hive sql 行列转换 开窗函数 炸裂函数
hive sql 行列转换 开窗函数 炸裂函数
准备原始数据集
学生表 student.csv
讲师表 teacher.csv
课程表 course.csv
分数表 score.csv
员工表 emp.csv
雇员表 employee.csv
电影表 movie.txt
学生表 student.csv
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,1995-04-30,男
004,刘德华,1998-08-28,男
005,唐国强,1993-09-10,男
006,陈道明,1992-11-12,男
007,陈坤,1999-04-09,男
008,吴京,1994-02-06,男
009,郭德纲,1992-12-05,男
010,于谦,1998-08-23,男
011,潘长江,1995-05-27,男
012,杨紫,1996-12-21,女
013,蒋欣,1997-11-08,女
014,赵丽颖,1990-01-09,女
015,刘亦菲,1993-01-14,女
016,周冬雨,1990-06-18,女
017,范冰冰,1992-07-04,女
018,李冰冰,1993-09-24,女
019,邓紫棋,1994-08-31,女
020,宋丹丹,1991-03-01,女
讲师表 teacher.csv
1001,张高数
1002,李体音
1003,王子文
1004,刘丽英
课程表 course.csv
01,语文,1003
02,数学,1001
03,英语,1004
04,体育,1002
05,音乐,1002
分数表 score.csv
001,01,94
002,01,74
004,01,85
005,01,64
006,01,71
007,01,48
008,01,56
009,01,75
010,01,84
011,01,61
012,01,44
013,01,47
014,01,81
015,01,90
016,01,71
017,01,58
018,01,38
019,01,46
020,01,89
001,02,63
002,02,84
004,02,93
005,02,44
006,02,90
007,02,55
008,02,34
009,02,78
010,02,68
011,02,49
012,02,74
013,02,35
014,02,39
015,02,48
016,02,89
017,02,34
018,02,58
019,02,39
020,02,59
001,03,79
002,03,87
004,03,89
005,03,99
006,03,59
007,03,70
008,03,39
009,03,60
010,03,47
011,03,70
012,03,62
013,03,93
014,03,32
015,03,84
016,03,71
017,03,55
018,03,49
019,03,93
020,03,81
001,04,54
002,04,100
004,04,59
005,04,85
007,04,63
009,04,79
010,04,34
013,04,69
014,04,40
016,04,94
017,04,34
020,04,50
005,05,85
007,05,63
009,05,79
015,05,59
018,05,87
员工表 emp.csv
7369,张三,研发,800.00,30
7499,李四,财务,1600.00,20
7521,王五,行政,1250.00,10
7566,赵六,销售,2975.00,40
7654,侯七,研发,1250.00,30
7698,马八,研发,2850.00,30
7782,金九,行政,2450.0,30
7788,银十,行政,3000.00,10
7839,小芳,销售,5000.00,40
7844,小明,销售,1500.00,40
7876,小李,行政,1100.00,10
7900,小元,讲师,950.00,30
7902,小海,行政,3000.00,10
7934,小红明,讲师,1300.00,30
7934,小红,讲师,1300.00,
雇员表 employee.csv
张无忌,男,1980/02/12,2022/08/09,销售,3000,12000,阿朱_小昭,张小无:8_张小忌:9
赵敏,女,1982/05/18,2022/09/10,行政,9000,2000,阿三_阿四,赵小敏:8
宋青书,男,1981/03/15,2022/04/09,研发,18000,1000,王五_赵六,宋小青:7_宋小书:5
周芷若,女,1981/03/17,2022/04/10,研发,18000,1000,王五_赵六,宋小青:7_宋小书:5
郭靖,男,1985/03/11,2022/07/19,销售,2000,13000,南帝_北丐,郭芙,5_郭襄:4
黄蓉,女,1982/12/13,2022/06/11,行政,12000,null,东邪_西毒,郭芙,5_郭襄:4
杨过,男,1988/01/30,2022/08/13,前台,5000,null,郭靖_黄蓉,杨小过:2
小龙女,女,1985/02/12,2022/09/24,前台,6000,null,张三_李四,杨小过:2
电影表 movie.txt
《疑犯追踪》-悬疑,动作,科幻,剧情
《Lie to me》-悬疑,警匪,动作,心理,剧情
《战狼2》-战争,动作,灾难
订单表 order.csv
1,1001,小元,2022-01-01,10
2,1002,小海,2022-01-02,15
3,1001,小元,2022-02-03,23
4,1002,小海,2022-01-04,29
5,1001,小元,2022-01-05,46
6,1001,小元,2022-04-06,42
7,1002,小海,2022-01-07,50
8,1001,小元,2022-01-08,50
9,1003,小辉,2022-04-08,62
10,1003,小辉,2022-04-09,62
11,1004,小猛,2022-05-10,12
12,1003,小辉,2022-04-11,75
13,1004,小猛,2022-06-12,80
14,1003,小辉,2022-04-13,94
创建数据库和数据表
create database chap06;
use chap06;
-- 学生表 student.csv
create external table student (stu_id string comment '学生ID',stu_name string comment '学生姓名',birthday string comment '出生日期',gender string comment '学生性别'
)row format delimited fields terminated by ','lines terminated by '\n'stored as textfilelocation '/quiz03/student';load data local inpath '/root/data/data02/student.csv' overwrite into table student;select * from student;-- 讲师表 teacher.csv
create external table teacher (tea_id string comment '课程ID',tea_name string comment '课程名称'
)row format delimited fields terminated by ','lines terminated by '\n'stored as textfilelocation '/quiz03/teacher';load data local inpath '/root/data/data02/teacher.csv' overwrite into table teacher;select * from teacher;-- 课程表 course.csv
create external table course (course_id string comment '课程ID',course_name string comment '课程名称',tea_id string comment '讲师ID'
)row format delimited fields terminated by ','lines terminated by '\n'stored as textfilelocation '/quiz03/course';load data local inpath '/root/data/data02/course.csv' overwrite into table course;select * from course;-- 分数表 score.csv
create external table score (stu_id string comment '学生ID',course_id string comment '课程ID',score int comment '成绩'
)row format delimited fields terminated by ','lines terminated by '\n'stored as textfilelocation '/quiz03/score';load data local inpath '/root/data/data02/score.csv' overwrite into table score;
select * from score;-- 员工表 emp.csv
create external table emp (emp_id int comment '员工ID',emp_name string comment '员工姓名',emp_job string comment '员工岗位',emp_salary decimal(8,2) comment '员工薪资',dept_id int comment '员工隶属部门ID'
)row format delimited fields terminated by ','lines terminated by '\n'stored as textfilelocation '/quiz01/emp';
load data local inpath '/root/data/data02/emp.csv' overwrite into table emp;
select * from emp;-- 雇员表 employee.csv
create external table employee(name string comment '姓名',sex string comment '性别',birthday string comment '出生年月',hiredate string comment '入职日期',job string comment '岗位',salary int comment '薪资',bonus int comment '奖金',friends array<string> comment '朋友',children map<string,int> comment '孩子'
)row format delimited fields terminated by ','collection items terminated by '_'map keys terminated by ':'lines terminated by '\n'stored as textfilelocation '/quiz04/employee';
load data local inpath '/root/data/data02/employee.csv' into table employee;
select * from employee;-- 电影表 movie.txt
create external table movie(name string comment '电影名称',category string comment '电影分类'
)row format delimited fields terminated by '-'lines terminated by '\n'stored as textfilelocation '/quiz04/movie';
load data local inpath '/root/data/data02/movie.txt' into table movie;
select * from movie;-- 订单表 order.csv
create external table `order`
(order_id string comment '订单id',user_id string comment '用户id',user_name string comment '用户姓名',order_date string comment '下单日期',order_amount int comment '订单金额'
)row format delimited fields terminated by ','lines terminated by '\n'stored as textfilelocation '/quiz04/order';
load data local inpath '/root/data/data02/order.csv' into table `order`;
select * from `order`;
行列转换
列转行
create table test (stu_name string,course_name string,score int
);
insert into test values ('张三','语文','80'),('张三','数学','90'), ('李四','语文','85'),('李四','数学','95');
select * from test;
select stu_name,max(case when course_name = '语文' then score end) as yuwen,max(case when course_name = '数学' then score end) as shuxuefrom test group by stu_name;

