机器学习第8天:SVM分类
文章目录
机器学习专栏
介绍
特征缩放
示例代码
硬间隔与软间隔分类
主要代码
代码解释
非线性SVM分类
结语
机器学习专栏
机器学习_Nowl的博客-CSDN博客
介绍
作用:判别种类
原理:找出一个决策边界,判断数据所处区域来识别种类
简单介绍一下SVM分类的思想,我们看下面这张图,两种分类都很不错,但是我们可以注意到第二种的决策边界与实例更远(它们之间的距离比较宽),而SVM分类就是一种寻找距每种实例最远的决策边界的算法
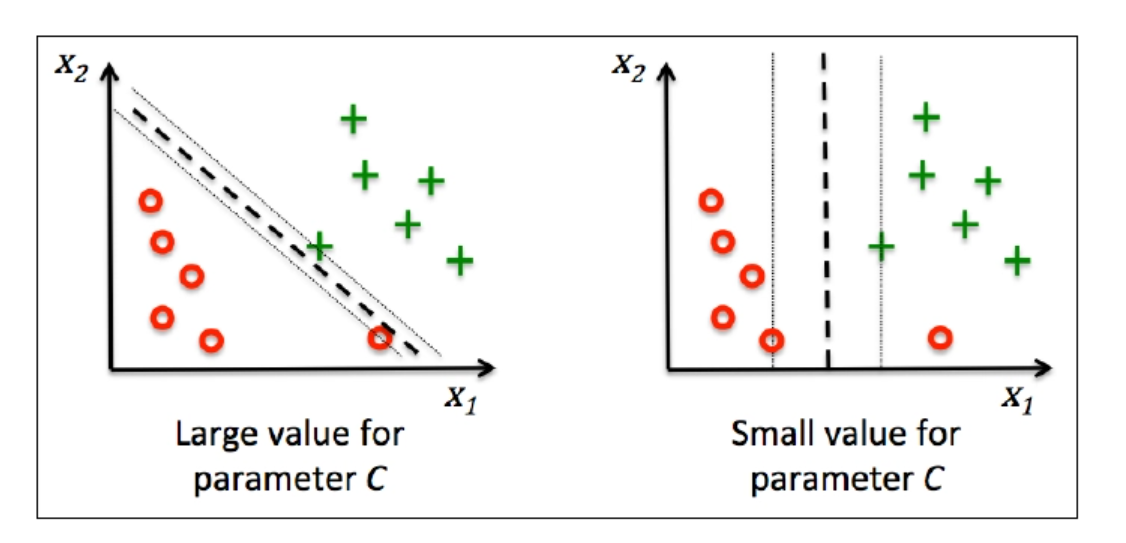
特征缩放
SVM算法对特征缩放很敏感(不处理算法效果会受很大影响)
特征缩放是什么意思呢,例如有身高数据和体重数据,若身高是m为单位,体重是g为单位,那么体重就比身高的数值大很多,有些机器学习算法就可能更关注某一个值,这时我们用特征缩放就可以把数据统一到相同的尺度上
示例代码
from sklearn.preprocessing import StandardScaler
import numpy as np# 创建一个示例数据集
data = np.array([[1.0, 2.0, 3.0],[4.0, 5.0, 6.0],[7.0, 8.0, 9.0]])# 创建StandardScaler对象
scaler = StandardScaler()# 对数据进行标准化
scaled_data = scaler.fit_transform(data)print("原始数据:\n", data)
print("\n标准化后的数据:\n", scaled_data)# 结果是
# [[-1.22474487 -1.22474487 -1.22474487]
# [ 0. 0. 0. ]
# [ 1.22474487 1.22474487 1.22474487]]
StandardScaler是一种数据标准化的方法,它对数据进行线性变换,使得数据的均值变为0,标准差变为1。
解释上面的数据
在每列上进行标准化,即对每个特征进行独立的标准化。每个数值是通过减去该列的均值,然后除以该列的标准差得到的。
- 第一列:(1−4)/9=−1.22474487(1−4)/9=−1.22474487,(4−4)/9=0(4−4)/9=0,(7−4)/9=1.22474487(7−4)/9=1.22474487。
- 第二列:(2−5)/9=−1.22474487(2−5)/9=−1.22474487,(5−5)/9=0(5−5)/9=0,(8−5)/9=1.22474487(8−5)/9=1.22474487。
- 第三列:(3−6)/9=−1.22474487(3−6)/9=−1.22474487,(6−6)/9=0(6−6)/9=0,(9−6)/9=1.22474487(9−6)/9=1.22474487。
这样,标准化后的数据集就符合标准正态分布,每个特征的均值为0,标准差为1。
硬间隔与软间隔分类
硬间隔分类就是完全将不同的个体区分在不同的区域(不能有一点误差)

