使用 ClickHouse 做日志分析
原作:Monika Singh & Pradeep Chhetri
这是我们在 Monitorama 2022 上发表的演讲的改编稿。您可以在此处找到包含演讲者笔记的幻灯片和此处的视频。
当 Cloudflare 的请求抛出错误时,信息会记录在我们的 requests_error 管道中。错误日志用于帮助解决特定于客户或网络范围的问题。
我们,站点可靠性工程师 (SRE),负责管理日志平台。我们已经运行Elasticsearch集群很多年了,这些年来日志量急剧增加。随着日志量的增加,我们开始面临一些问题。查询性能慢、资源消耗高等。我们的目标是通过提高查询性能并提供经济高效的日志存储解决方案来改善日志消费者的体验。这篇博文讨论了日志记录管道的挑战以及我们如何设计新架构以使其更快且更具成本效益。
在我们深入探讨维护日志管道的挑战之前,让我们先了解一下日志的特征。
日志的特征
不可预测:当今世界,微服务数量众多,集中式日志系统将收到的日志量非常难以预测。日志体量估算如此困难的原因有多种。主要是因为新应用程序不断部署到生产中,现有应用程序会自动扩展或缩小以满足业务需求,或者有时应用程序所有者启用调试日志级别并忘记将其关闭。
上下文:对于调试问题,通常需要上下文信息,即事件发生之前和之后的日志。单个日志行几乎没有帮助,通常,是一组日志行有助于构建上下文。此外,我们经常需要将多个应用程序的日志关联起来以绘制全貌。因此,必须保留日志在数据源处填充的顺序。
写入密集型:任何集中式日志系统都是写入密集型的。超过 99% 的已写入日志从未被读取。它们占用空间一段时间,并最终被保留策略清除。剩下的不到1%的被读取的日志非常重要,我们不能错过它们。
日志管道
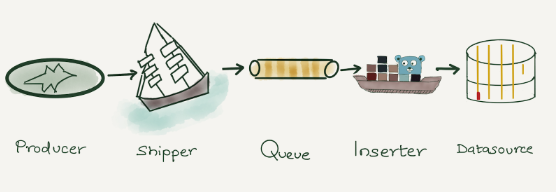
与大多数其他公司一样,我们的日志记录管道由生产者、路由转发器、队列、消费者和存储组成。
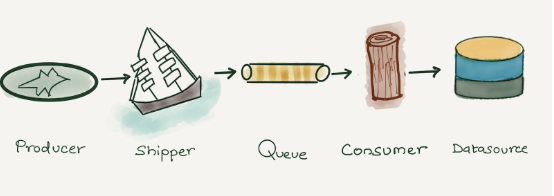
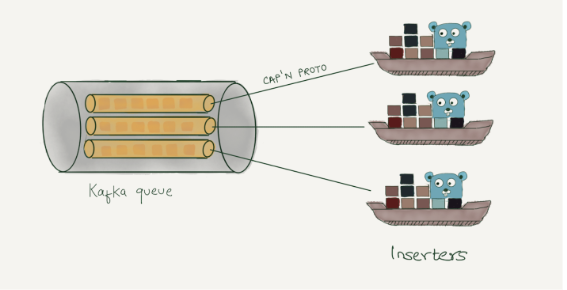
在 Cloudflare 全球网络上运行的应用程序(生产者)生成日志。这些日志以 Cap’n Proto 序列化格式在本地写入。 Shipper(内部解决方案)通过流将 Cap’n Proto 序列化日志推送到 Kafka(队列)进行处理。我们运行 Logstash(消费者),它从 Kafka 消费并将日志写入 ElasticSearch(数据存储)。然后使用 Kibana 或 Grafana 可视化数据。我们在 Kibana 和 Grafana 中内置了多个仪表板来可视化数据。
Cloudflare 的 Elasticsearch 瓶颈
在 Cloudflare,我们多年来一直运行 Elasticsearch 集群。多年来,日志量急剧增加,在优化 Elasticsearch 集群以处理此类量时,我们发现了一些限制。
Mapping 爆炸
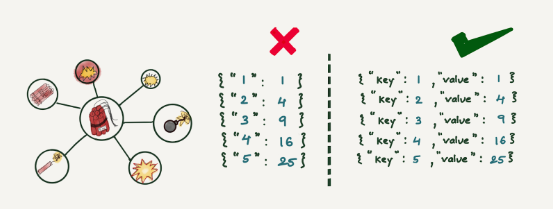
Mapping 爆炸是 Elasticsearch 众所周知的局限性之一。 Elasticsearch 维护一个映射,决定如何存储和索引新文档及其字段。当此映射中的键太多时,可能会占用大量内存,从而导致频繁的垃圾回收。防止这种情况的一种方法是使 schema 严格,这意味着任何不遵循此严格 schema 的日志行最终都会被删除。另一种方法是使其成为半严格的,这意味着不属于此映射的任何字段都将不可搜索。
多租户支持
Elasticsearch 没有很好的多租户支持。一个坏用户很容易影响集群性能。无法限制查询可以读取的文档或索引的最大数量或 Elasticsearch 查询可以占用的内存量。错误的查询很容易降低集群性能,即使查询完成后,它仍然会留下影响。
集群维护工作
管理Elasticsearch集群并不容易,尤其是多租户集群。一旦集群降级,就需要花费大量时间才能使集群恢复到完全健康的状态。在Elasticsearch中,更新索引模板意味着重新索引数据,这是一个相当大的开销。我们使用冷热分层存储,即最近的数据存储在 SSD 中,较旧的数据存储在机械硬盘中。虽然Elasticsearch每天都会将数据从热存储移动到冷存储,但它会影响集群的读写性能。
垃圾回收
Elasticsearch 使用 Java 开发并在 Java 虚拟机 (JVM) 上运行。它执行垃圾收集以回收由程序分配但不再引用的内存。Elasticsearch 需要垃圾收集调整。最新的 JVM 中默认的垃圾回收是 G1GC。我们尝试了其他 GC,例如 ZGC,这有助于减少 GC 暂停,但在读写吞吐量方面并没有给我们带来太多性能优势。
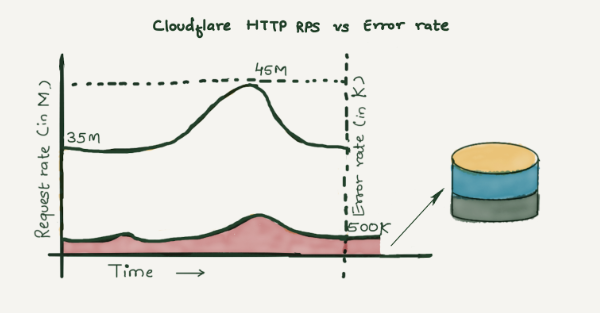
Elasticsearch 是一个很好的全文搜索工具,这些限制对于小型集群来说并不重要,但在 Cloudflare 中,我们每秒处理超过 35 到 4500 万个 HTTP 请求,其中每秒有超过 500K-800K 的请求失败。这些失败可能是由于不正确的请求、源服务器错误、用户配置错误、网络问题和各种其他原因造成的。
我们的客户支持团队使用这些错误日志作为定位客户问题的起点。错误日志包含有关 HTTP 请求所经过的各种 Cloudflare 产品的许多字段元数据。我们将这些错误日志存储在 Elasticsearch 中。我们对它们进行了大量采样,因为存储所有内容需要花费数百 TB 的空间,超出了我们的资源分配预算。此外,基于它构建的仪表板非常慢,因为它们需要对各个字段进行大量聚合。根据调试要求,我们需要将这些日志保留几周。
