大数据预处理技术
文章目录
前言
大数据技术成为前沿专业 也是现在甚至未来的朝阳产业,大数据有分别是 数据预处理 数据存储 大数据处理和分析 数据可视化 部分组成 ,大数据行业有数据则称王,大数据的核心是数据本身 怎么获取有价值的数据呢?本章讲具体讲解大数据预处理技术和获取手段和平台。
一、公开数据库
1.常见数据公开网站
UCI:经典的机器学习,数据挖掘,UCI数据集是一个常用的机器学习标准测试数据集,是加州大学欧文分校(University of CaliforniaIrvine)提出的用于机器学习的数据库。机器学习算法的测试大多采用的便是UCI数据集了,其重要之处在于“标准”二字,新编的机器学习程序可以采用UCI数据集进行测试。 UCI Machine Learning Repository 相关实验案例参考文章。
http://t.csdnimg.cn/CVFIs
国家数据:数据来源于国家统计局,包含我国经济民生等多个方面的数据,并且在月度季度年度都有覆盖,全面又权威。http://t.csdnimg.cn/wc7bC
CEIC:最完整的一套超过128个国家的经济数据,能够精准查找GDP,CPI,进口,出口,进口,外资直接投资,零售,销售等深度数据。
万得:金融业有着全面的数据覆盖,金融数据的类目更新非常快,商业分析者和投资者的青睐。
搜数网:汇集中国资讯行业收集的所有统计和调查数据,并提供多样化的搜索功能。
中国统计信息网:国家统计局的官方网站,汇集了海量的全国各级政府各年度的国民经济和社会发展统计信息。
亚马逊:跨科学云数据平台,多个领域的数据集。
figshare:研究成果共享平台,在这里可以找到来自世界得大牛们研究成果分享,获取其中的研究数据。
github: 一个全面得数据获取渠道,包含各个细分领域得数据库资源,自然科学和社会科学得覆盖都很全面,适合做研究和数据分析的人员。
2.政府开放数据
北京市政务数据资源网:包含竞技,交通,医疗,天气等数据。
深圳市政府数据开放平台:交通,文娱,就业,基础设施等数据。
上海市政务数据服务网:覆盖经济建设,文化科技,信用服务,交通出行等12个领域数据。
贵州省政府数据开放平台:包含了政府及国有企业数据。
Data.gov:美国政府开放数据,包含气候,教育,能源金融等各领域数据。
3.数据竞赛网站
竞赛的数据集通常干净且可研究性非常高。
DataCastle:专业的数据科学竞赛平台。
Kaggle:全球最大的数据竞赛平台。
天池:阿里旗下数据科学竞赛平台。
Datafountain:CCF指定的大数据竞赛平台。
二、网络爬虫
1.网络爬虫原理
网络爬虫的价值其实就是数据的价值,在互联网社会中,数据是无价之宝,一切皆为数据,谁拥有了大量有用的数据,谁就拥有了决策的主动权
认识爬虫
我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做 Sogouspider。

百度搜索引擎,其实可以更形象地称之为百度蜘蛛(Baiduspider),它每天会在海量的互联网信息中爬取优质的信息,并进行收录。当用户通过百度检索关键词时,百度首先会对用户输入的关键词进行分析,然后从收录的网页中找出相关的网页,并按照排名规则对网页进行排序,最后将排序后的结果呈现给用户。在这个过程中百度蜘蛛起到了非常想关键的作用。
百度的工程师们为“百度蜘蛛”编写了相应的爬虫算法,通过应用这些算法使得“百度蜘蛛”可以实现相应搜索策略,比如筛除重复网页、筛选优质网页等等。应用不同的算法,爬虫的运行效率,以及爬取结果都会有所差异。
1.0 爬虫定义
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
1.1 爬虫薪资
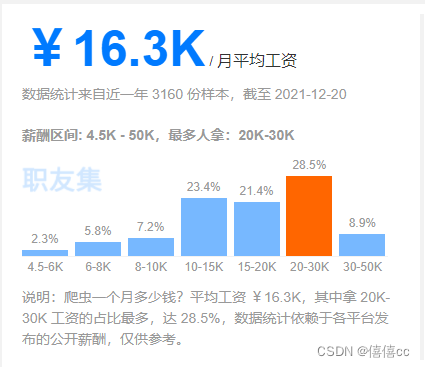
1.2 爬虫前景
每个职业都是有一个横向和纵向的发展,也就是所谓的广度和深度的意思。第一、如果专研得够深,你的爬虫功能很强大,性能很高,扩展性很好等等,那么还是很有前途的。第二、爬虫作为数据的来源,后面还有很多方向可以发展,比如可以往大数据分析、数据展示、机器学习等方面发展,前途不可限量,现在作为大数据时代,你占据在数据的的入口,还怕找不到发展方向吗?
1.3 爬虫创业
1.1.1 获取网页
爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息了。
- 使用socket下载一个页面
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:chenshifeng
@file:00.py
@time:2022/10/14
"""import socket# 不需要安装# 访问网站
url = 'www.baidu.com'
# 端口
port = 80def blocking():sock = socket.socket() # 建立对象sock.connect((url, port)) # 连接网站 ,发出一个HTTP请求request_url = 'GET / HTTP/1.0\r\nHost: www.baidu.com\r\n\r\n'sock.send(request_url.encode()) # 根据请求头来发送请求信息response = b'' # 建立一个二进制对象用来存储我们得到的数据chunk = sock.recv(1024) # 每次获得的数据不超过1024字节while chunk: # 循环接收数据,因为一次接收不完整response += chunkchunk = sock.recv(1024)header, html = response.split(b'\r\n\r\n', 1)f = open('index.html', 'wb')f.write(html)f.close()if __name__ == '__main__':blocking()
1.1.2 提取信息
获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS 选择器或 XPath 来提取网页信息的库,如 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。
提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
1.1.3 保存数据
提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为 TXT 文本或 JSON 文本,也可以保存到数据库,如 MySQL 和 MongoDB 等,也可保存至远程服务器,如借助 SFTP 进行操作等。
1.1.4 自动化程序
说到自动化程序,意思是说爬虫可以代替人来完成这些操作。首先,我们手工当然可以提取这些信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序。爬虫就是代替我们来完成这份爬取工作的自动化程序,它可以在抓取过程中进行各种异常处理、错误重试等操作,确保爬取持续高效地运行
1、爬虫技术概述
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。

