利用(Transfer Learning)迁移学习在IMDB数据上训练一个文本分类模型
1. 背景
有些场景下,开始的时候数据量很小,如果我们用一个几千条数据训练一个全新的深度机器学习的文本分类模型,效果不会很好。这个时候你有两种选择,1.用传统的机器学习训练,2.利用迁移学习在一个预训练的模型上训练。本博客教你怎么用tensorflow Hub和keras 在少量的数据上训练一个文本分类模型。
2. 实践
2.1. 下载IMDB 数据集,参考下面博客。
Imdb影评的数据集介绍与下载_imdb影评数据集-CSDN博客
2.2. 预处理数据
替换掉imdb目录 (imdb_raw_data_dir). 创建dataset目录。
import numpy as np
import os as osimport re
from sklearn.model_selection import train_test_splitvocab_size = 30000
maxlen = 200
imdb_raw_data_dir = "/Users/harry/Documents/apps/ml/aclImdb"
save_dir = "dataset"def get_data(datapath =r'D:\train_data\aclImdb\aclImdb\train' ):pos_files = os.listdir(datapath + '/pos')neg_files = os.listdir(datapath + '/neg')print(len(pos_files))print(len(neg_files))pos_all = []neg_all = []for pf, nf in zip(pos_files, neg_files):with open(datapath + '/pos' + '/' + pf, encoding='utf-8') as f:s = f.read()s = process(s)pos_all.append(s)with open(datapath + '/neg' + '/' + nf, encoding='utf-8') as f:s = f.read()s = process(s)neg_all.append(s)print(len(pos_all))# print(pos_all[0])print(len(neg_all))X_orig= np.array(pos_all + neg_all)# print(X_orig)Y_orig = np.array([1 for _ in range(len(pos_all))] + [0 for _ in range(len(neg_all))])print("X_orig:", X_orig.shape)print("Y_orig:", Y_orig.shape)return X_orig, Y_origdef generate_dataset():X_orig, Y_orig = get_data(imdb_raw_data_dir + r'/train')X_orig_test, Y_orig_test = get_data(imdb_raw_data_dir + r'/test')X_orig = np.concatenate([X_orig, X_orig_test])Y_orig = np.concatenate([Y_orig, Y_orig_test])X = X_origY = Y_orignp.random.seed = 1random_indexs = np.random.permutation(len(X))X = X[random_indexs]Y = Y[random_indexs]X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)print("X_train:", X_train.shape)print("y_train:", y_train.shape)print("X_test:", X_test.shape)print("y_test:", y_test.shape)np.savez(save_dir + '/train_test', X_train=X_train, y_train=y_train, X_test= X_test, y_test=y_test )def rm_tags(text):re_tag = re.compile(r'<[^>]+>')return re_tag.sub(' ', text)def clean_str(string):string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)string = re.sub(r"\'s", " \'s", string) # it's -> it 'sstring = re.sub(r"\'ve", " \'ve", string) # I've -> I 'vestring = re.sub(r"n\'t", " n\'t", string) # doesn't -> does n'tstring = re.sub(r"\'re", " \'re", string) # you're -> you arestring = re.sub(r"\'d", " \'d", string) # you'd -> you 'dstring = re.sub(r"\'ll", " \'ll", string) # you'll -> you 'llstring = re.sub(r"\'m", " \'m", string) # I'm -> I 'mstring = re.sub(r",", " , ", string)string = re.sub(r"!", " ! ", string)string = re.sub(r"\(", " \( ", string)string = re.sub(r"\)", " \) ", string)string = re.sub(r"\?", " \? ", string)string = re.sub(r"\s{2,}", " ", string)return string.strip().lower()def process(text):text = clean_str(text)text = rm_tags(text)#text = text.lower()return textif __name__ == '__main__':generate_dataset()执行完后,产生train_test.npz 文件
2.3. 训练模型
1. 取数据集