建议的解决方案
我们希望完全取消采样,即存储保留期内的每条日志行,为如此庞大的数据量提供快速查询支持,并在不增加成本的情况下实现这一切。为了解决所有这些问题,我们决定进行概念验证,看看是否可以使用 ClickHouse 来满足我们的要求。
Cloudflare 是 ClickHouse 的早期采用者,我们多年来一直在管理 ClickHouse 集群。我们已经拥有许多内部工具和库,用于将数据插入 ClickHouse,这使我们可以轻松进行概念验证。让我们看一下 ClickHouse 的一些功能,这些功能使其非常适合存储日志,并使我们能够构建新的日志管道。
ClickHouse 是一个面向列的数据库,这意味着与特定列相关的所有数据在物理上彼此相邻存储。即使在普通商用硬件上,这种数据布局也有助于快速顺序扫描。这使我们能够从老一代硬件中获得最大性能。
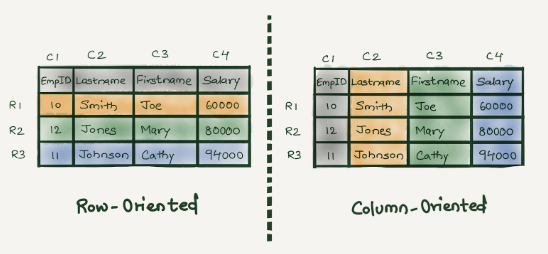
ClickHouse 专为分析工作负载而设计,数据可以有很多列。我们能够设计具有大量列的新 ClickHouse 表,而不会牺牲性能。
ClickHouse 索引的工作方式与关系数据库中的索引不同。在关系数据库中,主索引非常密集,并且每个表行包含一个条目。因此,如果表中有 100 万行,主索引也将有 100 万个条目。而在 ClickHouse 中,索引是稀疏的,这意味着每几千行只有一个索引条目。ClickHouse 索引使我们能够动态添加新索引。
ClickHouse 默认使用 LZ4 压缩所有内容。高效的压缩不仅有助于最大限度地减少存储需求,还可以让 ClickHouse 有效地使用页面缓存。
ClickHouse 的一项很酷的功能是可以按列配置压缩编解码器。我们决定为所有列保留默认的 LZ4 压缩。我们对 DateTime 列使用了 Double-Delta,对 Float 列使用了 Gorilla,对固定大小的 String 列使用了 LowCardinality。
ClickHouse是线性可扩展的;也就是说,写入可以通过添加新分片来扩展,读取可以通过添加新副本来扩展。ClickHouse 集群中的每个节点都是相同的。没有任何特殊节点有助于轻松扩展集群。
让我们看一下我们用来提供更快的读/写吞吐量和更好的日志数据压缩的一些优化。
Inserter
拥有高效的插入器与拥有高效的数据存储一样重要。在 Cloudflare,我们一直在运行相当多的分析管道,在编写新的插入器时我们借用了大部分概念。我们使用 Cap’n Proto 消息作为传输数据格式,因为它提供快速的数据编码和解码。扩展插入器很容易,可以通过添加更多 Kafka 分区并生成新的插入器 Pod 来完成。
Batch Size
将数据插入 ClickHouse 时的关键性能因素之一是批量大小。当批量较小时,ClickHouse 会创建许多小分区,然后将其合并为更大的分区。因此,较小的批量大小会给 ClickHouse 在后台带来额外的工作,从而降低 ClickHouse 的性能。因此,将其设置得足够大,以便 ClickHouse 可以愉快地接收数据批次,而不会达到内存限制,这一点至关重要。
数据模型
ClickHouse 提供内置的分片和复制,无需任何外部依赖。ClickHouse 的早期版本依赖于 ZooKeeper 来存储复制信息,但最新版本通过添加 clickhouse-keeper 消除了对 ZooKeeper 的依赖。
为了跨多个分片读取数据,我们使用分布式表,一种特殊的表。这些表本身不存储任何数据,而是充当存储实际数据的多个基础表的代理。
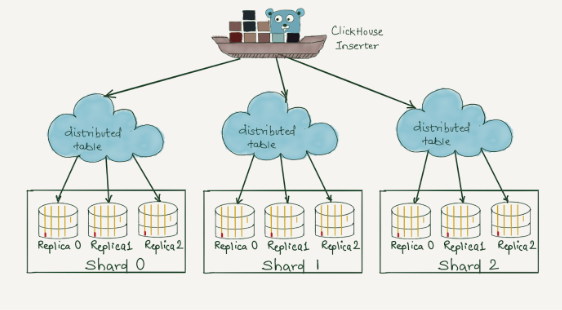
与任何其他数据库一样,选择正确的表 schema 非常重要,因为它将直接影响性能和存储利用率。我们想讨论将日志数据存储到 ClickHouse 中的三种方法。
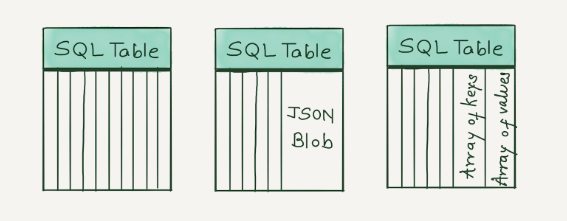
第一个是最简单且最严格的表模式,您可以在其中指定每个列名称和数据类型。任何具有此预定义 schema 之外的字段的日志行都将被删除。根据我们的经验,此架构将为您提供最快的查询性能。如果您已经知道前面所有可能字段的列表,我们建议使用它。您始终可以通过运行 ALTER TABLE 查询来添加或删除列。
第二种模式使用 ClickHouse 的一个非常新的功能,它完成了大部分繁重的工作。您可以将日志作为 JSON 对象插入,在幕后,ClickHouse 将了解您的日志架构并动态添加具有适当数据类型和压缩的新列。仅当您可以很好地控制日志架构并且总字段数小于 1,000 时,才应使用此架构。一方面,它提供了自动添加新列作为新日志字段的灵活性,但与此同时,一个糟糕的应用程序可以轻松地破坏 ClickHouse 集群。
第三种模式将相同数据类型的所有字段存储在一个数组中,然后使用 ClickHouse 内置数组函数来查询这些字段。即使字段超过 1,000 个,此架构也能很好地扩展,因为列数取决于日志中使用的数据类型。如果某个数组元素被频繁访问,可以利用ClickHouse的物化列功能将其取出作为专用列。我们建议采用此模式,因为它可以防止应用程序记录过多字段。
数据分区