软间隔分类就是允许一些偏差(图中绿和红色的点都有一些出现在了对方的分区里)
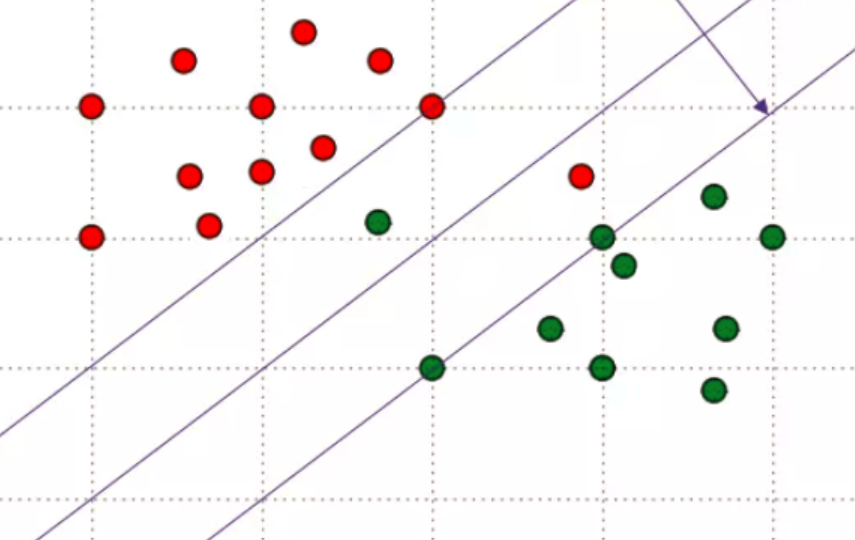
硬间隔分类往往会出现一些问题,例如有时候模型不可能完全分成两类,同时,硬间隔分类往往可能导致过拟合,而软间隔分类的泛化能力就比硬间隔分类好很多
主要代码
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVCmodel = Pipeline([("scaler", StandardScaler()),("linear_svc", LinearSVC(C=1, loss="hinge"))
])model.fit(x, y)代码解释
在这里,Pipeline的构造函数接受一个由元组组成的列表。每个元组的第一个元素是该步骤的名称(字符串),第二个元素是该步骤的实例。在这个例子中,第一个步骤是数据标准化,使用StandardScaler,命名为"scaler";第二个步骤是线性支持向量机,使用LinearSVC,命名为"linear_svc"。这两个步骤会按照列表中的顺序依次执行。
参数C是正则程度,hinge是SVM分类算法的损失函数,用来训练模型
非线性SVM分类
上述方法都是在数据集可线性分离时用到的,当数据集呈非线性怎么办,我们在回归任务中讲过一个思想,用PolynomialFeatures来产生多项式,再对每个项进行线性拟合,最后结合在一起得出决策边界
具体代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import PolynomialFeatures
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score# 生成非线性数据集
X, y = datasets.make_circles(n_samples=100, factor=0.5, noise=0.1, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用多项式特征和线性SVM
degree = 3 # 多项式的次数