def get_dataset_to_train():train_test = np.load('dataset/train_test.npz', allow_pickle=True)x_train = train_test['X_train']y_train = train_test['y_train']x_test = train_test['X_test']y_test = train_test['y_test']return x_train, y_train, x_test, y_test2. 创建模型
基于nnlm-en-dim50/2 预训练的文本嵌入向量,在模型外面加了两层全连接。
def get_model():hub_layer = hub.KerasLayer(embedding_url, input_shape=[], dtype=tf.string, trainable=True)# Build the modelmodel = Sequential([hub_layer,Dense(16, activation='relu'),Dropout(0.5),Dense(2, activation='softmax')])print(model.summary())model.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(),metrics=[keras.metrics.SparseCategoricalAccuracy()])return model还可以使用来自 TFHub 的许多其他预训练文本嵌入向量:
- google/nnlm-en-dim128/2 - 基于与 google/nnlm-en-dim50/2 相同的数据并使用相同的 NNLM 架构进行训练,但具有更大的嵌入向量维度。更大维度的嵌入向量可以改进您的任务,但可能需要更长的时间来训练您的模型。
- google/nnlm-en-dim128-with-normalization/2 - 与 google/nnlm-en-dim128/2 相同,但具有额外的文本归一化,例如移除标点符号。如果您的任务中的文本包含附加字符或标点符号,这会有所帮助。
- google/universal-sentence-encoder/4 - 一个可产生 512 维嵌入向量的更大模型,使用深度平均网络 (DAN) 编码器训练。
还有很多!在 TFHub 上查找更多文本嵌入向量模型。
3. 评估你的模型
def evaluate_model(test_data, test_labels):model = load_trained_model()# Evaluate the modelresults = model.evaluate(test_data, test_labels, verbose=2)print("Test accuracy:", results[1])def load_trained_model():# model = get_model()# model.load_weights('./models/model_new1.h5')model = tf.keras.models.load_model('models_pb')return model4. 测试几个例子
def predict(real_data):model = load_trained_model()probabilities = model.predict([real_data]);print("probabilities :",probabilities)result = get_label(probabilities)return resultdef get_label(probabilities):index = np.argmax(probabilities[0])print("index :" + str(index))result_str = index_dic.get(str(index))# result_str = list(index_dic.keys())[list(index_dic.values()).index(index)]return result_strdef predict_my_module():# review = "I don't like it"# review = "this is bad movie "# review = "This is good movie"review = " this is terrible movie"# review = "This isn‘t great movie"# review = "i think this is bad movie"# review = "I'm not very disappoint for this movie"# review = "I'm not very disappoint for this movie"# review = "I am very happy for this movie"#neg:0 postive:1s = predict(review)print(s)if __name__ == '__main__':x_train, y_train, x_test, y_test = get_dataset_to_train()model = get_model()model = train(model, x_train, y_train, x_test, y_test)evaluate_model(x_test, y_test)predict_my_module()完整代码
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Dropout
import keras as keras
from keras.callbacks import EarlyStopping, ModelCheckpoint
import tensorflow_hub as hubembedding_url = "https://tfhub.dev/google/nnlm-en-dim50/2"index_dic = {"0":"negative", "1": "positive"}def get_dataset_to_train():train_test = np.load('dataset/train_test.npz', allow_pickle=True)x_train = train_test['X_train']y_train = train_test['y_train']x_test = train_test['X_test']y_test = train_test['y_test']return x_train, y_train, x_test, y_testdef get_model():hub_layer = hub.KerasLayer(embedding_url, input_shape=[], dtype=tf.string, trainable=True)# Build the modelmodel = Sequential([hub_layer,Dense(16, activation='relu'),Dropout(0.5),Dense(2, activation='softmax')])print(model.summary())model.