网络爬虫到底是什么,学这个真的是“从入门到入狱”吗?_哔哩哔哩_bilibili
三、HTTP请求(Request)超文本传输协议
HTTP 协议的重要特点: 一发一收,一问一答

1.什么是URL?
URL 基本介绍
- 平时我们俗称的”网址“,其实就是 URL(Uniform Resource Locator),翻译为统一资源定位符
- 互连网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它

一个URL由如下几个部分构成:
协议: 通常是https或者http。表示通过何种方式获取该资源。你可能还见过其他协议类型,比如ftp或者file,协议后面跟着://
主机名: 可以是一个已经在DNS服务器注册过的域名 —— 或者是一个IP地址 —— 域名就表示背后的IP地址。一组主要由数字组成的用于标识接入网络的设备的字符串。
主机名后面可以指定端口,端口是可选的,如果不指定则使用默认端口,端口和主机名之间通过冒号隔开。
资源路径: 用于表示资源在主机上的文件系统路径。
可以在这之后通过问号连接可选的查询参数,如果有多个查询参数,通过&符连接
最后一项,如果需要的话可以添加#作为需要跳转的页面上的矛点名称。
一个URL的组成部分可以参考下面的图示:
2、爬虫的开发流程
-
爬虫的执行流程:
-
确定首页URL
-
发送请求, 获取数据
-
解析数据
-
保存数据
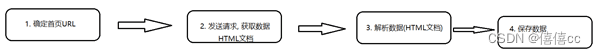
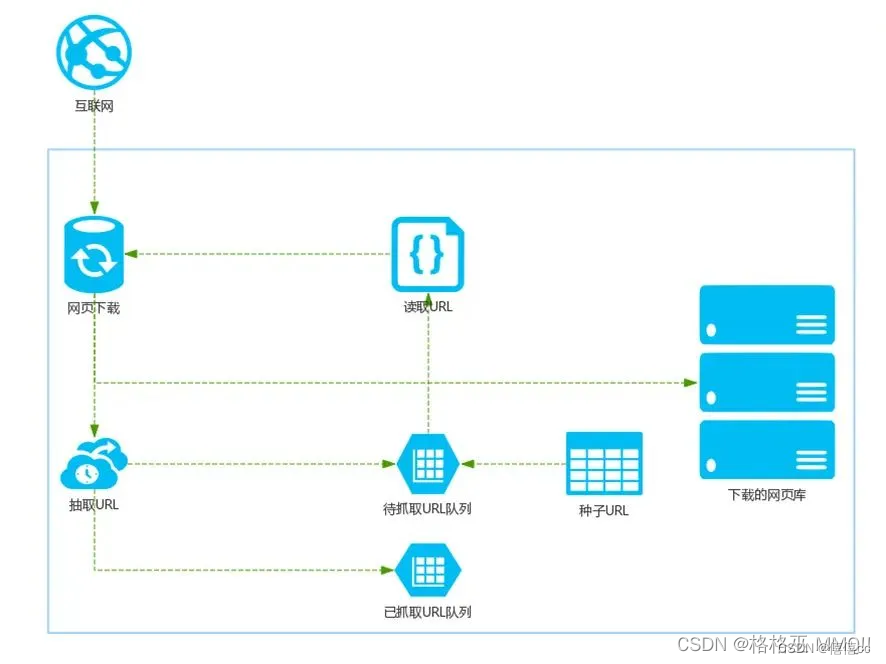
- 首先在互联网中选出一部分网页,以这些网页的链接地址作为种子URL;
- 将这些种子URL放入待抓取的URL队列中,爬虫从待抓取的URL队列依次读取;
- 将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址;
- 网页下载器通过网站服务器对网页进行下载,下载的网页为网页文档形式;
- 对网页文档中的URL进行抽取,并过滤掉已经抓取的URL;
- 对未进行抓取的URL继续循环抓取,直至待抓取URL队列为空。
3.爬虫分类
1.通用网络爬虫
通用网络爬虫又叫全网爬虫,主要由URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等模块构成。主要为大型搜索引擎,大型服务商等采集数据。
通俗来说就是抓取互联网上的所有数据。由于通用网络爬虫的爬行范围和爬取数据量十分巨大,对于爬取速度和存储空间要求较高,所以通常采用并行工作方式。
2.聚焦网络爬虫
聚焦网络爬虫又叫主题网络爬虫,爬取指定网页信息的一种爬虫。由于目的性更加明确,范围更加小,所以爬取速度快,大幅节约硬件和网络资源。
3.增量式网络爬虫
所谓增量式,就是增量式更新。意思是在需要的时候只爬取网页更新的部分,没有发生变化的部分不进行重复爬取。这样可以有效地减少数据下载量,加快运行速度,减小时间空间上的耗费,但是算法上的难度会相应增加。
4.深层网络爬虫
深层网络爬虫又称Deep Web爬虫。Web页面按照存在方式分为表层网页(Surface Web)和深层网页(Deep Web),表层网页是直接通过静态链接可直接访问的静态页面。深层网页则是隐藏在搜索表单后面的页面。
深层网络爬虫主要由六个基本功能模块(**爬行控制器、解析器、表单分析器、表单处理器、响应分析器、响应分析器、LVS控制器)**和两个爬虫内部数据结构(URL列表、LVS表)等部分构成。LVS表示标签/数值集合,用来表示填充表单的数据源。
4.反爬虫技术
4.1 通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2 基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
[评论:这种防爬,需要有足够多的ip来应对]
大多数网站都是前一种情况,对于这种情况,使用IP代理就可以解决。可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。这样的代理ip爬虫经常会用到,最好自己准备一个。有了大量代理ip后可以每请求几次更换一个ip,这在requests或者urllib2中很容易做到,这样就能很容易的绕过第一种反爬虫。
[评论:动态拨号也是一种解决方案]