svm_classifier = make_pipeline(StandardScaler(), PolynomialFeatures(degree), SVC(kernel='linear', C=1))
svm_classifier.fit(X_train, y_train)# 预测并计算准确率
y_pred = svm_classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)# 绘制决策边界
def plot_decision_boundary(X, y, model, ax):h = .02x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))Z = model.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)ax.contourf(xx, yy, Z, alpha=0.8)ax.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', s=80, linewidth=0.5)ax.set_xlim(xx.min(), xx.max())ax.set_ylim(yy.min(), yy.max())# 绘制结果
fig, ax = plt.subplots(figsize=(8, 6))
plot_decision_boundary(X_train, y_train, svm_classifier, ax)
ax.set_title('Polynomial SVM Decision Boundary')
plt.show()
运行结果
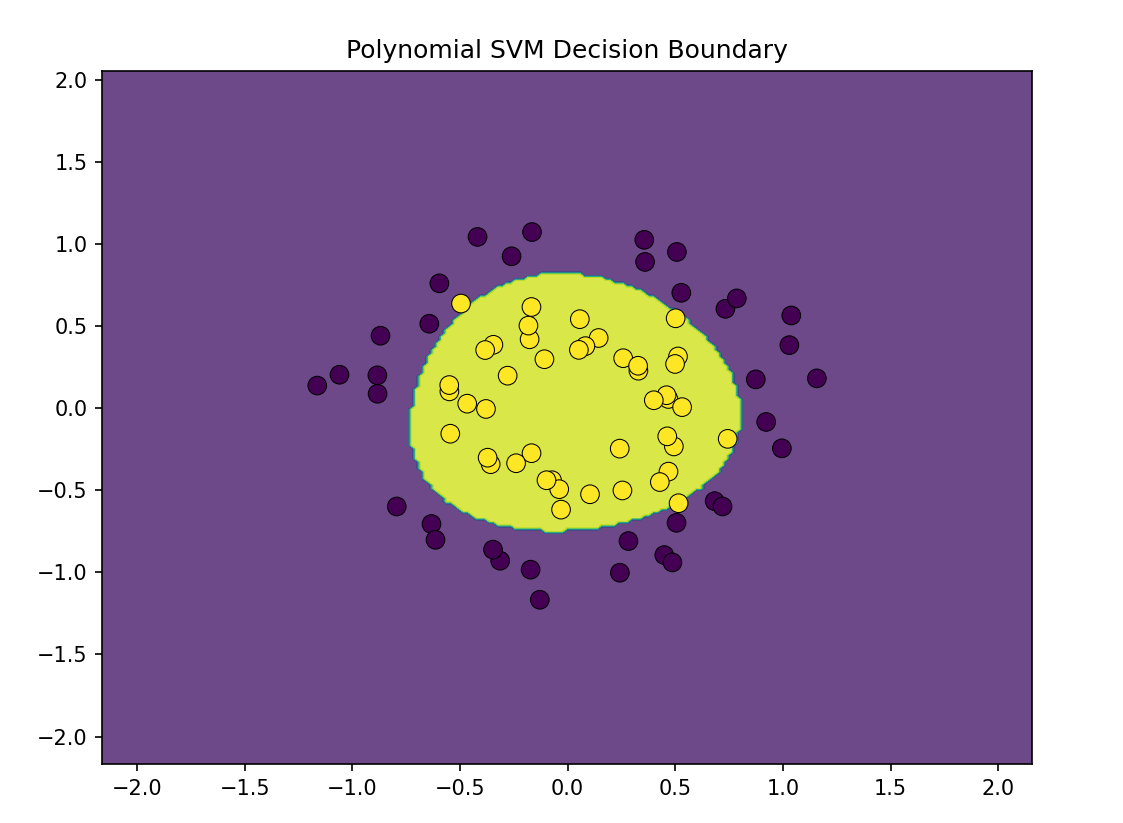
结语
SVM分类是一种经典的分类算法,也叫大间隔分类算法。它可以用来线性分类,也可以非线性分类(可以与PolynomialFeatures结合,当然还有其他方法,我们之后再说)
相关文章:
机器学习第8天:SVM分类
文章目录 机器学习专栏 介绍 特征缩放 示例代码 硬间隔与软间隔分类 主要代码 代码解释 非线性SVM分类 结语 机器学习专栏 机器学习_Nowl的博客-CSDN博客 介绍 作用:判别种类 原理:找出一个决策边界,判断数据所处区域来识别种类 简单…...