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(),metrics=[keras.metrics.SparseCategoricalAccuracy()])return modeldef train(model , train_data, train_labels, test_data, test_labels):# train_data, train_labels, test_data, test_labels = get_dataset_to_train()train_data = [tf.compat.as_str(tf.compat.as_bytes(str(x))) for x in train_data]test_data = [tf.compat.as_str(tf.compat.as_bytes(str(x))) for x in test_data]train_data = np.asarray(train_data) # Convert to numpy arraytest_data = np.asarray(test_data) # Convert to numpy arrayprint(train_data.shape, test_data.shape)early_stop = EarlyStopping(monitor='val_sparse_categorical_accuracy', patience=4, mode='max', verbose=1)# 定义ModelCheckpoint回调函数# checkpoint = ModelCheckpoint( './models/model_new1.h5', monitor='val_sparse_categorical_accuracy', save_best_only=True,# mode='max', verbose=1)checkpoint_pb = ModelCheckpoint(filepath="./models_pb/", monitor='val_sparse_categorical_accuracy', save_weights_only=False, save_best_only=True)history = model.fit(train_data[:2000], train_labels[:2000], epochs=45, batch_size=45, validation_data=(test_data, test_labels), shuffle=True,verbose=1, callbacks=[early_stop, checkpoint_pb])print("history", history)return modeldef evaluate_model(test_data, test_labels):model = load_trained_model()# Evaluate the modelresults = model.evaluate(test_data, test_labels, verbose=2)print("Test accuracy:", results[1])def predict(real_data):model = load_trained_model()probabilities = model.predict([real_data]);print("probabilities :",probabilities)result = get_label(probabilities)return resultdef get_label(probabilities):index = np.argmax(probabilities[0])print("index :" + str(index))result_str = index_dic.get(str(index))# result_str = list(index_dic.keys())[list(index_dic.values()).index(index)]return result_strdef load_trained_model():# model = get_model()# model.load_weights('./models/model_new1.h5')model = tf.keras.models.load_model('models_pb')return modeldef predict_my_module():# review = "I don't like it"# review = "this is bad movie "# review = "This is good movie"review = " this is terrible movie"# review = "This isn‘t great movie"# review = "i think this is bad movie"# review = "I'm not very disappoint for this movie"# review = "I'm not very disappoint for this movie"# review = "I am very happy for this movie"#neg:0 postive:1s = predict(review)print(s)if __name__ == '__main__':x_train, y_train, x_test, y_test = get_dataset_to_train()model = get_model()model = train(model, x_train, y_train, x_test, y_test)evaluate_model(x_test, y_test)predict_my_module()相关文章:
利用(Transfer Learning)迁移学习在IMDB数据上训练一个文本分类模型
1. 背景 有些场景下,开始的时候数据量很小,如果我们用一个几千条数据训练一个全新的深度机器学习的文本分类模型,效果不会很好。这个时候你有两种选择,1.用传统的机器学习训练,2.利用迁移学习在一个预训练的模型上训练…...
pom.xml格式化快捷键
在软件开发和编程领域,"格式化"通常指的是将代码按照一定的规范和风格进行排列,以提高代码的可读性和维护性。格式化代码有助于使代码结构清晰、统一,并符合特定的编码规范。 格式化可以包括以下方面: 缩进:…...

