JDK1.8 新特性(二)【Stream 流】
前言
上节我们学了 lambda 表达式,很快我就在 Flink 的学习中用到了,我学的是 Java 版本的 Flink,一开始会以为代码会很复杂,但事实上 Flink 中很多地方都用到了 函数接口,这也让我们在编写 Flink 程序的时候可以使用 lambda 表达式非常地简洁地实现匿名函数。
今天再来学习一个新的特性,Stream 流,光是看名字就觉得和大数据能扯上关系,我们的 Spark、Flink 当中不就都是这种流的概念嘛。
1、什么是 Strem 流
Stream 是 JDK1.8 中处理集合的关键抽象概念, Lambda 表达式 和 Stream 是JDK1.8 新增的函数式编程中最有亮点的特性了,它可以指定你希望对集合进行操作,可以执行非常复杂的查询过滤和映射等操作。使用 Stream API 对集合数据进行操作,就类似于使用 SQL 来执行对 Java 集合运算和表达的高阶抽象。
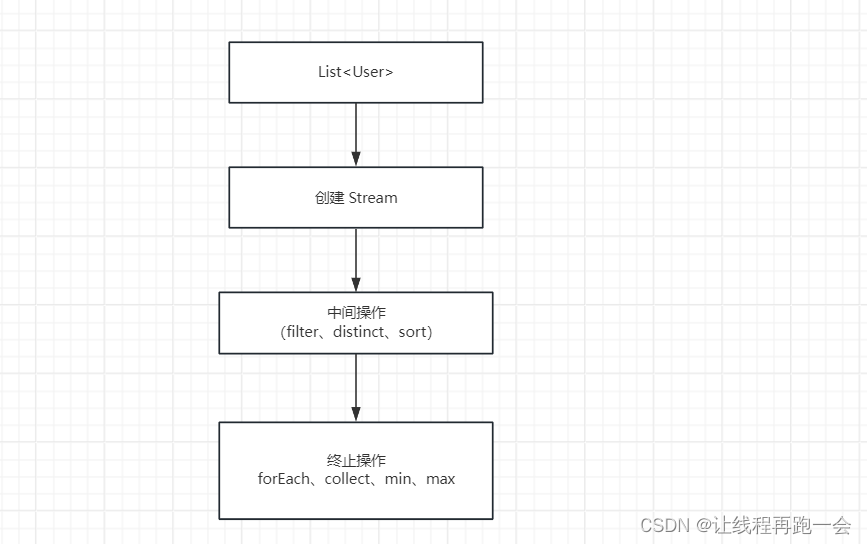
Stream API 可以极大地提高 Java 程序员的生产力,让程序员写出更加高效、干净、简洁的代码。那对我在大数据开发中更是如此。
这种风格将要处理的元素集合看做一种流,流在管道中传输,并且可以在管道的节点上进行处理,比如过滤、排序、聚合等。
2、Stream 创建方式
1、创建串行 Stream
Stream<User> userStream = list.stream();2、创建并行 Stream
Stream<User> userStream = list.parallelStream();3、关闭
在Java中,Stream只能被操作一次,一旦你对其进行了一次操作(比如forEach, collect等),它就会被关闭,再次操作就会报错:stream has already been operated upon or closed。
3、Stream 将 List 转换为 Set
1、创建 List 集合
Stream 是通过集合创建出来的,所以我们先创建一个集合,而集合内我们需要存放实体,所以先创建一个实体类 User:
public class User {public String name;public int age;public User(){}public User(String name, int age) {this.name = name;this.age = age;}@Overridepublic String toString() {return "User{" +"name='" + name + '\'' +", age=" + age +'}';}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;User user = (User) o;return age == user.age && Objects.equals(name, user.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}
}
创建集合
List<User> list = new ArrayList<>();list.add(new User("燕双鹰",28));list.add(new User("李大喜",20));list.add(new User("李元芳", 30));list.add(new User("李元芳", 30));重写 equals
注意:这里我们对实体类的 equals 和 hashcode 方法进行了重写,这在之前我是不会去重写的。重写和不重写的区别就是:
重写后,当两个实体对象的属性相同时,equals 方法返回 true,如果没有重写,则 equals 返回 false。
== 和 equals
== 用于比较基本数据类型的值是否相等或者对象的引用地址是否相同。
int a = 10;
int b = 10;
System.out.println(a==b); //trueString str1 = "hello";
String str2 = "hello";
System.out.println(str1==str2); //falseequals 用于比较两个对象的内容是否相等。在Object类中,默认的“equals()”实现使用“==”操作符比较对象的引用。但是,许多类(如String、Integer等)重写了“equals()”方法,以便根据类的特定属性比较对象的内容。