对于第二种情况,可以在每次请求后随机间隔几秒再进行下一次请求。有些有逻辑漏洞的网站,可以通过请求几次,退出登录,重新登录,继续请求来绕过同一账号短时间内不能多次进行相同请求的限制。
[评论:对于账户做防爬限制,一般难以应对,随机几秒请求也往往可能被封,如果能有多个账户,切换使用,效果更佳]
4.3动态页面的反爬虫
上述的几种情况大多都是出现在静态页面,还有一部分网站,我们需要爬取的数据是通过ajax请求得到,或者通过Java生成的。首先用Firebug或者HttpFox对网络请求进行分析。如果能够找到ajax请求,也能分析出具体的参数和响应的具体含义,我们就能采用上面的方法,直接利用requests或者urllib2模拟ajax请求,对响应的json进行分析得到需要的数据。
[评论:感觉google的、IE的网络请求分析使用也挺好]
四.数据交易平台
1.政府类
贵阳大数据交易所:贵阳大数据交易所
西咸新区大数据交易所
东湖大数据交易平台
华东江苏大数据交易平台
哈尔滨数据交易中心
上海数据交易中心
2.平台类
京东万象
聚合数据
数据宝
百度智能云
五 .数据预处理技术
1、数据预处理的必要性
数据预处理技术是数据分析以及数据挖掘过程中非常重要的一环。 数据预处理是指在对数据进行数据挖掘的主要处理以前,先对原始数据进行必要的清洗、集成、转换、离散、归约、特征选择和提取等一系列处理工作,达到挖掘算法进行知识获取要求的最低规范和标准。
2.为什么要对数据进行预处理呢?
对于数据分析而言,数据是显而易见的核心。但是并不是所有的数据都是有用的。大多数数据参差不齐,层次概念不清晰,数量级不同。这会给后期的数据分析带来很大的麻烦。
数据挖掘的对象是从现实现实世界采集到的大量的、各种各样大数据。现实生产和实际生活以及科学研究的多样性、不确定性、复杂性等导致采集到的原始数据比较散乱,它们是不符合挖掘算法进行知识获取的规范和标准的。所以这时我们必须把数据进行处理,从而得到标准规范的数据。进而进行分析。现实生活中的数据经常是“肮脏的”。也就是数据会有由于各种原因,存在各种问题。尤其是如今的大数据,因为“大”所以什么问题都有可能出现。那么我们的数据会出现什么问题呢?
(1)数据不完整性:不完整性指的是数据记录中可能会出现有一些数据属性的值丢失或不确定的情况,还有可能缺失必需的数据。这是系统设计时存在的缺陷或者使用过程中一些人为因素造成的,如有些数据缺失只是因为输入时被认为时不重要的,相关数据没有记录可能是由于理解错误,或者因为设备故障,与其他记录不一致的数据可能已经被删除,历史记录或修改的数据可能被忽略等。
(2)不确定的数据有很多可能的原因(含噪声):含噪声指的是数据具有不正确的属性值,包含错误或者存在偏离期望的离群值(指与其他数值比较差异较大的值)。它们产生的原因有很多,如手机数据的设备可能出现故障,人或者计算机可能在数据输入时出现错误,数据传输中可能出现了错误等。不正确的数据也可能是由命名约定或所用的数据代码不一致导致的。在实际使用系统中,还可能存在大量的模糊信息,有些数据甚至具有一定的随机性。
(3)数据不一致性:原始数据是从各个实际应用系统中获取的,由于各应用系统的数据缺乏统一的标准的定义,数据结构也有较大的差异,因此各系统之间的数据存在较大的不一致性,往往不能直接使用。同时,来自不同应用系统中的数据,由于合并还普遍存在数据重复和信息冗余现象。
(4)时效性也可能影响数据质量
数据的实时更新没有完全的统计。
因此,这里说存在不完整的、含噪声的和不一致的数据是现实世界大型的数据库或数据仓库的共同特点。一些比较成熟的算法对其处理的数据集合一般有一定的要求,如数据完整性好、数据的冗余性小、属性之间的相关性小。然而,实际系统中的数据一般无法直接满足数据挖掘算法的要求,因此必须对数据进行预处理,以提高数据质量,使之符合数据挖掘算法的规范和要求。
协议,转载请附上原文出处链接及本声明。
3、数据预处理的主要任务
数据预处理是指对数据进行数据挖掘之前,先对原始数据进行必要的清洗、集成、转换、离散和规约等一系列的处理工作,已达到挖掘算法进行知识获取研究所要求的最低规范和标准。在大数据处理过程中,数据预处理将占用60%~80%的时间。
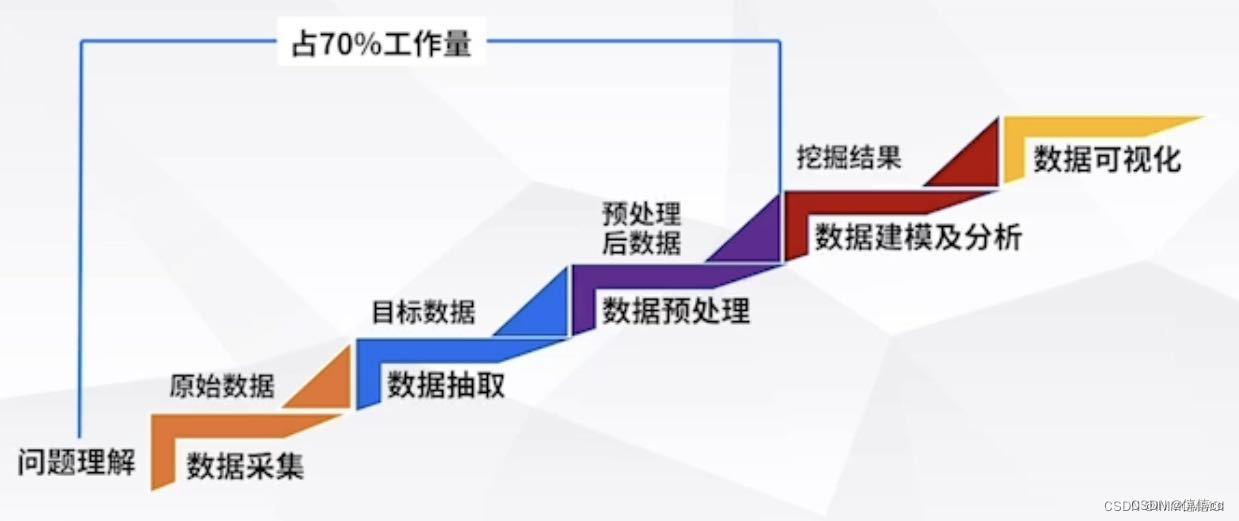
从对不同的源数据进行预处理的功能来分,数据预处理主要包括数据清洗(Data Cleaning)、数据集成(Data Integration)、数据变换(Data Transformation)、数据规约(Data Reduction)。等四个功能