-- 多个值转为集合 collect_list 不会去重
select collect_list(emp_job) job_list from emp;
-- 多个值转为集合 collect_set 会去重
select collect_set(emp_job) job_set from emp;
-- size 获取结合中元素的数量
select size(collect_set(emp_job)) job_count from emp;
-- concat_ws 将多个数据 以分隔符形式 拼接 concat_ws(分隔符,数据1,数据2,...)
select concat_ws('-',collect_set(emp_job)) job_string from emp;
-- split 字符串切分 以分隔符切分字符串 为集合
select split(concat_ws('-',collect_set(emp_job)),'-') job_item from emp;
行专列
create table sales (emp_name string,january int,february int,march int
);
insert into sales values ('张三',1000,2000,3000),('李四',1500,2500,3500);
select * from sales;

将转换后的结果还原
select t1.emp_name,sale_list[0] january,sale_list[1] february,sale_list[2] marchfrom(select t.emp_name,collect_list(sale) sale_list from(select emp_name,'january' yue, january sale from salesunion allselect emp_name,'february' yue,february sale from salesunion allselect emp_name,'march' yue,march sale from sales) tgroup by t.emp_name) t1;
UDF UDTF UDAF
UDF,即用户定义函数(user-defined function),作用于单行数据,并且产生一个数据行作为输出。
Hive中大多数函数都属于这一类,比如数学函数和字符串函数。UDF函数的输入与输出值是1:1关系。
UDTF,即用户定义表生成函数(user-defined table-generating function),
作用于单行数据,并且产生多个数据行。UDTF函数的输入与输出值是1:n的关系。
UDAF,用户定义聚集函数(user-defined aggregate function),作用于多行数据,产生一个输出数据行。
Hive中像COUNT、MAX、MIN和SUM这样的函数就是聚集函数。UDAF函数的输入与输出值是n:1的关系。
explode
array
select explode(array('java','python','scala','go')) as course;
map
select explode(map('name','李昊哲','gender','1')) as (key,value);
posexplode
select posexplode(array('java','python','scala','go')) as (pos,course);
inline
select inline(array(named_struct('id',1,'name','李昊哲','gender','1'),named_struct('id',2,'name','李哲','gender','0'),named_struct('id',3,'name','李大宝','gender','1')))as (id,name,gender);
lateral view
select * from employee lateral view explode(friends) t as friend;
select * from employee lateral view explode(children) t as children_name,children_age;
select * from employeelateral view explode(friends) t1 as friendlateral view explode(children) t2 as children_name,children_age;
select name, sex, birthday, hiredate, job, salary, bonus, friend,children_name,children_age from employee elateral view explode(friends) t1 as friendlateral view explode(children) t2 as children_name,children_age;
UDTF 案例
根据电影信息表,统计各分类的电影数量
select cate,count(name) as quantity from movielateral view explode(split(category,',')) tmp as categroup by cate;
窗口函数(开窗函数)
能为每行数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行
Function(arg1,…, argn) OVER ([PARTITION BY <…>] [ORDER BY <…>] [<window_expression>])
其中Function(arg1,…, argn) 可以是下面分类中的任意一个
聚合函数:比如sum max min avg count等
分析函数:比如lead lag first_value last_value等
排序函数:比如row_number rank dense_rank等
OVER [PARTITION BY <…>] 类似于group by 用于指定分组 每个分组你可以把它叫做窗口
如果没有PARTITION BY 那么整张表的所有行就是一组
[ORDER BY <…>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
[<window_expression>] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
聚合函数
聚合函数
rows 基于行
range 基于值
函数() over(rows between and 3)
- unbounded preceding 表示从前面的起点
- number preceding 往前
- current row 当前行
- number following 往后
- unbounded following 表示到后面的终点
统计每个用户截至每次下单的累计下单总额
select *,sum(order_amount) over (partition by user_id ,substr(order_date,1,7)order by order_daterows between unbounded preceding and current row) sum_order_amountfrom `order`;
select *,sum(order_amount) over (partition by user_id ,substr(order_date,1,7)order by order_daterows unbounded preceding) sum_order_amountfrom `order`;
统计每个用户截至每次下单的当月累积下单总额
select *,sum(order_amount) over (partition by user_id ,substr(order_date,1,7)order by order_daterows between unbounded preceding and unbounded following) sum_order_amountfrom `order`;
最近三笔订单总金额
- 当前订单金额与前两笔订单金额的总和
- 当前订单金额与后两笔订单金额的总和
- 当前订单金额与前一笔订单和后一笔订单金额的总和
当前订单金额与前两笔订单金额的总和
select *,sum(order_amount) over (partition by user_idorder by order_daterows 2 preceding) sum_order_amountfrom `order`;
当前订单金额与后两笔订单金额的总和
select *,sum(order_amount) over (partition by user_idorder by order_daterows 2 following) sum_order_amountfrom `order`;
当前订单金额与前一笔订单和后一笔订单金额的总和
select *,sum(order_amount) over (partition by user_idorder by order_daterows between 1 preceding and 1 following) sum_order_amountfrom `order`;
分析函数 lag lead first_value last_value
lag lead
lag() over() 与 lead() over() 函数是跟偏移量相关的两个分析函数,
通过这两个函数可以在一次查询中取出同一字段的前 N 行的数据 (lag) 和后 N 行的数据 (lead) 作为独立的列,
从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且 LAG 和 LEAD 有更高的效率。
over() 表示 lag() 与 lead() 操作的数据都在 over() 的范围内,可以使用 partition by 语句(用于分组) order by 语句(用于排序)。
partition by a order by b 表示以 a 字段进行分组,再 以 b 字段进行排序,对数据进行查询。
例如:lag(field, num, defaultvalue) field 需要查找的字段,num 往前查找的 num 行的数据,defaultvalue 没有符合条件的默认值
例如:lead(field, num, defaultvalue) field 需要查找的字段,num 往后查找的 num 行的数据,defaultvalue 没有符合条件的默认值
统计每个用户每次下单距离上次下单相隔的天数(首次下单按0天算)