【短文】【踩坑】可以在Qt Designer给QTableWidge添加右键菜单吗?
2023年11月18日,周六上午 今天早上在网上找了好久都没找到教怎么在Qt Designer给QTableWidge添加右键菜单的文章 答案是:不可以 在Qt Designer中无法直接为QTableWidget添加右键菜单。 Qt Designer主要用于创建界面布局和设计,无法直接添加…...

Git常用配置
git log 美化输出 全局配置参数 git config --global alias.lm "log --no-merges --color --dateformat:%Y-%m-%d %H:%M:%S --authorghost --prettyformat:%Cred%h%Creset - %Cgreen(%cd)%C(yellow)%d%Cblue %s %C(bold blue)<%an>%Creset --abbrev-commit"…...

力扣每日一题-数位和相等数对的最大和-2023.11.18
力扣每日一题:数位和相等数对的最大和 开篇 这道每日一题还是挺需要思考的,我绕晕了好久,根据题解的提示才写出来。 题目链接:2342.数位和相等数对的最大和 题目描述 代码思路 1.创建一个数组存储每个数位的数的最大值,创建一…...
【win32_001】win32命名规、缩写、窗口
整数类型 bool类型 使用注意: 一般bool 的false0;true1 | 2 | …|n false是为0,true是非零 不建议这样用: if (result TRUE) // Wrong! 因为result不一定只返回1(true),当返回2时,…...
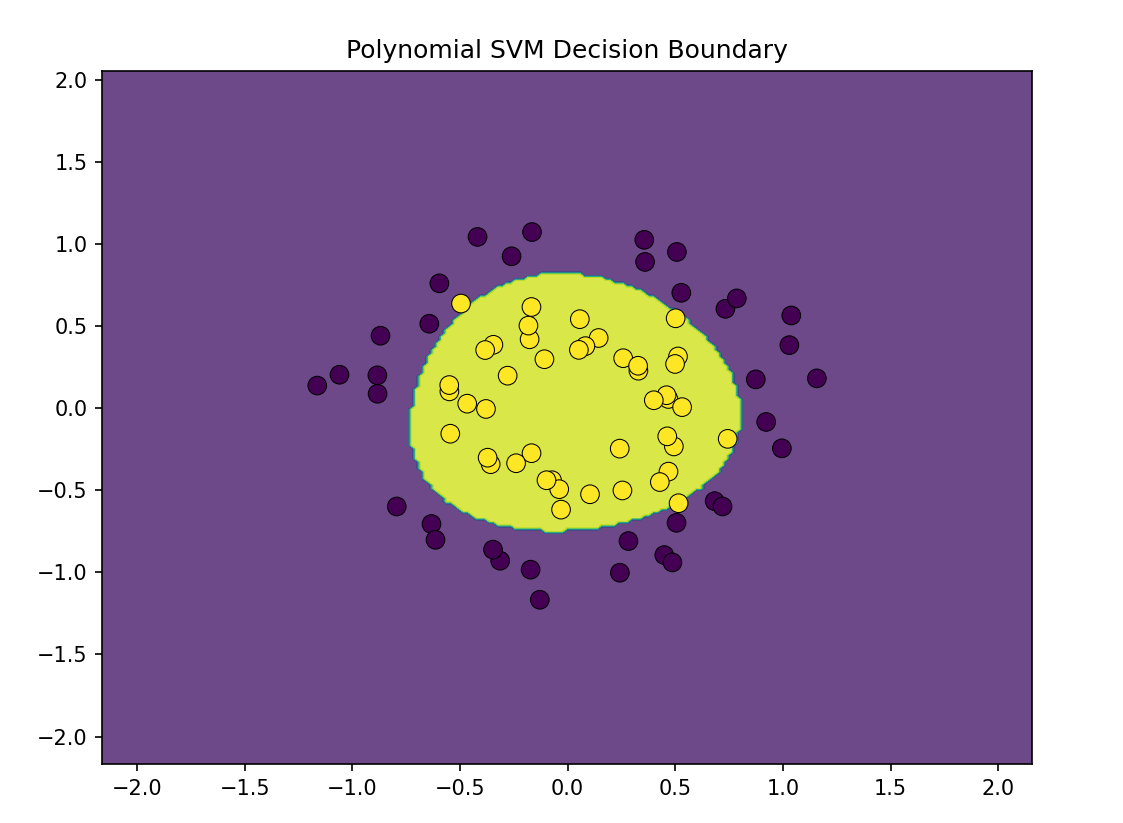
机器学习第8天:SVM分类
文章目录 机器学习专栏 介绍 特征缩放 示例代码 硬间隔与软间隔分类 主要代码 代码解释 非线性SVM分类 结语 机器学习专栏 机器学习_Nowl的博客-CSDN博客 介绍 作用:判别种类 原理:找出一个决策边界,判断数据所处区域来识别种类 简单…...

AI工具合集
网站:未来百科 | 为发现全球优质AI工具产品而生 (6aiq.com) 如今,AI技术涉及到了很多领域,比如去水印、一键抠图、图像处理、AI图像生成等等。站长之家之前也分享过一些,但是在网上要搜索找到它们还是费一些功夫。 今天发现了一…...

代码随想录算法训练营Day 54 || 392.判断子序列、115.不同的子序列
392.判断子序列 力扣题目链接(opens new window) 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,&quo…...
和puts())
C 语言 gets()和puts()
C 语言 gets()和puts() gets()和puts()在头文件stdio.h中声明。这两个函数用于字符串的输入/输出操作。 C gets()函数 gets()函数使用户可以输入一些字符,然后按Enter键。 用户输入的所有字符都存储在字符数组中。 空字符将添加到数组以使其成为字符串。 gets()允…...