set 去重底层原理
set 去重底层依赖于 map 集合实现放重复的 key,map 集合底层基于 equals ,它先比较 key 的hashcode 是否相同,相同情况下再调用 equals 方法判断是否真的相等。
所以一个实体类是否重写 equals 方法区别很大。
User u1 = new User("s",1);User u2 = new User("s",1);System.out.println(u1.equals(u2));上面的代码,如果我们以 User 对象作为 key,如果我们的 User 没有重写 equals 方法,那么返回的就是 false,因为默认使用 == ,引用地址不同;如果重写了 equals 方法,那么返回的就是 true,因为使用重写后的 equals ,两个对象属性相同返回 true。
注意:对象的比较不会去比较 hashcode。
HashMap<User, String> map = new HashMap<>();map.put(u1,"a");map.put(u2,"b");System.out.println(map.get(u1).equals(map.get(u2)));上面的代码,如果我们没有重写 hashcode 的情况下,那么返回的就是 true,因为 map 的底层是通过 hashcode 来比较两个 key 是否相同;如果重写了 hashcode ,那么返回的就是 true。
2、List 转为 Set
public static void main(String[] args) {List<User> list = new ArrayList<>();list.add(new User("燕双鹰",28));list.add(new User("李大喜",20));// 下面是两个属性相同的两个对象(我们已经重写了 equals 和 hashcode 方法)list.add(new User("李元芳", 30));list.add(new User("李元芳", 30));// todo 创建 Stream 的两种方式// 1. 串行流 stream() 单线程Stream<User> stream = list.stream();Set<User> set = stream.collect(Collectors.toSet());set.forEach(user->{System.out.println(user.toString());});
}运行结果:
User{name='李元芳', age=30}
User{name='燕双鹰', age=28}
User{name='李大喜', age=20}可以看到,重写 equals 和 hashcode 方法后,虽然相同属性的两个对象的内存地址不同,但也被去除重复了。
4、Stream 将 List 转为 Map
1、创建 List
注意:List 转为 Map 的时候,由于 Map 集合不允许存在重复的 key,所以我们必须保证 list 集合中作为 key 字段的属性值唯一。
List<User> list = new ArrayList<>();list.add(new User("燕双鹰",28));list.add(new User("李大喜",20));list.add(new User("李元芳", 30));2、List 转为 Map
Stream<User> stream = list.stream();// list 集合是没有 key 的,所以不能直接转为 map 集合,需要指定 key(指定对象的某个字段作为key)Map<String, User> collect = stream.collect(Collectors.toMap(new Function<User, String>() { // 第一个参数 list中的类型,第二个参数是key类型: String@Overridepublic String apply(User user) {return user.getName();}}, new Function<User, User>() { // 第一个参数 list中的类型,第二个参数是value类型: User@Overridepublic User apply(User user) {return user;}}));collect.forEach(new BiConsumer<String, User>() {@Overridepublic void accept(String key, User user) {System.out.println(key+","+user.toString());}}); 使用 lambda 表达式简化一下代码:
// 用lambda表达式Map<String, User> collect = stream.collect(Collectors.toMap(User::getName, user -> user));collect.forEach((key,user)-> System.out.println(key+","+user.toString()));
运行结果:
李元芳,User{name='李元芳', age=30}
李大喜,User{name='李大喜', age=20}
燕双鹰,User{name='燕双鹰', age=28}5、Strem 通过 reduce 方法求和
1、简单求和
这里我们通过 Stream.of() 方法来进行数据的构造(这让我想到了最近 Flink)。
Stream<Integer> stream = Stream.of(10, 50, 30, 10);Optional<Integer> res = stream.reduce(new BinaryOperator<Integer>() {@Overridepublic Integer apply(Integer integer, Integer integer2) {return integer + integer2;}});使用 lamda 表达式
Optional<Integer> res = stream.reduce(Integer::sum);关于结果的打印,我们后面讲到 Optional 类的时候再详细说,一般直接:
System.out.println(res.get());2、对象属性和