select order_id, user_id, user_name, order_date, order_amount from (select order_id, user_id, user_name, order_date, order_amount,lag(order_date,1,order_date) over (partition by user_id order by order_date) pre_order_datefrom `order`) t where datediff(order_date,pre_order_date) = 0;
每个用户每个月首笔订单时间
select order_id, user_id, user_name, order_date, order_amount from (select order_id, user_id, user_name, order_date, order_amount,lag(order_date,1,order_date) over (partition by user_id,substr(order_date,1,7) order by order_date) pre_order_datefrom `order`) t where datediff(order_date,pre_order_date) = 0;
每个用户每个月最后笔订单时间
select order_id, user_id, user_name, order_date, order_amount from (select order_id, user_id, user_name, order_date, order_amount,lead(order_date,1,order_date) over (partition by user_id,substr(order_date,1,7) order by order_date) next_order_datefrom `order`) t where datediff(order_date,next_order_date) = 0;
每个岗位先先入职的远哥和后入在的员工工资差
select name, sex, birthday, hiredate, job, salary, bonus, friends, children, new_salary,(salary - new_salary) salary_diff from (select name, sex, birthday, hiredate, job, salary, bonus, friends, children,lead(salary,1,salary) over (partition by job order by hiredate) new_salaryfrom employee) t;
first_value last_value
first_value 取每个分区内某列的第一个值
语法:first_value(col,true/false) over (partition by col1 order by col2)
第二个参数为true,跳过空值(默认为false)
last_value 取每个分区内某列的最后一个值
语法:last_value(col,true/false) over (partition by col1 order by col2)
第二个参数为true,跳过空值(默认为false)
每个用户每个月首笔订单时间
select order_id, user_id, user_name, order_date, order_amount,first_value(order_date) over (partition by user_id,substr(order_date,1,7) order by order_date) first_order_valuefrom `order`;
每个用户每个月最后笔订单时间
select order_id, user_id, user_name, order_date, order_amount,last_value(order_date) over (partition by user_id,substr(order_date,1,7) order by order_daterows between current row and unbounded following) last_order_valuefrom `order`;
每个用户每个月首笔订单时间和最后笔订单时间
select order_id, user_id, user_name, order_date, order_amount,first_value(order_date) over (partition by user_id,substr(order_date,1,7) order by order_date) first_order_value,last_value(order_date) over (partition by user_id,substr(order_date,1,7) order by order_daterows between current row and unbounded following) last_order_valuefrom `order`;
select order_id, user_id, user_name, order_date, order_amount, first_order_value, last_order_value from(select order_id, user_id, user_name, order_date, order_amount,first_value(order_date) over (partition by user_id,substr(order_date,1,7) order by order_date) first_order_value,last_value(order_date) over (partition by user_id,substr(order_date,1,7) order by order_daterows between current row and unbounded following) last_order_valuefrom `order`) t where order_date = first_order_value or order_date = last_order_value;
排序函数
分组排序取TopN
查询各科成绩前五名的学生
select a.course_id,a.stu_id,a.score from score aleft join score bon a.course_id = b.course_id and a.score <= b.scoregroup by a.stu_id,a.course_id,a.scorehaving count(a.stu_id) <=5order by a.course_id,a.score desc;
select S1.course_id,s1.stu_id,s1.score from score s1 where(select count(*) from score s2where s2.course_id=s1.course_id AND s2.score > s1.score) <= 5 order by s1.course_id,s1.score desc;
row_number
row_number() over () 连续序号
over()里头的分组以及排序的执行晚于 where 、group by、order by 的执行。
select * from(select course_id, stu_id, score,row_number() over (partition by course_id order by score desc ) as mumfrom score) t where mum <= 5;
rank
rank() over () 排名 跳跃排序 序号不是连续的
select * from(select course_id, stu_id, score,rank() over (partition by course_id order by score desc ) as mumfrom score) t where mum <= 5;
dense_rank
dense_rank() over () 排名 连续排序
select * from(select course_id, stu_id, score,dense_rank() over (partition by course_id order by score desc ) as mumfrom score) t where mum <= 5;
每个月每个消费总金额前三名的用户
select order_id, user_id, user_name, order_date, order_amount, total_order_amount, rank_total_order_amount from
(select order_id, user_id, user_name, order_date, order_amount, total_order_amount,dense_rank() over (partition by substr(order_date,1,7) order by total_order_amount desc) rank_total_order_amountfrom (select order_id, user_id, user_name, order_date, order_amount,sum(order_amount) over(partition by substr(order_date,1,7),user_id order by order_daterows between unbounded preceding and unbounded following) total_order_amountfrom `order`) t) t1 where rank_total_order_amount <= 3;
相关文章:
hive sql 行列转换 开窗函数 炸裂函数
hive sql 行列转换 开窗函数 炸裂函数 准备原始数据集 学生表 student.csv 讲师表 teacher.csv 课程表 course.csv 分数表 score.csv 员工表 emp.csv 雇员表 employee.csv 电影表 movie.txt 学生表 student.csv 001,彭于晏,1995-05-16,男 002,胡歌,1994-03-20,男 003,周杰伦,…...

