【深度学习笔记】01 数据操作与预处理
01 数据操作与预处理
- 一、数据操作
- 1.1 基本数据操作
- 1.2 广播机制
- 1.3 索引和切片
- 1.4 节省内存
- 1.5 转换为其他Python对象
- 二、数据预处理
- 读取数据集
- 处理缺失值
- 转换为张量格式
- 练习
一、数据操作
1.1 基本数据操作
导入torch
import torch
张量表示一个由数值组成的数组,这个数组可能有多个维度(轴)。具有一个轴的张量对应数学上的向量(vector),具有两个轴的张量对应数学上的矩阵(matrix),具有两个以上轴的张量没有特定的数学名称。
张量中的每个值称为张量的元素(element)。
# 使用arange创建一个行向量x
x = torch.arange(12)
x
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
可以通过张量的shape属性来访问张量(沿每个轴的长度)的形状(shape)
x.shape
torch.Size([12])
如果只想知道张量中元素的总数,即形状的所有元素乘积,可以检查它的大小(size)。因为这里处理的是一个向量,所以它的shape与size相同。
x.numel()
12
x.size()
torch.Size([12])
要想改变一个张量的形状而不改变元素数量和元素值,可以调用reshape函数
X = x.reshape(3, 4)
X
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
如果我们的目标形状是(高度,宽度),那么在知道宽度后,高度会被自动计算得出。我们可以通过-1来调用此自动计算出形状,即可以用x.reshape(-1, 4)获x.reshape(3, -1)来取代x.reshape(3, 4)。
使用全0、全1、其他常量或者从特定分布中随机采样的数字来初始化矩阵:
# 全0矩阵
torch.zeros((2, 3, 4))
tensor([[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]],[[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]]])
# 全1矩阵
torch.ones((2, 3, 4))
tensor([[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]],[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]]])
# 每个元素都从均值为0、标准差为1的标准高斯分布(正态分布)中随机采样的矩阵
torch.randn(3, 4)
tensor([[-0.1503, -0.1886, 0.3691, -0.5482],[ 1.1731, 0.1596, 1.1706, 0.0437],[ 0.0513, -0.5481, -0.7855, -0.9853]])
运算符:
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x / y, x ** y # **运算符表示求幂运算
(tensor([ 3., 4., 6., 10.]),tensor([-1., 0., 2., 6.]),tensor([0.5000, 1.0000, 2.0000, 4.0000]),tensor([ 1., 4., 16., 64.]))
torch.exp(x) # 求幂
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
把多个张量连接(concatenate)在一起
X = torch.arange(12, dtype = torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim = 0), torch.cat((X, Y), dim = 1)
(tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]]),tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
逻辑运算符构建二元张量:
X == Y
tensor([[False, True, False, True],[False, False, False, False],[False, False, False, False]])
对张量中所有元素求和,会产生一个单元素张量
X.sum()
tensor(66.)
1.2 广播机制
在某些情况下,即使张量形状不同,我们仍然可以通过调用广播机制(broadcasting mechanism)来执行按元素操作。这种机制的工作方式如下:
(1)通过适当复制元素来扩展一个获两个数组,以便在转换之后,两个张量具有相同的形状;
(2)对生成的数组执行按元素操作。
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b
(tensor([[0],[1],[2]]),tensor([[0, 1]]))
a + b
tensor([[0, 1],[1, 2],[2, 3]])
1.3 索引和切片
与任何python数组一样,第一个元素的索引是0,最后一个元素的索引是-1;可以指定范围以包含第一个元素和最后一个之前的元素。
X[-1], X[1:3]
(tensor([ 8., 9., 10., 11.]),tensor([[ 4., 5., 6., 7.],[ 8., 9., 10., 11.]]))
除读取外,还可以通过制定索引将元素写入矩阵
X[1, 2] = 9
X
tensor([[ 0., 1., 2., 3.],[ 4., 5., 9., 7.],[ 8., 9., 10., 11.]])
如果想为多个元素赋相同的值,只需要索引所有元素,然后赋值。
X[0:2, :] = 12
X
tensor([[12., 12., 12., 12.],[12., 12., 12., 12.],[ 8., 9., 10., 11.]])
其中,[0:2, :]访问第1行和第2行,其中“:”代表沿轴1(列)的所有元素
1.4 节省内存
运行一些操作可能会导致为新结果分配内存。
例如,如果我们用Y = X + Y,将取消引用Y指向的张量,而是指向新分配的内存处的张量。
before = id(Y)
Y = Y + X
id(Y) == before
False
运行Y = Y + X后,会发现id(Y)指向另一个位置。
这是因为Python首先计算Y + X,为结果分配新的内存,然后使Y指向内存中的这个新位置。
这可能是不可取的,原因有两个:
- 首先,我们不想总是不必要地分配内存。在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新所有参数。通常情况下,我们希望原地执行这些更新;
- 如果我们不原地更新,其他引用仍然会指向旧的内存位置,这样我们的某些代码可能会无意中引用旧的参数。
执行原地操作非常简单。
我们可以使用切片表示法将操作的结果分配给先前分配的数组,例如Y[:] = 。
为了说明这一点,我们首先创建一个新的矩阵Z,其形状与另一个Y相同,
使用zeros_like来分配一个全0的块。
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
id(Z): 1343601274288
id(Z): 1343601274288