我们构造一个 List 集合,然后转为 Stream 调用 reduce 方法进行求和。
注意:reduce 方法的返回结果类型必须和 Stream 的类型一致(就像我们 Hadoop 中的 WordCount)。
List<User> list = new ArrayList<>();list.add(new User("燕双鹰",28));list.add(new User("李大喜",20));list.add(new User("李元芳", 30));Stream<User> stream = list.stream();Optional<User> sum = stream.reduce(new BinaryOperator<User>() {@Overridepublic User apply(User user1, User user2) {return new User("sum",user1.getAge()+ user2.getAge());}});System.out.println(sum.get());lambda 表达式简化:
Stream<User> stream = list.stream();Optional<User> sum = stream.reduce(((user1, user2) -> new User("sum", user1.getAge() + user2.getAge())));System.out.println(sum.get());//786、Strem 查找集合最大值和最小值
1、创建集合
List<User> list = new ArrayList<>();
list.add(new User("燕双鹰",28));
list.add(new User("李大喜",20));
list.add(new User("李元芳", 30));2、查找最大 age 属性对象
Optional<User> max = stream.max(new Comparator<User>() {@Overridepublic int compare(User o1, User o2) {return o1.getAge() - o2.getAge();}});System.out.println(max.get());lambda表达式简化:
Optional<User> max = stream.max((user1, user2) -> user1.getAge() - user2.getAge());System.out.println(max.get()); //303、查找最小 age 属性对象
Optional<User> min = stream.min((user1, user2) -> user1.getAge() - user2.getAge());System.out.println(min.get()); //207、Stream 中 Match 用法
anyMatch 表示,任意一个元素满足条件返回 true。
allMatch 表示,所有元素满足条件才会返回 true。
noMatch 表示,所有条件都不满足这个条件才会返回 true。
1、创建集合
List<User> list = new ArrayList<>();list.add(new User("燕双鹰",28));list.add(new User("李大喜",20));list.add(new User("李元芳", 30));Stream<User> stream = list.stream();2、anyMatch
判断集合中是否存在 age 属性大于 25 的对象。
boolean res = stream.anyMatch(new Predicate<User>() {@Overridepublic boolean test(User user) {return user.getAge() > 25;}});System.out.println(res);lambda 表达式:
boolean res = stream.anyMatch(user -> user.getAge() > 25);System.out.println(res); //true3、allMatch
判断是否所有对象的 age属性都大于 30
boolean res = stream.allMatch(user -> user.getAge() > 30);System.out.println(res); //false4、noMatch
判断是否用户都不满足 name 为 “光头强 ”
boolean res = stream.noneMatch(user -> user.getName().equals("光头强"));System.out.println(res); //true8、Stream 过滤器
和我们 Flink 的 DataStream API 中的转换算子 filter 很像,它们都是把 判断条件结果为 true 的数据留下,false 则丢掉。
1、创建集合
List<User> list = new ArrayList<>();list.add(new User("燕双鹰",28));list.add(new User("李大喜",20));list.add(new User("李元芳", 30));Stream<User> stream = list.stream();2、过滤
Stream<User> filterStream = stream.filter(new Predicate<User>() {@Overridepublic boolean test(User user) { //为 true 则留下return user.getAge()>25;}});filterStream.forEach(new Consumer<User>() {@Overridepublic void accept(User user) {System.out.println(user);}});运行结果:
User{name='燕双鹰', age=28}
User{name='李元芳', age=30}lambda表达式:
Stream<User> filterStream = stream.filter(user -> user.getAge() > 25);filterStream.forEach(System.out::println);9、Stream Limit 和 Skip