AI工具合集
网站:未来百科 | 为发现全球优质AI工具产品而生 (6aiq.com) 如今,AI技术涉及到了很多领域,比如去水印、一键抠图、图像处理、AI图像生成等等。站长之家之前也分享过一些,但是在网上要搜索找到它们还是费一些功夫。 今天发现了一…...

代码随想录算法训练营Day 54 || 392.判断子序列、115.不同的子序列
392.判断子序列 力扣题目链接(opens new window) 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,&quo…...
和puts())
C 语言 gets()和puts()
C 语言 gets()和puts() gets()和puts()在头文件stdio.h中声明。这两个函数用于字符串的输入/输出操作。 C gets()函数 gets()函数使用户可以输入一些字符,然后按Enter键。 用户输入的所有字符都存储在字符数组中。 空字符将添加到数组以使其成为字符串。 gets()允…...

核—幂零分解
若向量空间 V \mathcal V V存在子空间 X \mathcal X X与 Y \mathcal Y Y,当 X Y V X ∩ Y 0 \mathcal {X\text{}Y\text{}V}\\ \mathcal {X}\cap \mathcal {Y}0 XYVX∩Y0 时称子空间 X \mathcal X X与 Y \mathcal Y Y是完备的,其中记为 X ⊕ Y V \ma…...

轻松掌控财务,分析账户花销,明细记录支出情况
随着科技的发展,我们的生活变得越来越智能化。然而,对于许多忙碌的现代人来说,管理财务可能是一件令人头疼的事情。复杂的账单、花销、收入,这些可能会让你感到无从下手。但现在,我们有一个全新的解决方案——一款全新…...

竞赛 题目:基于机器视觉opencv的手势检测 手势识别 算法 - 深度学习 卷积神经网络 opencv python
文章目录 1 简介2 传统机器视觉的手势检测2.1 轮廓检测法2.2 算法结果2.3 整体代码实现2.3.1 算法流程 3 深度学习方法做手势识别3.1 经典的卷积神经网络3.2 YOLO系列3.3 SSD3.4 实现步骤3.4.1 数据集3.4.2 图像预处理3.4.3 构建卷积神经网络结构3.4.4 实验训练过程及结果 3.5 …...

11. Spring源码篇之实例化前的后置处理器
简介 spring在创建Bean的过程中,提供了很多个生命周期,实例化前就是比较早的一个生命周期,顾名思义就是在Bean被实例化之前的处理,这个时候还没实例化,只能拿到该Bean的Class对象,如果在这个时候直接返回一…...

Python-Python高阶技巧:HTTP协议、静态Web服务器程序开发、循环接收客户端的连接请求
版本说明 当前版本号[20231114]。 版本修改说明20231114初版 目录 文章目录 版本说明目录HTTP协议1、网址1.1 网址的概念1.2 URL的组成1.3 知识要点 2、HTTP协议的介绍2.1 HTTP协议的概念及作用2.2 HTTP协议的概念及作用2.3 浏览器访问Web服务器的过程 3、HTTP请求报文3.1 H…...

P1304 哥德巴赫猜想
题目描述 输入一个偶数 N,验证 4∼N 所有偶数是否符合哥德巴赫猜想:任一大于 22 的偶数都可写成两个质数之和。如果一个数不止一种分法,则输出第一个加数相比其他分法最小的方案。例如 1010,10=3+7=5+510=3+7=5+5,则 10=5+510=5+5 是错误答案。 输入格式 第一行输入一个…...
)
CSDN每日一题学习训练——Python版(搜索插入位置、最大子序和)
版本说明 当前版本号[20231118]。 版本修改说明20231118初版 目录 文章目录 版本说明目录搜索插入位置题目解题思路代码思路参考代码 最大子序和题目解题思路代码思路参考代码 搜索插入位置 题目 给定一个排序数组和一个目标值,在数组中找到目标值,…...

Java在物联网中的重要性
【点我-这里送书】 本人详解 作者:王文峰,参加过 CSDN 2020年度博客之星,《Java王大师王天师》 公众号:JAVA开发王大师,专注于天道酬勤的 Java 开发问题中国国学、传统文化和代码爱好者的程序人生,期待你的关注和支持!本人外号:神秘小峯 山峯 转载说明:务必注明来源(…...