如果后续计算中没有重复使用X,也可以使用 X[:] = X + Y 或 X += Y 来减少操作的内存开销。
before = id(X)
X += Y
id(X) == before
True
1.5 转换为其他Python对象
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
(numpy.ndarray, torch.Tensor)
要将大小为1的张量转换为Python标量,可以调用item函数或Python的内置函数
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)
(tensor([3.5000]), 3.5, 3.5, 3)
二、数据预处理
读取数据集
创建一个人工数据集,并存储在csv文件中
import osos.makedirs(os.path.join('..', 'data'), exist_ok = True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')
导入pandas包并调用read_csv函数
import pandas as pddata = pd.read_csv(data_file)
print(data)
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
处理缺失值
“NaN”项代表缺失值
处理缺失数据的典型方法包括插值法和删除法,其中插值法用一个替代值弥补缺失值,删除法则直接忽略缺失值
在这里考虑插值法。通过位置索引iloc,将data分成inputs和outputs,其中前者为data的前两列,后者为data的最后一列。对于inputs中缺少的数值,用同一列的均值替换“NaN”项。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.select_dtypes(include = 'number').mean()) # 区别于书中的inputs.fillna(inputs.mean())
print(inputs)
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
对于inputs中的类别值和离散值,我们将“NaN”视为一个类别。由于Alley列只接受两种类型的类别值“Pave”和“NaN”,pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 Alley列为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少Alley列的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na = True)
print(inputs)
NumRooms Alley_Pave Alley_nan
0 NaN True False
1 2.0 False True
2 4.0 False True
3 NaN False True
转换为张量格式
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。
import torchX = torch.tensor(inputs.to_numpy(dtype = float))
y = torch.tensor(outputs.to_numpy(dtype = float))
X, y
(tensor([[nan, 1., 0.],[2., 0., 1.],[4., 0., 1.],[nan, 0., 1.]], dtype=torch.float64),tensor([127500., 106000., 178100., 140000.], dtype=torch.float64))
练习
创建包含更多行和列的原始数据集
(1)删除缺失值最多的列
(2)将预处理后的数据集转换为张量格式
# 创建数据集
import osos.makedirs(os.path.join('..', 'data'), exist_ok = True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price,others\n') # 列名f.write('NA,Pave,127500,Pave\n') # 每行表示一个数据样本f.write('2,NA,106000,NA\n')f.write('4,NA,178100,Pave\n')f.write('NA,NA,140000,Pave\n')import pandas as pddata = pd.read_csv(data_file)
print(data)
NumRooms Alley Price others
0 NaN Pave 127500 Pave
1 2.0 NaN 106000 NaN
2 4.0 NaN 178100 Pave
3 NaN NaN 140000 Pave
# 删除缺失值最多的列
count = 0
count_max = 0
labels = ['NumRooms','Alley','Price','others']
for label in labels:count = data[label].isna().sum()if count > count_max:count_max = countflag = label
data_new = data.drop(flag, axis = 1)
data_new
| NumRooms | Price | others | |
|---|---|---|---|
| 0 | NaN | 127500 | Pave |
| 1 | 2.0 | 106000 | NaN |
| 2 | 4.0 | 178100 | Pave |
| 3 | NaN | 140000 | Pave |
# 将data_new分成inputs和outputs,其中前者为data_new的前两列,后者为data_new的最后一列
inputs, outputs = data_new.iloc[:, 0:2], data_new.iloc[:, 2]
inputs = inputs.fillna(inputs.select_dtypes(include = 'number').mean()) # 对于inputs中的缺失值,用同一列的均值替换
print(inputs)
outputs = pd.get_dummies(outputs, dummy_na = True)
print(outputs)
NumRooms Price
0 3.0 127500
1 2.0 106000
2 4.0 178100
3 3.0 140000Pave NaN
0 True False
1 False True
2 True False
3 True False
# 转换为张量格式
import torchX = torch.tensor(inputs.to_numpy(dtype = float))
y = torch.tensor(outputs.to_numpy(dtype = float))
X, y
(tensor([[3.0000e+00, 1.2750e+05],[2.0000e+00, 1.0600e+05],[4.0000e+00, 1.7810e+05],[3.0000e+00, 1.4000e+05]], dtype=torch.float64),tensor([[1., 0.],[0., 1.],[1., 0.],[1., 0.]], dtype=torch.float64))
相关文章:

【深度学习笔记】01 数据操作与预处理
01 数据操作与预处理 一、数据操作1.1 基本数据操作1.2 广播机制1.3 索引和切片1.4 节省内存1.5 转换为其他Python对象 二、数据预处理读取数据集处理缺失值转换为张量格式练习 一、数据操作 1.1 基本数据操作 导入torch import torch张量表示一个由数值组成的数组ÿ…...

Python与设计模式--门面模式
8-Python与设计模式–门面模式 一、火警报警器(1) 假设有一组火警报警系统,由三个子元件构成:一个警报器,一个喷水器, 一个自动拨打电话的装置。其抽象如下: class AlarmSensor:def run(self):…...
改进YOLOv8 | YOLOv5系列:RFAConv续作,即插即用具有任意采样形状和任意数目参数的卷积核AKCOnv
RFAConv续作,构建具有任意采样形状的卷积AKConv 一、论文yolov5加入的方式论文 源代码 一、论文 基于卷积运算的神经网络在深度学习领域取得了显著的成果,但标准卷积运算存在两个固有缺陷:一方面,卷积运算被限制在一个局部窗口,不能从其他位置捕获信息,并且其采样形状是…...
机器学习-激活函数的直观理解
机器学习-激活函数的直观理解 在机器学习中,激活函数(Activation Function)是用于引入非线性特性的一种函数,它在神经网络的每个神经元上被应用。 如果不使用任何的激活函数,那么神经元的响应就是wxb,相当…...
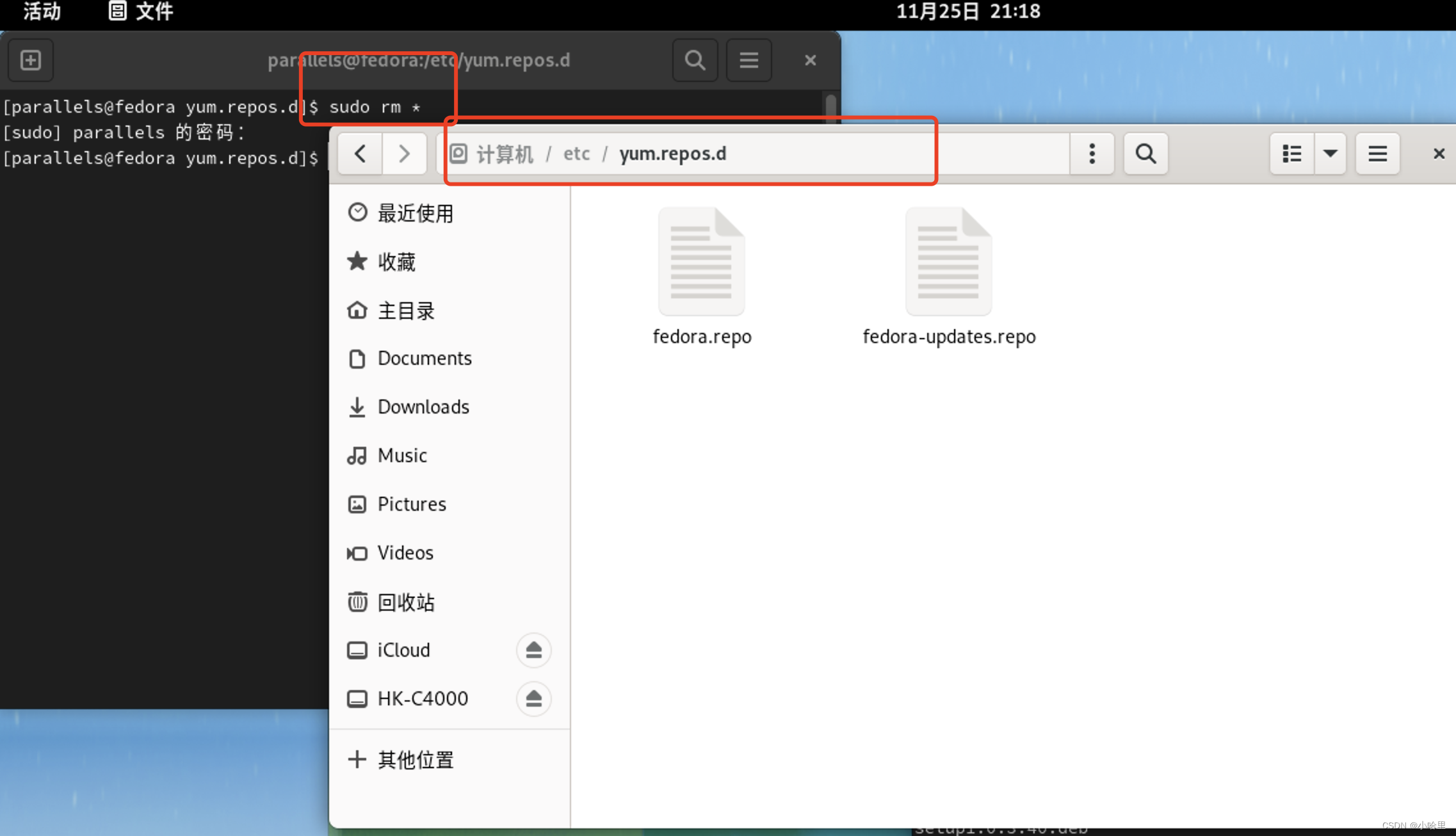
Fedora 36 ARM 镜像源更换与软件安装
1、什么是Fedora Fedora Linux是较具知名度的Linux发行套件之一,由Fedora专案社群开发、红帽公司赞助,目标是建立一套新颖、多功能并且自由的作业系统。 Fedora是商业化的Red Hat Enterprise Linux发行版的上游原始码。 2、Fedora软件安装 64 位 .deb&a…...