六.数据清洗
1.缺失值填充
- 删除含有缺失值样本
- 人工填写缺失值
- 使用一个全局常量填充缺失值
- 使用属性的均值填充缺失值
- 使用与给定元组同一类的所有样本的属性均值填充相应的缺失值
- 使用最可能的值填充缺失值
方法3~6填充的值都有可能不正确。方法6是最常用的和最可靠的填充缺失值的方法,使用已有数据的大部分信息来预测缺失值。
2.噪声平滑
噪声是指被测变量的一个随机错误和变化。平滑处理旨在帮助去掉数据中的噪声,常用的方法包括分箱、回归和聚类等
-
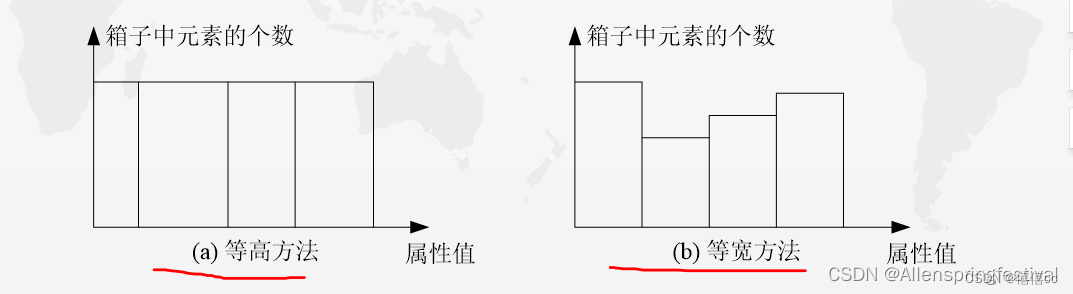
1.分箱
分箱(Bin)方法通过利用被平滑数据点的周围点(近邻),对一组排序数据进行平滑,排序后的数据被分配到若干箱子(称为 Bin)中。 如图5所示,对箱子的划分方法一般有两种,一种是等高方法,即每个箱子中元素的个数相等,另一种是等宽方法,即每个箱子的取值间距(左右边界之差)相同。
这里给出一个实例介绍分箱方法。假设有一个数据集X={4,8,15,21,21,24,25,28,34},这里采用基于平均值的等高分箱方法对其进行平滑处理,则分箱处理的步骤如下:
按平均值分箱
(1)把原始数据集X放入以下三个箱子: 箱子1:4,8,15 箱子2:21,21,24 箱子3:25,28,34
(2)分别计算得到每个箱子的平均值: 箱子1的平均值:9 箱子2的平均值:22 箱子3的平均值:29
(3)用每个箱子的平均值替换该箱子内的所有元素: 箱子1:9,9,9 箱子2:22,22,22 箱子3:29,29,29
(4)合并各个箱子中的元素得到新的数据集{9,9,9,22,22,22,29,29,29}。
按最大最小值(边界值)分箱
此外,还可以采用基于箱子边界的等宽分箱方法对数据进行平滑处理。利用边界进行平滑时,对于给定的箱子,其最大值与最小值就构成了该箱子的边界,利用每个箱子的边界值(最大值或最小值)可替换该箱子中的所有值。
这时的分箱结果如下:
箱子1:4,4,15
箱子2:21,21,24
箱子3:25,25,34 合并各个箱子中的元素得到新的数据集{4,4,15,21,21,24,25,25,34}。
-
2.回归
可以利用拟合函数对数据进行平滑。例如,借助线性回归方法(包括多变量回归方法),就可以获得多个变量之间的拟合关系,从而达到利用一个(或一组)变量值来预测另一个变量取值的目的。如图所示,利用回归分析方法所获得的拟合函数,能够帮助平滑数据并除去其中的噪声。
-
3.聚类
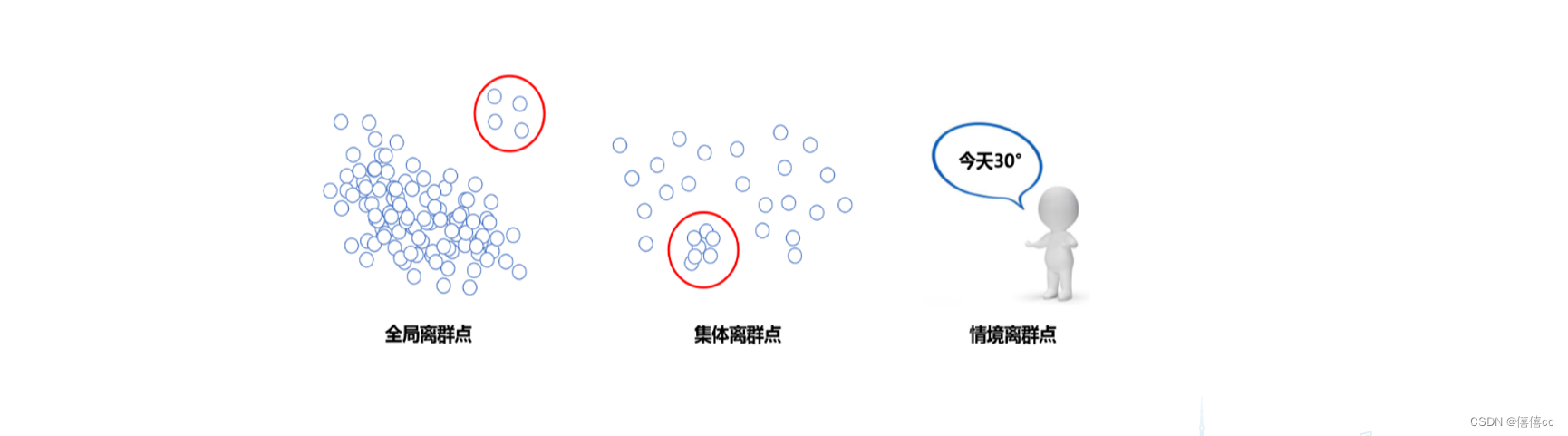
通过聚类分析方法可帮助发现异常数据。如图所示,相似或相邻近的数据聚合在一起形成了各个聚类集合,而那些位于这些聚类集合之外的数据对象,则被认为是异常数据
- 全局离群点:个别数据离整体数据数据较远。
- 集体离群点:一组数据与其他数据分布方式不同。
- 情景离群点:又称”条件离群点“,即在特定条件下可能又是合理的点。(比如夏天的28℃和冬天的28℃)
3.不一致的数据清洗
在实际数据库中,由于一些人为因素或者其他原因,记录的数据可能存在不一致的情况,因此,需要对这些不一致数据在分析前需要进行清理。例如,数据输入时的错误,可通过和原始记录对比进行更正。知识工程工具也可以用来检测违反规则的数据。还例如,在已知属性间依赖关系的情况下,可以查找违反函数依赖的值。
七.数据集成和数据转换
数据集成:数据集成需要考虑许多问题,如实体识别问题,主要是匹配来自多个不同信息源的现实世界实体。
冗余是另一个重要问题。如果一个属性能由另一个或另一组属性“导出”,则此属性可能是冗余的。属性或维命名的不一致也可能导致结果数据集中的冗余。有些冗余可通过相关分析检测到,如给定两个属性,根据可用的数据度量一个属性能在多大程度上蕴含另一个。常用的冗余相关分析方法有皮尔逊积距系数、卡方检验、数值属性的协方差等。