分区是 ClickHouse 数据的一个单位。 ClickHouse 用户常犯的一个错误是分区键过于细化,导致分区过多。由于我们的日志管道每天都会生成 TB 级的数据,因此我们创建了使用toStartOfHour(dateTime)分区的表。通过这种分区逻辑,当查询在 WHERE 子句中带有时间戳时,ClickHouse 就会知道分区并快速检索它。它还有助于根据数据保留策略设计有效的数据清除规则。
主键选择

ClickHouse 将数据按主键排序存储在磁盘上。因此,选择主键会影响查询性能并有助于更好的数据压缩。与关系数据库不同,ClickHouse 不需要每行都有唯一的主键,我们可以插入具有相同主键的多行。拥有多个主键会对插入性能产生负面影响。ClickHouse 的重要限制之一是,一旦创建表,主键就无法更新。
Data skipping indexes
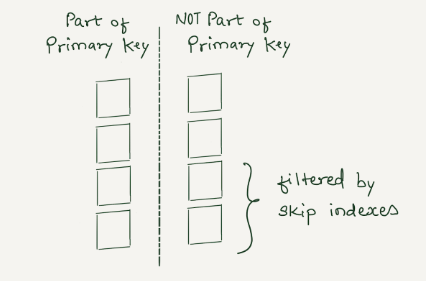
ClickHouse 查询性能与评估 WHERE 子句时是否可以使用主键成正比。我们有很多列,所有这些列都不能成为主键的一部分。因此,对这些列的查询将必须进行全面扫描,从而导致查询速度变慢。在传统数据库中,可以添加二级索引来处理这种情况。在 ClickHouse 中,我们可以添加另一类索引,称为数据跳过索引,它使用布隆过滤器并跳过读取保证不匹配的重要数据块。
ABR
我们在 requests_error 日志上构建了多个仪表板。加载这些仪表板通常会达到 ClickHouse 中为单个查询/用户设置的内存限制。
基于这些日志构建的仪表板主要用于识别异常情况。为了直观地识别指标中的异常情况,不需要确切的数字,但可以提供近似的数字。例如,要了解数据中心中错误的增加,我们不需要确切的错误数量。因此,我们决定使用围绕 ABR 概念构建的内部库和工具。
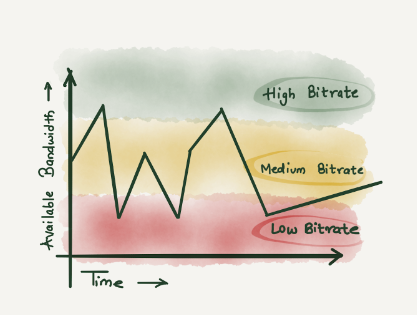
ABR 代表“自适应比特率” - 术语 ABR 主要用于视频流服务,其中服务器选择视频流的最佳分辨率以匹配客户端和网络连接。博客文章《解释 Cloudflare 的 ABR 分析》对此进行了详细描述。
换句话说,数据以多种分辨率或采样间隔存储,并为每个查询选择最佳解决方案。
ABR的工作方式是在向ClickHouse写入请求时,它将数据写入多个具有不同采样间隔的表中。例如table_1存储100%的数据,table_10存储10%的数据,table_100存储1%的数据,table_1000存储0.1%的数据等等。表之间的数据是重复的。 Table_10 将是 table_1 的子集。