多级缓存快速上手
哈喽~大家好,这篇来看看多级缓存。 🥇个人主页:个人主页 🥈 系列专栏:【微服务】 🥉与这篇相关的文章: JAVA进程和线程JAVA进程和线程-CSDN博客Http…...

初始React
<!DOCTYPE html> <html> <head> <meta charset"UTF-8" /> <title>React</title> </head> <body> 了解React <!-- React是一个用于构建web和原生态交互界面的库 相对于传统DOM开发优势:组件化开发…...

2.5 逆矩阵
一、逆矩阵的注释 假设 A A A 是一个方阵,其逆矩阵 A − 1 A^{-1} A−1 与它的大小相同, A − 1 A I A^{-1}AI A−1AI。 A A A 与 A − 1 A^{-1} A−1 会做相反的事情。它们的乘积是单位矩阵 —— 对向量无影响,所以 A − 1 A x x A^{…...
物流实时数仓:数仓搭建(ODS)
系列文章目录 物流实时数仓:采集通道搭建 物流实时数仓:数仓搭建 文章目录 系列文章目录前言一、IDEA环境准备1.pom.xml2.目录创建 二、代码编写1.log4j.properties2.CreateEnvUtil.java3.KafkaUtil.java4.OdsApp.java 三、代码测试总结 前言 现在我们…...