核—幂零分解
若向量空间 V \mathcal V V存在子空间 X \mathcal X X与 Y \mathcal Y Y,当 X Y V X ∩ Y 0 \mathcal {X\text{}Y\text{}V}\\ \mathcal {X}\cap \mathcal {Y}0 XYVX∩Y0 时称子空间 X \mathcal X X与 Y \mathcal Y Y是完备的,其中记为 X ⊕ Y V \ma…...

轻松掌控财务,分析账户花销,明细记录支出情况
随着科技的发展,我们的生活变得越来越智能化。然而,对于许多忙碌的现代人来说,管理财务可能是一件令人头疼的事情。复杂的账单、花销、收入,这些可能会让你感到无从下手。但现在,我们有一个全新的解决方案——一款全新…...

竞赛 题目:基于机器视觉opencv的手势检测 手势识别 算法 - 深度学习 卷积神经网络 opencv python
文章目录 1 简介2 传统机器视觉的手势检测2.1 轮廓检测法2.2 算法结果2.3 整体代码实现2.3.1 算法流程 3 深度学习方法做手势识别3.1 经典的卷积神经网络3.2 YOLO系列3.3 SSD3.4 实现步骤3.4.1 数据集3.4.2 图像预处理3.4.3 构建卷积神经网络结构3.4.4 实验训练过程及结果 3.5 …...

11. Spring源码篇之实例化前的后置处理器
简介 spring在创建Bean的过程中,提供了很多个生命周期,实例化前就是比较早的一个生命周期,顾名思义就是在Bean被实例化之前的处理,这个时候还没实例化,只能拿到该Bean的Class对象,如果在这个时候直接返回一…...

Python-Python高阶技巧:HTTP协议、静态Web服务器程序开发、循环接收客户端的连接请求
版本说明 当前版本号[20231114]。 版本修改说明20231114初版 目录 文章目录 版本说明目录HTTP协议1、网址1.1 网址的概念1.2 URL的组成1.3 知识要点 2、HTTP协议的介绍2.1 HTTP协议的概念及作用2.2 HTTP协议的概念及作用2.3 浏览器访问Web服务器的过程 3、HTTP请求报文3.1 H…...

P1304 哥德巴赫猜想
题目描述 输入一个偶数 N,验证 4∼N 所有偶数是否符合哥德巴赫猜想:任一大于 22 的偶数都可写成两个质数之和。如果一个数不止一种分法,则输出第一个加数相比其他分法最小的方案。例如 1010,10=3+7=5+510=3+7=5+5,则 10=5+510=5+5 是错误答案。 输入格式 第一行输入一个…...
)
CSDN每日一题学习训练——Python版(搜索插入位置、最大子序和)
版本说明 当前版本号[20231118]。 版本修改说明20231118初版 目录 文章目录 版本说明目录搜索插入位置题目解题思路代码思路参考代码 最大子序和题目解题思路代码思路参考代码 搜索插入位置 题目 给定一个排序数组和一个目标值,在数组中找到目标值,…...

Java在物联网中的重要性
【点我-这里送书】 本人详解 作者:王文峰,参加过 CSDN 2020年度博客之星,《Java王大师王天师》 公众号:JAVA开发王大师,专注于天道酬勤的 Java 开发问题中国国学、传统文化和代码爱好者的程序人生,期待你的关注和支持!本人外号:神秘小峯 山峯 转载说明:务必注明来源(…...

动态规划解背包问题
题目 题解 def knapsac(W: int, N: int, wt: List[int], val: List[int]) -> int:# 定义状态动作价值函数: dp[i][j],对于前i个物品,当前背包容量为j,最大的可装载价值dp [[0 for j in range(W1)] for i in range(N1)]# 状态动作转移for…...

PCL内置点云类型
PCL内置了许多点云类型供我们使用,下面先介绍PLC内置的点云数据类型 PCL中的点云类型为PointT;至于为什么是PointT类型需要追随到原来的ros开发中去,因为PCL库也是从原来的ROS中剥离出来的;大家都一致的认为点云结构是离散的N维信…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...

SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南
SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...