Demo
在 Cloudflare 中,我们使用内部库和工具将数据插入 ClickHouse,但这可以通过使用开源工具 - vector.dev 来实现。如果您想测试 ClickHouse 的日志摄取是如何工作的,您可以参考或使用https://github.com/cloudflare/cloudflare-blog/tree/master/2022-08-log-analytics的演示。
确保您已安装 docker 并运行docker compose up即可开始。这将打开三个容器,Vector.dev 用于生成矢量演示日志,将其写入 ClickHouse,ClickHouse 容器用于存储日志,Grafana 实例用于可视化日志。当容器启动后,访问 http://localhost:3000/dashboards 来使用预构建的演示仪表板。
总结
日志本质上应该是不可变的,而 ClickHouse 最适合处理不可变的数据。我们能够将关键且重要的日志生成应用程序之一从 Elasticsearch 迁移到更小的 ClickHouse 集群。
inserter 端的 CPU 和内存消耗减少了八倍。每个使用 600 字节的 Elasticsearch 文档在 ClickHouse 中减少到每行 60 字节。这种存储增益使我们能够在较新的集群中存储 100% 的事件。在查询方面,99分位的查询延迟也显著改善。
Elasticsearch 非常适合全文搜索,ClickHouse 非常适合分析!
不管是日志分析还是指标体系,都少不了监控告警。很多公司都会同时使用多个监控系统(云上的、云下的),导致监控事件散落各处,人员维护多份,缺少了告警聚合降噪、排班协同的能力。我们团队做了9年开源监控系统,深知大家的痛点,特推出 FlashDuty 事件 OnCall 中心的产品,一站式解决告警难题。
- 产品介绍地址:https://flashcat.cloud/product/flashduty/
- 产品注册体验:https://console.flashcat.cloud/
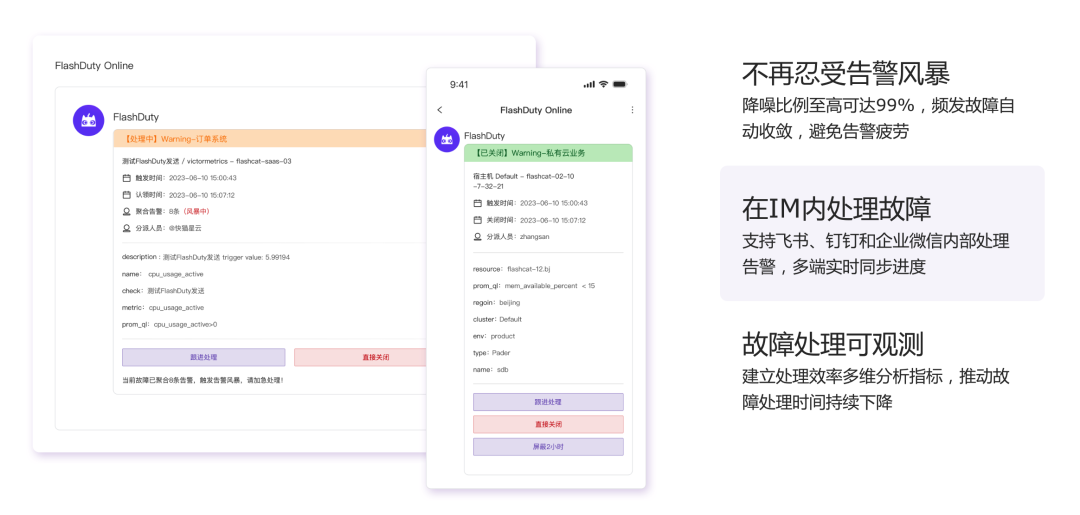
🛎️ 中心化告警处理,在正确的时间通知正确的人
💸 每一分钟都很关键,降低故障时间,就是赚钱
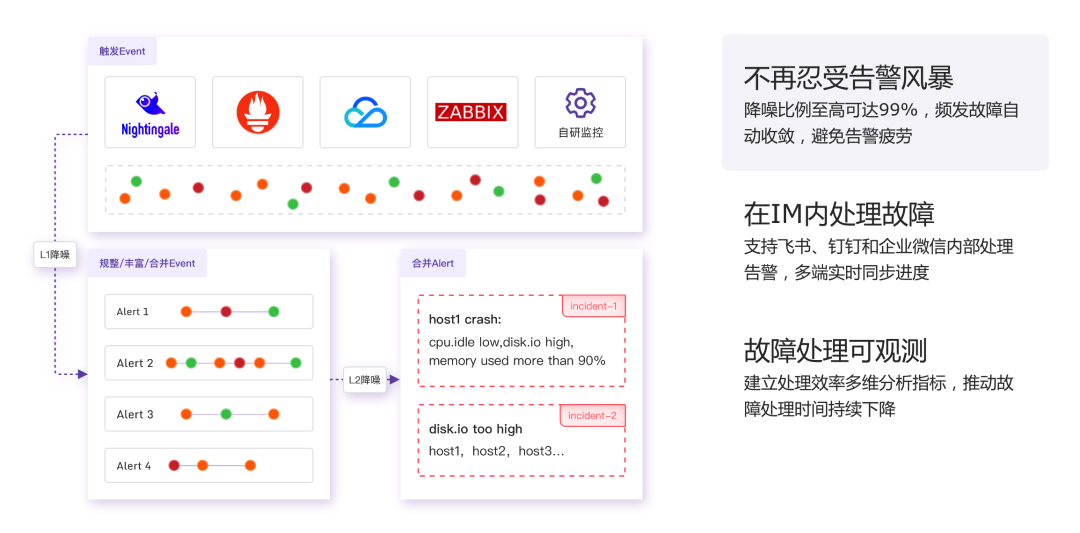
🖇️ 您常用的监控系统,我们都可以集成