【ARM 嵌入式 编译 Makefile 系列 18 -- Makefile 中的 export 命令详细介绍】
文章目录 Makefile 中的 export 命令详细介绍Makefile 使用 export导出与未导出变量的区别示例:导出变量以供子 Makefile 使用 Makefile 中的 export 命令详细介绍 在 Makefile 中,export 命令用于将变量从 Makefile 导出到由 Makefile 启动的子进程的环…...

【opencv】计算机视觉:停车场车位实时识别
目录 目标 整体流程 背景 详细讲解 目标 我们想要在一个实时的停车场监控视频中,看看要有多少个车以及有多少个空缺车位。然后我们可以标记空的,然后来车之后,实时告诉应该停在那里最方便、最近!!!实现…...
:FFmpeg与SDL环境配置)
播放器开发(三):FFmpeg与SDL环境配置
学习课题:逐步构建开发播放器【QT5 FFmpeg6 SDL2】 环境配置 我这边的是使用macOS;IDE用的是CLion;CMake构建,除了创建项目步骤、CMakeLists文件有区别之外的代码层面不会有太大区别。 配置上只添加一下CMakeLists中FFmpeg和SD…...
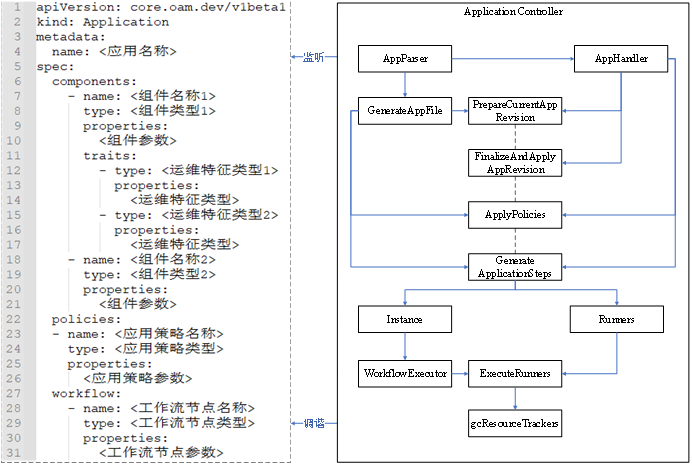
KubeVela核心控制器原理浅析
前言 在学习 KubeVela 的核心控制器之前,我们先简单了解一下 KubeVela 的相关知识。 KubeVela 本身是一个应用交付与管理控制平面,它架在 Kubernetes 集群、云平台等基础设施之上,通过开放应用模型来对组件、云服务、运维能力、交付工作流进…...

迎接“全全闪”时代 XSKY星辰天合发布星海架构和星飞产品
11 月 17 日消息,北京市星辰天合科技股份有限公司(简称:XSKY星辰天合)在北京首钢园举办了主题为“星星之火”的 XSKY 星海全闪架构暨星飞存储发布会。 (图注:XSKY星辰天合 CEO 胥昕) XSKY星辰天…...

[架构相关]基础架构设计原则
基础架构设计原则 文章目录 基础架构设计原则一、可用性(Availability)1.1、引入冗余1.2、负载均衡1.3、故障转移1.4、备份和恢复策略 二、可扩展性(Scalability)2.1 水平扩展2.2 垂直扩展2.3 弹性扩展 三、可靠性(Rel…...

测试在 Oracle 下直接 rm dbf 数据文件并重启数据库
创建一个新的表空间并创建新的用户,指定新表空间为新用户的默认表空间 create tablespace zzw datafile /oradata/cesdb/zzw01.dbf size 10m;zzw用户已经创建过,这里修改其默认表空间 alter user zzw quota unlimited on zzw; alter user zzw default …...

【开源】基于JAVA的计算机机房作业管理系统
项目编号: S 017 ,文末获取源码。 \color{red}{项目编号:S017,文末获取源码。} 项目编号:S017,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 登录注册模块2.2 课程管理模块2.3 课…...

Ubuntu 配置静态 IP
Ubuntu 18 开始可以使用netplan配置网络。配置文件位于/etc/netplan/xxx.yaml中,netplan默认是使用NetworkManager来配置网卡信息的。 修改配置文件: 1、打开文件编辑:sudo vi 01-network-manager-all.yaml原文件内容如下:netwo…...