Continuity” of stochastic integral wrt Brownian motion
See https://imathworks.com/math/math-continuity-of-stochastic-integral-wrt-brownian-motion/...
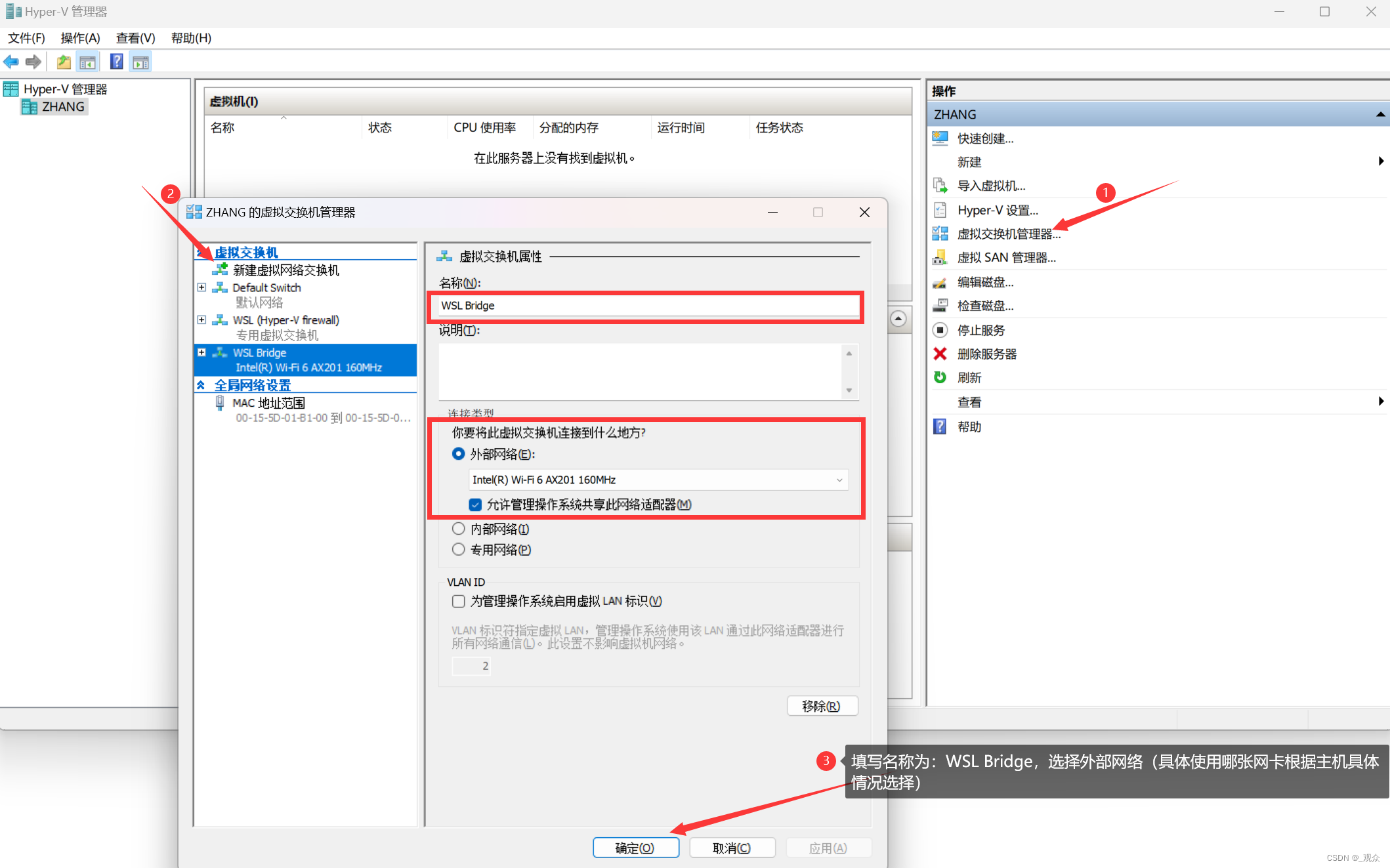
设置 wsl 桥接模式
一、环境要求 Win10/Win11 专业版,并已安装 Hyper-V 二、具体步骤 打开 Hyper-V 管理器 创建虚拟交换机 WSL Bridge 修改wsl配置文件 .wslconfig .wslconfig 文件所在路径如下: C:\Users\<UserName>\.wslconfig若 .wslconfig 文件不存在&am…...
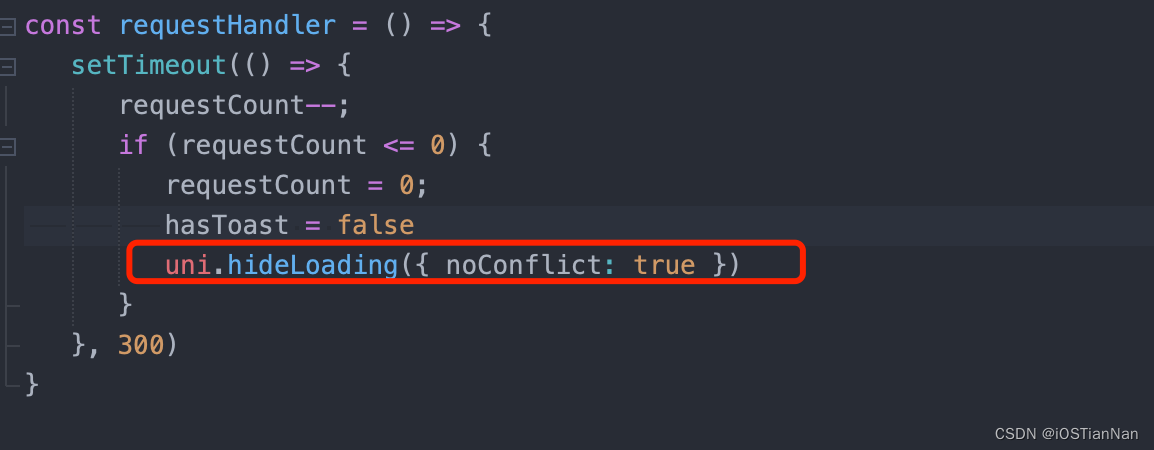
[uni-app] uni.showToast 一闪而过问题/设定时间无效/1秒即逝
toast一闪就消失 1.猜测频繁点击导致 – 排除 2.猜测再定时器内导致-- 排除 3.和封装的接口调用一起导致 - 是改原因 深挖发现: axios封装中, 对loading/hindloading进行了配置, 看来是 showToast 与 loading等冲突导致的 wx.hideLoading(Object object) 解决办法 再封装的…...