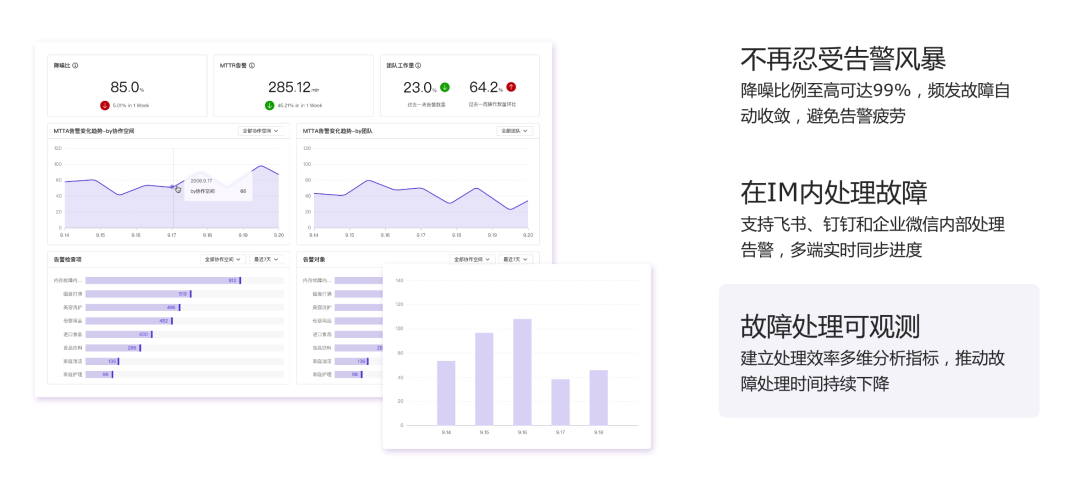
告警事件的及时处理,对于线上稳定性保障至关重要。一款中心式的告警事件 OnCall 中心,去除告警风暴,确保告警不遗漏,还能分析故障处理的MTTA、MTTR等效率指标,您的团队值得拥有,快来免费体验起来吧:FlashDuty - 一站式告警响应平台。
相关文章:
使用 ClickHouse 做日志分析
原作:Monika Singh & Pradeep Chhetri 这是我们在 Monitorama 2022 上发表的演讲的改编稿。您可以在此处找到包含演讲者笔记的幻灯片和此处的视频。 当 Cloudflare 的请求抛出错误时,信息会记录在我们的 requests_error 管道中。错误日志用于帮助解…...
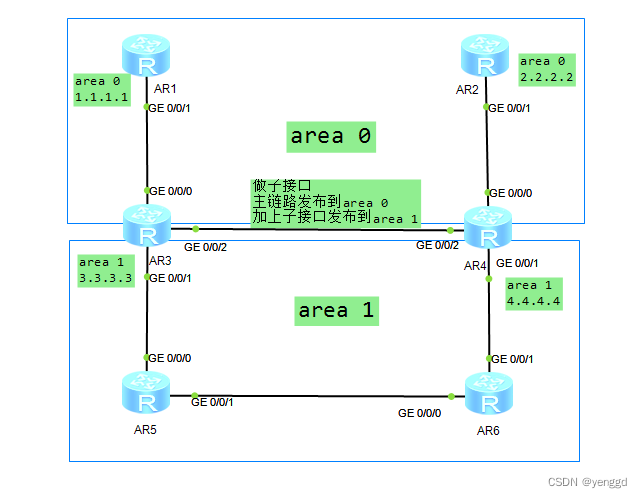
华为ospf路由协议防环和次优路径中一些难点问题分析
第一种情况是ar3的/0/0/2口和ar4的0/0/2口发布在区域1时,当ar1连接ar2的线断了以后,骨干区域就断了,1.1.1.1到2.2.2.2就断了,ping不通了。但ar5和ar6可以ping通2.2.2.2和1.1.1.1,ar3和ar4不可以ping通2.2.2.2和1.1.1.1…...
python-opencv划痕检测-续
python-opencv划痕检测-续 这次划痕检测,是上一次划痕检测的续集。 处理的图像如下: 这次划痕检测,我们经过如下几步: 第一步:读取灰度图像 第二步:进行均值滤波 第三步:进行图像差分 第四步࿱…...