Spring Cloud实战 |分布式系统的流量控制、熔断降级组件Sentinel如何使用
专栏集锦,大佬们可以收藏以备不时之需 Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html Logback 详解专栏:https:/…...
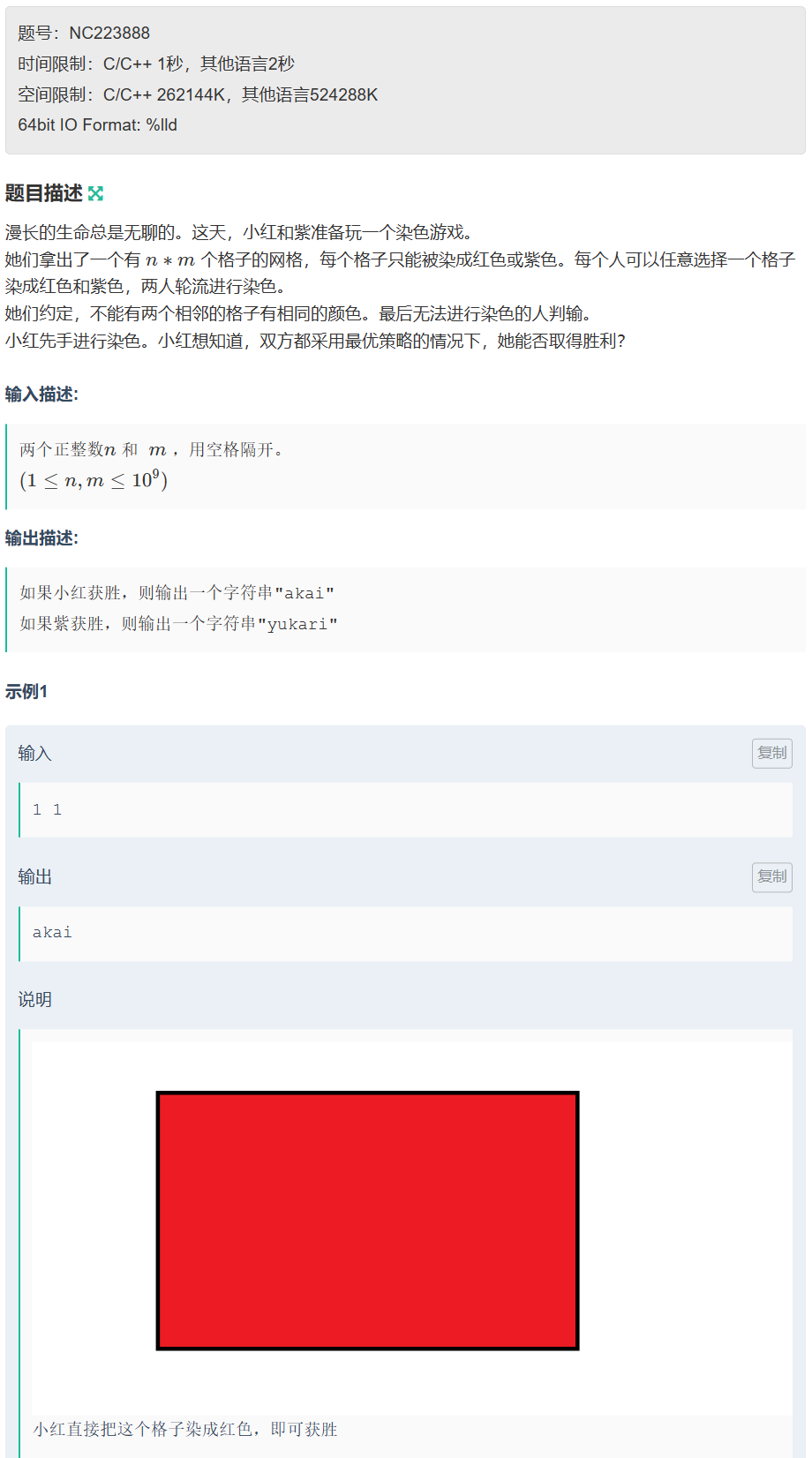
第六届 传智杯初赛B组
文章目录 A. 字符串拼接🍻 AC code B. 最小差值🍻 AC code C. 红色和紫色🍻 AC code D. abb🍻 AC code E. kotori和素因子🍻 AC code F. 红和蓝🍻 AC code 🥰 Tips:AI可以把代码从 j…...