7、信息打点——资产泄露CMS识别Git监控SVNDS_Store备份
知识点: CMS指纹识别、源码获取方式习惯&配置&特征等获取方式托管资产平台资源搜索监控 如何获取源码 直接识别CMS,根据CMS获取网站源码。CMS直接识别工具:云悉指纹识别平台。识别不了CMS,则通过以下方式获取源码&…...

【运维篇】5.6 Redis server 主从复制配置
文章目录 0. 前言1. 配置方式步骤1: 准备硬件和网络步骤2: 安装Redis步骤3: 配置主服务器的Redis步骤4: 配置从服务器的Redis步骤5: 测试复制功能步骤6: 监控复制状态 2. 参考文档 0. 前言 在Redis运维篇的第5.6章节中,将讨论Redis服务器的主从复制配置。在开始之前…...
Hive语法,函数--学习笔记
1,排序处理 1.1cluster by排序 ,在Hive中使用order by排序时是全表扫描,且仅使用一个Reduce完成。 在海量数据待排序查询处理时,可以采用【先分桶再排序】的策略提升效率。此时, 就可以使用cluster by语法。 cluster…...

LeetCode热题100——动态规划
动态规划 1. 爬楼梯2. 杨辉三角3. 打家劫舍 1. 爬楼梯 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? // 题解:每次都有两种选择,1或者2 int climbStairs(int n) {if (n …...
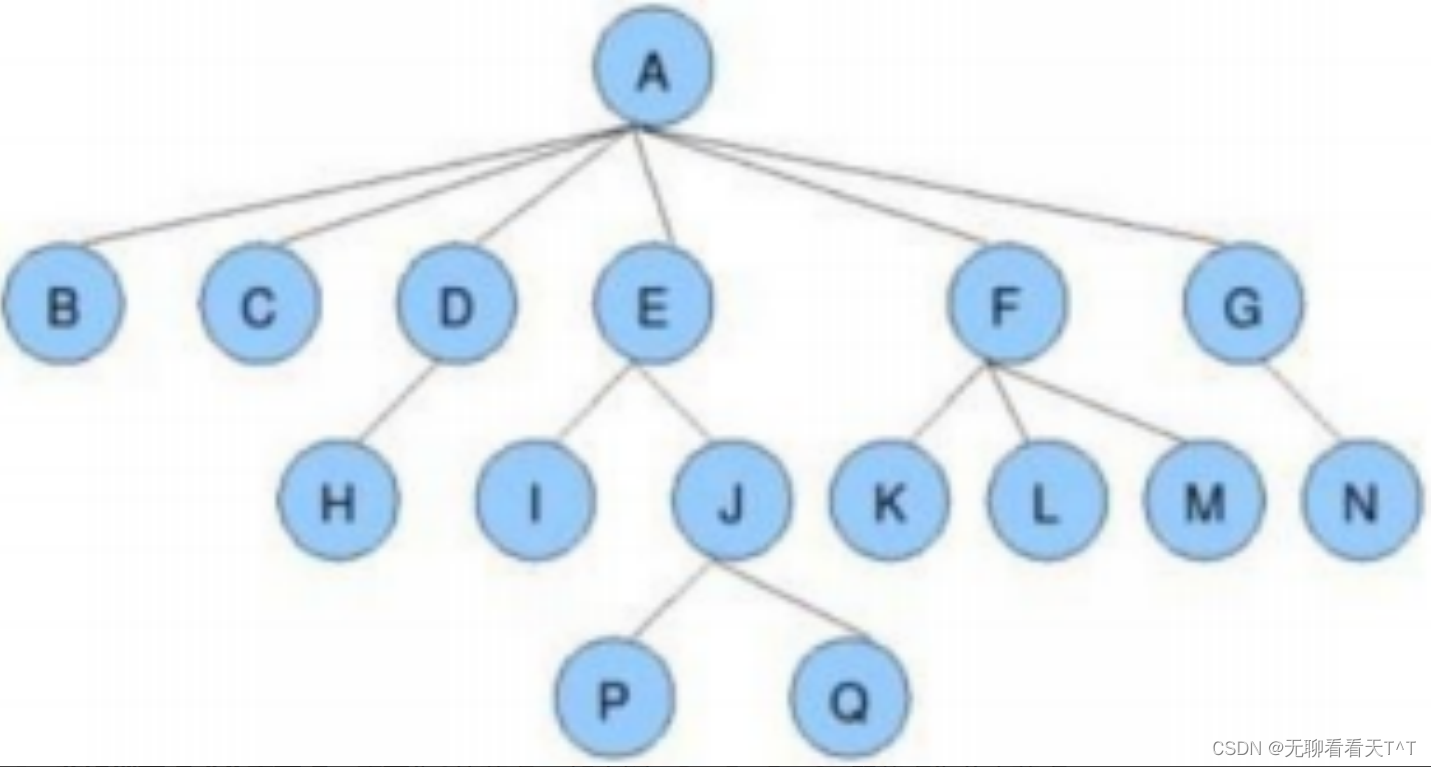
初识树(c语言)
树 定义:树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合。 有一个特殊的结点,称为根结点,根节点没有前驱结点 除根节点外,其余结点被分成M(M>0)个互不相交…...

听GPT 讲Rust源代码--src/librustdoc(2)