c++[string实现、反思]
我的码云 我的string码云 分析总结 1.项目结构 所有的类和函数需要在namespace中实现,要和string高度对应 private:char* _str;//字符串size_t _size;//有效长度size_t _capacity;//总空间,包括\0const static size_t npos-1;2.定义变量 <1> 所…...

c++版本opencv计算灰度图像的轮廓点
代码 #include<iostream> #include<opencv.hpp>int main() {std::string imgPath("D:\\prostate_run\\result_US_20230804_141531\\mask\\us\\104.bmp");cv::Mat imgGray cv::imread(imgPath, 0);cv::Mat kernel cv::getStructuringElement(cv::MORPH…...

【05】ES6:函数的扩展
一、函数参数的默认值 ES6 允许为函数的参数设置默认值,即直接写在参数定义的后面。 1、基本用法 默认值的生效条件 不传参数,或者明确的传递 undefined 作为参数,只有这两种情况下,默认值才会生效。 注意:null 就…...
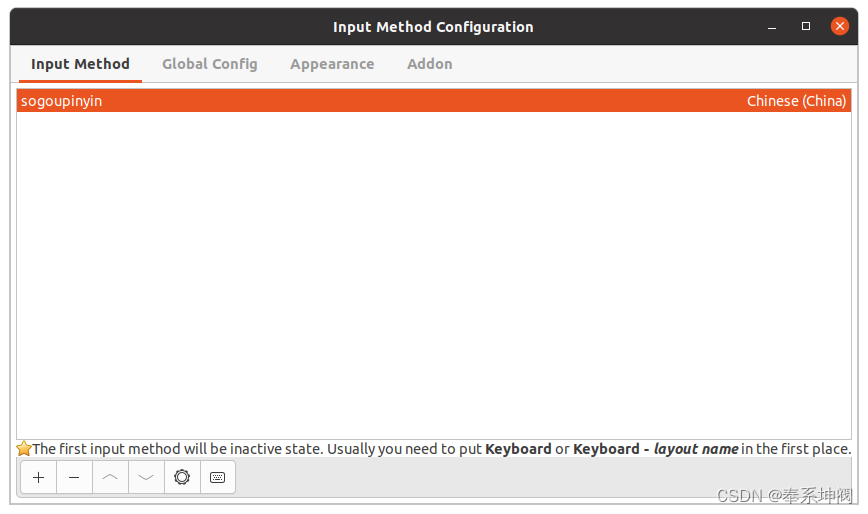
Ubuntu20.04安装搜狗输入法
1、安装包下载 搜狗输入法linux-首页搜狗输入法for linux—支持全拼、简拼、模糊音、云输入、皮肤、中英混输https://shurufa.sogou.com/linux点击立即下载,根据自己的硬件选择deb安装包。 2、输入法安装 当第一步完成以后,页面会自动跳转至搜狗的安装…...

linux的基础命令
文章目录 linux的基础命令一、linux的目录结构(一)Linux路径的描述方式 二、Linux命令入门(一)Linux命令基础格式 三、ls命令(一)HOME目录和工作目录(二)ls命令的参数1.ls命令的-a选…...

linux查询某个进程使用的内存量
linux查询某个进程使用的内存量 查进程用的内存,查看进程占用的内存量,centos查询内存使用 查某个进程id使用的内存量 ps -p 24450 -o rss | awk {print int($1/1024)"MB"} 该命令的含义是: ps -p 24450: 查找进程ID为24450的进…...