动态规划解背包问题
题目 题解 def knapsac(W: int, N: int, wt: List[int], val: List[int]) -> int:# 定义状态动作价值函数: dp[i][j],对于前i个物品,当前背包容量为j,最大的可装载价值dp [[0 for j in range(W1)] for i in range(N1)]# 状态动作转移for…...

PCL内置点云类型
PCL内置了许多点云类型供我们使用,下面先介绍PLC内置的点云数据类型 PCL中的点云类型为PointT;至于为什么是PointT类型需要追随到原来的ros开发中去,因为PCL库也是从原来的ROS中剥离出来的;大家都一致的认为点云结构是离散的N维信…...

clickhouse数据结构和常用数据操作
背景, 大数据中查询用mysql时间太长, 使用clickhouse 速度快, 数据写入mysql后同步到clickhouse中 测试1千万数据模糊搜索 mysql 需要30-40秒 clickhouse 约 100ms 一 数据结构和存储引擎 1 查看clickhouse所有数据类型 select * from system.data_type_families; 2 …...
upload-labs关卡9(基于win特性data流绕过)通关思路
文章目录 前言一、靶场需要了解的知识1::$data是什么 二、靶场第九关通关思路1、看源码2、bp抓包修改后缀名3、检查是否成功上传 总结 前言 此文章只用于学习和反思巩固文件上传漏洞知识,禁止用于做非法攻击。注意靶场是可以练习的平台,不能随意去尚未授…...

C++过河卒问题
#include <iostream> #include <cstring> using namespace std;int board[20][20]; // 棋盘 int dp[20][20][20][20]; // 动态规划数组int main() {int x0, y0, x1, y1;cin >> x0 >> y0 >> x1 >> y1; // 输入卒的起点和终点memset(board,…...
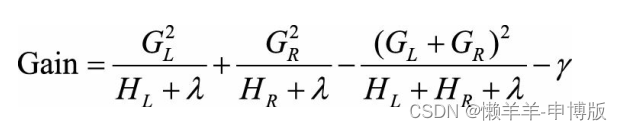
【机器学习12】集成学习
1 集成学习分类 1.1 Boosting 训练基分类器时采用串行的方式, 各个基分类器之间有依赖。每一层在训练的时候, 对前一层基分类器分错的样本, 给予更高的权重。 测试时, 根据各层分类器的结果的加权得到最终结果。 1.2 Bagging …...

nodeJs基础笔记
title: nodeJs基础笔记 date: 2023-11-18 22:33:54 tags: 1. Buffer 1. 概念 Buffer 是一个类似于数组的 对象 ,用于表示固定长度的字节序列。 Buffer 本质是一段内存空间,专门用来处理 二进制数据 。 2. 特点 Buffer 大小固定且无法调整Buffer 性能…...

Skywalking流程分析_9(JDK类库中增强流程)
前言 之前的文章详细介绍了关于非JDK类库的静态方法、构造方法、实例方法的增强拦截流程,本文会详细分析JDK类库中的类是如何被增强拦截的 回到最开始的SkyWalkingAgent#premain try {/** 里面有个重点逻辑 把一些类注入到Boostrap类加载器中 为了解决Bootstrap类…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...
)
别再瞎拖拽了!Unity Prefab从创建到批量修改的保姆级工作流(含变体与嵌套实战)
Unity Prefab高效工作流:从创建到批量修改的实战指南在Unity项目开发中,Prefab(预制体)是最基础也最强大的工具之一。但很多开发者,尤其是初学者,往往停留在简单的"拖拽-修改"阶段,没…...

终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代
终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法直接运行手机应用…...

一、[特殊字符]️ 误拦噩梦:护栏上线后的真实反弹
一、🛡️ 误拦噩梦:护栏上线后的真实反弹 不少团队在 LLM 推理服务中部署输入护栏后,遇到的第一个生产事故不是攻击漏过,而是正常请求被大规模误拦。某医疗平台上线正则输入过滤后,用户咨询“心绞痛的症状”被拦截&…...