题图来自 Chromium项目将支持Rust编程语言[1] File: rust/src/librustdoc/html/render/search_index.rs 在Rust源代码中,rust/src/librustdoc/html/render/search_index.rs文件的作用是生成搜索索引,用于在Rust文档页面上进行关键字搜索。该文件实现了一…...
多目标应用:基于非支配排序的蜣螂优化算法NSDBO求解微电网多目标优化调度(MATLAB)
一、微网系统运行优化模型 微电网优化模型介绍: 微电网多目标优化调度模型简介_IT猿手的博客-CSDN博客 二、基于非支配排序的蜣螂优化算法NSDBO 基于非支配排序的蜣螂优化算法NSDBO简介: https://blog.csdn.net/weixin46204734/article/details/128…...

泉盛UV-K5/K6全功能中文固件
https://github.com/wu58430/uv-k5-firmware-chinese/releases 主要功能: 中文菜单 许多来自 OneOfEleven 的模块: AM 修复,显著提高接收质量长按按钮执行 F 操作的功能复制快速扫描菜单中的频道名称编辑频道名称 频率显示选项扫描列表分配…...

基于JPBC的无证书聚合签名方案实现
基于JPBC的无证书聚合签名方案实现 摘要 一开始签名方案是基于PKI的,无证书签名起源于 基于身份密码体制, 2009 年第一篇无证书签名方案1被提出,随后出现了一些列方案2,3;包括无配对的无证书聚合签名方案4,更多内容参考文献5. 暂时没有看见…...
FreeRTOS内存管理分析
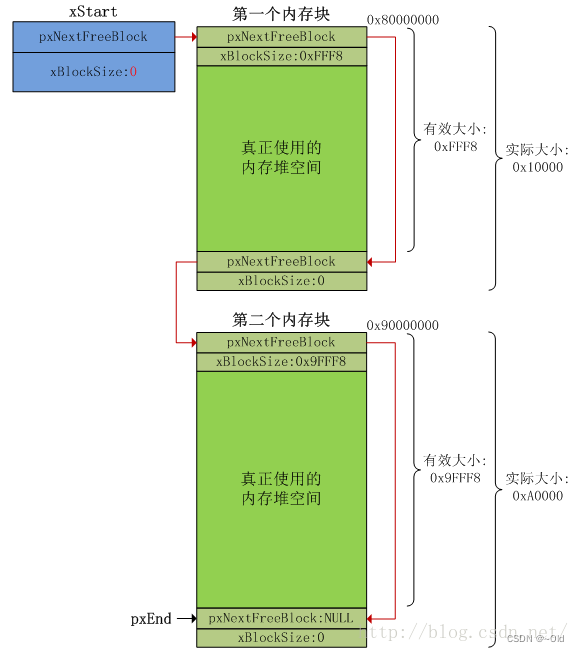
目录 heap_1.c内存管理算法 heap_2.c内存管理算法 heap_3.c内存管理算法 heap_4.c内存管理算法 heap_5.c内存管理算法 内存管理对应用程序和操作系统来说非常重要,而内存对于嵌入式系统来说是寸土寸金的资源,FreeRTOS操作系统将内核与内存管理分开实…...