list的总结
目录 1.什么是list 1.1list 的优势和劣势 优势: 劣势: 2.构造函数 2.1 default (1) 2.2 fill (2) 2.3 range (3) 2.4 copy (4) 3.list iterator的使用 3.1. begin() 3.2. end() 3.3迭代器遍历 4. list容量函数 4.1. empty() 4.2. siz…...
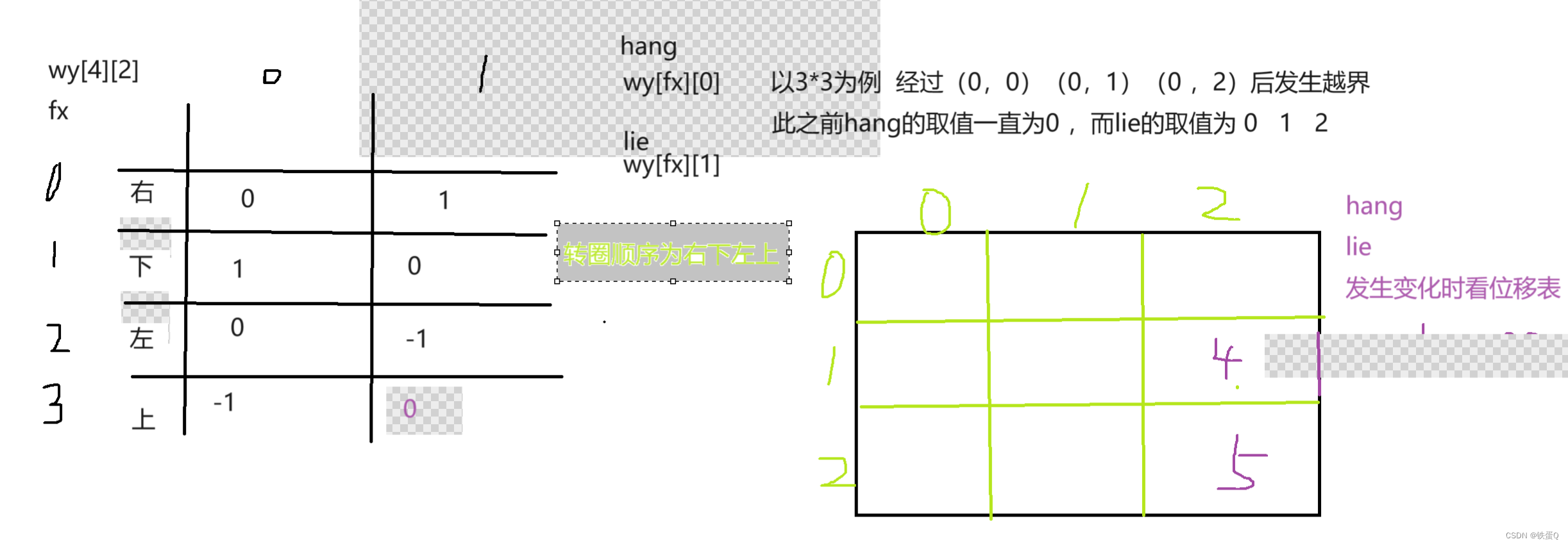
c语言数字转圈
数字转圈 题干输入整数 N(1≤N≤9),输出如下 N 阶方阵。 若输入5显示如下方阵: * 1** 2** 3** 4** 5* *16**17**18**19** 6* *15**24**25**20** 7* *14**23**22**21** 8* *13**12**11**10** 9*输入样例3输出样例* 1*…...
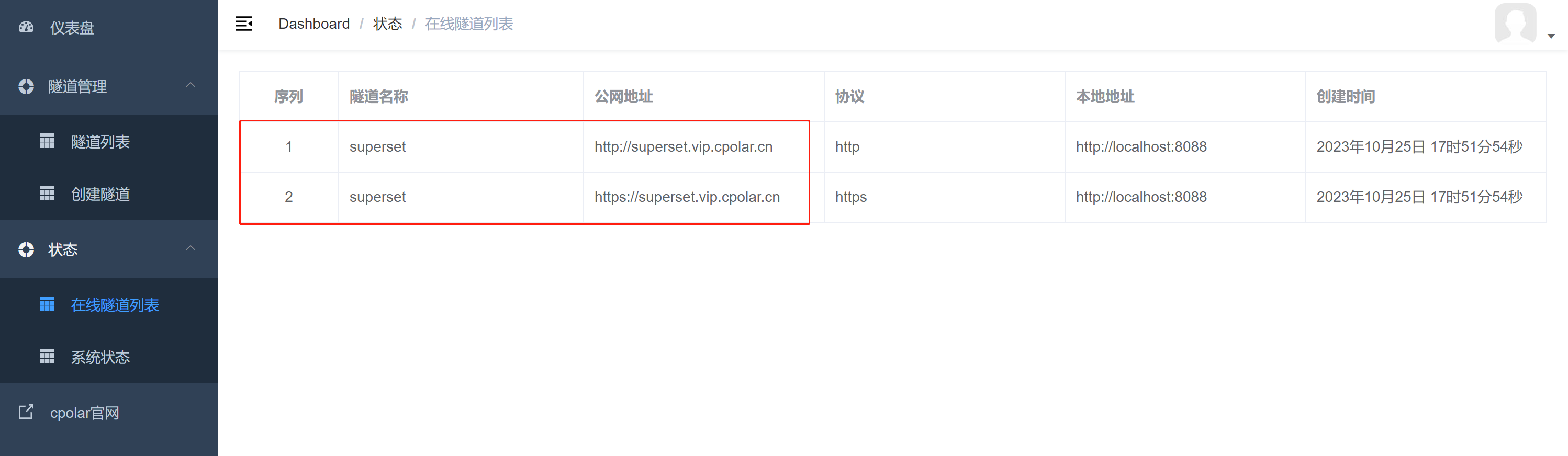
Apache Superset数据分析平台如何实现公网实时远程访问数据【内网穿透】
文章目录 前言1. 使用Docker部署Apache Superset1.1 第一步安装docker 、docker compose1.2 克隆superset代码到本地并使用docker compose启动 2. 安装cpolar内网穿透,实现公网访问3. 设置固定连接公网地址 前言 Superset是一款由中国知名科技公司开源的“现代化的…...
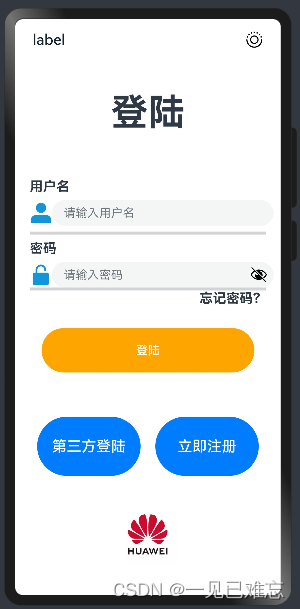
HarmonyOS应用开发实战—登录页面【ArkTS】
文章目录 本页面实战效果预览图一.HarmonyOS应用开发1.1HarmonyOS 详解1.2 ArkTS详解二.HarmonyOS应用开发实战—登录页面【ArkTS】2.1 ArkTS页面源码2.2 代码解析2.3 心得本页面实战效果预览图 一.HarmonyOS应用开发 1.1HarmonyOS 详解 HarmonyOS(鸿蒙操作系统)是华为公司…...

@RequestMapping
目录 作用: 位置: 属性 1.value 2.method 3.params 4.header 作用: 该注解是一个用来处理请求地址映射的注解。 位置: 可用于映射一个请求或一个方法,可以用在类或方法上。 用于方法上,表示在类的…...

