【古诗生成AI实战】之二——项目架构设计
[1] 项目架构
在我们深入古诗生成AI项目的具体实践之前,让我们首先理解整个项目的架构。本项目的代码流程主要分为三个关键阶段:
1、数据处理阶段;
2、模型训练阶段;
3、文本生成阶段。
第一步:在数据处理阶段,我们将重点放在文本的分割、清洗和标准化上。这个阶段的开始是对原始文本进行清洗,然后进行字级别的分词处理。例如,将“床前明月光”分词为[床,前,明,月,光]。这样的处理后,我们接着构建词典vocabulary,并从官方词向量库中提取出词典中的词对应的向量。
注意:如果你是初学者,可能会对词典构建和官方词向量的概念感到困惑。不用担心,我们将在后续的章节中详细解释这些概念。
第二步:模型训练阶段。这一阶段的核心任务是加载数据集,将其处理成模型可接受的输入input和标签label格式,并进行训练。训练完成后,模型的保存变得至关重要。我们会保存训练好的模型,以便在不同环境中重复使用,避免每次都从头开始训练。同时,我们还会特别保存那些表现最佳的模型,以便于后续生成高质量的古诗。
第三步:文本生成阶段。在这一阶段,我们将使用保存好的模型来处理新的文本数据。这里的“文本数据”可以是空的,即直接从模型中生成古诗。经过模型处理后,我们将得到新生成的古诗文本。
接下来,我们将逐一深入每个阶段,详细解析它们的工作流程和关键点。
[1.1] 数据处理阶段
数据处理阶段流程图如下:

为了确保项目代码具有高度的灵活性和扩展性,使其能够轻松适应其他数据集和不同的下游任务,我们精心设计了任务加载器task和预处理器processor。
通过任务加载器task和预处理器processor的处理,数据集中的所有字符被有效地整理和组织,形成了一个全面的字典。这个过程至关重要,因为它决定了模型如何理解和处理文本数据。值得注意的是,虽然第三方Word2Vec库通常非常庞大,大约有1GB的大小,并且包含了30万到100万个单字和词汇,但我们的字典大小大约只有7千左右(比如,Bert的词典大小也只有3万)。因此,一个关键的步骤是从这些庞大的第三方Word2Vec中精确地提取出与我们字典中的词汇相对应的词向量。
这一过程不仅优化了我们模型的存储和运算效率,而且确保了模型能够准确地理解和处理我们特定的数据集。这样的设计思路使得整个项目更加高效、灵活,为后续的不同应用场景奠定了坚实的基础。
[1.2] 模型训练阶段
模型训练阶段流程图如下:

同理,为了使项目代码有较强的拓展性,方便拓展到其他数据集上和其他下游任务上,我们设计了模型包装器wrapper,真正的模型结构model放入模型包装器wrapper。
在训练结束后,将最好的模型结果保存下来。
[1.3] 文本生成阶段
文本生成阶段流程图如下:

在我们的模型训练完成之后,一个令人兴奋的阶段就是利用训练好的模型来生成文本。在这个阶段,你可以选择输入一些自定义的前缀词,或者完全不输入任何内容。这取决于你想要模型生成的古诗的风格和内容。
一旦输入(如果有的话)被送入模型,模型就会根据输入预测下一个最可能的字。这个预测的字接着被拼接到原始输入的末尾,形成新的输入字符串。然后,这个更新后的字符串再次被送入模型。这个过程不断重复,直到生成了一整段文本。
这个生成过程非常有趣,因为它不仅展示了模型学习古诗的结构和语言风格的能力,而且还允许我们以创造性的方式使用模型,无论是模仿经典古诗风格,还是创作全新的诗句。这种交互式的文本生成过程为探索AI在文学创作领域的潜力提供了一个有趣的窗口。
[2] 古诗生成训练原理
理解整个实战项目的架构之后,你一定好奇模型的输入输出是什么,训练的目标是什么,如何让模型可以有生成能力呢?请参考下面的模型原理图:

在讨论古诗生成模型的细节之前,让我们先看一下典型的序列生成模型的架构。在这种模型中,输入通常是一个序列,例如一句或一整首古诗。这个模型的目标是生成一个与输入序列往左偏移一个单位的输出序列。
为了让模型能够识别古诗的开头和结尾,我们引入了特殊的符号来表示开始和结束。具体的符号并不重要,但为了示例,我们可以将开始符设为B(Begin)和结束符设为E(End)。
现在,让我们来详细探讨一下训练目标。
例如,如果输入序列是[B,床,前,明,月,光,E],那么我们将这个序列向左偏移一个单位作为训练标签,即目标序列是[床,前,明,月,光,E,E]。当输入通过模型处理后,我们希望每个输入元素都能准确地预测其下一个元素。也就是说,我们期望输入‘B’时模型预测出的字是‘床’,输入‘床’时预测出的字是‘前’,以此类推。当到达结束符‘E’时,我们预期模型接下来不断预测出‘E’,这表示古诗生成的结束。
图中的长方形“model”代表神经网络模型本身。这个模型通常是一个多层神经网络,比如循环神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)。这些类型的网络非常擅长处理序列数据,并能记住前面的信息,这对于生成连贯和有吸引力的古诗至关重要。
[3] 进行下一篇实战
【古诗生成AI实战】之三——任务加载器与预处理器
相关文章:
【古诗生成AI实战】之二——项目架构设计
[1] 项目架构 在我们深入古诗生成AI项目的具体实践之前,让我们首先理解整个项目的架构。本项目的代码流程主要分为三个关键阶段: 1、数据处理阶段; 2、模型训练阶段; 3、文本生成阶段。 第一步:在数据处理阶段…...
动态网页从数据库取信息,然后展示。
把数据库的驱动放在bin目录下。 通过servlet 读取数据库的内容,生成session,然后跨页面传给展示页。 package src;import java.io.IOException; import java.io.PrintWriter; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSe…...

单片机学习3——数码管
数码管,根据内部结构,可分为共阴极数码管和共阳极数码管。七段发光管加上一个小数点,共计8段。因此,我们对它编程的时候,刚好是用一个字节。 数码管的显示方式: 1)静态显示; 2&…...
数据库表结构导出成Excel或Word格式
前言 该工具主要用于导出excel、word,方便快速编写《数据库设计文档》,同时可以快速查看表的结构和相关信息。 本博客仅作记录,最新源码已经支持多种数据库多种格式导出,有兴趣的可移步源码作者地址:https://gitee.co…...
School training competition ( Second )
A. Medium Number 链接 : Problem - 1760A - Codeforces 就是求三个数的中位数 : #include<bits/stdc.h> #define IOS ios::sync_with_stdio(0);cin.tie(0);cout.tie(0); #define endl \nusing namespace std; typedef long long LL; const int N 2e510;inline void …...
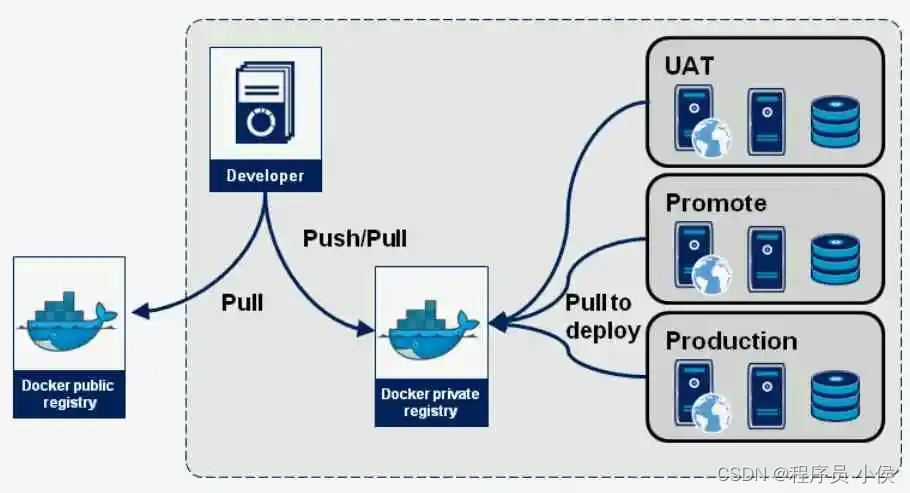
深度解析 Docker Registry:构建安全高效的私有镜像仓库
文章目录 什么是Docker Registry?Docker Hub vs. 私有RegistryDocker Hub:私有Registry: 如何构建私有Docker Registry?步骤一:安装Docker Registry步骤二:配置TLS(可选)步骤三&…...