hashMap索引原理
平日里面经常使用map这种数据结构,令人称奇的是他的访问速度为什么那么快?为什么可以通过key以接近O(1)的速度查找? 一、基础数据结构特点分析 1.1数组 查找的时间复杂度为O(1) 插入时间复杂度为O(n) 1.2链表 查找的时间复杂度为O(n) 插…...

qcow2、raw、vmdk等镜像格式工具
如果没有qemu,可以从这里下载安装:https://qemu.weilnetz.de/w64/...
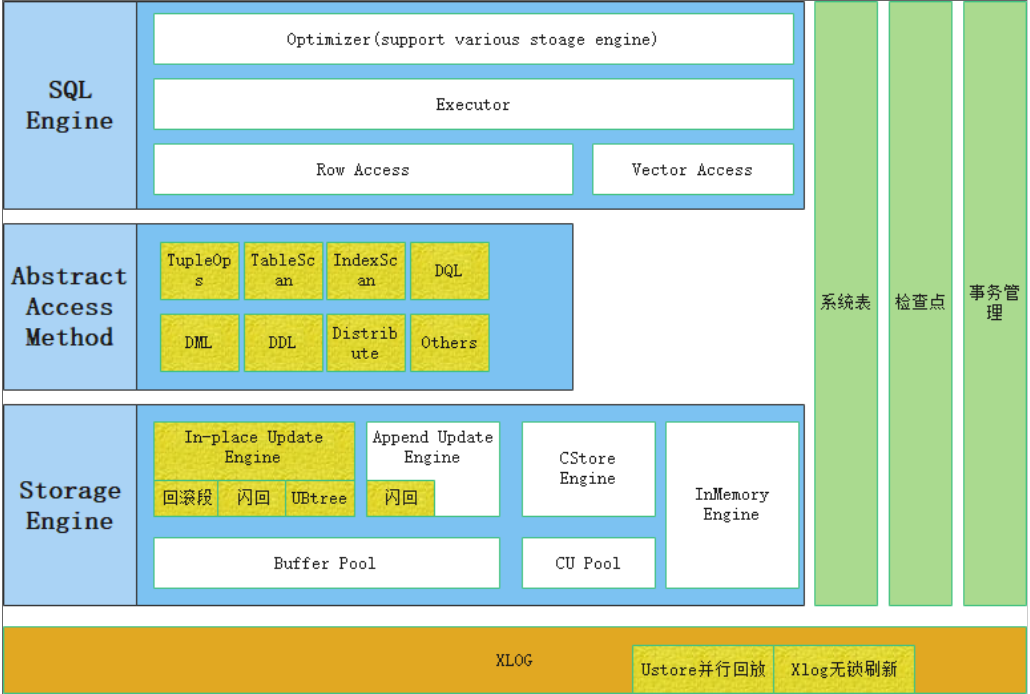
GaussDB新特性Ustore存储引擎介绍
1、 Ustore和Astore存储引擎介绍 Ustore存储引擎,又名In-place Update存储引擎(原地更新),是openGauss 内核新增的一种存储模式。此前的版本使用的行存储引擎是Append Update(追加更新)模式。相比于Append…...
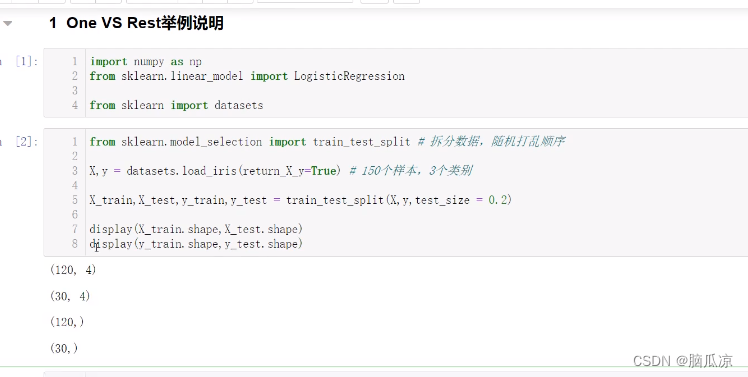
人工智能基础_机器学习046_OVR模型多分类器的使用_逻辑回归OVR建模与概率预测---人工智能工作笔记0086
首先我们来看一下什么是OVR分类.我们知道sigmoid函数可以用来进行二分类,那么多分类怎么实现呢?其中一个方法就是使用OVR进行把多分类转换成二分类进行计算. OVR,全称One-vs-Rest,是一种将多分类问题转化为多个二分类子问题的策略。在这种策略中,多分类问题被分解为若干个二…...
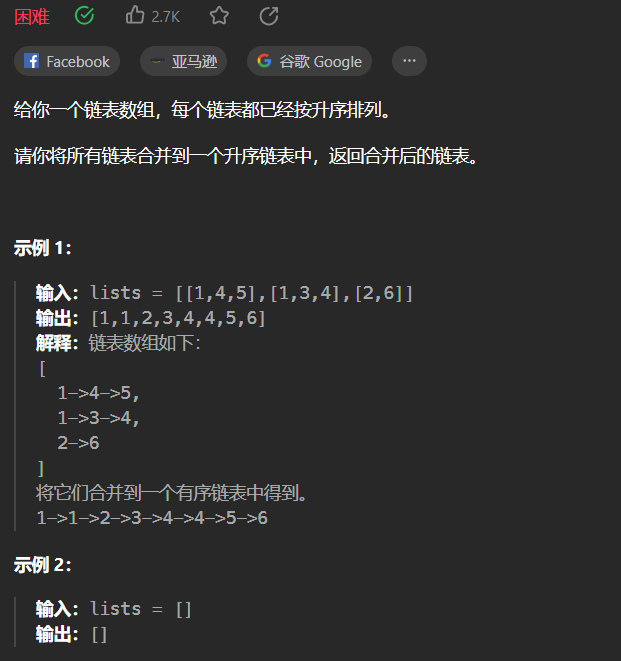
【LeetCode刷题-链表】--23.合并K个升序链表
23.合并K个升序链表 方法:顺序合并 在前面已经知道合并两个升序链表的前提下,用一个变量ans来维护以及合并的链表,第i次循环把第i个链表和ans合并,答案保存到ans中 /*** Definition for singly-linked list.* public class List…...