八.数据规约
数据立方体聚集:聚集操作用于数据立方体结构中的数据。数据立方体存储多维聚集信息。每个单元存放一个聚集值,对应于多维空间的一个数点,每个属性可能存在概念分层,允许在多个抽象层进行数据分析。
属性子集选择:当待分析数据集含有大量属性时,其中大部分属性与挖掘任务不相关或冗余,属性子集选择可以检测并删除不相关、冗余或弱相关的属性或维。其目标是找出最小属性集,使得数据类的概率分布尽可能地接近使用所有属性得到的原分布。
维规约:维度规约使用数据编码或变换得到原数据规约或“压缩”表示。减少所考虑的随机变量或属性个数 。
数值规约:数值规约通过选择替代的数据表示形式来减少数据量。即用较小的数据表示替换或估计数据。
九.数据脱敏
敏感数据,又称隐私数据,常见的敏感数据有: 姓名、身份证号码、地址、电话号码、银行账号、邮箱地址、所属城市、邮编、密码类 ( 如账户查询密码、取款密码、登录密码等 )、组织机构名称、营业执照号码、银行帐号、交易日期、交易金额等。
脱敏规则,一般的脱敏规则分类为可恢复与不可恢复两类。
使用环境,主要指脱敏之后的数据在哪些环境中使用。普遍按照生产环境和非生产环境(开发、测试、外包、数据分析等)进行划分。
总结
相关文章:
大数据预处理技术
文章目录 前言 大数据技术成为前沿专业 也是现在甚至未来的朝阳产业,大数据有分别是 数据预处理 数据存储 大数据处理和分析 数据可视化 部分组成 ,大数据行业有数据则称王,大数据的核心是数据本身 怎么获取有价值的数据呢?本章讲…...