leetcode 不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。 示例 1: 输入:n 3 输出:5 示例 2: 输入:n 1 输出:…...
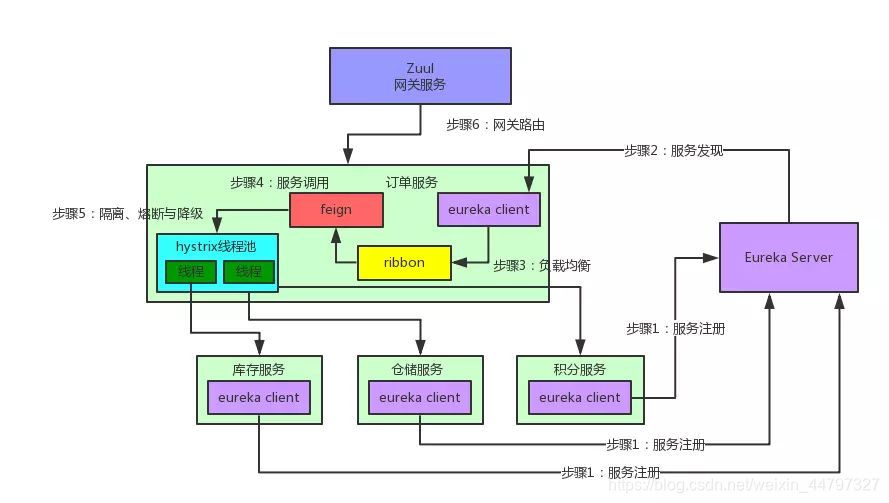
通俗易懂的spring Cloud;业务场景介绍 二、Spring Cloud核心组件:Eureka 、Feign、Ribbon、Hystrix、zuul
文章目录 通俗易懂的spring Cloud一、业务场景介绍二、Spring Cloud核心组件:Eureka三、Spring Cloud核心组件:Feign四、Spring Cloud核心组件:Ribbon五、Spring Cloud核心组件:Hystrix六、Spring Cloud核心组件:Zuul七…...

大数据预处理技术
文章目录 前言 大数据技术成为前沿专业 也是现在甚至未来的朝阳产业,大数据有分别是 数据预处理 数据存储 大数据处理和分析 数据可视化 部分组成 ,大数据行业有数据则称王,大数据的核心是数据本身 怎么获取有价值的数据呢?本章讲…...

跳表的学习记录
跳表(Skip List)是一种数据结构,它通过在多个层次上添加额外的前向指针来提高有序数据的搜索效率。跳表与其他常见的有序数据结构(如二叉搜索树、平衡树如AVL树和红黑树、B树等)相比,具有其独特的优缺点&am…...