同样,Stream 需要通过集合来创建。
List<User> list = new ArrayList<>();
list.add(new User("燕双鹰",28));
list.add(new User("李大喜",20));
list.add(new User("李元芳", 30));
list.add(new User("熊大",15));
list.add(new User("熊二",14));
list.add(new User("光头强",20));
Stream<User> stream = list.stream();1、取出前2条数据
// 在mysql中limit(start,end)需要传两个参数,但在这里只允许传入一个long类型的 maxSize// 取前2条数据stream.limit(2).forEach(System.out::println);运行结果:
User{name='燕双鹰', age=28}
User{name='李大喜', age=20}
2、取出第 [3,6) 条数据
注意,这里的索引是从 0 开始的。
// 取 [3,6)条数据 想要分页从先 skip 再 limit
stream.skip(2).limit(3).forEach(System.out::println);运行结果:
User{name='李元芳', age=30}
User{name='熊大', age=15}
User{name='熊二', age=14}10、Stream 排序 sorted
下面用到的数据。
List<User> list = new ArrayList<>();
list.add(new User("燕双鹰",28));
list.add(new User("李大喜",20));
list.add(new User("李元芳", 30));
list.add(new User("熊大",15));
list.add(new User("熊二",14));
list.add(new User("光头强",20));
Stream<User> stream = list.stream();1、直接排序
对于数值型的数据可以直接进行排序
Stream<Integer> integerStream = Stream.of(1, 5, 8, 3, 7);
integerStream.sorted().forEach(System.out::println); //1 3 5 7 82、根据对象字段进行升序
stream.sorted(new Comparator<User>() {@Overridepublic int compare(User o1, User o2) {return o1.getAge()-o2.getAge();}
}).forEach(System.out::println);lambda 表达式:
stream.sorted((o1, o2) -> o1.getAge()-o2.getAge()).forEach(System.out::println);运行结果:
User{name='熊二', age=14}
User{name='熊大', age=15}
User{name='李大喜', age=20}
User{name='光头强', age=20}
User{name='燕双鹰', age=28}
User{name='李元芳', age=30}JDK1.8 提供的函数接口
都在包 java.util.function 包下。
并行流
案例1 - 500亿次求和
1、使用单线程
Instant start = Instant.now();long sum = 0;for (long i = 0; i <= 50000000000L; i++) {sum+=i;}Instant end = Instant.now();System.out.println(sum);System.out.println("500亿次求和花费时间: "+ Duration.between(start,end).toMillis()+"ms"); // 单线程 11s左右 多线程 6s左右
2、使用并行流
Instant start = Instant.now();LongStream longStream = LongStream.rangeClosed(0,50000000000L);OptionalLong result = longStream.parallel().reduce(new LongBinaryOperator() {@Overridepublic long applyAsLong(long left, long right) {return left + right;}});Instant end = Instant.now();System.out.println(result.getAsLong());System.out.println("500亿次求和花费时间: "+ Duration.between(start,end).toMillis()+"ms"); // 单线程 11s左右 多线程 6s左右
可以发现,多线程明显要快很多。
总结
本次学习收获非常大,函数接口的思想在 Flink 中随处可见,的确,这样一种能够使得代码简洁高效的技术在大数据开发中是非常重要的。
相关文章:
JDK1.8 新特性(二)【Stream 流】
前言 上节我们学了 lambda 表达式,很快我就在 Flink 的学习中用到了,我学的是 Java 版本的 Flink,一开始会以为代码会很复杂,但事实上 Flink 中很多地方都用到了 函数接口,这也让我们在编写 Flink 程序的时候可以使用 …...
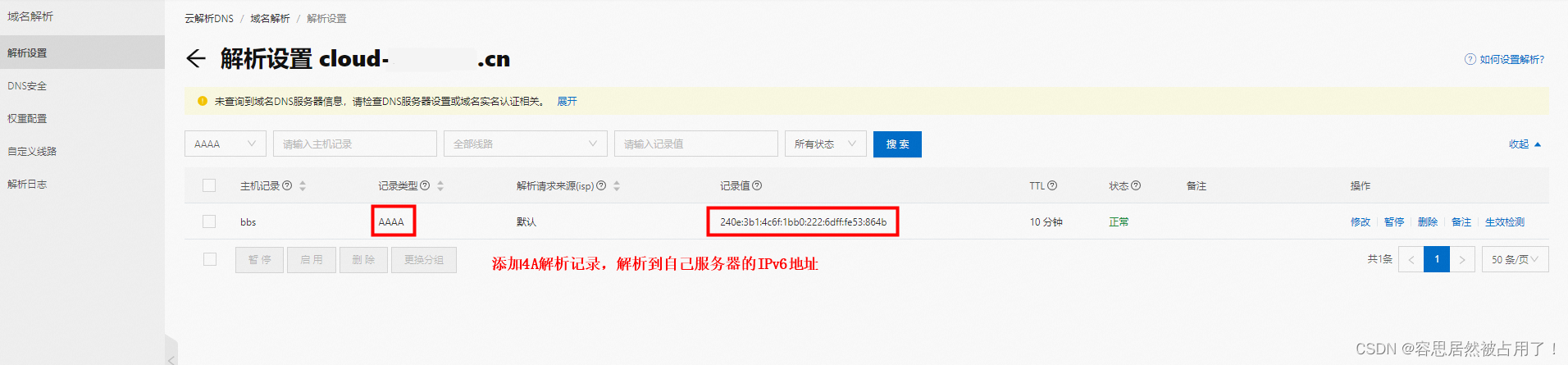
阿里云CentOS主机开启ipv6
目录 一、云主机开启和使用 ipv6 1、网络和交换机开启 ipv6 2、创建 / 编辑云主机,开启ipv6 3、安全组放行ipv6端口 二、使用 ipv6 地址进行 ssh 连接 三、ipv6 地址绑定域名 一、云主机开启和使用 ipv6 1、网络和交换机开启 ipv6 进入网络、交换机详情页面…...