跳表的学习记录
跳表(Skip List)是一种数据结构,它通过在多个层次上添加额外的前向指针来提高有序数据的搜索效率。跳表与其他常见的有序数据结构(如二叉搜索树、平衡树如AVL树和红黑树、B树等)相比,具有其独特的优缺点&am…...

电子学会C/C++编程等级考试2022年09月(二级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:统计误差范围内的数 统计一个整数序列中与指定数字m误差范围小于等于X的数的个数。 时间限制:5000 内存限制:65536输入 输入包含三行: 第一行为N,表示整数序列的长度(N <= 100); 第二行为N个整数,整数之间以一个空格分…...
如何使用nginx部署静态资源
Nginx可以作为静态web服务器来部署静态资源,这个静态资源是指在服务端真实存在,并且能够直接展示的一些文件数据,比如常见的静态资源有html页面、css文件、js文件、图片、视频、音频等资源相对于Tomcat服务器来说,Nginx处理静态资…...
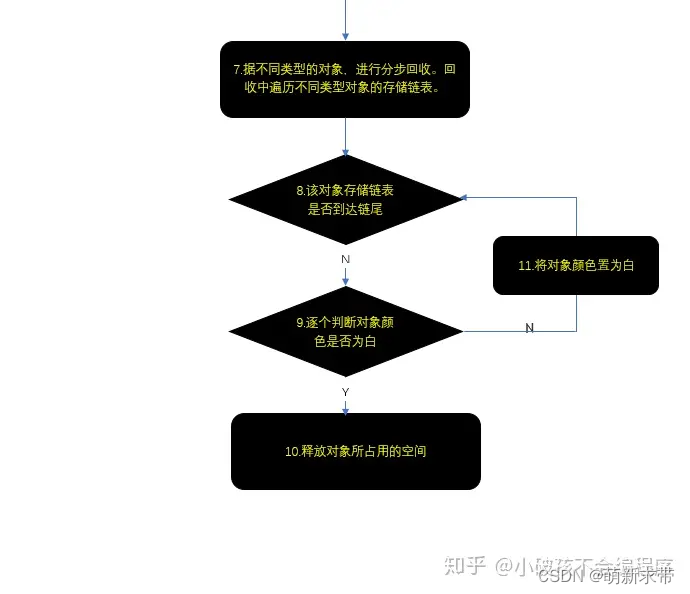
lua的gc原理
lua垃圾回收(Garbage Collect)是lua中一个比较重要的部分。由于lua源码版本变迁,目前大多数有关这个方面的文章都还是基于lua5.1版本,有一定的滞后性。因此本文通过参考当前的5.3.4版本的Lua源码,希望对Lua的GC算法有一个较为详尽的探讨。 L…...

redis作为缓存详解
目录 前言: 为什么说关系型数据库性能不高 如何提高MySQL并发量 缓存更新策略 定期更新 实时更新 内存淘汰策略 Redis内置的淘汰策略 缓存常见问题 缓存预热 缓存穿透 缓存雪崩 缓存击穿 前言: 对于缓存的理解,缓存目的就是为了…...
231127 刷题日报
这周值班。。多少写道题吧,保持每天的手感。老婆给买了lubuladong纸质书,加油卷。 1. 131. 分割回文串 写个这个吧,钉在耻辱柱上的题。 为啥没写出来: 1. 递归树没画对 把树枝只看做是1个字母,而且不清楚树枝和节点…...
【Linux】vim-多模式的文本编辑器
本篇文章内容和干货较多,希望对大家有所帮助👍 目录 一、vim的介绍 1.1 vi 与 vim的概念1.2 Vim 和 Vi 的一些对比 二、vim 模式之间的切换 2.1 进入vim2.2 [正常模式]切换到[插入模式]2.3 [插入模式]切换至[正常模式]2.4 [正常模式]切换至[底行模式…...