电子学会C/C++编程等级考试2022年09月(二级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:统计误差范围内的数 统计一个整数序列中与指定数字m误差范围小于等于X的数的个数。 时间限制:5000 内存限制:65536输入 输入包含三行: 第一行为N,表示整数序列的长度(N <= 100); 第二行为N个整数,整数之间以一个空格分…...
如何使用nginx部署静态资源
Nginx可以作为静态web服务器来部署静态资源,这个静态资源是指在服务端真实存在,并且能够直接展示的一些文件数据,比如常见的静态资源有html页面、css文件、js文件、图片、视频、音频等资源相对于Tomcat服务器来说,Nginx处理静态资…...
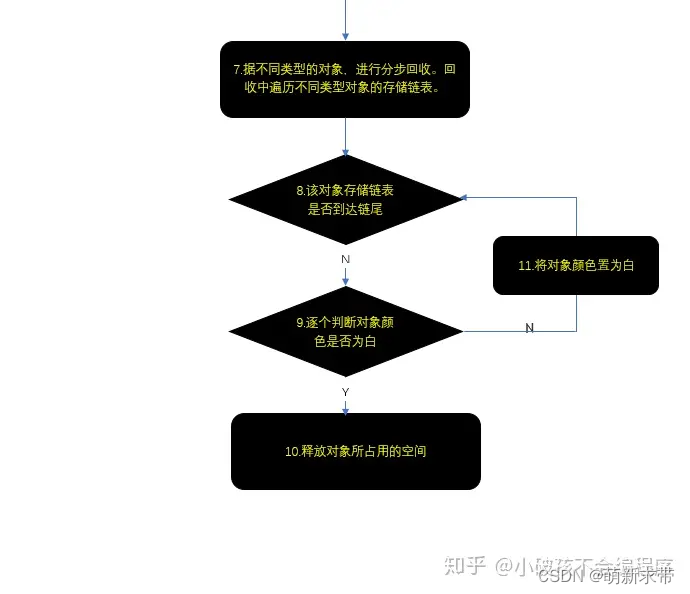
lua的gc原理
lua垃圾回收(Garbage Collect)是lua中一个比较重要的部分。由于lua源码版本变迁,目前大多数有关这个方面的文章都还是基于lua5.1版本,有一定的滞后性。因此本文通过参考当前的5.3.4版本的Lua源码,希望对Lua的GC算法有一个较为详尽的探讨。 L…...

redis作为缓存详解
目录 前言: 为什么说关系型数据库性能不高 如何提高MySQL并发量 缓存更新策略 定期更新 实时更新 内存淘汰策略 Redis内置的淘汰策略 缓存常见问题 缓存预热 缓存穿透 缓存雪崩 缓存击穿 前言: 对于缓存的理解,缓存目的就是为了…...
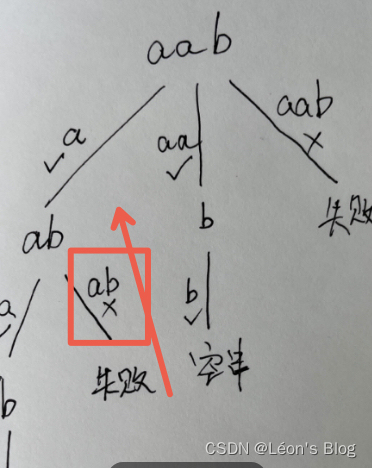
231127 刷题日报
这周值班。。多少写道题吧,保持每天的手感。老婆给买了lubuladong纸质书,加油卷。 1. 131. 分割回文串 写个这个吧,钉在耻辱柱上的题。 为啥没写出来: 1. 递归树没画对 把树枝只看做是1个字母,而且不清楚树枝和节点…...
【Linux】vim-多模式的文本编辑器
本篇文章内容和干货较多,希望对大家有所帮助👍 目录 一、vim的介绍 1.1 vi 与 vim的概念1.2 Vim 和 Vi 的一些对比 二、vim 模式之间的切换 2.1 进入vim2.2 [正常模式]切换到[插入模式]2.3 [插入模式]切换至[正常模式]2.4 [正常模式]切换至[底行模式…...

Ubuntu 启用 root 用户
在启用 root 用户之前,我们先来了解一下, ubuntu 命令的组成。 打开 ubuntu 的终端,现在的命令行是由 topeetubuntu:~$ 这几个字母组成,那么这几个字母都代表 什么意思呢? topeet …...
手摸手Element-ui路由VueRoute
后端WebAPI准备 https://router.vuejs.org/zh/guide/ https://v3.router.vuejs.org/zh/installation.html <template><el-table:data"tableData"style"width: 100%":row-class-name"tableRowClassName"><!-- <el-table-colum…...

