作用后,形状和大小不变,而且内部各点的相对位置不变的物体。在 Unity3D 中,刚体组件赋予了游戏对…...

第十九章绘图
Java绘图类 Graphics 类 Grapics 类是所有图形上下文的抽象基类,它允许应用程序在组件以及闭屏图像上进行绘制。Graphics 类封装了Java 支持的基本绘图操作所需的状态信息,主要包括颜色、字体、画笔、文本、图像等。 Graphics 类提供了绘图常用的…...
rpmbuild 包名 version 操作系统信息部分来源 /etc/rpm/macros.dist
/etc/rpm/macros.dist openeuler bclinux src.rpm openssl-1.1.1f-13.oe1.src.rpm 打包名称结果 openeuler openssl-1.1.1f-13.aarch64.rpm bclinux openssl-1.1.1f-13.oe1.bclinux.aarch64.rpm 验证 修改openeuler配置文件macros.dist 重新在openeuler上执行rpmbuild…...
【Linux专题】SFTP 用户配置 ChrootDirectory
【赠送】IT技术视频教程,白拿不谢!思科、华为、红帽、数据库、云计算等等https://xmws-it.blog.csdn.net/article/details/117297837?spm1001.2014.3001.5502 红帽认证 认证课程介绍:红帽RHCE9.0学什么内容,新版有什么变化-CSDN…...
)
openssl+ DES开发实例(Linux)
文章目录 一、DES介绍二、DES原理三、DES C实现源码 一、DES介绍 DES(Data Encryption Standard)是一种对称密钥加密算法,最初由 IBM 设计,于1977年成为美国国家标准,用于加密非机密但敏感的政府数据。DES 使用相同的…...

结构体几种实用的用法
结构体的初始化 结构体的初始化是指在声明结构体变量时,为其成员变量赋初值。结构体的初始化可以通过以下几种方式实现: 1. 在声明结构体变量的同时进行初始化: struct Student { char name[20]; int age; float score; } student {…...
—— TurboModules JSI通信机制)
React Native 源码分析(四)—— TurboModules JSI通信机制
本文会详细分析React Native 基于JSI的通信方式,除不会涉及Hemers引擎部分,其余代码都会详细分析,但比较简单的,不会很啰嗦,可以说是网上最完整详细的分析文章,代码通过断点截图,可以更方便查看运行的过程 1、React Native 源码分析(一)—— 启动流程 2、React Nativ…...
 格式化数值)
【C#学习】ToString() 格式化数值
格式字符串采用以下形式:Axx,其中 A 为格式说明符,指定格式化类型,xx 为精度说明符,控制格式化输出的有效位数或小数位数。 格式说明符 说明 示例 输出 C 货币 2.5.ToString(“C”) ¥2.50 D 十进制数 25.…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...