Ubuntu 启用 root 用户
在启用 root 用户之前,我们先来了解一下, ubuntu 命令的组成。 打开 ubuntu 的终端,现在的命令行是由 topeetubuntu:~$ 这几个字母组成,那么这几个字母都代表 什么意思呢? topeet …...
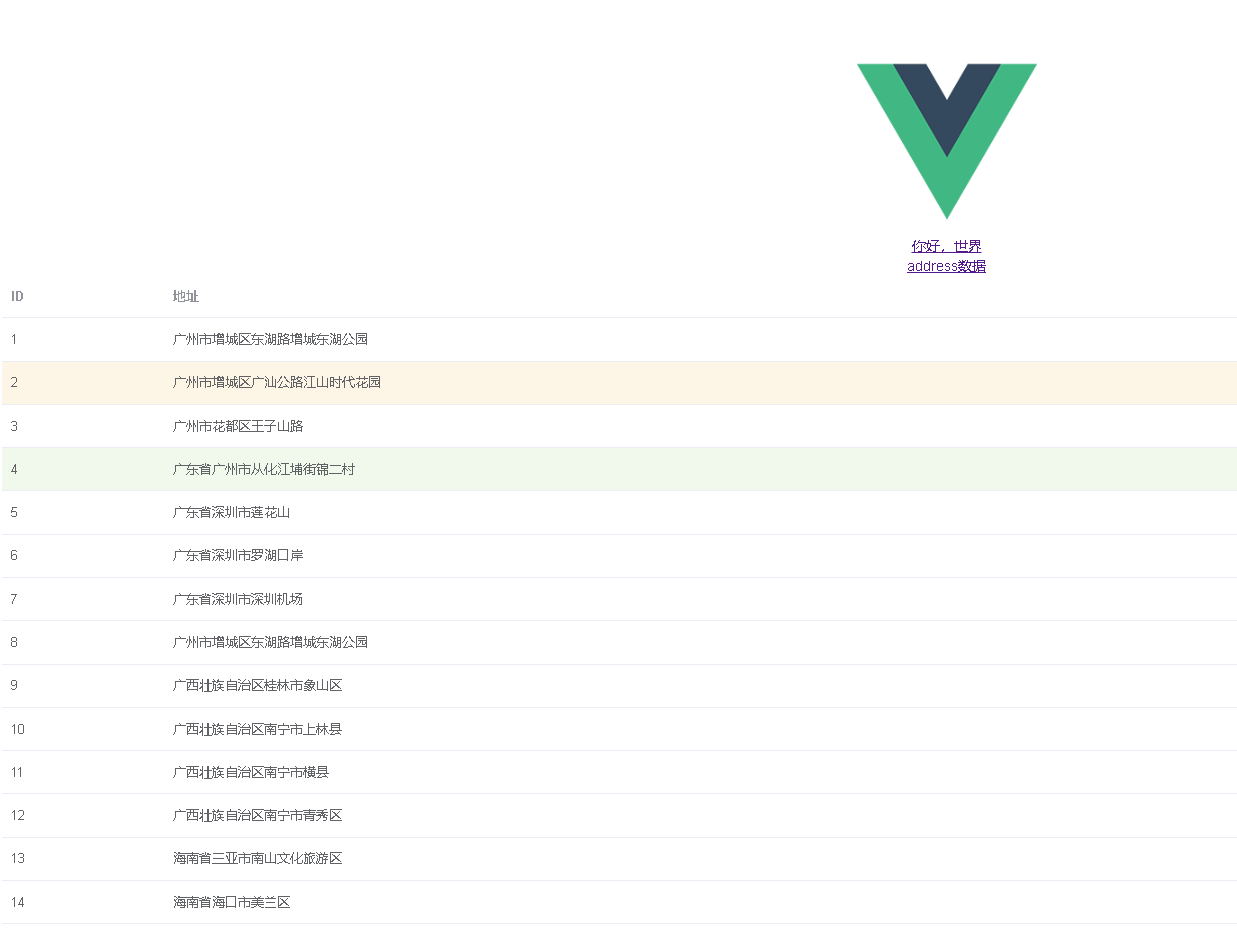
手摸手Element-ui路由VueRoute
后端WebAPI准备 https://router.vuejs.org/zh/guide/ https://v3.router.vuejs.org/zh/installation.html <template><el-table:data"tableData"style"width: 100%":row-class-name"tableRowClassName"><!-- <el-table-colum…...

探究Kafka原理-5.Kafka设计原理和生产者原理解析
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理🔥如果感觉博主的文章还不错的话,请ὄ…...

浅谈C#在unity应用中的工厂模式
文章目录 前言简单工厂模式工厂方法模式抽象工厂模式Unity实战 前言 工厂模式是一种创建型设计模式,它提供了一种将对象的实例化过程封装起来的方法,使得客户端代码不必直接依赖于具体类。这有助于降低代码的耦合度,提高代码的可维护性和可扩…...

卷积神经网络(Inception-ResNet-v2)交通标志识别
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据 二、构建一个tf.data.Dataset1.加载数据2. 配置数据集 三、构建Inception-ResNet-v2网络1.自己搭建2.官方模型 五、设置动态学习率六、训练模型七、模型评…...

网易云音频数据如何爬取?
在当今数字化时代,音频数据的获取和处理变得越来越重要。本文将详细介绍如何使用Objective-C语言构建音频爬虫程序,以爬取网易云音乐为案例。我们将从Objective-C的基础知识开始,逐步深入到爬取思路分析、构建爬虫框架、完整爬取代码等方面&a…...

97、Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
简介 论文地址 使用扩散模型来推断文本相关图像作为内容先验,并使用单目深度估计方法来提供几何先验,并引入了一种渐进的场景绘制和更新策略,保证不同视图之间纹理和几何的一致性 实现流程 简单而言: 文本-图片扩散模型生成一…...
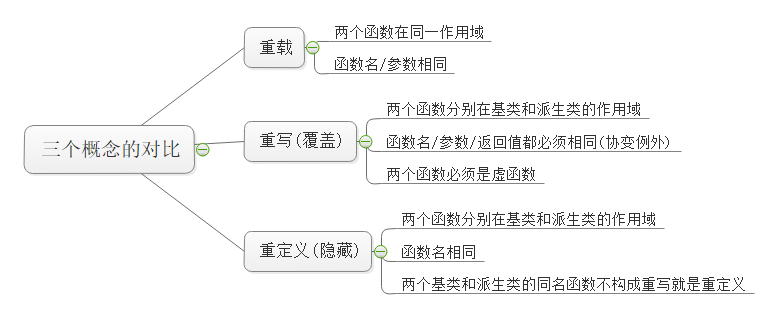
【C++】多态(上) 多态 | 虚函数 | 重写 | final、override | 接口继承与实现继承 | 抽象类
一、多态 概念 多态,就是多种状态,即不同的对象去完成同一个行为时会产生出不同的状态。比如:买票时,成人要原价买,学生和老人就可以享受优惠价便宜一点儿。同样是买票这个行为,不同的对象来做就有不同的…...