探究Kafka原理-5.Kafka设计原理和生产者原理解析
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理🔥如果感觉博主的文章还不错的话,请ὄ…...

浅谈C#在unity应用中的工厂模式
文章目录 前言简单工厂模式工厂方法模式抽象工厂模式Unity实战 前言 工厂模式是一种创建型设计模式,它提供了一种将对象的实例化过程封装起来的方法,使得客户端代码不必直接依赖于具体类。这有助于降低代码的耦合度,提高代码的可维护性和可扩…...

5步打造Xbox 360游戏PC运行环境:Xenia Canary模拟器全攻略
5步打造Xbox 360游戏PC运行环境:Xenia Canary模拟器全攻略 【免费下载链接】xenia-canary Xbox 360 Emulator Research Project 项目地址: https://gitcode.com/gh_mirrors/xe/xenia-canary Xenia Canary作为领先的Xbox 360开源模拟器,通过精准的…...

如何用智能工具彻底改变黑苹果配置:一站式自动化解决方案的革命性突破
如何用智能工具彻底改变黑苹果配置:一站式自动化解决方案的革命性突破 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在技术爱好者的世界…...

科学发表的组学多面板图组装
摘要 高效的图件能清晰传达研究数据与结果,而组装用于科学发表的组学多面板图是项耗时且易出错的工作,往往需要专业的软件和操作技能,目前尚无1款可快速高效组装复杂组学多面板图的专用工具。本研究开发了1款操作友好…...

企业内部培训,适合用教学云桌面吗?
企业内部培训常面临环境部署繁琐、运维压力大、设备资源固化、数据安全难控等问题,教学云桌面凭借集中化管理与弹性资源配置,成为不少企业的选型方向。结合实际应用与技术特性来看,教学云桌面适配企业培训场景,且能系统性解决传统…...
)
收藏!只会CRUD也能学大模型,程序员3个月上手实战指南(小白必看)
最近刷CSDN和技术交流群,经常看到很多程序员朋友在纠结两个问题,尤其刚入门或只做过基础开发的小白,问得最多: “我只会写CRUD,没接触过AI,现在学大模型还来得及吗?” “从现在开始学࿰…...

GLM-4V-9B多模态入门必看:图片上传→提问→结构化输出三步走
GLM-4V-9B多模态入门必看:图片上传→提问→结构化输出三步走 想让AI看懂图片并回答你的问题吗?GLM-4V-9B多模态大模型就能做到。这个模型不仅能理解图片内容,还能用文字详细回答你的各种问题,就像有个专业的图片分析师随时待命。…...

GBase 8a 字符集、排序规则和字符串比较结果偏差
GBase 8a 字符集、排序规则和字符串比较结果偏差 我最近看资料和整理现场问题时,越来越觉得 GBase 8a 里很多“查出来不对”的问题,并不是表没导对,也不是 SQL 逻辑写错了,而是字符集、排序规则、大小写处理和字符串比较语义没有统…...

Qwen3.5-9B中微子:探测器结构理解+相互作用模拟+数据分析提示
Qwen3.5-9B中微子:探测器结构理解相互作用模拟数据分析提示 1. 项目概述 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。该模型支持多模态理解(图文输入)和长上下文处理ÿ…...
。)
Python爬虫入门:10步快速掌握网页数据抓取,【大数据实战】如何从0到1构建用户画像系统(案例+数据仓库+Airflow调度)。
准备工作 安装Python环境,确保版本在3.6以上。推荐使用Anaconda管理Python环境,避免版本冲突。安装必要的库,如requests、BeautifulSoup、lxml等。可以通过pip命令快速安装: pip install requests beautifulsoup4 lxml理解基本概念…...

论文阅读:AIED 2025 Understanding University Students‘ Use of Generative AI: The Roles of Demographics an
总目录 大模型相关研究 2025版:https://blog.csdn.net/WhiffeYF/article/details/142132328 Understanding University Students’ Use of Generative AI: The Roles of Demographics and Personality Traits https://arxiv.org/abs/2505.02863 该论文题为《Und…...