【Git】第五篇:基本操作(添加文件)
.git目录结构 我们在前文中提过了.git目录,也明确说了我们不能手动去.git目录下创建修改等任何操作。 添加文件 我们现在已经了解到,git是一个版本控制器,可以对我们的文件进行管理。而我们需要使用git管理文件的时候,我们必须将…...

vue通过span-method合并列之后,合并列显示在中间位置,根据鼠标滑动跟随展示
当vue通过span-method合并列之后,出现的合并列显示在中间位置,但是如果页面没有分页,如何进行展示呢,难道要滑到最下面去看吗,下面我们来根据鼠标滑动跟随展示 没有处理的合并页面 <template> <el-table:dat…...

gRPC 四模式之 一元RPC模式
一元RPC模式 一元 RPC 模式也被称为简单 RPC 模式。在该模式中,当客户端调用服务器端的远程方法时,客户端发送请求至服务器端并获得一个响应,与响应一起发送的还有状态细节以及 trailer 元数据(这部分不是默认发送的,…...

Java GUI实现贪吃蛇游戏
贪吃蛇是一款经典的游戏,玩法相对简单但富有挑战性。以下是贪吃蛇游戏的基本玩法说明: 目标:控制一条蛇,在游戏区域内吃到尽可能多的食物,使蛇身变长,同时避免撞到自己的身体或游戏区域的边界。 控制&…...