DAMOYOLO-S跨平台部署演示:从Ubuntu服务器到Windows客户端的全链路
DAMOYOLO-S跨平台部署演示:从Ubuntu服务器到Windows客户端的全链路 最近在做一个项目,需要把目标检测模型部署到不同的设备上,既要跑在云端服务器做批量处理,又要在本地Windows电脑上实时运行。试了好几个模型,要么部…...
)
LLM服务版本管理实战手册(2024年头部AI团队内部流出版)
第一章:大模型工程化版本管理与回滚机制 2026奇点智能技术大会(https://ml-summit.org) 大模型工程化中的版本管理远超传统软件的 Git commit 粒度,需同时追踪模型权重、Tokenizer 配置、训练超参、推理服务镜像及依赖环境快照。单一 SHA 哈希已无法承载…...

Qwen3-VL-8B聊天系统实战场景:多模态AI助手在企业中的应用
Qwen3-VL-8B聊天系统实战场景:多模态AI助手在企业中的应用 1. 企业级多模态AI助手的核心价值 在数字化转型浪潮中,企业正面临信息处理效率与智能化服务的双重挑战。Qwen3-VL-8B聊天系统作为新一代多模态AI解决方案,通过融合视觉与语言理解能…...

如何快速解决网易云音乐NCM格式转换难题:专业工具完全解析
如何快速解决网易云音乐NCM格式转换难题:专业工具完全解析 【免费下载链接】ncmdump ncmdump - 网易云音乐NCM转换 项目地址: https://gitcode.com/gh_mirrors/ncmdu/ncmdump 还在为网易云音乐下载的NCM格式文件无法在其他设备播放而烦恼吗?ncmdu…...

造相-Z-Image效果展示:4090深度优化,中英文提示词直出惊艳作品
造相-Z-Image效果展示:4090深度优化,中英文提示词直出惊艳作品 你是否好奇,当顶级的RTX 4090显卡遇上专为它深度优化的文生图引擎,会产生怎样令人惊叹的作品?今天,我们不谈复杂的参数,不聊晦涩…...

Microsoft on GitHub项目结构深度解析:理解微软开源战略布局
Microsoft on GitHub项目结构深度解析:理解微软开源战略布局 【免费下载链接】microsoft.github.io Microsoft on GitHub 项目地址: https://gitcode.com/gh_mirrors/mi/microsoft.github.io Microsoft on GitHub项目作为微软开源战略的重要窗口,…...

higress 这个中登才是AI时代的心头好纤
核心摘要:这篇文章能帮你 ?? 1. 彻底搞懂条件分支与循环的适用场景,告别选择困难。 ?? 2. 掌握遍历DOM集合修改属性的标准姿势与性能窍门。 ?? 3. 识别流程控制中的常见“坑”,并学会如何优雅地绕过去。 ?? 主要内容脉络 ?? 一…...

vLLM-v0.17.1实战体验:3步搭建大模型API服务,实测推理速度翻倍
vLLM-v0.17.1实战体验:3步搭建大模型API服务,实测推理速度翻倍 1. vLLM框架简介与核心优势 vLLM是一个专为大语言模型推理优化的高性能服务框架,由加州大学伯克利分校Sky Computing Lab开发并开源。最新发布的v0.17.1版本在推理速度、内存管…...

控制平面核心:路由算法与 OSPF 协议
5.1 概述核心定位本章聚焦网络层的控制平面,是网络层两大核心平面(数据平面 控制平面)的关键组成部分。数据平面:负责路由器中转发IP 数据报,是 “执行层”,由路由器硬件 / 固件实现,处理每一个…...

为什么92%的AI初创公司输在IP起点?——基于56个真实败诉案例的AI研发全生命周期权属漏洞图谱
第一章:AI原生软件研发知识产权保护策略的底层逻辑 2026奇点智能技术大会(https://ml-summit.org) AI原生软件的研发范式已从根本上重构知识产权(IP)的生成、归属与边界——模型权重、提示工程链、微调数据集、推理服务接口乃至训练日志&…...