国内怎么投资黄金,炒黄金有哪些好方法?
随着我国综合实力的不断强大,投资市场的发展也日臻完善,现已成为了国际黄金市场的重要组成部分,人们想要精准判断金市走向,就离不开对我国经济等信息的仔细分析。而想要有效提升盈利概率,人们还需要掌握国内黄金投资的…...
springboot实现数据脱敏
springboot实现数据脱敏 怎么说呢,写着写着发觉 ”这写的什么玩意“ 。 总的来说就是,这篇文章并不能解决数据脱敏问题,但以下链接可以。 SpringBoot中利用自定义注解优雅地实现隐私数据脱敏 然后回到本文,本来是想基于AOP代理&am…...
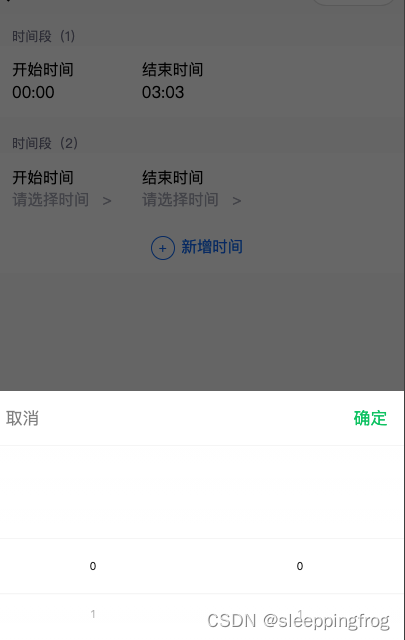
uniapp实现多时间段设置
功能说明: 1 点击新增时间,出现一个默认时间段模板,不能提交 2 点击“新增时间文本”,弹出弹窗,选择时间,不允许开始时间和结束时间同时为00:00, <view class"item_cont"> …...

uni-app - 去除隐藏页面右侧垂直滚动条
全局配置 "globalStyle": { //全局配置 "scrollIndicator":"none", // 不显示滚动条 "app-plus":{ "scrollIndicator":"none" // 在APP平台都不显示滚动条 } }局部配置 "path": "pages/ind…...

技术深度:G-Helper实现华硕笔记本精准散热控制与性能调优的架构解析
技术深度:G-Helper实现华硕笔记本精准散热控制与性能调优的架构解析 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, T…...

G-Helper深度解析:华硕笔记本轻量级控制工具的技术架构与实战手册
G-Helper深度解析:华硕笔记本轻量级控制工具的技术架构与实战手册 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF…...
)
放弃HAL库硬件IIC吧!手把手教你用STM32F103C8T6 GPIO模拟IIC读取MT6701角度(附完整工程)
STM32 GPIO模拟IIC驱动MT6701磁编码器实战指南 在嵌入式开发中,IIC总线因其简单性和多设备支持能力而广受欢迎。然而,许多开发者在使用STM32 HAL库的硬件IIC时都遇到过稳定性问题——从莫名其妙的通信失败到难以调试的时序错误。这些问题在需要高精度角度…...

避坑指南:在Python 3.7环境用ModelScope跑speech_campplus_sv声纹模型,小心这个隐藏Bug
深度解析Python 3.7环境运行ModelScope声纹模型的隐藏陷阱 当你在Python 3.7环境中满怀期待地运行达摩院的speech_campplus_sv声纹识别模型时,突然遭遇AttributeError: SpeakerVerificationPipeline object has no attribute model_cfg这样的错误提示,确…...

seo优化软件有哪些种类_seo优化软件对比
SEO优化软件有哪些种类_SEO优化软件对比 随着互联网的迅猛发展,网站在竞争中占据优势的关键在于其在搜索引擎上的排名。SEO优化软件在这一过程中扮演着不可或缺的角色。SEO优化软件究竟有哪些种类?每种软件又有什么特点呢?本文将详细探讨SEO…...

【learn-claude-code】S08BackgroundTasks - 后台任务:慢操作放后台,Agent 继续思考
核心理念 “慢操作放后台,Agent 继续思考” – 后台线程执行命令,完成后通知模型。 源码:https://github.com/xiayongchao/learn-claude-code-4j/blob/main/src/main/java/org/jc/agents/S08BackgroundTasks.java原版:https://g…...

Greasy Fork:开源用户脚本平台如何重塑你的浏览器体验
Greasy Fork:开源用户脚本平台如何重塑你的浏览器体验 【免费下载链接】greasyfork An online repository of user scripts. 项目地址: https://gitcode.com/gh_mirrors/gr/greasyfork 在当今互联网时代,浏览器已成为我们获取信息、处理工作的核心…...

基于S7-200控制的全方位自动洗车系统设计与实现:包含设计手册、PLC程序、仿真与实际接线全图解
基于S7-200控制的自动洗车系统设计 本设计包括设计说明书,PLC程序,组态仿真,I/O接口,带注释程序pdf版,接线图,控制电路图,主电路图,PLC接线图,顺序功能图。 总体设计系统…...

008.S3C2440中断分析|千篇笔记实现嵌入式全栈/裸机篇
1. 流程 S3C2440中断流程如下, 发生中断时,[SUB]SRCPND源挂起寄存器对应的bit位会置位, 然后[SUB]MASK屏蔽寄存器对应的bit位会卡一下,决定中断流要不要继续, 也就是说不管中断有没有被屏蔽,源挂起寄存…...

告别WebSecurityConfigurerAdapter:Spring Security 5.7+组件化配置实战指南
1. 从WebSecurityConfigurerAdapter到组件化配置的转变 如果你最近在升级Spring Boot应用,特别是从2.x版本迁移到3.x,肯定会遇到一个重大变化:Spring Security 5.7版本中,WebSecurityConfigurerAdapter这个老朋友已经被正式弃用了…...