Vue3 使用教程
目录 一、创建vue3工程1. 使用vue-cli创建2.使用 vite 创建 二、setup使用三、ref函数四、reactive函数五、计算属性与监视属性5.1 computed函数5.2 watch函数5.3 watchEffect函数 六、自定义hook函数七、toRef函数八、shallowReactive 与 shallowRef九、readonly 与 shallowRe…...
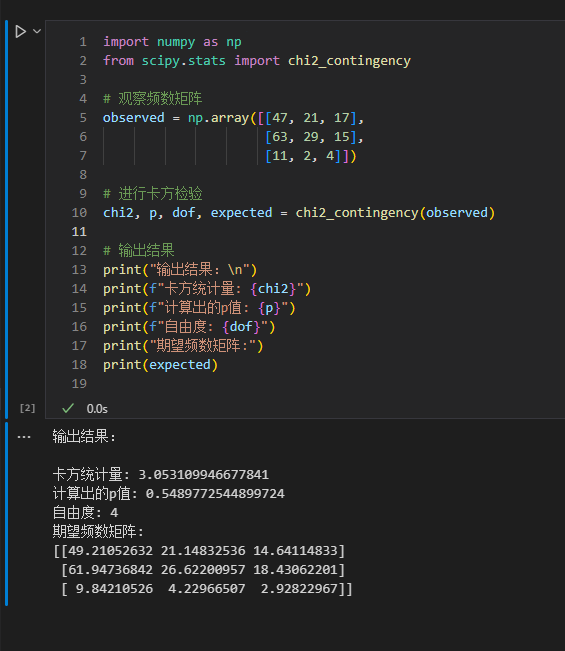
卡方检验-python代码
故事背景 问题 卡方检验的结果怎么计算? 方法 python代码 import numpy as np from scipy.stats import chi2_contingency# 观察频数矩阵 observed np.array([[47, 21, 17],[63, 29, 15],[11, 2, 4]])# 进行卡方检验 chi2, p, dof, expected chi2_contingency(o…...
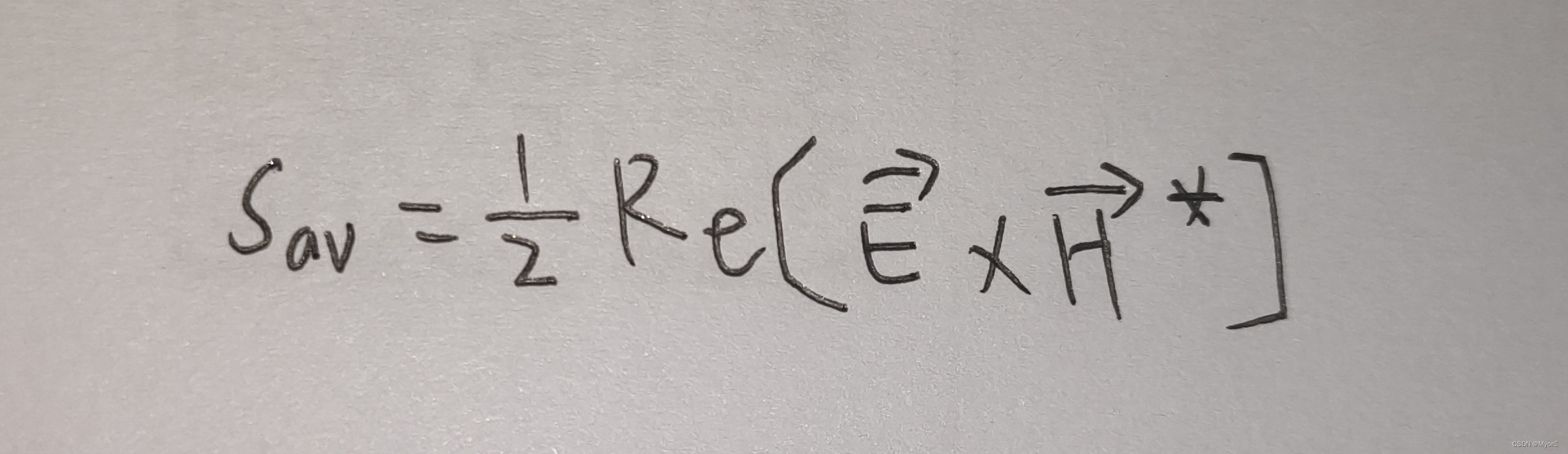
电磁场与电磁波part4--时变电磁场
1、采用洛伦兹条件使得矢量位 与标量位 分离在两个独立的方程中,且矢量位 仅与电流密度 有关,而标量位 仅与电荷密度 有关。 2、电磁能量守恒定理(坡印廷定理) 即减少的电磁能量电磁场所做的功流出的电磁能量 3、设u(r,t)是…...
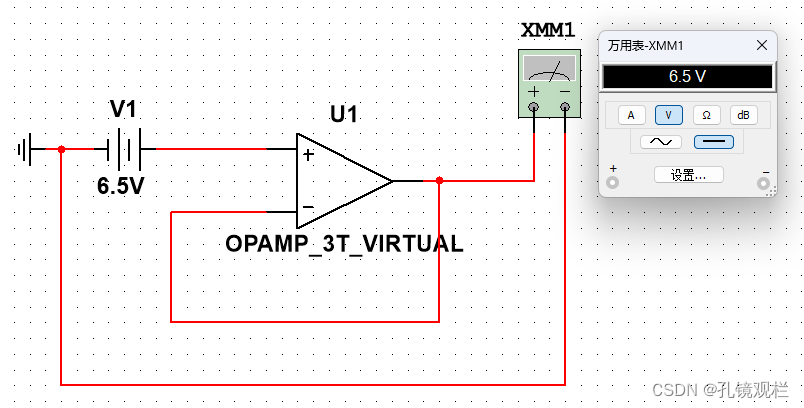
电压跟随器
电压跟随器即输入多大电压就输出多大的电压,那其起什么作用呢,直接用导线不行吗? 下图为Multisim软件仿真结果,很明显输入电压6.5V输出电压使用万用表测得同为6.5V,验证了电压跟随器的作用。 在同相放大电路的基础上&a…...