操作系统 应用题 例题+参考答案(考研真题)
1.(考研真题)一个多道批处理系统中仅有P1和P2两个作业,P2比P1晚5ms到达,它们的计算和I/O操作顺序如下。 P1:计算60ms,I/O 80ms,计算20ms。 P2:计算120ms,I/O 40ms&…...
免费获取GPT-4的五种工具
不可否认,由OpenAI带来的GPT-4已是全球最受欢迎的、功能最强大的大语言模型(LLM)之一。大多数人都需要使用ChatGPT Plus的订阅服务去访问GPT-4。为此,他们通常需要每月支付20美元。那么问题来了,如果您不想每月有这笔支…...

XTU OJ 1146 矩阵乘法学习笔记
原题 题目描述 给你两个矩阵A(n*k),B(k*m),请求A*B。 输入 第一行是一个整数K,表示样例的个数。 每个样例包含两个矩阵A和B。 每个矩阵的第一行是两个整数n,m,(1≤n,m≤10)表示矩阵的行和列 以后的n行,每行m个整数,每个整数的绝对值不超过…...
基于官方YOLOv4开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】
本文是关于基于YOLOv4开发构建目标检测模型的超详细实战教程,超详细实战教程相关的博文在前文有相应的系列,感兴趣的话可以自行移步阅读即可:《基于yolov7开发实践实例分割模型超详细教程》 《YOLOv7基于自己的数据集从零构建模型完整训练、…...

1、Docker概述与安装
相关资源网站: ● docker官网:http://www.docker.com ● Docker Hub仓库官网: https://hub.docker.com/ 注意,如果只是想看Docker的安装,可以直接往下拉跳转到Docker架构与安装章节下的Docker具体安装步骤,一步步带你安…...

论文笔记——FasterNet
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。 为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由…...

NVIDIA Profile Inspector终极指南:如何通过驱动级调优彻底解决游戏卡顿问题
NVIDIA Profile Inspector终极指南:如何通过驱动级调优彻底解决游戏卡顿问题 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否遇到过游戏帧率突然骤降、画面出现撕裂,或者操…...

DownKyi:解锁B站视频自由存取的数字工具箱
DownKyi:解锁B站视频自由存取的数字工具箱 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等)。 …...

SRC漏洞挖掘全攻略|从入门到变现,网安新手必看
2026 SRC漏洞挖掘全攻略|从入门到变现,网安新手必看 对于网安新手、计算机相关专业学生而言,想合法积累实战经验、赚取额外收入、丰富简历亮点,SRC漏洞挖掘绝对是最优路径。不同于CTF的竞技性、护网的高强度,SRC&#…...

手把手教你部署通义千问3-VL-Reranker-8B:从本地到公网HTTPS访问全流程
手把手教你部署通义千问3-VL-Reranker-8B:从本地到公网HTTPS访问全流程 1. 通义千问3-VL-Reranker-8B简介 通义千问3-VL-Reranker-8B是一款强大的多模态重排序服务,能够对文本、图像和视频进行混合检索与排序。这个8B参数量的模型支持32k上下文长度和3…...
)
用STM32F103C8T6+ESP8266搞定OneNET数据上传,手把手教你从零配置到云端显示(附完整代码)
从零构建STM32ESP8266物联网终端:OneNET平台数据上传与命令下发实战指南 引言:为什么选择STM32ESP8266组合? 在智能家居、工业监测等物联网应用场景中,低成本、高可靠性的硬件组合始终是开发者的首选。STM32F103C8T6作为ARM Corte…...

BitNet b1.58入门必看:从supervisord进程管理到WebUI调参完整指南
BitNet b1.58入门必看:从supervisord进程管理到WebUI调参完整指南 1. 项目概述 BitNet b1.58-2B-4T-gguf是一款极致高效的开源大模型,采用原生1.58-bit量化技术。这个模型最特别的地方在于它的权重只有-1、0、1三种值,平均每个权重仅占用1.…...

real-anime-z应用场景:动漫社团微信公众号推文配图自动化生成流程
real-anime-z应用场景:动漫社团微信公众号推文配图自动化生成流程 1. 引言:动漫社团的配图痛点 运营动漫社团微信公众号的小伙伴们,是否经常遇到这样的困扰: 每周需要制作大量推文配图,但社团美编人手有限原创插画成…...

PX4定点漂移别急着调参!先学会用Flight Review分析飞行日志定位问题
PX4定点漂移问题深度诊断:用Flight Review从数据中揪出真凶 无人机在定点模式下出现水平漂移,就像汽车在平坦路面上无故偏离车道一样令人困扰。许多飞手的第一反应是盲目调整控制器参数,这往往治标不治本。真正的高手会先打开飞行日志&#x…...

2026做一个简单基础的商城小程序最低多少钱?
2026年,小程序商城仍是中小商家线上拓客的核心选择,不少创业者、个体户最关心的问题的是:做一个满足基础卖货需求的商城小程序,最低需要花多少钱?其实,基础商城小程序的成本没有固定答案,核心取…...

支付宝沙箱验签踩坑记:Hutool JSONObject格式化参数设置不当引发的invalid-signature
支付宝沙箱验签失败深度解析:Hutool JSON格式化参数引发的隐形陷阱 当你在Java项目中集成支付宝支付功能时,是否遇到过这样的场景:本地测试一切正常,但一旦接入沙箱环境就频繁报错"invalid-signature"?这个问…...