强化学习笔记
这里写自定义目录标题 参考资料基础知识16.3 有模型学习16.3.1 策略评估16.3.2 策略改进16.3.3 策略迭代16.3.3 值迭代 16.4 免模型学习16.4.1 蒙特卡罗强化学习16.4.2 时序差分学习Sarsa算法:同策略算法(on-policy):行为策略是目…...

AI代码巫师:基于OpenClaw的智能编程技能设计与实战
1. 项目概述:当AI化身“代码巫师”在软件开发这个行当里,我们每天都在和代码打交道。从构思一个功能,到把它变成一行行可执行的指令,再到调试、优化、部署,这个过程充满了创造性的乐趣,也伴随着无数令人头疼…...

基于MCP协议构建Slack AI助手:从原理到实践
1. 项目概述:一个连接Slack与AI模型的社区驱动桥梁 最近在折腾AI应用集成时,发现了一个挺有意思的项目: node2flow-th/slack-mcp-community 。乍一看这个名字,你可能觉得它就是个普通的GitHub仓库,但如果你恰好是Sl…...

视频生成模型在机器人操作中的应用与优化
1. 项目背景与核心挑战去年在实验室部署机械臂时,我们发现传统编程方式在面对新物体抓取任务时需要重新调整参数和轨迹规划。这促使我们开始探索如何让机器人具备"看一眼就会"的能力——这正是视频生成模型在机器人操作领域大显身手的契机。当前机器人操作…...

ChatRWKV:基于RNN架构的大语言模型部署与调优实战
1. 项目概述:一个“非Transformer”的大语言模型新选择如果你最近在关注大语言模型的开源生态,除了Llama、Mistral这些基于Transformer架构的明星项目,可能还听说过一个名字有点特别的仓库:ChatRWKV。它的全称是“Chat with RWKV”…...

全新安装 SQL Server 并直接设置数据目录到 E 盘 完整步骤
我给你整理了一份零踩坑、一次性成功的安装流程,跟着做就能彻底解决问题。 一、安装前准备 下载安装包官网下载地址(推荐 Developer 免费版):https://www.microsoft.com/zh-cn/sql-server/sql-server-downloads备份数据ÿ…...

安达发|食品业数字化转型:APS计划排产排程排单软件破解生产难题
安达发APS高级生产计划智能排产排程自动排单软件系统推荐_MES 在当今快消品市场竞争日益激烈的背景下,食品行业正面临着前所未有的挑战——原材料保质期短、订单波动频繁、生产工艺复杂、多品种小批量生产常态化。传统的手工排产或Excel表格管理早已难以应对这些复…...

收藏!小白程序员必看:OpenClaw“养龙虾”背后的AI大模型浪潮与机遇
OpenClaw等AI Agent工具的火爆,标志着大模型技术进入大众视野。文章探讨了AI对就业市场的双重影响:一方面,自动化可能取代重复性工作(如数据录入、客服),引发就业焦虑;另一方面,AI催…...

npm install报错errno -4077?可能是你的项目路径或Node版本埋的坑
npm install报错errno -4077?可能是你的项目路径或Node版本埋的坑 接手老项目或升级开发环境时,npm install突然抛出errno -4077错误,往往让开发者一头雾水。这个看似权限问题的错误代码,背后可能隐藏着项目路径、Node版本兼容性、…...

从硬件到固件:拆解一台老旧PC,用逻辑分析仪抓取RTC唤醒信号的完整流程
从硬件到固件:拆解一台老旧PC,用逻辑分析仪抓取RTC唤醒信号的完整流程 拆开一台2005年的戴尔OptiPlex 755商用主机,灰尘随着螺丝刀的转动簌簌落下。这台服役15年的老将主板上的ICH8南桥芯片,正是我们探索RTC唤醒机制的绝佳实验平台…...

WiFi 6智能管理:从OFDMA、TWT到云端优化,解决家庭网络拥堵实战
1. WiFi 6的潜力与隐忧:为什么“智能”比“更快”更重要 WiFi 6终于走进了千家万户。铺天盖地的宣传都在告诉你,它能带来飞一般的网速、更低的延迟,以及同时连接海量设备的能力。从技术规格上看,这无疑是无线网络的一次巨大飞跃。…...