元宇宙3D云展厅应用到汽车销售的方案及特点
为了紧紧抓住年轻消费者的需求,汽车销售行业也正在经历一场深刻的变革。在这个变革的前沿,元宇宙3D汽车展厅作为一项全新技术闪亮登场,打破了传统汽车销售模式的限制,为消费者带来了前所未有的购车体验。 元宇宙3D汽车展厅采用了尖…...
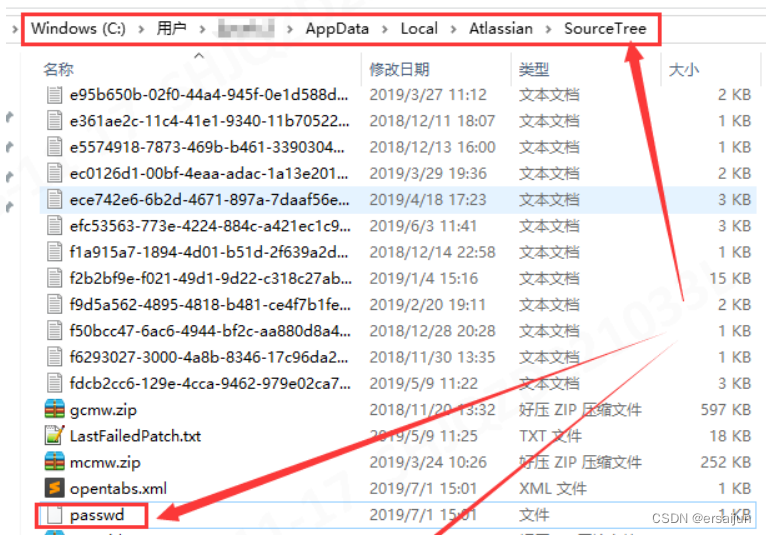
SourceTree修改Git密码
SourceTree用的好好的,无奈公司隔段时间强制更改电脑密码。更改完成后SourceTree无法使用,重新输入密码。VS的nuget也是。查资料虽然也能比较快的解决,但是。。。。在此转载记录下。 1. 找到 SourceTree 配置文件所在目录 ‘userhosts’ 目录…...

java中的深度复制和浅复制的BUG
刷题刷到LeetCode回溯DFS的算法题39题的时候,碰见一个Arraylist里面的bug,其中dfs函数里面的第一个if判断里面的语句 paths.add(path); path.clear();其中path是添加了path,但是添加之后path.clear(),导致原来添加到paths的path置为空数组,因为ArrayList的add只是把一个引用指…...

计算机毕业设计 基于SpringBoot的车辆网位置信息管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

集软件库、论坛、社区、工具箱、积分商城、会员体系、在线商城一体的后台系统+HBuilderX 前端软件社区
集软件库、论坛、社区、工具箱、积分商城、会员体系、在线商城等多个功能于一体的全面后台系统加上强大的HBuilderX前端软件社区,为用户提供了全面的应用开发和交流平台 企业猫提供了完善的后台搭建服务,通过该服务,用户可以方便地搭建出所需…...
】)
【解决Qt编译报错:-1: warning: **.so, not found(try using -rpath or -rpath-link)】
[TOC](Qt调用opencv报错👎 warning: libopencv_flann.so.406, needed by **//libopencv_features2d.so, not found (try using -rpath or -rpath-link)) 最终提示使用-rpath,于是抱着试试看的方法改写.pro文件: QMAKE_LIBDIR_FLAGS -Wl,-r…...

关于数据mysql ->maxwell->kafka的数据传输
个人名片: 🐅作者简介:一名大三在校生,热爱生活,爱好敲码! \ 💅个人主页 🥇:holy-wangle ➡系列内容: 🖼️ tkinter前端窗口界面创建与优化 &…...

【linux】查看CPU的使用率
命令1:top top 总体系统信息 uptime:系统的运行时间和平均负载。tasks:当前运行的进程和线程数目。CPU:总体 CPU 使用率和各个核心的使用情况。内存(Memory):总体内存使用情况、可用内存和缓存…...
)
【系统稳定性】1.6 黑屏(三)
五,QNX启动异常 qnx启动异常无疑同样是灾难级的存在。qnx是目前座舱方案中主流的存在,如果qnx存在异常会导致host或la或其他娱乐世界offline。那么导致qnx的原因有很多,相应地,我们也有很多的排查手段。 5.1 以太网连接 座舱方案中目前还是多域的设计,那么多域之间的连…...
《使用EasyExcel在Excel中增加序号列的方法》
《使用EasyExcel在Excel中增加序号列的方法》 1、简介2、正文3、核心代码4、使用方法5、效果 1、简介 在处理Excel文件时,有时候需要为表格增加序号列。本文介绍了如何使用Java代码实现在Excel中增加序号列的功能,并提供了一个示例代码。 2、正文 在处理…...

【分箱进阶篇】分箱的工程细节:从训练到部署的完整模式
基础篇参考:【分箱基础篇】pandas 分箱双子星:pd.cut 与 pd.qcut 我们在基础篇讲了 pd.cut 和 pd.qcut 各自怎么用。但在实际项目里,分箱不是调一次函数就完事的。通常来说,训练集上算出来的切分点要保存下来,测试集…...
)
别再只用DataParallel了!PyTorch单机多卡训练保姆级教程(从DP到DDP实战避坑)
从DataParallel到DDP:PyTorch单机多卡训练深度优化指南 当你的模型参数突破1亿大关,单卡训练时间从几小时延长到几天时,多GPU并行训练就从一个可选项变成了必选项。但面对PyTorch提供的DataParallel(DP)和DistributedDataParallel(DDP)两种方…...

从汇编指令到硬件行为:深入解析Aurix Tricore Trap触发与恢复的全过程
从汇编指令到硬件行为:深入解析Aurix Tricore Trap触发与恢复的全过程 当我们在调试Aurix Tricore处理器的异常处理机制时,常常会遇到一个令人困惑的现象:为什么有些Trap发生后程序能够继续执行,而有些则会导致系统崩溃ÿ…...

3步实现Mac微信防撤回:零配置本地化解决方案
3步实现Mac微信防撤回:零配置本地化解决方案 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 告别消息遗憾࿱…...

避开这些坑!用UDE STK 5.0给英飞凌AURIX芯片下载程序时,关于板卡休眠与唤醒的实战经验
避开这些坑!用UDE STK 5.0给英飞凌AURIX芯片下载程序时,关于板卡休眠与唤醒的实战经验 在嵌入式系统开发中,低功耗设计是一个永恒的话题。特别是对于汽车电子、工业控制等领域的应用,如何平衡系统性能和功耗表现,往往…...
)
银河麒麟V10 SP1下使用rsync实现多客户端定时数据备份(避坑指南)
银河麒麟V10 SP1多客户端数据同步全链路配置与优化实战 在IT运维工作中,数据备份如同氧气般不可或缺。想象一下,当数十台客户端设备同时运行时,如何确保关键业务数据能够安全、高效地集中备份?银河麒麟V10 SP1作为国产操作系统的…...

三步打造清爽Mac菜单栏:Dozer终极隐藏方案
三步打造清爽Mac菜单栏:Dozer终极隐藏方案 【免费下载链接】Dozer Hide menu bar icons on macOS 项目地址: https://gitcode.com/gh_mirrors/do/Dozer 还在为Mac菜单栏上拥挤不堪的图标感到困扰吗?想要一个简洁高效的工作界面?Dozer正…...
)
Python AOT编译迎来分水岭:2026年3大工业级工具实测对比(启动提速8.7×,内存降63%,兼容CPython 3.13+)
第一章:Python AOT编译的范式跃迁与工业落地元年定义长期以来,Python 以解释执行和动态特性见长,但其运行时开销、启动延迟与内存 footprint 成为云原生服务、边缘设备与实时系统规模化部署的关键瓶颈。2024 年,随着 Nuitka 14.x、…...

MedGemma-X实战教程:用status_gradio.sh实时监控GPU利用率与内存泄漏
MedGemma-X实战教程:用status_gradio.sh实时监控GPU利用率与内存泄漏 1. 为什么你需要实时监控MedGemma-X的GPU状态 MedGemma-X不是一台“开箱即用就永远稳定”的黑盒子。它是一套在GPU上高速运转的多模态影像认知系统——当它正在分析一张胸部X光片、生成结构化报…...

终极Neovim AI助手:Avante.nvim如何彻底改变你的编码体验 [特殊字符]
终极Neovim AI助手:Avante.nvim如何彻底改变你的编码体验 🚀 【免费下载链接】avante.nvim Use your Neovim like using Cursor AI IDE! 项目地址: https://gitcode.com/GitHub_Trending/ava/avante.nvim 在当今AI驱动的开发时代,Neov…...